
大規模言語モデルとは?
大規模言語モデル(LLM)は、翻訳、質問への回答、チャットやコンテンツの要約、コンテンツやコードの生成など、言語関連のタスクの実行に極めて効果的な機械学習モデルです。LLM は、膨大なデータセットから価値を引き出し、その価値、すなわち学習結果の容易な利用を可能にします。Databricks のプラットフォームは、LLM へのアクセスおよびワークフローへの統合をシンプルにします。ユーザー独自のデータを活用して LLM のファインチューニングを行うことで、ドメインパフォーマンスの向上が図れます。

LLM による自然言語処理
S&P Global は、Databricks 上の大規模言語モデルを使用して、企業の提出書類の主要な相違点と類似点をよりよく理解し、資産運用会社がより多様なポートフォリオを構築できるよう支援しています。
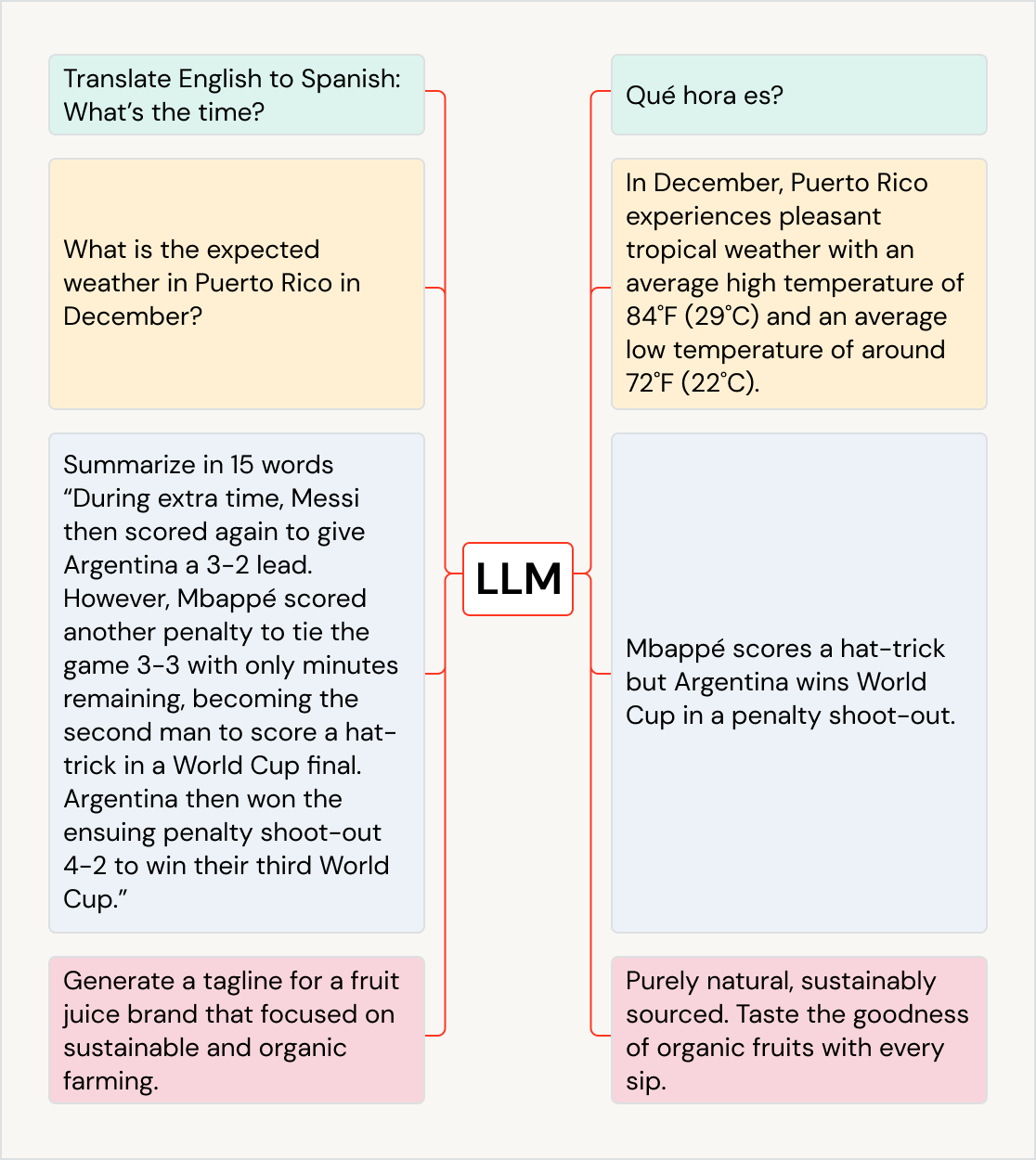
さまざまなユースケースに LLM を活用
LLM は、テキストを他の言語に翻訳する、チャットボットや AI アシスタントで顧客体験を向上させる、顧客からのフィード�バックを整理して適切な部署に分類する、決算説明会や法律文書などの大きな文書を要約する、新しいマーケティングコンテンツを作成する、自然言語からソフトウェアコードを生成する、といったユースケースや業界を超えてビジネスインパクトを促進します。