Concentrati sui carichi di lavoro dei dati, non sull'infrastruttura
Spark completamente gestito e senza versione per tutti i tuoi carichi di lavoro di dati e AI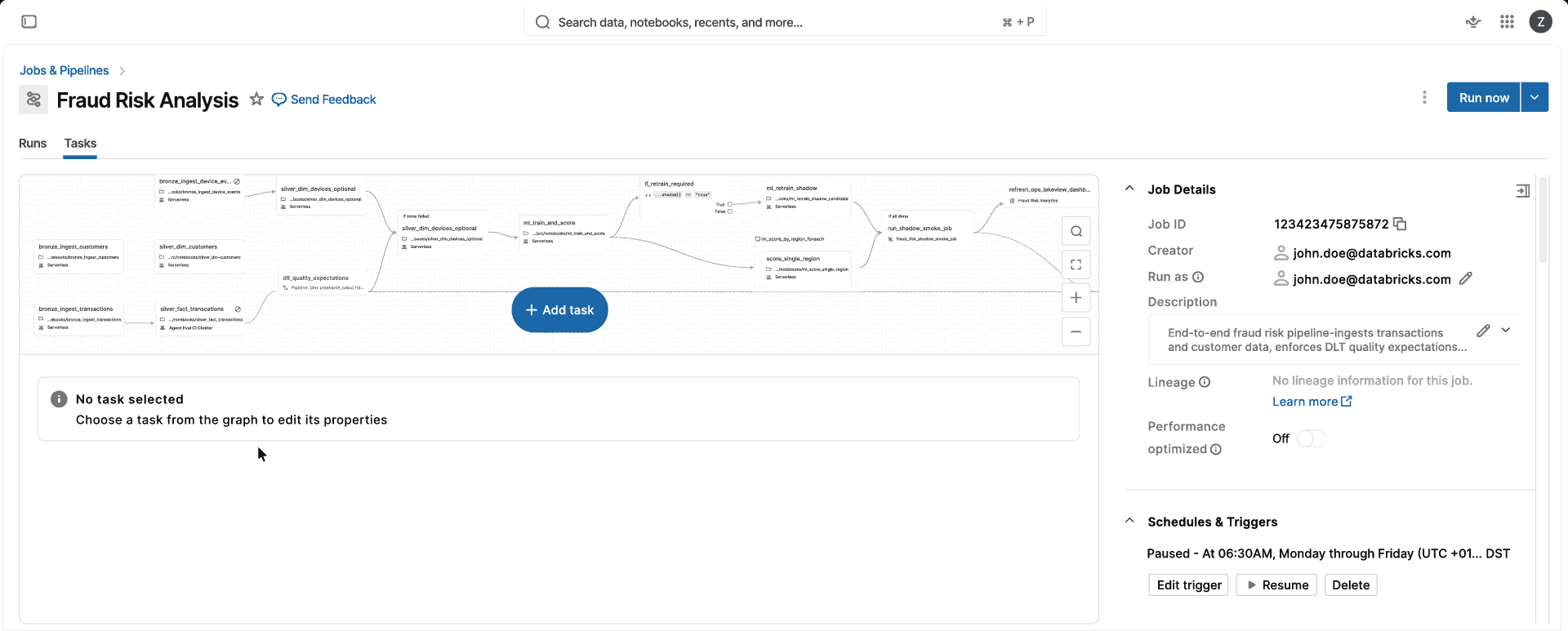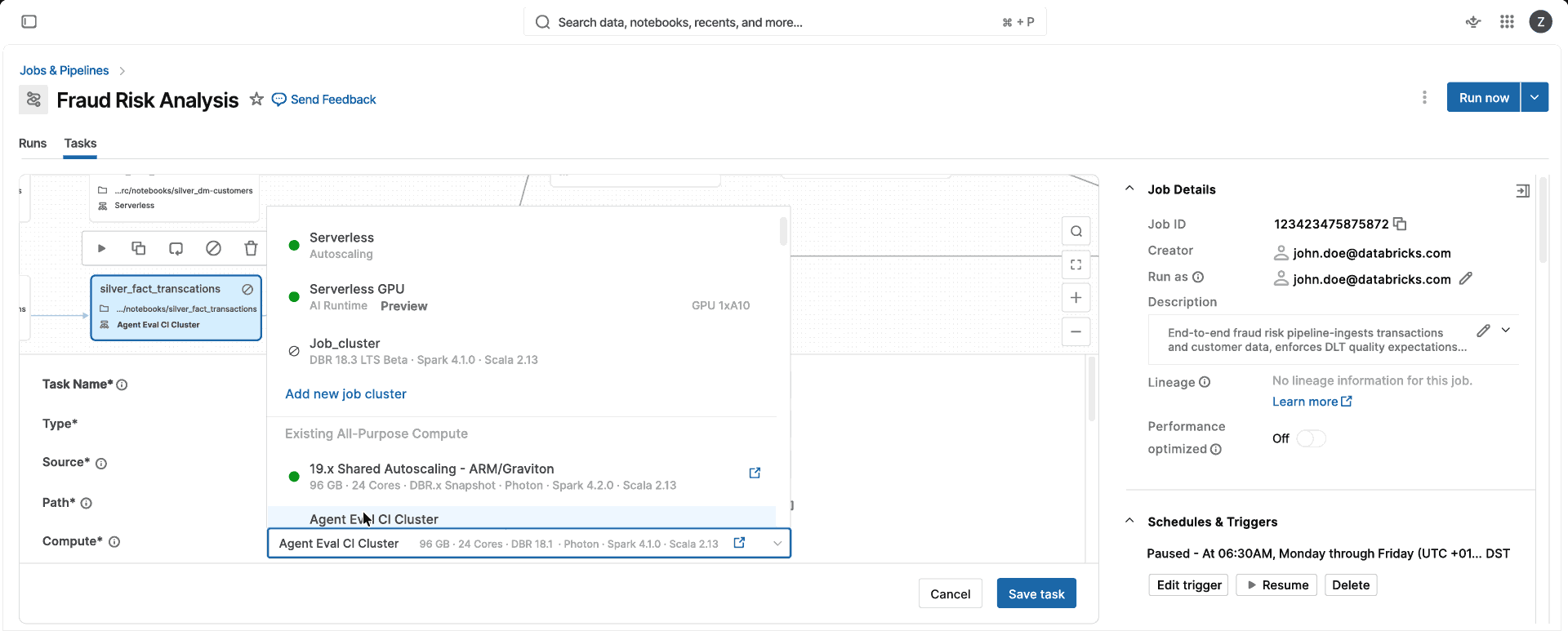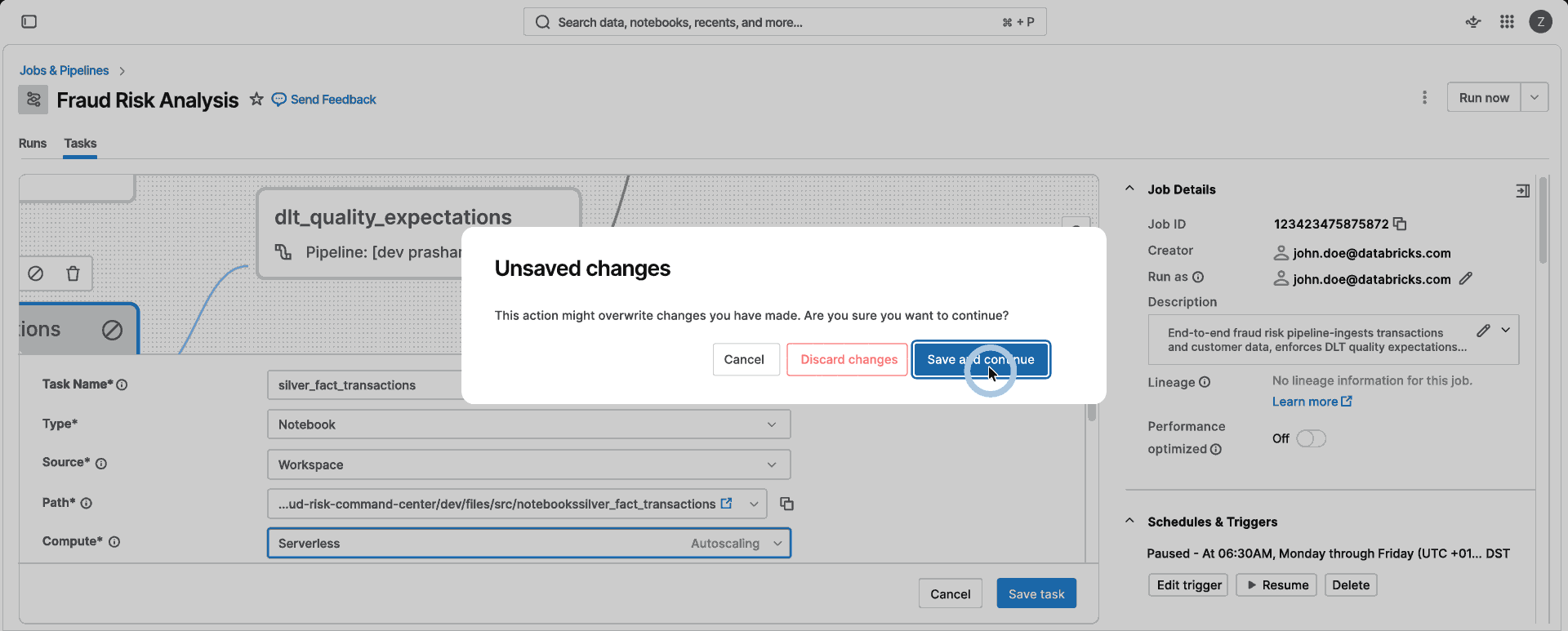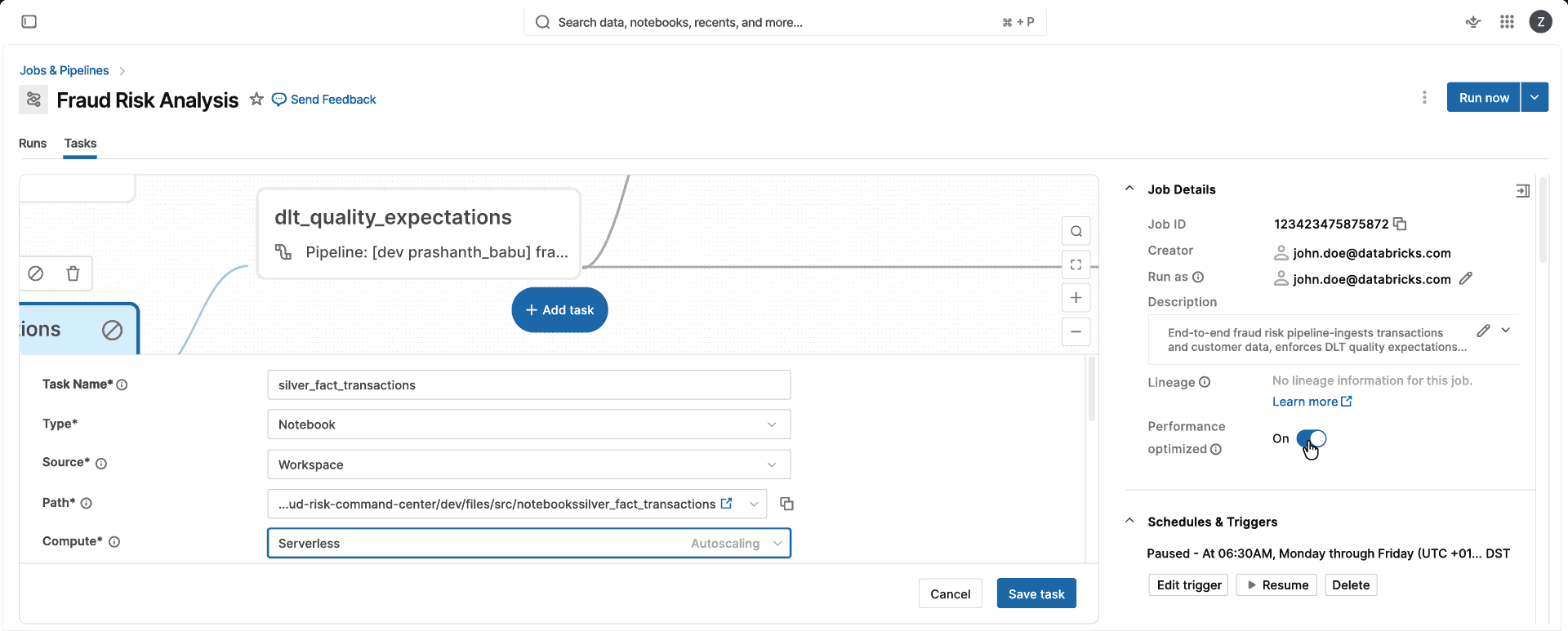
LE MIGLIORI AZIENDE UTILIZZANO IL COMPUTE SERVERLESS
Scegli il tuo obiettivo di business, non l'infrastruttura
