Databricks ワークスペースのディザスタリカバリの実装
この投稿は、ディザスタリカバリの概要、戦略、評価およびDatabricks ワークスペースのディザスタリカバリの自動化とツールの続きです。
ディザスタリカバリとは、自然災害または人為的災害の発生後に、重要なテクノロジーインフラストラクチャとシステムの復旧または継続を可能にする一連のポリシー、ツール、および手順を指します。AWS、Azure、Google Cloud などのクラウド サービス プロバイダーや SaaS 企業は、単一障害点に対するセーフガードを構築していますが、障害は発生します。障害の深刻度と、それが組織に与える影響は異なる場合があります。クラウドネイティブのワークロードには、明確なディザスタ リカバリ パターンが不可欠です。
Databricks のディザスタ リカバリ設定
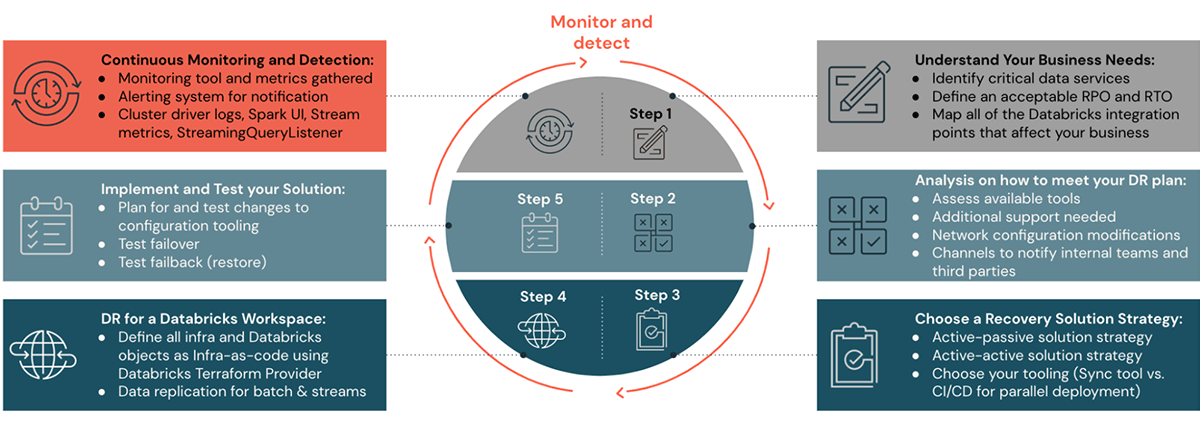
DRソリューション戦略の計画、設定、自動化を行うためのステップ1から4を理解するには、このDRブログシリーズの以前のブログ投稿をご覧ください。このブログ記事のステップ5と6では、DR設定を監視、実行、検証する方法について見ていきます。
ディザスタ リカバリ ソリューション
一般的なDatabricksの実装には、ノートブックのソースコード、クエリー、ジョブ構成、クラスタなどの多数の重要なアセットが含まれており、これらは、エンドユーザーへの混乱を最小限に抑え、サービスを継続して提供できるように、スムーズに復旧させる必要があります。
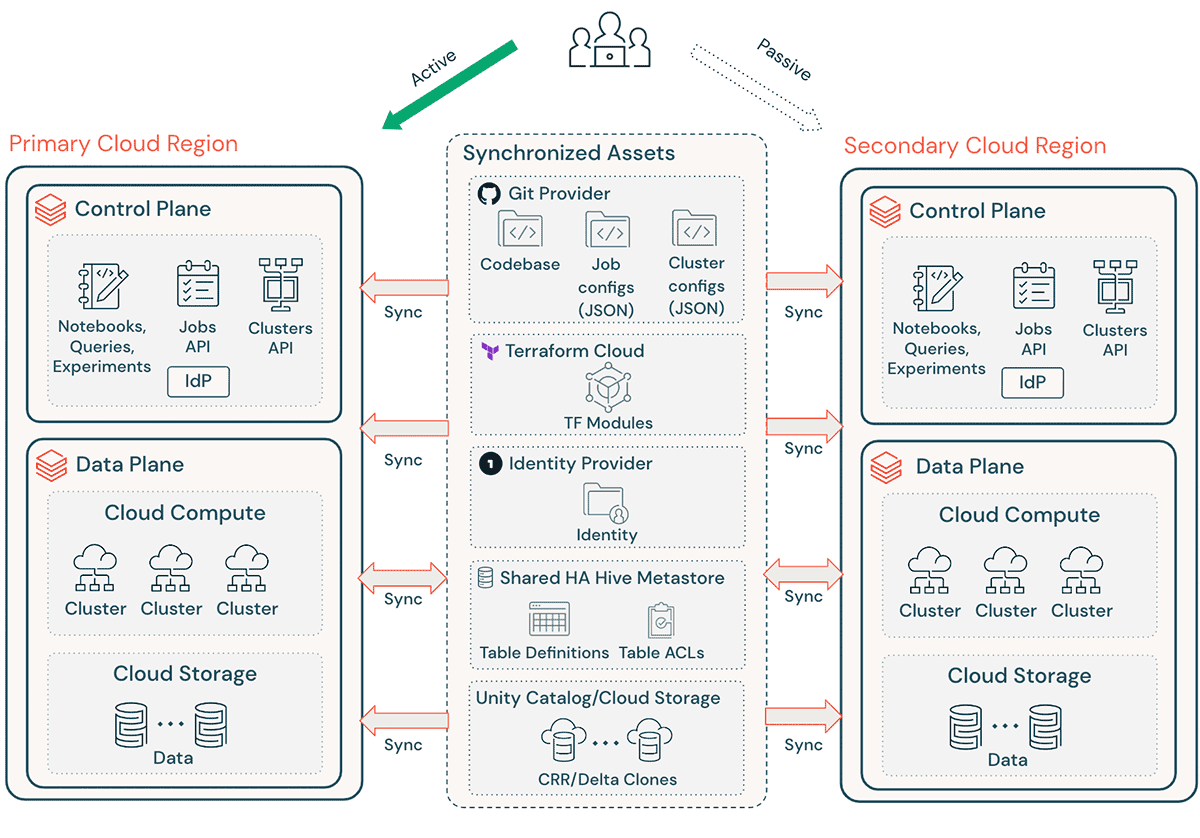
高レベルの DR に関する考慮事項:
- Terraform (TF) を介してアーキテクチャを複製可能にし、この環境を他の場所で作成および再作成できるようにします。
- Databricks Repos (AWS | Azure | GCP) を使用して、サポートされている任意のファイル (AWS | Azure | GCP) 内のノートブックとアプリケーションコードを同期します。
- Terraform Cloud を使用して、インフラとアプリのパイプラインの TF ラン (plan と apply) を Trigger し、状態を維持します
