BI ツールの広帯域接続を実現するには
によって Bogdan Ionut Ghit, Juliusz Sompolski, ステファニア・レオーネ 、 Reynold Xin(レイノルド・シン) による投稿
Tableau や Microsoft Power BI などのビジネスインテリジェンス(BI)ツールは、従来のデータウェアハウスから大規模なクエリ結果を抽出するのに多くの時間を要することで知られています。これは、通常、データ転送のボトルネックとなる SQL エンドポイントを介してシングルスレッドでデータを取得するためです。Databricks の SQL エンドポイントに使用している BI ツールを接続することで、データアナリストは、Simba ドライバに統合された ODBC/JDBC プロトコルを介してテーブルのデータのクエリを実行できます。また、Databricks ランタイム 8.3 および Simba ODBC 2.6.17 ドライバでリリースした Cloud Fetch では、AWS S3 や Azure Data Lake Storage などのクラウドストレージを経由してデータを並行して取得する新しい仕組みを導入しました。これにより、BI ツールへの高速なデータの取り込みが可能になりました。Cloud Fetch を使った実験では、並列化により抽出性能が 10 倍高速化したことが確認されています。
動機づけ�と課題
大規模な組織では、 BI ツールの利用が増加傾向です。これは、分析アプリケーションを実行するデータアナリストにクエリ実行の複雑さを見せることなく、優れたデータ視覚化を提供するためです。BI ツールは、標準の ODBC/JDBC プロトコルで SQL エンドポイントと通信し、クエリを実行して結果を抽出します。Cloud Fetch の導入前は、Databricks では Apache Spark™ と同様のアプローチを採用していました。この設定では、エンドツーエンドの抽出性能は、通常、シングルスレッドの SQL エンドポイントが結果を BI ツールに戻すのにかかる時間よって支配されます。
