LakeFlow
Importez, transformez et orchestrez vos données avec une solution de data engineering unifiée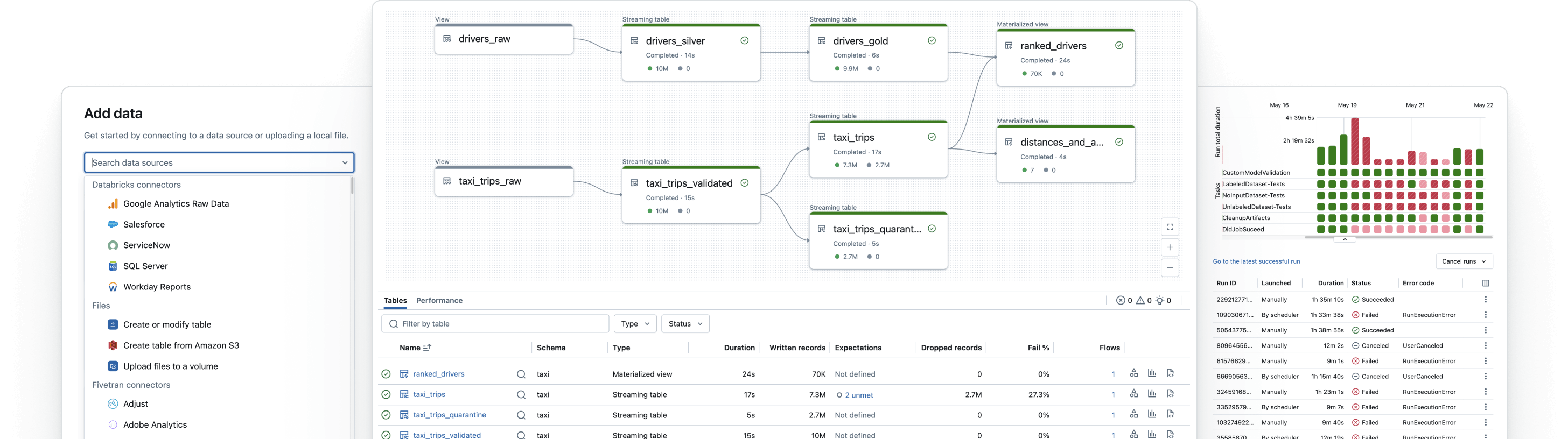
LES MEILLEURES ENTREPRISES UTILISENT LAKEFLOW
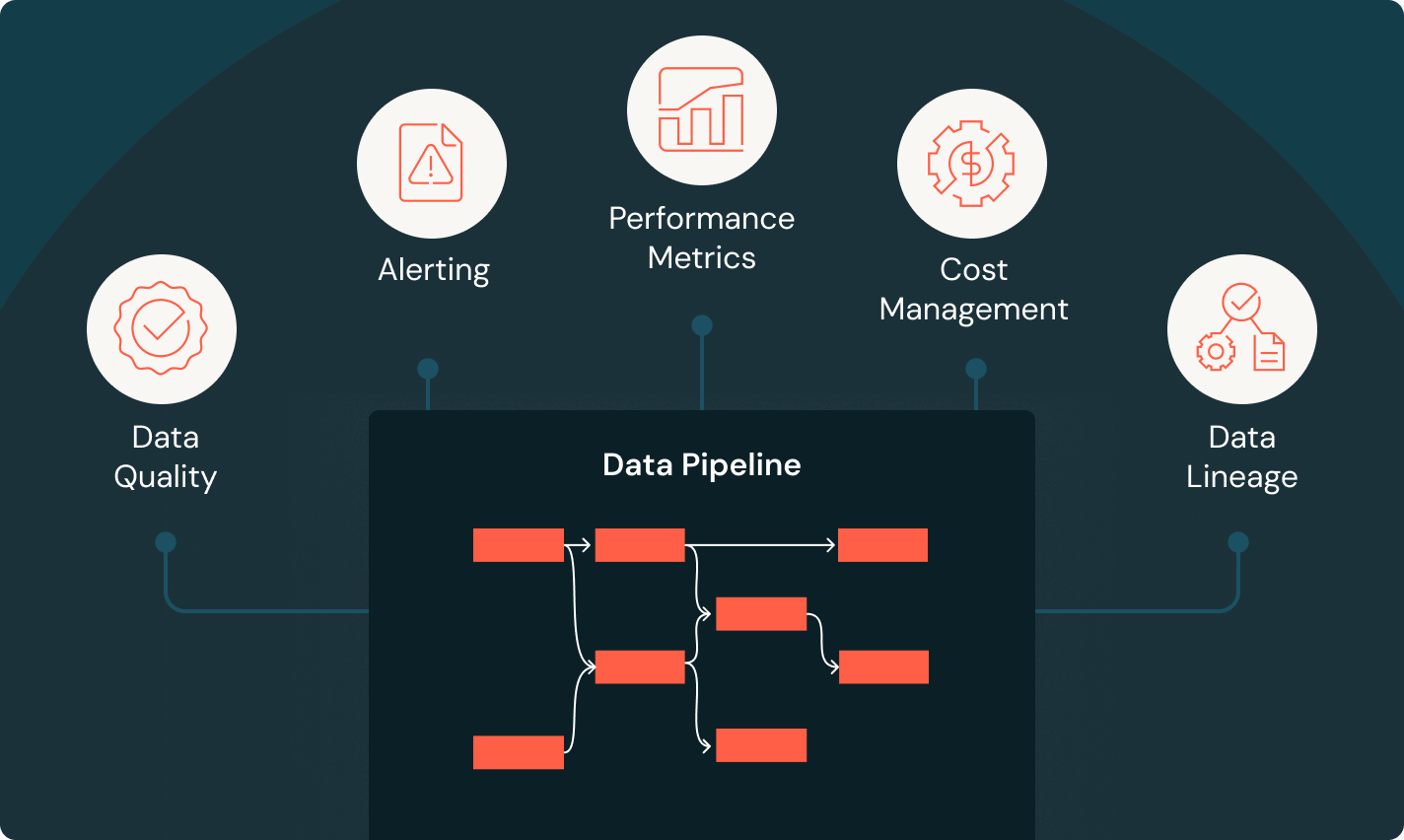
Une solution de bout en bout pour des données de haute qualité.
Des outils qui aident toutes les équipes à développer des pipelines de données fiables pour l'analytique et l'IA.Pile d'outils unifiée
Réduisez les coûts et les efforts d'intégration en confiant la collecte et le nettoyage des données à une seule solution. Gardez le contrôle grâce aux fonctions intégrées et unifiées de gouvernance et de traçabilité.
Data engineering agentique
Utilisez le langage naturel pour aller plus vite : les agents comprennent vos données et savent créer, maintenir et dépanner des pipelines de données.
Traitement efficace des données
En coulisses, un puissant moteur optimise automatiquement l'utilisation des ressources pour améliorer le rapport performance/prix des applications par batch et les cas d'utilisation en temps réel.
85 % d'accélération du développement
50 % de réduction des coûts
99 % de réduction de la latence des pipelines
Un outillage unifié pour toutes les charges de data engineering