また、アートを生成するモデルなど、他のモデルへの応用も可能です。一般的な LLM には、GPT ファミリーのモデル(ChatGPT など)、BERT、T5、BLOOM などがあります。
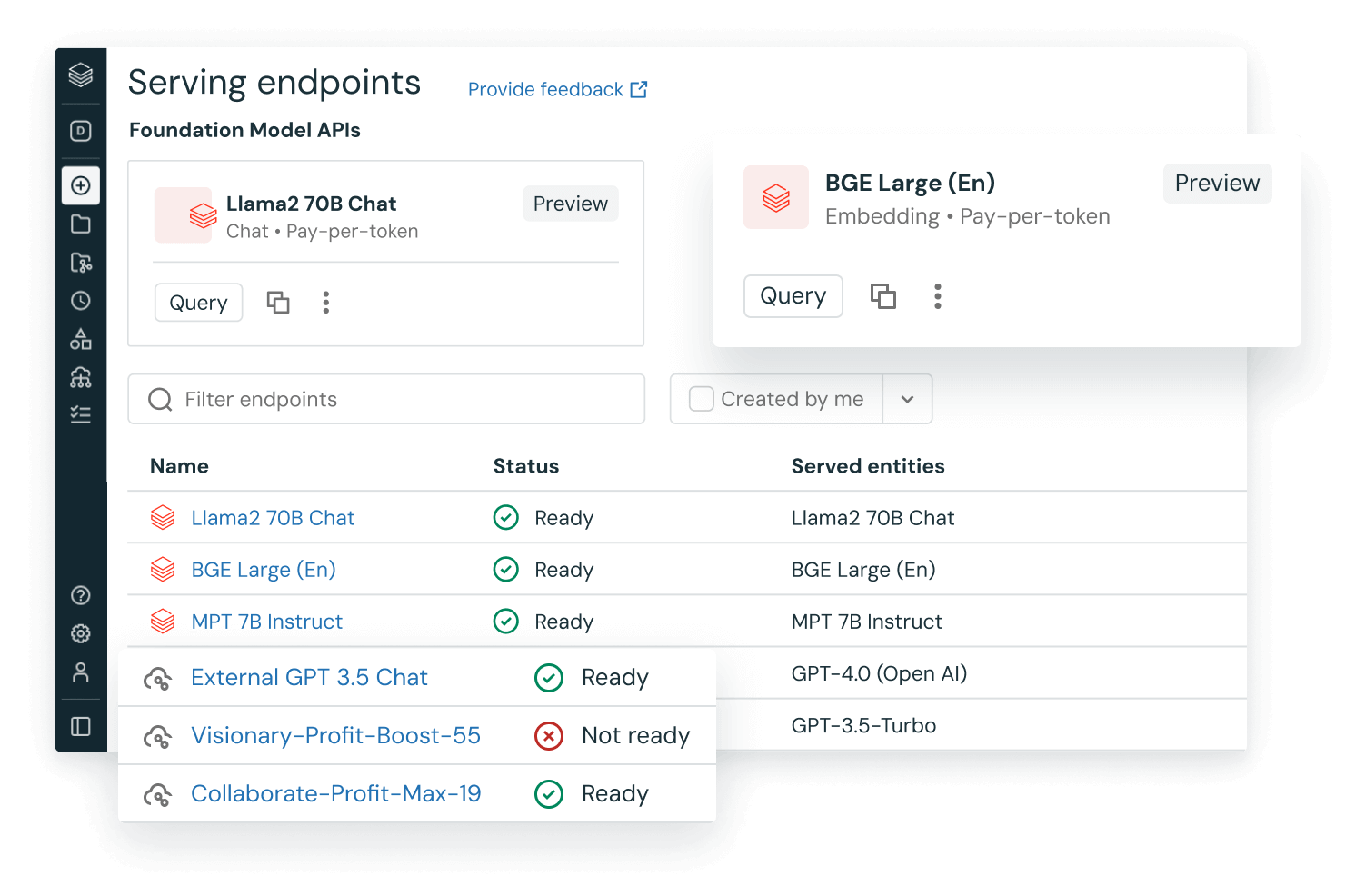
事前トレーニング済みの LLM をアプリで使用する
Hugging Face トランスフォーマーのライブラリやその他のオープンソースライブラリのような、既存の事前トレーニング済みモデルをワークフローに統合できます。トランスフォーマーのパイプラインは、GPU の利用を容易にし、GPU に送られるアイテムのバッチ処理を可能にし、スループットを向上させます。
Hugging Face トランスフォーマーの MLflow フレーバーを使用すると、変換パイプライン、モデル、および処理コンポーネントを MLflow トラッキングサービスにネイティブに統合できます。また、OpenAI のモデルや、John Snow Labs などのパートナーのソリューションを、Databricks 上のワークフローに組み込むことができます。
AI 機能により、SQL データアナリストは、データパイプラインやワークフローのなかで、OpenAI を含む LLM モデルに直接アクセスすることができます。
