Esegui il deploy di LLM privati utilizzando Databricks Model Serving
di Ahmed Bilal, Ankit Mathur, Kasey Uhlenhuth e Joshua Hartman
Siamo lieti di annunciare l'anteprima pubblica del supporto per l'ottimizzazione di GPU e LLM per Databricks Model Serving! Con questo lancio, è possibile distribuire modelli di IA open-source o personalizzati di qualsiasi tipo, inclusi LLM e modelli di visione, sulla piattaforma lakehouse. Databricks Model Serving ottimizza automaticamente il tuo modello per il serving di LLM, offrendo le migliori prestazioni della categoria senza alcuna configurazione.
Databricks Model Serving è il primo prodotto di serving GPU serverless sviluppato su una piattaforma unificata di dati e AI. Ciò consente di creare e implementare applicazioni di GenAI, dall'ingestion dei dati e dal fine-tuning fino al deployment e al monitoraggio del modello, tutto su un'unica piattaforma.
Sviluppa app di AI generativa con Databricks Model Serving
“Con Databricks Model Serving, siamo in grado di integrare l'AI generativa nei nostri processi per migliorare l'esperienza del cliente e aumentare l'efficienza operativa. Model Serving ci consente di implementare modelli LLM mantenendo il pieno controllo sui nostri dati e modelli.” —Ben Dias, Director of Data Science e analitiche di easyJet - Scopri di più
Ospita modelli di IA in modo sicuro senza doverti preoccupare della gestione dell'infrastruttura
Databricks Model Serving fornisce una soluzione unica per distribuire qualsiasi modello di IA senza la necessità di comprendere infrastrutture complesse. Questo significa che è possibile implementare qualsiasi modello di linguaggio naturale, visione, audio, tabellare o personalizzato, indipendentemente da come è stato addestrato, che sia stato creato da zero, derivato da open source o sottoposto a fine-tuning con dati proprietari. Logga semplicemente il tuo modello con MLflow e noi prepareremo automaticamente un container pronto per la produzione con librerie GPU come CUDA e lo distribuiremo su GPU serverless. Il nostro servizio completamente gestito si occuperà di tutto il lavoro pesante al posto tuo, eliminando la necessità di gestire le istanze, mantenere la compatibilità delle versioni e applicare patch alle versioni. Il servizio scalerà automaticamente le istanze per soddisfare i modelli di traffico, consentendo di risparmiare sui costi dell'infrastruttura e ottimizzando al contempo le prestazioni di latenza.
