L'evoluzione dell'ingegneria dei dati: come il calcolo serverless sta trasformando i notebook, i processi Lakeflow e le pipeline dichiarative Spark
Scopri come il calcolo serverless di Databricks offre semplicità, prestazioni e affidabilità senza pari per Notebook, Lakeflow Jobs e Spark Declarative Pipelines.
di Aaron Davidson, Ihor Leshko, Justin Breese, Piyush Singh, Vivek Narasimhan, Prashanth Babu Velanati Venkata, Roland Fäustlin, Hemant Saxena e Mostafa Mokhtar
- Il calcolo serverless per Notebook, Lakeflow Jobs e Spark Declarative Pipelines elimina la necessità di gestire l'infrastruttura e gli aggiornamenti di Spark.
- Il calcolo serverless sta migliorando automaticamente i carichi di lavoro e ha migliorato le prestazioni dell'80% e l'efficienza dei costi fino al 70% nell'ultimo anno senza la necessità di intervento da parte dell'utente.
- Il calcolo serverless è ora il prodotto di calcolo più stabile di Databricks, che dimensiona automaticamente i cluster per adattarsi ai volumi di dati crescenti e protegge i carichi di lavoro da interruzioni del cloud e esaurimenti delle scorte, con un conseguente aumento dell'89% delle esecuzioni riuscite
L'ingegneria dei dati ha raggiunto un punto di svolta. Poiché le organizzazioni si affidano sempre più all'AI e al machine learning per guidare le decisioni aziendali, la complessità della gestione dell'infrastruttura di calcolo è diventata un collo di bottiglia critico. I progressi nel calcolo serverless di Databricks aiutano i team a risparmiare fino al 20% del loro tempo su attività di routine come l'aggiornamento delle versioni di Databricks Runtime (DBR), la gestione delle impostazioni del cluster e la risoluzione dei problemi dell'infrastruttura. Oggi siamo entusiasti di condividere diversi recenti lanci di funzionalità per il calcolo serverless di Databricks e di come ha trasformato radicalmente il paradigma fornendo semplicità, prestazioni e affidabilità senza pari per Notebook, Lakeflow Jobs e Spark Declarative Pipelines (SDP, formalmente noto come DLT). Ad esempio, il calcolo serverless offre un risparmio sui costi del 70% con la modalità di prestazioni Standard rispetto ai carichi di lavoro ottimizzati per le prestazioni e oltre il 50% di risparmio sui costi per i carichi di lavoro Non-Spark. Inoltre, i carichi di lavoro ottimizzati per le prestazioni si avviano in pochi secondi e in genere vengono eseguiti due volte più velocemente. Versionless ha eseguito 25 aggiornamenti DBR su oltre 4,5 miliardi di carichi di lavoro con uno straordinario tasso di successo del 99,998% nell'ultimo anno.
La sfida della gestione dell'infrastruttura è reale
Ogni piattaforma di data engineering deve gestire un'ampia serie di responsabilità operative per mantenere i cluster Spark tradizionali, come ad esempio:
- Le reti devono essere configurate con VPC, gateway, intervalli di indirizzi IP ed endpoint privati.
- La sicurezza e la conformità richiedono un'attenta attenzione alla gestione delle vulnerabilità, alla crittografia e alla protezione contro l'esfiltrazione dei dati.
- Considerazioni sull'efficienza, come il dimensionamento delle istanze, l'utilizzo, i pool di istanze e l'ottimizzazione Delta, sono essenziali per l'esecuzione di un ambiente dati robusto.
- Mantenere runtime aggiornati con tutti gli ultimi miglioramenti delle prestazioni è un altro aspetto importante delle operazioni della piattaforma. Con due rilasci DBR di supporto a lungo termine ogni anno, è normale che i team valutino attentamente gli aggiornamenti per garantire stabilità, prestazioni e compatibilità con i loro carichi di lavoro.
Il calcolo serverless offre un modello operativo diverso: attività fondamentali, come la rete e gli intervalli IP, il rafforzamento della sicurezza, la gestione del ciclo di vita e gli aggiornamenti del runtime, vengono gestite automaticamente e ottimizzate continuamente. Ciò consente ai team di adottare prima le ultime ottimizzazioni e di dedicare più tempo alla creazione di prodotti dati e alla fornitura di valore aziendale piuttosto che alla gestione dell'infrastruttura.
Calcolo serverless: semplice, performante, senza manutenzione
Il calcolo serverless di Databricks è un calcolo gestito da Databricks, senza intervento manuale e con ottimizzazione automatica, e affronta queste sfide attraverso tre principi fondamentali:
- Semplice: devi solo scegliere se vuoi che il carico di lavoro venga eseguito velocemente (modalità ottimizzata per le prestazioni) o in modo efficiente in termini di costi (modalità standard). Databricks si sintonizza costantemente e automaticamente per raggiungere l'obiettivo selezionato. Non sono necessari manopole, tipi di istanza o selezione del fattore di scala.
- Performante: supportato dall'infrastruttura ottimizzata di Databricks e da un nuovo autoscaler, il calcolo serverless si avvia in pochi secondi, carica le librerie dipendenti in pochi secondi dalla cache e in genere viene eseguito due volte più velocemente dei cluster classici.
- Senza manutenzione: Databricks serverless scala automaticamente il tuo calcolo orizzontalmente e verticalmente per prevenire problemi di memoria insufficiente, ti protegge dalle interruzioni del cloud e esegue il failover sui tipi di istanza disponibili, con un alto grado di tolleranza agli errori. È anche versionless, aggiornandoti automaticamente agli ultimi miglioramenti delle prestazioni pur rimanendo completamente retrocompatibile.
Serverless è semplice
Prestazioni ed efficienza pronte all'uso
Con il calcolo serverless per Notebook, Spark Declarative Pipelines e Lakeflow Jobs, Databricks seleziona automaticamente l'infrastruttura giusta per il tuo carico di lavoro e quindi la ottimizza continuamente in base alle informazioni storiche sul carico di lavoro. Pertanto, gli utenti non devono più selezionare tipi di istanza specifici, impostazioni di autoscaler o ottimizzazioni, come Photon. La nostra AI rileva automaticamente quale infrastruttura e quali impostazioni avvantaggerebbero maggiormente il carico di lavoro e le abilita automaticamente, ad esempio, Photon viene utilizzato solo quando il carico di lavoro specifico beneficia dell'accelerazione Photon.
Per i carichi di lavoro che non richiedono Spark, la nostra selezione automatica dell'infrastruttura garantisce che quando Spark non è necessario, venga fornita al volo una VM più piccola. Questo approccio può offrire oltre il 50% di risparmio sui costi e un avvio più veloce di oltre il 33% rispetto ai cluster classici, semplicemente utilizzando solo le risorse di cui hai effettivamente bisogno.
L'introduzione delle modalità di prestazioni per Lakeflow Jobs e Spark Declarative Pipelines rappresenta un significativo progresso nell'ottimizzazione del calcolo, in quanto consente agli utenti di esprimere ciò per cui Databricks dovrebbe ottimizzare. La modalità ottimizzata per le prestazioni si avvia in pochi secondi e viene eseguita in genere due volte più velocemente dei cluster classici. Questa modalità sfrutta pool di macchine warm e un ridimensionamento aggressivo delle risorse per ridurre al minimo i tempi di elaborazione, rendendola ideale per carichi di lavoro interattivi e sensibili al tempo.
La modalità standard, che è generalmente disponibile da luglio, adotta un approccio diverso. Ottimizzando per l'efficienza dei costi piuttosto che per la pura velocità, offre un risparmio sui costi fino al 70% rispetto alla modalità ottimizzata per le prestazioni, pur mantenendo prestazioni competitive. Questa modalità è perfetta per carichi di lavoro batch, processi pianificati e pipeline in cui una latenza di avvio di 4-6 minuti è accettabile in cambio di significative riduzioni dei costi.
