coSTAR: Come distribuiamo agenti AI in Databricks velocemente, senza rompere nulla
Come siamo passati da revisioni manuali di due settimane a test e perfezionamento automatizzati in poche ore
- Noi creiamo e implementiamo agenti in Databricks utilizzando una metodologia completa e automatizzata di test e perfezionamento chiamata coSTAR (coupled Scenario, Trace, Assess, Refine), che abbiamo sviluppato utilizzando MLflow. La metodologia è strutturata attorno a un'analogia con lo sviluppo software tradizionale, utilizzando giudici LLM come suite di test e un assistente di codifica per perfezionare automaticamente l'implementazione dell'agente finché i test non vengono superati.
- Questa metodologia ha eliminato il precedente ciclo di sviluppo lento e manuale "esegui, rivedi, correggi, ripeti", che era soggetto a regressioni e mancava di fiducia. coSTAR ha ridotto il tempo necessario per verificare le modifiche da due settimane a poche ore, consentendo una maggiore velocità di sviluppo.
- Gli stessi test vengono eseguiti in produzione per individuare problemi sul traffico utente effettivo e come parte delle nostre pipeline CI/CD, aiutandoci a segnalare regressioni causate da modifiche nell'infrastruttura dipendente.
Non lasceresti mai che un assistente di codifica rifattorizzi il tuo codebase senza una suite di test. Senza test, l'assistente vola alla cieca. Potrebbe correggere una funzione e romperne silenziosamente altre tre. I test sono ciò che chiude il cerchio: eseguili, osserva i fallimenti, correggi il codice, eseguili di nuovo. Nessun test, nessuna fiducia.
In Databricks sviluppiamo e distribuiamo continuamente agenti che coprono una vasta gamma di funzionalità, dalle nuove funzionalità della piattaforma Databricks (ad esempio, le capacità di data-engineering, analisi delle tracce e machine learning in Genie Code), ai progetti OSS (ad esempio, l'assistente MLflow), ai flussi di lavoro di ingegneria interni (ad esempio, supporto on-call o revisori di codice automatizzati). Questi agenti possono eseguire attività di lunga durata, generare migliaia di righe di codice e creare nuovi asset di dati e AI, tra le altre cose. Sebbene avessimo alcuni controlli di base in atto fin dall'inizio, ci mancava il tipo di suite di test completa e automatizzata che ci avrebbe permesso di iterare con fiducia. Questo post descrive come abbiamo colmato questo divario utilizzando MLflow e la metodologia coSTAR (coupled Scenario, Trace, Assess, Refine) di best practice che abbiamo costruito attorno ad essa. coSTAR esegue due loop accoppiati: uno che allinea i giudici con il giudizio di esperti umani in modo che possano essere fidati, e uno che utilizza quei giudici fidati per affinare automaticamente l'agente fino a quando non supera tutti gli scenari di test.
