La prossima era del Lakehouse aperto: Apache Iceberg™ v3 in anteprima pubblica su Databricks
Prestazioni complete. Interoperabilità completa. Nessun compromesso.
di Ryan Blue, Daniel Weeks, Jason Reid, Benjamin Mathew e Hao Jiang
• Unity Catalog è l'hub centrale del tuo ecosistema Iceberg: indipendentemente dai motori o dai cataloghi utilizzati dal tuo team, ogni strumento legge gli stessi dati con una governance coerente e granulare
• Iceberg v3 introduce Row Lineage, Deletion Vectors e VARIANT, abilitando l'elaborazione incrementale ad alte prestazioni e i carichi di lavoro sui dati semi-strutturati
• Iceberg v3 pone fine al compromesso tra prestazioni e interoperabilità: Deletion Vectors, Row Lineage e VARIANT fanno parte della specifica aperta, quindi i team di dati ottengono questi guadagni di prestazioni senza sacrificare la compatibilità tra motori
Oggi, il supporto di Databricks per Iceberg v3 entra in Public Preview, sbloccando le ultime innovazioni della community Iceberg nativamente sull'open lakehouse. Iceberg v3 segna un importante passo avanti per i formati di tabella aperti, sbloccando casi d'uso nell'elaborazione incrementale dei dati e nell'analisi di dati semi-strutturati che in precedenza richiedevano soluzioni alternative fragili. Oltre a ciò, Iceberg v3 rappresenta una significativa innovazione tecnologica unificando ulteriormente il livello dati di Iceberg e Delta Lake, eliminando la necessità di riscrivere i dati durante la creazione di pipeline interoperabili.
Ecco le novità di Iceberg v3, perché sono importanti e perché Databricks è il posto migliore per eseguire il tuo lakehouse.
Cosa c'è di nuovo in Iceberg v3?
Le tabelle Managed Iceberg v3 di Unity Catalog supportano Row Lineage, Deletion Vectors e VARIANT, sbloccando nuovi casi d'uso e significativi vantaggi prestazionali. Databricks può anche interoperare con queste funzionalità su tabelle Iceberg esterne (tabelle Iceberg registrate in altri cataloghi), consentendo ai clienti di creare agenti e applicazioni AI sui propri dati, indipendentemente da dove risiedono.
Elaborazione Incrementale su Scala: Row Lineage e Deletion Vectors
La maggior parte dei dati arriva come un flusso di modifiche (INSERT, UPDATE, MERGE, DELETE) piuttosto che in batch, tipicamente provenienti da database operazionali, flussi di eventi e API di terze parti. Storicamente, l'elaborazione di queste modifiche richiedeva la risoluzione di due problemi difficili:
- Identificare quali righe sono cambiate nei dataset bronze
- Applicare in modo efficiente tali modifiche ai dataset silver/gold
I team di solito ricorrevano a scansioni complete delle tabelle o a sistemi CDC esterni per rilevare le modifiche, e a costose riscritture di file per applicarle. Ciò si traduceva in pipeline lente, costose da mantenere e soggette a drift e silos di dati.
Ora, il row lineage consente ai team di identificare rapidamente quali righe sono cambiate. Ogni riga in una tabella Iceberg v3 porta un row ID permanente e un numero di sequenza che riflette quando la riga è stata modificata l'ultima volta.
