データレイクハウスと機械学習の融合による再現性の強化
によって Mary Grace Moesta 、 Srijith Rajamohan, Ph.D. による投稿
機械学習が組織やプロジェクトにこれまでにない価値をもたらすことが証明されています。機械学習には、イノベーションの加速、パーソナライゼーション、需要予測など、さまざまなユースケースがあります。しかし、課題もあります。それは、使用されるデータのソースが無数に存在し、ツールや依存関係のエコシステムも絶え間なく変化することから、ソリューションは流動的かつ、元の状態への再現性が低くなってしまうことです。
機械学習で構築するモデルが常に正しいとは限りません。そこで、モデルの精度を高めるために実験を繰り返します。その実験の信頼性を高めるには、モデルと結果の再現性を高める必要があります。再現性を高める機械学習実験においては、少なくとも次の項目の再現が期待されます。
- データのトレーニング/検証/テスト
- コンピューティング
- 環境
- モデル(関連するハイパーパラメータなど)
- コード
しかし、機械学習での再現性の確保は、実際には非常に難しいタスクです。例えば、モデルのトレーニングに使用されたデータと同一のデータにアクセスする必要があります。その際、データが変更�されていないことをどのように保証したらよいでしょうか。ソースコードの追加に際しては、データのバージョン管理も必要です。
さらには、使用されたライブラリとバージョン、ハイパーパラメータ、モデルのそれぞれを把握しなければなりません。また、コードがエンドツーエンドで正常に実行されていない場合もあります。
このブログ記事では、Delta Lake 上に構築されたレイクハウスアーキテクチャとオープンソースライブラリである MLflow の組み合わせにより、上述のような機械学習における再現性の課題をどのように解決し、モデル精度を向上させるかを解説します。特に以下の項目を取り上げます。
- レイクハウスアーキテクチャ
- Delta Lake によるデータバージョン管理
- MLflow による実験のトラッキング
- データブリックスによるエンドツーエンドでの再現性
データレイクハウスとは(データレイクハウスが必要な理由)
通常、データサイエンティストがデータの起源(CSV、リレーショナルデータベースなど)を考慮することはありません。しかし、扱っているトレーニングデータが夜間に更新される場合などはどうでしょうか。ハイパーパラメータを指定してモデルを構築した翌日に、さらにハイパーパラメータを微調整してモデルを改良したいこともあるでしょう。調整後にモデルのパフォーマンスが改善された場合、それがハイパーパラメータの更新によるものか、元データの変更によるものか見分けられるでしょうか。
これらの状況は、データのバージョン管理が可能となっており、同一条件で比較できなければ、判別のしようがありません。「あらゆるデータのスナップショットを取っておけばよい」という意見もあるでしょう。しかし、それは相応の工数が必要であり、データがすぐに蓄積して維持やバージョン管理が困難になります。つまり、スケーラブルで信頼できる単一のデータソースが、データセット全体のスナップショットを取ることなく、バージョン管理は常に最新の状態に維持されている必要があるのです。
このような場合に役立つのが、データウェアハウスとデータレイクのメリットを組み合わせたレイクハウスです。レイクハウスの使用により、データレイクのスケーラビリティと低コストのストレージを、データウェアハウスの高速性と ACID トランザクション特性が保証された状態で利用できます。その結果、信頼できる単一のデータソースが実現し、最新データの取りこぼしや不整合の発生を避けることができます。