Cloud Fetch 導入前は、図1 にあるようにデータフローは比較的シンプルなものでした。BI ツールは、クラスタにバックアップされた SQL エンドポイントに接続し、クエリはコンピュートスロット上で並行して実行されます。クエリの結果は、クライアントとクラスタ間の通信においてコーディネーターノードとして機能する SQL エンドポイントに収集されます。SQL エンドポイントのリソース制限を超えることなく膨大なデータを提供できるように、Databricks は、SQL エンドポイントでディスクスピルを有効にし、100 MB 以上の結果をローカルディスクに格納するようにしました。全ての結果が収集され、ディスクがオーバーフローする可能性がある場合、SQL エンドポイントは、結果を要求する BI クライアントに結果を返す準備が整っています。サーバーは全てのデータを一度に返すのではなく、複数の小さなまとまり(チャンク)に分割して返します。
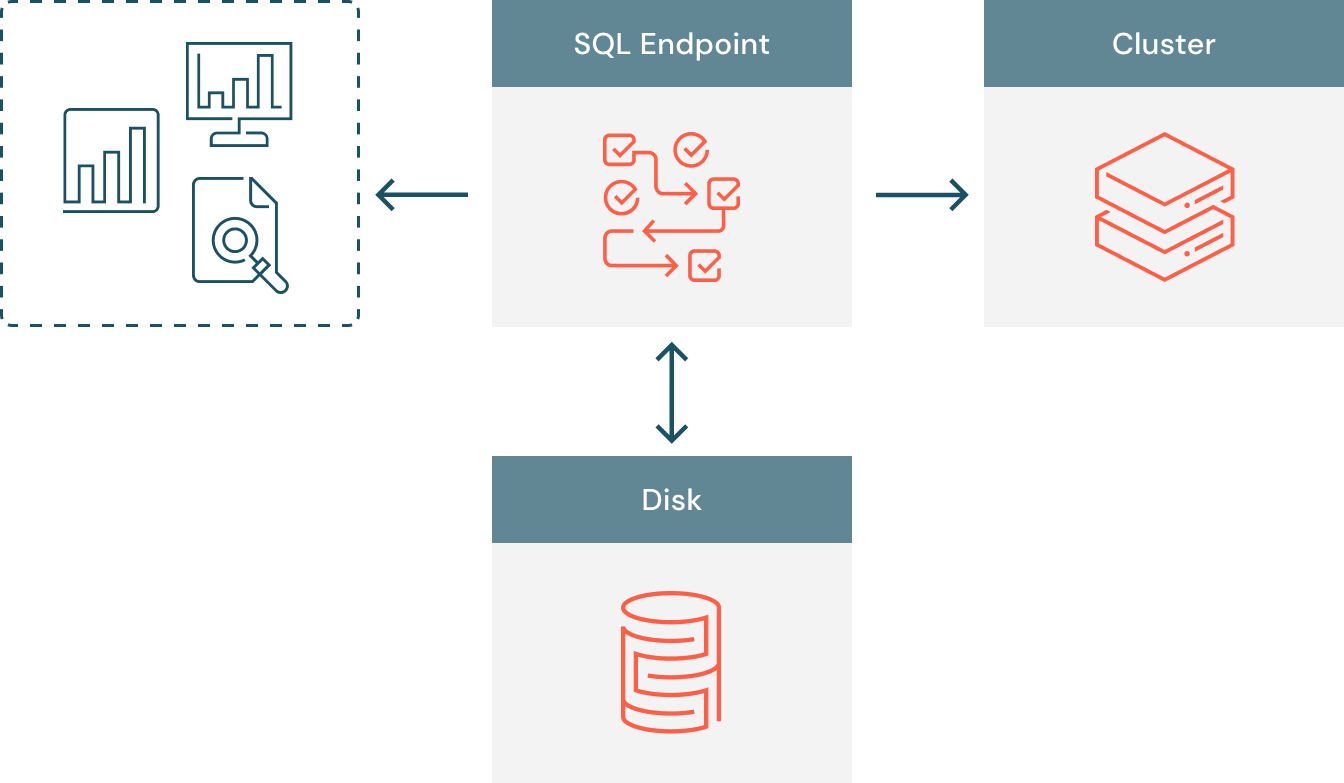
私たちは、数百 MB のデータを抽出する際に、データフローを非効率にし、SQL エンドポイントをボトルネックにするリスクを生じさせる 2 つの主要なスケーラビリティの問題を特定しました。
- マルチテナンシー: 制限された egress の帯域幅を、同じ SQL エンドポイントにアクセスする複数のユーザーが共有することがあります。同時接続ユーザーの数が増えると、それぞれのユーザーは低下した性能でデータを抽出することになります。
- 並列性の欠如:クラスタがクエリを並列に実行しても、エクゼキュータからのクエリ結果の収集および BI ツールへの返却はシングルスレッドで行われます。クライアントは数 MB のまとまり(チャンク)で順次結果を取得しますが、SQL エンドポイントのシングルスレッドが結果の格納と提供のボトルネックになります。
Cloud Fetch のアーキテクチャ
Databricks では、これらの制限に対処すべく、結果の書き込み/読み取りの両方が並列で行われるようにデータ抽出のアーキテクチャを構築し直しました。ハイレベルでは、各クエリは利用可能な全てのコンピュートリソースで実行される複数のタスクに分割され、これらのタスクは、Azure Data Lake Storage、AWS S3、または Google Cloud Storage に結果を書き込みます。SQL エンドポイントは、クライアントに署名付き URL としてファイルのリストを送信し、クライアントはクラウドストレージから直接データを並列でダウンロードできるようにします。
