Databricks pour le bien et la fondation de la vertu : Partenariat pour connecter les bénévoles médicaux à des services de santé essentiels dans 72 pays
par Priyanka Mehta et Shaunak Sen
- La Virtue Foundation s'est associée à Databricks for Good pour exploiter l'IA afin d'améliorer les résultats des soins de santé mondiaux.
- Le résultat a permis à la Virtue Foundation de mieux faire correspondre les compétences des cliniciens aux opportunités de bénévolat dans les pays en développement où ces compétences sont le plus nécessaires.
- Ensemble, les équipes Databricks et Virtue Foundation fournissent des ensembles de données de base mis à jour dans un format facilement accessible et exploitable.
Introduction
Virtue Foundation est une organisation à but non lucratif axée sur la prestation de soins de santé mondiaux et la création d'un marché efficace pour la philanthropie mondiale dans le domaine de la santé. À ce jour, ils ont soigné plus de 50 000 patients, avec un accent particulier sur le Ghana et la Mongolie. L'épine dorsale de ce marché est la curation des données des établissements de santé mondiaux via VF Match, une plateforme qui met en relation les professionnels de la santé avec des opportunités de bénévolat dans 72 pays à revenu faible ou intermédiaire. Databricks for Good collabore étroitement avec Virtue Foundation depuis 2024 pour exploiter l'IA afin d'agréger les données de ces pays et de les rendre exploitables.
Une première preuve de concept a démontré que les LLM pouvaient extraire des informations structurées à partir de diverses sources de données Web pour créer une carte de l'infrastructure de santé et, surtout, des lacunes dans les services dans les zones sous-dotées. Cependant, la mise à l'échelle de cette fonctionnalité et sa mise en production ont posé de nombreux défis. Depuis cette première itération, nous avons construit une plateforme basée sur Databricks qui a transformé la preuve de concept en un système de qualité production, agrégeant des données de milliers d'établissements de santé et d'organisations à but non lucratif du monde entier.
Dans cet article, nous expliquons comment nous avons amélioré nos travaux antérieurs pour permettre davantage à Virtue Foundation de faire correspondre sa communauté de professionnels de la santé bénévoles avec les besoins critiques de ces pays.
Construction des fondations : 72 pays de données sur la santé
Le cœur de VF Match est le Foundational Data Refresh (FDR) : un ensemble de données complet sur les établissements de santé et les organisations à but non lucratif, construit à partir de diverses sources Web. Nous ingérons et actualisons systématiquement les données de 72 pays à revenu faible ou intermédiaire du monde entier.
Deux sources de données complémentaires alimentent cette actualisation :
- Overture Maps : Un ensemble de données géospatiales open-source de Meta et Microsoft, fournissant des emplacements faisant autorité pour les établissements de santé.
- Bright Data : Une infrastructure industrielle de web scraping qui capture des informations en temps réel sur Internet.
Le cœur du FDR est un pipeline d'extraction d'informations alimenté par les modèles GPT d'OpenAI. Le traitement de plus de 25 millions de pages Web par des LLM avec des garanties de production a nécessité de repenser les pipelines d'inférence LLM traditionnels. Plutôt que de tenter une extraction en une seule étape, notre pipeline décompose la tâche en étapes ciblées : classification de la pertinence médicale, identification du type d'organisation (établissement médical ou ONG), et extraction des spécialités, équipements et procédures.