このようなメリットは、既存のデータレイクをメタデータ管理により増強することでパフォーマンスを最適化し、データウェアハウスへのデータコピーを不要にすることで実現されています。データのバージョン管理、信頼性の高いフォールトトレラントなトランザクション、高速なクエリエンジンが利用でき、それらの全てがオープンスタンダードで維持管理されます。
つまり、ストリーミング分析から BI、データサイエンス、AI に至る全ての主要なデータワークロードを対象とした単一ソリューションを実現できます。これが新たなスタンダードです。
このように、レイクハウスは理論的に大変すばらしいものです。では、実際に利用を開始するにはどうすればよいでしょうか。
Delta Lake によるデータバージョン管理
Delta Lake はレイクハウスアーキテクチャに活用されるオープンソースのプロジェクトです。オープンソースのレイクハウスプロジェクトはいくつかありますが、Delta Lake を選択する理由は、Apache Spark™ と緊密に統合されており、次のような機能のサポートが得られるためです。
- ACID トランザクション
- スケーラブルなメタデータ処理
- タイムトラベル
- スキーマの展開
- 監査履歴
- 削除と更新
- バッチ処理とストリーミングの統合
機械学習の良否はデータの品質によって決まります。Delta Lakeと上記の機能を使用することで、データサイエンスプロジェクトを開始するための文字どおりの確固たる基盤を得ることができます。常にデータへの変更や更新が生じている状況下でも、 ACID トランザクションにより読み込みと書き込みが同時発生する場合の整合性を確保します。バッチ処理、ストリーミング処理のどちらであるかは問われません。このような仕組みにより、出力�されるデータの一貫性が保たれます。
Delta Lake では、コミット以降の差分や変更点のみがトラッキングされ、 Delta トランザクションログに保存されます。そうすることで、データのバージョンに基づいたタイムトラベルを行えるようにして、モデルやハイパーパラメータ等の変更時にもデータの一貫性を維持します。一方、スキーマ適用がサポートされていることから、Delta Lake で指定するスキーマにとらわれることなく、機械学習モデルへの入力として別の特徴を追加することもできます。
変更点については、 history() メソッドを Delta API から使用してトランザクションログを確認できます。
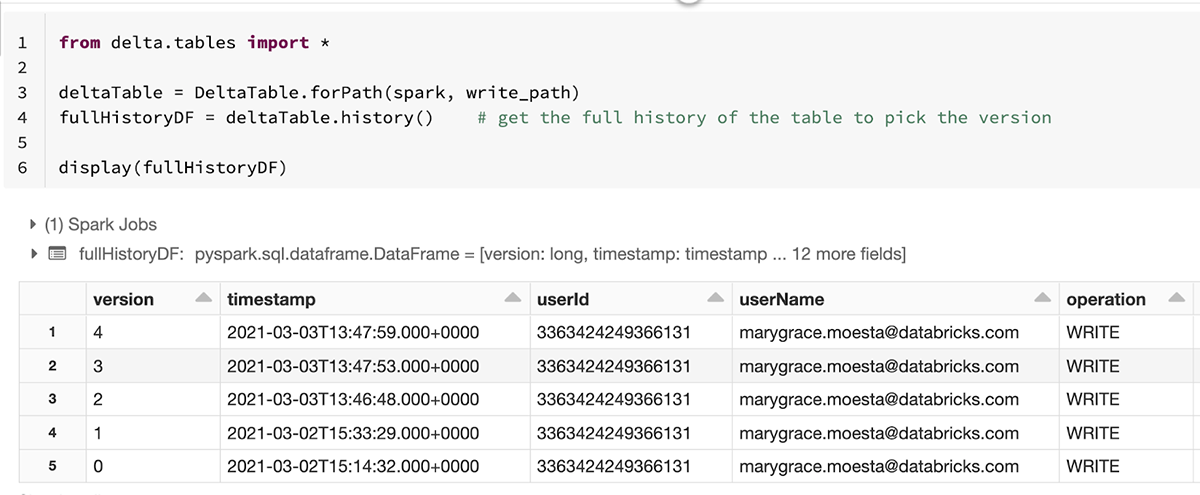
元データに対する全ての変更が系列に沿って追跡できるため、作成時と完全に同一のデータでモデルを再現できます。Delta Lake からデータを読み込む際には、バージョンやタイムスタンプで指定することが可能です。
MLflow によるモデルのトラッキング
確実にデータを再現できるようになれば、モデルの再現も行えるようになります。オープンソースライブラリである MLflow には、機械学習ライフサイクルの管理や、実験の再現性を高める手順を大幅に簡素化するため��の 4 つのコンポーネントが含まれています。

