Annuncio della disponibilità generale di Databricks Lakeflow
L'approccio unificato all'ingegneria dei dati attraverso ingestion, trasformazione e orchestrazione
- Databricks Lakeflow risolve le sfide di ingegneria dei dati poste da stack frammentati offrendo una soluzione unificata per l'ingestion, la trasformazione e l'orchestrazione sulla piattaforma di intelligenza dei dati.
- Lakeflow Connect aggiunge più connettori a database, origini file, applicazioni enterprise e data warehouse. Zerobus introduce scritture dirette ad alta produttività con bassa latenza.
- Lakeflow Declarative Pipelines, basato sul nuovo standard open Spark Declarative Pipelines, offre un nuovo IDE per data engineer per un migliore sviluppo di pipeline ETL.
Siamo entusiasti di annunciare che Lakeflow, la soluzione unificata di data engineering di Databricks, è ora disponibile in versione Generale. Include connettori di ingestione ampliati per origini dati popolari, una nuova “IDE per il data engineering” che semplifica la creazione e il debug di pipeline di dati, e funzionalità ampliate per l'operazionalizzazione e il monitoraggio dell'ETL.
Al Data + AI Summit dell'anno scorso, abbiamo introdotto Lakeflow – la nostra visione per il futuro del data engineering – una soluzione end-to-end che include tre componenti principali:
- Lakeflow Connect: Ingestione affidabile e gestita da applicazioni aziendali, database, file system e stream in tempo reale, senza l'overhead di connettori personalizzati o servizi esterni.
- Lakeflow Declarative Pipelines: Pipeline ETL scalabili basate sullo standard aperto Spark Declarative Pipelines, integrate con governance e osservabilità, e che offrono un'esperienza di sviluppo semplificata attraverso una moderna “IDE per il data engineering”.
- Lakeflow Jobs: Orchestrazione nativa per la Data Intelligence Platform, che supporta flussi di controllo avanzati, trigger di dati in tempo reale e monitoraggio completo.
Unificando il data engineering, Lakeflow elimina la complessità e i costi dell'assemblaggio di strumenti diversi, consentendo ai team di dati di concentrarsi sulla creazione di valore per il business. Lakeflow Designer, il nuovo generatore visuale di pipeline basato sull'IA, consente a qualsiasi utente di creare pipeline di dati di livello production senza scrivere codice.
È stato un anno intenso e siamo entusiasti di condividere le novità con il raggiungimento della disponibilità generale di Lakeflow.
I team di data engineering faticano a tenere il passo con le esigenze di dati della loro organizzazione
In ogni settore, la capacità di un'azienda di estrarre valore dai propri dati attraverso analytics e AI è il suo vantaggio competitivo. I dati vengono utilizzati in ogni aspetto dell'organizzazione: per creare viste Customer 360° e nuove esperienze cliente, per abilitare nuovi flussi di entrate, per ottimizzare le operazioni e per potenziare i dipendenti. Mentre le organizzazioni cercano di utilizzare i propri dati, si ritrovano con un insieme frammentato di strumenti. I data engineer trovano difficile affrontare la complessità delle attività di data engineering mentre navigano in stack di strumenti frammentati che sono dolorosi da integrare e costosi da mantenere.
Una sfida chiave è la governance dei dati: gli strumenti frammentati rendono difficile l'applicazione degli standard, portando a lacune nella discovery, nella lineage e nell'osservabilità. Un recente studio di The Economist ha rilevato che “metà dei data engineer afferma che la governance richiede più tempo di qualsiasi altra cosa”. La stessa indagine ha chiesto ai data engineer quali sarebbero i maggiori benefici per la loro produttività, e hanno identificato “‘semplificare le connessioni alle origini dati per l'ingestione dei dati’, ‘utilizzare una singola soluzione unificata invece di più strumenti’ e ‘una migliore visibilità sulle pipeline di dati per trovare e risolvere i problemi’ tra gli interventi principali”.
Una soluzione unificata di data engineering integrata nella Data Intelligence Platform
Lakeflow aiuta i team di dati ad affrontare queste sfide fornendo una soluzione end-to-end di data engineering sulla Data Intelligence Platform. I clienti Databricks possono utilizzare Lakeflow per ogni aspetto del data engineering: ingestione, trasformazione e orchestrazione. Poiché tutte queste funzionalità sono disponibili come parte di un'unica soluzione, non c'è tempo perso in complesse integrazioni di strumenti o costi aggiuntivi per licenziare strumenti esterni.
