Costruzione di ricerche di prodotti in tempo reale su Databricks
di Jiayi Wu, Luke Lefebure e Adam Gurary
- Come creare un sistema di ricerca prodotti in tempo reale su Databricks, coprendo i componenti di ingestione, recupero e ranking necessari per alimentare esperienze di ricerca moderne.
- Un'architettura di riferimento che utilizza Databricks AI Search, Lakeflow e Lakebase per elaborare i dati dei prodotti, recuperare risultati pertinenti e incorporare segnali operativi in tempo reale come prezzi, inventario e preferenze utente.
- Best practice e metriche per gestire la ricerca su larga scala, inclusa la valutazione della qualità del recupero, il monitoraggio della latenza e come agenti e applicazioni possono basarsi sui sistemi di ricerca.
Immagina di progettare un sistema di ricerca per un marketplace online che vende auto. In millisecondi, gli utenti si aspettano risultati che rientrino nel loro budget, corrispondano alle loro preferenze, siano disponibili nelle vicinanze e sembrino pertinenti.
Questo è ciò che la moderna ricerca di prodotti sul web comporta. Non è solo uno strumento di ricerca, ma un motore decisionale in tempo reale che deve recuperare, filtrare, classificare e rispondere quasi istantaneamente, il tutto bilanciando metriche di business e tecniche come ricavi, tasso di click, latenza e pertinenza.
Databricks fornisce la piattaforma end-to-end per la creazione di questi sistemi, dall'ingestione scalabile dei dati (Lakeflow) al recupero basato su vettori (AI Search) ai dati operativi in tempo reale (Lakebase) alle esperienze di ricerca basate su agenti (Agent Bricks). Questo blog illustra come questi componenti si uniscono per alimentare la ricerca di prodotti in tempo reale.
Componenti per la ricerca di prodotti
La ricerca di prodotti non riguarda semplicemente la risposta a una domanda o la presentazione di informazioni tramite un chatbot. È un processo di scoperta e decisione, dinamico, personalizzato e strettamente legato ai ricavi. Gli acquirenti si aspettano di sfogliare, confrontare ed esplorare. L'obiettivo non è generare una singola risposta, ma presentare un insieme classificato di scelte che sembrino pertinenti, affidabili e degne di considerazione.
Un sistema di ricerca di prodotti in tempo reale ha generalmente 3 segmenti (Figura 1).
- Ingestione prepara i dati del prodotto per la ricerca. Titoli, descrizioni e attributi dei prodotti vengono elaborati, convertiti in embedding, arricchiti con metadati e indicizzati per un recupero rapido.
- Recupero trova ciò che potrebbe essere pertinente generando un set di candidati utilizzando la ricerca full-text, semantica o ibrida combinata con il filtraggio strutturato.
- Raffinamento determina come i risultati devono essere interpretati e ordinati applicando la comprensione della query, la logica di classificazione, la personalizzazione e le regole di business.

{kind=link}
Dietro la barra di ricerca
Nessuna di queste esperienze esiste senza una solida infrastruttura e metriche significative.
- L'infrastruttura rende possibili velocità e pertinenza.
- Le metriche dimostrano che il tuo sistema è effettivamente veloce e pertinente, non solo sulla carta.
La moderna ricerca di prodotti richiede entrambi: le basi ingegneristiche per fornire risultati e la disciplina delle metriche per convalidare continuamente che tali risultati siano sufficientemente buoni.
