Implementazione di una rete neurale convoluzionale per la classificazione di automobili
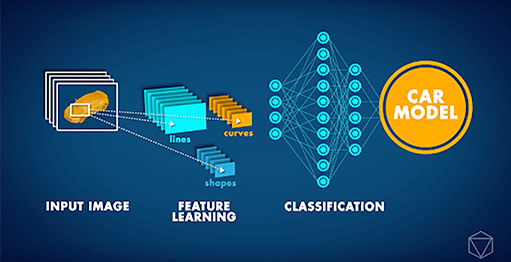
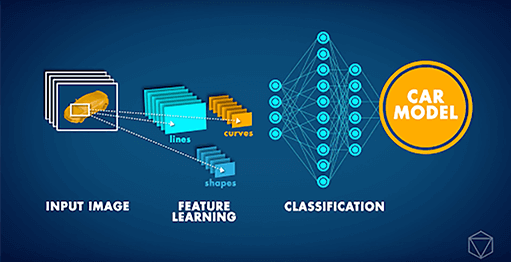
Le Reti Neurali Convoluzionali (CNN) sono architetture di Reti Neurali all'avanguardia utilizzate principalmente per attività di visione artificiale. Le CNN possono essere applicate a diverse attività, come il riconoscimento di immagini, la localizzazione di oggetti e il rilevamento dei cambiamenti. Recentemente, il nostro partner Data Insights ha ricevuto una richiesta complessa da un'importante casa automobilistica: sviluppare un'applicazione di Computer Vision che potesse identificare il modello di auto in una data immagine. Considerando che modelli di auto diversi possono apparire molto simili e che qualsiasi auto può apparire molto diversa a seconda dell'ambiente circostante e dell'angolazione da cui viene fotografata, un compito del genere era, fino a poco tempo fa, semplicemente impossibile.

Tuttavia, a partire dal 2012 circa, la ‘Rivoluzione del Deep Learning’ ha reso possibile la gestione di questo tipo di problema. Invece di ricevere una spiegazione del concetto di auto, i computer hanno potuto studiare ripetutamente le immagini e apprendere tali concetti da soli. Negli ultimi anni, ulteriori innovazioni nelle reti neurali artificiali hanno portato a un'AI in grado di eseguire attività di classificazione delle immagini con un'accuratezza a livello umano. Sulla base di tali sviluppi, siamo stati in grado di addestrare una CNN profonda per classificare le auto in base al loro modello. La rete neurale è stata addestrata sullo Stanford Cars set di dati, che contiene oltre 16.000 immagini di auto, per un totale di 196 modelli diversi. Nel tempo abbiamo potuto osservare che l'accuratezza delle previsioni ha iniziato a migliorare, man mano che la rete neurale apprendeva il concetto di auto e a distinguere i diversi modelli.
{kind=link}
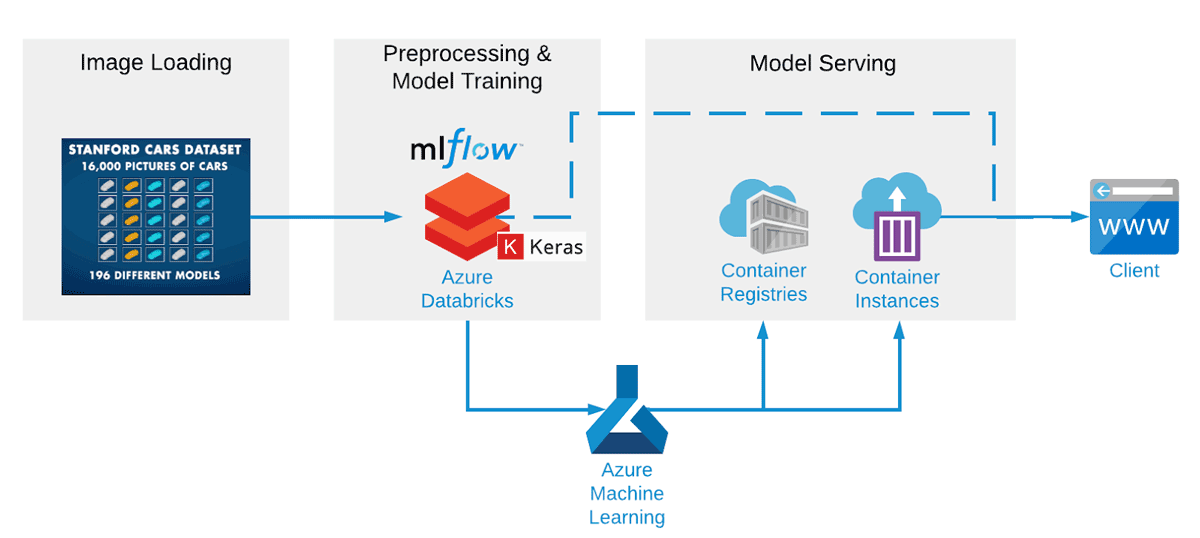
Insieme al nostro partner abbiamo creato una pipeline di machine learning end-to-end utilizzando Apache Spark™ e Koalas per il pre-processing dei dati, Keras con Tensorflow per l'addestramento del modello, MLflow per il tracciamento dei modelli e dei risultati e Azure ML per il deployment di un servizio REST. Questa configurazione all'interno di Azure Databricks è ottimizzata per addestrare le reti in modo rapido ed efficiente e aiuta anche a provare molte configurazioni CNN diverse molto più rapidamente. Anche dopo solo pochi tentativi di addestramento, l'accuratezza della CNN ha raggiunto circa l'85%.