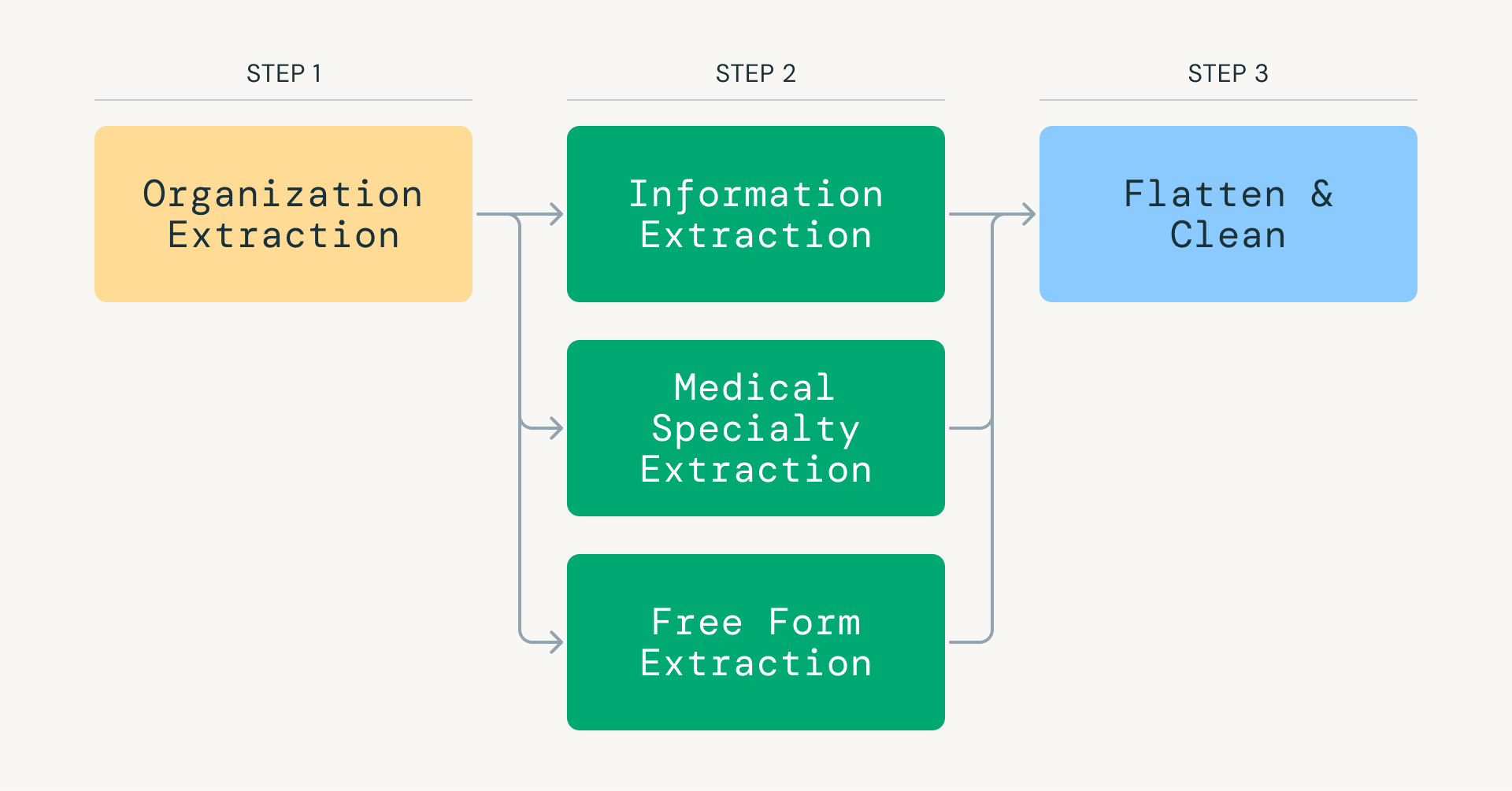 Fig 1 : Étapes clés du Foundational Data Refresh (FDR).">
Fig 1 : Étapes clés du Foundational Data Refresh (FDR).">Cette approche réduit considérablement la consommation de jetons tout en concentrant chaque invocation de modèle sur une tâche étroite et de haute précision. Databricks et Apache Spark sont utilisés pour orchestrer et paralléliser efficacement les données extraites, distribuant les charges de travail sur des milliers d'exécuteurs et permettant une inférence LLM à haut débit.
Un certain nombre de fonctionnalités critiques rendent ce pipeline évolutif et prêt pour la production :
- Modélisation de données extensible : Les données à chaque étape sont stockées dans un schéma en étoile, simplifiant l'analyse en aval et améliorant les performances des requêtes.
- Point de contrôle basé sur l'état : Chaque enregistrement suit son état de traitement, permettant aux pipelines de reprendre à tout moment sans retraiter les lignes avec des appels LLM coûteux.