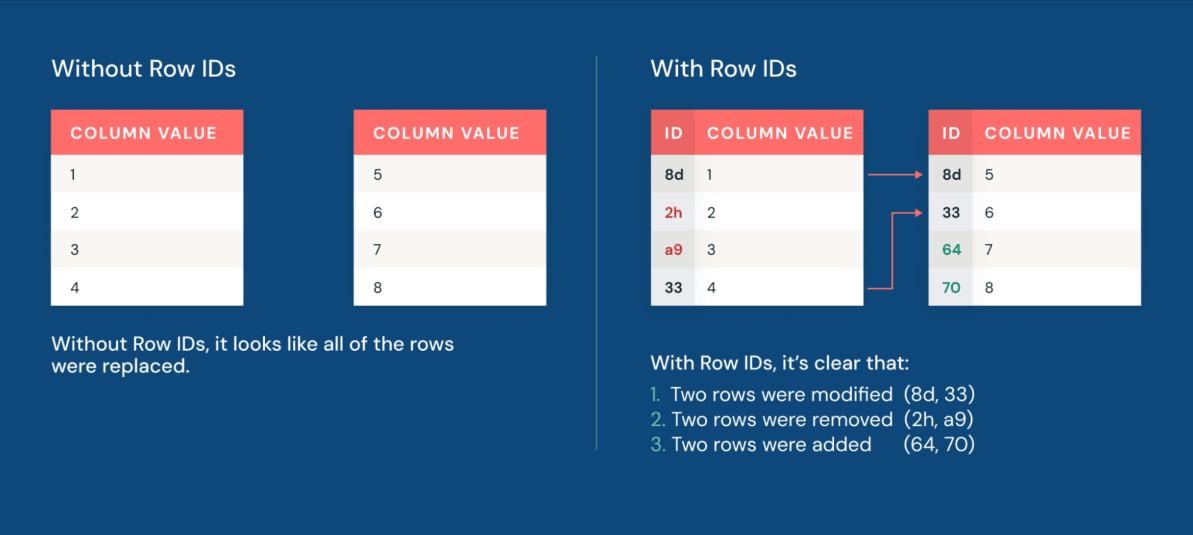
Inoltre, i deletion vectors rendono l'applicazione delle modifiche ai dataset più performante che mai. I deletion vectors consentono a Iceberg di tracciare quali righe sono state logicamente eliminate senza riscrivere immediatamente i file di dati sottostanti. Invece di eliminare fisicamente le righe riscrivendo grandi file Parquet, il motore scrive un file di eliminazione leggero accanto ai dati. Il risultato è una performance di manipolazione dei dati fino a 10 volte più veloce rispetto al tradizionale approccio copy-on-write.

Con i Deletion Vectors ora nativi per Iceberg, Geodis può costruire il suo Lakehouse Iceberg su Databricks senza compromettere le prestazioni o la scelta del motore.
“Ora che i Deletion Vectors sono arrivati su Iceberg, possiamo centralizzare il nostro patrimonio di dati Iceberg in Unity Catalog, sfruttando il motore di nostra scelta e mantenendo prestazioni al top.” —Delio Amato, Chief Architect & Data Officer, Geodis
Insieme, row lineage e deletion vectors rendono il CDC una proprietà nativa della tabella stessa. I team possono costruire pipeline che si concentrano sull'elaborazione incrementale di solo ciò che è effettivamente cambiato, riducendo i costi e accelerando il time-to-insight per ogni analista e data scientist a valle.

Dati Semi-Strutturati come Cittadini di Prima Classe tramite VARIANT
Log, risposte API, clickstream e payload IoT sono fonti di dati semi-strutturati molto preziose. Man mano che si evolvono, i modelli AI possono adattarsi ad essi, imparando direttamente dai segnali del mondo reale in cambiamento.
Tuttavia, storicamente, i team di dati hanno affrontato un doloroso compromesso quando lavoravano con dati semi-strutturati. Un approccio standard era imporre schemi rigidi, ma ciò portava a pipeline fragili che si rompevano ogni volta che i dati upstream cambiavano. Un'altra soluzione canonica era archiviare i dati come dump di stringhe grezze, ma ciò rendeva le query molto complesse e lente. Nessuno dei due approcci era scalabile.
Il tipo VARIANT di Iceberg v3 risolve questo compromesso. VARIANT è un tipo di colonna nativo che archivia payload semi-strutturati insieme a colonne relazionali nella stessa tabella Iceberg. Ciò non richiede alcun flattening, archiviazione in un sistema separato o una pipeline ETL per la normalizzazione. Piuttosto, i team di dati possono ingerire dati semi-strutturati grezzi così come sono e interrogarli con SQL standard.

Panther utilizza VARIANT per alimentare l'ingestione e l'analisi su larga scala di log di sicurezza semi-strutturati.
“Unity Catalog e Iceberg v3 sbloccano la potenza dei dati semi-strutturati tramite VARIANT. Ciò consente l'interoperabilità e la raccolta di log su scala petabyte conveniente.” —Russell Leighton, Chief Architect, Panther
Con VARIANT, i tuoi modelli AI e le pipeline di analisi funzionano direttamente sui dati live ed evolutivi in un'unica tabella governata. Quando compaiono nuovi campi nelle risposte API o nuovi tipi di eventi nei clickstream, sono immediatamente interrogabili senza una migrazione dello schema. Con ottimizzazioni delle prestazioni come lo shredding, i clienti possono beneficiare di prestazioni simili a quelle colonnari sui loro dati semi-strutturati, sbloccando pipeline BI, dashboard e alerting a bassa latenza.