Esegui carichi di lavoro di dati e AI su compute che si scalano, si aggiornano e si ottimizzano automaticamente, senza alcuna gestione dell'infrastruttura.Completamente gestito
Un compute. Nessuna decisione da prendere sull'ottimizzazione per CPU, per la memoria o sulla classe di istanza, nessuna configurazione di cluster da gestire. Scegli la modalità Standard o Ottimizzata per le prestazioni e Databricks selezionerà automaticamente per te i tipi di istanza e di compute corretti (singola VM o cluster Spark), in modo che il tuo team possa distribuire prodotti di dati invece di gestire il compute.
Performante
L'architettura serverless si avvia in secondi, non in minuti, carica gli ambienti dalla cache e si ridimensiona automaticamente in base alle esigenze del carico di lavoro. La modalità Standard offre un'elaborazione batch economica, mentre la modalità ottimizzata per le prestazioni esegue in genere i job sensibili alla latenza 2 volte più velocemente dei cluster classici.
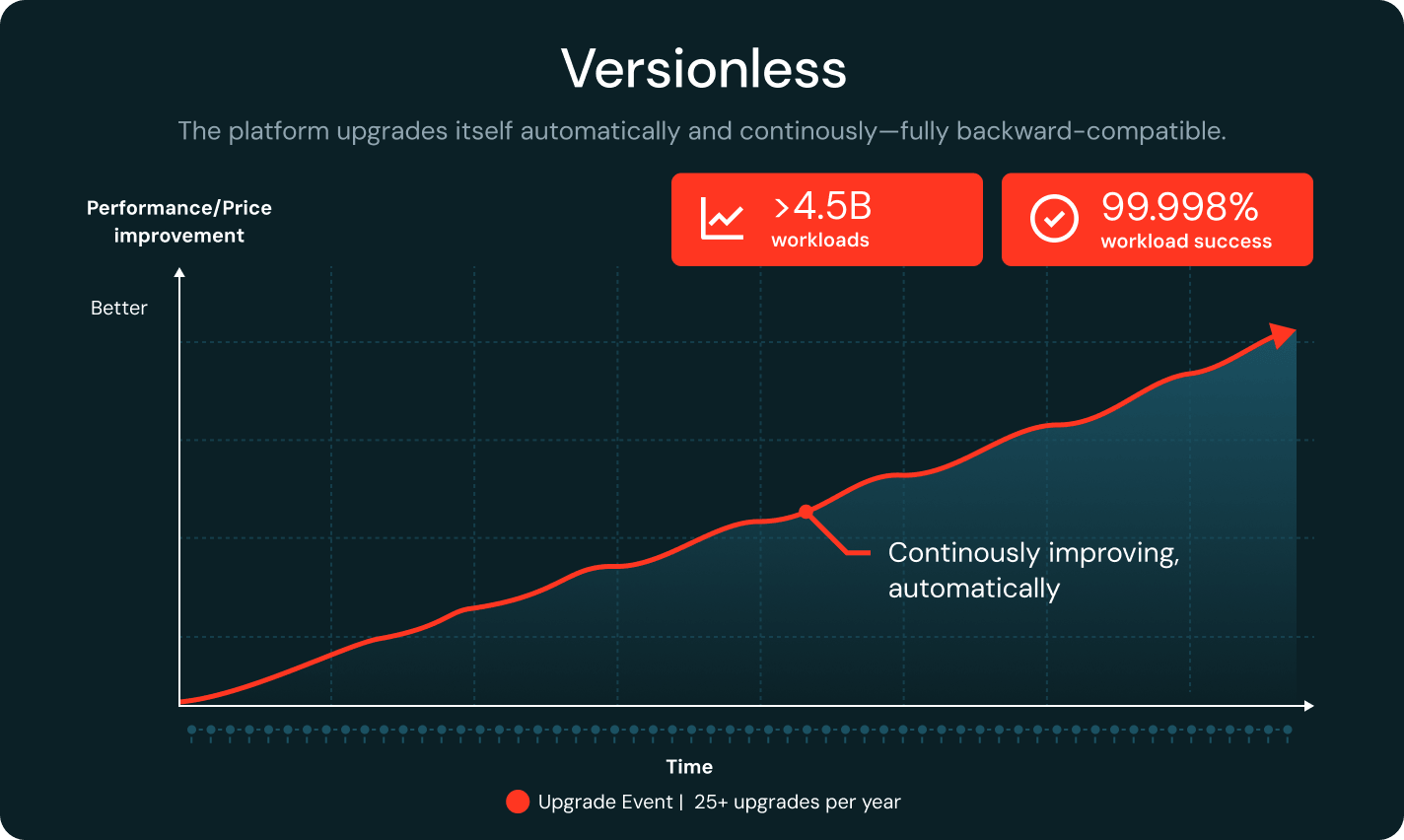
Senza versione
