Disaster Recovery Overview, Strategies, and Assessment
Part 1 of Disaster Recovery on Databricks
by Lorin Dawson, Rohit Nijhawan and Serge Smertin
When deciding on a Disaster Recovery (DR) strategy that serves the entire firm for most applications and systems, an assessment of priorities, capabilities, limitations, and costs is necessary.
While it is tempting to expand the scope of this conversation to various technologies, vendors, cloud providers, and on-premises systems, we'll only focus on DR involving Databricks workspaces. DR information specific to cloud infrastructure for AWS, Azure, and GCP is readily available at other sources.
In addition, how DR fits into Business Continuity (BC), and its relation to High Availability (HA) is out of scope for this series. Suffice to say that solely leveraging HA services are not sufficient for a comprehensive DR solution.
This initial part of the series will focus on determining an appropriate DR strategy and implementation for critical use cases and/or workloads running on Databricks. We will discuss some general DR concepts, but we'd encourage readers to visit the Databricks documentation (AWS | Azure | GCP) for an initial overview of DR terminology, workflow, and high-level steps to implement a solution.
Disaster Recovery planning for a Databricks workspace
Defining Loss Limits
Determining an acceptable Recovery Point Objective (RPO), the maximum targeted period in which data might be lost, and Recovery Time Objective (RTO), the targeted duration of time and service level within which a business process must be restored, is a fundamental step toward implementing a DR strategy for a use case or workload running on Databricks. RTO and RPO should be decided within specific contexts, for example at the use case or workload level, and independently of each other. These define the loss limits during a disaster event, will inform the appropriate DR strategy, and determine how fast the DR implementation should recover from a disaster event.
RPO for Databricks Objects
Databricks objects should be managed with CI/CD and Infrastructure as Code (IaC) tooling, such as Terraform (TF), for replication to a DR site. Databricks Repos (AWS | Azure | GCP) provides git integration that facilitates pulling source code to a single or multiple workspaces from a configured git provider, for example, GitHub.
Databricks REST APIs (AWS | Azure | GCP) can be used to publish versioned objects to the DR site at the end of a CI/CD pipeline, however, this approach has two limitations. First, the REST APIs will not track the target workspace's state, requiring additional effort to ensure all operations are safe and efficient. Second, an additional framework would be required to orchestrate and execute all of the needed API calls.
Terraform eliminates the need to track state manually by versioning it and then applying required changes to the target workspace, making any necessary changes on behalf of the user in a declarative fashion. A further advantage of TF is the Databricks Terraform Provider which permits interaction with almost all Dataricks and Cloud resources needed for a DR solution. Finally, Databricks is an official partner of Hashicorp, and Terraform can support multi-cloud deployments. The Databricks Terraform Provider will be used to demonstrate a DR implementation as part of this series. DB-Sync is a command-line tool for the Databricks Terraform Provider that may be easier to use for managing replication for non-TF users.
The RPO for Databricks objects will be the time difference between the most recent snapshot of an object's state and the disaster event. System RPO should be determined as the maximum RPO of all objects.
RPO for Databases and Tables
Multiple storage systems can be required for any given workload. Data Sources that Apache Spark accesses through JDBC, such as OLAP and OLTP systems, will have options available for DR offered through the cloud provider. These systems should be considered as in-scope for the DR solution, but will not be discussed in-depth here since each cloud provider has varying approaches to backups and replication. Rather, the focus will be on the logical databases and tables that are created on top of files in Object storage.
Each Databricks workspace uses the Databricks File System (DBFS), an abstraction on top of Object storage. The use of DBFS to store critical, production source code and data assets are not recommnded. All users will have read and write access to the object storage mounted to DBFS, with the exception of the DBFS root. Furthermore, DBFS Root does not support cloud-native replication services and will rely solely on a combination of Delta DEEP CLONE, scheduled Spark Jobs, and the DBFS CLI to export data. Due to these limitations, anything that must be made replicated to the DR site should not be stored in DBFS.