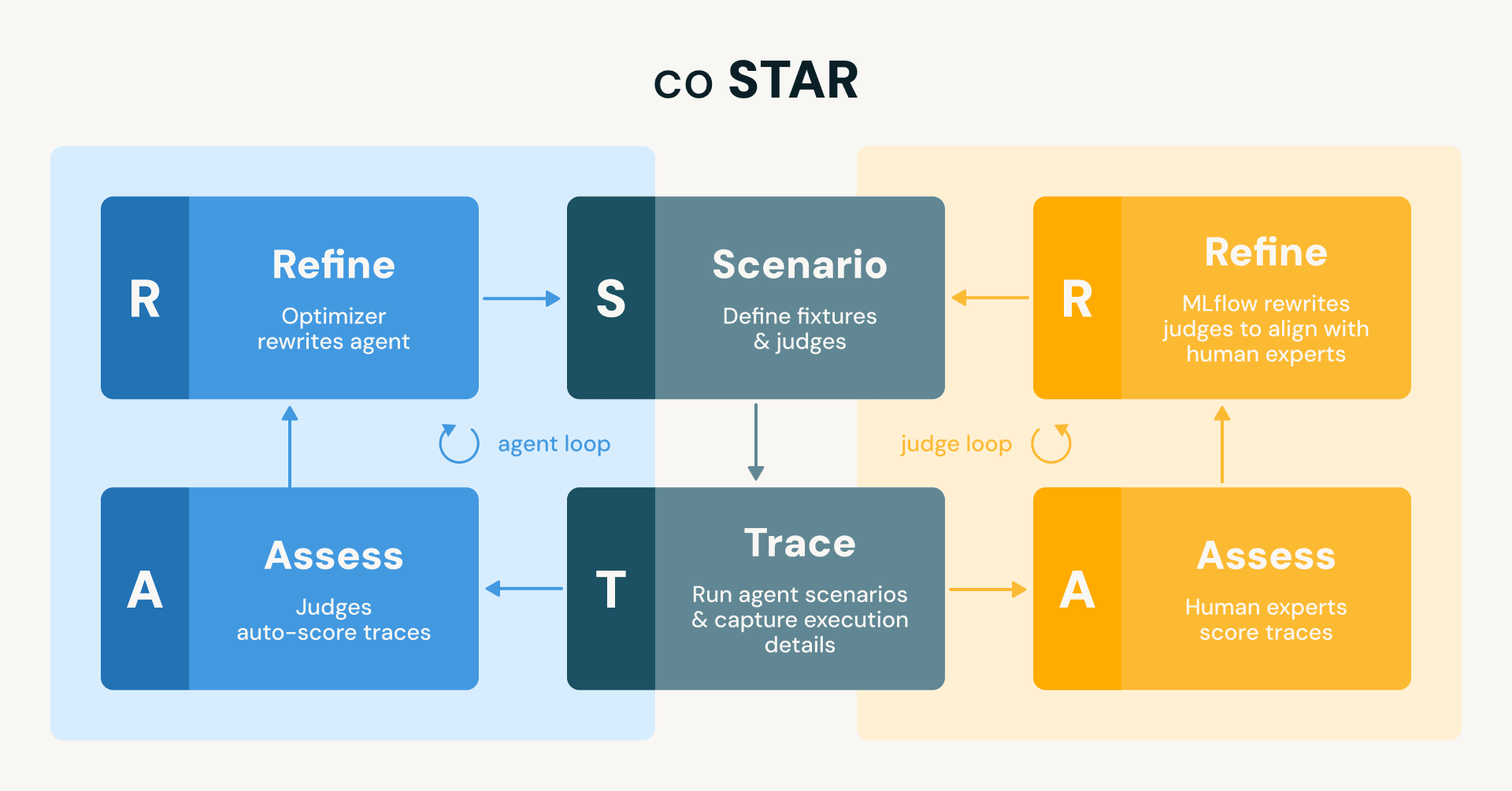
Figura: Il framework coSTAR esegue due loop STAR speculari (Scenario → Trace → Assess → Refine). Il loop dell'agente (blu) utilizza i giudici per valutare automaticamente le tracce e affina l'agente per allinearsi ai giudici. Il loop del giudice (arancione) utilizza esperti umani per valutare le tracce e affina i giudici per allinearli alle loro valutazioni. Entrambi i loop condividono gli stessi scenari e tracce.
Il Problema: Codificare Senza Test
All'inizio, il nostro loop di sviluppo era così: esegui l'agente, rivedi manualmente il suo output, individua un difetto, chiedi a un assistente di codifica di correggerlo. Ripeti.
