TEST - Un guide concis pour le réglage fin et la création de LLM personnalisés
par Team Databricks
Introduction
L'IA générative (GenAI) a le potentiel de démocratiser l'IA, de transformer chaque secteur d'activité, de soutenir chaque employé et d'engager chaque client. Pour être la plus utile, les modèles GenAI nécessitent une compréhension approfondie des données d'entreprise d'une organisation. À ce jour, les techniques les plus populaires pour donner aux modèles GenAI la connaissance de votre entreprise sont l'ingénierie de prompt, la génération augmentée par récupération (RAG), les chaînes et les agents. Cependant, ces techniques atteignent leurs limites lorsqu'elles utilisent des modèles généraux non adaptés à des domaines et des applications spécifiques. Pour améliorer les résultats générés et réduire les coûts, les développeurs d'applications GenAI doivent se tourner vers la création de modèles personnalisés via le fine-tuning ou le pré-entraînement.
Le fine-tuning spécialise un modèle d'IA existant pour un domaine ou une tâche spécifique en l'entraînant davantage sur un ensemble plus petit de données personnalisées. Les techniques incluent le fine-tuning supervisé pour le suivi des instructions ou le chat, ainsi que le pré-entraînement continu. Le pré-entraînement crée un modèle entièrement nouveau en l'entraînant à partir de zéro sur des données entièrement personnalisables. Toutes ces techniques permettent aux développeurs de créer de la propriété intellectuelle et de la différenciation pour leur domaine ou leur application, avec le potentiel de créer des modèles meilleurs et plus précis et d'utiliser des architectures de modèles plus petites et moins coûteuses.
Dans ce guide sur la création de modèles personnalisés, nous abordons :
- Motivation : Pourquoi et quand devriez-vous créer un modèle GenAI personnalisé ?
- Principes : Quelles pratiques de haut niveau devraient guider votre stratégie et votre mise en œuvre lors de la création de modèles personnalisés ?
- Techniques : Comment pouvez-vous créer des modèles personnalisés ? Quelles techniques et quels "pièges" devez-vous connaître pour la préparation des données, l'entraînement et l'évaluation ?
Ce guide s'adresse aux praticiens qui prévoient de créer des modèles personnalisés. Nous supposons une compréhension de la GenAI et des grands modèles de langage (LLM), y compris des termes tels que l'ingénierie de prompt, RAG, les agents, le fine-tuning et le pré-entraînement. Pour du matériel d'introduction, veuillez consulter notre section sur l' IA générative et les LLM.
À propos de Databricks
Databricks fournit des outils unifiés pour construire, déployer et surveiller des solutions d'IA et de ML — de la création de modèles prédictifs aux dernières GenAI et LLM. Construit sur la plateforme Databricks Data Intelligence Platform, Databricks permet aux organisations d'intégrer en toute sécurité et de manière rentable leurs données d'entreprise dans le cycle de vie de l'IA avec n'importe quel modèle GenAI. Nous permettons aux clients de déployer, gouverner, interroger et surveiller des modèles fine-tunés ou pré-déployés par Databricks, comme Meta Llama 3, DBRX ou BGE, ou provenant d'autres fournisseurs de modèles comme Azure OpenAI GPT-4, Anthropic Claude, AWS Bedrock et AWS SageMaker. Pour personnaliser les modèles avec des données d'entreprise, Databricks fournit tous les modèles architecturaux, de l'ingénierie de prompt, RAG, au fine-tuning et au pré-entraînement.
Databricks fournit des capacités de fine-tuning et de pré-entraînement GenAI inégalées par toute autre plateforme d'IA. En juin 2024, les clients de Databricks avaient créé plus de 200 000 modèles d'IA personnalisés au cours de l'année précédente. De plus, Databricks propose des modèles pré-entraînés que les clients peuvent utiliser directement. En mars 2024, Databricks a publié DBRX, un nouveau LLM open source performant qui a été pré-entraîné à partir de zéro, sous une licence commercialement viable. En juin 2024, Databricks et Shutterstock ont publié un autre modèle pré-entraîné, Shutterstock ImageAI, Powered by Databricks, un modèle de pointe de texte à image.
L'infrastructure et la technologie que nous avons utilisées pour construire ces modèles performants sont les mêmes que celles fournies à nos clients. Consultez nos histoires clients Databricks pour lire des succès en matière de données et d'IA dans tous les secteurs d'activité.
Motivation : Pourquoi faire du fine-tuning ou créer des LLM personnalisés ?
Les clients commencent généralement à créer des modèles GenAI personnalisés lorsque les modèles existants présentent des limitations frustrantes en termes de qualité, de coût ou de latence. Les spécificités varient pour chaque cas d'utilisation, mais voici quelques exemples :
- « J'ai besoin d'un modèle pour générer le langage de requête spécial de mon produit. Je peux le faire en utilisant des API de modèles et du prompting à quelques exemples, mais c'est très lent et coûteux. »
- « Mon bot RAG fonctionne bien, mais il utilise une API de modèle volumineuse et puissante qui est trop chère pour mon cas d'utilisation à haut débit. Je n'ai pas besoin d'un modèle aussi général, donc je veux faire le fine-tuning d'un petit modèle ciblé et peu coûteux. »
- « Je ne trouve pas de modèle open source performant en langue X, donc je veux créer un modèle adapté pour comprendre X. »
Les modèles GenAI les plus célèbres sont des modèles généraux conçus pour tout faire (ou presque). Bien qu'impressionnants, ces modèles sont trop volumineux et coûteux pour la plupart des cas d'utilisation, et ils ne connaissent rien à vos données propriétaires ou à votre application. Dans tous les exemples ci-dessus, la création d'un modèle personnalisé et spécialisé a amélioré la qualité ou réduit le coût et la latence. Le modèle personnalisé est devenu une propriété intellectuelle et a fourni un avantage concurrentiel pour le produit du client.
Une motivation moins courante mais plus pressante pour la création de modèles personnalisés provient de préoccupations juridiques ou réglementaires, en particulier dans les industries plus réglementées. Certains clients souhaitent ou ont besoin d'un contrôle total sur leurs modèles afin de gérer les risques, tels que les accusations d'utilisation illégale de contenu pour l'entraînement de modèles. En pré-entraînant un modèle entièrement personnalisé, vous pouvez savoir et prouver exactement comment le modèle a été créé.
Alors, comment commencer ? Bien que la GenAI soit un domaine de recherche complexe, il peut être simple de commencer à personnaliser les modèles GenAI. Il existe un chemin naturel, du fine-tuning de base au pré-entraînement complexe, et la plateforme Databricks prend en charge l'ensemble de ce flux de travail. En suivant ce chemin, vous développerez une expertise et des données qui alimenteront des types de personnalisation de modèles futurs plus complexes.
Principes : Quand et comment devriez-vous faire du fine-tuning ou créer des modèles personnalisés ?
Quand, pourquoi et comment devriez-vous créer des modèles personnalisés ?
À un niveau élevé, les systèmes GenAI peuvent être personnalisés de deux manières :
- IA Composée : À partir d'un ou plusieurs modèles existants, vous pouvez construire des systèmes RAG, des agents et d'autres systèmes d'IA composés autour de ces modèles.
- Modèles personnalisés : Vous pouvez personnaliser un modèle existant (fine-tuning) ou créer un modèle entièrement nouveau (pré-entraînement).
Ces deux options peuvent être combinées, par exemple un RAG utilisant un LLM fine-tuné. De telles combinaisons — et la vitesse du développement GenAI — peuvent rendre la planification et la création d'applications GenAI complexes. Pour simplifier votre approche, nous recommandons trois principes directeurs.
Principe 1 : Commencez petit et progressez
Pour toute application GenAI, nous vous recommandons de commencer simplement et d'ajouter de la complexité si nécessaire. Cela peut signifier commencer avec un modèle existant (tel que les API Databricks Foundation Model) et effectuer une ingénierie de prompt simple. Ensuite, ajoutez des techniques au besoin pour améliorer vos métriques de qualité, de coût et de vitesse.