“Databricks Model Serving sta accelerando la nostra capacità di infondere intelligenza in un'ampia gamma di casi d'uso, dalle applicazioni di ricerca semantica alle previsioni sui trend nei media. Astraendo e semplificando i meccanismi intricati del dimensionamento di CUDA e server GPU, Databricks ci permette di concentrarci sui nostri ambiti di competenza, estendendo l'uso dell'AI in Condé Nast a tutte le nostre applicazioni senza il fastidio e il fardello dell'infrastruttura."
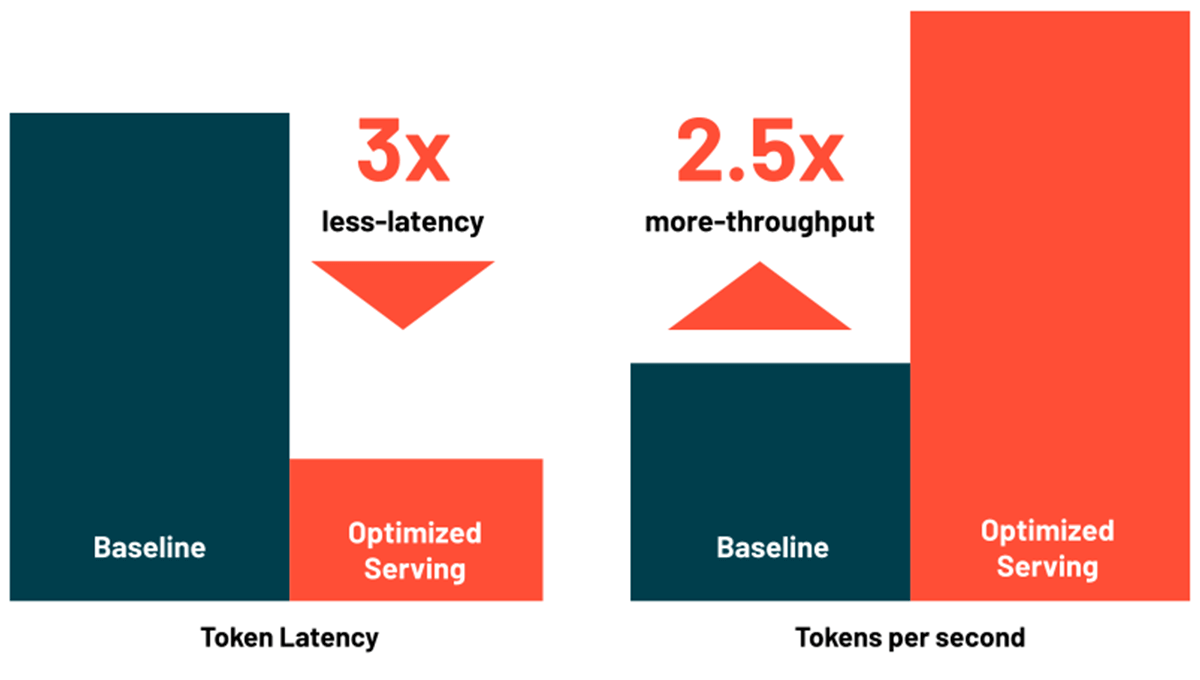
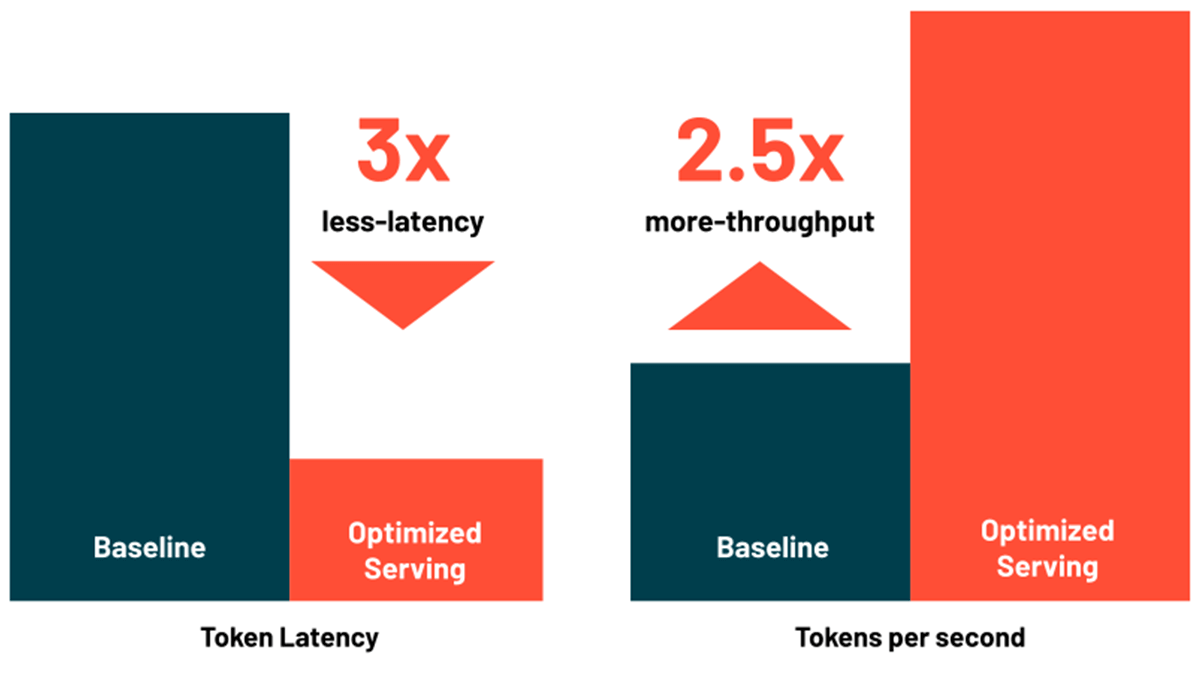
Riduci la latenza e i costi con il serving ottimizzato degli LLM
Databricks Model Serving ora include ottimizzazioni per il serving efficiente di modelli linguistici di grandi dimensioni, riducendo la latenza e i costi fino a 3-5 volte. Utilizzare Optimized LLM Serving è incredibilmente facile: basta fornire il modello insieme ai suoi pesi OSS o sottoposti a fine-tuning e al resto pensiamo noi per garantire che il serving del modello avvenga con prestazioni ottimizzate. Ciò consente di concentrarsi sull'integrazione dell'LLM nella propria applicazione invece di scrivere librerie di basso livello per le ottimizzazioni del modello. Databricks Model Serving ottimizza automaticamente i modelli della classe MPT e Llama2 e il supporto per altri modelli sarà presto disponibile.
{kind=link}
Accelera i deployment tramite le integrazioni con Lakehouse AI
Quando si mettono in produzione gli LLM, non si tratta solo di eseguire il deploy dei modelli. È inoltre necessario integrare il modello utilizzando tecniche come la generazione aumentata dal recupero (RAG), il fine-tuning efficiente dei parametri (PEFT) o il fine-tuning standard. Inoltre, è necessario valutare la qualità dell'LLM e monitorare continuamente il modello per verificarne le prestazioni e la sicurezza. Ciò comporta spesso che i team impieghino molto tempo a integrare strumenti eterogenei, il che aumenta la complessità operativa e crea un overhead di manutenzione.
Databricks Model Serving è basato su una piattaforma unificata di dati e AI che consente di gestire l'intero ciclo LLMOps, dall'ingestion dei dati e dal fine-tuning fino al deployment e al monitoraggio, tutto su un'unica piattaforma, creando una visione coerente dell'intero ciclo di vita dell'AI che accelera il deployment e riduce al minimo gli errori. Model Serving si integra con vari servizi LLM all'interno della Lakehouse, tra cui:
- Fine-tuning: migliora la precisione e differenziati effettuando il fine-tuning dei modelli fondazionali con i tuoi dati proprietari direttamente su Lakehouse.