Object storage can be mounted to DBFS (AWS | Azure | GCP), and this creates a pointer to the external storage. The mount prevents data from being synced locally on DBFS but will require the mount to be updated as part of DR since the mount point path will need to direct to different Object storage in the DR site. Mounts can be difficult to manage and could potentially point to the wrong storage, which requires additional automation and validation as part of the DR solution. Accessing Object Storage directly through external tables reduces both complexity and points of failure for DR.
Using Apache Spark, a user can create managed and unmanaged tables (AWS | Azure | GCP). The metastore will manage data for managed tables, and the default storage location for managed tables is `/user/hive/warehouse` in DBFS. If managed tables are in use for a workload that requires DR, data should be migrated from DBFS, and use a new database with the location parameter specified to avoid the default location.
An unmanaged table is created when the `LOCATION` parameter is specified during the `CREATE TABLE` statement. This will save the table's data at the specified location, and it will not be deleted if the table is dropped from the metastore. The metastore can still be a required component in DR for unmanaged tables if the source code accesses tables that are defined in the metastore by using SparkSQL or the `table` method ( Python | Scala ) of the SparkSession.
Directly using an object store, for example, Amazon S3, allows for the use of Geo-Redundant Storage if required and avoids the concerns associated with DBFS.
Data Replication
For DR, the recommended storage format is Delta Lake. Parquet is easily converted to Delta format with the `CONVERT TO DELTA` command. The ACID guarantees of Delta Lake virtually eliminate data corruption risks during failover to and failback from a DR site. Furthermore, a deep clone should be used to replicate all Delta tables. It provides an incremental update ability to avoid unnecessary data transfer costs and has additional built-in guarantees for data consistency that are not available with az- and region-based Geo-Redundant Replication (GRR) services. A further disadvantage of GRR is that the replication is one-way, creating the need for an additional process when failing back to the primary site from the DR site, whereas deep clones can work in both directions, primary site to the DR site and vice versa.
The diagram below demonstrates the initial shortcoming of using GRR with Delta Tables:
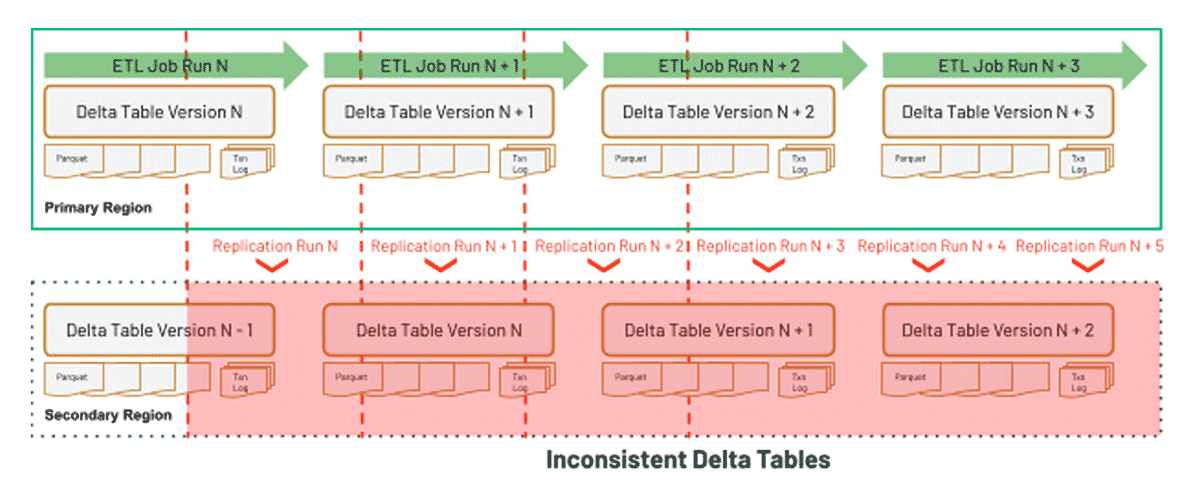
To use GRR and Delta Tables, an additional process would need to be created to certify a complete Delta Table Version (AWS | Azure | GCP) at the DR site.