Impostazione di una rete neurale artificiale per la classificazione di immagini
In questo articolo illustriamo alcune delle principali tecniche utilizzate per mettere in produzione una rete neurale. Se vuoi provare a eseguire la rete neurale in autonomia, i notebook completi con una guida meticolosa passo passo sono disponibili di seguito.
Questa demo utilizza lo Stanford Cars Dataset disponibile pubblicamente, che è uno dei set di dati pubblici più completi, sebbene un po' datato, quindi non troverai modelli di auto successivi al 2012 (tuttavia, una volta addestrato, il transfer learning potrebbe facilmente consentire la sostituzione con un nuovo set di dati). I dati vengono forniti tramite un account di archiviazione ADLS Gen2 che è possibile montare sul proprio workspace.

Come primo passaggio del pre-processing dei dati, le immagini vengono compresse in file hdf5 (uno per l'addestramento e uno per il testing). Questi possono quindi essere letti dalla rete neurale. Questo passaggio può essere omesso completamente, se lo si desidera, poiché i file hdf5 fanno parte dello storage ADLS Gen2 fornito nell'ambito dei notebook qui disponibili.
- Caricare il set di dati Stanford Cars in file HDF5
- Utilizzare Koalas per la image augmentation
- Addestra la CNN con Keras
- Deployment del modello come servizio REST su Azure ML
Image Augmentation con Koalas
La quantità e la diversità dei dati raccolti hanno un grande impatto sui risultati che si possono ottenere con i modelli di deep learning. La data augmentation è una strategia che può migliorare in modo significativo i risultati dell'apprendimento senza la necessità di raccogliere effettivamente nuovi dati. Con diverse tecniche come cropping, padding e flipping orizzontale, comunemente utilizzate per addestrare grandi reti neurali, i set di dati possono essere ampliati artificialmente aumentando il numero di immagini per l'addestramento e il testing.
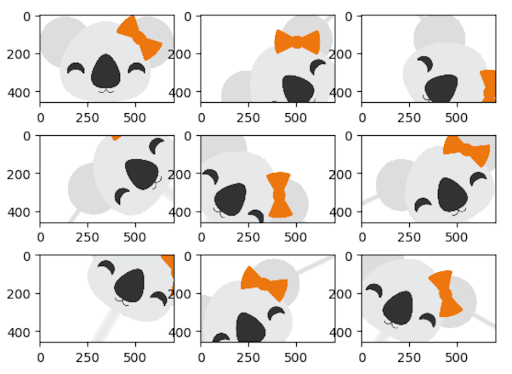
L'applicazione dell'aumento a un ampio corpus di dati di addestramento può essere molto costosa, soprattutto quando si confrontano i risultati di approcci diversi. Con Koalas diventa facile provare i framework esistenti per l'aumento delle immagini in Python e scalare il processo su un cluster con più nodi utilizzando l'API Pandas, familiare alla Data Science.
Codifica di una ResNet in Keras
Una CNN è composta da diversi "blocchi", dove ogni blocco rappresenta semplicemente un gruppo di attività operative da applicare a determinati dati di input. Questi blocchi possono essere ampiamente suddivisi in:
- Blocco di identità: una serie di attività operative che mantengono invariata la forma dei dati.
- Blocco convoluzionale: una serie di attività operative che riducono la forma dei dati di input a una forma più piccola.