Se questo ti ricorda la scrittura di codice senza test e il controllo manuale di ogni modifica, è esattamente quello che era. E è fallito esattamente nel modo in cui avresti previsto. La reazione ovvia è "quindi scrivi i test". Ma il testing degli agenti è strutturalmente diverso dal testare una funzione deterministica, e diverse sfide si accumulano contemporaneamente:
- Non determinismo. La stessa implementazione, lo stesso input, può produrre output diversi in esecuzioni diverse. I test devono valutare le proprietà dell'output piuttosto che affermare output esatti.
- Loop di feedback lenti. Una singola esecuzione dell'agente può richiedere decine di minuti. Non c'è iterazione nel modo in cui una suite di test sub-secondaria consente. Ogni ciclo di valutazione è costoso.
- Errori a cascata. Una decisione sbagliata al passaggio 3 causa un fallimento al passaggio 7. Quando il sintomo emerge, la causa principale è sepolta diversi passaggi indietro nell'esecuzione dell'agente.
- Qualità soggettiva. Per molte dimensioni di test (questo codice di feature engineering è buono? questo approccio di pulizia dei dati è appropriato?) non esiste una verità oggettiva. Il giudizio su queste dimensioni dipende dall'esperienza del dominio.
Questi vincoli hanno plasmato ogni decisione di progettazione che segue. Sono anche ciò che rende interessante questo problema: non stiamo solo costruendo un esecutore di test, stiamo costruendo una metodologia di ottimizzazione automatizzata per processi stocastici, di lunga durata e multi-step in cui "corretto" è una questione di giudizio.
L'Analogia Che Guida il Nostro Approccio
Se strizzi gli occhi, lo sviluppo dell'agente si mappa chiaramente sul loop di sviluppo che ogni ingegnere conosce già:
| Software tradizionale | Sviluppo agente |
|---|---|
| Codice sorgente | Implementazione dell'agente (incluse prompt, scelte di FM, strumenti) |
| Suite di test | Giudici LLM |
| Fixture di test (setup, input, output atteso) | Definizioni dello scenario (stato iniziale, prompt, aspettative) |
| Esecutore di test / harness | L'harness di test esegue l'agente sotto test, produce tracce |
| Correttezza del test (i test verificano la cosa giusta?) | Allineamento del giudice (il giudice concorda con gli esperti umani?) |
| L'assistente di codifica corregge il codice finché i test non superano | L'assistente di codifica affina l'implementazione finché i giudici non superano |
| CI esegue tutti i test su ogni modifica | CI esegue scenari + giudici su ogni modifica |
| Monitoraggio della produzione | Gli stessi giudici vengono eseguiti sul traffico live |
Questa analogia non è solo illustrativa. È l'architettura letterale del nostro sistema, che chiamiamo coSTAR: due loop coppiati che utilizzano definizioni di Scenario come fixture di test, cattura di Trace come harness di test, Assess con giudici come suite di test e Refine come loop rosso-verde. Esaminiamo ogni pezzo.
S - Definizioni dello Scenario
Nei test tradizionali, una fixture di test imposta le precondizioni: crea un database, popolalo con dati, configura l'ambiente. Il nostro equivalente è una definizione dello scenario: una descrizione strutturata dello stato iniziale, del prompt dell'utente e dei risultati attesi.
Ecco uno scenario semplificato per testare un agente Data Analyst su un dataset disordinato:
Ogni scenario raggruppa la configurazione, l'input e i criteri di successo in un unico posto, proprio come una fixture di test. Manteniamo una suite di questi per diversi agenti, coprendo casi comuni, casi limite e fallimenti passati noti. La suite cresce nel tempo man mano che scopriamo nuove modalità di fallimento: ogni bug che troviamo in produzione diventa un nuovo scenario, allo stesso modo in cui ogni bug di produzione dovrebbe diventare un test di regressione.
Perché preoccuparsi di questa struttura? Perché le esecuzioni degli agenti sono costose. Un singolo scenario richiede minuti per essere eseguito. Dobbiamo essere deliberati su ciò che testiamo e abbiamo bisogno che le definizioni dello scenario siano portatili: lo stesso scenario può essere eseguito su diverse implementazioni di agenti o diverse versioni dello stesso agente.
