Dalla conoscenza tribale alle risposte istantanee: come abbiamo sviluppato Reffy su Databricks
- Perché trovare il giusto riferimento del cliente al momento giusto è stata una sfida persistente per le vendite e il marketing di Databricks.
- Come abbiamo creato Reffy, un'app agentica full-stack che utilizza RAG, AI Search, AI Functions e Lakebase, per rendere immediatamente ricercabili oltre 2.400 storie di clienti.
- Dal suo lancio nel dicembre 2025, oltre 1.800 dipendenti di Databricks hanno eseguito più di 7.500 query su Reffy.
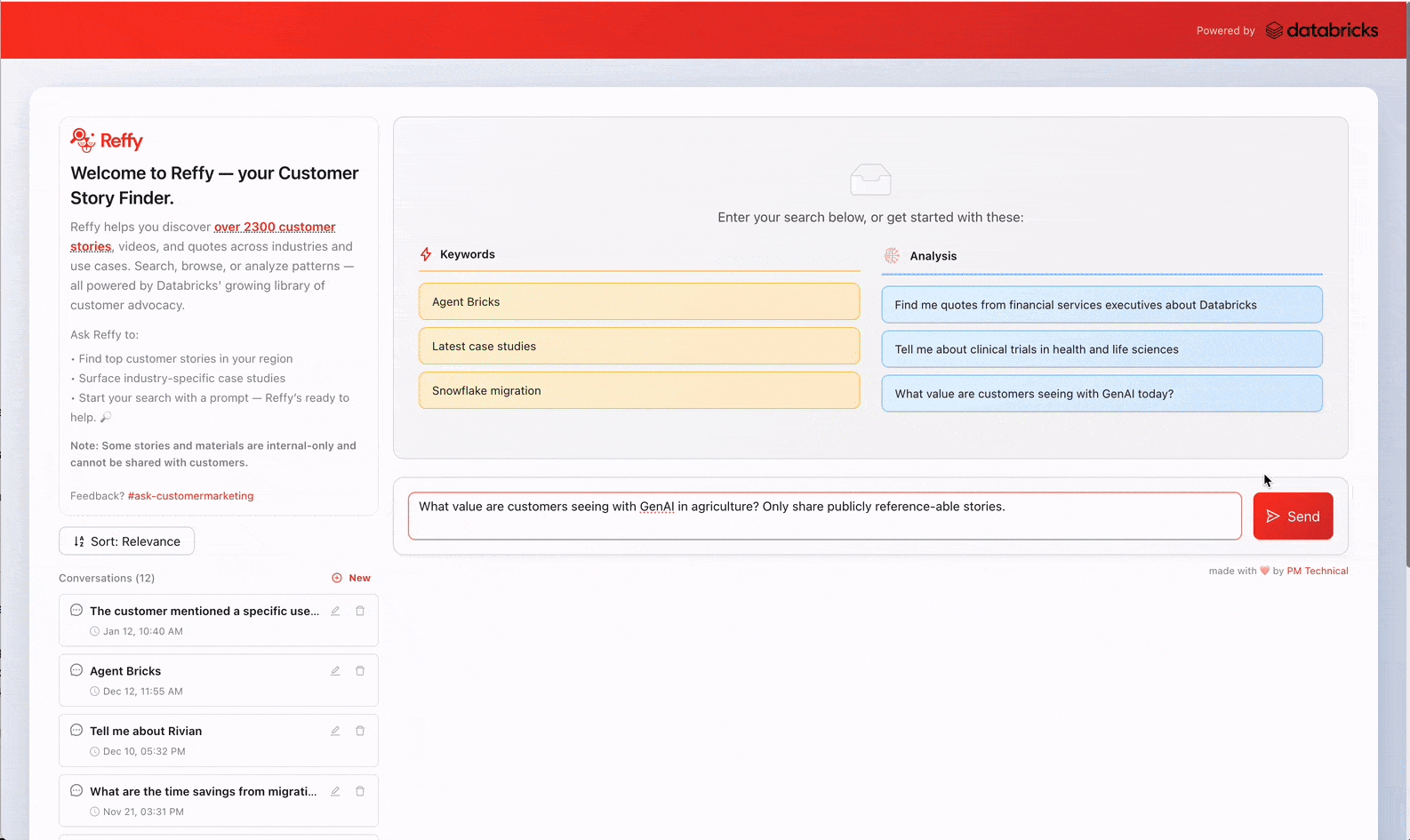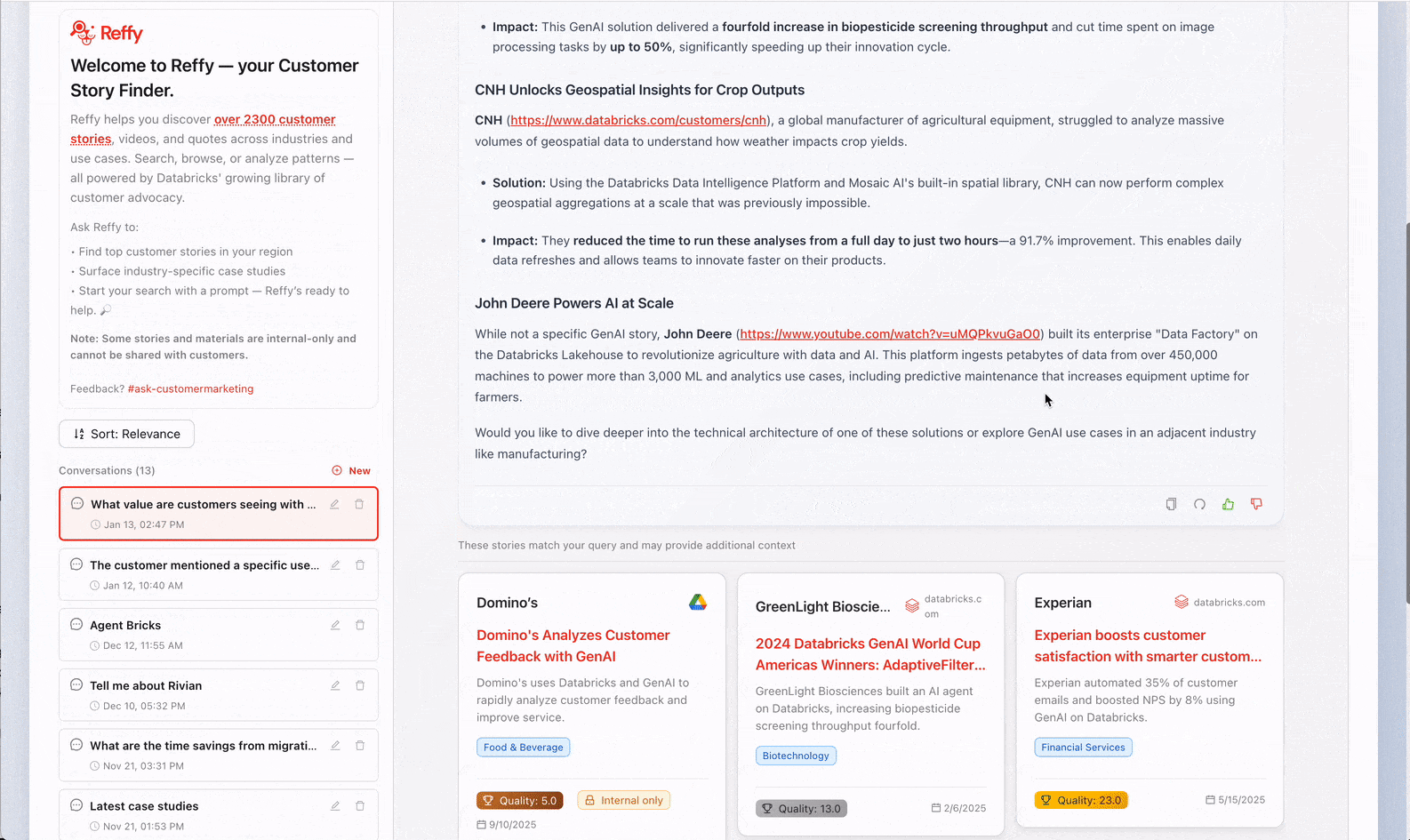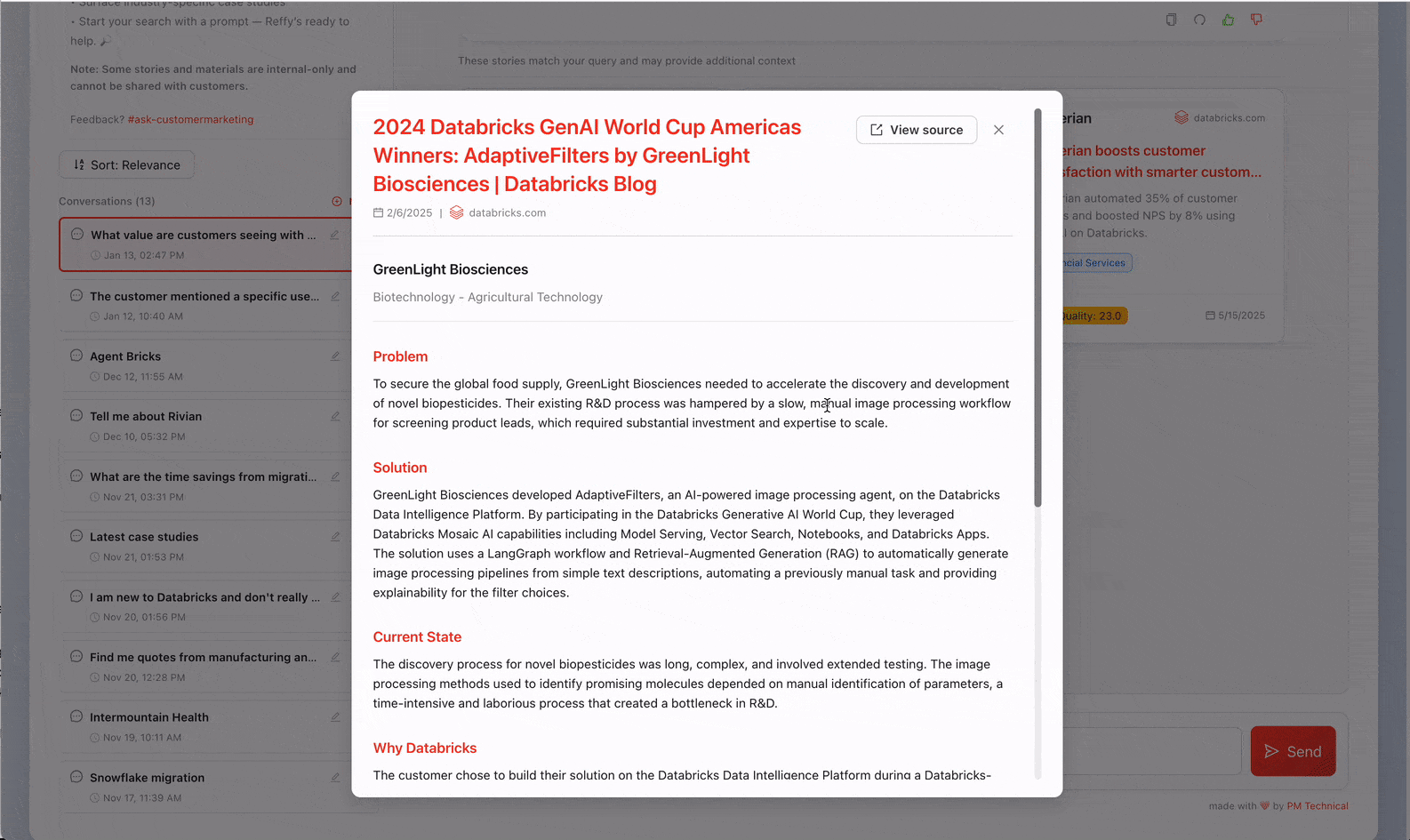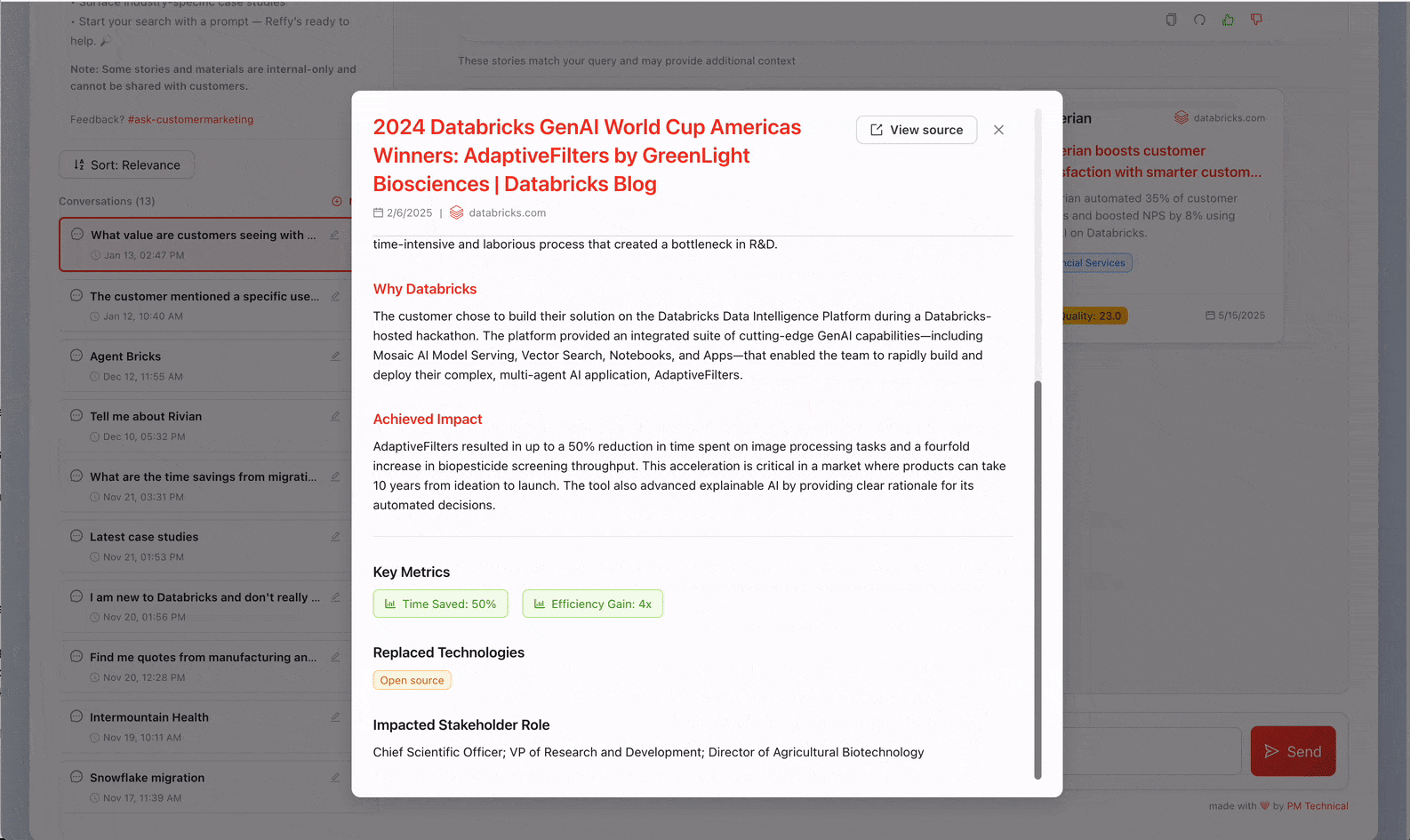
Trovare la storia di successo del cliente giusta al momento giusto è sorprendentemente più difficile di quanto dovrebbe essere. Per migliorare la produttività dei dipendenti, abbiamo creato Reffy, un'app che consente agli utenti di scoprire e analizzare oltre 2.400 referenze di clienti Databricks, fornendo risposte personalizzate, analisi incrociate delle storie, citazioni e altro ancora. Nei suoi primi due mesi, oltre 1.800 persone dei team vendite e marketing di Databricks hanno eseguito più di 7.500 query su Reffy. Questo si traduce in uno storytelling più pertinente e coerente, un'esecuzione più rapida delle campagne e la certezza che le testimonianze dei clienti vengano utilizzate su larga scala. Rendendo queste storie facili da trovare e da consultare, abbiamo risolto il problema della conoscenza tribale legata alle referenze dei clienti e abbiamo sbloccato il prezioso lavoro di tante persone che le hanno raccolte nel corso degli anni.