Una CNN è una serie di blocchi di identità e blocchi convoluzionali (o ConvBlock) che riducono un'immagine di input a un gruppo compatto di numeri. Ciascuno di questi numeri risultanti (se il modello è addestrato correttamente) dovrebbe alla fine fornire informazioni utili per classificare l'immagine. Una CNN residuale aggiunge un passaggio aggiuntivo per ogni blocco. I dati vengono salvati come variabile temporanea prima dell'applicazione delle attività operative che costituiscono il blocco, dopodiché questi dati temporanei vengono aggiunti ai dati di output. Generalmente, questo passaggio aggiuntivo viene applicato a ogni blocco. Ad esempio, la figura seguente mostra una CNN semplificata per il rilevamento di numeri scritti a mano:
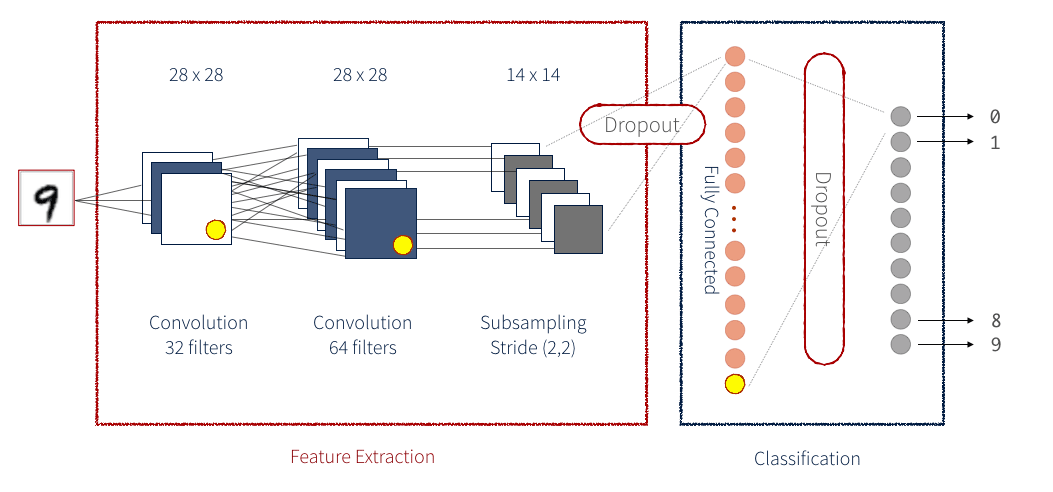
Esistono molti metodi diversi per implementare una rete neurale. Uno dei modi più intuitivi è tramite Keras. Keras fornisce una semplice libreria front-end per eseguire i singoli passaggi che compongono una rete neurale. Keras può essere configurato per funzionare con un back-end Tensorflow o con un back-end Theano. Qui useremo un back-end Tensorflow. Una rete Keras è suddivisa in più livelli, come illustrato di seguito. Per la nostra rete, stiamo anche definendo la nostra implementazione del cliente di un livello.
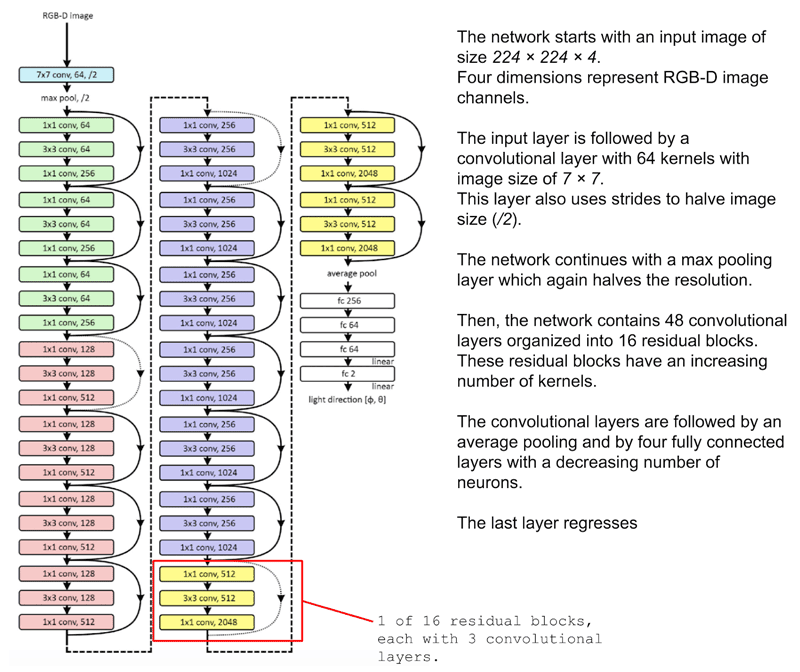
Il Scale Layer
Per qualsiasi operazione personalizzata che abbia pesi addestrabili, Keras consente di implementare il proprio livello. Quando si gestiscono enormi quantità di dati di immagine, si possono riscontrare problemi di memoria. Inizialmente, le immagini RGB contengono dati interi (0-255). Quando si esegue la gradient descent come