Delta Live Tables annuncia nuove funzionalità e ottimizzazioni delle prestazioni
DLT annuncia lo sviluppo di Enzyme, un'ottimizzazione delle prestazioni creata appositamente per i carichi di lavoro ETL, e lancia diverse nuove funzionalità tra cui l'Autoscaling avanzato
Dalla disponibilità di Delta Live Tables (DLT) su tutti i cloud ad aprile (annuncio), abbiamo introdotto nuove funzionalità per semplificare lo sviluppo, migliorato la gestione automatizzata dell'infrastruttura, annunciato un nuovo livello di ottimizzazione chiamato Project Enzyme per accelerare l'elaborazione ETL e abilitato diverse funzionalità enterprise e miglioramenti dell'UX.
DLT consente ad analisti e data engineer di creare rapidamente pipeline ETL batch o in streaming pronte per la produzione in SQL e Python. DLT semplifica lo sviluppo ETL consentendo di definire la pipeline di elaborazione dati in modo dichiarativo. DLT comprende le dipendenze della pipeline e automatizza quasi tutte le complessità operative.
Delta Live Tables è cresciuto fino ad alimentare casi d'uso ETL di produzione presso aziende leader in tutto il mondo sin dalla sua nascita. DLT è utilizzato da oltre 1.000 aziende, dalle startup alle grandi imprese, tra cui ADP, Shell, H&R Block, Jumbo, Bread Finance e JLL.
Con DLT, gli ingegneri possono concentrarsi sulla fornitura di dati anziché sull'operatività e la manutenzione delle pipeline e sfruttare le funzionalità chiave. Abbiamo abilitato diverse funzionalità enterprise e miglioramenti dell'UX, tra cui il supporto per Change Data Capture (CDC) per acquisire in modo efficiente e semplice i dati in arrivo continuamente, e lanciato un'anteprima di Enhanced Auto Scaling che offre prestazioni superiori per i carichi di lavoro in streaming. Vediamo nel dettaglio i miglioramenti:
Semplifica lo sviluppo
Abbiamo esteso la nostra interfaccia utente per semplificare la gestione del ciclo di vita end-to-end dell'ETL.
Miglioramenti dell'UX. Abbiamo esteso la nostra interfaccia utente per semplificare la gestione delle pipeline DLT, visualizzare gli errori e fornire accesso ai membri del team con ricche ACL per le pipeline. Abbiamo anche aggiunto un'interfaccia utente di osservabilità per visualizzare le metriche di qualità dei dati in un'unica vista, e reso più semplice pianificare le pipeline direttamente dall'interfaccia utente. Scopri di più.
Pulsante Pianifica Pipeline. DLT consente di eseguire pipeline ETL in modalità continua o attivata. Le pipeline continue elaborano nuovi dati man mano che arrivano e sono utili in scenari in cui la latenza dei dati è fondamentale. Tuttavia, molti clienti scelgono di eseguire le pipeline DLT in modalità attivata per controllare più da vicino l'esecuzione della pipeline e i costi. Per semplificare l'attivazione delle pipeline DLT con una pianificazione ricorrente utilizzando Databricks Jobs, abbiamo aggiunto un pulsante 'Pianifica' nell'interfaccia utente DLT per consentire agli utenti di impostare una pianificazione ricorrente con pochi clic senza uscire dall'interfaccia utente DLT. È anche possibile visualizzare una cronologia delle esecuzioni e navigare rapidamente ai dettagli del Job per configurare le notifiche via email. Scopri di più.
Change Data Capture (CDC). Con DLT, i data engineer possono implementare facilmente il CDC con una nuova API dichiarativa APPLY CHANGES INTO, sia in SQL che in Python. Questa nuova funzionalità consente alle pipeline ETL di rilevare facilmente le modifiche ai dati di origine e applicarle ai set di dati in tutto il lakehouse. DLT elabora le modifiche ai dati in Delta Lake in modo incrementale, contrassegnando i record da inserire, aggiornare o eliminare durante la gestione degli eventi CDC. Scopri di più.
