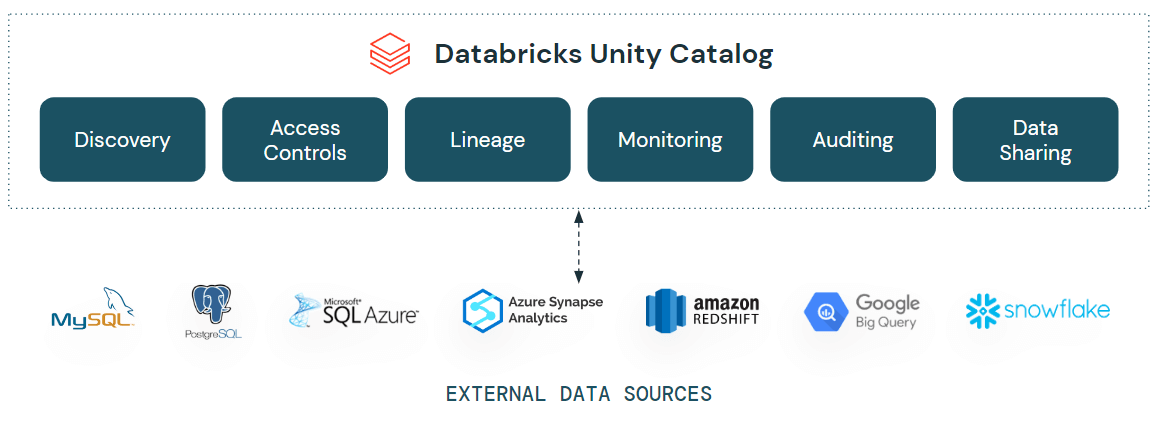
UnityカタログにLakehouseフェデレーション機能を導入
データの所在を問わず、すべてのデータを発見し、照会し、管理する
によって Matei Zaharia, Andrew Li, Can Efeoglu, シリエル・シメオネ 、 サチン タクール による投稿
翻訳: Masahiko Kitamura
オリジナル記事: Introducing Lakehouse Federation Capabilities in Unity Catalog
データチームは、データの断片化、データの統合にかかる時間とコスト、多数のシステムにわたるデータガバナンスの管理の難しさなどが主な原因で、適切なデータに素早くアクセスするために多くの課題に直面しています。
そのため、本日Data+AI Summitで、組織が統一されたガバナンスを備えた、拡張性とパフォーマンスの高いデータメッシュアーキテクチャを構築できるUnity CatalogのLakehouse Federation機能を発表できることを嬉しく思います。
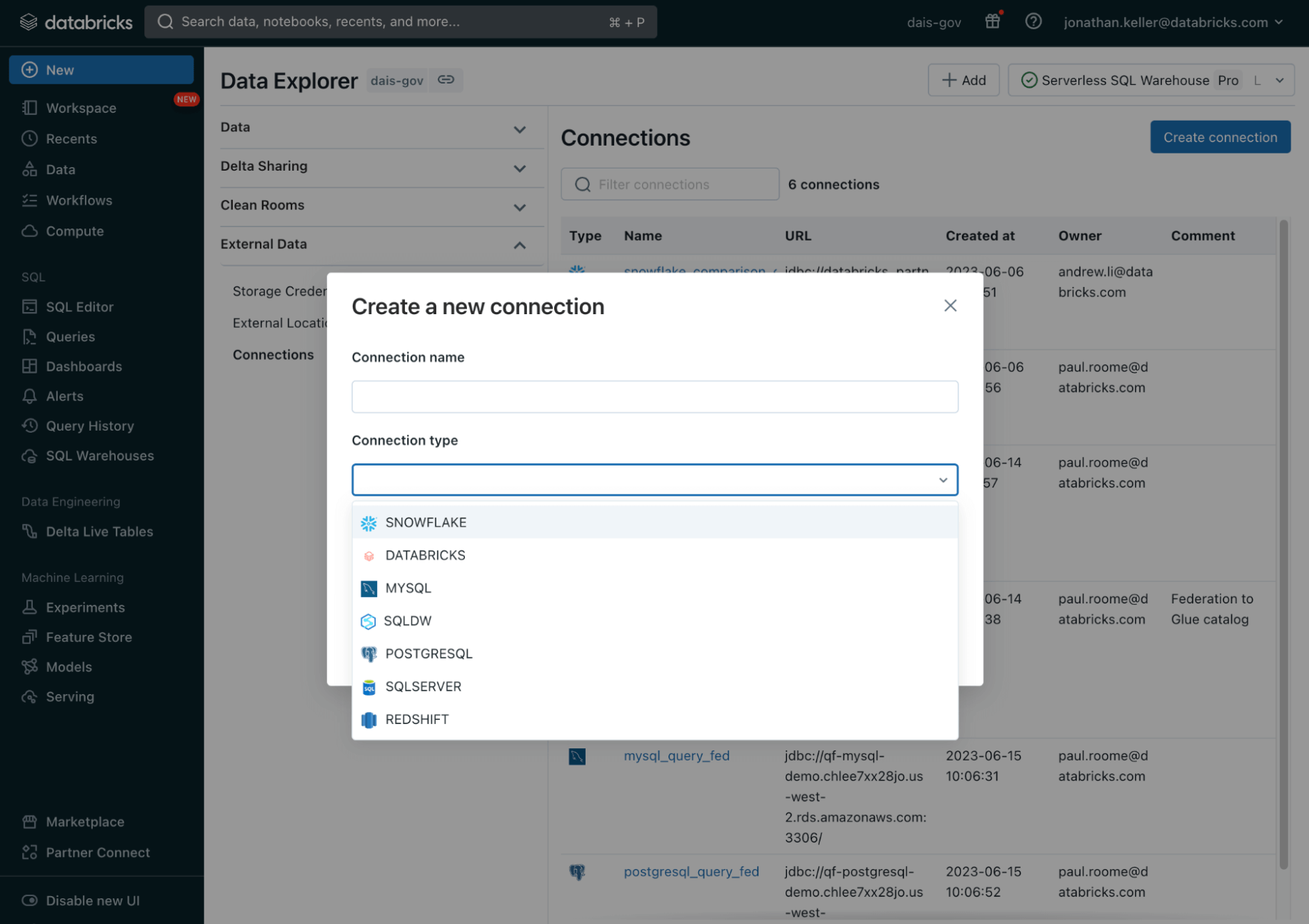
Unity Catalogは、データとAIのための統合ガバナンスソリューションを提供します。Unity CatalogのLakehouseフェデレーション機能により、MySQL、PostgreSQL、Amazon Redshift、Snowflake、Azure SQL Database、Azure Synapse、GoogleのBigQueryなどのデータプラットフォーム間で、データを移動またはコピーすることなく、Databricks内からデータを発見、クエリ、ガバナンスすることができ、そのすべてが簡素化された統一されたエクスペリエンス内で実現します。これは、行や列レベルのアクセス制御、タグのようなディスカバリ機能、データのリネージといったUnity Catalogの高度なセキュリティ機能が、これらの外部データソース全体で利用でき、一貫したガバナンスが保証されることを意味します。
BayerのテックリードであるJelle de Jongからは以下のような声をもらっています。