Unity Catalog offre interoperabilità e prestazioni per aziende multi-engine e multi-catalog
Le aziende moderne si affidano a più motori e cataloghi per supportare diversi casi d'uso tra unità di business e sistemi legacy. Unity Catalog è stato progettato per consentire l'interoperabilità e la governance tra cataloghi, ottimizzando al contempo i layout dei dati in base ai pattern di query.
Governance unificata tra cataloghi e motori
Le API aperte di Unity Catalog consentono ai clienti di scrivere una volta e leggere ovunque - niente più duplicazione dei dati o controlli di accesso isolati. UC può federarsi ad altri cataloghi Iceberg, consentendo l'interoperabilità bidirezionale. Tutti i dati Iceberg in Snowflake, AWS Glue, Salesforce e altri cataloghi principali, possono essere letti da Unity Catalog, e tutti i dati in UC possono essere accessibili da queste stesse piattaforme di terze parti tramite API aperte.
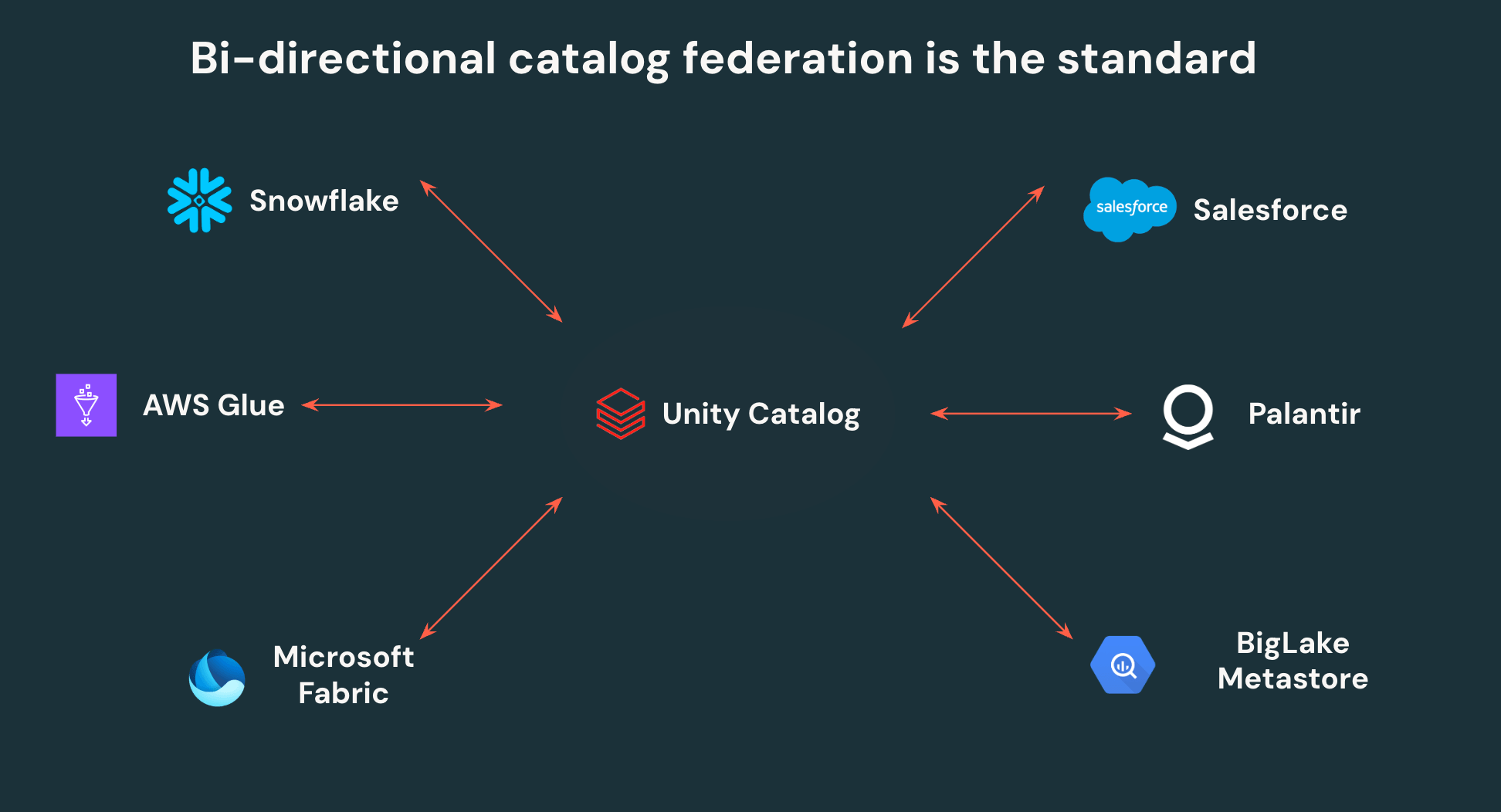
Oltre a ciò, Unity Catalog è il primo catalogo a supportare il controllo degli accessi granulare su motori esterni, consentendo ai team di definire filtri di riga e maschere di colonna una volta e farli applicare ovunque vengano acceduti i dati. Centralizzare la governance su Unity Catalog rende significativamente più facile per i team di sicurezza governare e monitorare il loro lakehouse, dando anche autonomia ai team di dati per puntare qualsiasi strumento al loro lakehouse.