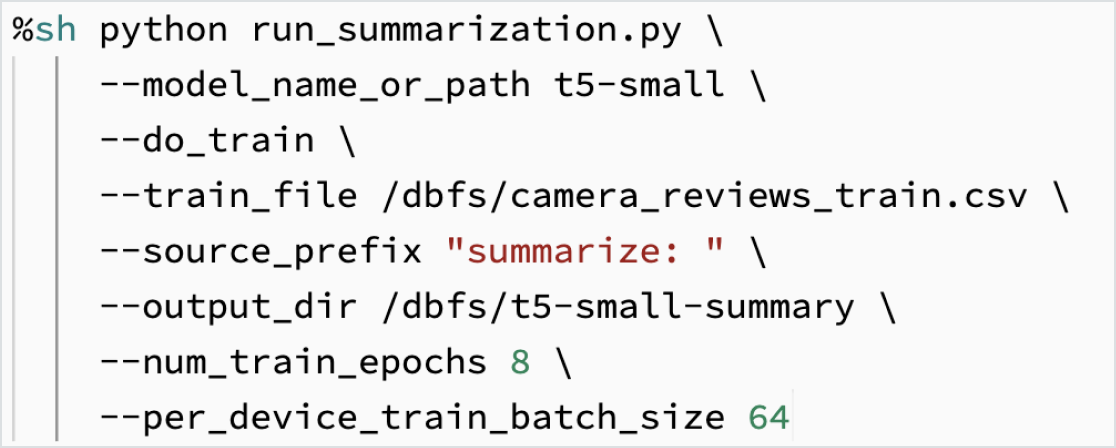
ユーザー独自のデータを使用して LLM をファインチューニングする
特定のタスクのために、ユーザー独自のデータでモデルをカスタマイズできます。Hugging Face や DeepSpeed などのオープンソースツールのサポートにより、基礎となる LLM を迅速かつ効率的に取得し、独自のデータでトレーニングを開始することで、ドメインやワークロードに対してより高い精度を持つことができます。これにより、トレーニングに使用するデータを管理できるようになり、責任を持って AI を使用していることを確認できます。

Dolly 2.0 は、Databricks が独自の LLM を低コストで迅速にトレーニングする方法を実証するために開発された、大規模言語モデル(LLM)です。モデルのトレーニングに使用された、人間が作成した高品質のデータセットdatabricks-dolly-15kもオープンソース化されています。Dolly 2.0 では、お客さま自身が LLM を所有、運用、カスタマイズすることが可能になりました。エンタープライズは、独自の LLM にデータを送る必要がなく、自社のデータで LLM を構築し、トレーニングできます。Dolly 2.0 のコード、モデルウェイト、databricks-dolly-15k のデータセットは、 Hugging Faceで入手できます。