- Amazon S3、Azure ADLS、GCS などのクラウドストレージアカウントから DR リージョンにデータを複製します。AWS をご利用の場合、S3 Multi-Region Access Points を使って、異なる AWS リージョンの複数の S3 バケットにまたがってデータを保存することも可能です。
- Databricksクラスターの定義には、アベイラビリティーゾーン固有の情報を含めることができます。AWS で Databricks を実行する場合は、リージョンのフェイルオーバー中に問題が発生しないように、「auto-az」クラスター属性を使用してください。
- DR リージョンで 構成ドリフトを管理します。DR リージョンで、インフラストラクチャ、データ、構成が必要な状態であることを確認してください。
- 本番環境のコードとアセットには、両方のリージョンの本番システムに同時に変更をプッシュする CI/CD ツールを使用してください。たとえば、ステージング/開発環境から本番運用にコードとアセットをプッシュする場合、CI/CD システムによって両方のリージョンで同時に利用可能になります。
- Git を使用して、TF ファイル、インフラストラクチャのコードベース、ジョブ設定、およびクラスタ設定を同期します。
- セカンダリ リージョンで TF `apply` を実行する前に、リージョン固有の設定を更新する必要があります。
注: Feature Store、MLflow パイプライン、機械学習実験追跡、モデル管理、モデルデプロイメントなどの特定のサービスは、現時点ではディザスタリカバリには実行可能とは見なされません。Structured Streaming と Delta Live Tables の場合、exactly-once 保証を維持するにはアクティブ/アクティブ デプロイメントが必要ですが、パイプラインは 2 つのリージョン間で結果整合性を持ちます。
その他の高レベルの考慮事項については、この シリーズ の以前の記事で確認できます。
モニタリングと検出
災害を迅速に宣言し、インシデントから復旧できるように、ワークロードが正常な状態でない場合は、できるだけ早くそれを把握することが極めて重要です。この応答時間は、適切な情報と相まって、意欲的な復旧目標を達成するために不可欠です。現実的で達成可能な目標を設定するために、インシデントの検出、通知、エスカレーション、発見、宣言を計画と目標に組み込むことが不可欠です。