MLflow を使用してトラッキングすることで、ハイパーパラメータ、メトリック、コード、モデル、その他の各アーティファクト(ファイル、プロット、データバージョンなど)を一元的な場所に記録できるようになります。Delta Lake テーブルや関連するバージョンも記録され、データ全体のコピーやスナップショットを取ることなく、各実行におけるデータの整合性が確保されます。具体例として、ワインデータセットにおけるランダムフォレストモデルの作成と、 MLflow による実験のロギングについてみてみましょう。コードの全体は、こちらの Notebook で確認できます。
実験結果は MLflow のトラッキング UI に記録され、データブリックスの Notebook の右上隅にある実験アイコンを選択すれば利用できます(実験のロケーションが異なっていると利用できません)。ここでは、実行ごとの比較と、特定のメトリックやパラメータ等に基づいたフィルタリングが行えます。

パラメータやメトリック等の手動でのロギングに加え、 自動ロギング機能もあり、MLflow がサポートする組み込みのモデルフレーバーを対象としています。たとえば、sklearn モデルで自動ロギングを行うには、 mlflow.sklearn.autolog() を追加します。パラメータとメトリックが記録され、estimator.fit() が呼び出されるときには、分類問題の混同行列の生成等が行われます。
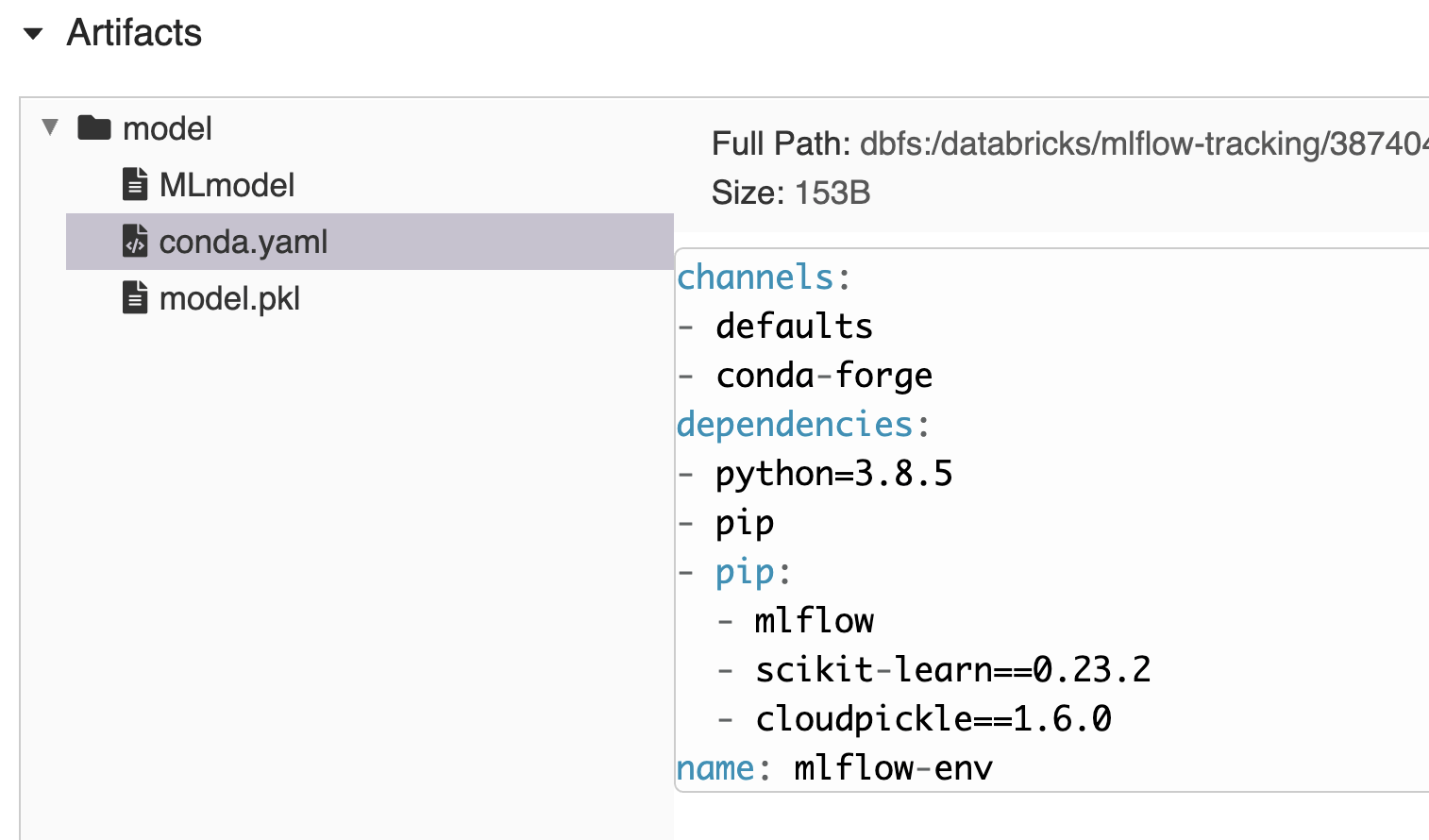
トラッキングサーバーにモデルを記録する際には、MLflow により標準モデルパッケージ形式が作成されます。自動的に conda.yaml ファイルが作成され、モデルの読み込みに必要な環境を再作成する際に求められるチャネル、依存関係、バージョンが定められます。つまり、 MLflow によるトラッキングやロギングが行われたモデルを使用すれば、その環境のミラーリングが容易に行えるということです。
データブリックスプラットフォーム上のマネージド MLflow を使用すれば、「実行の再現」機能により、ボタンをクリッ��クするだけでトレーニングの実行を再現できます。この機能では、データブリックスの Notebook、クラスタ構成、インストールしたその他のライブラリのスナップショットが自動的に作成されます。
![Databricks の [実行] オプションを再現](https://www.databricks.com/jp/wp-content/uploads/2021/04/reproduce-ml-blog-img-5.png)
ぜひ、この「実行の再現」機能を試して、自身やチームで行った実験が再現できるか確認してみてください。
考察
この記事では、レイクハウスアーキテクチャと Delta Lake、MLflow を組み合わせて、機械学習のデータ、モデル、コード、環境を再現する際の課題への対処方法を解説しました。こちらの Notebook を利用して、ぜひ実験の再現性を高めてみてください。なお、上で述べた項目について再現できるようになっても、まだ制御できない対象が存在する可能性はあります。しかし、データブリックスの Delta Lake と MLflow を使用して機械学習ソリューションを構築すれば、実験の再現に関する多くの課題に対処できます。
データレイクハウスで解決できる他の課題について、従来の二層データアーキテクチャの課題について言及したこのブログでご紹介しています。企業がレイクハウスアーキテクチャを活用してどのように課題解決しているかご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。