parte dell'ottimizzazione durante la backpropagation, si noterà che i gradienti interi non consentono una precisione sufficiente per regolare correttamente i pesi della rete. Pertanto, è necessario passare alla precisione float. È qui che possono sorgere problemi. Anche quando le immagini vengono ridimensionate a 224x224x3, utilizzando diecimila immagini di addestramento si ottengono oltre 1 miliardo di voci in virgola mobile. Invece di convertire un intero set di dati in precisione float, la pratica migliore è utilizzare uno 'Scale Layer', che ridimensiona i dati di input un'immagine alla volta e solo quando è necessario. Questo dovrebbe essere applicato dopo la Batch Normalization nel modello. I parametri di questo Scale Layer sono anche parametri che possono essere appresi tramite l'addestramento.
Per utilizzare questo livello personalizzato anche durante lo scoring, dobbiamo impacchettare la classe insieme al nostro modello. Con MLflow possiamo ottenere questo risultato con un dizionario Keras custom_objects che mappa i nomi (stringhe) a classi o funzioni personalizzate associate al modello Keras. MLflow salva questi livelli personalizzati utilizzando CloudPickle e li ripristina automaticamente quando il modello viene caricato con mlflow.keras.load_model(). e mlflow.pyfunc.load_model().
Monitoraggio dei risultati con MLflow e Azure Machine Learning
Lo sviluppo del machine learning comporta complessità aggiuntive rispetto allo sviluppo del software. La miriade di strumenti e framework disponibili rende difficile tracciare gli esperimenti, riprodurre i risultati e distribuire i modelli di machine learning. Insieme ad Azure Machine Learning è possibile accelerare e gestire il ciclo di vita del machine learning end-to-end utilizzando MLflow per creare, condividere e distribuire in modo affidabile applicazioni di machine learning con Azure Databricks.