In questo articolo approfondiremo le motivazioni alla base di Reffy, la soluzione completa di Databricks, il suo impatto sulla nostra organizzazione e come intendiamo scalarla ulteriormente a livello interno.
La sfida di democratizzare la conoscenza tacita
"Chi altro lo ha fatto?" è una domanda che ogni venditore si sente rivolgere. Un potenziale cliente è incuriosito dalla tua proposta, ma prima di procedere vuole una prova: un cliente come lui che ha già percorso questa strada. Rispondere dovrebbe essere facile.
Per il nostro team di marketing, le storie dei clienti sono un input fondamentale per quasi ogni iniziativa: campagne, lanci di prodotti, pubblicità, PR, briefing per gli analisti e comunicazioni dirigenziali. Quando queste storie non sono facili da trovare o valutare, i problemi reali si aggravano: le referenze di alto valore vengono sfruttate eccessivamente, i casi d'uso o i settori industriali più recenti vengono trascurati e l'efficacia del marketing viene limitata dalla conoscenza tribale.
Databricks ha migliaia di talk su YouTube, case studies su databricks.com, slide interne, articoli di LinkedIn, post di Medium. Da qualche parte si trova il riferimento perfetto: un'azienda di servizi finanziari in Canada che si occupa di rilevamento di frodi in tempo reale, un rivenditore che ha sostituito un data warehouse legacy, un produttore che sta scalando la GenAI. Ma trovarlo? È qui che le cose si complicano. Le storie sono distribuite su decine di piattaforme senza una ricerca unificata e, quando si trova qualcosa, non si riesce a capire subito se è valido: presenta risultati aziendali credibili o solo affermazioni vaghe?
Quindi, le persone fanno quello che fanno di solito: inviano un messaggio al team di marketing su Slack, scavano in cartelle che ricordano a malapena o chiedono in giro finché qualcuno non trova qualcosa di utilizzabile. A volte trovano oro. Più spesso, si accontentano di qualcosa di "abbastanza buono" o rinunciano del tutto, senza mai sapere se la storia perfetta era sempre stata a portata di mano.
Chiaramente, avevamo bisogno di un modo migliore per consentire ai team di vendita e marketing di scoprire le storie di successo dei clienti più pertinenti.
Reffy: una soluzione full-stack su Databricks
Per risolvere questo problema, consolidiamo tutte le storie in un'unica tabella, le categorizziamo e usiamo un agente basato su RAG per potenziare la ricerca, il tutto reso disponibile tramite un'app Databricks dall'interfaccia personalizzata. L'architettura copre l'intera piattaforma Databricks: Lakeflow Jobs orchestra le nostre pipeline ETL, Unity Catalog governa i nostri dati, AI Search potenzia il recupero, Model Serving ospita il nostro agente, Lakebase gestisce le letture e le scritture in tempo reale e Databricks Apps fornisce il frontend. Entriamo nel dettaglio.
Sorgenti di dati & ETL
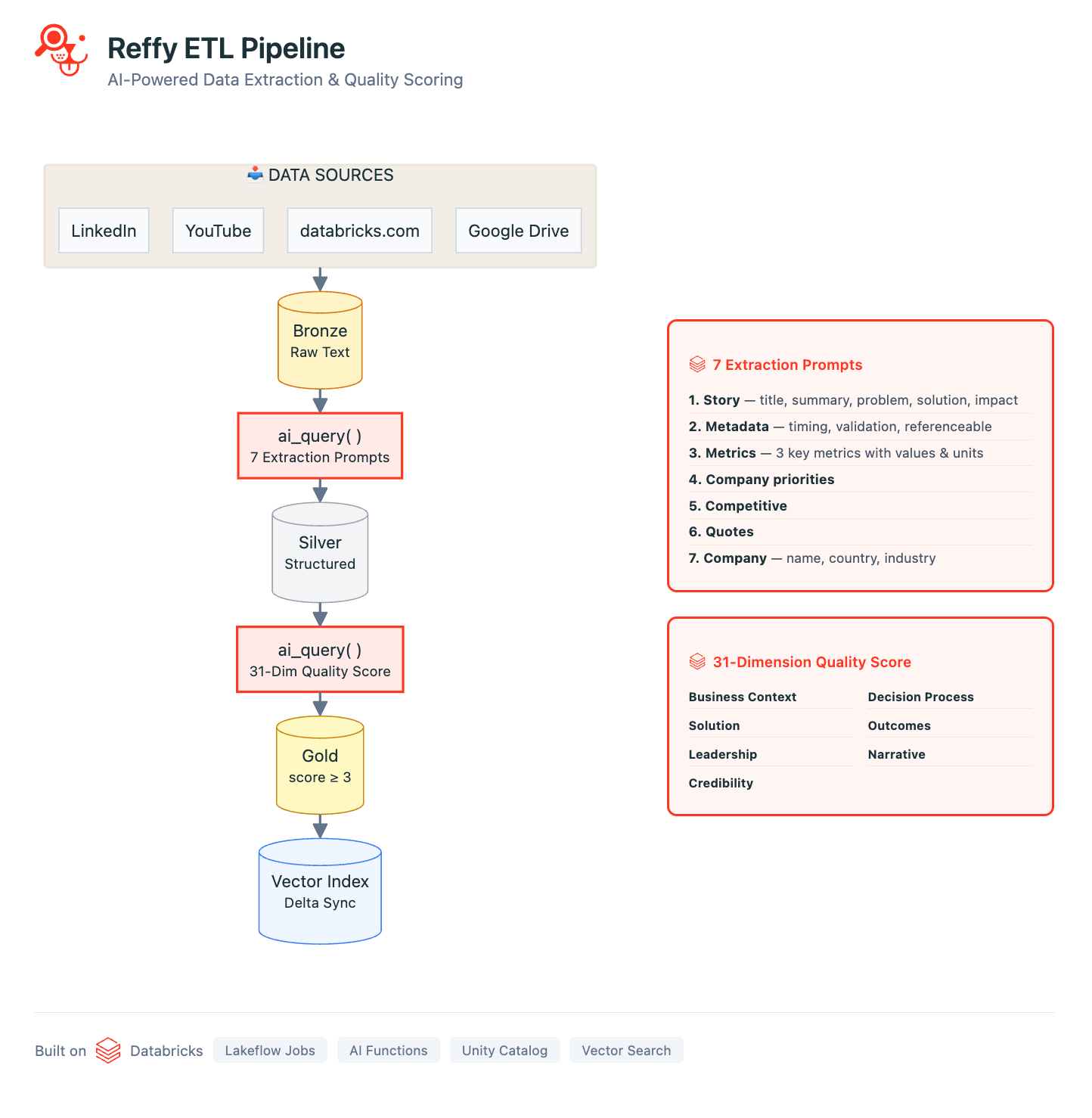
La nostra pipeline è definita in una serie di Databricks Notebook orchestrati con Lakeflow Jobs. La pipeline inizia raccogliendo il testo delle storie da tutte le nostre fonti di dati: usiamo librerie Python standard di web scraping per raccogliere le trascrizioni di YouTube, gli articoli di LinkedIn/Medium e tutte le storie pubbliche dei clienti su databricks.com. Utilizzando gli script di Google Apps, consolidiamo anche il testo di centinaia di presentazioni e documenti Google interni in un unico Foglio Google. Tutte queste fonti vengono elaborate con metadati di base e salvate in una tabella Delta Lake 'Bronze' in Unity Catalog (UC).