「データ・サイエンティストもビジネス・ユーザーも、統一されたユーザー・インターフェースを通じて、多様なデータ・ソースにアクセスすることができるようになりました。私たちは、データフォーマットをDelta Lakeに標準化し続けていますが、Lakehouse Federationのおかげで、データ抽出に投資する前に機敏に反復できるようになったことに感激しています。」
データの断片化がイノベーションを遅らせる
Databricks Lakehouse Platformでは、あらゆる規模の何千もの組織が、データとAIを活用して、世界全体、あらゆる業界でイノベーションを起こしています。しかし、歴史的、組織的、あるいは技術的な理由から、データは多くの運用システムや分析システムに散在しており、さらなる課題を引き起こしています:
- すべてのデータの発見とアクセスが困難: ほとんどの組織では、貴重なデータが複数のデータソースに分散している。複数のデータベース、データウェアハウス、オブジェクト・ストレージ・システムなどにあるかもしれない。そのため、データや洞察が不完全になり、顧客が十分な情報に基づいた意思決定を行い、迅速なイノベーションを実現する妨げとなっている。
- エンジニアリングのボトルネックによる実行の遅さ: 複数のデータソースにまたがるデータをクエリするには、通常、まず外部データソースから選択したプラットフォームにデータを移動する必要がある。その労力に見合わないデータもあるかもしれない。一部のデータは、単一の統一された場所に到達するまでに時間がかかりすぎ、イノベーションを遅らせる。
- サイロ化したシステム間でのコンプライアンスの弱さ: ガバナンスが分断されているため、取り組みが重複し、不適切なアクセスや漏えいを監視・防止できないリスクが高まる。
UnityカタログのLakehouseフェデレーションでデータエステートを統合
Lakehouse Federationは、これらの重要なペインポイントに対応し、企業がサイロ化されたデータシステムをレイクハウスの拡張機能として公開、照会、管理することを容易にします。これらの新機能により、以下のことが可能になります:
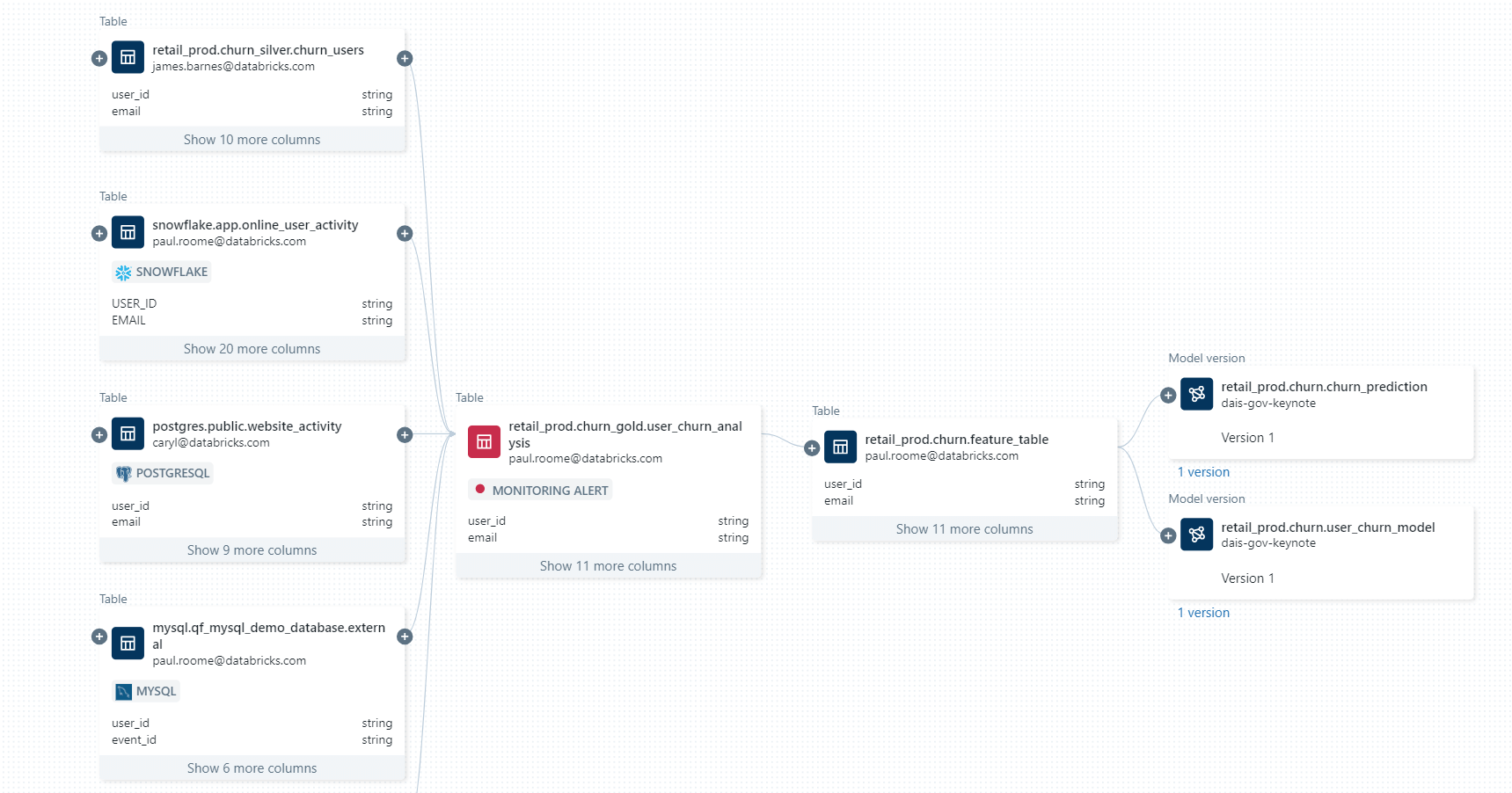