Le modalità di prestazioni consentono agli utenti di concentrarsi sugli insight dei dati e sulle esigenze aziendali specifiche del loro caso d'uso, piuttosto che sulla gestione dell'infrastruttura. Questa semplicità consente agli utenti di dedicare più tempo alla generazione di insight dai dati. Tieni presente che serverless nei notebook interattivi si avvia sempre in pochi secondi e viene eseguito velocemente per sfruttare al meglio il tempo degli utenti.
| Modalità di calcolo serverless | Prestazioni tipiche | Vantaggi principali |
|---|---|---|
| Modalità interattiva per Notebook La migliore esperienza serverless per la data science, piattaforma completamente gestita per Databricks Notebook | Avvio in < 10 secondi, scalabilità rapida |
|
| Modalità ottimizzata per le prestazioni per Lakeflow Jobs e SDP La migliore esperienza serverless per la data engineering, con avvio ed esecuzione rapidi per Lakeflow Jobs e SDP sensibili al tempo | Avvio in < 1 minuto, scalabilità rapida |
|
| Modalità standard per Lakeflow Jobs e Pipelines Esperienza serverless a basso costo, piattaforma completamente gestita per eseguire Jobs e SDP | Avvio in 4-6 minuti, scalabilità conservativa |
|
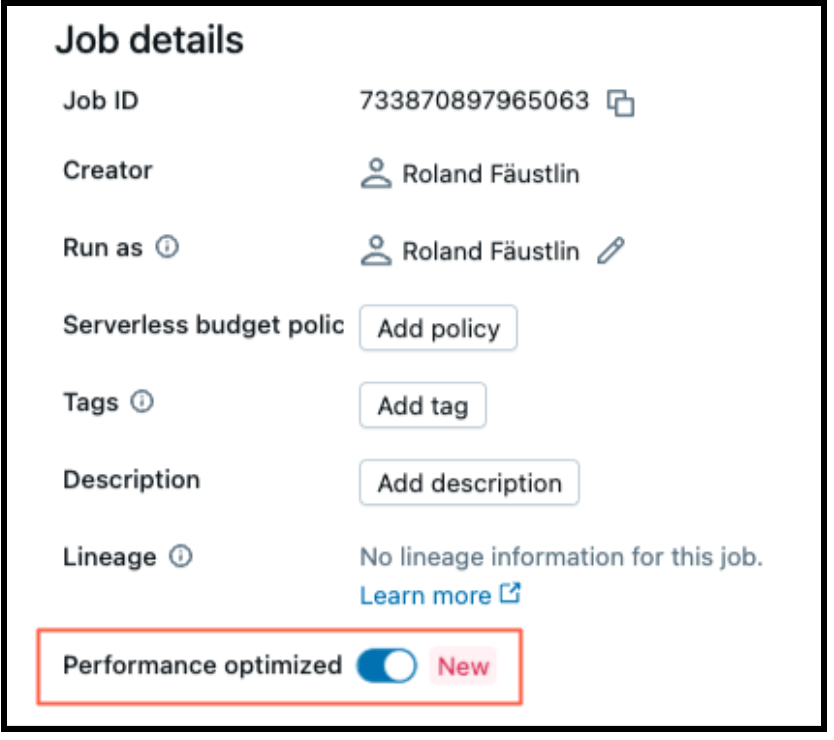