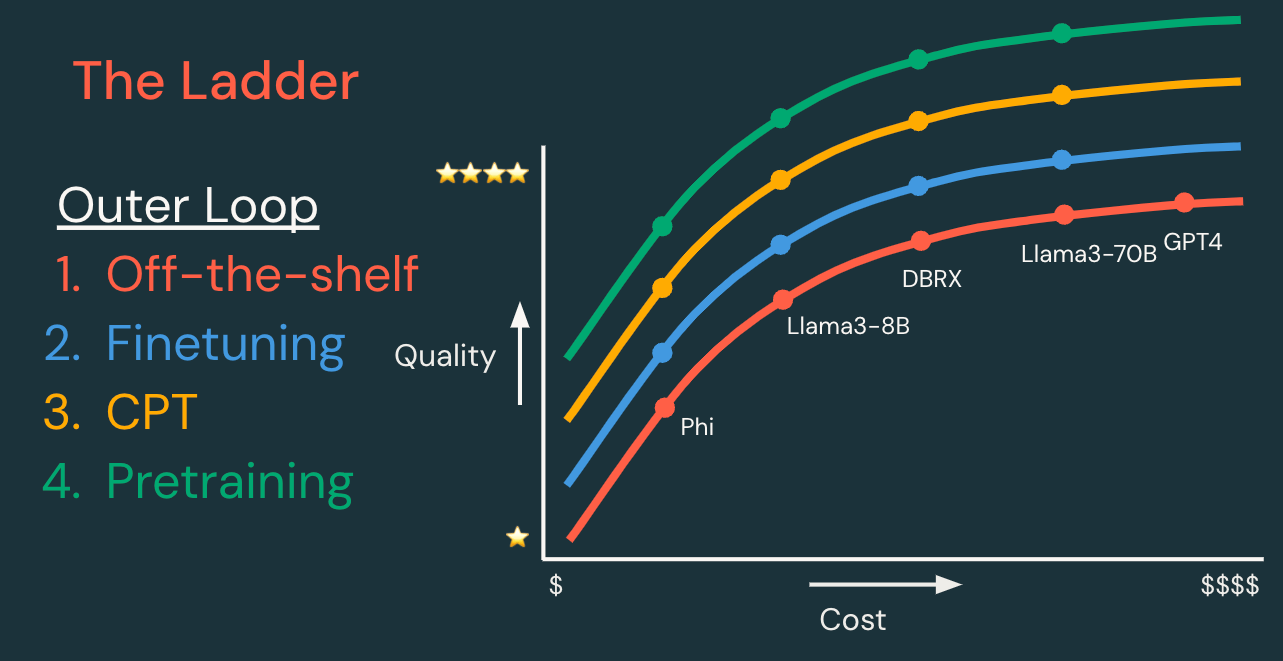
L'« échelle » des techniques peut être divisée en boucles de développement internes et externes, décrites ci-dessous.
Boucle externe : Échelle de personnalisation des modèles | ||||
Chaque étape a le potentiel de créer un modèle de meilleure qualité, moins coûteux et/ou avec une latence plus faible. | Données requises | Temps de développement | Coût de développement | |
Modèle existant | Commencez avec un modèle ou une API de modèle existant, et itérez d'abord sur la boucle interne. | Aucune, ou données pour RAG | Heures | $ |
Fine-tuning supervisé | Personnalisez un modèle pour mieux gérer votre tâche spécifique. “Attendez-vous à des requêtes comme celles-ci, et fournissez des réponses comme celles-là.” | Des centaines à des dizaines de milliers d’exemples | Jours | $$ |
Pré-entraînement continu | Personnalisez un modèle pour mieux comprendre votre domaine. “Apprenez le langage de ce domaine d’application de niche.” | Des millions à des milliards de jetons | Semaines | $$$ |
Pré-entraînement | Créez un nouveau modèle pour un contrôle, une personnalisation et une propriété complets. “Apprenez tout à partir de zéro !” | Des milliards à des trillions de jetons | Mois | $$$$$$ |
Boucle interne : Techniques d’IA combinées | |
Chaque technique ci-dessous peut améliorer la qualité de génération pour un modèle donné. Ces techniques sont listées par ordre (approximatif) de complexité, mais elles peuvent être mélangées et associées. | |
Ingénierie des prompts | Créez des prompts spécifiques à la tâche pour guider le comportement du modèle. |
Prompting Few-Shot | Fournissez des données dans les prompts pour enseigner aux modèles au moment de l’inférence. |
RAG | Fournissez des données spécifiques à la requête aux modèles comme contexte supplémentaire. |
Agents | Fournissez aux modèles des outils appelables et/ou un flux de contrôle complexe. |
Adopter une technique de la boucle interne est relativement peu coûteux et rapide, par rapport à monter d’un cran dans la boucle externe. Par conséquent, chaque fois que vous montez dans la boucle externe, il est utile d’itérer sur tout ou partie des techniques de la boucle interne. Cette désignation “interne” par opposition à “externe” est inversée par rapport à ce que vous attendriez de l’architecture système — la boucle “interne” de l’IA combinée enveloppe la boucle “externe” de votre modèle. Nous appelons la personnalisation du modèle la boucle “externe” car c’est la boucle externe en termes de votre flux de travail, tel que dicté par les coûts relatifs des boucles interne et externe.
Principe 2 : Soyez axé sur les données
Avant d’investir sérieusement dans un projet, définissez soigneusement votre mesure de succès et suivez les pratiques populaires de développement piloté par l’évaluation.
Au niveau des systèmes d’IA, considérez les métriques de qualité, de coût et de latence.
- Qualité impliquera probablement plusieurs métriques : précision, feedback utilisateur, toxicité, etc.
- Coûts pour les systèmes en production se concentrent généralement sur l’inférence du modèle et le service des données
- Latence peut signifier la latence de bout en bout, ou le temps jusqu’au premier jeton pour les applications plus interactives
Quels chiffres ces métriques doivent-elles atteindre pour déclarer le succès ? Quelles contraintes strictes avez-vous sur ces métriques pour garantir une bonne expérience utilisateur, un retour sur investissement positif ou d’autres exigences commerciales ? Consultez cette présentation de notre scientifique IA en chef pour plus de détails.
Au niveau du projet et des affaires, analysez le retour sur investissement.
- Coûts (investissement) doivent être divisés en deux phases :
- Coûts de développement peuvent inclure les coûts de calcul et humains pour la préparation des données, l’entraînement du modèle et le développement du système
- Coûts récurrents peuvent inclure le service des modèles et des données, ainsi que les heures-personnes de maintenance
- Impact commercial (rendement)
- Revenus ou autres objectifs commerciaux et résultats clés (OKR) peuvent aller du gain de temps humain (pour un bot de support GenAI) aux revenus directs (pour un produit alimenté par GenAI)
- Création de propriété intellectuelle, comme de nouveaux modèles ou données, peut être l’impact le plus difficile à mesurer mais le plus important à long terme. Tout le monde peut utiliser les mêmes API de fournisseurs de modèles, mais vous seul pouvez utiliser vos modèles et données propriétaires.
Vos objectifs axés sur les données informeront vos choix concernant la personnalisation du modèle (principe 1). Par exemple, si vous atteignez vos métriques de qualité mais dépassez vos contraintes de coûts en utilisant une API de modèle coûteuse, vous pourriez passer au réglage fin d’un modèle plus petit et plus efficace, adapté à votre tâche spécifique, afin de réduire les coûts tout en maintenant la qualité. Le réglage fin entraînera des coûts de développement supplémentaires mais réduira les coûts récurrents — et réduira le coût global à long terme.
Principe 3 : Restez pragmatique
L’évaluation des modèles et systèmes GenAI est difficile. Les techniques de réglage fin et de pré-entraînement sont un domaine de recherche actif. L’enthousiasme académique et industriel (et les LLM) génèrent beaucoup plus de contenu qu’on ne peut en lire. Ces sources de confusion rendent difficile de savoir quand utiliser quelles techniques. (“Ai-je besoin de LoRA ? Qu’est-ce que l’apprentissage par curriculum ? Quelle architecture de modèle est la meilleure ?”)