Databricks aggiorna continuamente il runtime, pur rimanendo pienamente retrocompatibile. Il rilevamento delle regressioni pin automaticamente i carichi di lavoro alle versioni stabili. Con oltre 25 aggiornamenti all'anno e una percentuale di successo del carico di lavoro del 99,998%, i team risparmiano fino al 20% del tempo di ingegneria.
compute che funziona e basta
Smetti di gestire l'infrastruttura e start a eseguire i tuoi carichi di lavoro di dati e AI su un ambiente di calcolo completamente gestito, a scalabilità automatica e senza versione.Serverless si aggiorna continuamente e automaticamente, rimanendo pienamente retrocompatibile e mantenendo i carichi di lavoro in esecuzione senza intervento.
Scegli la modalità Standard per carichi di lavoro batch con costi ottimizzati o la modalità a prestazioni ottimizzate per i job sensibili alla latenza, che in genere eseguono i job a una velocità 2 volte superiore rispetto ai cluster classici.
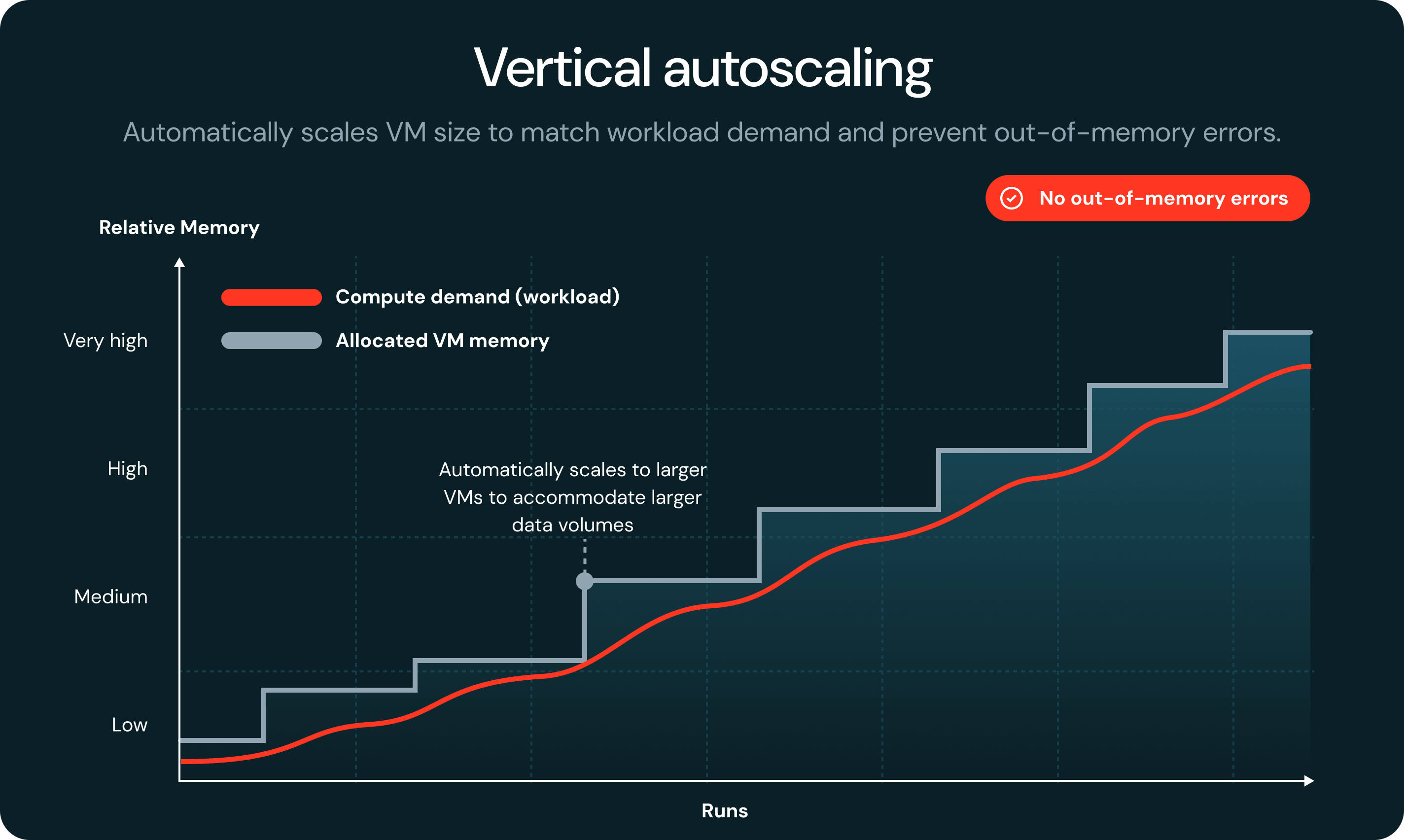
Quando un task esaurisce la memoria, la tecnologia serverless rileva automaticamente l'errore e lo riavvia su una VM più grande, senza errori del job o intervento manuale.
Gli ambienti delle librerie vengono memorizzati nella cache a livello globale, quindi non appena un utente della tua organizzazione utilizza un set specifico di pacchetti, l'ambiente è pronto in pochi secondi per tutti gli altri.
Il Serverless scala il compute in secondi, non minuti, adattandolo automaticamente alle esigenze del carico di lavoro senza la configurazione di cluster.