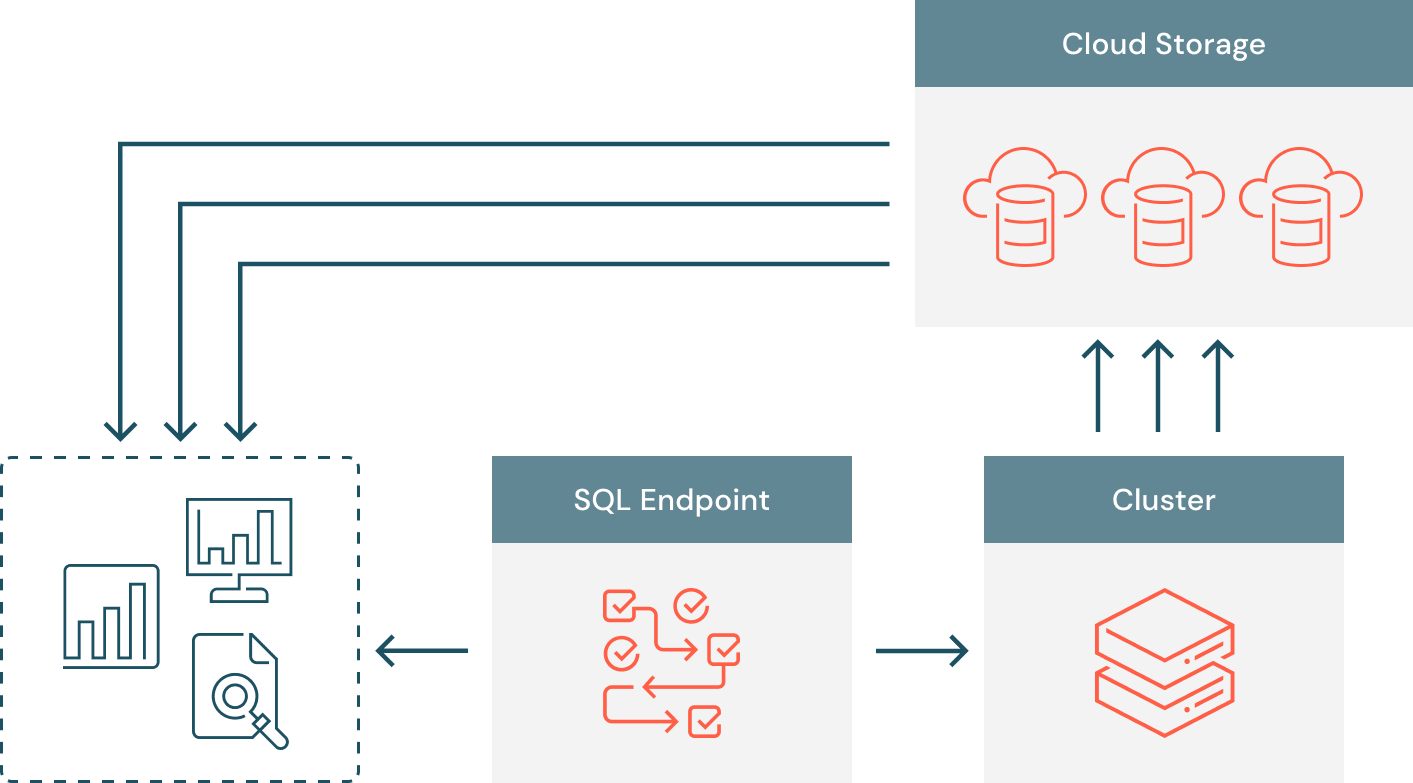
データのレイアウト
クエリタスクは、入力されたデータセットの個々のパーティションを処理し、Arrow のシリアル化された結果を生成します。Apache Arrow は、近年、列指向のインメモリデータ分析のデファクトスタンダードとなっており、すでに多くのオープンソースプロジェクトで採用されています。各クエリタスクは、Arrow のストリーミングフォーマットを使用して、20 MB のまとまり(チャンク)でクラウドストレージにデータを書き込みます。各ファイルの中には、一定の行数とバイト数で構成された複数のアローバッチが存在する場合があります。それぞれのファイルの中には、一定の行数とバイト数で構成された複数の Arrow バ ッチが存在する場合があります。
結果の収集
SQL エンドポイントでは、MB/GB 規模のクエリ結果を収集するの��ではなく、クラウドストレージへのリンクを格納するようになりました。そのため、メモリフットプリントとディスクスピルのオーバーヘッドが大幅に削減されました。実験結果では、Cloud Fetch は、1 MB 以上のクエリ結果のサイズに対して 2 倍以上のスループット向上を実現しています。しかし、1 MB 以下の結果のクラウドストアへのアップロードでは、無視できないレイテンシが発生しました。そこで、小規模なクエリ結果では結果をインライン化してレイテンシを回避し、大規模なクエリ結果では結果をアップロードしてスループットを向上させることができるハイブリッドのフェッチメカニズムを設計しました。SQL エンドポイントで結果を収集する際、3 つのシナリオが考えられます。
- 全てのタスクが Arrow バッチを返し、合計サイズが 1 MBよりも小さい場合。レイテンシによる影響を受けやすく、クラウドストア経由の取得に向かない極めて短いクエリのケースです。これらの結果は、上述のシングルスレッドのメカニズムを介してクライアントに直接返されます。
