Collega qualsiasi sorgente di dati, un'unica piattaforma
Arricchisci i tuoi agenti AI con il contesto aziendale completo.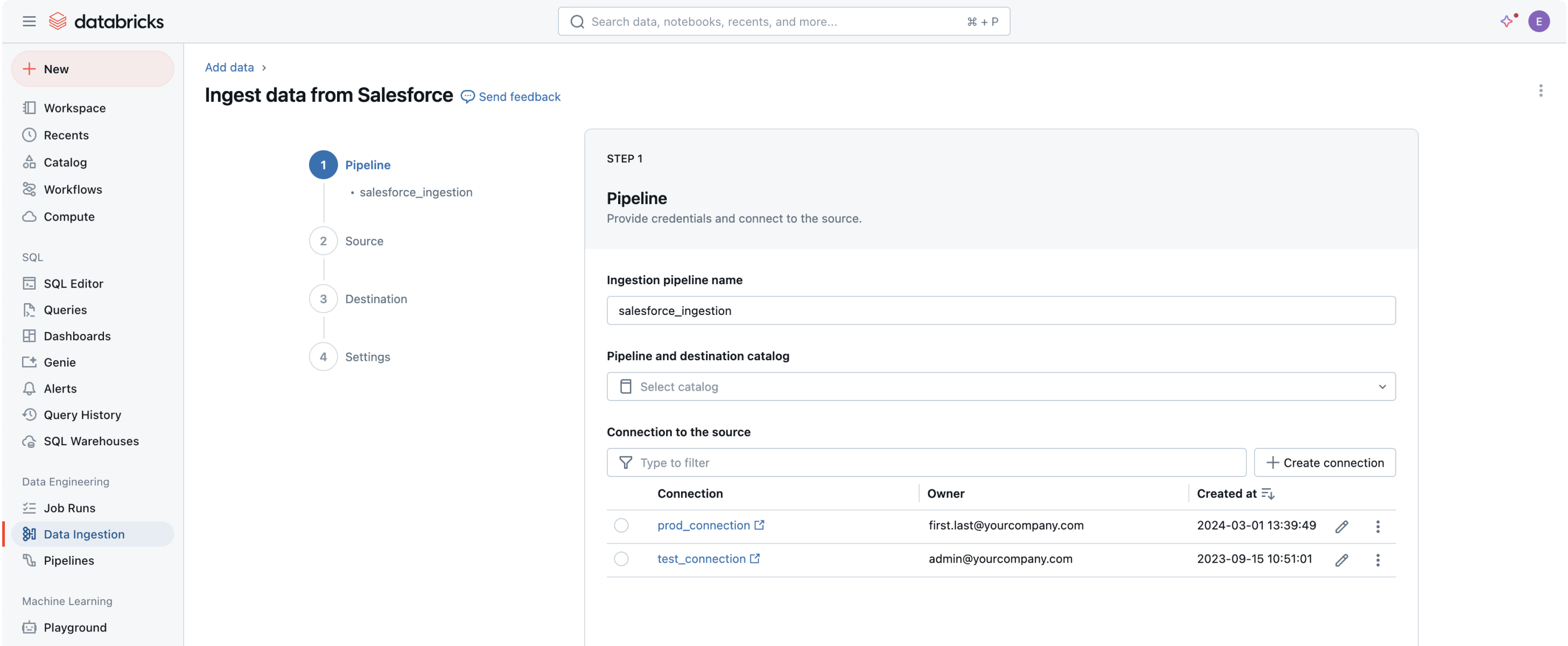