Beaucoup de personnes nouvelles dans le domaine GenAI ont entendu dire qu’on peut jeter des montagnes de données sur GenAI et qu’il apprendra des choses incroyables. Tempérez ces attentes. La quantité de données est importante, mais la qualité des données, les techniques d’entraînement et l’évaluation le sont aussi.
Les clients Databricks peuvent en partie s’appuyer sur les conseils intégrés à Databricks tout au long de leur parcours dans l’échelle de la personnalisation GenAI. Ces conseils vont des API simples pour les modèles généraux au Agent Bricks Custom Agents pour RAG et les agents, en passant par une interface utilisateur et une API pour le réglage fin, et même une API guidée pour le pré-entraînement.
Cependant, plus vous poussez la personnalisation, plus vous rencontrerez de techniques et de décisions possibles. Nous vous recommandons de rester pragmatique. Les techniques qui ont fonctionné en recherche peuvent ne pas fonctionner dans des applications réelles. Les modèles bons pour une tâche peuvent être mauvais pour une autre. Les meilleures techniques évolueront avec le temps. Pour naviguer dans cette complexité, gardez à l’esprit les principes 1 et 2 : Définissez votre étoile polaire et suivez-la en vous basant sur les données et les métriques.
Nous vous recommandons également de vous associer à nous. Au-delà de votre équipe Databricks immédiate, notre équipe de services professionnels peut vous guider depuis les preuves de concept initiales jusqu’aux exécutions complètes de pré-entraînement. Notre équipe de recherche Mosaic collabore avec de nombreux clients pour des exécutions de pré-entraînement, leur donnant accès à des connaissances et des conseils de pointe.
Techniques pour construire des LLM personnalisés
Étant donné que vous souhaitez monter dans la boucle externe de personnalisation du modèle, comment devriez-vous aborder les techniques introduites avec le principe 1 ? Cette section aborde l’évaluation, puis explore les principales techniques de personnalisation.
Remarque : Ce guide ne se concentre pas sur la boucle interne d’itération sur un modèle fixe. Pour plus d’informations sur ces techniques, consultez les cours Fondamentaux de l’IA générative et Ingénierie de l’IA générative avec Databricks.
Cette section développe les techniques de personnalisation décrites précédemment dans la boucle externe du principe 1. Nous les listons ici et notons que votre choix de technique sera largement déterminé par les données dont vous disposez (principe 2).
Boucle externe : Échelle de personnalisation du modèle | ||
Type de données requis | Conseils sur la taille des données | |
Modèle existant | NA | Aucune, ou données pour RAG |
Fine-tuning supervisé | Données de requête-réponse (ou autrement “étiquetées”) | Au moins 100 à 10 000 exemples |
Pré-entraînement continu | Texte “brut” pour la prédiction du prochain token | Millions à milliards de tokens, ou 1 %+ de l’ensemble d’entraînement d’origine |
Pré-entraînement | Texte “brut” pour la prédiction du prochain token | Milliards à trillions de tokens |
Dans la section suivante, nous aborderons chaque technique plus en détail, en commençant par des conseils qui restent constants pour toutes les techniques.
Données
Vos données doivent correspondre à votre cas d’utilisation. Si vous effectuez un fine-tuning d’un modèle pour qu’il réponde d’une certaine manière, vos données d’entraînement doivent démontrer des “bonnes” réponses. Si vous effectuez un pré-entraînement continu pour comprendre un domaine spécifique, vos données doivent représenter ce domaine.
Abordez les problèmes juridiques et de licence dès le départ. Lorsque vous utilisez des données publiques, en particulier pour le pré-entraînement, sachez que certains ensembles de données publics sont bien organisés pour éviter les complications juridiques et que certains ensembles de données ne le sont pas. Lorsque vous utilisez vos propres données d’entreprise, assurez-vous d’être certain de la provenance, en particulier si les données proviennent de clients ou de modèles GenAI avec des licences restrictives.
Collectez des données tôt et souvent. Les requêtes, les réponses et les commentaires des utilisateurs de vos applications aujourd’hui peuvent devenir des entrées pour le réglage et l’entraînement de votre modèle GenAI à l’avenir — mais seulement si vous y faites attention. De nombreux modèles propriétaires et open source sont soumis à des restrictions d’utilisation, alors suivez attentivement la provenance des réponses générées. Pour vous donner une flexibilité future, évitez de mélanger des modèles et des données avec des licences incompatibles et privilégiez les licences ouvertes.
Utilisez des données synthétiques avec prudence. Les données synthétiques peuvent être utiles, mais les données d’entreprise authentiques sont presque toujours plus précieuses. Les données “réelles” peuvent être utilisées pour informer les LLM sur la manière de générer des données synthétiques, ce que vous apprendrez plus tard dans ce guide. Les données synthétiques font toujours l'objet de recherches actives.
Modèles
Soyez conscient des modèles de base par rapport aux modèles d’instructions/de chat. La plupart des principales versions de LLM incluent à la fois des modèles de base (pré-entraînés mais non affinés) et des variantes suivant les instructions ou de chat (affinées). Voir nos recommandations sur le type à utiliser dans les sections suivantes.
Utilisez les modèles suggérés par les fonctionnalités de Databricks. Mosaic Research étudie les architectures de modèles de pointe, partage certaines recommandations de premier plan pour les modèles GenAI et priorise ces modèles de premier plan dans Databricks Model Training et d�’autres fonctionnalités.
Descendez vers un code plus personnalisé si nécessaire. Si les modèles ou les méthodes d’entraînement par défaut ne répondent pas à vos besoins, vous pouvez toujours “descendre dans la pile” et utiliser un code plus personnalisé. Les clusters Databricks accélérés par GPU (calcul général) et Databricks Model Training (calcul spécialisé en deep learning) prennent tous deux en charge le code d’entraînement arbitraire pour GenAI et d’autres modèles de deep learning.
Identifiez les modèles qui montrent des promesses pour votre cas d’utilisation. Avant le réglage, examinez si le modèle générique montre des promesses pour votre application. La “promesse” peut être mesurée par des tests manuels ad hoc à l’aide de l’ AI Playground ou un test plus rigoureux à l’aide d’un ensemble de données de référence ou de votre ensemble de données d’évaluation personnalisé. Les tests peuvent nécessiter un entraînement à petite échelle. Pour le fine-tuning, le modèle s’améliore-t-il après le fine-tuning sur un petit ensemble de 100 exemples ? Pour le pré-entraînement, le modèle s’améliore-t-il grâce au pré-entraînement continu sur un ensemble de données spécifique ?
N’oubliez pas vos contraintes. Choisissez la taille de votre modèle en fonction de vos contraintes de coût et de latence au moment de l’inférence. N’oubliez pas non plus que la création de modèles personnalisés n’est que la boucle externe ; vous pouvez également optimiser les coûts et la latence dans la boucle interne, par exemple en acheminant les requêtes plus simples vers des modèles plus petits.
Astuce : Votre travail sur des techniques plus simples ne sera pas perdu, car ces techniques forment une séquence. Par exemple, après avoir pré-entraîné un modèle, vous effectuez généralement un fine-tuning supervisé ensuite.
Évaluation
Le principe 2 recommande d’être axé sur les données, avec des métriques. Avant de plonger dans les spécificités de la création de modèles personnalisés, nous aborderons les métriques relatives à l’évaluation et à la qualité qui peuvent guider votre travail.
Comme en ingénierie logicielle, nous recommandons de suivre une pyramide de tests.
