Disaster Recovery Automation and Tooling for a Databricks Workspace
Part 2 of Disaster Recovery on Databricks
by Lorin Dawson, Rohit Nijhawan and Sonali Guleria
This post is a continuation of the Disaster Recovery Overview, Strategies, and Assessment blog.
Introduction
A broad ecosystem of tooling exists to implement a Disaster Recovery (DR) solution. While no tool is perfect on its own, a mix of tools available in the market augmented with custom code will provide teams implementing DR the needed agility with minimal complexity.
Unlike backups or a one-time migration, a DR implementation is a moving target, and often, the needs of the supported workload can change both rapidly and frequently. Therefore, there is no out-of-the-box or one size fits all implementation. This blog provides an opinionated view on available tooling and automation best practices for DR solutions on Databricks workspaces. In it, we are targeting a general approach that will provide a foundational understanding for the core implementation of most DR solutions. We cannot consider every possible scenario here, and some engineering efforts on top of the provided recommendations will be required to form a comprehensive DR solution.
Available Tooling for a Databricks Workspace
A DR strategy and solution can be critical and also very complicated. A few complexities that exist in any automation solution that become critically important as part of DR are idempotent operations, managing infrastructure state, minimizing configuration drift, and required for DR is supporting automation at various levels of scope, for example, multi-AZ, multi-region, and multi-cloud.
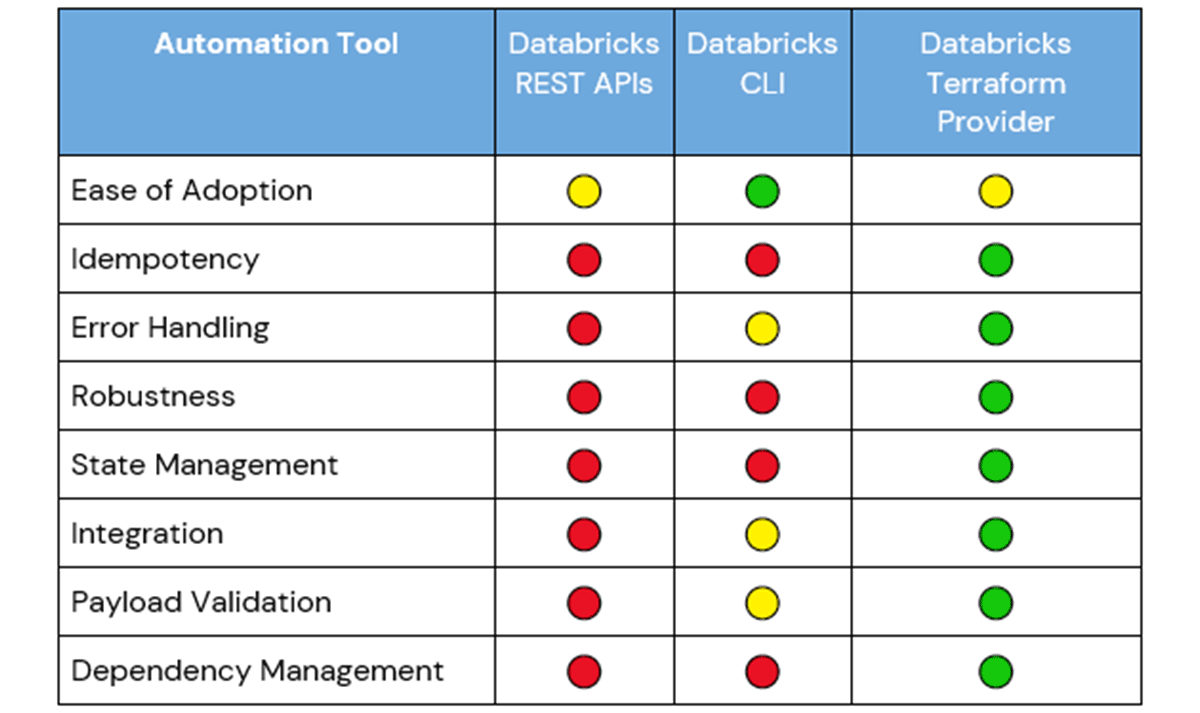
Three main tools exist for automating the deployment of Databricks-native objects. Those are the Databricks REST APIs, Databricks CLI, and the Databricks Terraform Provider. We will consider each tool in turn to review its role in implementing a DR solution.