Analisi dell'architettura
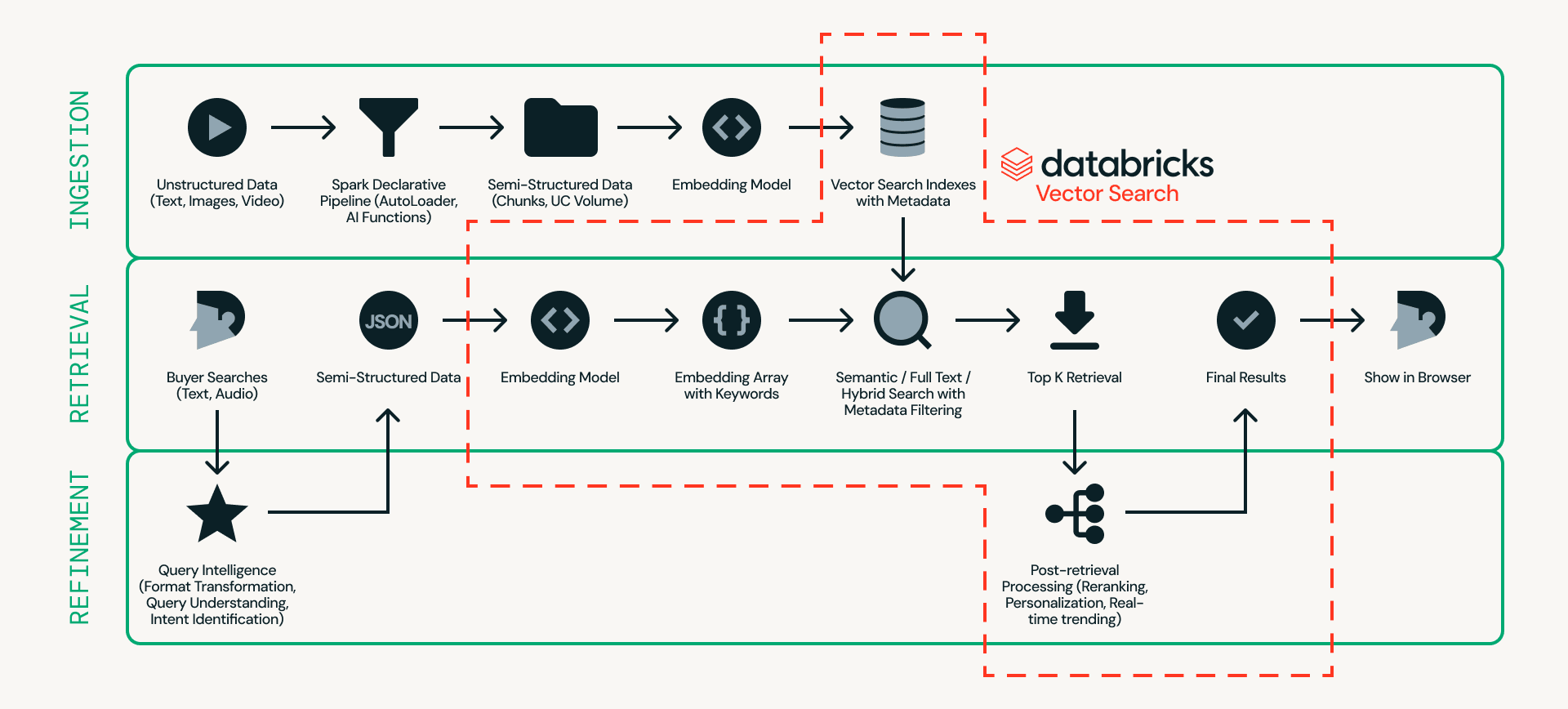
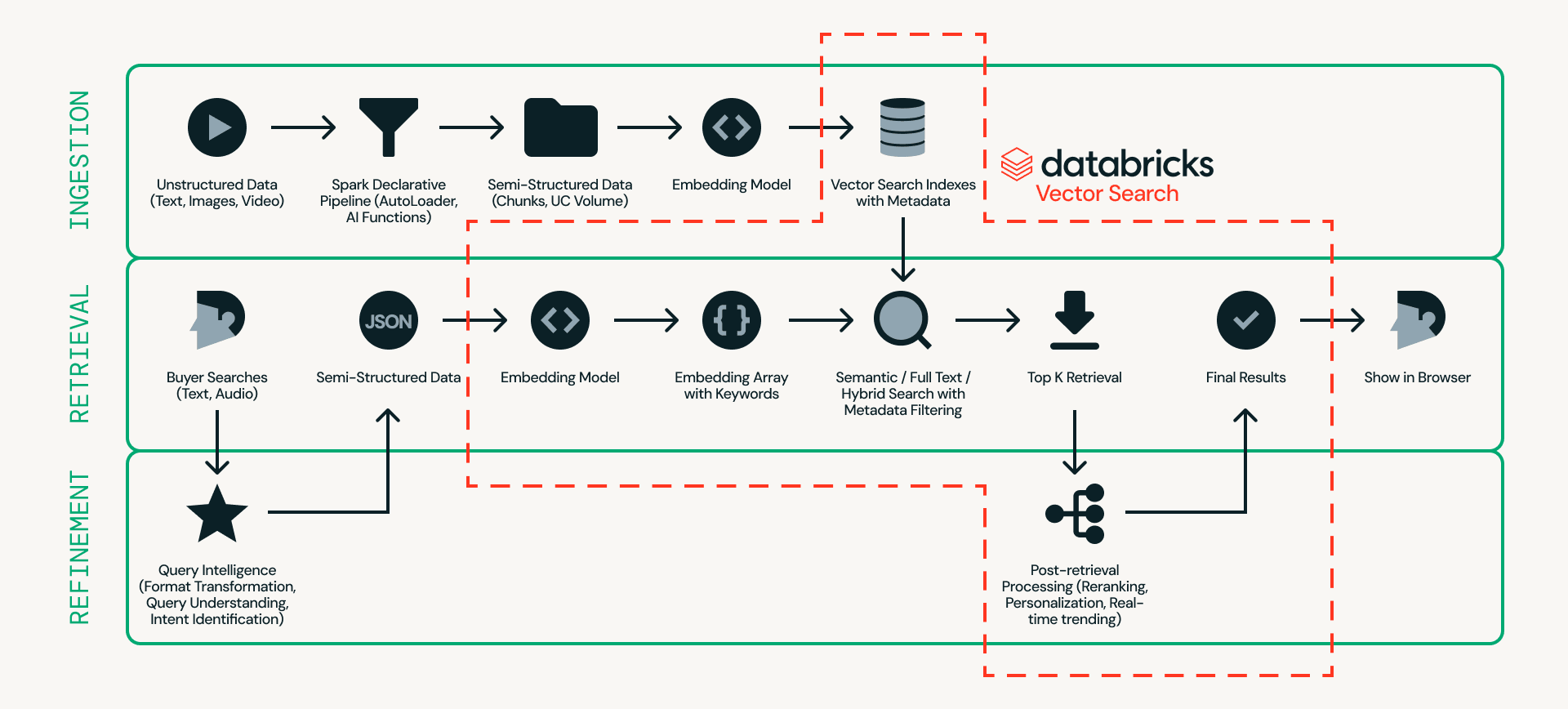
Innanzitutto, diamo un'occhiata all'architettura. La Figura 2 mostra un esempio dettagliato di un'architettura di ricerca di prodotti in tempo reale.
{kind=link}
Al centro di questo design c'è Databricks AI Search, che gestisce ingestione, recupero e raffinamento in un'unica piattaforma, eliminando la necessità di collegare più sistemi esterni.
- Ingestione prepara i dati del prodotto in modo che possano essere cercati in modo efficiente. Fonti non strutturate come elenchi di prodotti e immagini vengono elaborate tramite pipeline scalabili utilizzando Databricks Auto Loader, Lakeflow Spark Declarative Pipeline e AI Functions (ad es. ai_parse_document). I dati possono quindi essere suddivisi in blocchi e convertiti in embedding con metadati (ad es. modello dell'auto, colore o prezzo) in Databricks AI Search.
- Recupero gestisce le query in tempo reale. L'input dell'utente viene trasformato in embedding e filtri strutturati, e Databricks AI Search recupera i primi candidati utilizzando la ricerca semantica, la ricerca full-text o la ricerca ibrida con filtraggio dei metadati.
- Raffinamento migliora i candidati recuperati in risultati finali. Mentre il recupero fornisce una solida base, questo livello affina i risultati interpretando l'intento, applicando la logica di classificazione e incorporando personalizzazione e regole di business quando necessario. Il contesto operativo in tempo reale, come lo stato della sessione, l'inventario, i prezzi e le preferenze dell'utente, può essere servito tramite Lakebase, consentendo segnali a bassa latenza inferiori a 10 ms di influenzare l'ordinamento finale.