Analogie des tests logiciels | Vitesse/coût vs. fidélité | Exemples |
Tests unitaires | Mesures substituts rapides et peu coûteuses | Tests avec réponses correctes/incorrectes |
Tests d’intégration | Tests de vitesse/coût moyen | Métriques LLM-en-tant-qu’juge sur des ensembles de données de référence |
Tests de bout en bout | Tests lents mais réalistes | Feedback humain |
Les exemples de la pyramide de tests ci-dessus sont rédigés de manière générique et évitent la question des tests des modèles (la boucle externe du principe 1) par rapport aux systèmes d’IA composés (boucle interne). Lors de la création d’un modèle personnalisé, vous voudrez tester à la fois le modèle lui-même et les systèmes d’IA qui l’utiliseront. Par exemple, les “métriques LLM-en-tant-qu’juge” pourraient être utilisées pour tester la capacité d’un modèle à suivre les instructions, et elles pourraient être utilisées pour tester les métriques de récupération et les métriques de réponse aux questions d’un système RAG.
Modèles et tâches spécifiques vs. généraux
Votre pyramide de tests sera très différente lors du fine-tuning d’un modèle pour une tâche spécifique par rapport au pré-entraînement d’un modèle à usage général. Être axé sur les données et les métriques signifie adapter votre pyramide de tests aux cas d’utilisation en aval de votre modèle.
Si vous effectuez un fine-tuning d’un modèle pour une tâche spécifique, n’oubliez pas de commencer petit (principe 1). Par exemple, vous pourriez :
- Construire un ensemble de données de requête-réponse “golden” pour l’évaluation. Assurez-vous qu’il est équilibré entre les requêtes et les sujets potentiels.
- Utiliser des métriques LLM-en-tant-qu’juge pour augmenter l’échelle de l’évaluation. Choisissez ou personnalisez des métriques pour votre tâche spécifique.
- Utiliser l’évaluation humaine ou utilisateur comme test final
Lorsque vous commencez le pré-entraînement continu ou le pré-entraînement complet, vos évaluations peuvent devenir plus complexes. Lors de la planification de votre pyramide de tests, décomposez votre évaluation selon les différentes compétences que vous pensez que votre modèle doit posséder afin de pouvoir vous concentrer sur les domaines importants. Cela peut signifier :
- Compétences telles que la connaissance générale, la logique ou la compréhension de lecture
- Domaines tels que la finance, le droit ou la santé
- Langues, y compris les langues naturelles ou les langages de programmation
- Autres dimensions, de la longueur du contexte aux garde-fous intégrés
Conseils :
- Adaptez votre évaluation à vos cas d'utilisation. Par exemple, si vous modifiez un modèle pour gérer des longueurs de contexte plus importantes, n'oubliez pas que les métriques de perplexité de pré-entraînement continu ne suffisent pas. Votre jeu de données d'évaluation doit également inclure des tâches à contexte long.
- Testez à la fois l'apprentissage et l'oubli. Si vous effectuez un pré-entraînement continu pour améliorer la compréhension d'un modèle d'une langue spécifique (par exemple, le malais), déterminez si vos cas d'utilisation exigent que ce modèle conserve sa compréhension existante des langues (par exemple, l'anglais). Si c'est le cas, votre évaluation devrait tester le malais et l'anglais.
- Testez ce que vos clients utiliseront réellement. Si vous pré-entraînez un nouveau modèle (de base), vous effectuerez probablement un réglage fin supervisé pour créer la version du modèle que vos clients utiliseront réellement. Votre évaluation finale (de bout en bout) doit porter sur le modèle réglé, et non sur le modèle de base.
Exemples tirés de la création de DBRX
En mai 2024, Databricks a publié DBRX, un LLM open source de pointe (à l'époque). Sa suite d'évaluation fournit un bon exemple de pyramide de tests, qui est décrite ci-dessous.
Analogie de test logiciel | Exemples de métriques tirées de la création de DBRX | |
Tests unitaires | Mosaic Evaluation Gauntlet | 39 benchmarks disponibles publiquement répartis sur six compétences clés : compréhension du langage, compréhension écrite, résolution de problèmes symboliques, connaissances du monde, bon sens et programmation |
Tests d'intégration | MT-Bench | Données de benchmark de conversation multi-tours et de suivi d'instructions |
IFEval | Données de benchmark de suivi d'instructions | |
Arena Hard | Générateur basé sur Chatbot Arena pour des données de benchmark de préférences humaines | |
Tests de bout en bout | Retours internes et clients et tests A/B | Tests itératifs avec des utilisateurs internes et externes pour collecter à la fois des métriques de tests A/B et des annotations humaines |
Red-teaming | Tests d'experts pour générer des sorties indésirables (offensantes, biaisées ou autrement non sécurisées) |
Pour plus d'informations sur les métriques d'évaluation, nous recommandons ce cours Generative AI Engineering. Pour les outils, nous recommandons MLflow, qui prend en charge les métriques automatisées (LLM-en tant que juge), les jeux de données d'évaluation et une application d'évaluation humaine. L'évaluation d'agents utilise les API MLflow open source pour l'évaluation des LLM. Pour une évaluation plus approfondie pour le pré-entraînement, nous pouvons travailler avec vous pour développer votre plan d'évaluation personnalisé.
Réglage fin supervisé
La première technique de personnalisation de modèle utilisée par la plupart des praticiens est le réglage fin supervisé (SFT), dans lequel un modèle est entraîné sur des données étiquetées pour l'optimiser pour une tâche ou un comportement spécifique.
Les cas d'utilisation courants incluent :
- Reconnaissance d'entités nommées : Réglage fin d'un modèle pour reconnaître des entités spécifiques au domaine
- Complétion de chat et réponse aux questions : Réglage fin d'un modèle pour répondre dans un ton spécifique
- Formatage de sortie : Réglage fin d'un modèle pour répondre avec des sorties spécifiques et structurées
- Suivi d'instructions : Après le pré-entraînement d'un modèle général, il est courant d'utiliser le réglage fin d'instructions pour apprendre au modèle à répondre aux instructions et aux requêtes, plutôt que de simplement générer du texte de complétion
Terminologie : « Réglage fin » est souvent utilisé pour signifier « réglage fin supervisé », mais techniquement, « réglage fin » est toute adaptation d'un modèle existant. Le pré-entraînement continu et l'apprentissage par renforcement à partir des retours humains (RLHF) sont également des types de réglage fin.
Le réglage fin est de loin le type de personnalisation de modèle le plus rapide et le moins cher. Par exemple, pour le modèle MPT-7B publié en mai 2023, le réglage fin d'instructions a coûté 46 $ pour traiter 9,6 millions de jetons, tandis que le pré-entraînement a coûté 250 800 $ pour traiter 1 billion de jetons.
Données
Lors de la préparation de vos données, le contenu et le formatage sont essentiels. Une grande partie du réglage fin consiste à apprendre au modèle quels types d'entrées attendre et quels types de sorties vous attendez. À quoi ressembleront les requêtes de vos utilisateurs, en termes de format, de ton, de couverture thématique ou d'autres aspects ? Vos données d'entraînement doivent représenter ces attentes.
La taille des données est un sujet de questionnement fréquent et dépend finalement du cas d'utilisation. Dans certains cas, nous avons obtenu de bons résultats en réglant finement sur de minuscules ensembles de données de centaines ou de milliers d'exemples, mais certaines applications exigent des dizaines de milliers ou des centaines de milliers d'exemples. Commencez petit pour valider votre plan, puis augmentez itérativement, en développant votre jeu de données d'entraînement si nécessaire.
Les données synthétiques peuvent être utiles pour le SFT, le plus souvent pour élargir un ensemble de données « réelles » trop petit. Un LLM peut être invité à générer des données SFT synthétiques similaires à des exemples de vos données réelles.
Consultez également la documentation sur la préparation des données pour Databricks Model Training.
Modèles
Plus tôt dans ce guide, nous avons recommandé d'utiliser par défaut les modèles pris en charge par Databricks Model Training et de tester les modèles pour leur potentiel pour votre cas d'utilisation. Un bon exemple de cela est venu de MPT. Bien que MPT n'ait pas été entraîné en pensant au japonais, un rapide test de réglage fin avec 100 exemples de paires prompt-réponse en japonais a donné un modèle étonnamment efficace pour un client. Ce test rapide a validé l'approche et a ouvert la voie à un réglage fin à plus grande échelle.