Regardless of the tools selected for implementation, any solution should be able to:
- manage state while introducing minimal complexity,
- perform idempotent, all-or-nothing changes, and
- re-deploy in case of a misconfiguration.
Databricks REST API
There are several fundamental reasons why REST APIs are powerful automation tools. The adherence to the common HTTP standard and the REST architecture style allows a transparent, systematic approach to security, governance, monitoring, scale, and adoption. In addition, REST APIs rarely have third-party dependencies and generally include well-documented specifications. The Databricks REST API (AWS | Azure | GCP) has several powerful features that one can leverage as part of a DR solution, yet there are significant limitations to their use within the context of DR.
Benefits
Support for defining, exporting, and importing almost every Databricks object is available through REST APIs. Any new objects created within a workspace on an ad-hoc basis can be exported using the `GET` Statements API method. Conversely, JSON definitions of objects that are versioned and deployed as part of a CI/CD pipeline can be used to create those defined objects in many workspaces simultaneously using the `POST` Statements API method.
The combination of objects being defined with JSON, broad familiarity with HTTP, and REST makes this a low-effort workflow to implement.
Limitations
There is a tradeoff for the simplicity of using Databricks REST APIs for automating workspace changes. These APIs do not track state, are not idempotent, and are imperative, meaning the API calls must successfully execute in an exact order to achieve a desirable outcome. As a result, custom code, detailed logic, and manual management of dependencies are required to use the Databricks REST APIs within a DR solution to handle errors, payload validation, and integration.
JSON definitions and responses from `GET` statements should be versioned to track the overall state of the objects. `POST` statements should only use versioned definitions that are tagged for release to avoid configuration drift. A well-designed DR solution will have an automated process to version and tag object definitions, as well as ensure that only the correct release is applied to the target workspace.
REST APIs are not idempotent, so an additional process will need to exist to ensure idempotency for a DR solution. Without this in place, the solution may generate multiple instances of the same object that will require manual cleanup.
REST APIs are imperative and unaware of dependencies. When making API calls to replicate objects for a workload, each object will be necessary for the workload to successfully run, and the operation should either fully succeed or fail, which is not a native capability for REST APIs. This means that the developer will be responsible for handling error management, savepoints and checkpoints, and resolving dependencies between objects.
Despite these limitations of using a REST API for automation, the benefits are strong enough that virtually every Infrastructure as Code (IaC) tool builds on top of them.
Databricks CLI
The Databricks CLI ( AWS | Azure | GCP ) is a Python wrapper around the Databricks REST APIs. For this reason, the CLI enjoys the same benefits and disadvantages as the Databricks REST APIs for automation so will be covered briefly. However, the CLI introduces some additional advantages to using the REST APIs directly.
The CLI will handle authentication ( AWS | Azure | GCP ) for individual API calls on behalf of the user and can be configured to authenticate to multiple Databricks workspaces across multiple clouds via stored connection profiles ( AWS | Azure | GCP ). The CLI is easier to integrate with Bash and/or Python scripts than directly calling Databricks APIs.
For use in Bash scripts, the CLI will be available to use once installed, and the CLI can be treated as a temporary Python SDK, where the developer would import the `ApiClient` to handle authentication and then any required services to manage the API calls. An example of this is included below using the `ClusterService` to create a new cluster.
This snippet demonstrates how to create a single-node cluster using the Databricks CLI as a module. The temporary SDK and additional services can be found in the databricks-cli repository. The lack of idempotence present in both the REST APIs and CLI can be highlighted with the code snippet above. Running the code above will create a new cluster with the defined specifications each time it is executed; no validation is performed to verify if the cluster already exists before creating a new one.
Terraform
Infrastructure as Code (IaC) tools are quickly becoming the standard for managing infrastructure. These tools bundle vendor-provided and open-source APIs within a Software Development Kit (SDK) that includes additional tools to enable development, such as a CLI and validations, that allow infrastructure resources to be defined and managed in easy-to-understand, shareable, and reusable configuration files. Terraform in particular has significant popularity given its ease of use, robustness, and support for third-party services on multiple cloud providers.