CDC Slowly Changing Dimensions—Type 2. Quando si gestiscono dati che cambiano (CDC), spesso è necessario aggiornare i record per tenere traccia dei dati più recenti. SCD Type 2 è un modo per applicare aggiornamenti a una destinazione in modo che i dati originali vengano preservati. Ad esempio, se un'entità utente nel database si sposta in un indirizzo diverso, possiamo memorizzare tutti gli indirizzi precedenti per quell'utente. DLT supporta SCD type 2 per le organizzazioni che richiedono il mantenimento di una traccia di controllo delle modifiche. SCD2 conserva una cronologia completa dei valori. Quando il valore di un attributo cambia, il record corrente viene chiuso, viene creato un nuovo record con i valori dei dati modificati e questo nuovo record diventa il record corrente. Scopri di più.
Gestione automatizzata dell'infrastruttura
Autoscaling Migliorato (anteprima). Dimensionare manualmente i cluster per prestazioni ottimali, dati volumi di dati mutevoli e imprevedibili, come con i carichi di lavoro in streaming, può essere difficile e portare a un sovradimensionamento. L'attuale autoscaling dei cluster non è consapevole degli SLO di streaming e potrebbe non scalare rapidamente anche se l'elaborazione è in ritardo rispetto al tasso di arrivo dei dati, o potrebbe non scalare verso il basso quando il carico è basso. DLT impiega un algoritmo di autoscaling migliorato creato appositamente per lo streaming. L'Autoscaling Migliorato di DLT ottimizza l'utilizzo del cluster garantendo al contempo la minimizzazione della latenza end-to-end complessiva. Lo fa rilevando le fluttuazioni dei carichi di lavoro in streaming, inclusi i dati in attesa di essere acquisiti, e fornendo la giusta quantità di risorse necessarie (fino a un limite specificato dall'utente). Inoltre, l'Autoscaling Migliorato spegnerà in modo grazioso i cluster quando l'utilizzo è basso, garantendo l'evacuazione di tutti i task per evitare di influire sulla pipeline. Di conseguenza, i carichi di lavoro che utilizzano l'Autoscaling Migliorato risparmiano sui costi perché vengono utilizzate meno risorse infrastrutturali. Scopri di più.
Aggiornamento automatico e Canali di Rilascio. I cluster Delta Live Tables (DLT) utilizzano un runtime DLT basato su Databricks runtime (DBR). Databricks aggiorna automaticamente il runtime DLT circa ogni 1-2 mesi. DLT aggiornerà automaticamente il runtime DLT senza richiedere l'intervento dell'utente finale e monitorerà lo stato della pipeline dopo l'aggiornamento. Se DLT rileva che la Pipeline DLT non può avviarsi a causa di un aggiornamento del runtime DLT, ripristineremo la pipeline alla versione precedente nota e funzionante. È possibile ricevere avvisi anticipati su modifiche che interrompono gli script di inizializzazione o altri comportamenti DBR sfruttando i canali DLT per testare la versione di anteprima del runtime DLT ed essere notificati automaticamente in caso di regressione. Databricks consiglia di utilizzare il canale CURRENT per i carichi di lavoro di produzione. Scopri di più.