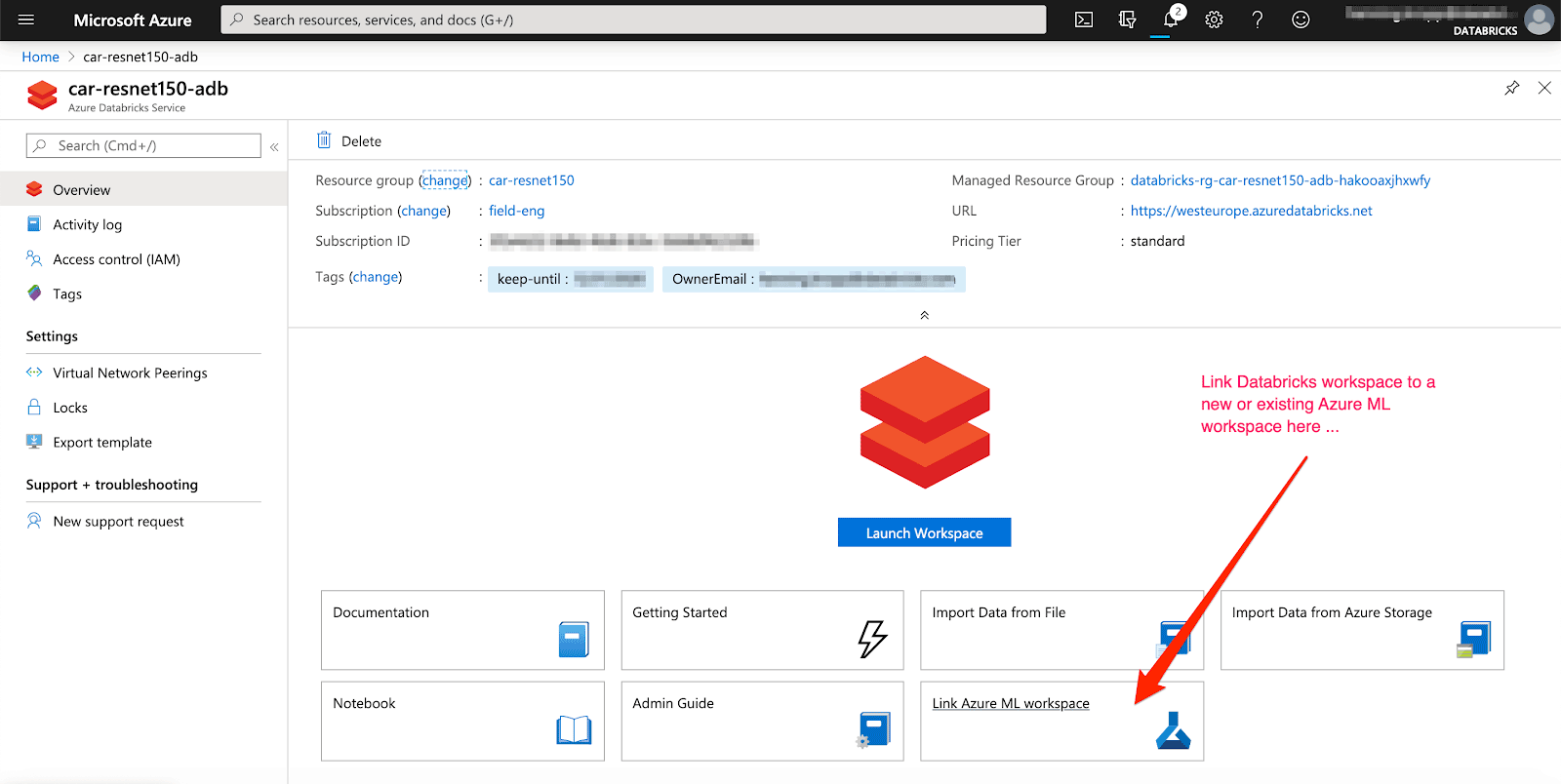
Per tenere traccia automaticamente dei risultati, è possibile collegare un workspace di Azure ML nuovo o esistente al proprio workspace di Azure Databricks. Inoltre, MLflow supporta la registrazione automatica per i modelli Keras (mlflow.keras.autolog()), rendendo l'esperienza estremamente semplice.
Sebbene le utilità di persistenza del modello integrato di MLflow siano pratiche per creare pacchetti di modelli da varie librerie di ML diffuse come Keras, non coprono tutti i casi d'uso. Ad esempio, potresti voler usare un modello da una libreria di ML non supportata in modo esplicito dai flavour integrati di MLflow. In alternativa, potresti voler creare un pacchetto con codice di inferenza e dati personalizzati per creare un modello MLflow. Fortunatamente, MLflow fornisce due soluzioni che possono essere usate per eseguire queste attività: Modelli Python personalizzati e Flavour personalizzati.
In questo scenario vogliamo assicurarci di poter utilizzare un motore di inferenza del modello che supporti la gestione delle richieste da un client API REST. A tale scopo, stiamo usando un modello personalizzato basato sul modello Keras creato in precedenza per accettare un oggetto Dataframe JSON che contiene un'immagine codificata in Base64.
Nel passaggio successivo possiamo utilizzare questo py_model e distribuirlo su un server Azure Container Instances, operazione che può essere eseguita tramite l'integrazione di MLflow in Azure ML.