Il calcolo serverless rende facile la regolazione per prestazioni o efficienza come attivare un interruttore. Quando "Ottimizzato per le prestazioni" è abilitato, i tuoi carichi di lavoro si avvieranno ed eseguiranno più velocemente. Quando è disabilitato, i tuoi carichi di lavoro verranno eseguiti in modalità "Standard", ottimizzando l'efficienza.
Gestione e governance complete dei costi
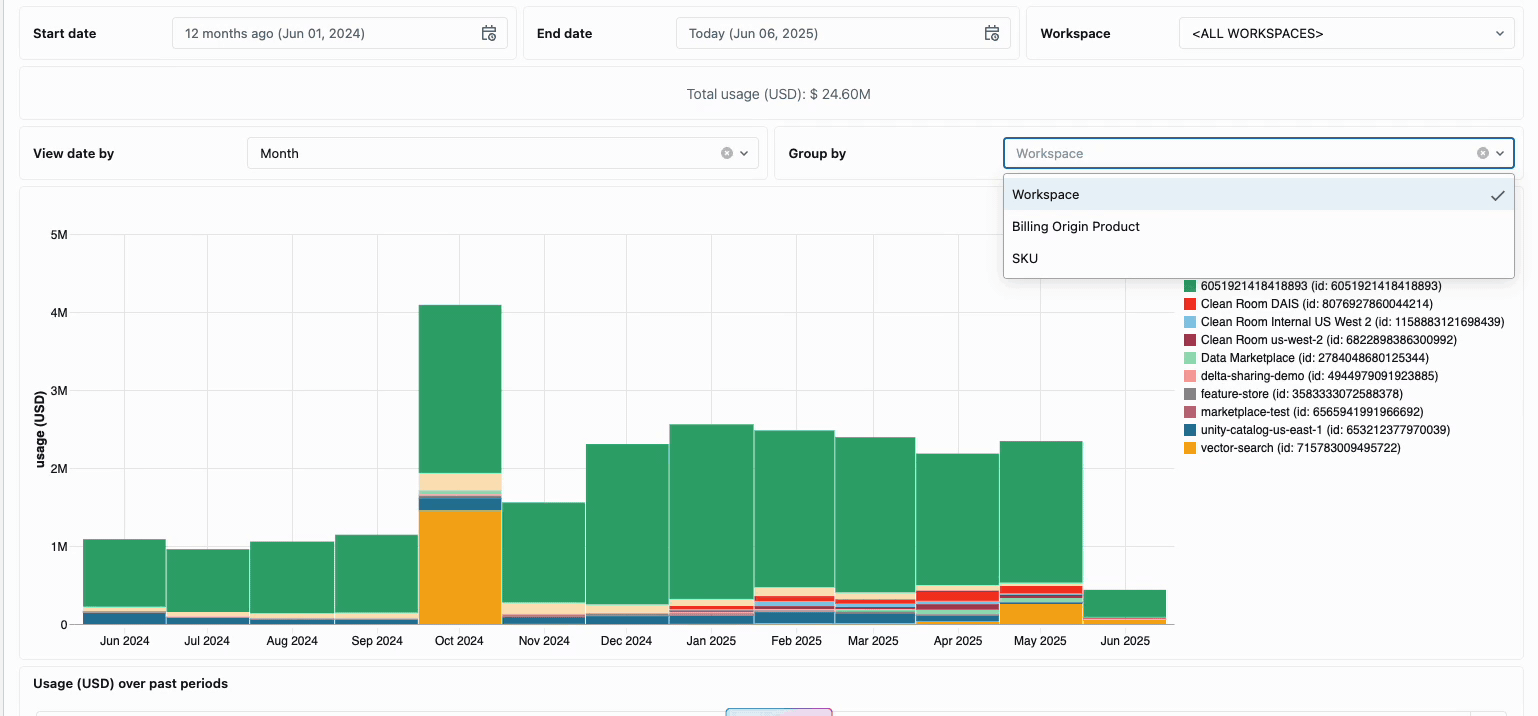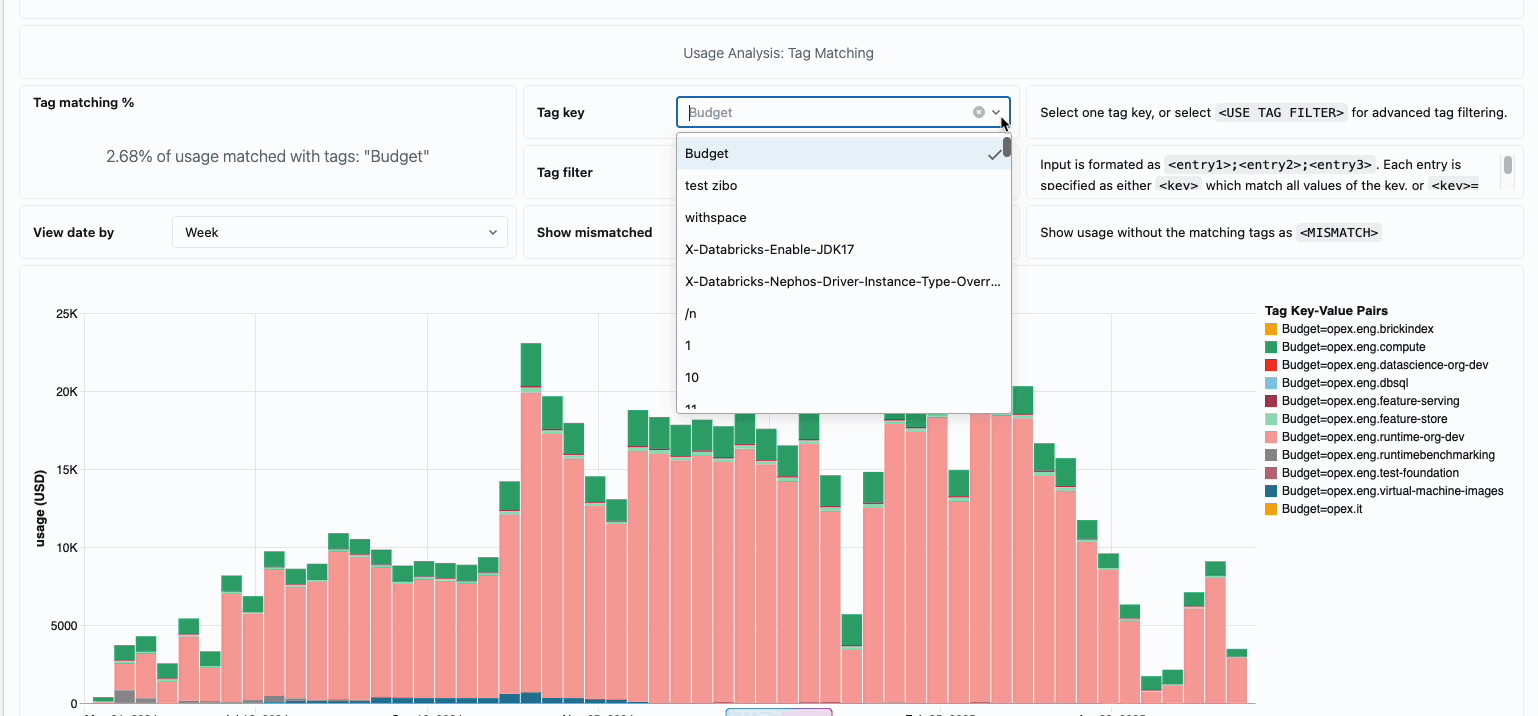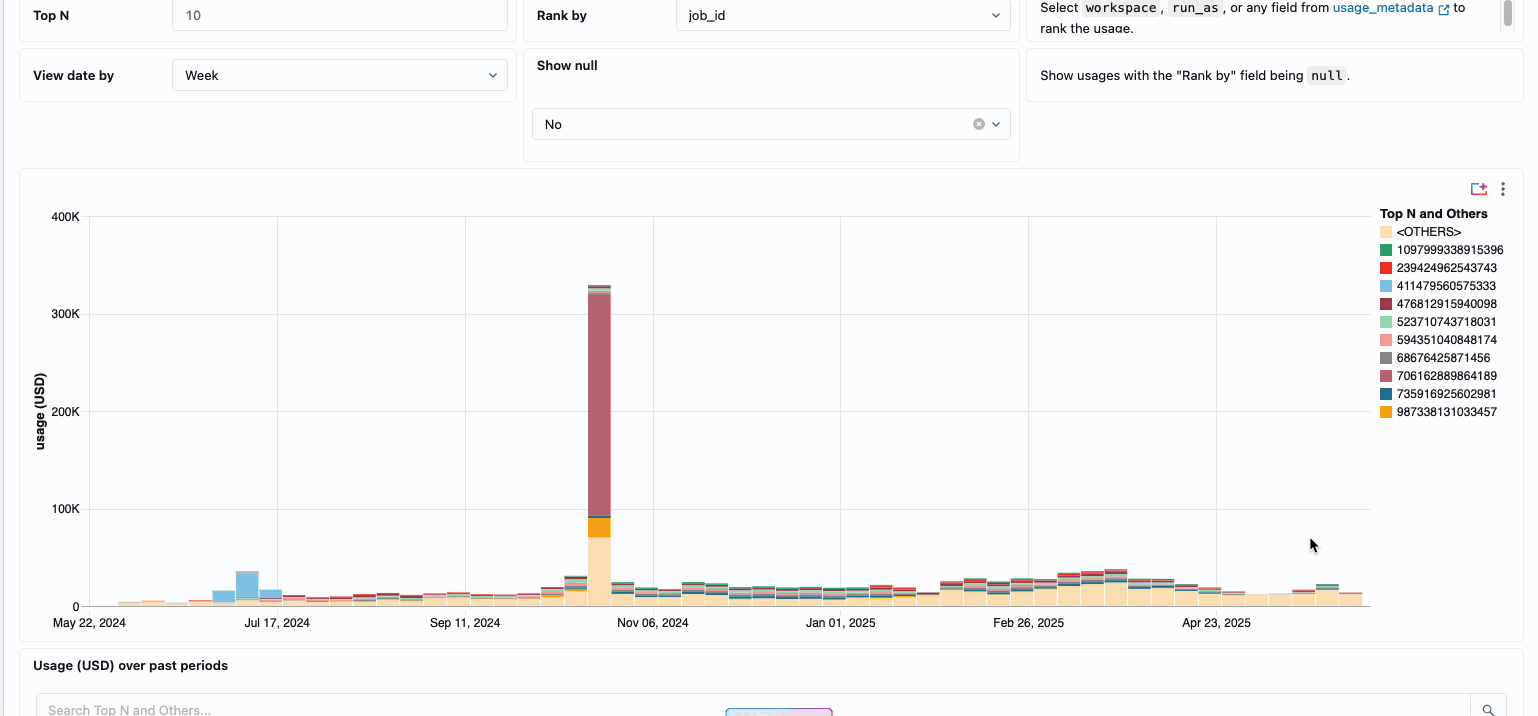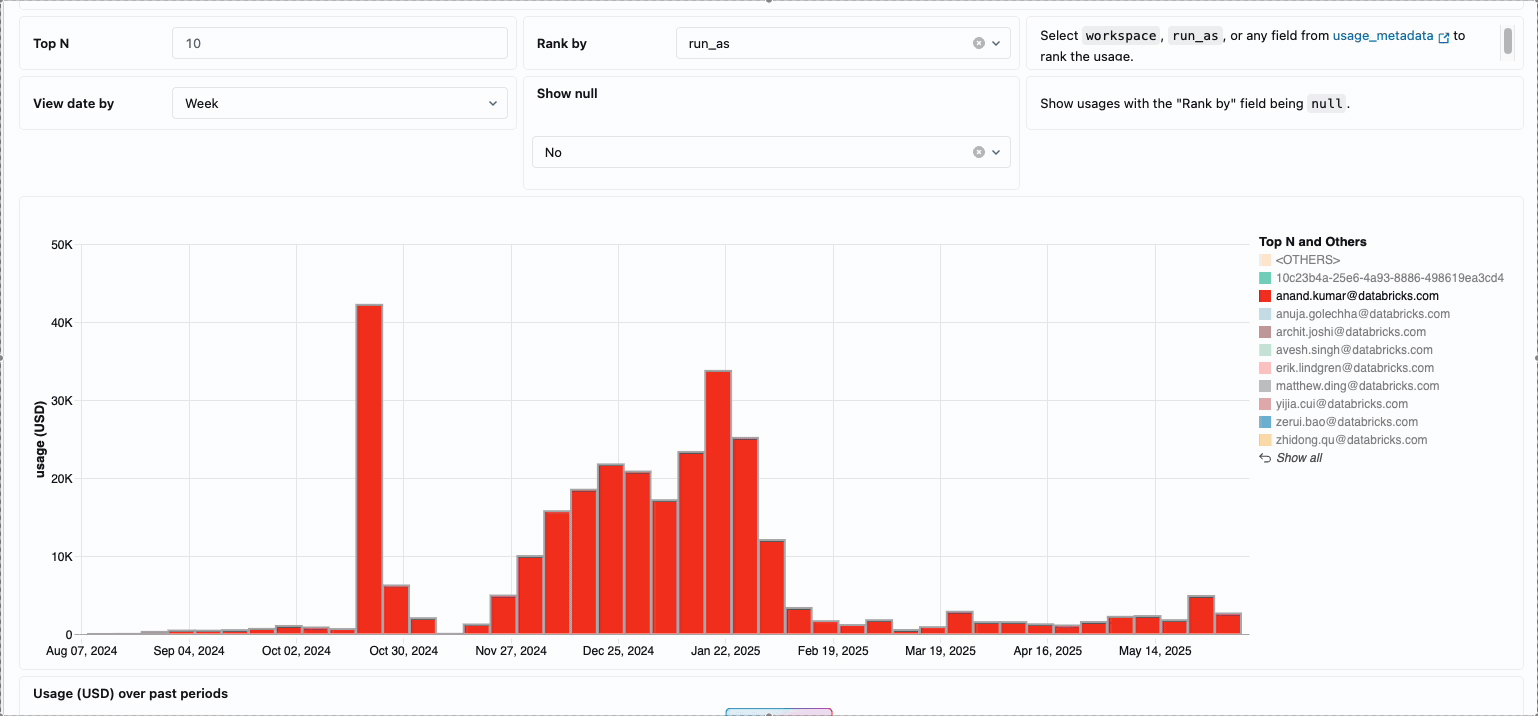
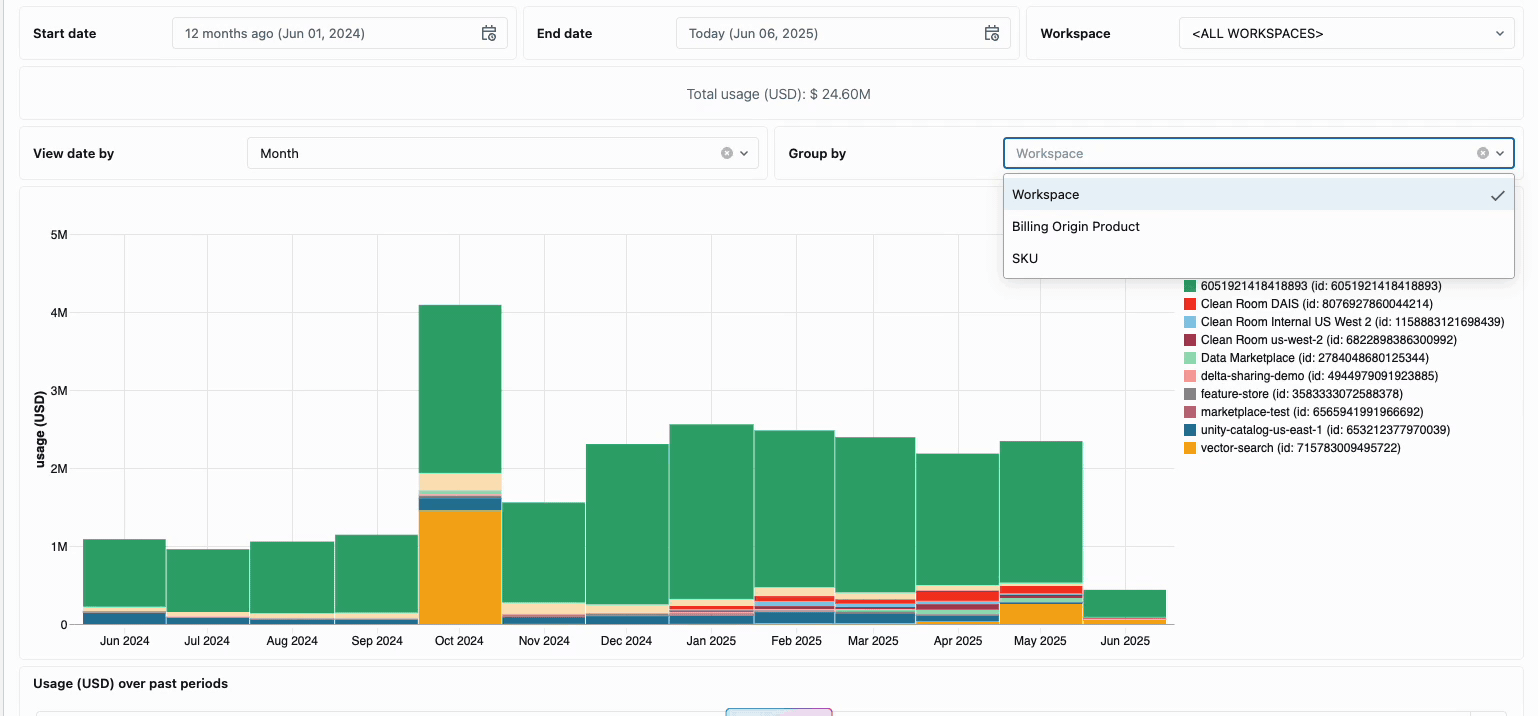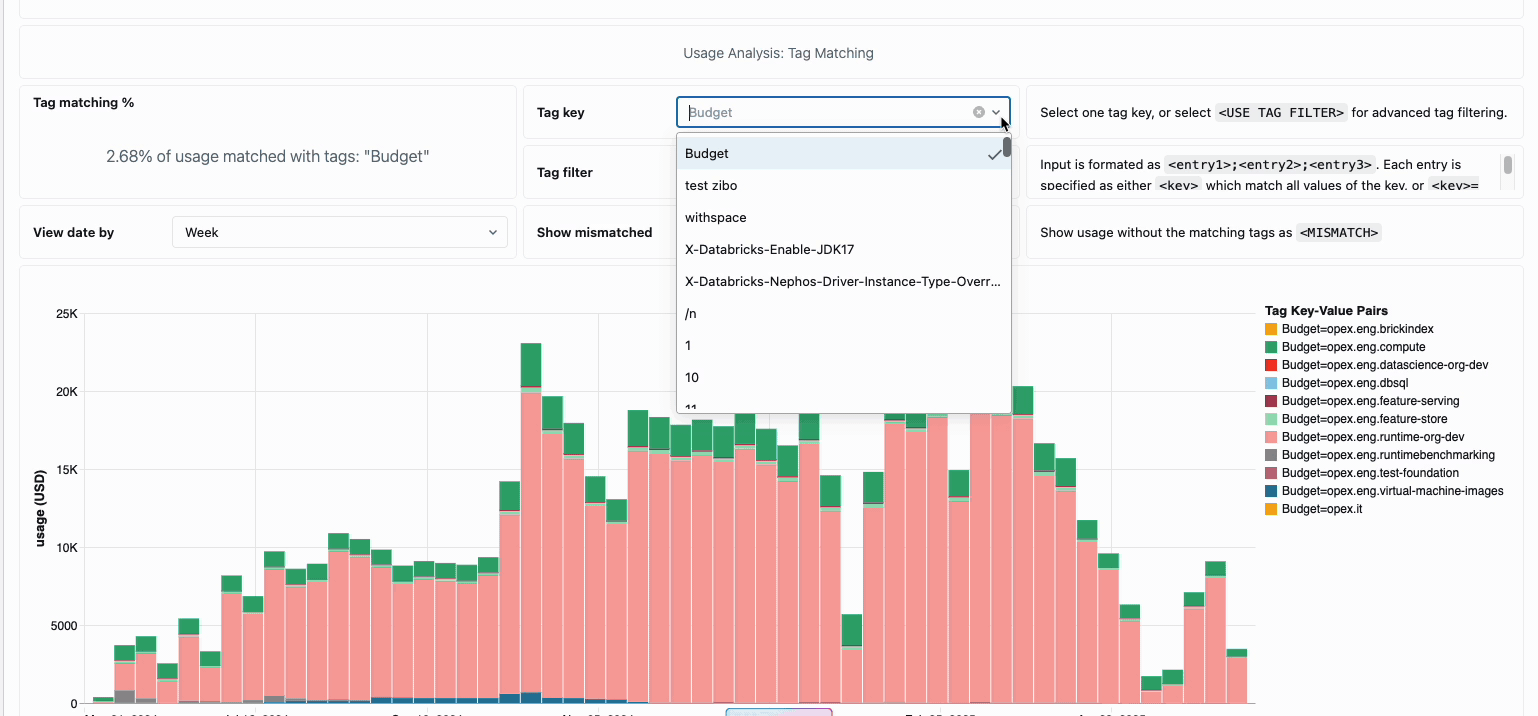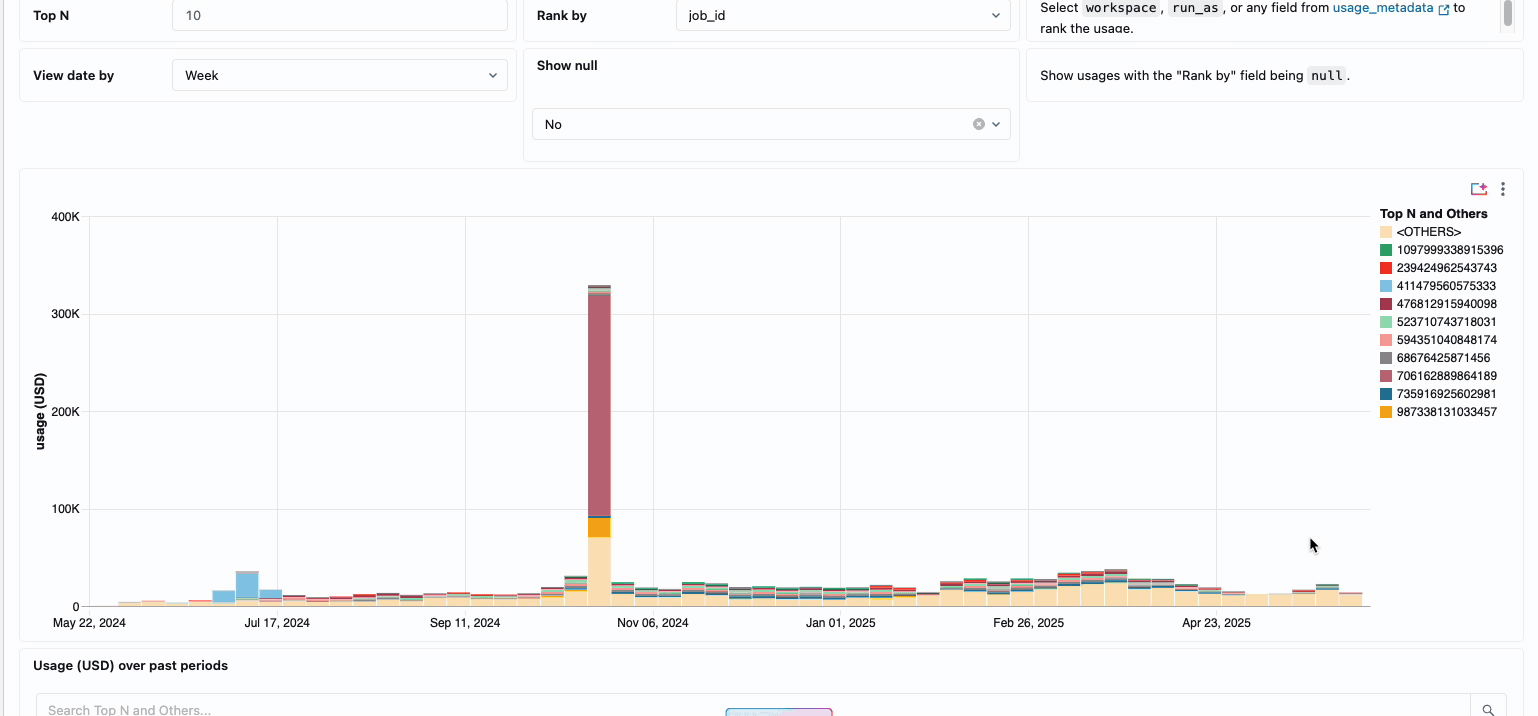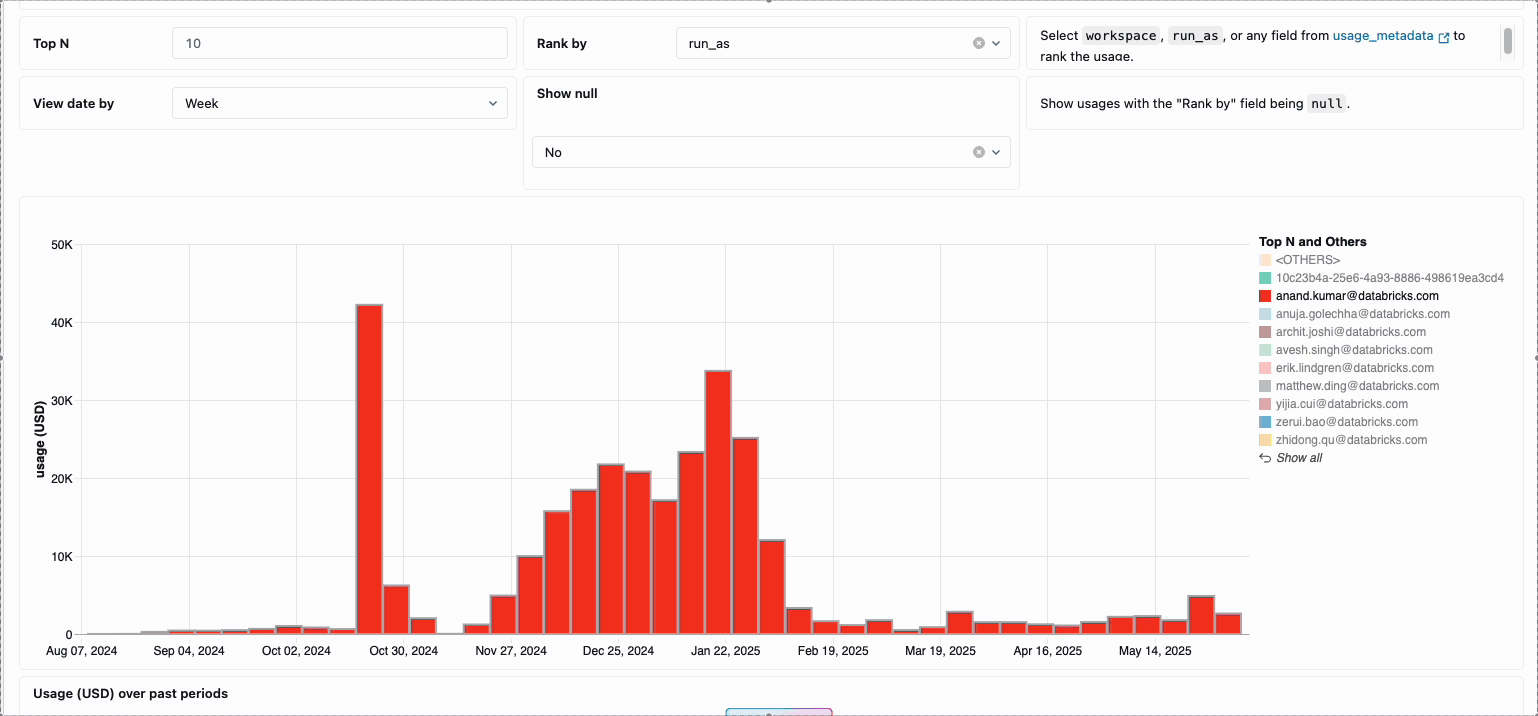
La gestione dei costi di calcolo tra i team di data engineering distribuiti ha tradizionalmente richiesto di mettere insieme fonti di dati disparate e componenti di fatturazione: un processo dispendioso in termini di tempo che spesso oscura il vero costo totale di proprietà. Il calcolo serverless trasforma questa complessità in chiarezza attraverso la fatturazione unificata, consolidando tutti i componenti di costo in un'unica vista comprensibile. Gli amministratori ottengono visibilità immediata attraverso dashboard di budget predefiniti e query personalizzabili basate su tabelle di sistema, eliminando così la necessità di lavoro di riconciliazione manuale tra diversi fornitori di servizi.