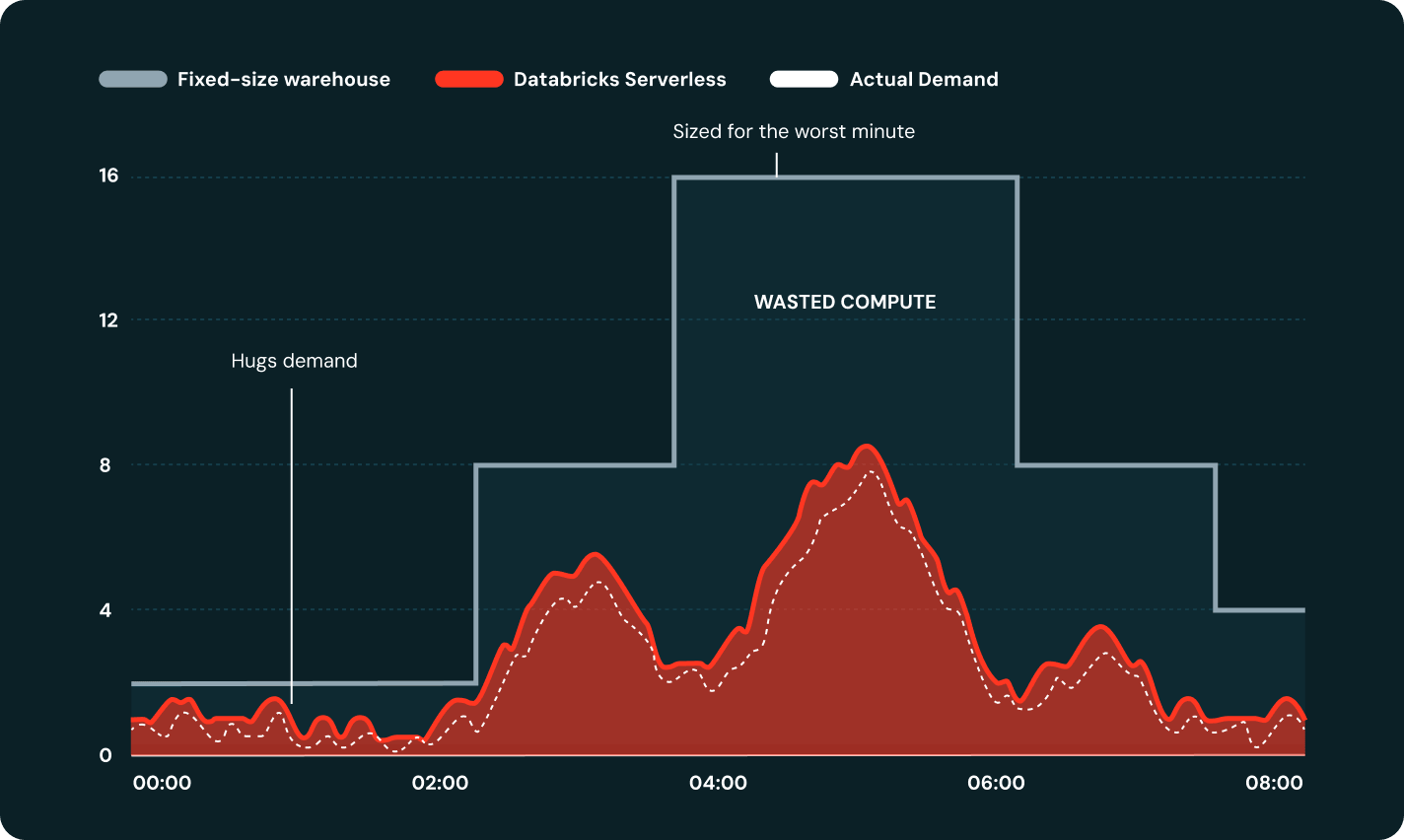
Serverless ritenta automaticamente le attività non riuscite e aggira gli errori a livello di cloud, mantenendo le pipeline nei tempi previsti senza bisogno di intervento manuale.