Alcune linee guida pratiche quando si costruiscono sistemi di ricerca su Databricks:
- Sperimenta facilmente con i modelli. Scambia gli embedding models con un minimo attrito e sfrutta le capacità native di reranking. Gli aggiornamenti futuri consentiranno il fine-tuning con un clic dei modelli di reranking direttamente all'interno della piattaforma, semplificando l'ottimizzazione della pertinenza.
- Servi lo stato dell'applicazione alla velocità della ricerca. Utilizza Lakebase per archiviare lo stato dell'applicazione in tempo reale — contesto della sessione, inventario, prezzi, preferenze dell'utente — con latenza inferiore a 10 ms. La sincronizzazione CDC gestita aggiorna automaticamente Lakebase a Delta, quindi i modelli di classificazione e le analisi riflettono sempre i dati operativi correnti senza pipeline personalizzate.
- Testa la scalabilità prima della produzione. Valida la latenza e il throughput in condizioni di traffico realistiche, inclusi scenari QPS elevati. Puoi simulare carichi di lavoro di produzione oggi stesso utilizzando il notebook di test di carico per la ricerca, con il supporto nativo per il test di carico con un clic in una versione futura. Per traffico sostenuto, sfrutta gli endpoint QPS elevati per gestire la concorrenza su larga scala e monitora le prestazioni tramite l'osservabilità degli endpoint per tracciare latenza, throughput e stato del sistema.