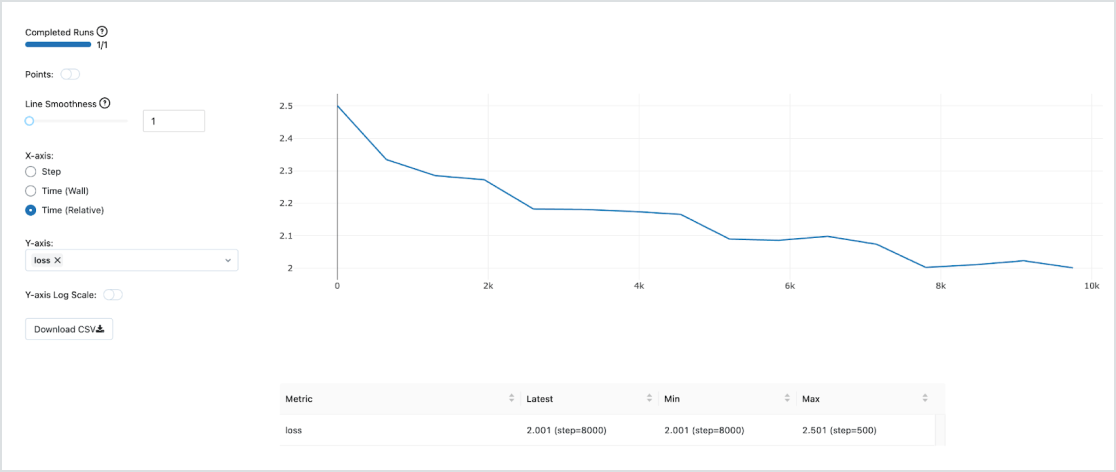
LLMOps (LLM のためのMLOps)をビルトイン
モデルの追跡、管理、デプロイメントには、マネージド MLflow に組み込まれた本番環境対応の MLOps を使用できます。モデルがデプロイされると、レイテンシー、データドリフトなどを監視し、再トレーニングパイプラインをトリガーできます。これらは全て、同じ Datbricks レイクハウス統合プラットフォーム上で行うことができ、エンドツーエンドの LLMOps を実現します。
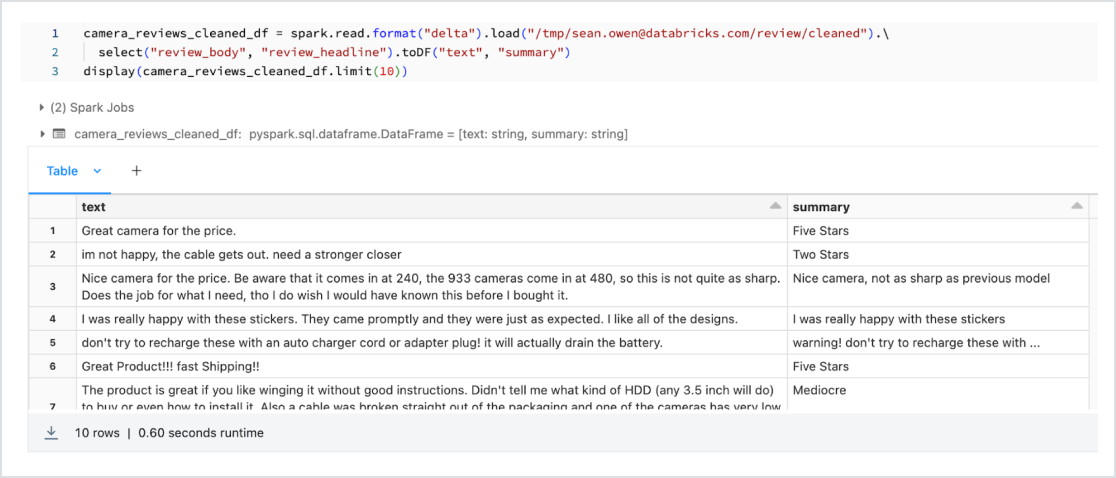
データとモデルを統合プラット�フォームで
ほとんどのモデルは複数回トレーニングされるため、トレーニングデータを同じ ML プラットフォーム上に置くことは、パフォーマンスとコストの両面で極めて重要になってきます。レイクハウスで LLM をトレーニングすることで、極めて費用対効果の高いデータレイクハウス内で、一流のツールとコンピューティングを利用し、データの経年変化に合わせてモデルの再トレーニングを継続できます。