Ora abbiamo tutte le nostre storie in un unico posto, ma non abbiamo ancora alcuna informazioni dettagliate sulla loro qualità. Per rimediare a questo, classifichiamo il testo applicando un rigoroso sistema di punteggio a 31 punti (sviluppato dal nostro Value team) a ogni storia tramite AI Functions. Usiamo un prompt per chiedere a Gemini 2.5 di giudicare la qualità complessiva della storia identificando la sfida di business, la soluzione, la credibilità del risultato e perché Databricks si trovasse in una posizione unica per fornire valore. Giudicare le storie in questo modo ci permette anche di escludere quelle di qualità più bassa da Reffy. Il prompt estrae anche metadati chiave come paese e settori industriali, prodotti utilizzati, concorrenza e citazioni, e aggiunge un tag alle storie a seconda che siano condivisibili pubblicamente o solo per uso interno. Questo set di dati arricchito viene salvato in una tabella 'Silver' in UC.
Le fasi finali dell'ETL includono il filtraggio delle storie con punteggio basso e la creazione di una nuova colonna 'summary' che concatena i componenti essenziali della storia. L'idea è semplice: sincronizziamo questa tabella 'Gold' con un indice Databricks AI Search, con la colonna di riepilogo che contiene tutte le informazioni essenziali di cui un LLM avrebbe bisogno per abbinare le storie dei clienti alle query.
AI agentiva
Utilizzando il framework DSPy, definiamo un agente di chiamata a strumenti in grado di cercare i riferimenti dei clienti più pertinenti con una ricerca ibrida per parole chiave e semantica. Adoriamo DSPy! Gli agenti creati con esso sono facili da testare in modo iterativo in un notebook Databricks senza doverli ridistribuire ogni volta a un endpoint di Model Serving, il che si traduce in un ciclo di sviluppo più rapido. La sintassi è estremamente intuitiva rispetto ad altri framework popolari e include eccellenti componenti di ottimizzazione dei prompt. Se non l'hai ancora fatto, dai assolutamente un'occhiata a DSPy.
Abbiamo strutturato il nostro agente per le storie dei clienti per facilitare una ricerca per parole chiave estremamente rapida e una risposta più lunga da parte del LLM con tanto di ragionamento, a seconda dell'input dell'utente: se si pone una domanda, si ottiene una risposta ben ponderata con le relative fonti, ma se si inseriscono solo alcune parole chiave, Reffy restituirà i risultati migliori in meno di due secondi. Utilizziamo anche il re-ranker di Databricks per AI Search per migliorare i risultati di RAG.
Per garantire una risposta equilibrata e professionale, utilizziamo il seguente prompt di sistema:
L'agente viene registrato in MLflow e distribuito in Databricks Model Serving utilizzando il nostro Agent Framework. Dato che la maggior parte dell'elaborazione viene eseguita dal fornitore del modello, possiamo cavarcela con la distribuzione su una piccola istanza CPU, risparmiando sui costi dell'infrastruttura rispetto alle GPU.