Genie Code
Créez et gérez des pipelines de données avec une IA agentique qui comprend vos données.
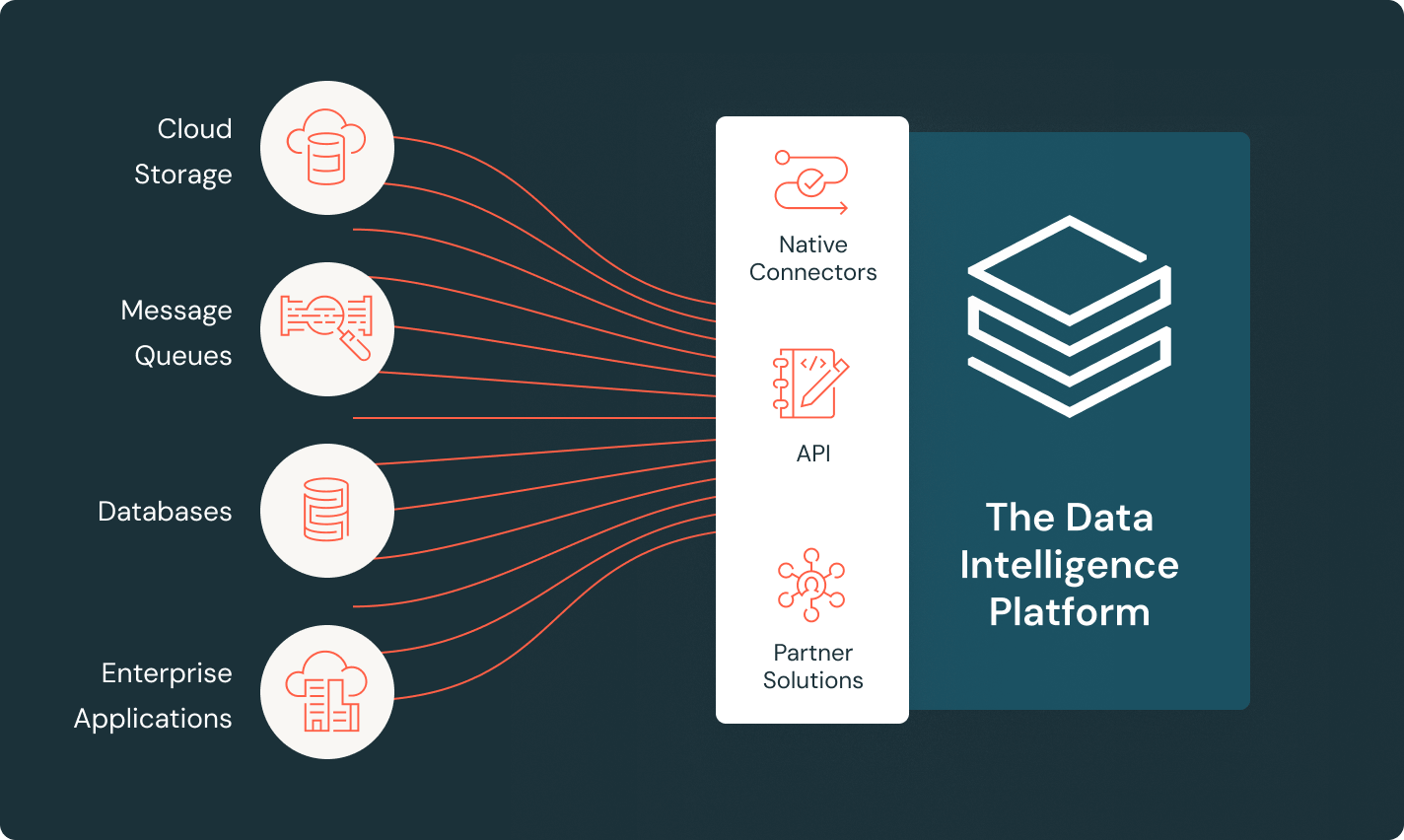
LakeFlow Connect
Avec des connecteurs d'ingestion de données efficaces et une intégration native à la Data Intelligence Platform, les équipes accèdent en toute simplicité à l'analytique et à l'IA avec une gouvernance unifiée.