Inoltre, Lakeflow è integrato nella Data Intelligence Platform e con ciò arrivano modi coerenti per distribuire, governare e osservare tutti i casi d'uso di dati e AI. Ad esempio, per la governance, Lakeflow si integra con Unity Catalog, la soluzione di governance unificata per la Data Intelligence Platform. Attraverso Unity Catalog, i data engineer ottengono piena visibilità e controllo su ogni parte della pipeline di dati, consentendo loro di comprendere facilmente dove vengono utilizzati i dati e di individuare le cause dei problemi non appena si presentano.
Che si tratti di versionare il codice, distribuire pipeline CI/CD, proteggere i dati o osservare metriche operative in tempo reale, Lakeflow sfrutta la Data Intelligence Platform per fornire un luogo unico e coerente per gestire le esigenze end-to-end del data engineering.
Lakeflow Connect: Più connettori e scritture dirette veloci su Unity Catalog
Nell'ultimo anno, abbiamo visto una forte adozione di Lakeflow Connect con oltre 2.000 clienti che utilizzano i nostri connettori di ingestione per sbloccare il valore dei loro dati. Un esempio è Porsche Holding Salzburg che sta già vedendo i vantaggi dell'utilizzo di Lakeflow Connect per unificare i propri dati CRM con l'analytics per migliorare l'esperienza del cliente.
“Utilizzare il connettore Salesforce di Lakeflow Connect ci aiuta a colmare un divario critico per Porsche dal punto di vista del business per quanto riguarda la facilità d'uso e il prezzo. Dal lato del cliente, siamo in grado di creare un'esperienza cliente completamente nuova che rafforza il legame tra Porsche e il cliente con un percorso cliente unificato e non frammentato.” —Lucas Salzburger, Project Manager, Porsche Holding Salzburg
Oggi, stiamo ampliando la gamma di origini dati supportate con più connettori integrati per un'ingestione semplice e affidabile. I connettori di Lakeflow sono ottimizzati per un'estrazione dati efficiente, incluso l'utilizzo di metodi di change data capture (CDC) personalizzati per ciascuna rispettiva origine dati.
Questi connettori gestiti ora coprono applicazioni aziendali, origini file, database e data warehouse, con rilascio in vari stati di rilascio:
- Applicazioni aziendali: Salesforce, Workday, ServiceNow, Google Analytics, Microsoft Dynamics 365, Oracle NetSuite
- Origini file: SFTP, SharePoint
- Database: Microsoft SQL Server, Oracle Database, MySQL, PostgreSQL
- Data warehouse: Snowflake, Amazon Redshift, Google BigQuery
Inoltre, un caso d'uso comune che vediamo dai clienti è l'ingestione di dati di eventi in tempo reale, tipicamente con infrastrutture di message bus ospitate al di fuori della loro piattaforma dati. Per semplificare questo caso d'uso su Databricks, stiamo annunciando Zerobus, un'API di Lakeflow Connect che consente agli sviluppatori di scrivere dati di eventi direttamente nel loro lakehouse ad altissima velocità (100 MB/s) con latenza quasi in tempo reale (<5 secondi). Questa infrastruttura di ingestione semplificata offre prestazioni su larga scala ed è unificata con la Databricks Platform, in modo da poter sfruttare immediatamente strumenti di analytics e AI più ampi.
“Joby è in grado di utilizzare i nostri agenti di produzione con Zerobus per inviare gigabyte di dati di telemetria al minuto direttamente al nostro lakehouse, accelerando il tempo per ottenere insight, il tutto con Databricks Lakeflow e la Data Intelligence Platform.” —Dominik Müller, Factory Systems Lead, Joby Aviation Inc.
Lakeflow Declarative Pipelines: Sviluppo ETL accelerato basato su standard aperti
Dopo anni di gestione ed evoluzione di DLT con migliaia di clienti su petabyte di dati, abbiamo preso tutto ciò che abbiamo imparato e creato un nuovo standard aperto: Spark Declarative Pipelines. Questa è la prossima evoluzione nello sviluppo di pipeline: dichiarativa, scalabile e aperta.
