Cleanlab Studioを使ったより良いデータでより良いLLMを
によって Anish Athalye による投稿
Original: Better LLMs with Better Data using Cleanlab Studio
翻訳: junichi.maruyama
この投稿とそれに付随するノートブックとチュートリアルビデオは、Cleanlab Studioを使用して、大規模言語モデル(LLM、基礎モデルとも呼ばれる)のパフォーマンスを、それらが微調整されるデータを改善することによって改善する方法(Data-centric AI(DCAI)とも呼ばれるアプローチ)を示します。事例として、LLMの最も一般的な使用例の1つである、テキスト分類のためのモデルのファインチューニングを、Stanford politeness classification datasetで探ります。
この投稿では、モデル・アーキテクチャ、ハイパーパラメータ、またはトレーニング・プロセスを変更するために時間やリソースを費やすことなく、Cleanlab Studioがトレーニング・データを系統的に改良してLLMのパフォーマンスを37%向上させる方法を紹介します。
なぜ悪いデータが問題なのか?
データは企業におけるAI/MLの原動力となるが、現実のデータセットには7~50%のアノテーションエラーが含まれていることが判明している。不良データは、全体として1兆ドル規模の問題である。当然のことながら、不完全にラベル付けされたデータから外れ値まで、誤ったデータは、意図認識、エンティティ認識、シーケンス生成などのタスクにおけるMLモデルのトレーニング(および評価)を阻害�し、その影響は深刻です。LLMも例外ではありません。事前に訓練されたLLMは多くの世界知識を備えていますが、OpenAIが指摘するように、ノイズの多い訓練データによってその性能に悪影響が出ます。
この投稿では、LLMの微調整における不良データの影響を示し、Cleanlab Studioを使用してトレーニングデータを改善することで、機械学習の専門知識を必要とせず、コードを書かず、モデルアーキテクチャ、ハイパーパラメータ、トレーニングプロセスを変更するために時間やリソースを費やすことなく、不良データの悪影響(誤ったラベルなど)を軽減する方法を検証しています。
Cleanlab Studioは(どのモデルが使用されているかに関係なく)データを扱うため、GPT-10のようなまだ発明されていないLLMにも適用可能です。
LLMをファインチューニングする理由?
LLMは、その強力な生成・識別能力により、最近、至る所で使用されるようになりましたが、特定のビジネスユースケースに対して信頼できる出力を生成するのに苦労することがあります。多くの場合、ドメイン固有のラベル付きデータでのトレーニング(LLMのファインチューニングと呼ばれる)が必要とされます。
この記事では、OpenAIが提供するAPIを使ってLLMのファインチューニングを行います。DollyやMPT-7BのようなオープンソースのLLMをDatabricks上で直接ファインチューニングすることも可能です。ほとんどのデータアノテーションプロセスでは、ドメイン固有のトレーニングデータにラベルエラーが発生することが避けられず、APIやオープンソースのLLMを使用している場合でも、LLMのファインチューニングや評価精度に悪影響を与える可能性があります。
なぜCleanlab Studioなのか?