サービス ステータス通知
Databricksステータスページで�は、コントロールプレーン用のすべてのコアDatabricksサービスの概要が提供されます。ステータスページを表示することで、特定のサービスのステータスを簡単に確認できます。オプションで、個々のサービスコンポーネントのステータス更新をサブスクライブすることもできます。サブスクライブしたステータスが変更されると、アラートが送信されます。
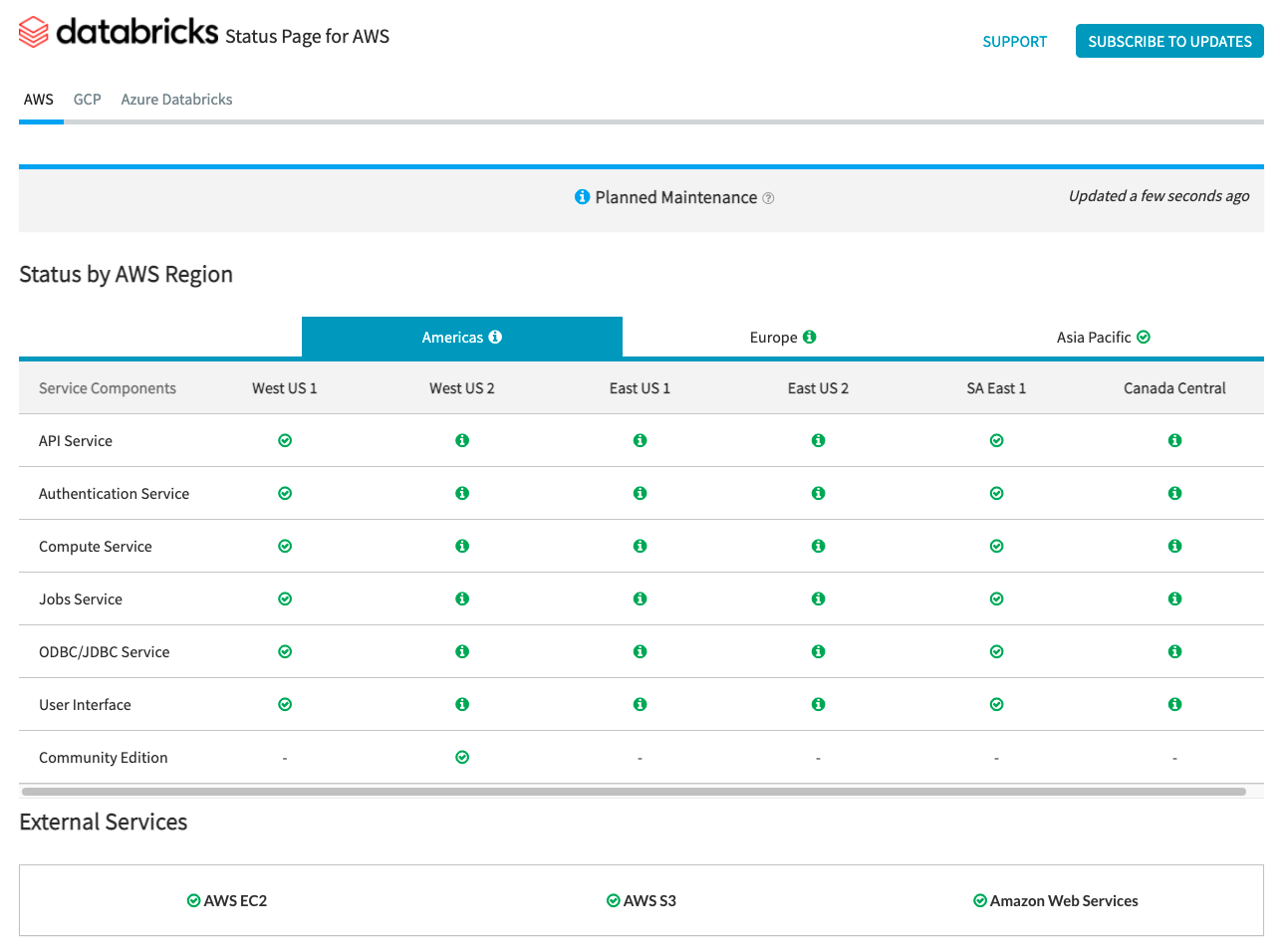
データプレーンのステータス チェックについては、モニタリングにAWS Health Dashboard、Azure Status Page、GCP Service Health Pageを使用してください。
AWS と Azure は、ツールがステータス チェックを取り込んでアラートを発行するために使用できる API エンドポイントを提供します。
インフラストラクチャのモニタリングとアラート
ツールを使用してインフラストラクチャからデータを収集および分析することで、チームはパフォーマンスを経時的に追跡できます。これにより、チームはダウンタイムやサービス全体の低下を積極的に最小限に抑えることができます。さらに、長期的にモニタリングすることで、最適化やアラート発報の基準となるピークパフォーマンスのベースラインを��確立できます。
DR のコンテキストでは、組織はサービスプロバイダーからのアラートを待つことができない場合があります。RTO/RPO 要件がサービスプロバイダーからのアラートを待つのに十分な許容範囲であっても、パフォーマンスの低下を事前にベンダーのサポートチームに通知することで、より早い段階でコミュニケーションラインを開くことができます。
DataDogとDynatraceはどちらも、AWS、Azure、GCP、Databricksクラスター用のインテグレーションとエージェントを提供する、一般的なモニタリングツールです。
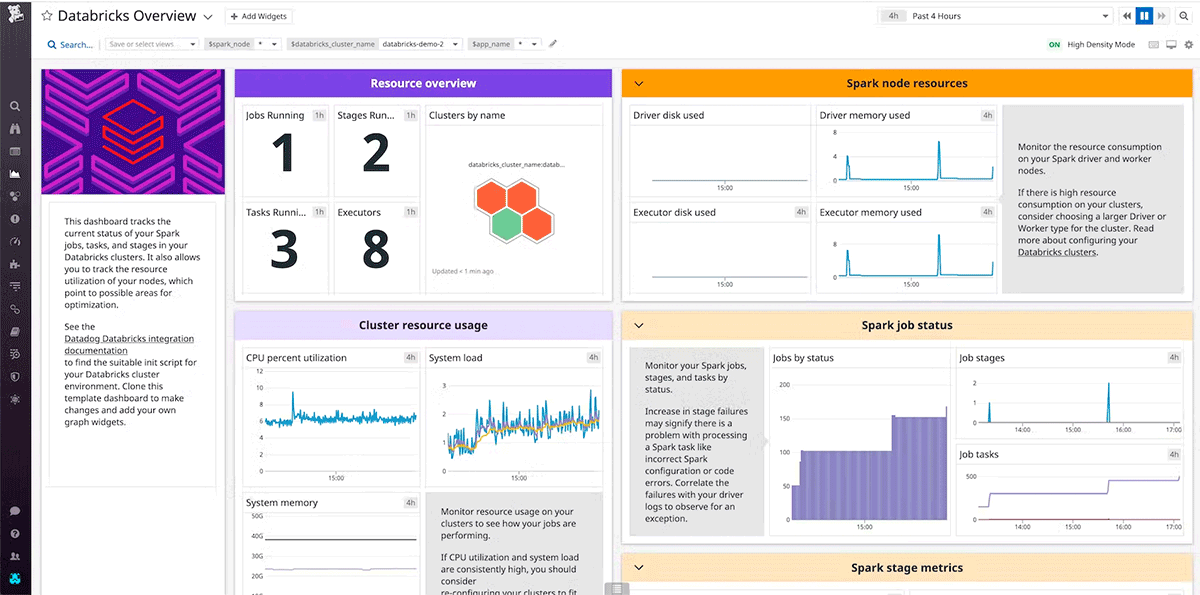
ヘルスチェック
最も厳しいRTO要件に対応するには、Databricksサービスや、ワークロードがデータプレーンで直接やり取りするその他のサービス(たとえば、クラウドプロバイダーのオブジェクトストアやVMサービスなど)のヘルスチェックに基づいて、自動フェイルオーバーを実装できます。