- Registre d'extraction configurable : Chaque méthode d'extraction est contrôlée par un objet structuré spécifiant le prompt système, rendant la logique d'extraction modulaire, reproductible et extensible.
- Traitement distribué évolutif : Le système traite des charges de travail déséquilibrées de plusieurs téraoctets en utilisant Spark pour le parallélisme, Photon pour les performances à grande échelle et une orchestration de qualité production.
Ces garanties sont appliquées via Lakeflow Jobs, qui orchestre plus de 15 tâches interdépendantes avec une logique conditionnelle, une exécution parallèle et des politiques de nouvelle tentative intelligentes. Le résultat est un système qui traite les données des établissements de santé à grande échelle avec la précision d'experts médicaux.
Résolution d'entités à grande échelle
Une fois les données des établissements et des organisations à but non lucratif collectées et extraites à l'aide d'un LLM, un défi classique apparaît : la résolution d'entités. Le même établissement peut apparaître dans plusieurs sources de données avec des variations de nom, des adresses incohérentes ou des détails de contact manquants. La déduplication traditionnelle échoue dans ces scénarios en raison de données désordonnées, nous utilisons donc Splink, un framework open-source de liaison probabiliste d'enregistrements. En utilisant les informations sourcées dans notre étape d'extraction d'informations, Splink évalue les paires correspondantes via des comparaisons pondérées sur des champs tels que le numéro de téléphone, l'adresse postale, et plus encore. Le résultat est une clé unifiée par établissement, garantissant que les utilisateurs finaux voient un enregistrement faisant autorité pour chaque établissement médical et ONG.
