Pipeline di dati in streaming a bassa latenza con Delta Live Tables e Apache Kafka
di Frank Munz
Delta Live Tables (DLT) è il primo framework ETL che utilizza un approccio dichiarativo semplice per creare pipeline di dati affidabili e gestisce completamente l'infrastruttura sottostante su larga scala per dati batch e streaming. Molti casi d'uso richiedono insight azionabili derivati da dati quasi in tempo reale. Delta Live Tables abilita pipeline di dati in streaming a bassa latenza per supportare tali casi d'uso con basse latenze, ingerendo direttamente dati da event bus come Apache Kafka, AWS Kinesis, Confluent Cloud, Amazon MSK, o Azure Event Hubs.
Questo articolo illustrerà l'uso di DLT con Apache Kafka, fornendo il codice Python necessario per ingerire stream. Verrà spiegata l'architettura di sistema consigliata e verranno esplorate le impostazioni DLT correlate da considerare lungo il percorso.
Piattaforme di streaming
Gli event bus o message bus disaccoppiano i produttori di messaggi dai consumatori. Un caso d'uso di streaming popolare è la raccolta di dati click-through dagli utenti che navigano su un sito web, dove ogni interazione dell'utente viene memorizzata come evento in Apache Kafka. Lo stream di eventi da Kafka viene quindi utilizzato per l'analisi dei dati in streaming in tempo reale. Molteplici consumatori di messaggi possono leggere gli stessi dati da Kafka e utilizzarli per apprendere gli interessi del pubblico, i tassi di conversione e i motivi di rimbalzo. I dati di eventi in streaming in tempo reale dalle interazioni dell'utente spesso devono anche essere correlati agli acquisti effettivi memorizzati in un database di fatturazione.
Apache Kafka
Apache Kafka è un popolare event bus open source. Kafka utilizza il concetto di topic, un log distribuito append-only di eventi in cui i messaggi vengono bufferizzati per un certo periodo di tempo. Sebbene i messaggi in Kafka non vengano eliminati una volta consumati, non vengono nemmeno memorizzati indefinitamente. La retention dei messaggi per Kafka può essere configurata per topic e per impostazione predefinita è di 7 giorni. I messaggi scaduti verranno eventualmente eliminati.
Questo articolo è incentrato su Apache Kafka; tuttavia, i concetti discussi si applicano anche a molti altri event bus o sistemi di messaggistica.
Pipeline di dati in streaming
In una pipeline di flusso dati, Delta Live Tables e le loro dipendenze possono essere dichiarate con un'istruzione SQL standard Create Table As Select (CTAS) e la parola chiave DLT "live".
Durante lo sviluppo di DLT con Python, il decoratore @dlt.table viene utilizzato per creare una Delta Live Table. Per garantire la qualità dei dati in una pipeline, DLT utilizza Expectations, che sono semplici clausole di vincolo SQL che definiscono il comportamento della pipeline con record non validi.
Poiché i carichi di lavoro di streaming spesso presentano volumi di dati imprevedibili, Databricks impiega autoscaling avanzato per le pipeline di flusso dati al fine di minimizzare la latenza end-to-end complessiva, riducendo al contempo i costi spegnendo l'infrastruttura non necessaria.
Delta Live Tables vengono completamente ricalcolate, nell'ordine corretto, esattamente una volta per ogni esecuzione della pipeline.
Al contrario, le Delta Live Tables in streaming sono stateful, calcolate in modo incrementale ed elaborano solo i dati aggiunti dall'ultima esecuzione della pipeline. Se la query che definisce una tabella live in streaming cambia, i nuovi dati verranno elaborati in base alla nuova query, ma i dati esistenti non verranno ricalcolati. Le tabelle live in streaming utilizzano sempre una sorgente in streaming e funzionano solo su stream append-only, come Kafka, Kinesis o Auto Loader. Le DLT in streaming si basano su Spark Structured Streaming.
È possibile concatenare più pipeline in streaming, ad esempio, carichi di lavoro con volumi di dati molto elevati e requisiti di bassa latenza.
Ingestione diretta da motori di streaming
Delta Live Tables scritte in Python possono ingerire direttamente dati da un event bus come Kafka utilizzando Spark Structured Streaming. È possibile impostare un breve periodo di retention per il topic Kafka per evitare problemi di conformità, ridurre i costi e quindi beneficiare dello storage economico, elastico e governabile che Delta offre.
Come primo passo nella pipeline, si consiglia di ingerire i dati così come sono in una tabella bronze (raw) ed evitare trasformazioni complesse che potrebbero eliminare dati importanti. Come qualsiasi Delta Table, la tabella bronze manterrà la cronologia e consentirà di eseguire attività GDPR e di conformità.