ユーザーエクスペリエンスを反映し、主要業績評価指標 (KPI) に基づいたヘルスチェックを設計します。シャローハートビートチェックでは、システムが動作しているか、つまりクラスターが実行中であるかどうかを評価できます。一方、個々のノードのCPUやディスク使用量からのシステム��メトリクス、アクティブな各ステージやキャッシュされたパーティションにわたるSparkメトリクスなどのディープヘルスチェックは、シャローハートビートチェックよりもさらに踏み込み、パフォーマンスの大幅な低下を判断します。ワークロードの機能とベースラインパフォーマンスに応じて、複数のシグナルに基づいたディープヘルスチェックを使用してください。
ヘルスチェックを使用してフェイルオーバーの決定を完全に自動化する場合は、注意が必要です。誤検知が発生した場合や、アラームが作動してもビジネスがその影響を許容できる場合は、フェイルオーバーする必要はありません。誤ったフェイルオーバーは、可用性のリスクとデータ破損のリスクをもたらし、時間的にコストのかかる操作です。アラームがトリガーされた場合に意思決定を行うため、オンコールのインシデント マネージャーなど、ヒューマンインザループを設けることを推奨します。不要なフェイルオーバーは壊滅的な事態を招く可能性があるため、追加のレビューによってフェイルオーバーが必要かどうかを判断できます。
DR ソリューションの実行
ディザスタ リカバリ ソリューションには、大まかに分けて 2 つの実行シナリオが存在します。最初のシナリオでは、DR サイトは一時的なものと見なされます。プライマリ サイトでサービスが復旧すると、ソリューションは DR サイトから永続的なプライマリ サイトへのフェイルオーバーをオーケストレーションする必要があります。DR サイトは一時的なものであり、このシナリオではフェイルバックが複雑になるため、DR サイトがアクティブな間の新しいアーテ�ィファクトの作成は推奨されません。逆に、2 番目のシナリオでは、DR サイトが新しいプライマリに昇格するため、ユーザーはサービスが復旧するのを待つ必要がなく、より迅速に作業を再開できます。さらに、このシナリオではフェイルバックは不要ですが、以前のプライマリ サイトを新しい DR サイトとして準備する必要があります。