- データエステートの統合ビューを構築: 構造化データ、非構造化データを問わず、すべてのデータを一箇所で自動的に分類・発見し、組織内の誰もが、どこにデータが存在するかにかかわらず、指先ひとつですべてのデータに安全にアクセスし、探索できるようにします。
- 単一のエンジンですべてのデータを効率的に検索・結合が可能: 単一のエンジンで、最も完全なデータ(インジェスト不要)に対して、すべてのデータ、アナリティクス、AIのユースケースにわたるアドホックな分析とプロトタイピングを加速します。ソースを横断した高度なクエリプランニングとキャッシングにより、1つのクエリで複数のプラットフォームからデータにアクセスして組み合わせる場合でも、最適なクエリパフォーマンスを実現します。
- データソース全体でデータを保護: 1つの権限モデルを使用してアクセスルールを設定、適用し、データソース全体ですべてのデータを保護します。行や列レベルのセキュリティ、タグベースのポリシー、プラットフォーム間で一貫した集中監査などのルールを適用し、データの使用状況を追跡し、組み込みのデータリネージと監査可能性でコンプライアンス要件を満たします。
SEGA EuropeのデータサービストップのFelix Bakerからのフィードバックです。「Lakehouse Federationのおかげで、複数のクラウドにある複�数のソースから、利用状況、販売状況、ゲームの遠隔測定データなどのデータを組み合わせ、1つの場所からすべてを表示し、照会することができるようになりました。データを元のデータソースに残したまま、Databricks Lakehouseから利用できるようになりました。頻繁に更新される財務データを移動する必要がなくなったので、貴重な時間を節約でき、消費者に最高のゲーム体験を提供することに集中できます。」
ShellのChief Digital Technologu AdvisorのBryce Bartmannからは以下の声をいただきました。「Lakehouse Federationのおかげで、既存のデータ環境をUnity Catalogに統合する作業をより迅速に進めることができました。これにより、シェルのデータガバナンスがよりシンプルになり、より多くのデータセットが一箇所で発見可能になり、認証が標準化され、共通のプログラミング言語でデータセット間のクエリが可能になりました。最終的には、今日のエネルギーセクターで起きている変革をより効果的に進めることができるようになります。」
