Spark sur Databricks
La meilleure plateforme pour exécuter vos charges Spark, par les créateurs d'Apache Spark™
Par sa simplicité, son excellence opérationnelle et son rapport performance/prix inégalé, la plateforme lakehouse Databricks est le meilleur environnement pour vos charges Apache Spark™.
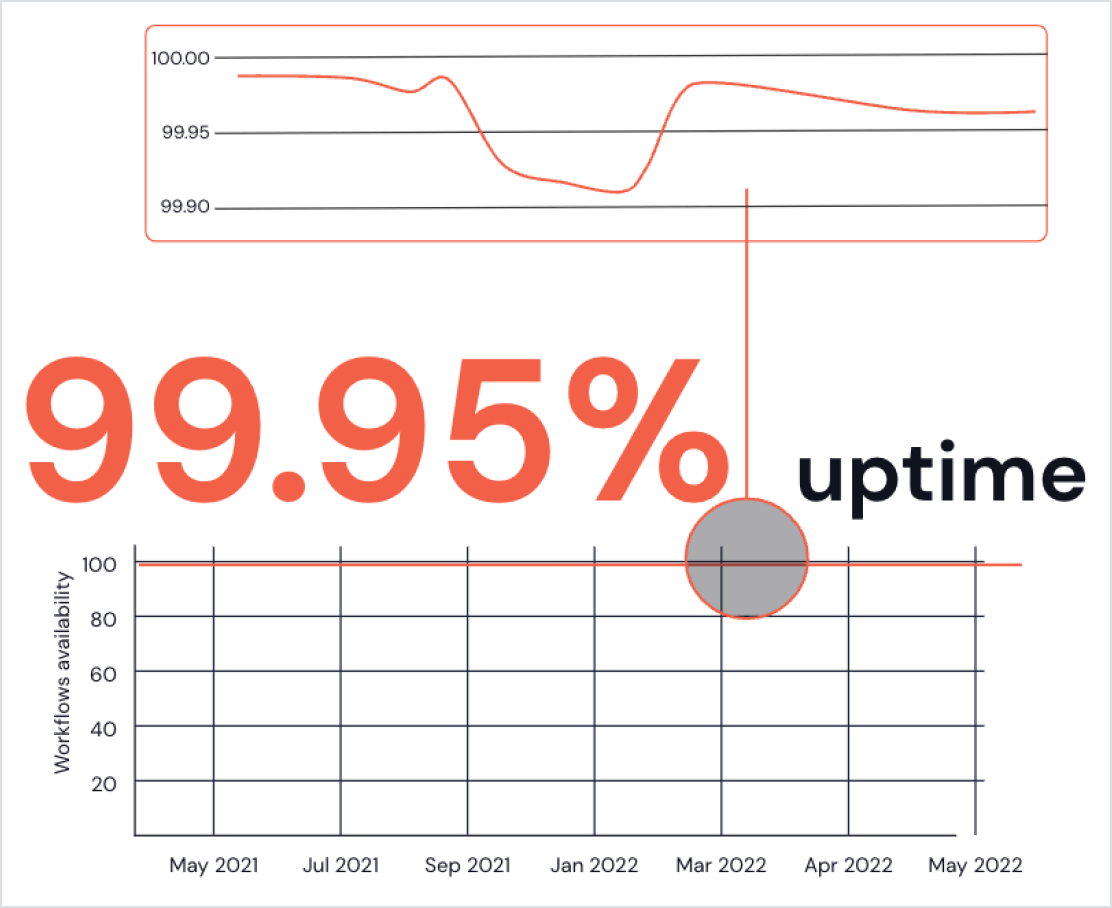
Une excellence opérationnelle de premier ordre
Chaque jour, nous aidons des milliers de clients à lancer des millions de VM pour exécuter leurs applications Spark. Nous prenons en charge les derniers outils de développement et les directives les plus récentes afin que vous puissiez développer et déployer vos applications Spark en toute confiance et sans obstacle.
