Spark SQL におけるウィンドウ関数の紹介
によって Yin Huai 、 Michael Armbrust による投稿
O'Reillyの新刊 ebook のプレビューをいち早く入手し、Delta Lake の使い方をステップバイステップで学びましょう。
このブログ記事では、Apache Spark に追加された新しいウィンドウ関数機能をご紹介します。ウィンドウ関数を使用すると、Spark SQL のユーザーは、指定された行のランクや、入力行の範囲にわたる移動平均などの結果を計算できます。これにより、Spark の SQL および DataFrame API の表現力が大幅に向上します。このブログでは、まずウィンドウ関数の概念を紹介し、次に Spark SQL および Spark の DataFrame API での使用方法について説明します。
ウィンドウ関数とは?
1.4 より前は、Spark SQL で単一の戻り値を計算するために使用できる関数は 2 種類ありました。substr や round などの組み込み関数またはUDF は、単一の行の値を入力として受け取り、各入力行に対して単一の戻り値を生成します。SUM や MAX などの集計関数は、行のグループに対して操作を行い、各グループに対して単一の戻り値を計算します。
これらはどちらも実用的で非常に役立ちますが、これらの種類の関数だけでは表現できない操作がまだ数多く��あります。具体的には、行のグループに対して操作を行いながら、各入力行に対して単一の値を返す方法はありませんでした。この制限により、移動平均の計算、累積合計の計算、または現在の行の前の行の値へのアクセスなど、さまざまなデータ処理タスクの実行が困難になります。幸いなことに、Spark SQL のユーザーにとっては、ウィンドウ関数がこのギャップを埋めます。
コアとしては、ウィンドウ関数は、フレームと呼ばれる行のグループに基づいて、テーブルの各入力行に対して戻り値を計算します。各入力行には、一意のフレームを関連付けることができます。ウィンドウ関数のこの特性により、他の関数よりも強力になり、ユーザーはウィンドウ関数なしでは表現が困難(不可能ではないにしても)なさまざまなデータ処理タスクを簡潔に表現できます。それでは、2 つの例を見てみましょう。
以下に示すようなproductRevenue テーブルがあるとします。
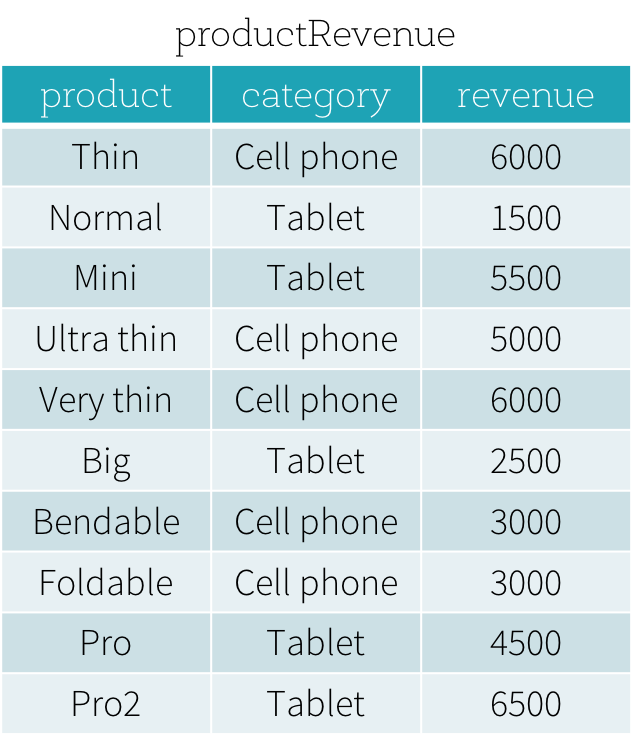
次の 2 つの質問に答えたいと思います。
- 各カテゴリで最も売れている製品と 2 番目に売れている製品は何ですか?
- 各製品の収益と、その製品と同じカテゴリの最も売れている製品の収益との差は何ですか?