以下、OpenAIの最先端AIシステムの育成戦略について引用します。:
"私たちは、良いデータを残すことよりも、悪いデータをすべてフィルタリングすることを優先しました。"
OpenAIのように、堅牢で信頼性の高いMLモデルを作成するためにデータ内の問題を手動で処理する組織もありますが、多くの組織にとって法外なコストがかかることがあります!Cleanlab Studioは、MITから出たconfident learningと呼ばれる高度なアルゴリズムを使用して、ほとんどの種類の実世界データ(画像、テキスト、表形式、音声など)の問題を自動的に発見して修正することにより、少ない労力でデータセットを体系的に改善することができます。Cleanlab StudioにはDatabricks connectorが含まれており、Databricksに保存されているデータの品質を簡単に向上させることができます。
Cleanlab Studio は、LLMのパフォーマンスを高めるだけでなく、(1)ビジネスインテリジェンスやアナリティクスチームが信頼性の低いデータを信頼性の高いインサイトに変える、(2)MLOpsやテクノロジーチームが信頼性の低いデータに対して信頼性の高いAIソリューションをトレーニングする、エンドツーエンドのプラットフォームです。このプラットフォームはこちらから無料で試用することができます:https://cleanlab.ai/
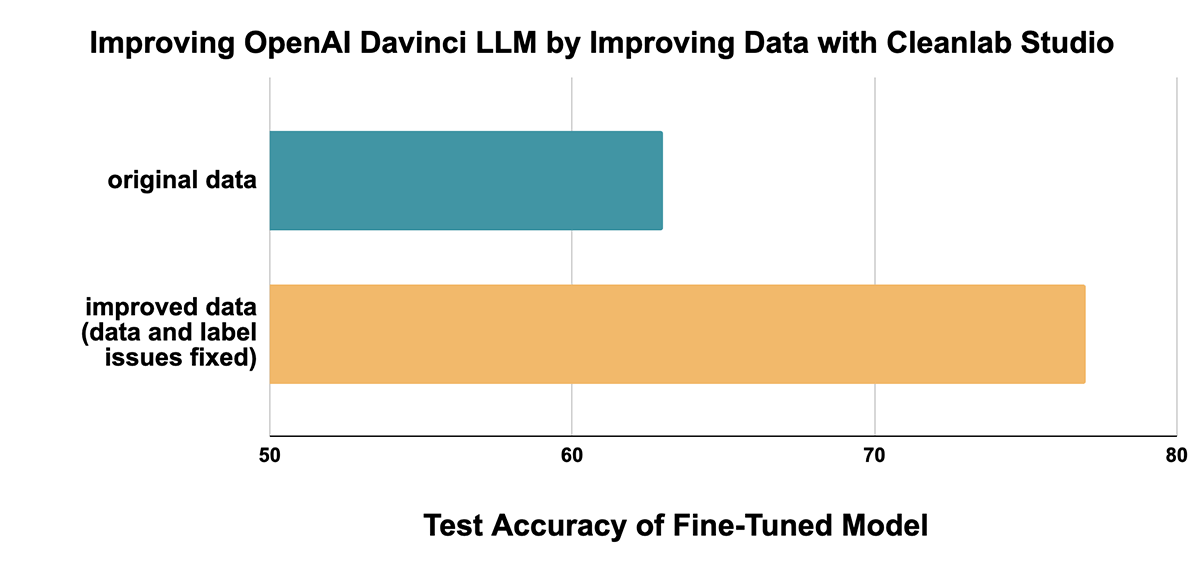
ケーススタディ: Cleanlab StudioでLLMの精度を37%向上させた。
この事例では、Stanford Politeness Datasetの一種を検討し、テキストフレーズを3つのクラス(impolite, neutral, polite)のいずれかにラベル付けしている。このデータセットは、人間のアノテーターによってラベル付けされたものであり、ラベルの中には当然ながら低品質のものもある。