- Crea ricerche pronte per gli agenti fin dal primo giorno. Ogni indice AI Search con embedding gestiti ottiene automaticamente un server MCP gestito. Usalo per l'integrazione di agenti senza configurazione, il VectorSearchRetrieverTool per il controllo code-first, o punta un Knowledge Assistant al tuo indice per domande e risposte istantanee con citazioni, alimentato da Instructed Retriever, che offre un'accuratezza del 70% superiore rispetto ai sistemi RAG standard.
Metriche che contano
Un sistema di ricerca non ha successo perché ha un aspetto elegante su un diagramma. Ha successo perché fornisce risultati rapidi e pertinenti che guidano i risultati aziendali.
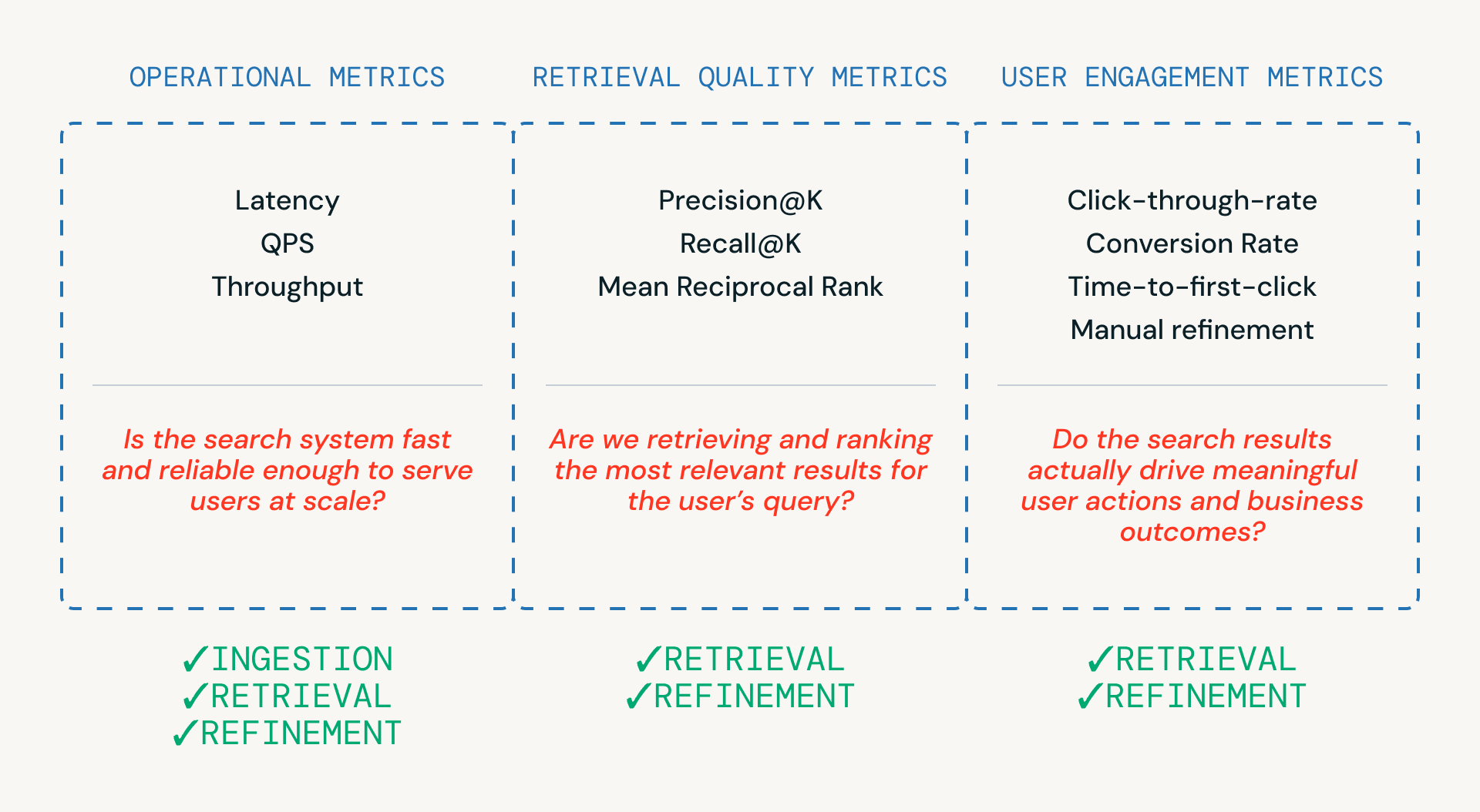
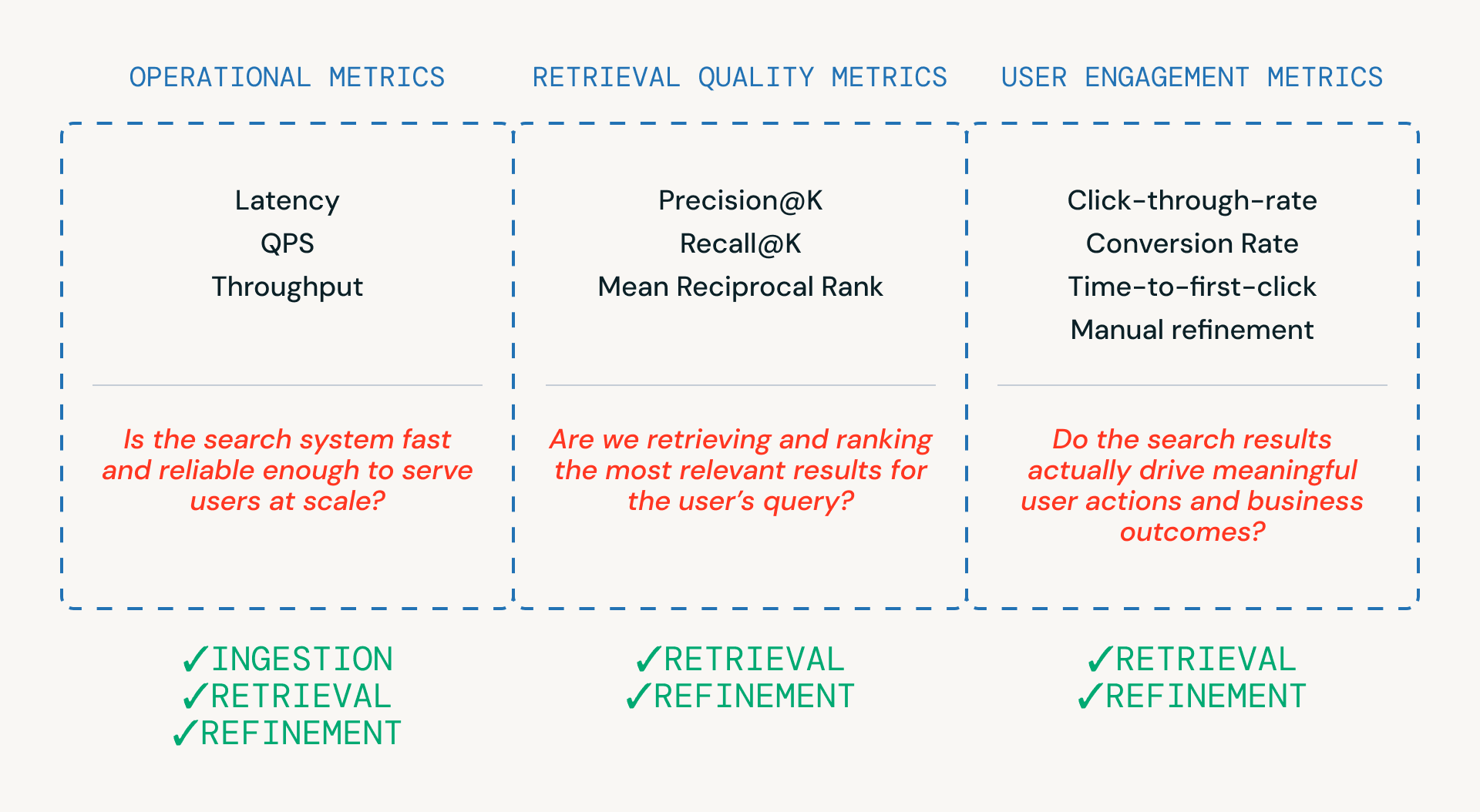
Come mostrato nella Figura 3, tre categorie di metriche aiutano i team a valutare una pipeline di ricerca, ciascuna legata a un diverso livello del sistema.
- Metriche operative garantiscono che il sistema sia abbastanza veloce e affidabile da servire gli utenti su larga scala. Queste sono fondamentali in tutte le fasi di ingestione, recupero e raffinamento.