Per le organizzazioni che richiedono chargeback interni, le policy di utilizzo serverless consentono l'applicazione di tag che aggregano automaticamente i costi per team o progetto, garantendo un'attribuzione e una responsabilità accurate tra le unità aziendali. La piattaforma fornisce anche più livelli di protezione contro la spesa accidentale: timeout intelligenti impediscono alle query fuori controllo di esaurire i budget, mentre policy di utilizzo granulari offrono agli amministratori un controllo preciso su chi può accedere al calcolo serverless e a quale velocità possono consumare risorse, creando un framework di governance completo che bilancia l'innovazione con la responsabilità fiscale.
{kind=link}
Serverless: progettato per le prestazioni
La memorizzazione nella cache dell'ambiente elimina l'overhead dell'installazione delle dipendenze
Le configurazioni di calcolo tradizionali spesso si basano su passaggi di installazione per preparare l'ambiente giusto per ogni esecuzione, soprattutto quando i team hanno diverse esigenze di libreria. Il calcolo serverless cambia questo utilizzando la memorizzazione nella cache intelligente dell'ambiente. Gli utenti definiscono il loro ambiente una volta e Databricks analizza, scarica e installa automaticamente le librerie necessarie, quindi crea uno snapshot e lo memorizza nella cache. Le esecuzioni future caricano l'ambiente dalla cache in pochi secondi, senza download o installazioni necessari. Questo è particolarmente utile per i piccoli carichi di lavoro ed è in media 2 volte più veloce. I nuovi ambienti di base predefiniti consentono agli amministratori di gestire centralmente gli ambienti preconfigurati per diversi team, semplificando i flussi di lavoro per analisti, data scientist e ingegneri ML.
L'avvio è una priorità per noi e i Notebook e i Workflow serverless hanno fatto un'enorme differenza. Il calcolo serverless per i notebook lo rende facile con un solo clic.—Chiranjeevi Katta, Data Engineer presso Airbus
Spark Declarative Pipelines serverless dimezzano i tempi di esecuzione senza compromettere i costi, migliorano l'efficienza ingegneristica e semplificano le operazioni di dati complesse, consentendo ai team di concentrarsi sull'innovazione piuttosto che sull'infrastruttura sia negli ambienti di produzione che di sviluppo. —Cory Perkins, Sr. Data & AI Engineer presso Qorvo
In pratica, in tutti i carichi di lavoro su Databricks, vediamo che il calcolo serverless è in media più efficiente in termini di costi del 20% rispetto ai carichi di lavoro di cluster classici comparabili e, mentre i clienti pagano il loro provider cloud per l'avvio dei cluster classici, Databricks non addebita l'avvio.
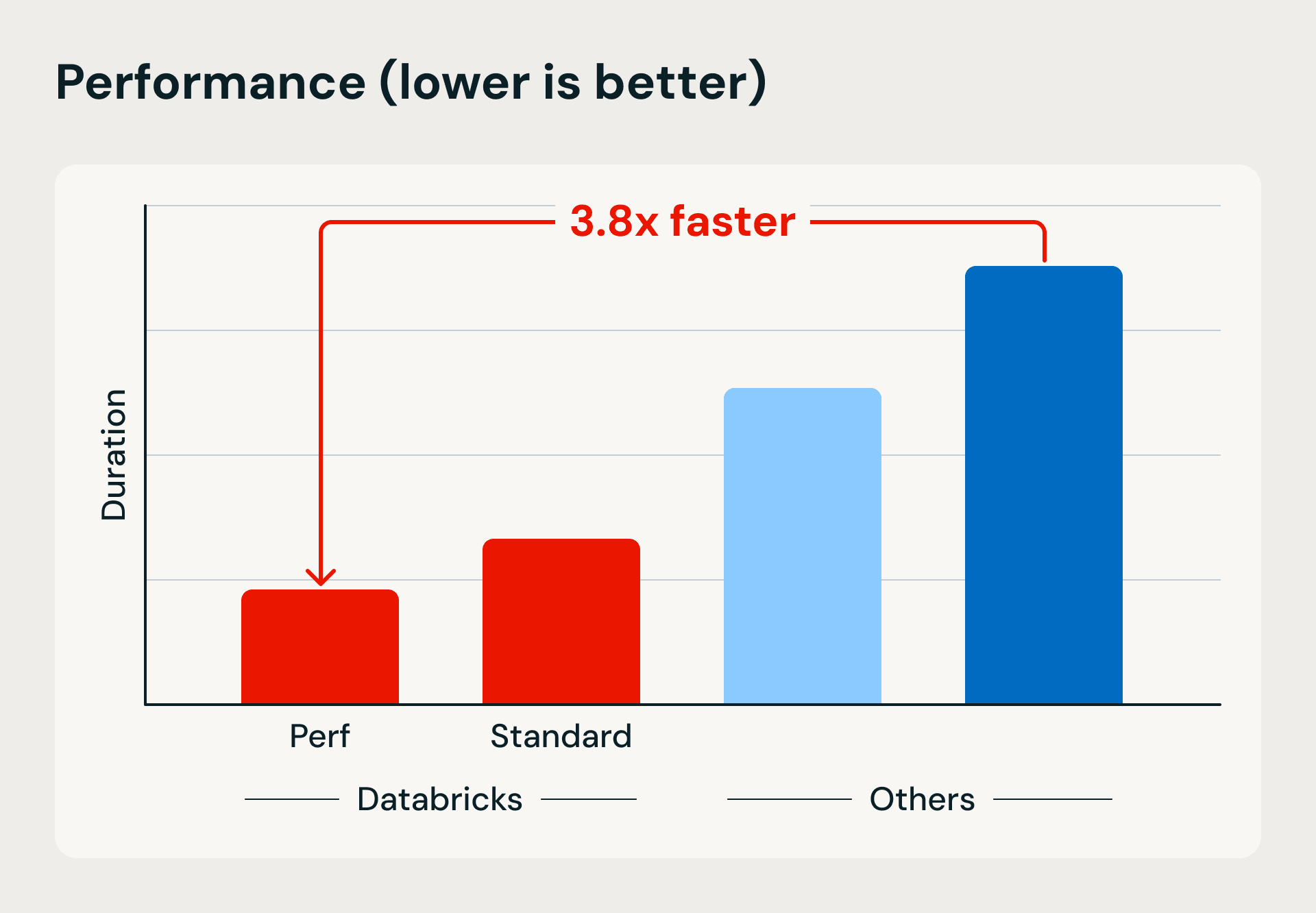
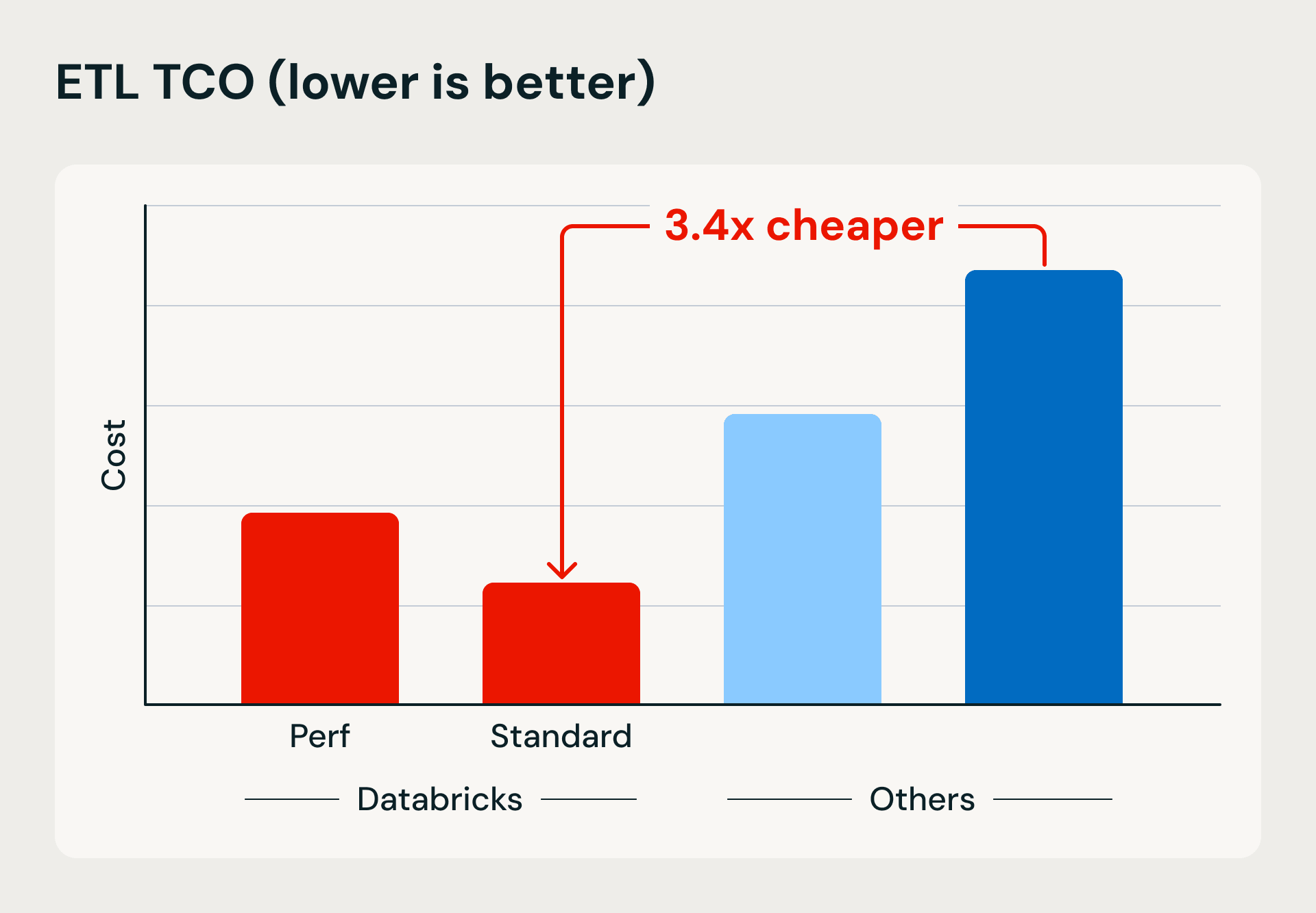