T - Cattura delle Tracce
Per eseguire la nostra suite di test, utilizziamo un harness che invia il prompt di ogni scenario all'agente sotto test (AUT). Ogni esecuzione viene catturata come una traccia MLflow: un log strutturato di ogni chiamata allo strumento, ogni output intermedio e ogni artefatto prodotto dall'agente. Pensala come una scatola nera: cattura tutto ciò che l'agente ha fatto, in ordine, in modo da poter ispezionare qualsiasi parte dell'esecuzione in seguito.
Una decisione architetturale chiave: disaccoppiamo l'esecuzione dalla valutazione. L'harness di test produce tracce; i giudici (che introdurremo successivamente) le valutano. Questi sono passaggi separati. Persistendo le tracce, possiamo iterare sui giudici senza rieseguire gli scenari. Modifichi una soglia? Rivaluta le tracce registrate in pochi secondi. Aggiungi un nuovo giudice? Eseguilo su ogni traccia che hai mai raccolto. Sospetti che un giudice sia sbagliato? Confronta i suoi verdetti con le registrazioni e debuggalo offline. Una costosa esecuzione dell'agente produce dati che vengono riutilizzati molte volte, anche come candidati per il Golden Set che useremo per allineare i giudici in seguito.
A - Valutare con i Giudici
I giudici operano sulle tracce e ragionano sulle proprietà dell'esecuzione: l'agente ha prodotto codice valido? L'output ha soddisfatto una soglia di qualità? L'agente ha seguito il giusto processo? Come accennato in precedenza, questa valutazione è diversa dai test unitari tradizionali: l'output dell'agente è non deterministico e ricco, quindi affermare output esatti è essenzialmente inutile.
L'approccio standard per implementare questi giudici è "LLM-as-a-Judge": fornire l'intera traccia a un modello e chiedere un punteggio e, cosa altrettanto importante, una motivazione per quel punteggio. Tuttavia, è come scrivere un test che scarica l'intero stato del programma in un'asserzione. È costoso, fragile e difficile da debuggare. Per i nostri agenti, una singola traccia può essere lunga migliaia di righe. Inserirla nella finestra di contesto di un giudice degrada la qualità del giudizio.
Invece, utilizziamo i giudici agentici di MLflow: giudici che sono essi stessi agenti, dotati di strumenti per esplorare selettivamente la traccia. Proprio come un test ben scritto chiama una funzione specifica e controlla un valore di ritorno specifico, un giudice agentico chiama uno strumento specifico sulla traccia e controlla una proprietà specifica.
Ecco alcuni esempi di giudici che abbiamo utilizzato nei nostri agenti:
Il giudice di invocazione delle skill esplora la traccia e identifica se l'agente ha invocato skill che sono target dello scenario (in caso contrario, lo scopo della skill non è chiaro all'AUT):
Il giudice delle best practice verifica se l'output segue le best practice secondo la documentazione ufficiale di Databricks:
Outcome Judge ispeziona il trace per gli asset di output e afferma determinate proprietà. Tornando all'esempio del Data Analyst, identifica la parte del trace in cui è stato creato il codice di ingegneria e valuta se il codice è appropriato per il compito da svolgere:
Questo judge è interessante perché affronta direttamente il problema della qualità soggettiva: ciò che conta come buon feature engineering dipende dall'esperienza del dominio. Un LLM judge non può risolvere questo problema subito. È allettante provare a scrivere i criteri completi nel prompt del judge: "preferire l'imputazione della mediana rispetto alla media per distribuzioni asimmetriche, scalare sempre le feature prima dei modelli basati sulla distanza, ..." Ma codificare il giudizio completo di un esperto di dominio in un prompt è laborioso e fragile. È molto più facile per gli esseri umani guardare un esempio e dire "questo è buono" o "questo è cattivo" piuttosto che scrivere la specifica completa. Questo è esattamente il motivo per cui l'allineamento funziona, come vedremo a breve.