どちらのシナリオでも、DR ソリューションの範囲内の各リージョンは必要なすべてのサービスをサポートする必要があり、ターゲット ワークスペースが良好な動作状態であることを検証するプロセスが安全策として存在しなければなりません。この検証には、シミュレートされた認証、自動化されたクエリー、API コール、ACL チェックなどが含まれる場合があります。
フェイルオーバー
DR サイトへのフェイルオーバーをトリガーする際、ソリューションは、システムを正常にシャットダウンできるものと想定することはできません。ソリューションは、プライマリ サイトで実行中のサービスのシャットダウンを試み、各サービスのシャットダウン ステータスを記録してから、定義された時間間隔で適切なステータスになっていないサービスのシャットダウンを試み続ける必要があります。これにより、プライマリサイトと DR サイトの両方でデータが同時に処理されるリスクが軽減され、データの破損が最小限に抑えられ、サービスが復元された後のフェイルバックプロセスが容易になります。
DR サイトを有効化するための大まかなステップは次のとおりです。
- 障害が発生したサービスがオンラインに復帰した場合にプライマリ リージョンが新しい�データの処理を起動しないように、プライマリ サイトでシャットダウン プロセスを実行して、プライマリ リージョンのプール、クラスタ、およびスケジュールされたジョブを無効にします。
- DRサイトのインフラストラクチャと構成が最新の状態であることを確認してください。
- 最後に同期されたデータの日付を確認します。ディザスタリカバリの業界用語をご覧ください。このステップの詳細は、データの同期方法や固有のビジネス ニーズによって異なります。
- データソースを安定させ、それらがすべて利用可能であることを確認します。オブジェクトストレージ、データベース、pub/sub システムなど、すべての重要な外部データソースを含めます。
- プラットフォームユーザーに通知します。
- 関連するプールを起動します(または `min_idle_instances` を適切な数に増やします)。
- 関連するクラスター、ジョブ、SQLウェアハウスを起動します (終了していない場合)。