Comparing the above graphic with using Delta DEEP CLONE to simplify replication for DR, a deep clone ensures that the latest version of the Delta table is replicated in its entirety, guarantees file order, and provides additional control over when the replication happens:
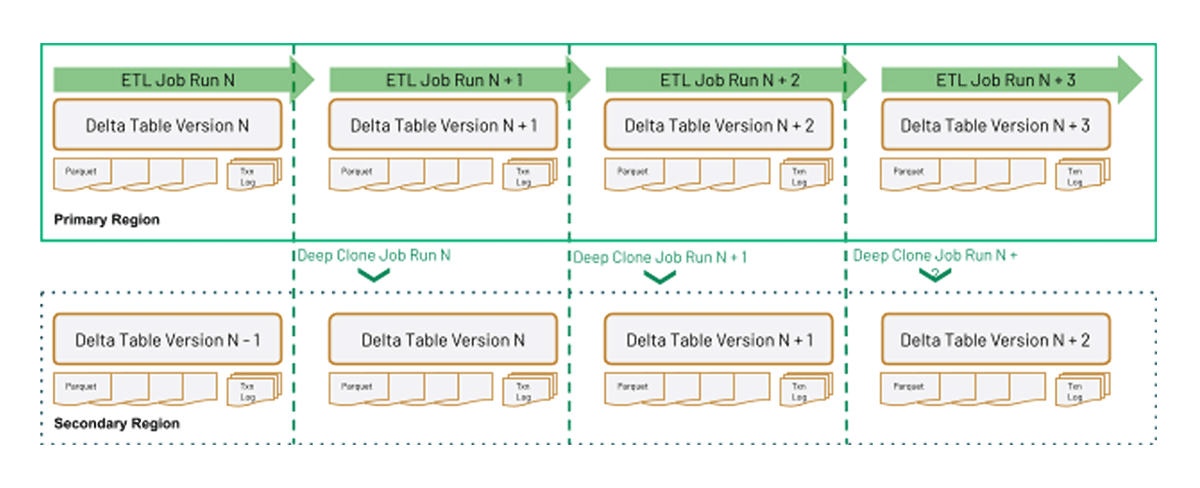
Delta DEEP CLONE will be used to demonstrate replicating Delta Tables from a primary to the secondary site as part of this blog series.
Files that cannot be converted to Delta should rely on GRR. In this case, these files should be stored within a different location than Delta files to avoid conflicts from running both GRR and Delta DEEP CLONE. A process in the DR site will need to be put in place to guarantee complete dataset availability to the business when using GRR; however, this would not be needed when using deep clones.
For data in an object store, RPO will depend on when it was last replicated using Delta Deep Clone or the SLAs provided by the cloud provider in the case of using Geo-Redundant Storage.
Metastore Replication
Several metastore options are available for a Databricks deployment, and we'll briefly consider each one in turn.
Beginning with the default metastore, a Databricks deployment has an internal Unity Catalog ( AWS | Azure | GCP ) or Hive (AWS | Azure | GCP) metastore accessible by all clusters and SQL Endpoints to persist table metadata. A custom script will be required to export tables and table ACLs from the internal Hive metastore. This couples RPO to the Databricks workspace, meaning that the RPO for the metadata required for managed tables will be the time difference in hours between when those internal metastore tables and table ACLs were last exported and the disaster event.
A cluster can connect to an existing, external Apache Hive metastore (AWS | Azure | GCP). The external metastore allows for additional replication options by leveraging cloud provider services for the underlying database instance. For example, leveraging a multi-az database instance or a cloud-native database, such as Amazon Aurora, to replicate the metastore. This option is available for Databricks on AWS, Azure Databricks, and Databricks on GCP. RPO will depend on SLAs provided by the cloud provider services if there is no manual or automated export process.
The ability to use Glue Catalog as a metastore is unique to Databricks deployments on AWS. RPO for the Glue Catalog will depend on a replication utility and/or SLAs provided by AWS.
Recovery Time Objective (RTO) in Databricks
RTO will be measured from the time that the Databricks workspace in the primary site is unavailable to the time that the workspace in the DR site reaches a predetermined level of operation to support critical activities.