In generale, il nostro test suite per un singolo agente include judge in diverse categorie:
Controlli deterministici, cose che possiamo verificare meccanicamente, senza bisogno di LLM:
- Sintassi/linting sul codice generato
- Validazione dello schema di output (esistono le tabelle previste? i tipi di colonna sono corretti?)
- Linting della sequenza di strumenti (l'agente ha letto i log di errore prima di provare a correggere il problema, o è passato direttamente alla modifica del codice?)
Controlli basati su LLM, decisioni che richiedono la comprensione del contesto:
- Linee guida per il diff del codice (l'agente ha modificato righe non correlate? ha introdotto API deprecate?)
- Aderenza alle best practice (il codice generato segue le convenzioni per questo dominio?)
Metriche operative, segnali che non passano/falliscono individualmente ma monitorano la salute nel tempo:
- Utilizzo dei token (conteggi elevati di token spesso segnalano che l'agente sta lottando, ritentando, tornando indietro o girando in tondo)
- Conteggi delle chiamate agli strumenti e rapporti di fallimento (un picco di chiamate agli strumenti fallite indica che qualcosa non va)
- Latenza (tempo effettivo impiegato dall'agente per completare il task)
Le metriche operative meritano una nota. Non bloccano una release nel modo in cui lo fanno i judge pass/fail, ma sono fondamentali per la gestione dei costi e l'allerta precoce. Se l'utilizzo dei token raddoppia dopo una modifica, qualcosa è andato storto anche se tutti i judge continuano a passare; l'agente sta probabilmente facendo più lavoro del dovuto. Monitoriamo questi dati nel tempo e avvisiamo in caso di anomalie.
Espansione del test suite nel tempo
I test suite non vengono creati in una sola seduta. Evolveranno nel tempo. Iniziano con i controlli più semplici che forniscono un segnale: l'output esiste? È parsabile? Seguono poi i controlli strutturali: l'output ha lo schema giusto, le colonne giuste, i tipi giusti? Solo in seguito arrivano i judge di validazione dati end-to-end: l'output produce effettivamente risultati corretti quando viene eseguito?
Questo rispecchia come i test suite maturano nel software tradizionale. Test di integrazione esaustivi non arrivano il primo giorno. Si inizia con smoke test, poi unit test man mano che emergono modalità di fallimento, costruendo nel tempo una copertura end-to-end. La chiave è che l'infrastruttura supporta l'aggiunta di nuovi judge a basso costo, in modo che il test suite cresca insieme all'agente.
Testare i Test: Allineamento dei Judge
Ecco un problema che ogni ingegnere conosce: un test suite instabile o errato che approva codice scadente spedisce bug con sicurezza. Allo stesso modo, i judge che approvano risultati scadenti danno un falso senso di sicurezza. È qui che entra in gioco il secondo ciclo del framework coSTAR: gli stessi scenari e trace che guidano il perfezionamento dell'agente guidano anche il perfezionamento del judge, con punteggi di esperti umani come ground truth. Questo è importante perché, a differenza dei test tradizionali in cui la correttezza dei test può essere verificata tramite ispezione, i judge LLM sono stocastici e possono variare nel modo in cui interpretano i criteri in linguaggio naturale. Quindi abbiamo bisogno di un modo per verificarli e mantenerli allineati con gli esperti umani.
Per fare questo allineamento, prima curiamo un Golden Set di tipicamente dozzine di esempi di output dell'agente che i nostri ingegneri hanno valutato manualmente. Questa è la ground truth con cui i judge devono concordare. Poi sfruttiamo le capacità di allineamento di MLflow (alimentate da tecniche come GEPA e MemAlign) per affinare automaticamente il judge rispetto al Golden Set. Notare che questo è strutturalmente lo stesso ciclo STAR che usiamo per affinare l'AUT stesso, ma il passaggio di valutazione è eseguito da esperti umani e il passaggio di perfezionamento si applica al judge.