Benefits
Similar to Databricks, Terraform is open-source and cloud-agnostic. As such, a DR solution built with Terraform can manage multi-cloud workloads. This simplifies the management and orchestration as the developers neither have to worry about individual tools and interfaces per cloud nor need to handle cross-cloud dependencies.
Since Terraform manages state, the file `terraform.tfstate` stores the state of infrastructure and configurations, including metadata and resource dependencies. This allows for idempotent and incremental operations through a comparison of the configuration files and the current snapshot of state in `terraform.tfstate`. Tracking state also permits Terraform to leverage declarative programming. HashiCorp Configuration Language (HCL), used in Terraform, only requires defining the target state and not the processes to achieve that state. This declarative approach makes managing infrastructure, state, and DR solutions significantly easier, as opposed to procedural programming:
- When dealing with procedural code, the full history of changes is required to understand the state of the infrastructure.
- The reusability of procedural code is inherently limited due to divergences in the state of the codebase and infrastructure. As a result, procedural infrastructure code tends to grow large and complex over time.
Limitations
Terraform requires some enablement to get started since it may not be readily familiar to developers like REST APIs or procedural CLI tools.
Access controls should be strictly defined and enforced within teams that have access to Terraform. Several commands, in particular `taint` and `import`, can seem innocuous but these commands allow developers to integrate their own changes into the state until such governance practices are enacted.
Terraform does not have a rollback feature. To do this, you have to revert to the previous version and then re-apply. Terraform deletes everything that is "extraneous" no matter how it was added.
Terraform Cloud and Terraform Enterprise
Given the benefits and the robust community that Terraform provides, it is ubiquitous in enterprise architectures. Hashicorp provides managed distributions of Terraform - Terraform Cloud and Terraform Enterprise. Terraform Cloud provides additional features that make it easier for teams to collaborate on Terraform together and Terraform Enterprise is a private instance of the Terraform Cloud offering advanced security and compliance features.
Deploying Infrastructure with Terraform
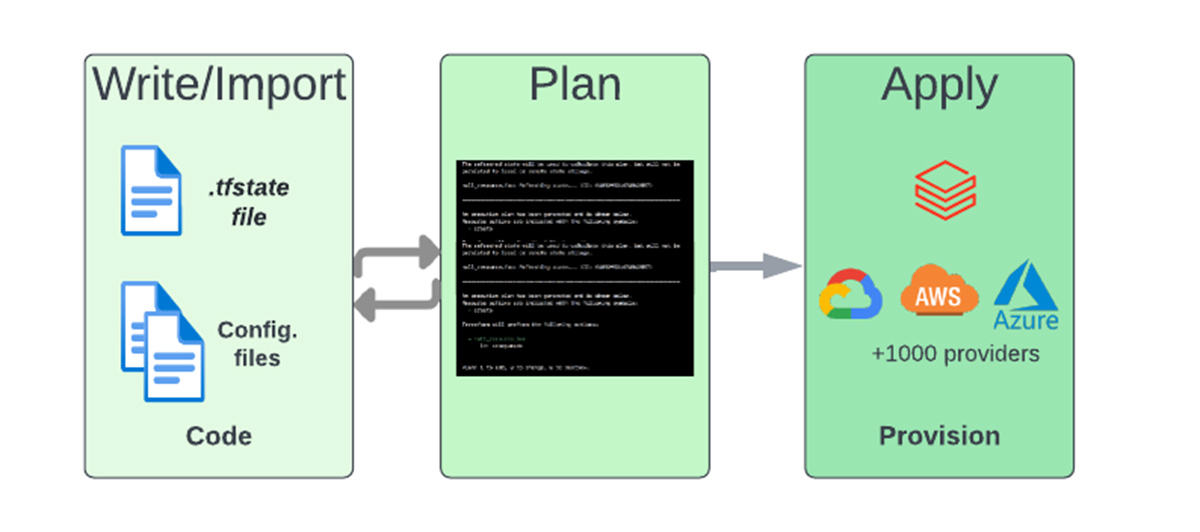
A Terraform deployment is a simple three-step process:
- Write infrastructure configuration as code using HCL and/or import existing infrastructure to be under Terraform management.
- Perform a dry run using `terraform plan` to preview the execution plan and continue to edit the configuration files as needed until the desired target state is produced.