Collega qualsiasi sorgente di dati, un'unica piattaforma
Oltre 100 connettori integrati per applicazioni aziendali, database e origini file forniscono ai tuoi agenti AI un contesto completo e affidabile.Flessibile e facile
I connettori completamente gestiti forniscono una UI e un'API semplici per una configurazione facile e democratizzano l'accesso ai dati. Le funzionalità automatizzate aiutano anche a semplificare la manutenzione della pipeline con un sovraccarico minimo.
Connettori integrati
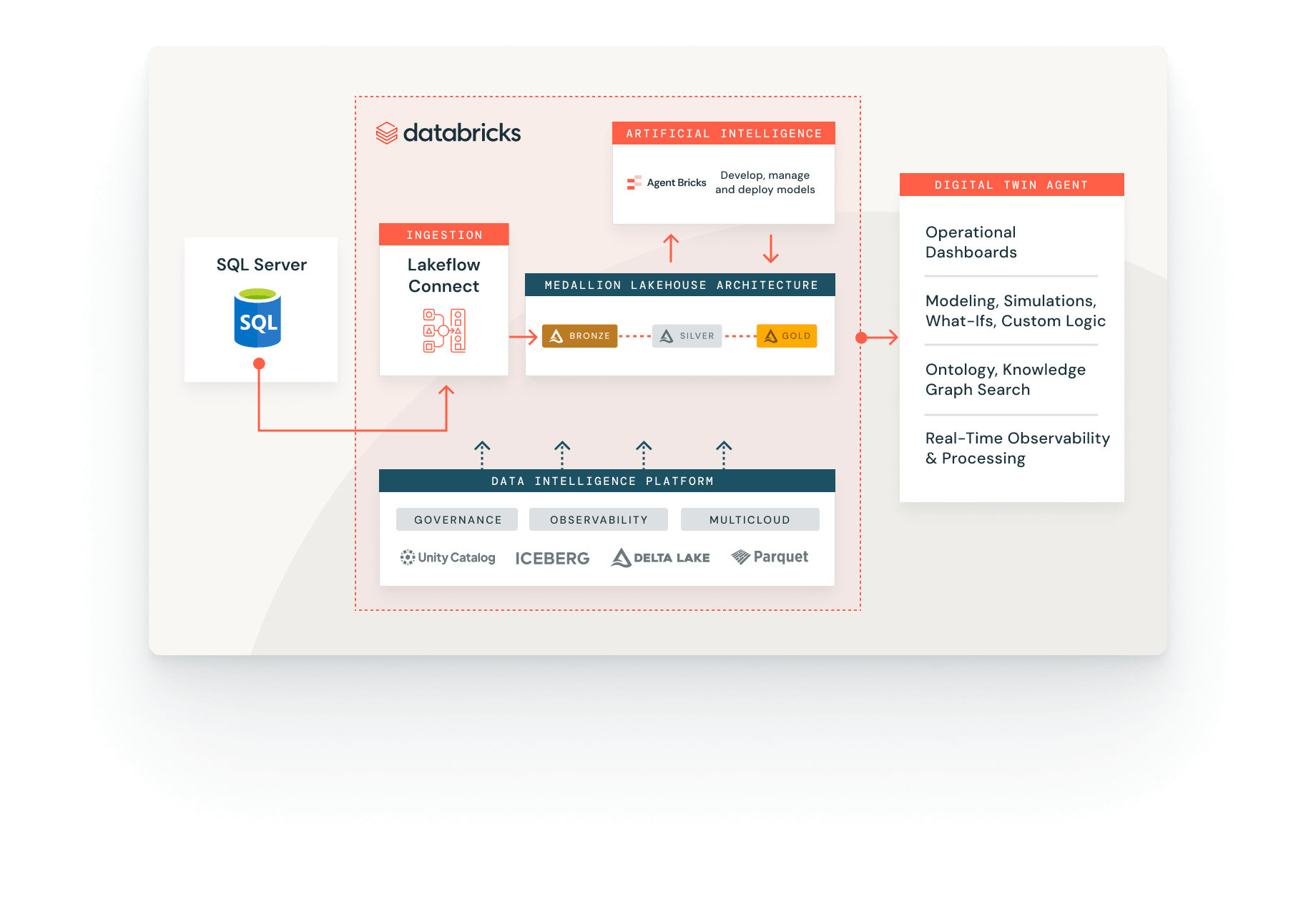
L'ingestione dei dati è completamente integrata con la Data Intelligence Platform. Crea pipeline di ingestione con la governance di Unity Catalog, l'osservabilità di Lakehouse Monitoring e un'orchestrazione fluida con flussi di lavoro per l'analisi, il machine learning e la BI.
Integrazione diretta con agenti IA
Alimenta le tue applicazioni AI e BI a valle con un contesto aziendale ad alta fedeltà. Elimina i silo e fornisci ai tuoi agenti AI una logica di business completa per un ragionamento affidabile.
Robuste capacità di ingestione per le fonti di dati più popolari
Importare tutti i dati nella Data Intelligence Platform è il primo passo per estrarre valore e contribuire a risolvere i problemi di dati più complessi della tua organizzazione.L'interfaccia utente (UI) no-code o una semplice API consente ai professionisti dei dati di operare in autonomia, risparmiando ore di programmazione.
Importa solo nuovi dati o aggiornamenti delle tabelle, rendendo l'acquisizione dei dati veloce, scalabile ed efficiente dal punto di vista operativo.