E oggi, siamo entusiasti di annunciare la disponibilità generale di Lakeflow Declarative Pipelines, portando la potenza di Spark Declarative Pipelines sulla Databricks Data Intelligence Platform. È compatibile al 100% con lo standard aperto, quindi puoi sviluppare pipeline una volta e eseguirle ovunque. È anche retrocompatibile al 100% con le pipeline DLT, quindi gli utenti esistenti possono adottare le nuove funzionalità senza riscrivere nulla. Lakeflow Declarative Pipelines sono un'esperienza completamente gestita su Databricks: compute serverless senza interventi manuali, integrazione profonda con Unity Catalog per la governance unificata e un'IDE per Data Engineering appositamente creata.
La nuova IDE per Data Engineering è un ambiente moderno e integrato costruito per semplificare l'esperienza di sviluppo delle pipeline. Include:
- Codice e DAG affiancati, con visualizzazione delle dipendenze e anteprime istantanee dei dati
- Debug contestuale che segnala i problemi inline
- Integrazione Git integrata per uno sviluppo rapido
- Creazione e configurazione assistite dall'IA
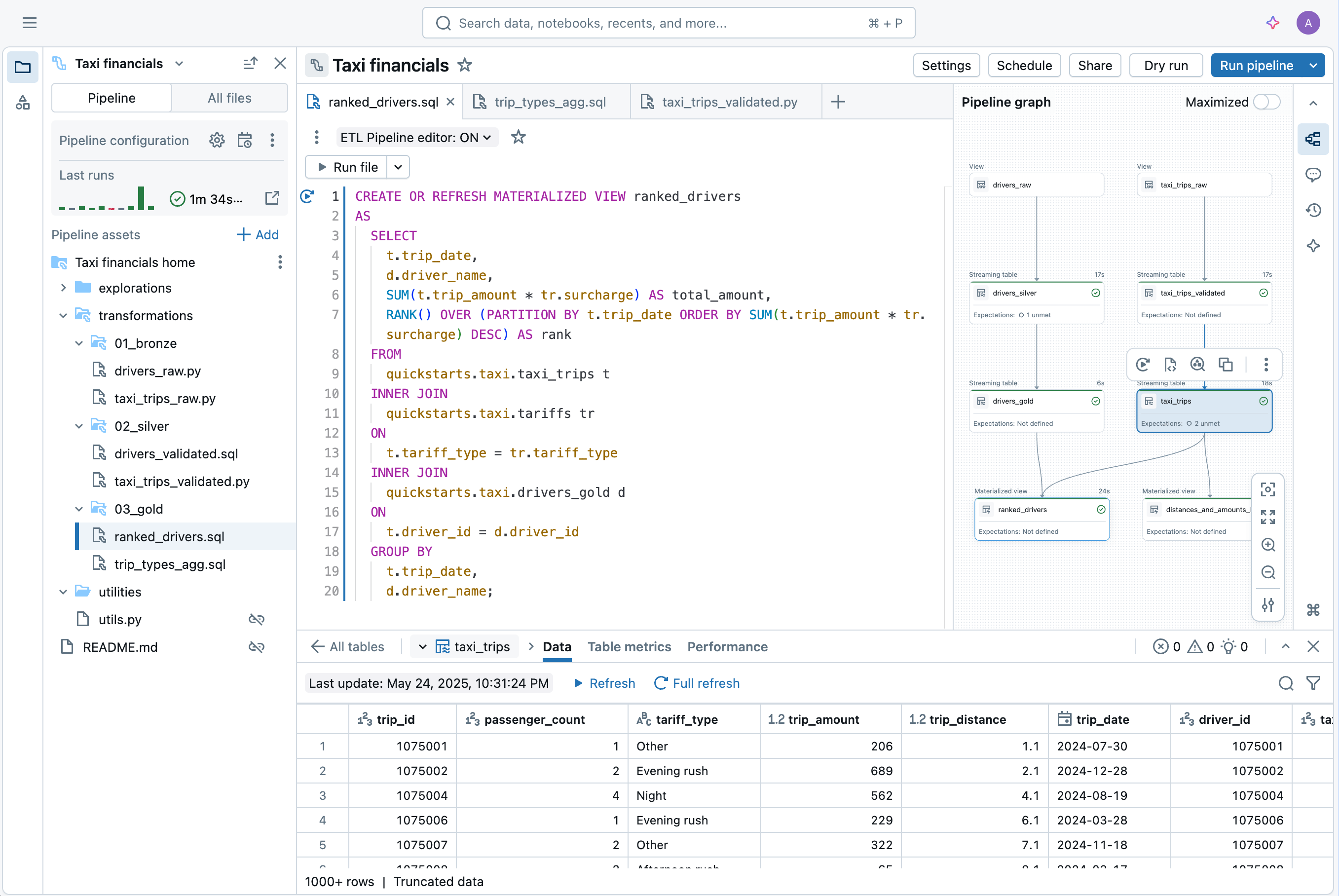
“Il nuovo editor riunisce tutto in un unico posto: codice, grafico della pipeline, risultati, configurazione e risoluzione dei problemi. Niente più salti tra schede del browser o perdita di contesto. Lo sviluppo risulta più mirato ed efficiente. Posso vedere direttamente l'impatto di ogni modifica al codice. Un clic mi porta alla riga di errore esatta, il che rende il debug più veloce. Tutto è collegato: codice ai dati; codice alle tabelle; tabelle al codice. Passare da una pipeline all'altra è facile, e funzionalità come le cartelle di utilità auto-configurate eliminano la complessità. Questo è il modo in cui dovrebbe funzionare lo sviluppo delle pipeline.” —Chris Sharratt, Data Engineer, Rolls-Royce