- Run `terraform apply` to provision the infrastructure.
Databricks Terraform Provider
Databricks is a select partner of Hashicorp and officially supports the Databricks Terraform Provider with issue tracking through Github. Using the Databricks Terraform Provider helps standardize the deployment workflow for DR solutions and promotes a clear recovery pattern. The provider not only is capable of provisioning Databricks Objects, like Databricks REST APIs and the Databricks CLI, but can also provision a Databricks workspace, cloud infrastructure, and much more through the Terraform Providers available. Furthermore, the experimental exporter functionality should be used to capture the initial state of a Databricks workspace in HCL code while maintaining referential integrity. This significantly reduces the level of effort required to adopt IaC and Terraform.
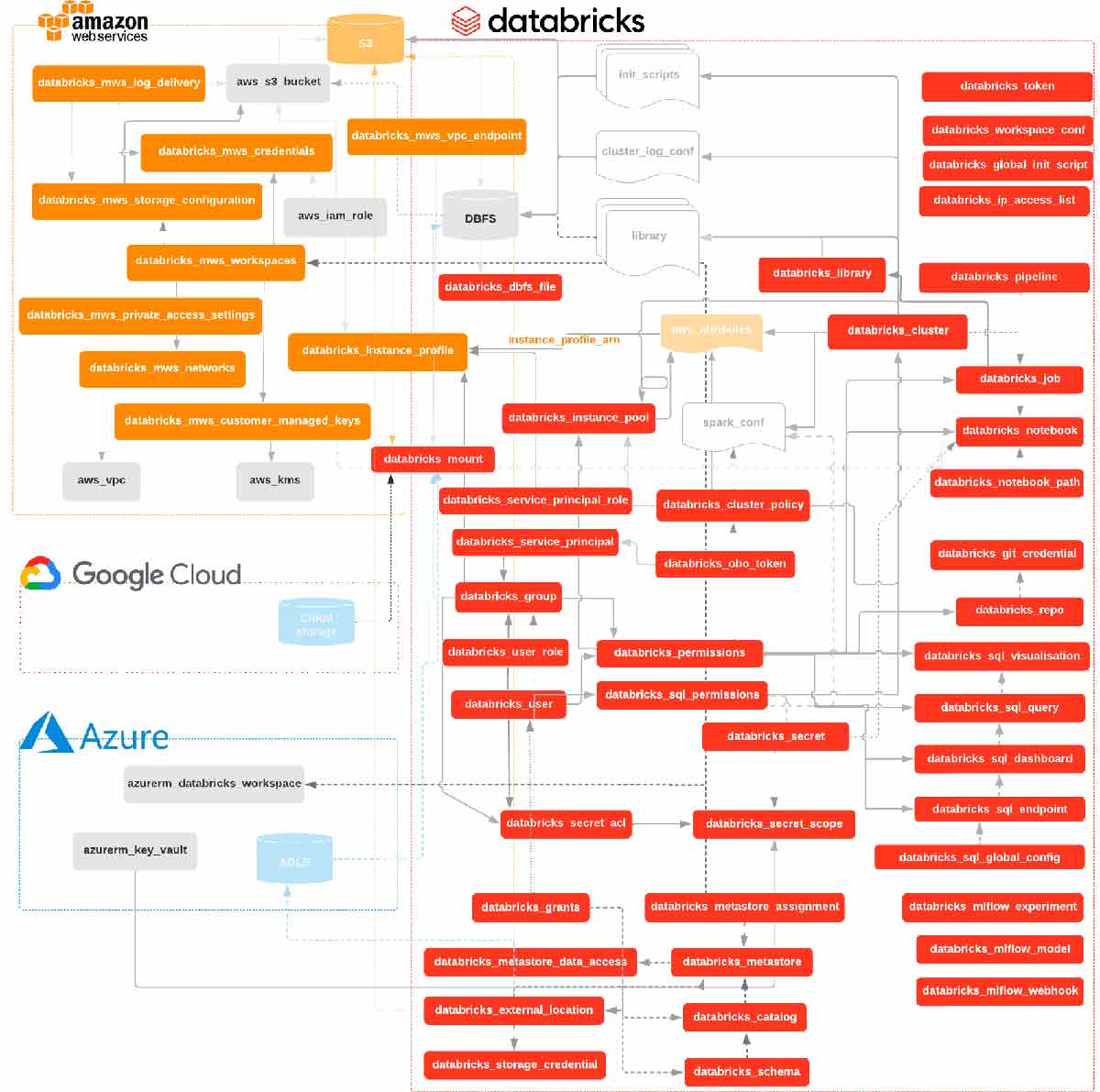
In conjunction with the Databricks Provider, Terraform is a single tool that can automate the creation and management of all the resources required for a DR solution of a Databricks workspace.