- 全てのタスクが Arrow バッチを返し、その合計サイズが 1 MB以上であるか、またはタスクが Arrow バッチとクラウドファイルの混合を返す場合。このケースでは、タスクと同じデータのレイアウトを使用して、SQL エンドポイントから残りの Arrow バッチをクラウドストアにアップロードし、ファイルの結果リストを格納します。
- 全てのタスクが、クラウドファイルへのリンクを返す場合。このケースでは、クラウドのリンクをメモリ上に格納しておき、クライアントのフェッチリクエストに応じて返却します。
フェッチリクエスト
SQL エンドポイントでデータが利用可能になると、BI ツールは小規模なチャンクを順次要求してデータの取得を開始できます。フェッチリクエストがあると、SQL エンドポイントは現在のオフセットに対応するファイルを取得し、署名付き URL のセットをクライアントに返します。このような URL は、クラウドのプロバイダに依存せず、基本的な HTTP クライアントを使用してダウンロードできるため、BI クライアントにとって便利です。BI ツールは、並列で返されたファイルをダウンロードし、その内容を解凍して、Arrow バッチから個々の行を抽出します。
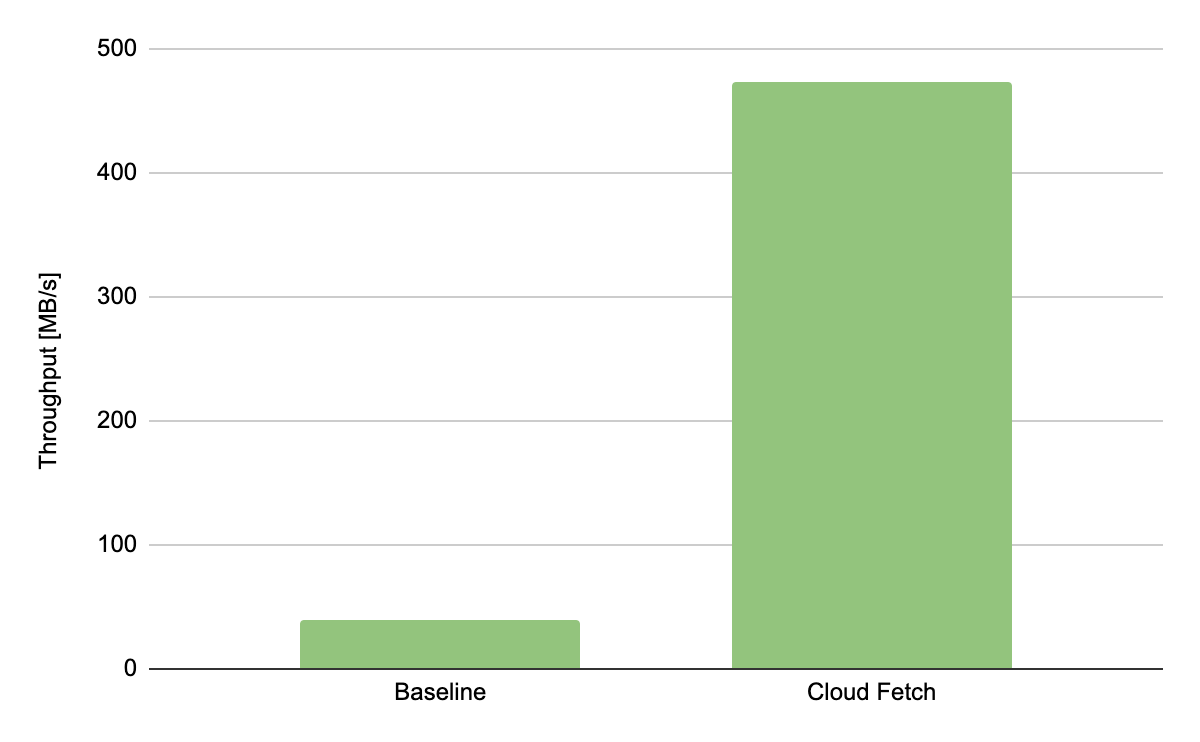
実験結果
合計 3.42 GB、20 列、400 万行の合成データセットを使用してデータ抽出の実験を行った結果、Cloud Fetch の有効化により、シングルスレッドのベースラインと比較して抽出スループットが 12 倍改善したことを観測しました。
使ってみる
データ抽出を高速にする Cloud Fetch を開始するには、最新の ODBC ドライバをダウンロードしてください�。この機能は、Azure Databricks と Amazon の両方で、Databricks Runtime 8.3 以降で展開された Databricks SQL およびインタラクティブな Databricks クラスタで利用可能です。最新の Simba ODBC ドライバ 2.6.17 と、近日公開予定の Simba JDBC ドライバ 2.6.18 には、Cloud Fetch の機能が組み込まれています。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。