Guida all'implementazione di un modello di data vault sulla Databricks Lakehouse Platform
Esistono molti modelli di dati diversi che è possibile utilizzare durante la progettazione di un sistema analitico, come modelli di dominio specifici dei settori industriali e le metodologie Kimball, Inmon e Data Vault. A seconda dei requisiti specifici, è possibile utilizzare queste diverse tecniche di modellazione durante la progettazione di una lakehouse. Tutti hanno i loro punti di forza e ognuno può essere adatto a diversi casi d'uso.
In definitiva, un modello di dati non è altro che un costrutto che definisce tabelle diverse con relazioni uno-a-uno, uno-a-molti e molti-a-molti definite. Le piattaforme dati devono fornire le best practice per la fisicizzazione del modello di dati, per facilitare il recupero delle informazioni e migliorare le prestazioni.
In un articolo precedente, abbiamo trattato Five Simple Steps for Implementing a Star Schema in Databricks With Delta Lake. In questo articolo spiegheremo cos'è un Data Vault, come implementarlo nei layer Bronze/Silver/Gold e come ottenere le migliori prestazioni dal Data Vault con la Databricks Lakehouse Platform.
Definizione di modellazione Data Vault
L'obiettivo della modellazione Data Vault è adattarsi ai requisiti aziendali in rapida evoluzione e supportare fin dalla progettazione uno sviluppo più rapido e agile dei data warehouse. Un Data Vault è adatto alla metodologia lakehouse poiché il modello di dati è facilmente estensibile e granulare con la sua progettazione hub, link e satellite, pertanto le modifiche alla progettazione e all'ETL sono facili da implementare.
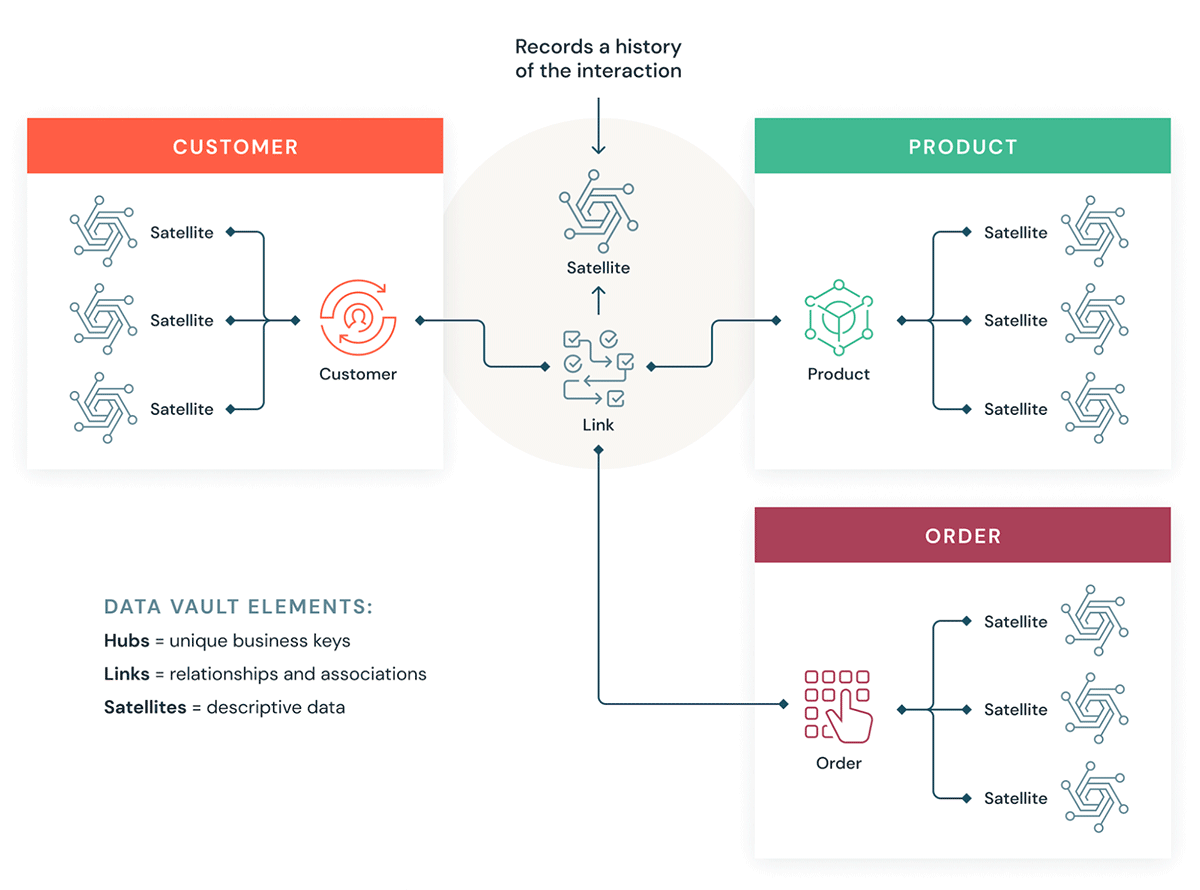
Comprendiamo alcuni elementi costitutivi di un Data Vault. In genere, un modello Data Vault ha tre tipi di entità:
- Hub — Un hub rappresenta un'entità di business fondamentale, come clienti, prodotti, ordini, ecc. Gli analisti utilizzeranno le chiavi naturali/di business per ottenere informazioni su un hub. La chiave primaria delle tabelle Hub è solitamente derivata da una combinazione di ID del concetto di business, data di caricamento e altre informazioni sui metadati.