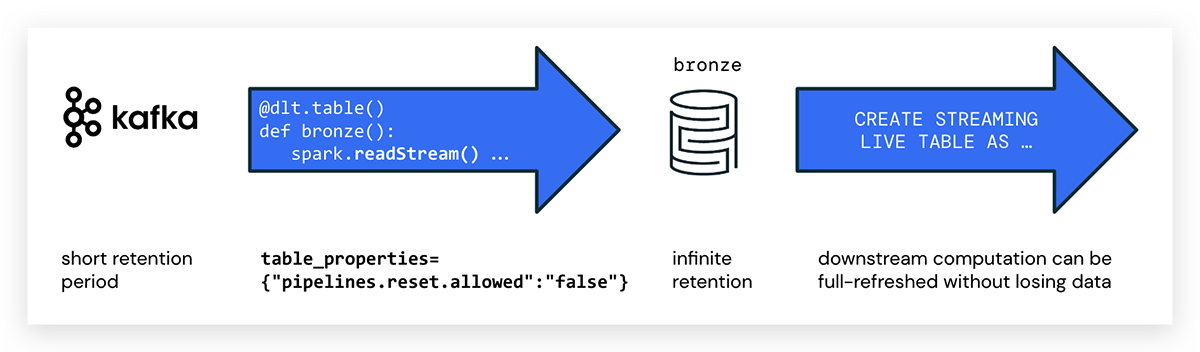
Quando si scrivono pipeline DLT in Python, si utilizza l'annotazione @dlt.table per creare una tabella DLT. Non esiste un attributo speciale per contrassegnare le DLT in streaming in Python; è sufficiente utilizzare spark.readStream() per accedere allo stream. Un esempio di codice per creare una tabella DLT con il nome kafka_bronze che consuma dati da un topic Kafka è il seguente:
pipelines.reset.allowed
Si noti che gli event bus in genere scadono i messaggi dopo un certo periodo di tempo, mentre Delta è progettato per una retention infinita.
Ciò potrebbe portare al fatto che i dati sorgente su Kafka siano già stati eliminati durante l'esecuzione di un refresh completo per una pipeline DLT. In questo caso, non tutti i dati storici potrebbero essere recuperati dalla piattaforma di messaggistica e i dati sarebbero mancanti nelle tabelle DLT. Per evitare la perdita di dati, utilizzare la seguente proprietà della tabella DLT:
pipelines.reset.allowed=false
Impostare pipelines.reset.allowed su false impedisce i refresh della tabella, ma non impedisce le scritture incrementali nelle tabelle o il flusso di nuovi dati nella tabella.
Checkpointing
Se si è uno sviluppatore esperto di Spark Structured Streaming, si noterà l'assenza di checkpointing nel codice sopra. In Spark Structured Streaming, il checkpointing è necessario per persistere le informazioni sullo stato di avanzamento su quali dati sono stati elaborati con successo e, in caso di errore, questi metadati vengono utilizzati per riavviare una query fallita esattamente da dove si era interrotta.
Mentre i checkpoint sono necessari per il recupero da errori con garanzie exactly-once in Spark Structured Streaming, DLT gestisce lo stato automaticamente senza alcuna configurazione manuale o checkpointing esplicito richiesto.
Mix di SQL e Python per una pipeline DLT
Una pipeline DLT pu�ò essere composta da più notebook, ma un notebook DLT deve essere interamente scritto in SQL o Python (a differenza di altri notebook Databricks in cui è possibile avere celle di linguaggi diversi in un unico notebook).
Ora, se la vostra preferenza è SQL, potete codificare l'ingestione dei dati da Apache Kafka in un notebook in Python e quindi implementare la logica di trasformazione delle vostre pipeline di dati in un altro notebook in SQL.
Schema mapping
Quando si leggono dati da una piattaforma di messaggistica, lo stream di dati è opaco e deve essere fornito uno schema.
L'esempio Python seguente mostra la definizione dello schema degli eventi da un fitness tracker e come la parte value del messaggio Kafka viene mappata a tale schema.
Vantaggi
La lettura di dati in streaming in DLT direttamente da un message broker minimizza la complessità architetturale e fornisce una latenza end-to-end inferiore, poiché i dati vengono trasmessi direttamente dal message broker e non è coinvolto alcun passaggio intermedio.
Ingestione in Streaming con Intermediario Object Store Cloud
Per alcuni casi d'uso specifici, potresti voler scaricare dati da Apache Kafka, ad esempio utilizzando un connettore Kafka, e archiviare i tuoi dati in streaming in un intermediario object store cloud. In un workspace Databricks, l'object store specifico del cloud provider può quindi essere mappato tramite il Databricks File System (DBFS) come una cartella indipendente dal cloud. Una volta scaricati i dati, Databricks Auto Loader può ingerirli.