L'app Databricks
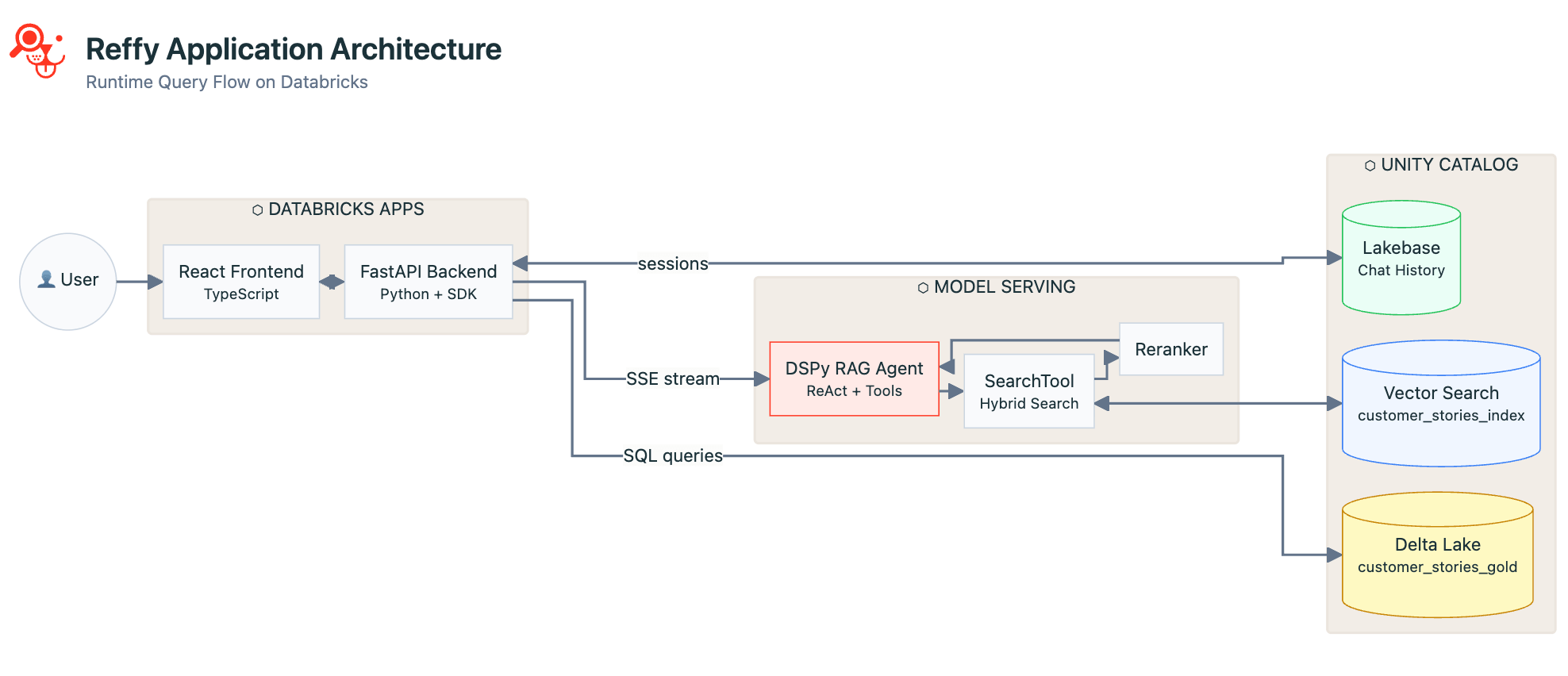
Ora che i dati sono stati puliti e indicizzati e l'agente funziona bene, è il momento di creare un'app per legare tutto insieme e renderla accessibile agli utenti non tecnici. Abbiamo scelto un frontend React con un backend Python FastAPI. React è gradevole e reattivo nel browser e supporta l'output in streaming dal nostro endpoint di Model Serving. FastAPI ci consente di sfruttare tutti i vantaggi del Python SDK di Databricks nella nostra app, ovvero:
- Autenticazione unificata: nessuna modifica al codice durante l'autenticazione locale in fase di sviluppo rispetto alla distribuzione in Databricks Apps. Le app hanno le stesse variabili d'ambiente dell'autenticazione locale, quindi il codice funziona senza problemi.
- Ampia copertura delle API — possiamo richiamare Model Serving, eseguire query SQL o qualsiasi altra cosa di cui potremmo aver bisogno da un Databricks Workspace, tutto tramite un unico SDK.
Reffy è principalmente un'app di chat, quindi utilizziamo Lakebase per rendere persistenti la cronologia delle conversazioni, i log e le identità degli utenti per letture e scritture veloci, per il controllo qualità e per un follow-up ponderato quando gli utenti ritornano o avviano nuove conversazioni.