- Collegamenti - I collegamenti rappresentano le relazioni tra gli hub. Contiene solo le chiavi di join. È come una tabella dei fatti senza fatti nel modello dimensionale. Nessun attributo, solo chiavi di join.
- Satelliti — Le tabelle Satellite contengono gli attributi delle entità nell'hub o nei link. Contengono informazioni descrittive sulle entità aziendali principali. Sono simili a una versione normalizzata di una tabella dimensionale. Ad esempio, un hub clienti può avere molte tabelle satellite, quali gli attributi geografici, il punteggio di credito e i livelli di fedeltà del cliente, ecc.
Uno dei principali vantaggi dell'utilizzo della metodologia Data Vault è che i job ETL esistenti richiedono un refactoring significativamente minore quando il modello di dati cambia. Data Vault è uno stile di modellazione "ottimizzato per la scrittura", supporta approcci di sviluppo agile ed è ideale per l'approccio data lake e lakehouse.
Come Data Vault si integra in un Lakehouse
Vediamo come alcuni dei nostri clienti utilizzano il Data Vault Modeling in un'architettura Databricks Lakehouse:
Considerazioni per l'implementazione di un modello Data Vault in Databricks Lakehouse
- La modellazione Data Vault consiglia di usare un hash delle business key come chiavi primarie. Databricks supporta le funzioni hash, md5 e SHA pronte all'uso per supportare le business key.
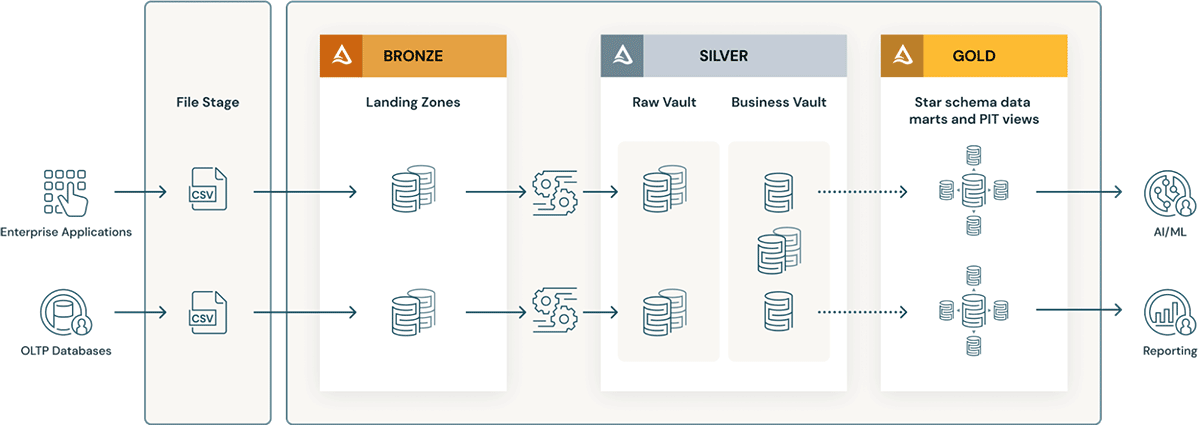
- I layer di Data Vault includono il concetto di landing zone (e talvolta di staging zone). Entrambi questi livelli fisici si adattano naturalmente al livello Bronze del data lakehouse. Se i dati della landing zone arrivano in formati come Avro, CSV, parquet, XML e JSON, vengono convertiti in tabelle in formato Delta nella staging zone, in modo che il successivo ETL possa avere prestazioni elevate.