- Exécutez vos applications Spark individuellement ou déployez-les sur Databricks Workflows en toute simplicité
- Exécutez des notebooks Spark avec d'autres types de tâches pour créer des pipelines de données déclaratifs sur des ressources de calcul entièrement managées
- La supervision des workflows vous permet de suivre l'évolution des performances de vos applications Spark et de diagnostiquer les problèmes en quelques clics
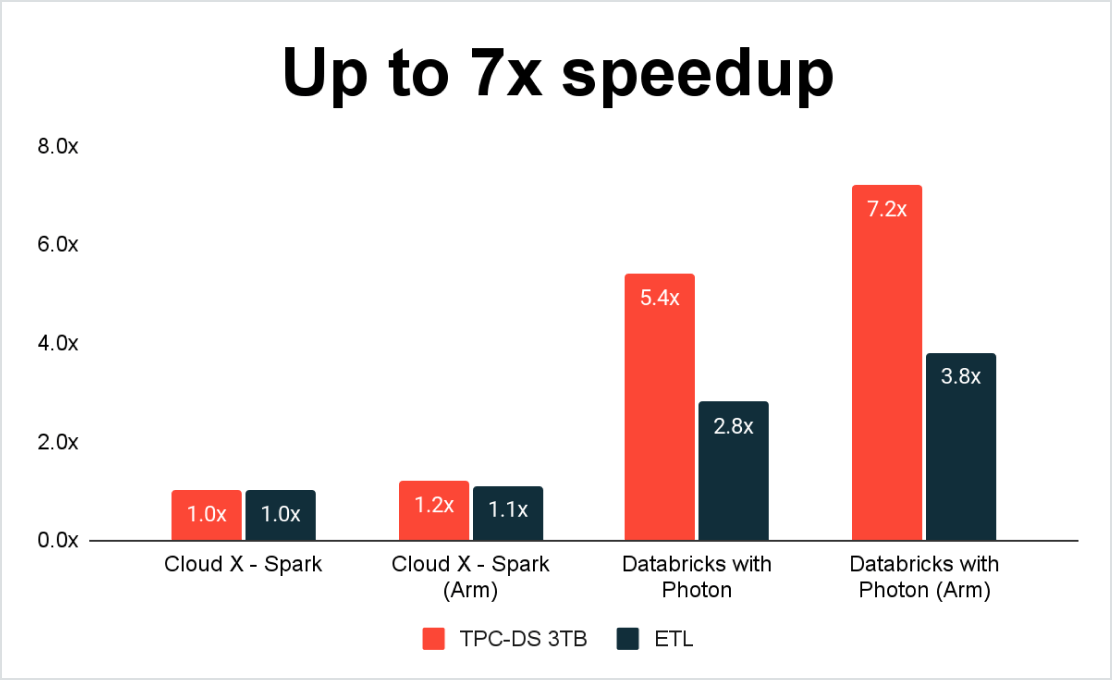
Le meilleur rapport performance-prix pour les charges Spark
En choisissant la plateforme lakehouse Databricks pour exécuter vos charges Spark, vous profitez des avantages de Photon, un moteur d'exécution vectorisée rapide en C++ pour les charges Spark et SQL, qui fonctionne à l'arrière-plan des interfaces de programmation existantes de Spark. Photon délivre des performances de requête inégalées à faible coût et sait tirer parti des architectures matérielles les plus modernes, dont Graviton d'AWS.
En plus de vous offrir des performances exceptionnelles, Spark sur Databricks affiche un TCO global plus bas grâce à des fonctionnalités comme l'autoscaling dynamique, qui garantit que vous ne payez que ce que vous utilisez. Databricks propose également des instances de GPU et spot.

Analytique de bout en bout et gouvernance unifiée sur la plateforme lakehouse Databricks
Alors que d'autres plateformes vous contraignent à intégrer un éventail d'outils et à gérer différents modèles de gouvernance, Databricks unifie le data warehouse, le data lake et le streaming de données au sein d'une plateforme lakehouse simple traitant tous vos cas d'usage de data engineering, d'analytique et d'IA dans leur intégralité. Elle repose sur un socle de données ouvert et fiable qui traite efficacement tous les types de données, unifie le batch et le streaming, et applique un modèle commun de sécurité et de gouvernance à toutes vos plateformes de données et clouds.

Innover en continu
Le prix SIGMOD Systems 2022 a récompensé Spark en tant que système de traitement unifié des données à la fois innovant, open source et largement répandu, capable de traiter aussi bien les charges relationnelles, de streaming et de machine learning.
Et l'innovation se poursuit. Nous avons récemment introduit Spark Connect et le projet Lightspeed.
Spark Connect découple le client et le serveur pour gagner en stabilité et permettre d'exécuter des applications Spark dans n'importe quel contexte.
Le projet Lightspeed, qui représente la nouvelle génération du streaming structuré Spark, poursuit sur la voie d'une latence faible et prévisible, tout en enrichissant les fonctionnalités de traitement des événements.
Ready to get started?