- Integrazione della ricerca vettoriale: integra ed esegui la ricerca vettoriale in modo fluido per casi d'uso di generazione aumentata da recupero e ricerca semantica. Iscriviti per l'anteprima qui.
- Gestione LLM integrata: integrazione con Databricks AI Gateway come livello API centrale per tutte le chiamate LLM.
- MLflow: Valuta, confronta e gestisci gli LLM tramite PromptLab di MLflow.
- Qualità e diagnostica: acquisisci automaticamente richieste e risposte in una tabella Delta per monitorare ed eseguire il debug dei modelli. Puoi anche combinare questi dati con le tue etichette per generare set di dati di addestramento tramite la nostra partnership con Labelbox.
- Governance unificata: gestisci e governa tutti gli asset di dati e AI, inclusi quelli utilizzati e prodotti da Model Serving, con Unity Catalog.
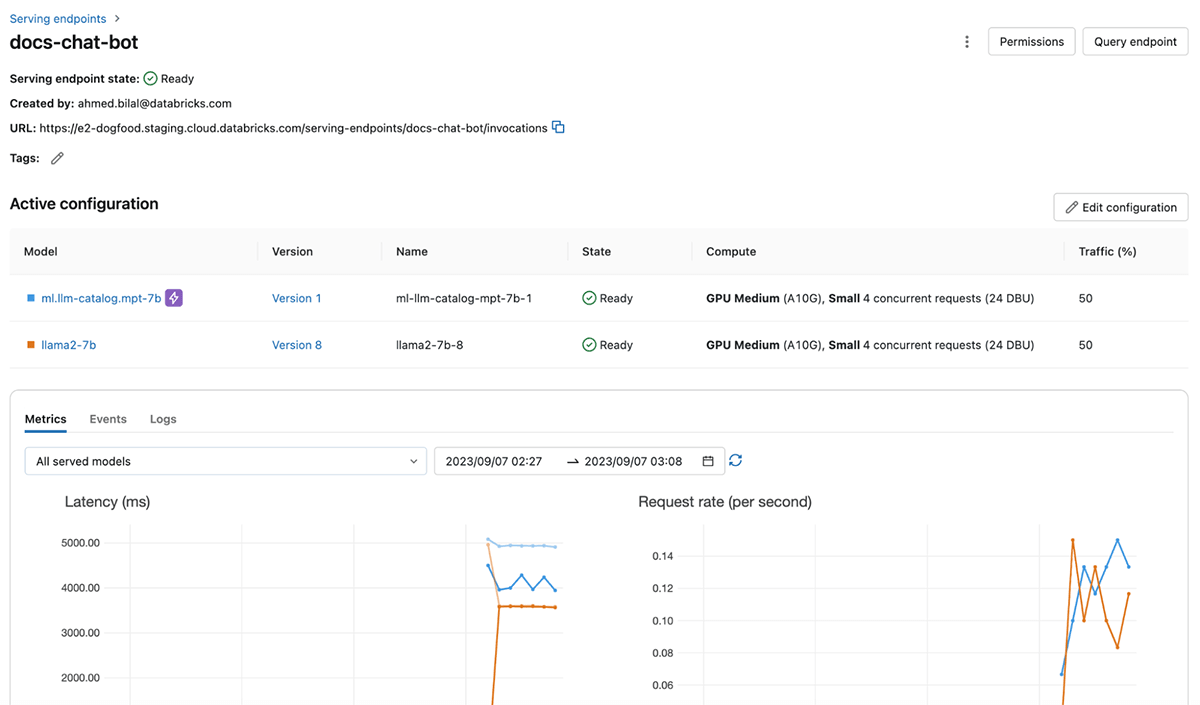
Porta affidabilità e sicurezza al serving degli LLM
Databricks Model Serving fornisce risorse di compute dedicate che consentono l'inferenza su larga scala, con il pieno controllo su dati, modello e configurazione del deployment. Ottenendo una capacità dedicata nella regione cloud prescelta, si beneficia di una bassa latenza di overhead, prestazioni prevedibili e garanzie supportate da SLA. Inoltre, i tuoi workload di serving sono protetti da più livelli di sicurezza, garantendo un ambiente sicuro e affidabile anche per le attività più sensibili. Abbiamo implementato diversi controlli per soddisfare le esigenze di conformità uniche dei settori industriali altamente regolamentati. Per ulteriori dettagli, visita questa pagina o contatta il tuo team account di Databricks.
Guida introduttiva al serving su GPU e di LLM
- Provalo! Esegui il deployment del tuo primo LLM su Databricks Model Serving leggendo il tutorial introduttivo (AWS | Azure).
- Approfondisci la documentazione di Databricks Model Serving.
- Scopri di più sull'approccio di Databricks all'AI generativa qui.
- Percorso di apprendimento per Generative AI Engineer: segui corsi personalizzati, on-demand e con istruttore sull'AI generativa
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.