Interoperabilità Delta e Iceberg
Delta Lake con UniForm sblocca l'interoperabilità tra gli ecosistemi Delta Lake e Iceberg dei clienti: scrivi una volta su Delta Lake e leggi come Iceberg da Snowflake, BigQuery, Redshift, Athena, Trino o qualsiasi altro motore Iceberg. Con Iceberg v3 che adotta nativamente Deletion Vectors, Row Lineage e VARIANT, i clienti non affrontano più un compromesso tra le funzionalità di performance di Delta Lake e la compatibilità Iceberg. Il risultato è una singola copia dei dati che serve ogni motore nel tuo stack, senza pipeline di replica da mantenere o rischio di drift. Un importante fornitore di servizi finanziari ha sostituito un costoso servizio di replica full-table con UniForm, consentendo a Snowflake di leggere direttamente dalle tabelle gestite da Unity Catalog.
Ottimizzazione e performance automatizzate
Oltre all'interoperabilità, Databricks riunisce prestazioni, ottimizzazione del layout e governance in un unico sistema, così i team non devono assemblare queste funzionalità da soli. Databricks combina la manutenzione intelligente (Ottimizzazione Predittiva), ottimizzazioni del layout fisico basate su pattern di query (Liquid Clustering Automatico) e governance cross-engine (Unity Catalog) in un unico livello, senza richiedere alcuna configurazione manuale.
Altre offerte Iceberg gestite richiedono ai team di gestire autonomamente la manutenzione delle tabelle, il layout dei file e l'applicazione delle policy di accesso. Su Databricks, queste funzionalità sono unificate e automatiche, eliminando un'intera classe di overhead operativo e preservando al contempo la piena portabilità dei dati.
Inizia con Apache Iceberg v3 su Databricks
Iceberg v3 su Databricks è oggi in Public Preview! I team possono ora sfruttare le migliori funzionalità di Delta e Iceberg senza compromettere prestazioni e interoperabilità.
Iceberg v3 è disponibile su Databricks Runtime 18.0+ con Unity Catalog abilitato.
Creare una tabella Iceberg gestita da Unity Catalog con v3 abilitato è facile:
Creare una tabella Delta gestita da Unity Catalog con UniForm e v3 abilitato è altrettanto semplice:
Guardando avanti: Iceberg v4
Iceberg v3 unifica il livello dati tra Delta e Iceberg su una base performante e interoperabile – la prossima frontiera è il livello dei metadati. Gli ingegneri Databricks stanno attivamente promuovendo diverse proposte core per Iceberg v4 nella community Apache per rendere i metadati più semplici, veloci e scalabili. Queste includono l'albero dei metadati adattivo, che semplifica la struttura dei metadati in modo che la maggior parte delle operazioni richieda la scrittura di un solo file invece di diversi. Ulteriori proposte includono il supporto per percorsi relativi per un'agevole ricollocazione delle tabelle tra ambienti e un modello di statistiche modernizzato che si estende a tipi di dati più recenti come VARIANT e GEOMETRY. Insieme, questi avanzamenti significheranno un'ingestione più rapida, una pianificazione delle query più efficiente e una gestione delle tabelle più semplice su scala enterprise. Siamo entusiasti di continuare ad avanzare la specifica Iceberg con la community.
Scopri di più al Data and AI Summit
Inizia con Iceberg v3 e unisciti a noi al prossimo Data and AI Summit a San Francisco, dal 15 al 18 giugno 2026, per saperne di più sulla nostra roadmap Iceberg e sul lavoro svolto nell'ecosistema.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.