
Explorez la data science en profondeur avec Databricks
Rationalisez le workflow Data Science de bout en bout – de la préparation des données au partage des informations, en passant par la modélisation – grâce à un environnement unifié et collaboratif reposant sur une fondation ouverte de lakehouse. Bénéficiez de ressources de calcul préconfigurées, d'un IDE intégré, d'une prise en charge multilingue, d'un accès rapide à des données fiables et d'outils intégrés de visualisation avancée, pour donner un maximum de flexibilité à vos équipes d'analytique.

Collaboration dans l'ensemble du workflow de Data Science
Écrivez du code en Python, R, Scala et SQL, explorez les données grâce à des visualisations interactives et découvrez de nouveaux insights avec les notebooks de Databricks. Partagez du code en toute confiance et en toute sécurité grâce à la co-création, aux commentaires, à la gestion de versions automatique, aux intégrations Git et aux contrôles d'accès basés sur les rôles.

Concentrez-vous sur la Data Science, pas sur l'infrastructure
Vous n'êtes plus limité par la capacité de stockage de votre ordinateur portable, ni par la puissance de calcul dont vous disposez. Migrez rapidement votre environnement local vers le cloud et connectez des notebooks à vos ressources de calcul personnelles et vos clusters autogérés.

Utilisez votre IDE local préféré avec un calcul évolutif.
Le choix d'un IDE est très personnel et impacte considérablement la productivité.Connectez votre IDE préféré à Databricks afin de pouvoir continuer à bénéficier d'un stockage de données et d'un calcul sans limite. Ou utilisez simplement RStudio ou JupyterLab directement depuis Databricks pour une expérience fluide.
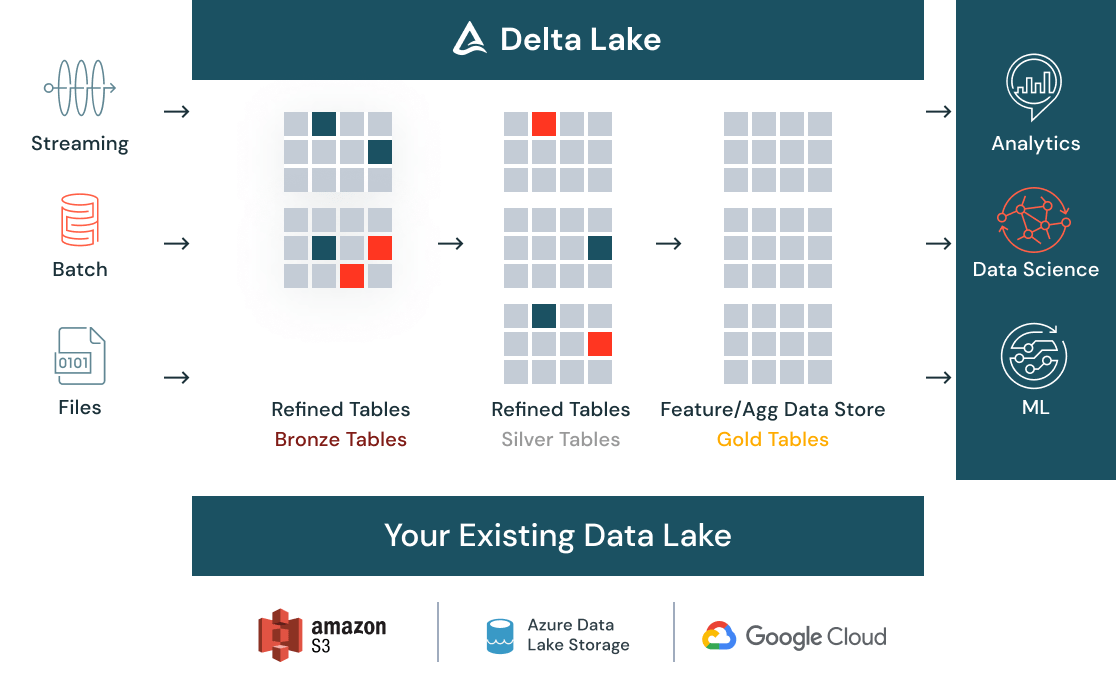
Soyez prêt pour la data science
Avec Delta Lake, nettoyez et cataloguez en un seul endroit toutes vos données, en batch et en streaming, structurées ou non structurées. Mettez-les à disposition de toute votre organisation via un magasin de données centralisé. Quand les données arrivent, des contrôles de qualité automatiques garantissent qu'elles répondent aux attentes et qu'elles sont prêtes pour l'analytique. Au fur et à mesure que les données sont alimentées par de nouvelles entrées et qu'elles sont transformées, la gestion de versions vous permet de répondre aux besoins de conformité.