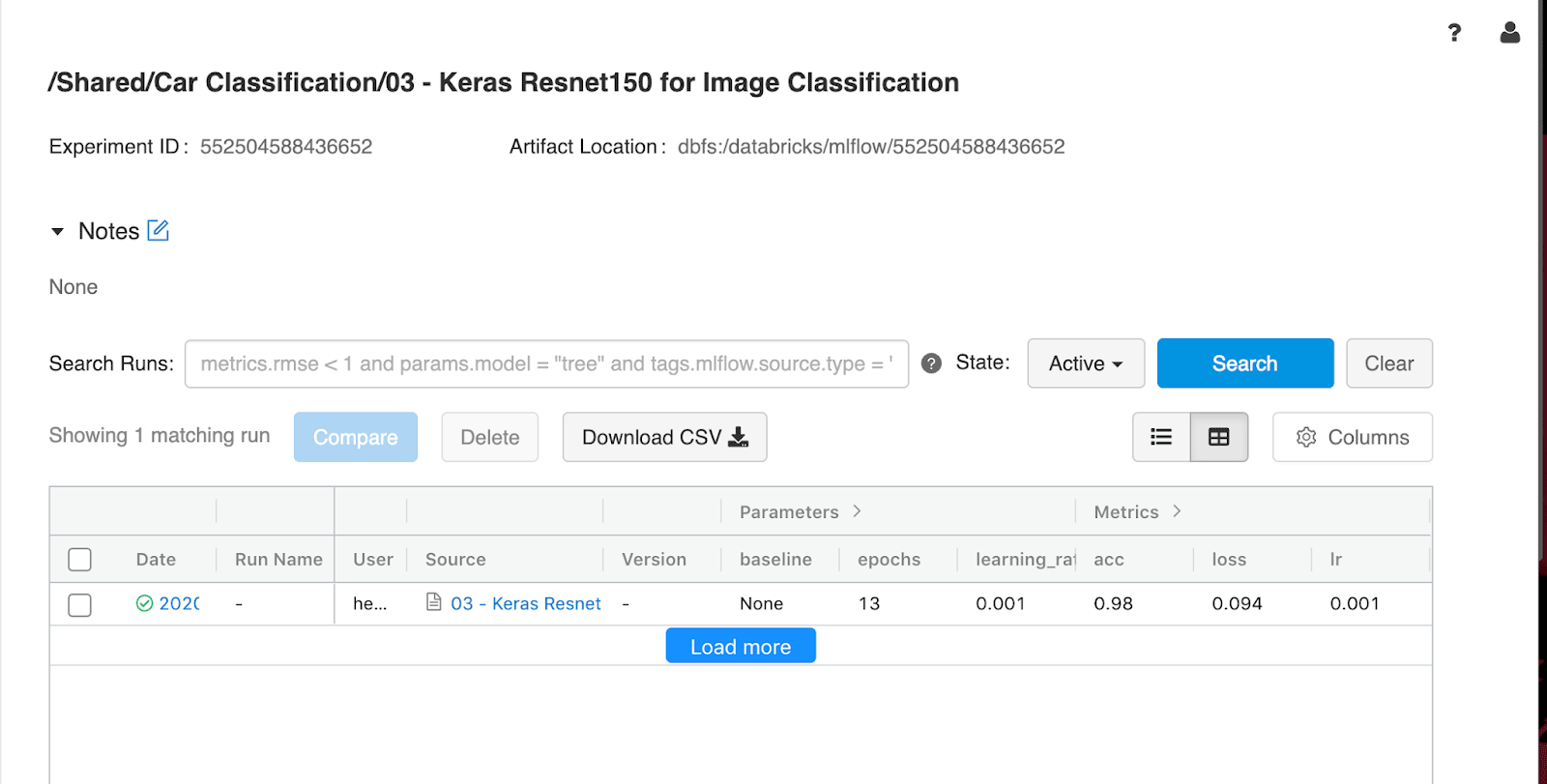
Distribuire un modello di classificazione di immagini in Istanze di Azure Container
A questo punto abbiamo un modello di machine learning addestrato e abbiamo registrato un modello nel nostro workspace con MLflow nel cloud. Come passaggio finale, vorremmo distribuire il modello come servizio web su Istanze di Azure Container.
Un servizio web è un'immagine, in questo caso una Docker Image. Incapsula la logica di punteggio e il modello stesso. In questo caso, usiamo la nostra rappresentazione personalizzata del modello MLflow, che ci dà il controllo su come la logica di punteggio gestisce le immagini da un client REST e su come viene modellata la risposta.
Container Instances è un'ottima soluzione per testare e comprendere il flusso di lavoro. Per distribuzioni di produzione scalabili, valuta la possibilità di usare Azure Kubernetes Service. Per ulteriori informazioni, vedi come e dove eseguire la distribuzione.
Guida introduttiva alla classificazione di immagini con CNN
Questo articolo e i Notebook illustrano le tecniche principali utilizzate per la configurazione di un flusso di lavoro end-to-end per l'addestramento e la distribuzione di una rete neurale in produzione in Azure. Gli esercizi del notebook collegato illustrano i passaggi necessari per la creazione di questo ambiente Azure Databricks personale usando strumenti come Keras, Databricks Koalas, MLflow e Azure ML.
Risorse per sviluppatori
- Notebook
- Video: https://www.youtube.com/watch?v=mxEqcIbPqPs
- GitHub: https://github.com/EvanEames/Cars
- Slide: https://www.slideshare.net/jonbros/deep-learning-with-databricks
- PDF: https://github.com/EvanEames/Cars/blob/master/CNN_howto.pdf
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.