Monitoraggio continuo e metriche
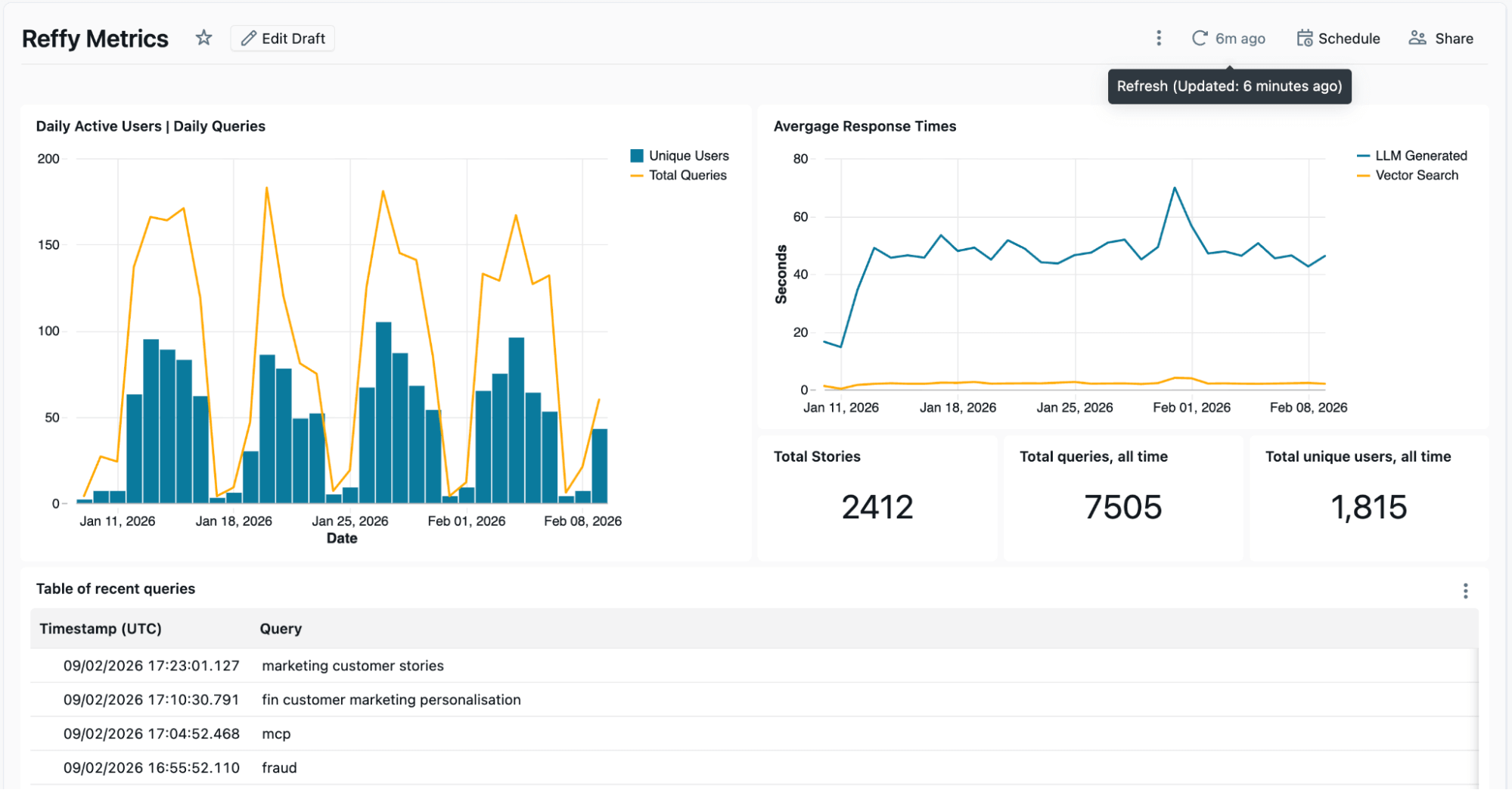
I Log di Lakebase vengono elaborati in un Lakeflow Job separato per far emergere le metriche chiave, come gli utenti attivi giornalieri e i tempi medi di risposta, in una dashboard AI/BI. Questa dashboard ci mostra anche gli input e le risposte recenti e ci siamo spinti oltre, applicando un'altra funzione di IA per riassumere input e risposte in temi recenti ed eseguire un'analisi delle lacune. Vogliamo capire quali storie di clienti sono più popolari e dove potremmo avere delle lacune, e i log che raccogliamo da Reffy ci aiutano proprio a questo. Ad esempio, abbiamo scoperto che gli utenti erano particolarmente desiderosi di trovare storie su Agent Bricks e Lakebase, due dei più recenti prodotti di Databricks.