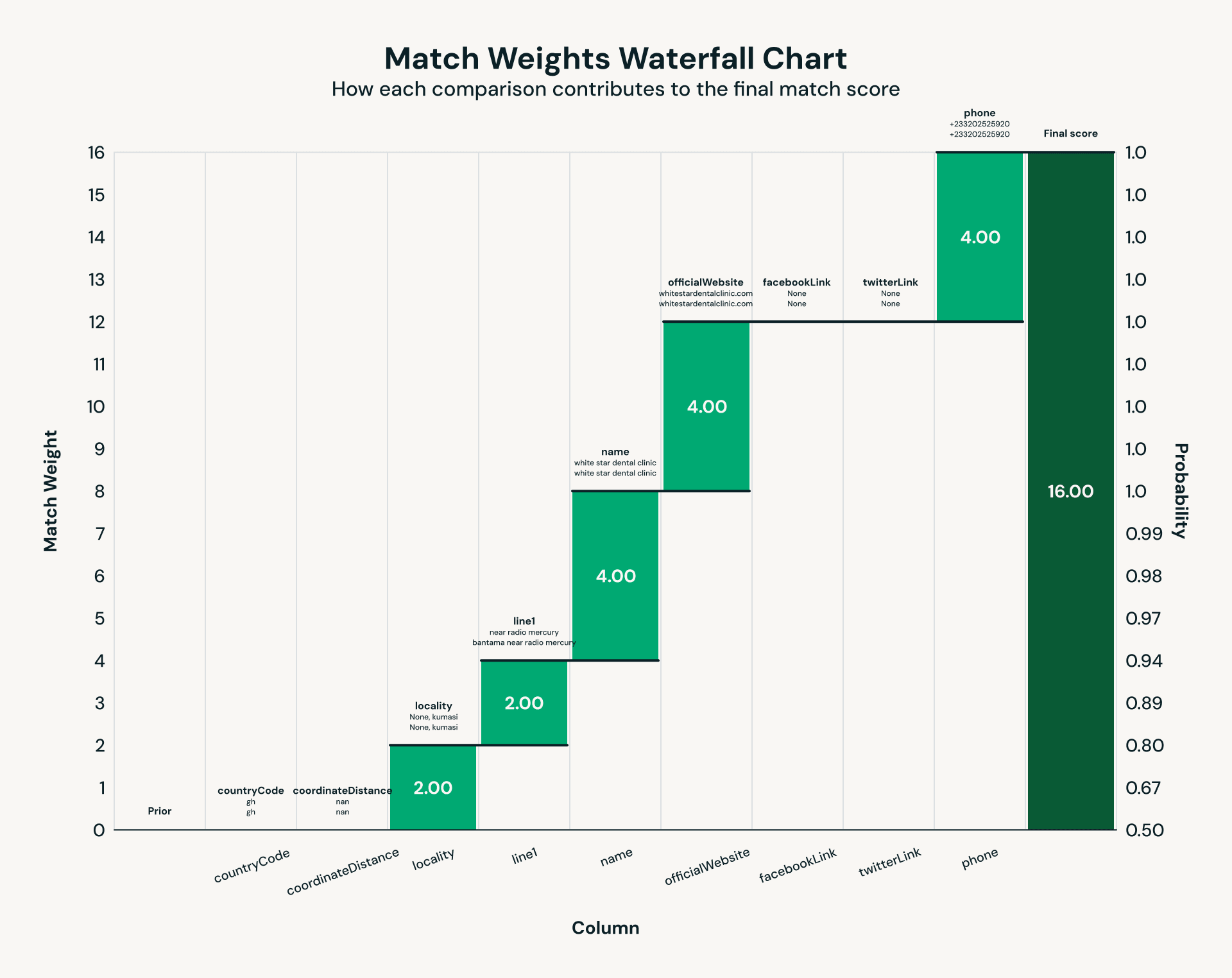 Fig 2 : Exemple de jeu de règles pour la résolution d'entités via Splink.">
Fig 2 : Exemple de jeu de règles pour la résolution d'entités via Splink.">L'exécution de la correspondance probabiliste sur des milliers d'établissements de santé et d'organisations à but non lucratif a révélé des goulots d'étranglement de performance classiques qui apparaissent à l'échelle des téraoctets. Le cœur de la liaison d'enregistrements est la comparaison par paires, qui crée des charges de travail intrinsèquement déséquilibrées : les comparaisons courantes produisent des partitions massives tandis que la plupart des autres restent beaucoup plus petites. Les premières exécutions l'ont clairement montré, avec une partition Spark s'exécutant pendant 30 minutes tandis que la médiane se terminait en 52 secondes – un cas classique de « stragglers » (la « malédiction du dernier réducteur ») dégradant les performances du travail. L'activation de Photon, le moteur de requêtes vectorisées de Databricks, a réduit les partitions de données les plus longues de 30 minutes à environ 2 minutes : une amélioration de 15x.
VF Agent : Le langage naturel rencontre les données de santé
En regardant vers l'avenir, nous avons développé un prototype d'agent qui permet aux experts d'analyser les données en utilisant le langage naturel. Nous utilisons une architecture multi-agents construite dans LangGraph et exploitons Databricks Model Serving, AI Search et Genie.