Lors du choix de la taille d'un modèle, envisagez de commencer par un modèle surdimensionné. Lors du réglage avec un petit jeu de données, un modèle plus grand est plus susceptible de produire de bons résultats qu'un modèle plus petit. Commencer avec un grand modèle peut vous informer du potentiel de vos données et de votre cas d'utilisation, et le SFT est relativement peu coûteux. Après avoir constaté le potentiel, vous pouvez tester avec des modèles plus petits et plus de données.
Vous pouvez exécuter le SFT sur des variantes de base ou des variantes instruct/chat des modèles. Par défaut, nous vous recommandons d'utiliser une variante instruct/chat, surtout si vous avez un petit jeu de données. Si vous avez effectué un pré-entraînement continu pour créer un modèle de base personnalisé, vous pouvez alors exécuter le SFT sur votre modèle de base personnalisé.
Databricks Model Training
Databricks Model Training fournit des interfaces simples (UI et API) pour les tâches de réglage fin supervisé. Au-delà des conseils sur les données et les modèles déj�à présentés dans ce guide, considérez :
- Tâche : Les tâches SFT peuvent être spécifiées de différentes manières, en fonction du format de requête attendu. Notez que nous recommandons par défaut le formatage de complétion de chat, même pour les tâches de suivi d'instructions, afin de respecter les normes courantes.
- Configuration: Au fur et à mesure de vos itérations, le premier hyperparamètre à optimiser est le taux d'apprentissage. Essayez une grille de taux, puis zoomez sur une grille de taux d'apprentissage plus fins centrés autour des meilleurs taux initiaux, similaire à l'ajustement des taux d'apprentissage dans les algorithmes d'apprentissage automatique (ML) traditionnels. Envisagez également d'ajuster la durée de l'entraînement (époques ou jetons) en fonction des tracés de la progression de l'apprentissage. Certaines tâches de fine-tuning nécessitent peu d'époques, et d'autres bénéficient de 50 époques ou plus.
- Évaluation: Spécifiez un jeu de données d'évaluation pour permettre à Databricks Model Training de calculer des évaluations initiales (« tests unitaires »). Même un petit jeu de données de 50 paires requête-réponse peut vous donner un signal, bien que des jeux de données plus grands et plus variés soient meilleurs. Utilisez Databricks MLflow pour des évaluations plus approfondies, d'autant plus que la perte d'évaluation (ou la précision) au moment de l'entraînement peut ne pas bien correspondre aux évaluations des utilisateurs finaux.
Plus d'informations sur le fine-tuning supervisé
Nous recommandons Databricks Model Training pour un flux de travail simple et efficace par défaut. Cependant, si vous avez besoin d'utiliser une architecture de modèle non prise en charge ou si vous avez besoin de méthodes de tuning plus personnalisées, vous pouvez exécuter du code entièrement personnalisé sur des clusters Databricks accélérés par GPU (calcul général) et Databricks Model Training.
Ce guide n'aborde pas le fine-tuning efficace en termes de paramètres (PEFT), une famille de techniques telles que l'adaptation de rang faible (LoRA) pour rendre le fine-tuning et l'inférence plus efficaces. Consultez ce blog, ce blog ou Hugging Face PEFT pour des descriptions et des exemples de ces techniques.
Pré-entraînement continu
Le fine-tuning supervisé (SFT) n'est pas conçu pour apprendre à un modèle à comprendre un nouveau domaine. Pour personnaliser un modèle afin qu'il comprenne une nouvelle langue, un secteur de niche ou un autre domaine spécifique, les praticiens peuvent se tourner vers le pré-entraînement continu (CPT). Le CPT est similaire au pré-entraînement, sauf que vous prenez un modèle pré-entraîné existant, puis vous continuez le processus de pré-entraînement en utilisant de nouvelles données. Après le CPT pour s'adapter à un nouveau domaine, le modèle est généralement adapté à des tâches spécifiques via le fine-tuning supervisé.
Les cas d'utilisation courants incluent :
- Langues : Les modèles généraux ont souvent vu de nombreuses langues naturelles dans leurs données d'entraînement, mais ils peuvent être faibles dans toutes les langues sauf les principales. Le CPT peut améliorer la compréhension d'un modèle d'une langue spécifique.
- Programmation : Les modèles généraux ont souvent vu au moins quelques langages de programmation dans leurs données d'entraînement, mais les modèles peuvent ne pas être principalement conçus pour le codage ou peuvent ne pas bien comprendre un langage de programmation spécifique. Le CPT peut apprendre à un modèle à coder dans un langage de programmation spécifique.
- Domaines industriels : Les modèles généraux peuvent ne pas avoir de connaissances approfondies sur des sujets spécifiques, tels que la biologie moléculaire, le droit de l'environnement ou la réglementation financière. Le CPT peut améliorer les connaissances et la compréhension d'un modèle d'un domaine spécifique.
Pour améliorer le modèle de suivi d'instructions de mon bot de questions-réponses RAG, dois-je utiliser le fine-tuning supervisé (SFT) ou le pré-entraînement continu (CPT) ?
Les deux techniques peuvent être applicables, mais cela dépend des données d'entraînement dont vous disposez et de ce que vous souhaitez améliorer chez le modèle. Si vous souhaitez apprendre au modèle à répondre d'une certaine manière, utilisez le SFT — si vous avez des données requête-réponse pour l'entraînement. Si le modèle ne comprend pas votre domaine ou votre langue, utilisez le CPT — si vous avez une quantité importante de données textuelles pour l'entraînement. Gardez à l'esprit qu'après le CPT, vous devrez probablement exécuter le SFT pour réapprendre au modèle à répondre aux requêtes.
Puis-je utiliser le SFT ou le CPT pour enseigner de nouvelles connaissances et de nouveaux faits à mon modèle ?
Oui, les deux techniques peuvent transmettre certaines connaissances, mais le CPT est plus applicable. Quoi qu'il en soit, vous devrez peut-être utiliser RAG pour rendre votre système d'IA robuste en basant les réponses sur les données sources.
Données
Lorsque vous réfléchissez aux données dont vous avez besoin pour le CPT, rappelez-vous le principe 2 (« piloté par les données »). Qu'est-ce que vous voulez améliorer chez le modèle d'origine ? Vos données doivent représenter le domaine, la langue, les connaissances, etc. que vous souhaitez inculquer au modèle. Pour un cas d'utilisation spécifique, cela se traduira probablement par l'exécution du CPT sur vos données d'entreprise propriétaires pertinentes pour le cas d'utilisation — vos bases de connaissances internes, des articles de recherche pertinents des 20 dernières années, etc. Pour un modèle plus général, nos conseils pour les données deviennent plus similaires à ceux du pré-entraînement, où vous pouvez sélectionner plusieurs jeux de données pour représenter les différentes compétences importantes pour votre cas d'utilisation.
Astuce : Oublier vs. apprendre. Lorsque vous testez le CPT, gardez à l'esprit qu'il existe des compromis entre l'oubli des connaissances antérieures et l'acquisition de nouvelles connaissances. Votre objectif est de modifier le comportement du modèle pour qu'il imite vos données d'entraînement CPT, mais cela peut signifier oublier des aspects des données de pré-entraînement d'origine. Par conséquent, assurez-vous que vos données d'entraînement CPT et votre suite d'évaluation couvrent les domaines qui vous intéressent.
Pour le format des données, vos données seront du texte « brut ». C'est-à-dire que vous exécuterez le CPT en faisant de la prédiction du prochain jeton, tout comme lors du pré-entraînement.
Pour la taille des données, le CPT peut aller de l'ajustement d'un modèle à l'aide de moins de jetons à la modification significative d'un modèle à l'aide de nombreux jetons. « Moins » et « beaucoup » dépendront de la taille du modèle, mais une estimation raisonnable est de plusieurs milliards de jetons pour les LLM modernes de taille moyenne. Une règle générale est que le CPT nécessitera au moins ~1 % de la taille de l'ensemble d'entraînement d'origine.
Ai-je besoin à la fois de données brutes pour le CPT et de données de prompt-réponse pour le SFT ?