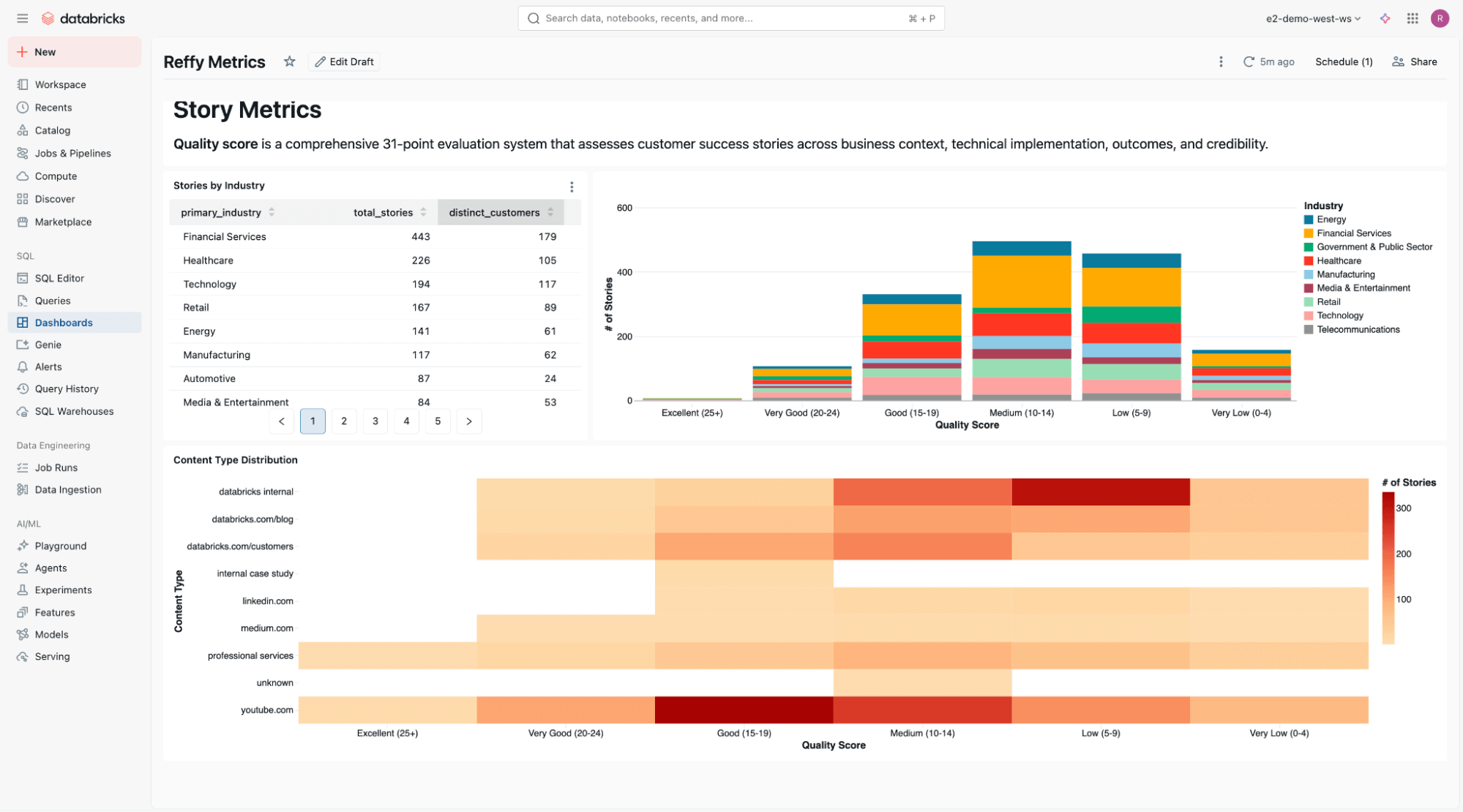
Nella parte inferiore della dashboard, includiamo un'analisi statica della qualità delle storie per tutti i settori industriali e i tipi di contenuto.
Una nota sulla configurazione di sviluppo
La maggior parte dello sviluppo dei progetti avviene in Cursor e, come accennato in precedenza, l'autenticazione unificata tra la CLI di Databricks e l'SDK semplifica le cose. Effettuiamo l'accesso una sola volta tramite la CLI e tutte le nostre build locali di Reffy che utilizzano l'SDK vengono autenticate. Quando vogliamo eseguire test in Databricks Apps, usiamo la CLI per sincronizzare il codice più recente con il nostro Workspace e quindi distribuiamo l'app. Databricks Apps verifica la presenza delle stesse variabili d'ambiente per l'autenticazione che abbiamo impostato in locale, quindi le nostre chiamate a Model Serving e agli SQL Warehouse che si basano sull'SDK funzionano perfettamente! Il nostro devloop iterativo diventa:
- Accedi al Workspace tramite CLI
- Scrivere codice in Cursor
- Testa in locale
- Sincronizza il codice con il workspace & distribuisci l'app
- Test in Databricks Apps
Infine, per garantire una CI/CD e una portabilità adeguate, utilizziamo i Databricks Asset Bundles per raggruppare tutto il codice e le risorse utilizzate da Reffy in un unico pacchetto. Questo bundle viene quindi distribuito tramite GitHub Actions nel nostro workspace di produzione di destinazione.
Cosa abbiamo imparato
Diversi team in Databricks avevano già risolto parti di questo problema in modo indipendente, gravitando naturalmente verso il lavoro più entusiasmante: il livello AI. Tuttavia, l'ingegneria dei dati rimane il fulcro & eseguire correttamente l'ETL, valutare la qualità delle storie e strutturare i dati per un recupero efficace si sono rivelati tanto critici quanto l'agente stesso.
La collaborazione è stata altrettanto essenziale. Le storie dei clienti toccano quasi ogni angolo dell'organizzazione: Vendite, Marketing, Field ingegneria e PR svolgono tutti un ruolo. La creazione di solide partnership con questi gruppi ha plasmato sia il prodotto che i dati che lo alimentano.
Prossimi passi
Anche se il frontend dell'applicazione offre un valore immediato, la vera potenza emergerà collegando Reffy con altre soluzioni in Databricks. Prevediamo di fornire tale connettività tramite un'API e un server MCP, consentendo ai team di accedere alla customer intelligence direttamente all'interno dei loro flussi di lavoro e strumenti esistenti.
Con Databricks e Lakebase, possiamo anche capire come migliaia di utenti interagiscono con Reffy nel tempo. Queste informazioni dettagliate ci permetteranno di perfezionare continuamente lo strumento e di dare forma con cura alle storie aggiunte a questo ecosistema in crescita.
Per i team di Databricks che oggi si confrontano con la ricerca di riferimenti dei clienti, Reffy offre un esempio concreto di ciò che è possibile fare quando queste funzionalità vengono riunite. Per iniziare a creare la tua app agentica su Databricks, scopri di più su Databricks Apps, la nostra guida RAG, Lakebase e Agent Bricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.