- Il Raw Vault viene creato dalla zona di landing o di staging. I dati vengono modellati come tabelle Hub, Link e Satellite nel Vault di dati grezzi. Ulteriori regole ETL "business" solitamente non vengono applicate durante il caricamento del Vault di dati grezzi.
- Tutte le business rule ETL, le regole di qualità dei dati, di pulizia e di conformità vengono applicate tra Raw Vault e Business Vault. Le tabelle del Business Vault possono essere organizzate per domini di dati, che fungono da "repository centrale" aziendale di dati standardizzati e puliti. I data steward e gli SME sono responsabili della governance, della qualità dei dati e delle regole di business relative alle loro aree del Business Vault.
- Le tabelle di supporto alle query, come le tabelle Point-in-Time (PIT) e le Bridge table, vengono create per il livello di presentazione al di sopra del business vault. Le tabelle PIT miglioreranno le prestazioni delle query poiché alcuni satelliti e hub sono pre-collegati e forniscono alcune condizioni WHERE con filtri "point in time". Le Bridge table pre-collegano hub o entità per fornire viste appiattite simili a una "tabella dimensionale" per le Entità. Le Delta Live Tables sono esattamente come le Materialized View e possono essere usate per creare tabelle Point-in-Time e Bridge table nel livello Gold/di presentazione al di sopra del Business Data Vault.
- Man mano che i processi di business cambiano e si adattano, il modello Data Vault può essere facilmente esteso senza un refactoring massiccio come i modelli dimensionali. Hub aggiuntivi (aree tematiche) possono essere facilmente aggiunti ai link (tabelle di join puro) e satelliti aggiuntivi (ad es. segmentazioni dei clienti) possono essere aggiunti a un hub (cliente) con modifiche minime.
- Inoltre, il caricamento di un Data Warehouse con modello dimensionale nel livello Gold diventa più semplice per i seguenti motivi:
- Gli hub semplificano la gestione delle chiavi (le chiavi naturali degli hub possono essere convertite in chiavi surrogate tramite colonne Identity).
- I satelliti facilitano il caricamento delle dimensioni perché contengono tutti gli attributi.
- I Link rendono il caricamento delle tabelle fact piuttosto semplice, perché contengono tutte le relazioni.
Suggerimenti per ottenere le migliori prestazioni da un modello Data Vault in Databricks Lakehouse
- Utilizza tabelle in formato Delta per le tabelle di Raw Vault, Business Vault e Gold layer.
- Assicurati di utilizzare gli indici OPTIMIZE e Z-order su tutte le chiavi di join di Hub, Link e Satellite.
- Non partizionare eccessivamente le tabelle, specialmente le tabelle satellite più piccole. Utilizza l'indicizzazione con filtro di Bloom sulle colonne di tipo Data, sulle colonne flag correnti e sulle colonne predicato che vengono in genere filtrate per garantire le migliori prestazioni, specialmente se è necessario creare indici aggiuntivi oltre a Z-order.
- Delta Live Tables (Viste materializzate) rende molto facile la creazione e la gestione di tabelle PIT.
- Riduci
optimize.maxFileSizea un numero inferiore, ad esempio 32-64 MB invece del valore default di 1 GB. Creando file più piccoli, puoi beneficiare del file pruning e ridurre al minimo l'I/O per recuperare i dati che devi unire. - Il modello Data Vault presenta un numero relativamente maggiore di join, quindi utilizza la versione più recente di DBR che garantisce che l'Adaptive Query Execution sia attivo per impostazione predefinita, in modo che venga utilizzata automaticamente la migliore strategia di join. Utilizza Join hints solo se necessario. ( per l'ottimizzazione avanzata delle prestazioni).
Scopri di più sulla modellazione Data Vault su Data Vault Alliance.
Inizia a creare il tuo Data Vault nel Lakehouse
Prova Databricks gratis per 14 giorni
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.