Altre funzioni
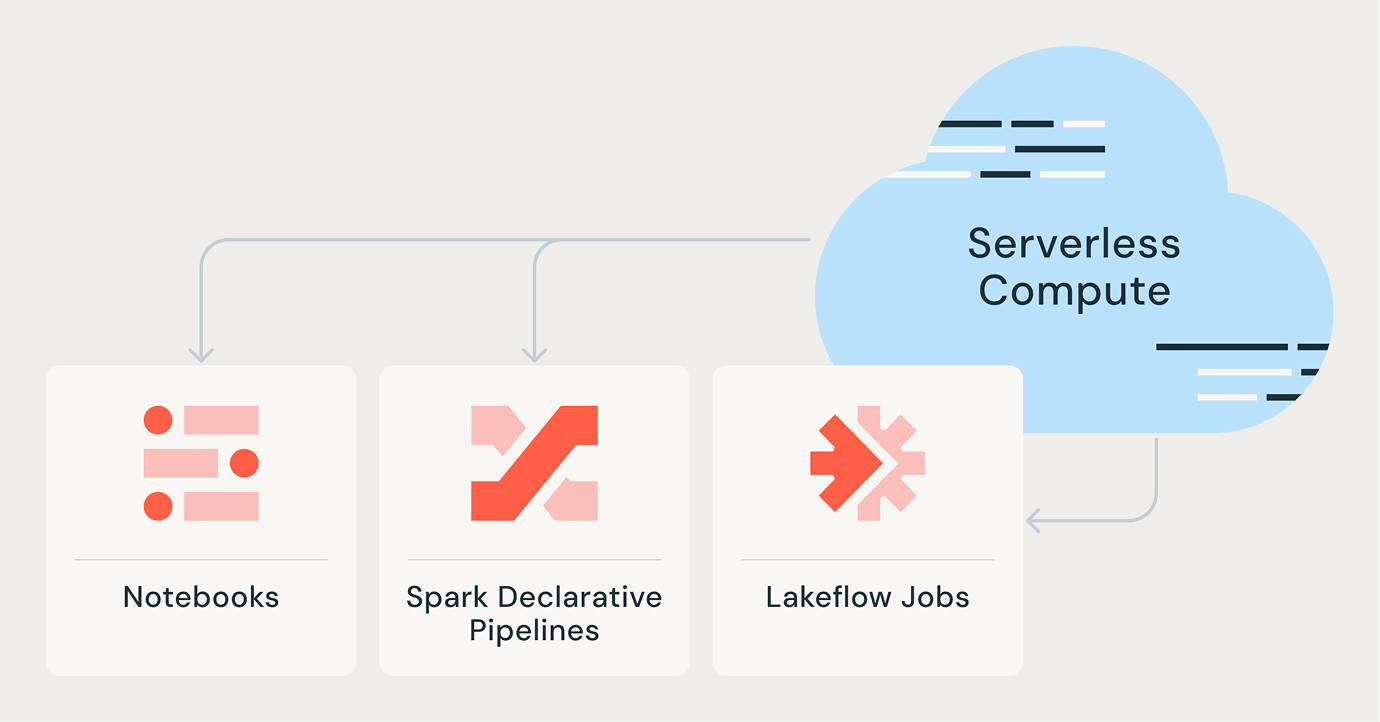
Serverless per ogni carico di lavoro

Esegui query sui dati senza gestire il compute del warehouse
I SQL warehouse Serverless di Databricks start in pochi secondi e si scalano automaticamente per soddisfare la domanda, in modo che gli analisti abbiano sempre compute pronta. Nessuna decisione sul dimensionamento, nessun cluster inattivo e nessun sovraccarico infrastrutturale. Solo query veloci e affidabili.




I prezzi basati sull'utilizzo tengono sotto controllo la spesa
Si pagano solo i prodotti utilizzati e conteggiati al secondo.Scopri di più
Scopri di più sui prodotti basati su serverless compute
Job di Lakeflow
Fornisci ai team gli strumenti per automatizzare e orchestrare al meglio qualsiasi flusso di lavoro ETL, di analisi o AI, con osservabilità avanzata, alta affidabilità e supporto per una vasta gamma di attività.

Databricks SQL
Un data warehouse intelligente e auto-ottimizzante, basato su architettura lakehouse, che offre il miglior rapporto prezzo/prestazioni sul mercato.

Spark Declarative Pipelines
Semplifica l’ETL batch e in streaming grazie a funzionalità automatizzate per la qualità dei dati, il Change Data Capture (CDC), l’ingestione, la trasformazione e la governance centralizzata.

Notebook
Aumenta la produttività dei team con i Databricks Collaborative Notebook, che consentono la collaborazione in tempo reale e semplificano i flussi di lavoro per la data science.

Databricks Apps
Crea applicazioni utilizzando i framework più diffusi e avvalendoti delle funzionalità di distribuzione serverless e di governance integrata. Fornisci soluzioni di impatto agli utenti senza dover gestire infrastrutture complesse.

Lakebase
Un Postgres integrato con il lakehouse, progettato per carichi di lavoro operativi moderni.
Fai il passo successivo
Contenuti associati
FAQ su Serverless compute
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il tuo percorso di trasformazione dei dati