- ジョブの並列実行数を変更し、関連するジョブを実行します。これらは、1回限りのラン、または定期的なランが可能です。
- ジョブスケジュールを有効にする。
- Databricks ワークスペースの URL またはドメイン名を使用する外部ツールについては、新しいコントロールプレーンを考慮して構成を更新します。たとえば、REST API や JDBC/ODBC 接続の URL を更新します。コントロールプレーンが変更されると、Databricks Web アプリケーションの顧客向け URL が変更されるため、組織のユー��ザーに新しい URL を通知してください。
フェイルバック
フェイルバック時にプライマリ サイトに戻る方が制御しやすく、メンテナンス期間中に実行できます。フェイルバックはフェイルオーバーと非常によく似たプランに従いますが、4つの大きな例外があります:
- ターゲット リージョンがプライマリ リージョンになります。
- フェイルバックは制御されたプロセスであるため、シャットダウンは1回限りのアクティビティであり、サービスがオンラインに戻る際にサービスをシャットダウンするためのステータスチェックは不要です。
- DRサイトは、今後のフェイルオーバーに備えて、必要に応じてResetする必要があります。
- 得られた教訓は DR ソリューションに組み込み、将来の災害イベントに備えてテストする必要があります。
まとめ
ディザスタリカバリ設定が適切に機能することを確認するために、実際の条件下で定期的にテストします。必要なときに使用できないディザスタ リカバリ ソリューションを保持していてもほとんど意味がありません。一部の組織では、数か月ごとにリージョン間でフェイルオーバーとフェイルバックを実行して、DR インフラストラクチャをテストしています。定期的に DR サイトにフェイルオーバーすることで、想定とプロセスをテストし、RPO と RTO の観点からリカバリ要件を満たしていることを確認します。これにより、組織の緊急時対応ポリシーと手順も最新の状態に保たれます。プロセスや設定全般に必要となる組織的な変更をテストします。ディザスタ リカバリ計画はデプロイ パイプラインに影響を与えるため、チ�ームが何を同期する必要があるかを認識していることを確認してください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。