Si vous exécutez le CPT suivi du SFT, alors oui. Cependant, si vous avez des données pour le CPT mais peu de données pour le SFT, vous pouvez augmenter votre petit jeu de données SFT avec des données requête-réponse à l'aide d'autres jeux de données SFT ou de données synthétiques.
Les données synthétiques peuvent être utiles pour le CPT, en particulier pour la distillation, où un modèle grand et puissant est utilisé pour générer des données afin d'entraîner un modèle plus petit. La distillation peut aider à créer des modèles plus petits, plus rapides et moins chers, et peut compléter vos données non synthétiques spécifiques à vos cas d'utilisation.
Consultez également la documentation sur la préparation des données pour Databricks Model Training.
Modèles
Tout comme pour le SFT, nous recommandons d'utiliser par défaut les modèles pris en charge par Databricks Model Training et de tester les modèles pour leur potentiel pour votre cas d'utilisation.
Nos recommandations concernant le tuning d'un modèle de base par rapport à une variante instruct/chat, et concernant l'exécution du SFT après le CPT, sont entrelacées. Le chemin le plus courant, et notre recommandation par défaut, est d'exécuter le CPT sur un modèle de base, suivi du SFT pour le fine-tuning d'instructions ou de chat. Cependant, il y a des nuances :
- Variante de base vs instruct/chat : Il est plus courant d'exécuter le CPT sur le modèle de base. L'exécution du CPT sur un grand jeu de données sur une variante instruct ou chat peut amener ce modèle à perdre une partie de sa capacité à suivre les instructions ou à converser.
- SFT après CPT : Si vous exécutez le CPT sur une grande quantité de données, vous le suivrez probablement avec le SFT. Cependant, si vous exécutez le CPT sur un modèle de suivi d'instructions ou de chat en utilisant une petite quantité de données, vous n'aurez peut-être pas besoin de SFT par la suite. Nous avons vu certains clients le faire, puis utiliser directement le modèle résultant dans leurs applications.
Databricks Model Training
Databricks Model Training offre des interfaces simples (UI et API) pour le CPT. Les conseils pour le SFT mentionnés précédemment dans ce guide s'appliquent également au CPT. De manière pratique, la fonctionnalité Model Training peut être utilisée pour exécuter à la fois le CPT et le SFT.
Votre pyramide de tests issue de la discussion précédente sur l'évaluation nécessitera des tests plus robustes et généraux, car le CPT peut modifier le modèle plus fondamentalement que le SFT. À mesure que vous augmentez l'échelle du CPT, votre pyramide de tests pourrait ressembler davantage à une suite de tests de pré-entraînement.
Plus d'informations sur le CPT
À mesure que vos charges de travail CPT deviennent plus personnalisées et plus importantes, vous pourriez également souhaiter explorer la pile de pré-entraînement discutée ci-dessous.
Le CPT est utile pour tester des données en vue du pré-entraînement. Si vos données CPT couvrent un nouveau domaine (comme un nouveau langage de programmation), alors démontrer un succès avec le CPT indique que les données peuvent être utiles dans le cadre d'un jeu de données de pré-entraînement.
Pré-entraînement
Supposons que votre application GenAI ait progressé grâce au pré-entraînement continu, et que vous pensiez que le pré-entraînement d'un modèle entièrement personnalisé est la prochaine étape nécessaire pour améliorer votre application. Cette section esquisse le processus et les meilleures pratiques à un niveau élevé, mais en pratique, vous devriez suivre le processus de pré-entraînement avec votre équipe Databricks.
Devriez-vous jamais passer directement au pré-entraînement ?
Non. Même si des contraintes réglementaires ou autres exigent que vous créiez un nouveau modèle que vous possédez entièrement, il est préférable de prototyper d'abord sur les échelons inférieurs de l'échelle de personnalisation. Cela vous permet de réduire les risques des exécutions de pré-entraînement plus coûteuses et complexes.
Quelles sont les étapes du pré-entraînement ?
La réalité est que le pré-entraînement est un processus itératif et adaptatif, mais les étapes générales communes du pré-entraînement incluent :
- Commencez par le fine-tuning et le pré-entraînement continu. Faites preuve de diligence raisonnable !
- Préparez les jeux de données. Cela se produit pendant l'étape 1, où le CPT vous aide à tester l'utilité de certains jeux de données.
- Pré-entraînez un modèle de base capable d'effectuer la complétion de texte. Cela implique de surveiller l'entraînement, d'ajuster l'exécution en cours de route et d'utiliser des techniques adaptatives comme l'apprentissage par curriculum pour ajuster le mélange de données.
- Exécutez le fine-tuning d'instructions ou de chat pour créer une variante d'instructions/chat.
- Utilisez éventuellement des techniques comme l'apprentissage par renforcement à partir des retours humains (RLHF) pour affiner davantage le modèle.
- À chaque étape ci-dessus, évaluez vos modèles en cours de route.
Ce bref résumé procédural met l'accent sur la diligence raisonnable et l'évaluation en raison du coût relativement élevé du pré-entraînement complet. Rappelez-vous l'exemple cité précédemment du modèle MPT-7B, pour lequel le pré-entraînement a coûté 5452 fois plus cher que le fine-tuning d'instructions.
Données
Votre choix et votre traitement des données joueront un rôle majeur dans le succès de vos exécutions de pré-entraînement.
Quelles données ?
Votre mélange de données doit être choisi avec soin pour représenter votre application cible.
- Tout comme les évaluations doivent être décomposées par les compétences que vous souhaitez que votre modèle possède, réfléchissez à ce que chaque jeu de données que vous apportez au pré-entraînement enseignera au modèle. Vous pouvez tester l'impact de ces jeux de données au préalable en utilisant le pré-entraînement continu.
- Peu de modèles performants publient des détails sur leurs mélanges de données. Certains modèles plus anciens ont des listes publiées (par exemple, MPT, LLaMA, OLMo). Consultez également cette discussion sur le mélange de données.
- Vous mélangerez probablement des jeux de données publics et propriétaires. Les jeux de données publics correctement validés peuvent répondre à certains de vos besoins d'entraînement, tels que l'enseignement des capacités linguistiques, des connaissances générales et de certaines compétences spécifiques. Les jeux de données propriétaires confèrent à vos modèles un avantage concurrentiel indisponible pour quiconque.
La quantité et la qualité des données sont importantes, mais à différents moments. Il est courant de commencer le pré-entraînement sur « toutes les données » avec des contrôles de qualité moins stricts. Initialement, plus de jetons se traduisent par un meilleur apprentissage des capacités linguistiques de base. Cependant, plus tard, pendant le pré-entraînement, il est courant de changer le mélange de données pour un ensemble plus petit et de meilleure qualité. « Haute qualité » n'a pas de définition académique, mais intuitivement, cela signifie qu'il est organisé à l'aide de techniques de bon sens. Voir ce qui suit pour plus d'informations sur la préparation des données.
Quelle quantité de données ?
- Votre taille de données doit être choisie en tenant compte de la taille et de l'architecture du modèle.
- La règle empirique « Chinchilla » est la plus célèbre : # jetons = 20 * # paramètres. Pour réduire les coûts d'inférence, nous vous recommandons d'entraîner un modèle plus petit avec plus de données pour obtenir une qualité de génération similaire, conformément aux résultats de ce document LLaMA.
- Les architectures de mélange d'experts (MoE) peuvent modifier ce calcul, nécessitant souvent moins de données pour une taille de modèle donnée. Pour les MoE, utilisez le nombre de paramètres actifs (pas le nombre total de paramètres) pour effectuer ce calcul.
- Gardez à l'esprit que certaines tâches sont plus difficiles que d'autres. Par exemple, les modèles à 7 milliards de paramètres nécessitent généralement au moins 2 billions de jetons de données d'entraînement pour aborder le benchmark de codage HumanEval.
Comment les données doivent-elles être préparées ?
- Téléchargement et analyse : Vous devez généralement acquérir les données vous-même. Peu de fournisseurs proposent des données à l'échelle d'Internet pré-téléchargées, et les exigences réglementaires peuvent varier selon le client.