この記事と付属のnotebookとtutorial videoで、その方法を説明します:
- OpenAIのAPIを利用した最先端のLLMを、元データをベースラインとしてファインチューニングする
- 元のデータ(低品質)で学習させたLLMを評価:テスト精度は65%を達成した
- Cleanlab Studioを使用して、コードを書いたりMLの専門知識がなくても、confident learningとDCAIを使用してデータ品質を改善し、改善されたデータセットを作成する。
- 改善されたデータセットでLLMをファインチューニングする。
- 改善されたLLMを評価:改善されたデータセットでファインチューニングを行うことで、テストエラーを37%削減する。
ポライトネスデータセット
訓練データセット(download)には、1人の人間によるラベル付けが行われた1916の例が含まれている。もちろん、人間は間違いを犯すので、このようなラベル付けプロセスは信頼できない。テストデータセット(download))は、5人の注釈者がラベル付けした480個の例であり、真の丁寧さの高品質な近似値としてコンセンサスラベルを用いる(このコンセン��サスラベルに対するテスト精度を測定する)。公正な比較を行うため、このテストデータセットは実験中ずっと固定されています(ラベルのクリーニングやデータセットの変更はすべてトレーニングセットで行われます)。
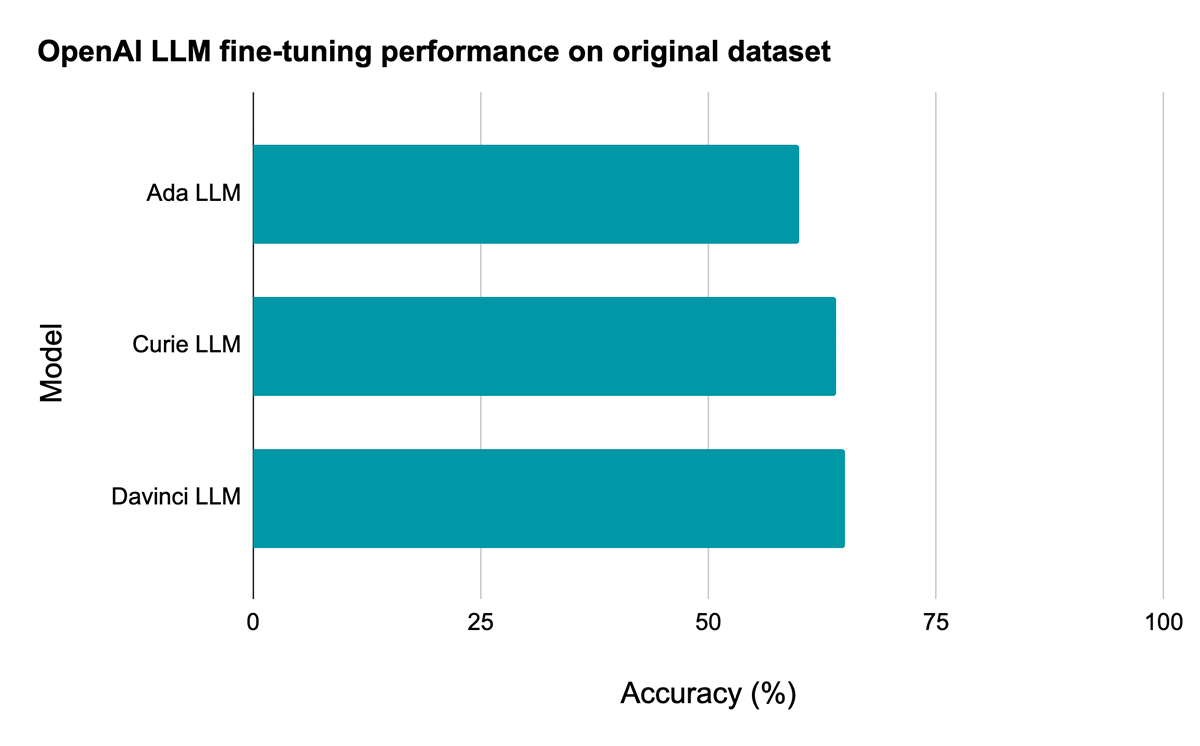
Baseline LLM: 65% accuracy (without Cleanlab Studio)