Annuncio di Enzyme, un nuovo livello di ottimizzazione progettato specificamente per accelerare il processo di esecuzione dell'ETL
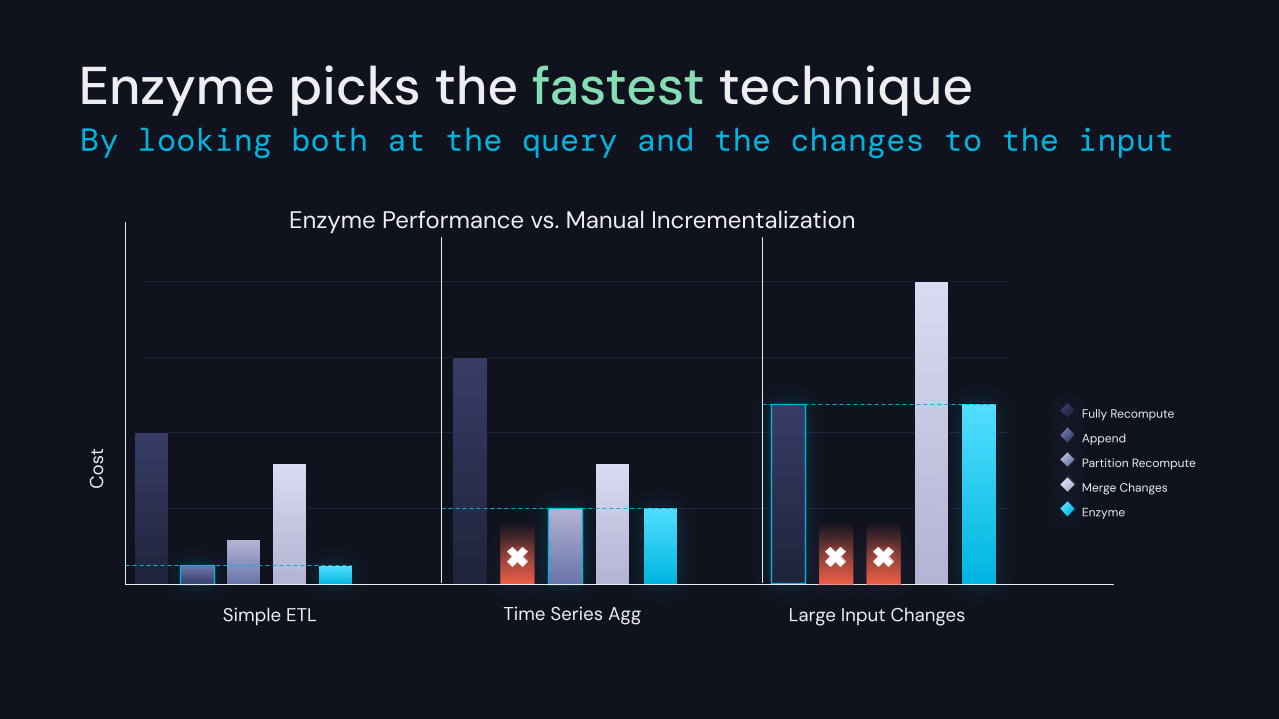
La trasformazione dei dati per prepararli all'analisi downstream è un prerequisito per la maggior parte degli altri carichi di lavoro sulla piattaforma Databricks. Mentre SQL e DataFrames rendono relativamente facile per gli utenti esprimere le proprie trasformazioni, i dati di input cambiano costantemente. Ciò richiede la ricompilazione delle tabelle prodotte dall'ETL. Ricompilare i risultati da zero è semplice, ma spesso proibitivo in termini di costi alla scala su cui operano molti dei nostri clienti.
Siamo lieti di annunciare che stiamo sviluppando il progetto Enzyme, un nuovo livello di ottimizzazione per l'ETL. Enzyme mantiene efficientemente aggiornata una materializzazione dei risultati di una data query archiviata in una tabella Delta. Utilizza un modello di costo per scegliere tra varie tecniche, comprese le tecniche utilizzate nelle viste materializzate tradizionali, lo streaming delta-to-delta e i pattern ETL manuali comunemente utilizzati dai nostri clienti.
Inizia con Delta Live Tables sul Lakehouse
Guarda la demo qui sotto per scoprire la facilità d'uso di DLT sia per i data engineer che per gli analisti:
Se sei un cliente Databricks, segui semplicemente la guida per iniziare. Leggi le note di rilascio per saperne di più su cosa è incluso in questo rilascio GA. Se non sei un cliente Databricks esistente, iscriviti per una prova gratuita e puoi visualizzare i nostri dettagli sui prezzi DLT qui.
Unisciti alla conversazione nella Databricks Community dove i colleghi appassionati di dati stanno chiacchierando degli annunci e degli aggiornamenti del Data + AI Summit 2022. Impara. Fai rete. Festeggia.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.