- Metriche di qualità del recupero misurano se il sistema sta effettivamente recuperando e classificando candidati pertinenti e sono strettamente legate alle fasi di recupero e raffinamento in cui avvengono la classificazione e il reranking.
- Le metriche di coinvolgimento degli utenti catturano il comportamento reale — che gli utenti facciano clic, perfezionino o infine convertano - fornendo feedback che informa i miglioramenti nel recupero e nei perfezionamenti nel tempo.
{kind=link}
Alcune linee guida pratiche quando si valutano i sistemi di ricerca su Databricks:
- Bilancia le metriche, non ottimizzarne solo una. Sistemi di ricerca efficaci devono bilanciare metriche multiple — raramente si vince su tutte le metriche contemporaneamente. Ad esempio, ottimizzare aggressivamente la precisione può aumentare la latenza o nascondere risultati pertinenti, portando infine a clienti frustrati.
- Monitora attentamente la latenza in tempo reale. Suddividi la latenza per fasi della pipeline e traccia la latenza di coda come p95/p99 per identificare rapidamente i colli di bottiglia. Tecniche come la cache possono aiutare a soddisfare rigidi SLA di latenza.
- Traccia le metriche sistematicamente. Usa MLflow per registrare e valutare le metriche di recupero e di coinvolgimento tra gli esperimenti. La valutazione nativa della qualità del recupero arriverà presto su Databricks AI Search, rendendo tutto ancora più facile.