Generally speaking and assuming that data is already replicated, this will require source code and dependencies for the workload/use case to be available, a live cluster or SQL Endpoint, and the metastore if accessing data through a database and tables (as opposed to accessing files directly) before RTO can be achieved.
RTO will depend on the DR strategy and implementation that is selected for the workload or use case.
Disaster Recovery Strategies
Disaster Recovery strategies can be broadly broken down into two categories: active/passive and active/active. In an active/passive implementation, the primary site is used for normal operations and remains active. However, the DR (or secondary) site requires pre-planned steps, depending on a specific implementation, to be taken for it to be promoted to primary. Whereas in an active/active strategy, both sites remain fully operational at all times.
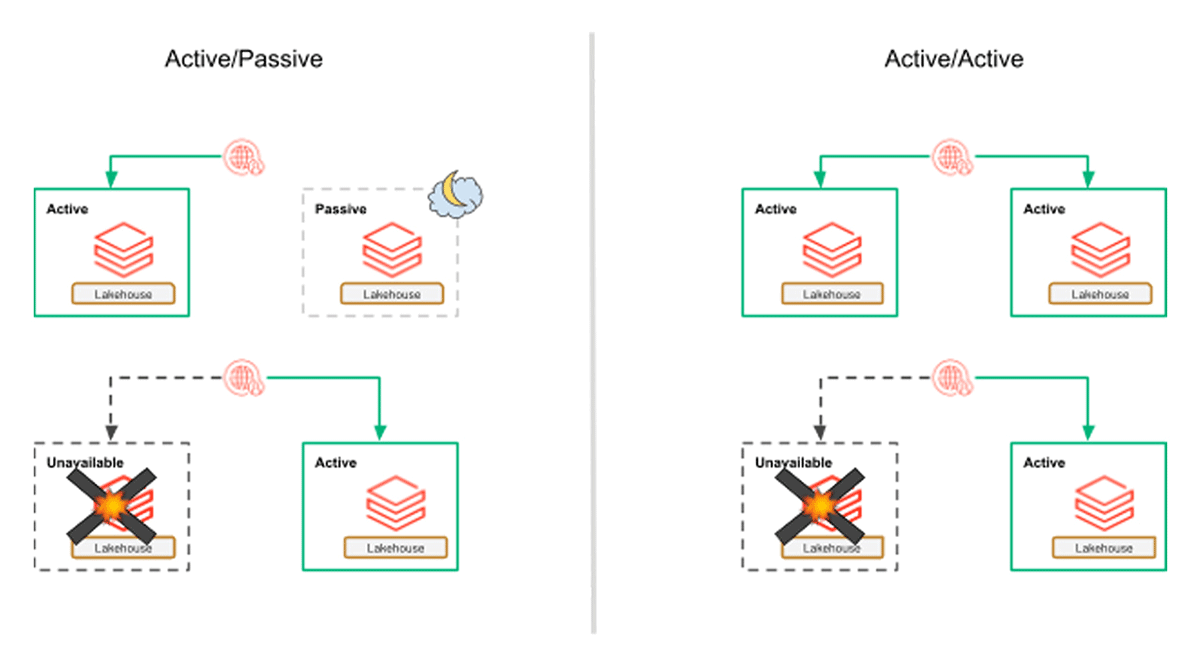
Active/Passive Strategies
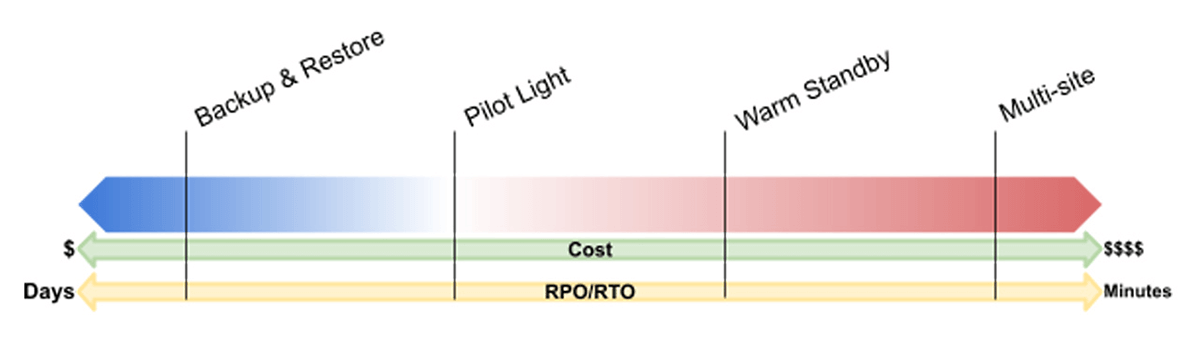
The main difference between Pilot Light and Backup & Restore is the immediate availability of data, including the metastore if reads and writes are not path-based. Some infrastructure, generally that has no or little cost, is provisioned. For a Databricks workspace, this would mean a workspace and required cloud infrastructure is deployed with required Databricks Objects provisioned (source code, configurations, instance profiles, service principals, etc.), but clusters and SQL Endpoints would not be created.