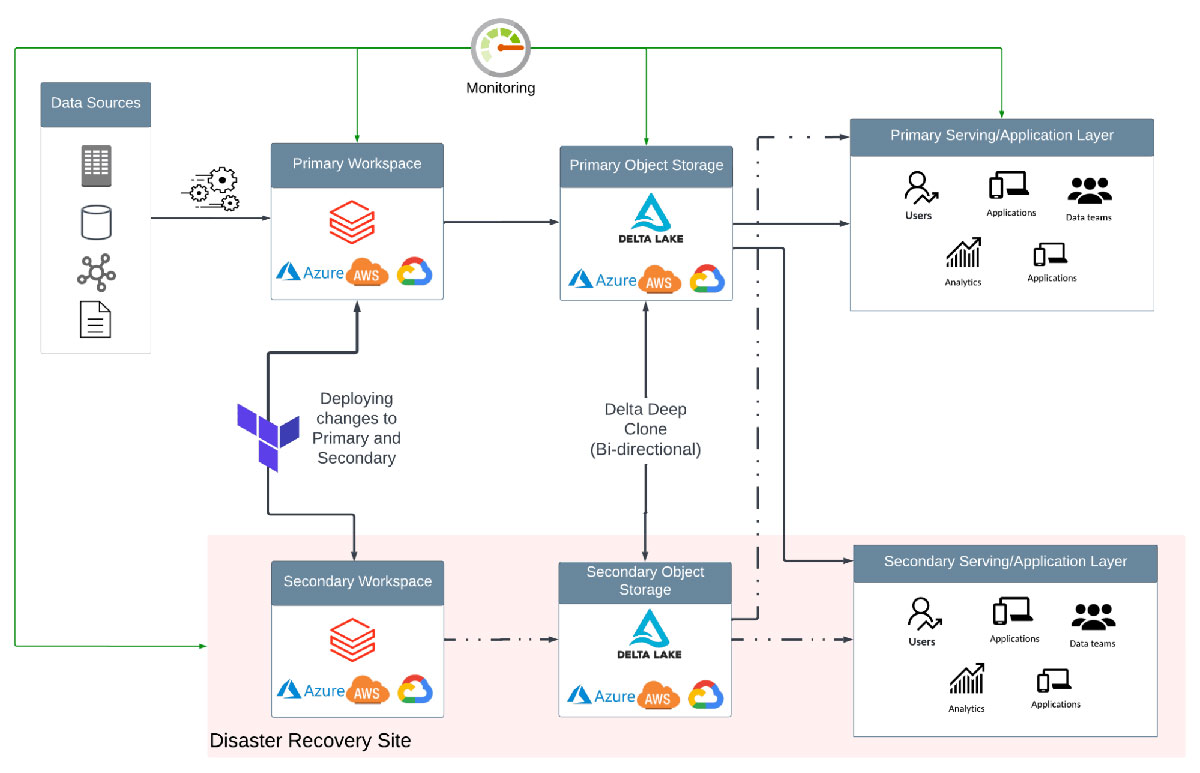
Automation Best Practices for Disaster Recovery
Terraform is the recommended approach for efficient Databricks deployments, managing cloud infrastructure as part of CI/CD pipelines, and automating the creation of Databricks Objects. These practices simplify implementing a DR solution at scale.
All infrastructure and Databricks objects within the scope of the DR solution should be defined as code. For any resource that is not already managed by TF, definite the resource as code is a one-time activity.
Workloads that are scheduled and/or automated should be prioritized for DR and should be brought under TF management. Ad-hoc work, for example, an analyst generating a report on production data, should be automated as much as possible with an optional, manual validation. For artifacts that cannot be automatically managed, i.e. some user interaction is required, strict governance with a defined process will ensure these are under the management of the DR solution. Adding tags when configuring compute, including Jobs ( AWS | Azure | GCP ), Clusters ( AWS | Azure | GCP ), and SQL Endpoints (AWS | Azure | GCP ), can facilitate the identification of objects which should be within scope for DR.