Confronto tra prestazioni e costi che mostra i vantaggi del calcolo serverless di Databricks in termini di velocità di esecuzione ed efficienza. Il benchmark carica 1 TB in Bronze utilizzando Lakeflow Jobs e upsert basati su merge, quindi affina e deduplica i dati in tabelle Silver e Gold.
Dopo aver trasferito le nostre pipeline Databricks al calcolo 'serverless', HP ha realizzato un risparmio cloud di oltre il 32% e ha diminuito il runtime combinato dei processi del 36%. La gestione dell'infrastruttura senza sforzo fornita da 'serverless' ha reso questa decisione una scelta ovvia e strategica. —Luis Alonso, Head of Data Strategy & Engineering presso HP Marketing
Spark Declarative Pipelines serverless su Google Cloud hanno ridefinito il nostro approccio in Uplight, consentendoci di eseguire carichi di lavoro ETL più del doppio della velocità mantenendo bassi i costi. La facilità d'uso, l'ottimizzazione automatica e l'efficienza del calcolo serverless rendono la scalabilità più gestibile e ci consentono di dare la priorità alla fornitura di valore ai nostri clienti. —Micaela Christopher, Director of Data Science & Engineering presso Uplight
Storicamente, il passaggio dai dati grezzi al livello silver ci richiedeva circa 16 minuti, ma dopo il passaggio a serverless, sono solo circa 7 minuti. —Aaron Jepsen, Director IT Operations presso Jet Linx Aviation
Il significativo miglioramento dei tempi di avvio, combinato con la riduzione della configurazione e della manutenzione di DataOps, migliora notevolmente la produttività e l'efficienza. —Gal Doron, Head of Data presso AnyClip
Serverless è senza manutenzione
Selezione automatica dell'infrastruttura: eliminazione della gestione manuale dei cluster
L'approccio classico alla gestione dei cluster offre agli utenti la massima libertà nella scelta di una delle tante possibili combinazioni di configurazione e nella regolazione della configurazione per soddisfare i mutevoli requisiti di dati e aziendali nel tempo, inclusa la prevenzione di errori di memoria insufficiente o colli di bottiglia delle prestazioni. Il calcolo serverless cambia radicalmente il gioco attraverso la selezione dell'infrastruttura AI. Il sistema monitora continuamente i modelli di carico di lavoro e l'utilizzo delle risorse, scalando automaticamente a istanze più grandi quando vengono rilevati vincoli di memoria ed eseguendo senza problemi il failover a tipi di istanza compatibili durante le interruzioni del provider cloud. Sfruttando la cronologia completa del carico di lavoro e i dati sulle prestazioni in tempo reale, il calcolo serverless prende decisioni ottimali sull'infrastruttura senza intervento umano, con conseguenti 89% in meno di interruzioni rispetto agli ambienti di calcolo classici. Questo approccio automatizzato non solo protegge gli utenti dalle limitazioni del provider cloud, ma consente anche la correzione automatica dei problemi comuni dell'infrastruttura, rendendo il calcolo serverless l'offerta di calcolo più stabile e affidabile di Databricks.