- Backup & Restore is largely considered the least efficient in terms of RTO. Backups are created on the primary site and copied to the DR site. For regional failover, infrastructure must be restored as well as performing recovery from data backups. In the case of an object store, data would still need to be replicated from the Primary site.
In this scenario, all the necessary configurations for infrastructure and Databricks Objects would be available at the DR site but not provisioned. File-based tables may need to be backfilled and other data sources would need to be restored from the most recent backup. Given the nature of Big Data, RTO can be days.
- In a Pilot Light implementation, data stores and databases are up-to-date based on the defined RPO for each, and they are ready to service workloads. Other infrastructure elements are defined, usually through an Infrastructure as Code (IaC) tool, but not deployed.
- Warm Standby maintains live data stores and databases, in addition to a minimum live deployment. The DR site must be scaled up to handle all production workloads.
Building off of Pilot Light, Warm Standby would have additional objects deployed. For example, specific clusters or SQL Endpoints may be created, but not started, to reduce RTO for serving data to downstream applications. This can also facilitate continuous testing which can increase confidence in the DR solution and the health of the DR site. Clusters and SQL Endpoints may be turned on periodically to prevent deletion and for testing or even kept turned on in extreme cases that have a very strict RTO.
Active/Active Strategy (Multi-Site)
For a multi-site DR implementation, both the primary and DR sites should be fully deployed and operational. In the event of a disaster event, new requests would simply need to be routed to the DR site instead of the primary. Multi-site offers the most efficient RTO but is also the most costly and complex.
The complexity arises from synchronizing data (ie. tables and views), user profiles, cluster definitions, jobs definitions, source code, libraries, init scripts, and any other artifacts in between the primary and DR workspaces. Further complicating matters are any hard-coded connection strings, Personal Access Tokens (PAT tokens), and URIs for API calls in various scripts and code.
Determining the Correct DR Strategy
As analytical systems become more important, failures will cause a greater impact on businesses and become more costly, and potential failure points are constantly growing as environments become more complex and interrelated. As a result, performing impact analysis on use cases and/or workloads to determine if DR is necessary and ensuring teams are prepared for the implementation of such has become a critical activity.
There are tradeoffs between each listed strategy. Ultimately, RPO and RTO will inform which one should be selected for workloads and use cases. Then, the damages, financial and non-financial, of a disaster event should be weighed against the cost to implement and maintain any given DR strategy. Based on the estimated figures, a DR strategy should be selected and implemented to ensure the continuation of services in a timely manner following a disaster-caused disruption.
Get started
Determining if a DR solution is required for the applications using the Databricks Lakehouse Platform can prevent potential losses and maintain trust with consumers of the platform. The correct DR strategy and implementation ensure costs must not exceed potential losses (financial or non-financial) while providing services to resume critical applications and functions in the event of a disaster. The assessment below provides a starting point and guidance for performing an Impact and Preparedness Analysis to determine an appropriate DR strategy and implementation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.