R - Refine
Con judge che il ciclo dei judge ha allineato al giudizio di esperti umani, possiamo ora fidarci del ciclo dell'agente. Un assistente di codifica tratta l'agente come il suo codebase e i judge come il suo test suite. Legge i fallimenti, diagnostica le cause principali, corregge l'agente e riesegue tutto. L'ingegnere è ancora il revisore e l'arbitro finale delle modifiche proposte all'agente, ma questa iterazione automatizzata consente di risparmiare notevole sforzo umano nell'analisi e nel miglioramento dell'agente.
Ecco come si è svolta un'iterazione per l'agente Data Analyst:
Rosso. Abbiamo eseguito la versione iniziale dell'agente contro il nostro scenario suite. Il judge delle best practice ha segnalato una discrepanza: il nostro agente stava generando codice per viste logiche che era diverso dalle nostre raccomandazioni/documentazione ufficiali. Sebbene questa discrepanza non influisse sulla correttezza, aveva implicazioni sulla manutenzione e sul deployment del codice generato. Questo è un esempio di una regressione insidiosa che sarebbe difficile da individuare con un'indagine manuale.
Verde. L'assistente di codifica ha analizzato il feedback del judge e identificato il divario: l'agente stava utilizzando un'abilità che non era prescrittiva riguardo al tipo di viste da creare (temporanee vs permanenti). Dopo aver aggiunto la guida pertinente all'abilità, i test sono stati superati con successo e la modifica è stata verificata per non introdurre altre regressioni (sulla base di altri scenari di test).
Regression Tests per l'Infrastruttura, Non Solo per l'Agente
Finora abbiamo descritto i judge come test per l'agente, che catturano regressioni quando l'implementazione dell'agente cambia. Ma in pratica, non è solo l'agente a cambiare. L'agente dipende da strumenti e infrastrutture esterne, e anche questi cambiano.
I nostri agenti chiamano strumenti MCP, interfacce standardizzate per l'accesso ai dati, l'esecuzione del codice, la configurazione dell'ambiente e altro ancora. Questi strumenti hanno i propri team di sviluppo e cicli di rilascio. Quando uno strumento cambia la sua implementazione (ad esempio, uno strumento di esecuzione del codice inizia a restituire stderr in un formato diverso, o uno strumento di accesso ai dati cambia il modo in cui gestisce i valori null) l'agente non è cambiato affatto, ma il comportamento dell'agente può interrompersi.
Poiché eseguiamo i nostri judge su ogni build notturna, agiscono come regression test contro l'intero stack, non solo sull'implementazione corrente dell'agente. Quando un team di strumenti rilascia una modifica che causa il fallimento dei judge da parte di un agente, catturiamo l'errore immediatamente, prima che raggiunga i clienti. Ancora più importante, il fallimento del judge ci dice cosa si è rotto (la specifica dimensione di qualità che è regredita), il che rende molto più facile determinare se la causa principale è nell'agente o in uno strumento da cui l'agente dipende.
Questo è lo stesso valore che i test di integrazione forniscono nel software tradizionale: proteggono il contratto tra il codice e le sue dipendenze. L'unica differenza è che qui, il "codice" è un agente e le "dipendenze" sono strumenti MCP.
Da Eval al Monitoraggio della Produzione
C'è un'altra estensione dell'analogia di testing che si è rivelata sorprendentemente preziosa: eseguire gli stessi judge sul traffico di produzione.
Nel software tradizionale, il testing non si ferma al CI. Anche la produzione viene monitorata: tassi di errore, percentili di latenza, metriche di business sul traffico live. La stessa logica di test che valida il codice in fase di sviluppo riappare spesso come controlli di integrità e avvisi in produzione.