Infrastructure code should be separate from application code and exist in at least two exclusive repositories, one repository containing infrastructure modules that serve as blueprints and another repository for live infrastructure configurations. The separation simplifies testing module code and promotes immutable infrastructure versions using trunk-based development. Furthermore, state files must not be manually altered and be sufficiently secured to prevent any sensitive information from being leaked.
Critical infrastructure and objects that are in-scope for DR must be integrated into CI/CD pipelines. By adding Terraform into an existing workflow, developers can deploy infrastructure in the same pipeline although steps will differ due to the nature of infrastructure code.
- Test: The only way to test modules is to deploy real infrastructure into a sandbox environment, allowing them to be inspected to verify deployed resources. A dry run is the only significant test that can be performed for live infrastructure code to check what changes it would make against the current, live environment.
- Release: Modules should leverage a human-readable tag for release management; while, live code will generate no artifact. The main branch of the live infrastructure repo will represent in exactness what is deployed.
- Deploy: The pipeline for deploying live infrastructure code will depend on `terraform apply` and which configurations were updated. Infrastructure deployments should be run on a dedicated, closed-off server so that CI/CD servers do not have permission to deploy infrastructure. Terraform Cloud and Terraform Enterprise offer such an environment as a managed service.
Unlike application code, infrastructure code workflows require a human-in-the-loop review for three reasons:
- Building an automated test harness that elicits sufficient confidence in infrastructure code is difficult and expensive.
- There is no concept of a rollback with infrastructure code. The environment would have to be destroyed and re-deployed from that last-known safe version.
- Failures can be catastrophic, and the additional review can help catch problems before they're applied.
The human-in-the-loop best practice is even more important within a DR solution than traditional IaC. A manual review should be required for any changes since a rollback to a known good state on the DR site may not be possible during a disaster event. Furthermore, an incident manager should own the decision to fail over to the DR site and fail back to the primary site. Processes should exist to ensure an accountable and responsible person are always available to trigger the DR solution if needed and that they're able to consult with the appropriate, impacted business stakeholders.
A manual decision will avoid unnecessary failover. Short outages that either do not qualify as a Disaster Event or that the business may be able to withstand, may still trigger a failover if the decision is fully automated. Allowing this to be a business-driven decision, avoids the unnecessary risk of data corruption inherent to a failover/failback process and reduces cost in the effort of coordinating the failback. Finally, if this is a human decision, the business could assess the impact by allowing for changes on the fly. A few example scenarios where this could be important include deciding how quickly to failover for an e-commerce company near Christmas compared to a regular sales day, or a Financial Services company that must failover quicker because regulatory reporting deadlines are pending.
A monitoring service is a required component for every DR solution. Detection of failure must be fully automated, even though automation of the failover/failback decision is not recommended. Automated detection provides two key benefits. It can trigger alerts to notify the Incident Manager, or person responsible, and timely surface information required to assess the impact and make the failover decision. Likewise, after a failover, the monitoring service should also detect when services are back online and alert the required persons that the primary site has returned to a healthy state. Ideally, all service level indicators (SLIs), such as latency, throughput, availability, etc., which are monitored for health and used to calculate service level objectives (SLOs) should be available in a single pane.
Services with which the workload directly interfaces should be in-scope for monitoring. A high-level overview of services common in Lakehouse workloads can be found in part one of this series. However, it is not an exhaustive list. Databricks services to which a user can submit a request that should be monitored can be found on the company's status page ( AWS | Azure | GCP ). In addition, services in your cloud account are required for appliances deployed by SaaS providers. In the instance of a Databricks deployment, this includes compute resources ( AWS | Azure | GCP ) to spin up Apache Spark™ clusters and object storage ( AWS | Azure | GCP ) that the Spark application can use for storing shuffle files.
Get Started:
Terraform Tutorials - HashiCorp Learn
Terraform Provider Documentation for Databricks on AWS
Azure Databricks Terraform Provider Documentation
Terraform Provider for Documentation Databricks on GCP
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.