付属のノートブックでは、データセットをDBFSにダウンロードする方法、Sparkを使ってデータを前処理する方法、OpenAI APIにアップロードできるファイルを用意する方法、OpenAI APIを呼び出してモデルのファインチューニングを行う方法を説明しています。今回評価した3つのモデルの中で最も強力なDavinciモデルは、オリジナルの(低品質の)トレーニングデータセットでファインチューニングを行った場合、テストセットの精度が65%に達しました。
Cleanlab Studioを使ったデータの改善
Cleanlab StudioのDatabricks connectorを使って、わずか1行のコードでデータセットをアップロードすれば、高度なデータ中心AIアルゴリズムにデータのエラーを発見させることができます。
Cleanlab Studioは、データの問題を自動的に見つけるだけでなく、ヒューマンインザループのアプローチを使ってデータを修正することができます。ツールは、誤りのフラグが立った�データを表示し、その処理方法に関する提案(ラベルを変更する、データポイントを異常値としてマークしてデータセットから削除するなど)を提示します。
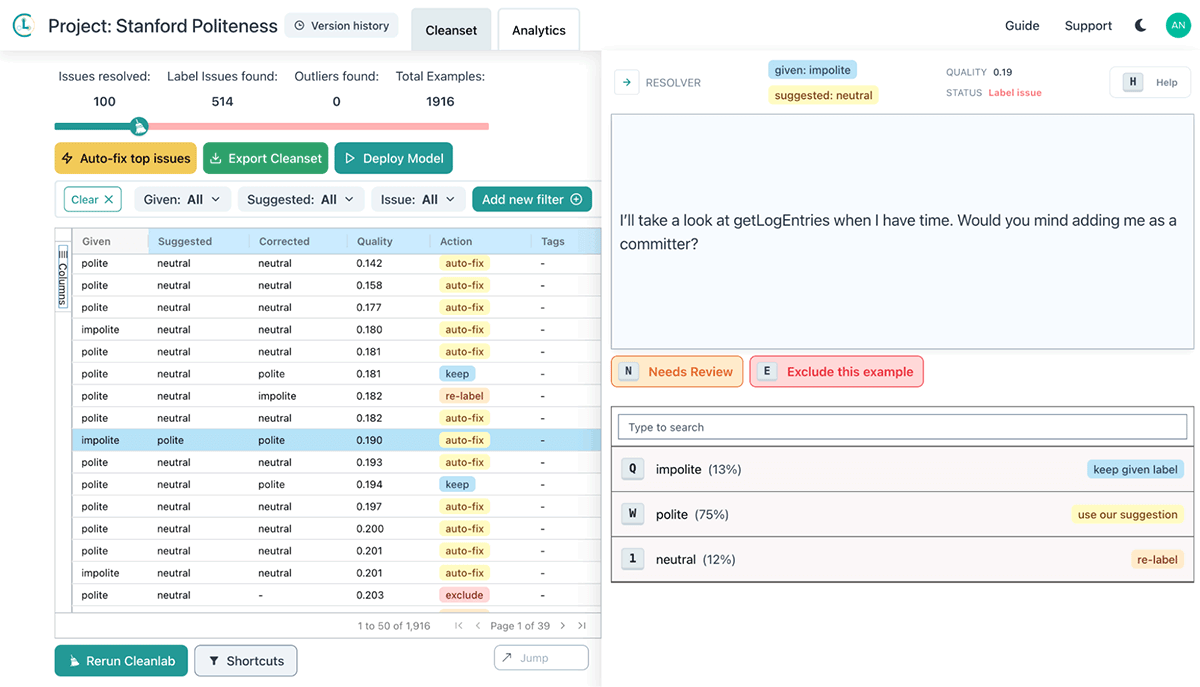
今回の事例では、このヒューマンインザループアプローチを使用して、トレーニングセット内の誤ったデータポイントを効率的に発見し、修正しました。その後、わずか1行のコードで、改善されたデータセットをDatabricksにインポートすることができます:
データ改善による影響: 78% accuracy (with Cleanlab Studio)
Cleanlab Studioから得られた改善されたデータセットでLLMをファインチューニングし、(同じテストセットで)テスト精度を計算しながら同じ評価を繰り返すと、モデルの種類を問わず劇的な改善が見られる:
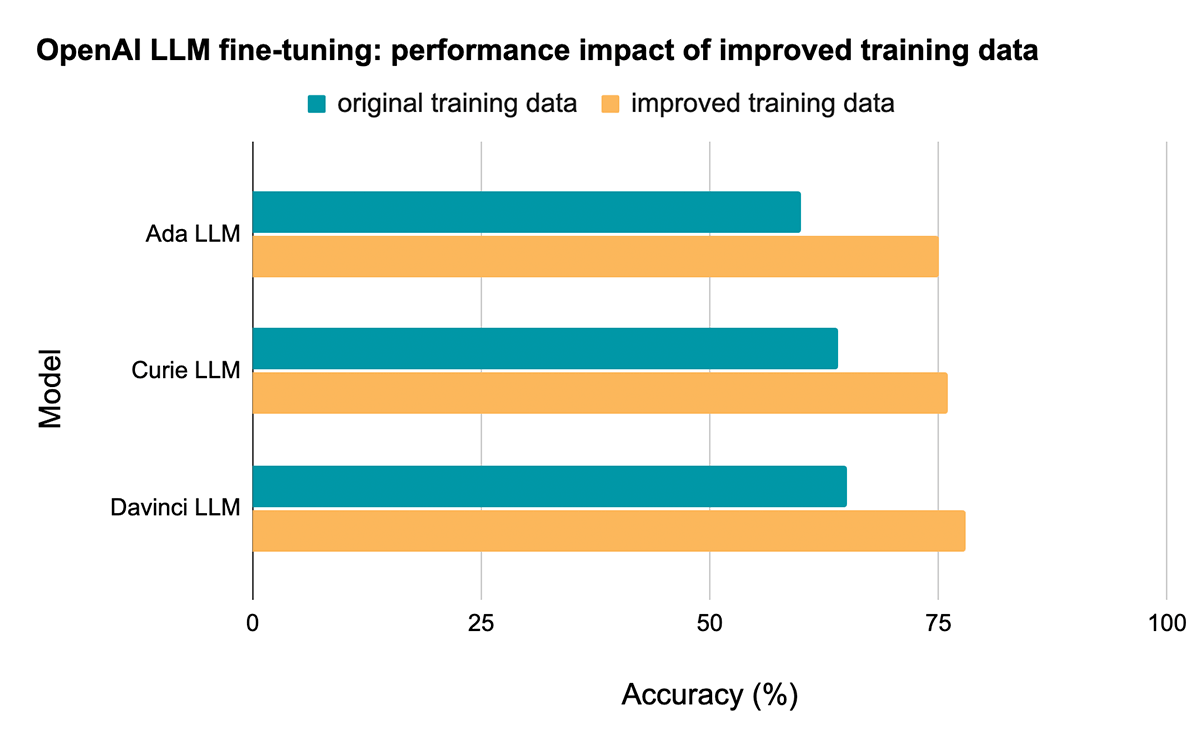
例えば Davinciモデルでは、学習データの質を向上させるだけで、テスト精度が65%から78%に向上しエラー率を37%削減することができました!
Takeaway: Cleanlab Studioを使用して、信頼性の低いデータをより信頼性の高い洞察とモデルに変換します
外れ値やラベルの問題などのエラーは実世界のデータセットによくあることで、これらの��エラーは、このデータでトレーニングされたMLモデルの信頼性と堅牢性、および得られる洞察と分析に劇的な影響を与えることがあります。Cleanlab Studioは、データサイエンティストがしばしば恐れる退屈な手作業を回避するために、AI自動化技術によって誤りやノイズのあるデータに対処するためのソリューションです。Cleanlab Studioは、コードを書いたりMLの専門知識がなくても、あらゆるMLモデル(LLMだけではない)やほとんどの種類のデータ(テキストだけでなく、画像、音声、表形式データなど)のデータやラベルの問題を効率的に発見し修正することができます。この記事のケーススタディでは、モデルアーキテクチャ、ハイパーパラメータ、またはトレーニングプロセスを変更するために時間やリソースを費やすことなく、分類タスク用に微調整されたLLMのパフォーマンスをCleanlab Studioが37%向上させたことを確認しました。
Cleanlab Studioは、基礎となるデータを改善することでモデルと洞察を向上させるため、現在存在する、あるいは将来存在する可能性のあるあらゆるモデルやLLMに対応し、より正確なモデルがリリースされればされるほど、問題を特定する能力が向上します!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。