最初の質問「各カテゴリで最も売れている製品と 2 番目に売れている製品は何ですか?」に答えるには、収益に基づいてカテゴリ内の製品をランク付けし、ランクに基づいて最も売れている製品と 2 番目に売れている製品を選択する必要があります。以下は、ウィンドウ関��数 dense_rank を使用してこの質問に答えるための SQL クエリです(ウィンドウ関数の構文については次のセクションで説明します)。
このプログラムの結果を以下に示します。ウィンドウ関数を使用しない場合、ユーザーはすべてのカテゴリの最高の収益値をすべて見つけ、この派生データセットを元の productRevenue テーブルと結合して収益差を計算する必要があります。
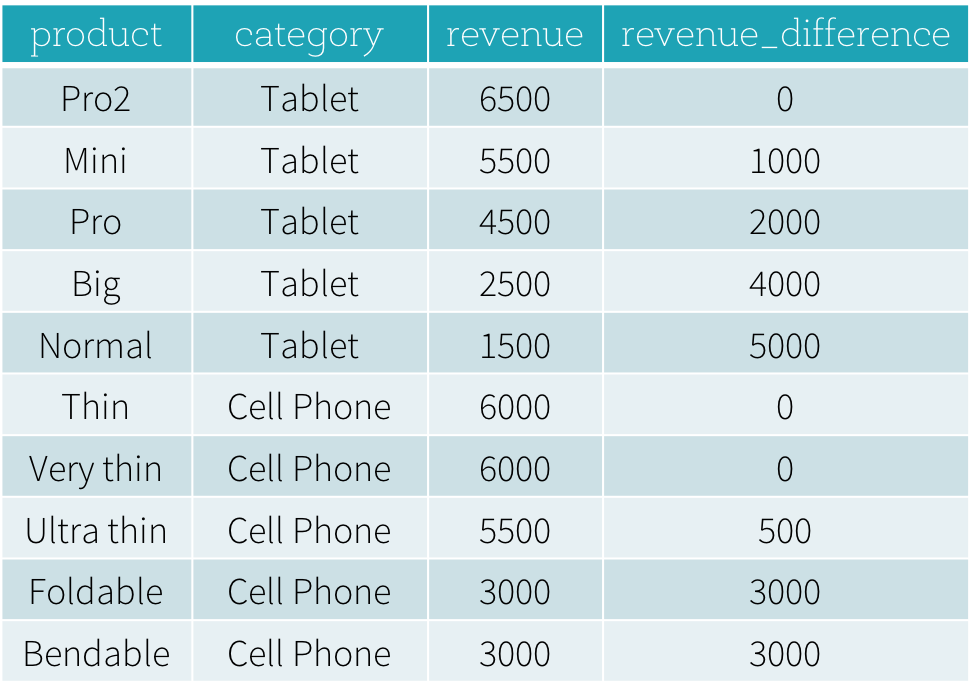
ウィンドウ関数の使用
Spark SQL は、ランキング関数、分析関数、集計関数の 3 種類をサポートしています。利用可能なランキング関数と分析関数は、以下の表にまとめられています。集計関数については、既存の集計関数をウィンドウ関数として使用できます。
| SQL | DataFrame API | |
| ランキング関数 | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| 分析関数 | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
ウィンドウ関数を使用するには、ユーザーは次のいずれかによって関数がウィンドウ関数として使用されていることをマークする必要があ�ります。
- SQL でサポートされている関数の後に OVER 句を追加する。例:
avg(revenue) OVER (...)。または - DataFrame API でサポートされている関数で over メソッドを呼び出す。例:
rank().over(...)。
関数がウィンドウ関数としてマークされたら、次の重要なステップは、この関数に関連付けられたウィンドウ仕様を定義することです。ウィンドウ仕様は、指定された入力行に関連付けられたフレームに含まれる行を定義します。ウィンドウ仕様は 3 つの部分で構成されます。
- パーティション指定: 指定された行と同じパーティションに含まれる行を制御します。また、ユーザーは、順序付けおよびフレーム計算の前に、カテゴリ列の値が同じであるすべての行が同じマシンに収集されるようにしたい場合があります。パーティション指定が与えられない場合、すべてのデータが 1 つのマシンに収集される必要があります。
- 順序指定: パーティション内の行の順序を制御し、パーティション内の指定された行の位置を決定します。
- フレーム指定: 現在の入力行に対する相対的な位置に基づいて、現在の入力行のフレームに含まれる行を指定します。たとえば、「現在の行から前の 3 行」は、現在の入力行と現在の行の前の 3 行を含むフレームを記述します。
SQL では、PARTITION BY および ORDER BY キーワードを使用して、それぞれパーティション指定のパーティション指定式と順序指定の順序指定式を指定します。SQL 構文を以下に示します。
OVER (PARTITION BY ... ORDER BY ...)