Facciamo la stessa cosa. I judge che abbiamo costruito per la valutazione sono progettati per valutare qualsiasi conversazione dell'agente, non solo scenari di valutazione. Quindi li eseguiamo (o un sottoinsieme campionato) su conversazioni di produzione reali. Questo ci fornisce:
- Allerta precoce sul drift. Se il tasso di superamento dei judge diminuisce sulle conversazioni di produzione, qualcosa è cambiato. Forse un aggiornamento del modello ha degradato la qualità, forse i prompt degli utenti sono cambiati in un modo che l'agente gestisce male. Lo vediamo nei punteggi dei judge prima di vederlo nei reclami degli utenti.
- Segnale del mondo reale per il test suite. Le conversazioni di produzione che i judge segnalano come fallimenti diventano candidati per nuovi scenari di valutazione. È così che il test suite cresce organicamente: i fallimenti reali ritornano nella valutazione, chiudendo il ciclo tra produzione e sviluppo.
- Monitoraggio dei costi a livello di agente. Monitoriamo l'utilizzo dei token e il numero di chiamate agli strumenti sulle conversazioni di produzione. Una modifica neutrale dal punto di vista della qualità che triplica i costi è ancora una regressione.
L'idea chiave è che la stessa infrastruttura di punteggio (giudici, metriche, tracce registrate) svolge un doppio ruolo. Costruiscila una volta per la valutazione e il monitoraggio della produzione ne sarà una conseguenza.
Dove Siamo Ora
Abbiamo adottato questa metodologia in diversi agenti che abbiamo rilasciato sulla piattaforma Databricks (ad es. le capacità di ingegneria dei dati, machine learning e analisi delle tracce in Genie), agenti interni per la produttività degli sviluppatori, nonché altri agenti rivolti ai clienti (ad es. AI Dev Kit, o l'assistente MLflow OSS). Nel complesso abbiamo riscontrato benefici tangibili:
- Rispetto alle valutazioni manuali, le suite di test automatizzate hanno ridotto il tempo necessario per verificare le modifiche da 2 settimane a poche ore. Di conseguenza, ciò ha permesso ai nostri team di rilasciare miglioramenti con maggiore velocità.
- Diverse suite di test sono cresciute fino a centinaia di scenari di test per agente, aumentando la nostra fiducia nell'individuare regressioni.
- I test di integrazione hanno segnalato modifiche nell'infrastruttura dipendente, permettendoci di prevenire regressioni in produzione. Esempi di queste modifiche includono il comportamento della gestione TODO nel modello sottostante, modifiche che influiscono sulla latenza o modifiche del modello.
MLflow è stato anche fondamentale come piattaforma di test GenAI, aiutando i nostri ingegneri a standardizzare la metodologia, accelerare lo sviluppo dei test e condividere le best practice tra i team.
Cosa Non Funziona (Ancora)
Anche l'analogia dei test è utile qui. Le nostre limitazioni si allineano a problemi di test familiari:
La generazione di scenari è manuale (scrivere casi di test è costoso). Abbiamo automatizzato il punteggio, l'allineamento e l'ottimizzazione, ma la generazione degli scenari stessi è ancora un compito umano. Ogni scenario richiede la creazione di uno stato iniziale realistico, un prompt significativo e aspettative corrette. Questo è il collo di bottiglia che limita la dimensione della suite di test, e una suite di test ristretta porta direttamente al problema successivo. L'automazione della generazione di scenari (sintetizzare casi di test diversi e realistici dai pattern di traffico di produzione o dalla specifica dell'agente) è un'area di lavoro attiva per noi.