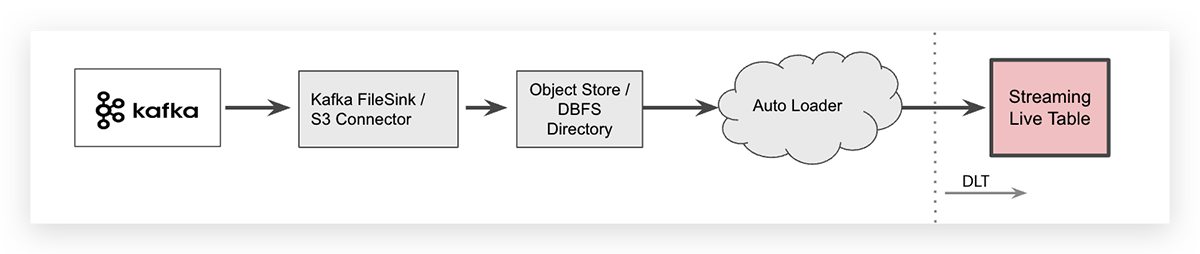
Auto Loader può ingerire dati con una singola riga di codice SQL. La sintassi per ingerire file JSON in una tabella DLT è mostrata di seguito (è spezzata su due righe per leggibilità).
Nota che Auto Loader stesso è una sorgente dati in streaming e tutti i file arrivati di recente verranno elaborati esattamente una volta, da qui la parola chiave streaming per la tabella raw che indica che i dati vengono ingeriti in modo incrementale in quella tabella.
Poiché scaricare dati in streaming su un object store cloud introduce un passaggio aggiuntivo nell'architettura del tuo sistema, aumenterà anche la latenza end-to-end e creerà costi di archiviazione aggiuntivi. Tieni presente che il connettore Kafka che scrive i dati degli eventi nell'object store cloud deve essere gestito, aumentando la complessità operativa.
Pertanto, Databricks raccomanda come best practice di accedere direttamente ai dati dell'event bus da DLT utilizzando Spark Structured Streaming come descritto sopra.
Altri Event Bus o Sistemi di Messaggistica
Questo articolo è incentrato su Apache Kafka; tuttavia, i concetti discussi si applicano anche ad altri event bus o sistemi di messaggistica. DLT supporta qualsiasi sorgente dati che Databricks Runtime supporta direttamente.
Amazon Kinesis
In Kinesis, scrivi messaggi su uno stream serverless completamente gestito. Come Kafka, Kinesis non archivia i messaggi in modo permanente. La retention predefinita dei messaggi in Kinesis è di un giorno.
Quando si utilizza Amazon Kinesis, sostituire format("kafka") con format("kinesis") nel codice Python per l'ingestione in streaming sopra e aggiungere impostazioni specifiche di Amazon Kinesis con option(). Per maggiori informazioni, consulta la sezione su Kinesis Integration nella documentazione di Spark Structured Streaming.
Azure Event Hubs
Per le impostazioni di Azure Event Hubs, consulta la documentazione ufficiale di Microsoft e l'articolo Ricette Delta Live Tables: Consumo da Azure Event Hubs.
Riepilogo
DLT è molto più del semplice "T" in ETL. Con DLT, puoi facilmente ingerire da sorgenti in streaming e batch, pulire e trasformare dati sulla Databricks Lakehouse Platform su qualsiasi cloud con qualità dei dati garantita.
I dati da Apache Kafka possono essere ingeriti connettendosi direttamente a un broker Kafka da un notebook DLT in Python. La perdita di dati può essere evitata per un refresh completo della pipeline anche quando i dati sorgente nello strato di streaming Kafka sono scaduti.
Inizia
Se sei un cliente Databricks, segui semplicemente la guida per iniziare. Leggi le note di rilascio per saperne di più su cosa è incluso in questa release GA. Se non sei un cliente Databricks esistente, iscriviti per una prova gratuita e puoi visualizzare i nostri dettagli sui prezzi DLT qui.
Unisciti alla conversazione nella Community Databricks dove colleghi appassionati di dati stanno chiacchierando degli annunci e degli aggiornamenti del Data + AI Summit 2022. Impara. Fai rete.
Ultimo ma non meno importante, goditi la sessione Dive Deeper into Data Engineering dal summit. In quella sessione, ti guiderò attraverso il codice di un altro esempio di dati in streaming con uno stream live di Twitter, Auto Loader, Delta Live Tables in SQL e analisi del sentiment Hugging Face.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.