- Nettoyage : Bien que le pré-entraînement puisse tirer parti de grandes quantités de données de faible qualité, il est utile d'améliorer la qualité des données. Par exemple, ce document RefinedWeb estime qu'environ 11 % de Common Crawl est utile. Le nettoyage des données pour le pré-entraînement est un sujet vaste et complexe avec beaucoup de recherches actives. Voir ce document pour un excellent aperçu des étapes courantes, notamment :
- Filtrage linguistique pour réduire le texte aux langues principales d'intérêt
- Filtrage heuristique pour supprimer le texte répétitif, les documents trop courts ou trop longs, le texte non naturel, etc.
- Filtrage de qualité pour identifier le texte susceptible d'avoir été écrit ou revu par des humains
- Filtrage par domaine pour identifier le texte concernant les domaines d'intérêt
- Déduplication du contenu au sein ou entre les jeux de données
- Filtrage du contenu toxique et explicite basé sur l'origine ou le texte
- Notez que toutes ces techniques ont des mises en garde. Pour chacune, la rigueur du filtrage doit être ajustée pour faire un compromis entre précision et rappel. Pour certaines, le filtre peut être malavisé : la duplication peut indiquer que le texte est plus valide ou important, et un modèle qui n'a jamais vu de contenu toxique peut ne pas reconnaître la toxicité et répéter ainsi facilement les entrées utilisateur toxiques.
- Comme mentionné, le pré-entraînement précoce peut utiliser plus de données avec des contrôles de qualité moins stricts, tandis que le pré-entraînement ultérieur peut se concentrer sur des sous-ensembles de données plus soigneusement nettoyés.
- Pré-calcul : La prétokénisation et la concaténation des données pour optimiser leur format pour le pré-entraînement peuvent améliorer l'efficacité.
Le traitement des données est la spécialité d'origine de Databricks. Utilisez les éléments suivants :
- Workflows pour définir les tâches et l'orchestration, avec Apache Spark™ et les optimisations Delta pour le traitement à grande échelle
- Delta Lake comme format de stockage de vos données
- Unity Catalog pour la gestion des données
- Carnets, Intégration IDE et Databricks SQL pour le développement et l'exploration des données
- Surveillance du Lakehouse pour la surveillance à long terme des pipelines et des sources de données
Modèles
Bien que les chercheurs vantent naturellement les nouvelles architectures de modèles comme de grandes avancées, il y a une raison pour laquelle l'architecture Transformer domine toujours, malgré sa date de 2017 — elle fonctionne très bien. De même, nous recommandons généralement de s'en tenir à des choix architecturaux éprouvés, tels que :
- Utilisez des mécanismes d'attention standard tels que l'attention quadratique ou FlashAttention-2, plutôt que des méthodes moins testées issues de la recherche
- Envisagez des architectures de mélange d'experts (MoE) pour un entraînement et une inférence plus efficaces, ainsi que pour une arithmétique de plus faible précision
- Entraînez votre transformeur en utilisant la prédiction du prochain jeton
Databricks prend en charge le pré-entraînement sur des architectures arbitraires, mais nous fournissons des configurations de pré-entraînement plus simples pour les architectures recommandées principales via Databricks Model Training, qui fournit des versions gérées et optimisées d'outils tels que Mosaic LLM Foundry et Mosaic Diffusion. Ces outils peuvent simplifier les choix en fournissant des valeurs par défaut standard et bien testées. Par exemple, en juillet 2024, LLM Foundry recommande FlashAttention-2 comme mécanisme d'attention standard, et il prend en charge les architectures MoE telles que DBRX. Pour votre application particulière, nous pouvons vous conseiller sur les spécificités de l'architecture.
En ce qui concerne la taille du modèle, n'oubliez pas de commencer petit (principe 1). L'entraînement d'un modèle de 7 milliards de paramètres coûte environ 10 fois moins cher qu'un modèle de 70 milliards, et cela peut éclairer vos choix de modélisation pour lorsque vous augmenterez l'échelle. De plus, tenez compte des contraintes de latence et de coût de votre cas d'utilisation comme plafonds pour la taille potentielle du modèle.
Pile d'entraînement et infrastructure
Avec vos données et vos choix de modélisation préparés, vous êtes peut-être maintenant prêt à pré-entraîner. Cela peut être l'étape la plus coûteuse que vous entreprendrez avec GenAI, d'où la préparation minutieuse des étapes précédentes. Pendant cette étape, il est essentiel d'utiliser des outils robustes et des conseillers experts pour que le pré-entraînement se déroule sans problème.
Les exécutions de pré-entraînement comportent de nombreux défis. La plateforme Databricks gère automatiquement bon nombre de ces défis pour l'utilisateur.
Défi | Databricks |
Chargement des données : Vous devrez peut-être charger des billions de jetons. | Databricks offre des temps de démarrage et de récupération rapides. |
Mise à l'échelle et optimisation : Vous devrez peut-être passer de dizaines à des milliers de GPU. Il existe de nombreuses techniques pour optimiser les performances d'entraînement. | Databricks offre une mise à l'échelle transparente via le parallélisme de données et FSDP, ainsi qu'une bibliothèque d'optimisations composables. Il atteint une utilisation de pointe des FLOPS du modèle (MFU). |
Récupération après échec : Vous pouvez vous attendre à environ 1 défaillance d'infrastructure tous les 1000 jours-GPU sur la plupart des clouds. Les tâches de pré-entraînement peuvent connaître des pics de perte ou une divergence. | Databricks détecte automatiquement les échecs et effectue des redémarrages rapides. La pile d'entraînement réduit également les pics de perte. |
Déterminisme : Le chargement et l'entraînement distribués des données rendent le déterminisme difficile, mais il est précieux pour la récupération et la reproductibilité. | Les algorithmes de chargement et d'entraînement de données de Databricks rendent le pré-entraînement beaucoup plus reproductible. |
La pile Databricks Training s'étend du matériel à la gestion des charges de travail. Le tableau suivant répertorie les éléments clés à apprendre en premier.
Étape | Composant Databricks | Détails |
Chargement des données | Fournit un flux rapide et reproductible de données d'entraînement à partir du stockage cloud, y compris des démarrages et redémarrages rapides. | |
Entraînement | Fournit des meilleures pratiques et techniques composables pour un entraînement distribué et efficace. | |
Configuration du flux de travail | Permet une définition simple des flux de travail, y compris la préparation des données, l'entraînement, le réglage fin et l'évaluation. Databricks peut fournir des configurations standard pour vous aider à démarrer le pré-entraînement d'architectures courantes. | |
Suivi des expériences | Suit l'évaluation et d'autres métriques pendant les exécutions de pré-entraînement. Databricks prend également en charge Weights & Biases. |
Votre cas d'utilisation peut suivre les chemins bien tracés définis comme « recettes » de configuration par LLM Foundry, auquel cas votre flux de travail peut être très axé sur la configuration. Ou, si vous avez besoin d'architectures ou de code plus personnalisés, vous pouvez vous concentrer sur les parties de niveau inférieur de la pile telles que MCLI, en travaillant plus directement avec l'infrastructure Databricks.
Calcul et coûts
Avant de pré-entraîner un modèle, il est important d'estimer les coûts. Le coût du pré-entraînement est souvent simple à estimer car il se résume à l'estimation des heures de GPU, en fonction de la taille des données et du modèle. Votre équipe Databricks peut fournir des estimations précises, mais pour tout fournisseur, assurez-vous de comprendre deux calculs clés :
FLOPS = 6 x paramètres x jetons
Cette règle empirique vous indique que le calcul (et le coût) augmentera linéairement avec la taille du modèle et la taille des données. Notez que « paramètres » se traduira par « paramètres actifs » pour les architectures éparses comme les MoE.
Utilisation des FLOPS du modèle (MFU) = utilisation moyenne des GPU en pratique
La MFU n'est jamais de 100 % en pratique, et elle est souvent bien inférieure. Différents modèles et types de données peuvent atteindre différentes MFU. La pile Databricks est optimisée pour atteindre une MFU performante.