L'assistente di codifica può sovradattarsi (suite di test troppo ristretta). Se la suite di test non copre abbastanza casi, l'assistente di codifica creerà un'implementazione dell'agente che eccelle con quegli input specifici ma fallisce con quelli nuovi. Questo è l'equivalente dell'agente di scrittura di codice che supera i test unitari ma fallisce in produzione. Mitighiamo questo reintroducendo i fallimenti di produzione nella valutazione e ampliando la copertura nel tempo, ma finché la generazione di scenari non sarà automatizzata, la suite di test crescerà più lentamente di quanto vorremmo.
L'allineamento dei giudici è costoso (la calibrazione dei test richiede lavoro umano). La creazione del Golden Set richiede agli esperti di dominio di valutare manualmente gli output, esattamente il collo di bottiglia che stiamo cercando di eliminare. E non è un costo una tantum: man mano che gli agenti evolvono, i giudici necessitano di ricalibrazione. Stiamo indagando modi per renderlo più intelligente misurando l'incertezza del giudice, identificando gli esempi specifici in cui il giudice è sottodimensionato e un'etichetta umana risolverebbe l'ambiguità. L'obiettivo è l'apprendimento attivo per l'allineamento dei giudici: invece di chiedere agli esperti di valutare un campione casuale, presentare solo gli esempi in cui il giudice è incerto e l'input di un esperto di dominio affinerebbe maggiormente i suoi criteri.
I fallimenti multi-step sono difficili da attribuire (analisi della causa principale). Quando un agente fallisce al passaggio 7 di una pipeline di 10 passaggi, la causa principale è stata al passaggio 7 o al passaggio 3? I nostri giudici rilevano il sintomo ma l'assistente di codifica a volte corregge il passaggio sbagliato, come correggere un fallimento del test modificando la funzione sbagliata. Una migliore tracciabilità causale è un'area di lavoro attiva.
Le nuove modalità di fallimento sfuggono (lacune di copertura). coSTAR ottimizza all'interno delle dimensioni coperte dai giudici. Se emerge una nuova classe di fallimenti che nessun giudice verifica, è invisibile, proprio come un bug nel codice che nessun test esercita. coSTAR migliora *all'interno* della sua suite di test, ma non può espandere la suite di test da sola. Gli esseri umani devono ancora notare nuove modalità di fallimento e aggiungere giudici.
Punti Chiave
- Lo sviluppo degli agenti ha un problema di testing. Senza una valutazione automatizzata, stai codificando senza test e otterrai le regressioni che meriti.
- Dai strumenti ai giudici, non tracce. Un giudice agentivo che chiama strumenti mirati è come un test unitario focalizzato. Scaricare la traccia completa in un giudice è come scaricare lo stato del programma in un'asserzione. Non scala.
- Testa i tuoi test. I giudici LLM sono stocastici. Allineali rispetto a set di dati dorati valutati da esseri umani allo stesso modo in cui convalideresti una suite di test rispetto a una specifica.
- Chiudi il cerchio. La vera vittoria è il ciclo coSTAR completo: scenari fidati, tracce registrate, giudici allineati e un assistente di codifica che perfeziona l'agente finché i test non superano. La valutazione senza perfezionamento automatizzato è solo metà della storia.
- Costruisci una volta, monitora ovunque. Gli stessi giudici che validano nella valutazione possono monitorare la produzione. Un investimento, due ritorni.
- L'accoppiamento è fondamentale. Il perfezionamento dell'agente è affidabile solo quanto i giudici che lo guidano. I due cicli accoppiati di coSTAR — uno che guadagna fiducia nei giudici, uno che usa quella fiducia per perfezionare l'agente — sono ciò che rende il perfezionamento automatizzato significativo piuttosto che solo veloce.
Stiamo costruendo coSTAR come parte di MLflow. Se stai affrontando problemi simili, ci piacerebbe sentirlo.
- Prova Genie Code per vedere le funzionalità che abbiamo rilasciato utilizzando la metodologia coSTAR.
- Segui i tutorial su MLflow per iniziare a definire e utilizzare i giudici LLM per il perfezionamento iterativo degli agenti.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.