DataFrame API では、ウィンドウ仕様を定義する�ためのユーティリティ関数を提供しています。Python を例にとると、ユーザーは次のようにパーティション指定式と順序指定式を指定できます。
順序付けとパーティショニングに加えて、ユーザーはフレームの開始境界、フレームの終了境界、およびフレームのタイプを定義する必要があります。これらはフレーム仕様の 3 つのコンポーネントです。
境界には、 UNBOUNDED PRECEDING、UNBOUNDED FOLLOWING、CURRENT ROW、UNBOUNDED PRECEDING と UNBOUNDED FOLLOWING は、それぞれパーティションの最初の行と最後の行を表します。他の 3 つの境界タイプについては、現在の入力行の位置からのオフセットを指定し、その具体的な意味はフレームのタイプに基づいて定義されます。フレームには、ROW フレームと RANGE フレームの 2 種類があります。
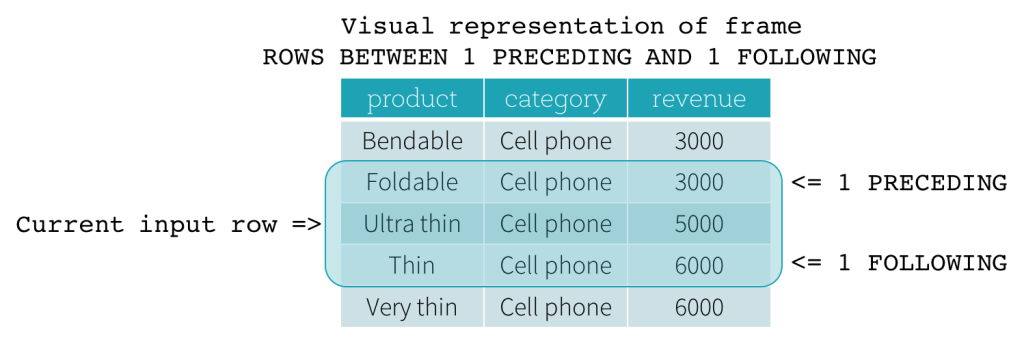
ROW フレーム
ROWフレームは、現在の入力行の位置からの物理的なオフセットに基づいています。これは、CURRENT ROW、CURRENT ROWが使用される場合、現在の入力行を表します。1 PRECEDING、終了境界として1 FOLLOWINGを持つROWフレームを示しています(SQL構文ではROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)。
RANGEフレーム
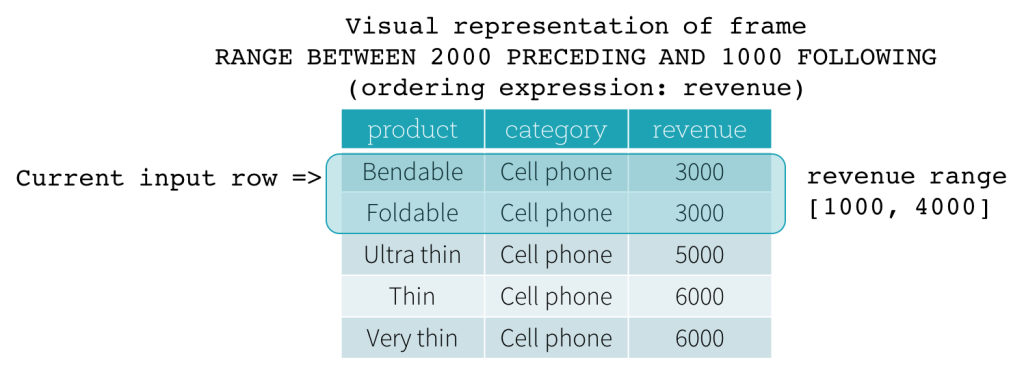
RANGEフレームは、現在の入力行の位置からの論理的なオフセットに基づいています。構文はROWフレームと似ています。論理的なオフセットとは、現在の入力行の順序付け式の値と、フレームの境界行の同じ式の値との差です。この定義のため、RANGEフレームを使用する場合、順序付け式は1つしか許可されません。また、RANGEフレームでは、現在の入力行と同じ順序付け式の値を持つすべての行は、境界計算に関しては同じ行と見なされます。
それでは、例を見てみましょう。この例では、順序付け式はrevenueです。開始境界は2000 PRECEDING、終了境界は1000 FOLLOWINGです(SQL構文ではRANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWINGとして定義されます)。次の5つの図は、現在の入力行の更新に伴ってフレームがどのように更新されるかを示しています。基本的に、現在の入力行ごとに、revenueの値に基づいて、revenue範囲[現在のrevenue値 - 2000、現在のrevenue値 + 1000]を計算します。この範囲に含まれるrevenue値を持つすべての行が、現在の入力行のフレームに含まれます。