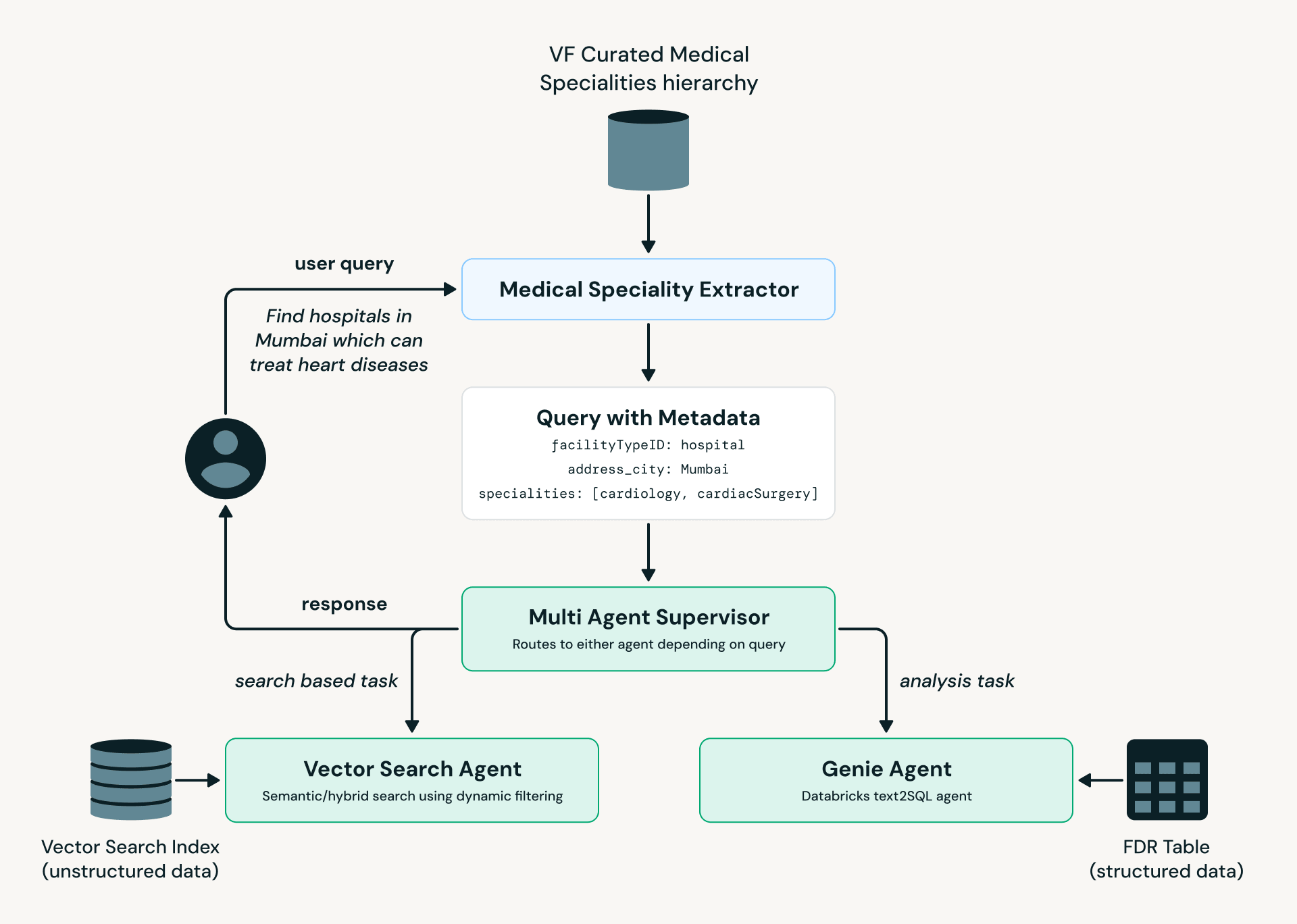 Fig 3 : VF Agent : Diagramme du flux de processus">
Fig 3 : VF Agent : Diagramme du flux de processus">Comme illustré dans le diagramme ci-dessus, le Medical Specialty Extractor convertit le langage de l'utilisateur en terminologie médicale standardisée, qui est ensuite transmise au Multi-Agent Supervisor. En fonction de l'intention et de la complexité de la requête, elle est acheminée vers le AI Search Agent (découverte et recherche d'établissements) ou le Genie Agent (requêtes analytiques sur des données structurées).
Résumé
Les professionnels de la santé peuvent désormais découvrir plus rapidement des opportunités à jour, trouver des correspondances avec leurs spécialités médicales et accéder à des données mondiales sur des milliers d'établissements dans le monde. Le parcours de Virtue Foundation, de la preuve de concept à la production, démontre ce qui est possible lorsque des systèmes d'IA avancés sont associés à une plateforme de données unifiée.
Le résultat final est une vue mondiale de l'infrastructure de santé, révélant où les professionnels de la santé bénévoles sont le plus nécessaires.
Si vous souhaitez en savoir plus sur ce projet, veuillez consulter :
- Présentation du projet Databricks x Virtue Foundation - YouTube
- Interview UN Bloomberg (YouTube) - vers la minute 38:00
- Témoignage vidéo : Bright Initiative x Virtue Foundation x Databricks
Veuillez en savoir plus sur certains de nos autres projets Databricks for Good ci-dessous :
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.