Ricerca in Produzione su Scala — FOX Sports
FOX Sports ha costruito la sua barra di ricerca basata sull'IA su Databricks AI Search, gestendo migliaia di QPS con un miglioramento di 2 volte nel tasso di successo delle query. Lanciata per il Super Bowl LIX, la loro architettura dimostra diversi pattern trattati in questo blog:
- Ingestione in tempo reale. Spark Structured Streaming ingerisce continuamente contenuti negli indici Delta Sync man mano che vengono pubblicati
- Recupero in due fasi. Corrispondenza esatta delle entità per giocatori e squadre, più ricerca semantica ponderata nel tempo per articoli e video, orchestrata da Databricks Model Serving
- Ottimizzazione della produzione. Uno strato di cache e una funzionalità di ricerche di tendenza — che guidano oltre il 25% di tutte le richieste di ricerca — gestiscono picchi di traffico elevati durante gli eventi dal vivo
Dalla Ricerca alle Applicazioni Intelligenti
La ricerca di prodotti non esiste isolatamente — è un livello in uno stack di applicazioni più ampio. Ecco come il resto della piattaforma Databricks estende ciò che puoi costruire su AI Search.
Applicazioni in Tempo Reale con Lakebase
Per applicazioni di ricerca rivolte ai clienti — marketplace, cataloghi di prodotti, piattaforme multimediali — l'indice di ricerca è solo una parte della storia. Le applicazioni necessitano anche di un database transazionale per lo stato operativo: livelli di inventario, prezzi, sessioni utente, preferenze di personalizzazione. Lakebase fornisce questo come database completamente gestito e compatibile con PostgreSQL, nativamente integrato con la piattaforma Databricks. La sincronizzazione bidirezionale gestita con Delta Lake significa che i modelli di ranking vengono addestrati sui dati operativi più recenti e le intuizioni analitiche fluiscono nuovamente nello strato applicativo — tutto governato da Unity Catalog.
Ricerca basata su Agenti con Agent Bricks
Databricks fornisce automaticamente un server MCP gestito per ogni indice AI Search, sbloccando molteplici pattern di integrazione:
- Assistente alla Conoscenza. Una chatbot di domande e risposte sui tuoi documenti. Puntala su un indice AI Search e ottieni ricerche di documenti pronte per la produzione con citazioni. Utilizza Instructed Retriever sotto il cofano — 70% di accuratezza in più rispetto a RAG vanilla e 30% in più rispetto a RAG agentico.
- Agenti personalizzati. Usa il VectorSearchRetrieverTool o MCP con qualsiasi framework (OpenAI Agents SDK, LangGraph, LlamaIndex). Controllo completo sui parametri di recupero, embedding e filtri. Distribuisci come Databricks Apps con tracciamento MLflow.
- Agente Supervisore. Orchestra molteplici sotto-agenti: un Assistente alla Conoscenza per Q&A sui documenti, uno spazio Genie per query su dati strutturati e Funzioni UC per logica di business personalizzata — tutti coordinati da un unico supervisore.
Conclusione
Costruire un moderno sistema di ricerca prodotti richiede più di un indice di ricerca. Richiede un'infrastruttura progettata per gestire scala reale, prestazioni e osservabilità:
- Esecuzione a bassa latenza. La comprensione delle query, il recupero, il filtraggio e il riordino devono essere completati entro rigidi budget di latenza p95/p99.
- Capacità di recupero ibrido. Combina la somiglianza semantica (embedding) con il filtraggio strutturato come prezzo, categoria o disponibilità.
- Scalabilità sotto carico. Sostieni alti QPS e concorrenza durante il traffico di picco senza degradare le prestazioni.
- Osservabilità. Mantieni una chiara visibilità sui breakdown della latenza, sulle prestazioni di ranking e sulla salute generale del sistema.
- Pronto per agenti per impostazione predefinita. Ogni indice AI Search è uno strumento MCP, immediatamente utilizzabile da Knowledge Assistant, agenti personalizzati e Agenti Supervisori.
- Supporto operativo full-stack. Lakebase fornisce il database transazionale per lo stato delle applicazioni in tempo reale, sincronizzato con Delta senza ETL.
Pronto a costruire? Segui la guida alla qualità del recupero per confrontare e ottimizzare la tua pipeline di ricerca, vedi come FOX Sports ha costruito la ricerca basata sull'IA su larga scala e approfondisci la documentazione di AI Search per iniziare.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.