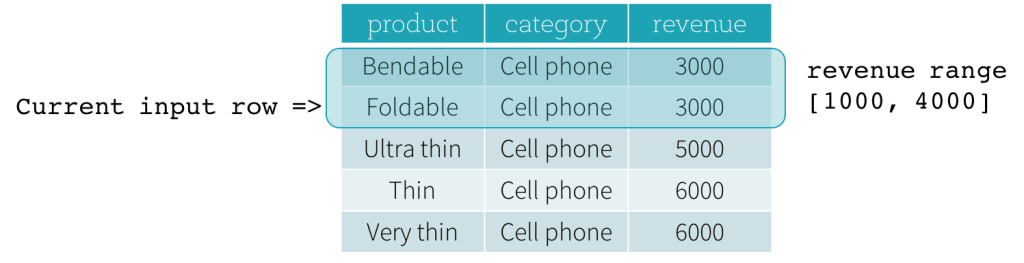
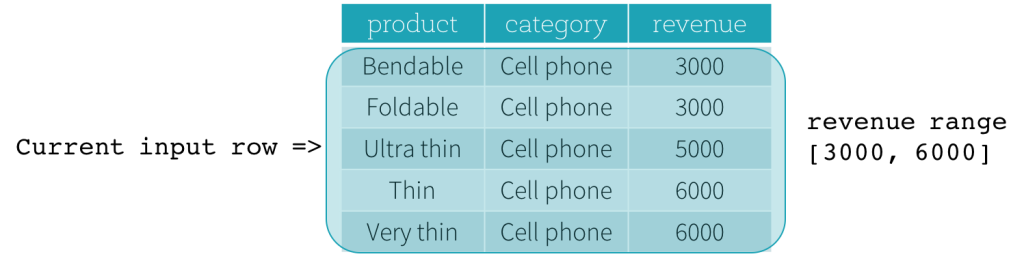
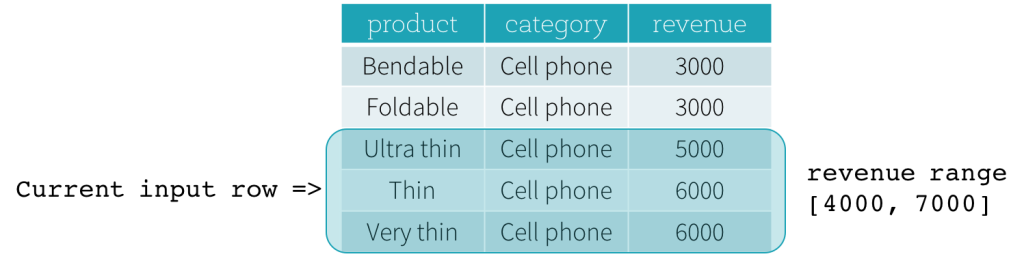
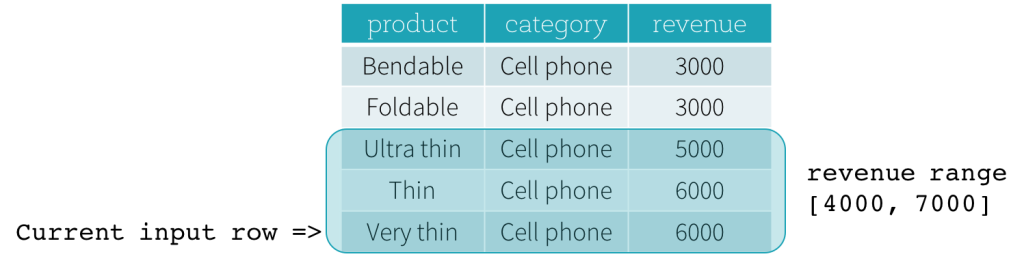
要約すると、ウィンドウ仕様を定義するために、ユーザーはSQLで次の構文を使用できます。
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
ここで、frame_typeはROWS(ROWフレームの場合)またはRANGE(RANGEフレームの場合)のいずれかです。startはUNBOUNDED PRECEDING、CURRENT ROW、endはUNBOUNDED FOLLOWING、CURRENT ROW、
Python DataFrame APIでは、ユーザーは次のようにウィンドウ仕様を定義できます。
次は何ですか?
Spark 1.4のリリース以降、ウィンドウ関数の評価オペレータのパフォーマンスを向上させ、メモリ消費量を削減する最適化について、コミュニティメンバーと積極的に協力してきました。これらの一部はSpark 1.5に追加され、その他は将来のリリースに追加されます。パフォーマンス改善作業に加えて、Spark SQLでのウィンドウ関数サポートをさらに強力にするために、近日中に2つの機能を追加する予定です。まず、DateおよびTimestampデータ型に対するIntervalデータ型サポートの追加に取り組んでいます(SPARK-8943)。Intervalデータ型を使用すると、ユーザーはRANGEフレームの
これらのSpark機能を試すには、Databricksの無料トライアルを入手するか、Community Editionを使用してください。
謝辞
Spark 1.4でのウィンドウ関数サポートの開発は、Sparkコミュニティの多くのメンバーによる共同作業です。特に、初期パッチを提供してくれたWei Guo氏に感謝いたします。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信ト�レイにお届けします。