Des outils visuels avec peu de code pour explorer les données
Utilisez des outils visuels natifs dans les notebooks Databricks pour préparer, transformer et analyser vos données. Donnez aux équipes, quel que soit leur niveau d'expertise, les moyens de travailler avec les données. Une fois vos transformations de données et vos visualisations terminées, vous pouvez générer le code qui s’exécute en arrière-plan. Comme vous n'avez plus besoin d'écrire le code de base, vous pouvez consacrer davantage de temps à des tâches plus productives.
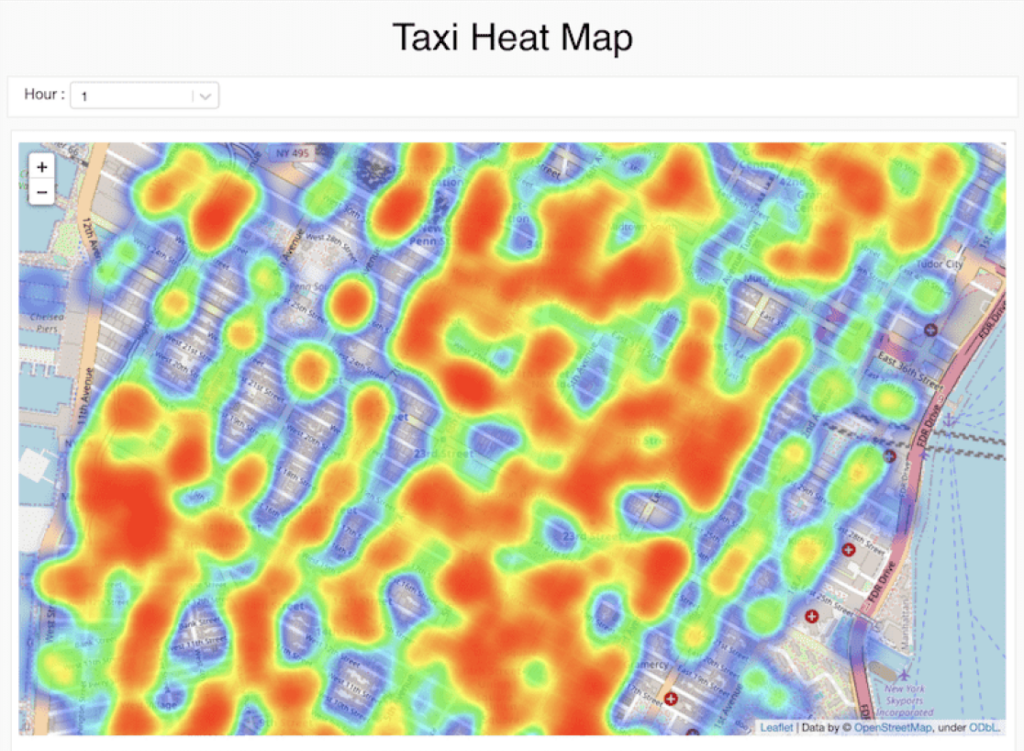
Découvrez et partagez de nouveaux insights
Partagez et exportez facilement vos résultats en transformant rapidement votre analyse en tableau de bord dynamique. Constamment à jour, ces derniers peuvent également exécuter des requêtes interactives. Les cellules, les visualisations ou les notebooks peuvent être partagés avec un contrôle d'accès basé sur les rôles et exportés dans plusieurs formats, notamment HTML et IPython Notebook.