Le pipeline dichiarative di Lakeflow sono ora il modo unificato per creare pipeline scalabili, governate e continuamente ottimizzate su Databricks, sia che tu stia lavorando con il codice o visivamente tramite il Lakeflow Designer, una nuova esperienza no-code che consente ai professionisti dei dati di qualsiasi livello tecnico di creare pipeline di dati affidabili.
Lakeflow Jobs: Orchestrazione affidabile per tutti i carichi di lavoro con osservabilità unificata
Databricks Workflows è da tempo considerato affidabile per orchestrare flussi di lavoro mission-critical, con migliaia di clienti che si affidano alla nostra piattaforma per pipeline che eseguono oltre 110 milioni di job ogni settimana. Con il GA di Lakeflow, stiamo evolvendo Workflows in Lakeflow Jobs, unificando questo orchestratore nativo maturo con il resto dello stack di data engineering.
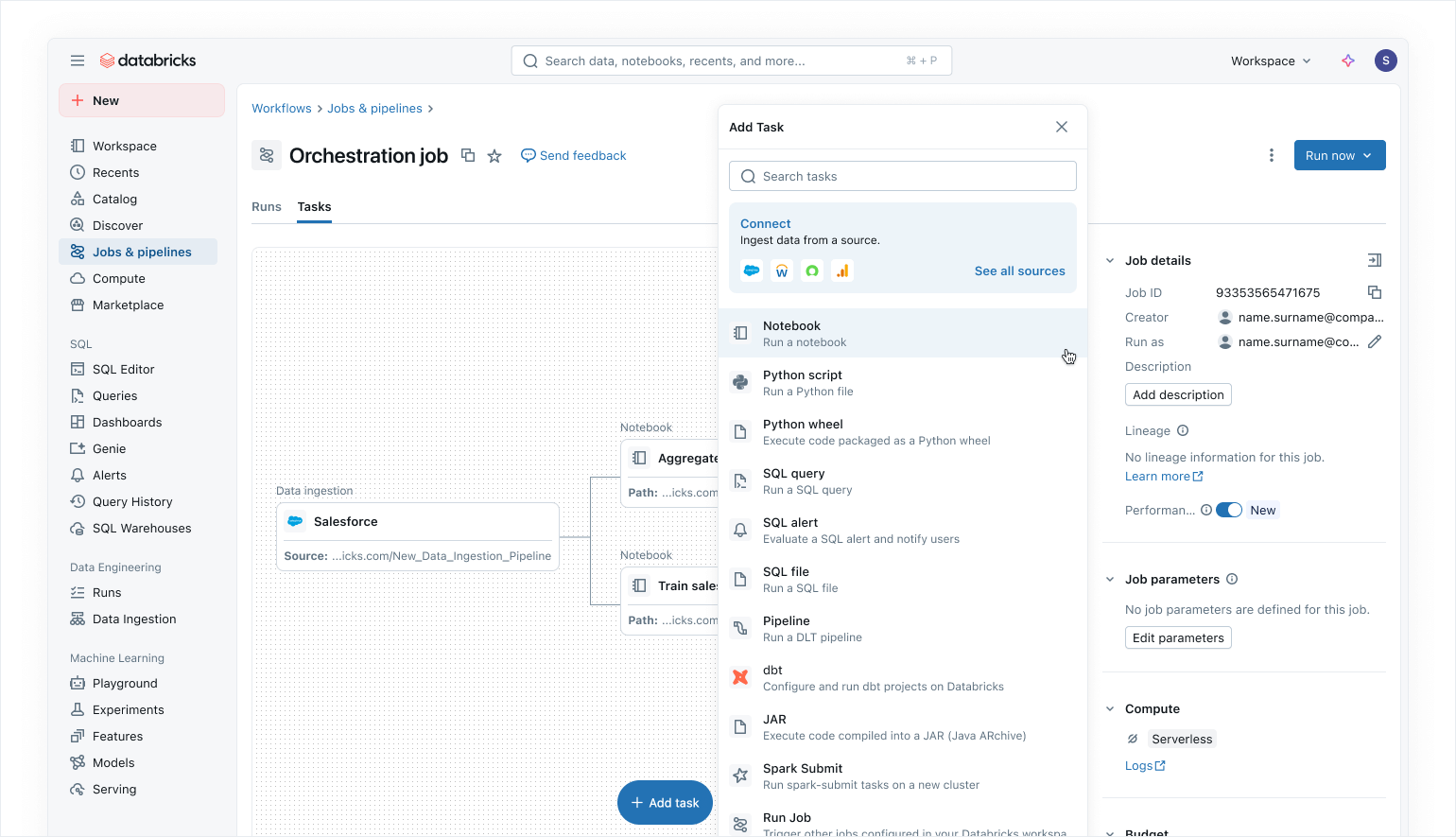
Lakeflow Jobs ti consente di orchestrare qualsiasi processo sulla Piattaforma Dati Intelligente con un set crescente di funzionalità, tra cui:
- Supporto per una raccolta completa di tipi di task per orchestrare flussi che includono pipeline dichiarative, notebook, query SQL, trasformazioni dbt e persino la pubblicazione di dashboard AI/BI o su Power BI.
- Funzionalità di controllo del flusso come esecuzione condizionale, cicli e impostazione dei parametri a livello di task o di job.
- Trigger per l'esecuzione dei job oltre la semplice pianificazione, con trigger di arrivo di file e i nuovi trigger di aggiornamento delle tabelle, che assicurano che i job vengano eseguiti solo quando sono disponibili nuovi dati.