これらの新機能は、最近発表されたopen Hive interfaceと相まって、組織がデータ管理、発見、およびガバナンスをUnityカタログに一元化し、Amazon EMR、Apache Spark、Amazon Athena、Presto、Trinoなどの幅広いコンピューティングプラットフォームから接続できることを意味します。新しいインターフェースは、複数のデータカタログを管理する必要性をなくし、これらのプラットフォーム間で一貫したデータガバナンスを保証します。
What's next?
これらの新機能は現在プライベート・プレビュー中です。7月に予定されているパブリック・プレビューにはこちら(here)からお申し込みいただけます。
また、Unity Catalogのガバナンス機能をApache IcebergやHudiを含む様々なオープンストレージフォーマットに拡張し、Deltaユニバーサルフォーマット(「UniForm」)のパブリックプレビューを行っています。この統合により、DeltaテーブルをIcebergテーブルのように(そして近いうちにApache Hudiも)読み取ることができるようになり、Unity Catalogは3つの主要なオープンレイクハウス・ストレージフォーマットすべてをサポートする唯一のユニバーサルカタログとなります。
最後に、将来的には、Unityカタログで定義されたアクセスポリシーを連携データソースにプッシュして、データがアクセスされる場所で一貫した実施を行うこともできるようになります。これにより、異なるガバナンス・ツール間で冗長なポリシー定義を維持する必要がなくなる。
Databricks 社の共同設立者兼最高技術責任者であるマテイ・ザハリア氏によるData+AI Summit 2023 の基調講演をご覧ください。
Data + AI Summitへの参加登録はこちらから(here)。直接、またはバーチャルで参加し、データ、アナリティクス、AIの最新動向をご覧ください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。