Apache Spark™ Declarative Pipelines
Simplifiez l'ETL par batch et en streaming grâce à la qualité de données automatisée, la change data capture (CDC), l'acquisition et la transformation des données, ainsi que la gouvernance unifiée.

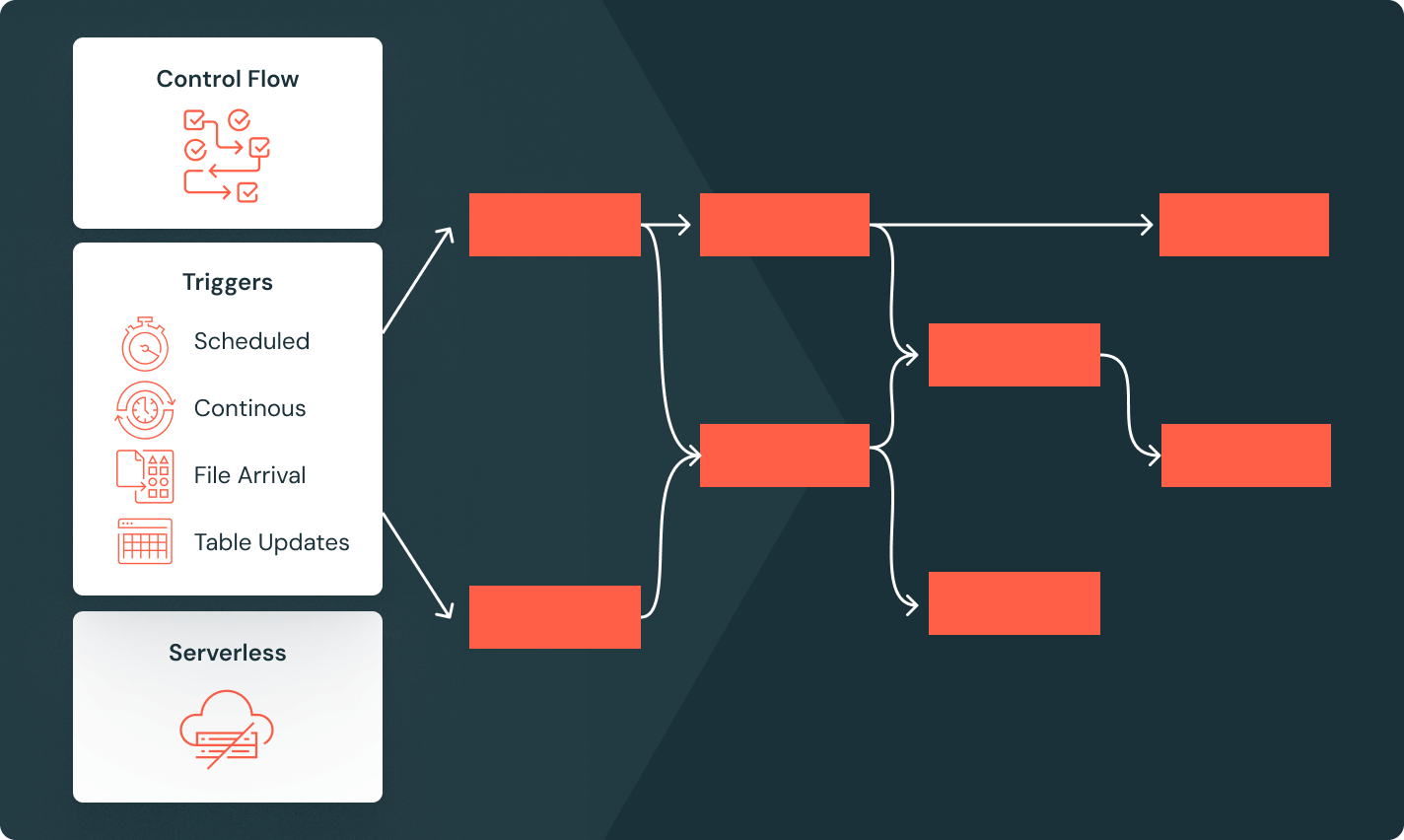
Tâches Lakeflow
Donnez aux équipes les moyens de mieux automatiser et orchestrer tous les workflows d'ETL, d'analytique et d'IA grâce à une observabilité approfondie, une haute fiabilité et la prise en charge d'un large éventail de tâches.

Unity Catalog
Encadrez sans problème tous vos assets de données avec la seule solution de gouvernance unifiée et ouverte de l'industrie pour les données et l'IA, intégrée à la Databricks Data Intelligence Platform
Lakeflow Designer
Préparez et transformez les données directement sur Databricks, avec des outils de création pilotés par IA.
Développez des pipelines de données fiables

Transformez les données brutes en tables gold de haute qualité
Mettez en œuvre des pipelines ETL pour filtrer, enrichir, nettoyer et agréger les données pour toutes vos initiatives d'analytique, d'IA et de BI. Optez pour une architecture en médaillon pour traiter les données et les faire passer des tables bronze à silver et gold.

Passez à l'étape suivante




FAQ sur le data engineering
Prêts à devenir une entreprise axée sur les données et l'IA ?
Faites le premier pas de votre transformation data