Esegui l'ingestione dei dati in un ambiente 100% serverless che offre una startup rapida e la scalabilità automatica dell'infrastruttura.

La profonda integrazione con Databricks Unity Catalog offre funzionalità robuste tra cui lineage e qualità dei dati.

Ingestione dei dati con Databricks
Risoluzione dei problemi dei clienti in un'ampia gamma di settori industriali

Misura il rendimento della campagna e mappa il percorso del cliente
Consolida i dati frammentati di annunci e campagne da Meta, Google Ads e TikTok Ads. Acquisisci gli stati storici della piattaforma per eseguire analisi puntuali accurate e creare un percorso cliente unificato.



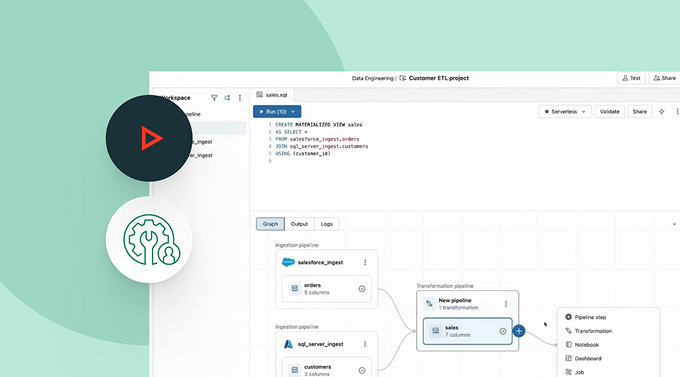


I prezzi basati sull'utilizzo tengono sotto controllo la spesa
Paga solo per i prodotti che utilizzi con una granularità al secondo.Scopri di più
Esplora altre offerte integrate e intelligenti sulla Data Intelligence Platform.
Job di Lakeflow
Fornisci ai team gli strumenti per automatizzare e orchestrare al meglio qualsiasi flusso di lavoro ETL, di analisi o AI, con osservabilità avanzata, alta affidabilità e supporto per una vasta gamma di attività.
Pipeline dichiarative di Apache Spark™
Semplifica l’ETL batch e in streaming grazie a funzionalità automatizzate per la qualità dei dati, il Change Data Capture (CDC), l’ingestione, la trasformazione e la governance centralizzata.

Unity Catalog
Gestisci tutti i tuoi asset di dati con l'unica soluzione di governance unificata e aperta del settore per dati e AI, integrata nella Databricks Data Intelligence Platform.

Delta Lake
Unifica i dati nel tuo lakehouse, di qualunque formato e tipo, per tutti i tuoi carichi di lavoro di analisi e AI.

Genie Code
Crea e gestisci pipeline di dati con un'AI agentica che comprende i tuoi dati.
Guida introduttiva
Esplora la documentazione sull'acquisizione dei dati
Acquisisci dati da varie fonti, su più cloud e tramite Lakeflow Connect.
Tour di Lakeflow Connect
Lakeflow Connect è ora disponibile a livello generale per Salesforce, Workday e SQL Server.
Per accedere in anteprima ad altri connettori, contatta il team del tuo account Databricks.



FAQ sull'ingestione dei dati
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il tuo percorso di trasformazione dei dati