Con serverless [...], abbiamo ottenuto un miglioramento di 3-5 volte nella latenza. Ciò che prima richiedeva 10 minuti ora richiede solo 2-3 minuti. —Bryce Dugar, Data Engineering Manager presso Cincinnati Reds
La disponibilità di opzioni serverless semplifica l'overhead sulla manutenzione ingegneristica e l'ottimizzazione dei costi. Questa mossa si allinea perfettamente con la nostra strategia generale di migrare tutte le pipeline ad ambienti serverless all'interno di Databricks. —Bala Moorthy, Senior Data Engineering Manager presso Compass
Aggiornamenti versionless per miglioramenti automatici di prestazioni e sicurezza
Forse la capacità più trasformativa del calcolo serverless è la sua architettura versionless, che elimina la necessità di aggiornamenti manuali del runtime (DBR). Tenersi al passo con l'ultimo runtime porta significativi miglioramenti delle prestazioni. Il calcolo serverless reimmagina radicalmente questo processo attraverso un'architettura rivoluzionaria che consente lo scambio DBR senza interruzioni senza modifiche sostanziali. Solo nell'ultimo anno, Databricks ha eseguito automaticamente 25 aggiornamenti DBR su oltre 4,5 miliardi di carichi di lavoro con uno straordinario tasso di successo del 99,998%. Anche nei rari casi in cui vengono rilevati problemi, i carichi di lavoro vengono automaticamente riportati alla versione stabile precedente mentre i problemi vengono risolti in background, garantendo operazioni ininterrotte. I risultati parlano da soli: la combinazione di miglioramenti automatici della selezione dell'infrastruttura e aggiornamenti versionless ha portato a un miglioramento del rapporto prezzo-prestazioni di oltre l'80% in meno di un anno, senza richiedere agli utenti di toccare il carico di lavoro. Questo approccio versionless significa che il calcolo serverless migliora continuamente, fornendo automaticamente le ultime ottimizzazioni Spark, patch di sicurezza e miglioramenti delle prestazioni, mentre i team di data engineering si concentrano interamente sulla creazione di valore aziendale piuttosto che sulla gestione degli aggiornamenti dell'infrastruttura.
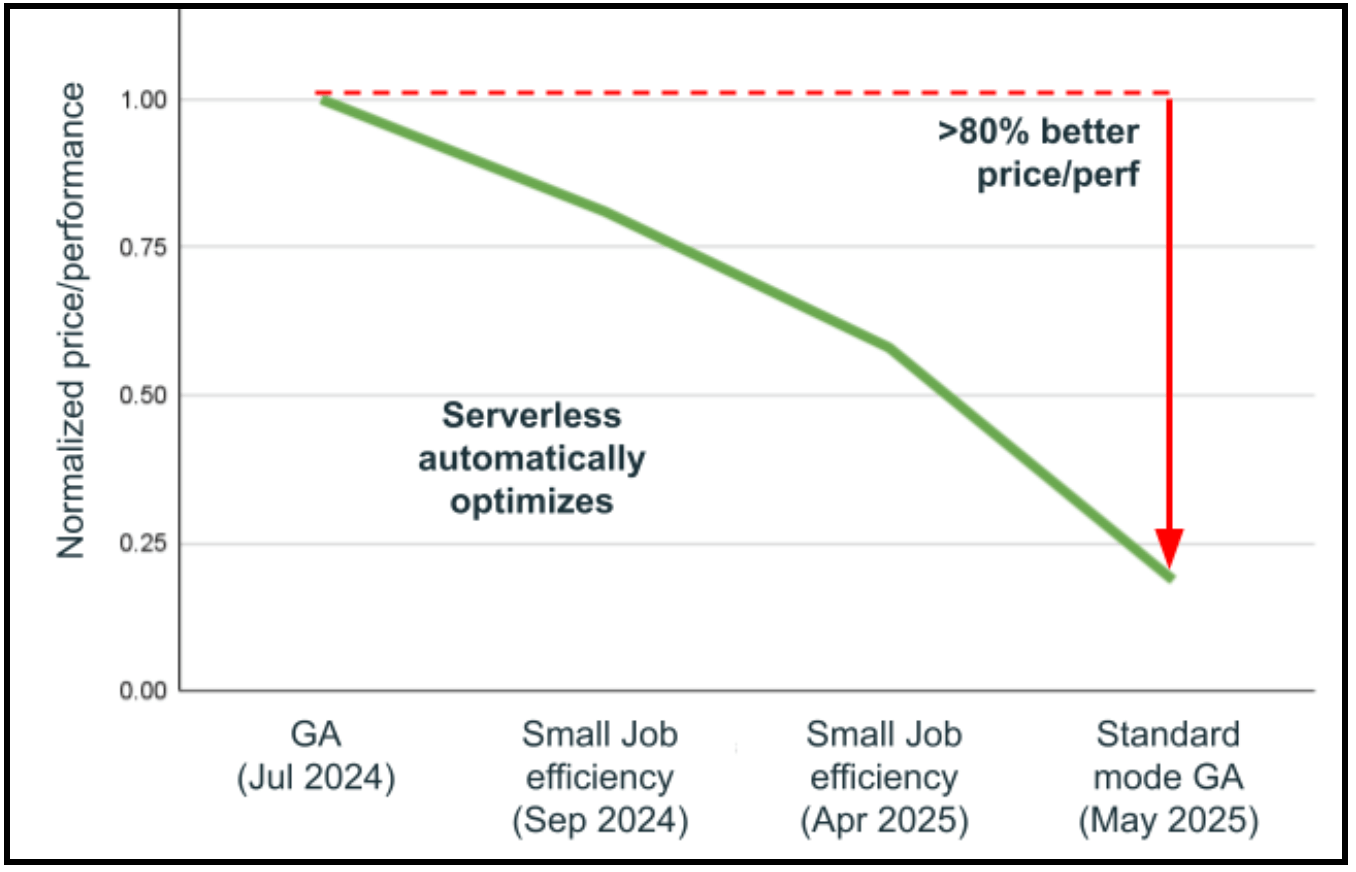
Altre funzionalità serverless
Il calcolo serverless offre ora un set completo di funzionalità avanzate, tra cui:
- Gli ambienti basati sull'area di lavoro consentono agli amministratori di gestire centralmente gli ambienti utente con la memorizzazione automatica nella cache per un avvio rapido.
- Il supporto per i processi Scala offre lo sviluppo IDE locale con funzionalità di distribuzione JAR fat.
- Il supporto GPU, inclusi A10 e H100, e il supporto SparkML aprono serverless al machine learning e ai carichi di lavoro GenAI.
- Sospendi e riprendi semplifica notevolmente lo sviluppo e il debug potendo acquisire snapshot degli stati di calcolo correnti e riprendere il lavoro in un secondo momento senza perdere alcun lavoro e senza dover pagare per i cluster.
- Le funzionalità avanzate di gestione dei costi includono limiti di velocità (in arrivo), durata prevista della query con avvisi e tabelle di sistema espanse per un'analisi dettagliata dei costi.
Queste aggiunte rafforzano la posizione del calcolo serverless come la piattaforma di calcolo più capace e intelligente per la data engineering e siamo solo all'inizio.
Inizia oggi il tuo viaggio serverless
L'evidenza è convincente: il calcolo serverless rappresenta l'evoluzione definitiva dell'infrastruttura dati, offrendo semplicità, affidabilità e ottimizzazione delle prestazioni senza precedenti. Con la modalità Standard generalmente disponibile e che offre un risparmio sui costi fino al 70%, non c'è mai stato un momento migliore per passare dalla complessa gestione dei cluster al calcolo intelligente e automatizzato. Sia che tu abbia bisogno dell'esecuzione fulminea della modalità ottimizzata per le prestazioni o dell'efficienza dei costi della modalità Standard, il calcolo serverless elimina la complessità dell'infrastruttura migliorando continuamente i tuoi carichi di lavoro attraverso aggiornamenti DBR automatici e miglioramenti delle prestazioni.
- Iscriviti a un account Databricks serverless
- Calcolo serverless per Notebook, Lakeflow Jobs e Spark Declarative Pipelines
- Guida pratica al calcolo serverless
- Introduzione a SDP
- Demo SDP
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.