- Job serverless che fornisce ottimizzazioni automatiche per migliori prestazioni e costi inferiori.
“Con i job serverless di Lakeflow, abbiamo ottenuto un miglioramento della latenza da 3 a 5 volte. Quello che prima richiedeva 10 minuti ora richiede solo 2-3 minuti, riducendo significativamente i tempi di elaborazione. Questo ci ha permesso di fornire cicli di feedback più rapidi per giocatori e allenatori, garantendo che ottengano le informazioni di cui hanno bisogno quasi in tempo reale per prendere decisioni attuabili.” —Bryce Dugar, Data Engineering Manager, Cincinnati Reds
Come parte dell'unificazione di Lakeflow, Lakeflow Jobs porta l'osservabilità end-to-end in ogni livello del ciclo di vita dei dati, dall'ingestione dei dati alla trasformazione e all'orchestrazione complessa. Un set di strumenti diversificato si adatta a ogni esigenza di monitoraggio: strumenti di monitoraggio visivo forniscono ricerca, stato e tracciamento a colpo d'occhio, strumenti di debug come i profili delle query aiutano a ottimizzare le prestazioni, avvisi e tabelle di sistema aiutano a far emergere i problemi e offrono insight storici e le aspettative sulla qualità dei dati applicano regole e garantiscono standard elevati per le tue esigenze di pipeline dati.
Inizia con Lakeflow
Lakeflow Connect, Lakeflow Declarative Pipelines e Lakeflow Jobs sono tutti Generalmente Disponibili per ogni cliente Databricks oggi. Scopri di più su Lakeflow qui e visita la documentazione ufficiale per iniziare con Lakeflow per il tuo prossimo progetto di data engineering.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.