Qu'en est-il des époques ?
L'entraînement pendant N époques coûtera N fois plus cher qu'une époque. Cependant, pour le pré-entraînement, il est courant d'utiliser une seule époque, bien que vous puissiez répéter certaines données clés de haute qualité dans votre entraînement. Ceci est différent des nombreuses époques utilisées dans l'apprentissage profond plus traditionnel. Voir cet article pour plus d'informations.
En plus des coûts de calcul de pré-entraînement, estimez également :
- Coûts des données, y compris l'achat, la curation et l'étiquetage
- Coûts d'inférence
Pendant le pré-entraînement
Une fois que vous lancez le pré-entraînement, il peut très bien « fonctionner tout seul » sur Databricks, mais il est toujours important de surveiller l'entraînement et de savoir comment déboguer ou améliorer l'apprentissage. Votre équipe Databricks peut vous aider à surveiller et à déboguer les problèmes.
La surveillance couvre deux domaines principaux :
- Infrastructure : Databricks Training gère la plupart des problèmes d'infrastructure pour vous. Par exemple, il enregistrera et reprendra automatiquement l'entraînement en cas de défaillance des GPU, du réseau ou d'autres infrastructures. Il est utile de surveiller l'utilisation, surtout lors de l'utilisation de configurations non standard.
- Progrès de l'apprentissage : Les métriques telles que la perte sur les données d'entraînement et d'évaluation doivent être surveillées pour détecter les problèmes de données et de configuration. Les symptômes les plus courants à surveiller sont les pics de perte et la divergence. Dans Databricks Training, nous recommandons l'enregistrement dans MLflow Experiments par défaut pour le suivi en direct et l'examen a posteriori.
Débogage nécessite le plus souvent des ajustements sur :
- Configurations : Si vos configurations sont mal définies, ces problèmes apparaissent souvent tôt pendant l'entraînement. Le taux d'apprentissage est la configuration la plus courante nécessitant des ajustements.
- Données : Par exemple, un problème d'entraînement courant est de voir des pics de perte dus à des jeux de données mal mélangés. Databricks Training simplifie le mélange via la bibliothèque Mosaic Streaming, mais le mélange a un coût, donc Streaming prend en charge différents paramètres de mélange pour prendre en charge les compromis qualité-coût. Si vous observez des pics de perte, il est possible que la définition de paramètres de mélange plus robustes dans Streaming permette d'éviter ces pics. Par exemple, si vos données proviennent de différents buckets (domaines, langues, etc.) et ne sont pas correctement mélangées, vous êtes plus susceptible de voir des pics de perte.
Apprentissage par curriculum : Le pré-entraînement ne s'exécute souvent pas sur un seul jeu de données homogène. Le modèle final peut souvent être amélioré en variant le mélange de données pendant le processus d'entraînement, et la technique la plus courante pour cela est l' apprentissage par curriculum, dans lequel les jeux de données de meilleure qualité et plus ciblés sont mis en avant dans le mélange de données plus tard pendant l'entraînement. Les mélanges de données peuvent être spécifiés à l'avance, ou le mélange de données peut être ajusté manuellement pour renforcer le modèle dans certains domaines.
Après le pré-entraînement
Après le pré-entraînement, il peut y avoir des étapes supplémentaires pour préparer un modèle aux applications finales, telles que :
- Apprentissage par curriculum supplémentaire ou pré-entraînement continu pour ajuster le modèle
- Ajustement fin supervisé, par exemple pour le suivi d'instructions ou le chat
- Apprentissage par renforcement à partir des retours humains (RLHF), une technique avancée pour ajuster un modèle afin qu'il corresponde aux préférences humaines. Cela peut être très puissant mais complexe à maîtriser, et ce n'est pas nécessaire pour toutes les applications. Pour de nombreuses applications, l'ajustement fin supervisé ou les garde-fous peuvent suffire.
- Itération sur les éléments ci-dessus, en fonction des évaluations des utilisateurs finaux du modèle ou de l'application
L'avenir
Le rythme du développement de la GenAI ne ralentit pas. Les GPU et autres matériels spécialisés deviendront plus rapides et moins chers. Les piles logicielles s'amélioreront. De nouvelles architectures de modèles et techniques d'entraînement passeront de la recherche à la pratique. Que pouvez-vous faire pour vous préparer ?
Avec Databricks, vous pourrez tirer parti de nombreux développements par défaut. Databricks Model Training, Model Serving et d'autres fonctionnalités continueront d'ajouter la prise en charge des derniers modèles de pointe. De nouvelles techniques d'entraînement et d'inférence seront intégrées en coulisses. Pour les charges de travail plus importantes et plus complexes, Databricks prendra en charge la personnalisation complète, et les charges de travail les plus avant-gardistes seront réalisées en collaboration avec l'équipe de recherche Mosaic.
Au sein de votre organisation, concentrez-vous sur le soutien de charges de travail flexibles et personnalisables, maintenant et à l'avenir :
- Développez votre infrastructure IA. Mettez en place la gouvernance des API de modèles via une passerelle IA. Mettez en place des processus de sécurité à l'aide d'un cadre de sécurité IA. Standardisez et unifiez les données et la gouvernance IA sous Unity Catalog. Développez la boucle interne à l'aide de Agent Framework et la boucle externe à l'aide de Model Training. Développez votre pratique MLOps, y compris Model Serving et Monitoring robustes.
- Développez votre expertise IA. Travaillez avec votre équipe Databricks pour développer un centre d'excellence (CoE) pour l'IA. Tirez parti de Databricks Training pour guider les équipes le long de parcours d'apprentissage adaptés à leurs rôles.
- Développez votre propriété intellectuelle. Cette PI comprendra non seulement des modèles personnalisés mais, plus important encore, vos données d'entreprise. Collectez des données des applications et des utilisateurs actuels, suivez la provenance et soyez attentif à la réglementation et aux licences. Ces données alimenteront toute votre personnalisation GenAI — tant le RAG dans la boucle interne que le réglage et le pré-entraînement dans la boucle externe.
Ressources
Cours
- Suivez le tutoriel Get Started With Generative AI en auto-apprentissage et obtenez un certificat Databricks
- Fondamentaux de l'IA générative (Databricks Academy)
- Ingénierie de l'IA générative avec Databricks (Formation animée par un instructeur et Databricks Academy)
- Consultez Databricks Training et Databricks Academy pour de nouveaux cours
Lecture
- Le grand livre de l'IA générative pour une collection d'articles de blog approfondissant différents aspects du développement de modèles et de systèmes d'IA générative
- Un guide compact sur la génération augmentée par récupération (RAG) pour une plongée en profondeur dans la création d'applications d'IA générative utilisant des LLM augmentés par des données d'entreprise
- Articles de blog de Mosaic Research
- Le grand livre de MLOps : Deuxième édition pour une plongée en profondeur dans MLOps avec Databricks, y compris LLMOps
- Page Databricks pour une présentation du produit, des détails sur les fonctionnalités et des liens vers de nombreuses ressources
- Documentation Databricks pour GenAI pour AWS, Azure et GCP
Sessions Data + AI Summit 2024
- Personnalisation de vos modèles : RAG, ajustement fin et pré-entraînement
- Dans les tranchées avec DBRX : Construction d'un modèle open-source à la pointe de la technologie
À propos de Databricks
Databricks est l'entreprise de données et d'IA. Plus de 10 000 organisations dans le monde — y compris Block, Comcast, Condé Nast, Rivian, Shell et 70 % des entreprises du Fortune 500 — s'appuient sur la plateforme Databricks Data Intelligence pour maîtriser leurs données et les exploiter grâce à l'IA. Databricks a son siège à San Francisco, avec des bureaux dans le monde entier, et a été fondée par les créateurs originaux de Lakehouse, Apache SparkTM, Delta Lake et MLflow. Pour en savoir plus, suivez Databricks sur LinkedIn, X et Facebook.
Contactez-nous pour une démo personnalisée :
databricks.com/contact
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.