Databricks SQLのマテリアライズド・ビューとストリーミング・テーブルの紹介
Empower data analysts to ingest, transform and deliver fresh data entirely in SQL
によって ポール・ラッパス, Michael Armbrust, Yannis Papakonstantinou 、 Nitin Sharma による投稿
翻訳:Junichi Maruyama. - Original Blog Link
AWSとAzure上のDatabricks SQL でマテリアライズド・ビューとストリーミング・テーブルが公開されたことをお知らせできることを嬉しく思います。ストリーミングテーブルは、クラウドストレージやメッセージキューからの増分インジェストを提供します。マテリアライズド・ビューは、新しいデータが到着すると自動的にインクリメンタルに更新されます。これら2つの機能を組み合わせることで、インフラストラクチャを必要としないデータパイプラインが実現し、セットアップが簡単で、新鮮なデータをビジネスに提供することができます。このブログポストでは、アナリストやアナリティクス・エンジニアがデータウェアハウスでデータとアナリティクス・アプリケーションをより効果的に提供するために、これらの新機能がどのように役立つかを探ります。
背景
データウェアハウスとデータエンジニアリングは、データ駆動型の組織にとって極めて重要である。データウェアハウスはアナリティクスとレポーティングの主要な場所として機能し、データエンジニアリングはデータの取り込みと変換のためのデータパイプラインを作成する。
しかし、従来のデータウェアハウスは、ストリーミングの取り込みと変換のために設計されていません。レガシーデータウェアハウスはバッチ処理用に設計されているため、従来のデータウェアハウスで大量のデータを低レイテ��ンシーで取り込むことは、高価で複雑です。その結果、チームは、ウェアハウスの外部で設定を必要とし、中間ステージング場所としてクラウドストレージを使用する必要がある、不器用なソリューションを実装しなければなりませんでした。このようなシステムの管理にはコストがかかり、エラーが発生しやすく、メンテナンスも複雑です。
Databricks Lakehouse Platformは、統合ソリューションを提供することで、この従来のパラダイムを破壊します。Delta Live Tables (DLT)はデータエンジニアリングとストリーミングを行うのに最適な場所であり、Databricks SQLは既存のデータレイク上のアナリティクスワークロードに対して最大12倍の価格/パフォーマンスを提供します。
さらに、dbtのようなパートナーは、この発表の後半で詳しく説明するこれらのネイティブ機能と統合できるようになりました。
データウェアハウスユーザーが直面する一般的な課題
データウェアハウスは、ビジネスインテリジェンス(BI)アプリケーションを通じた内部レポーティングのための分析とデータ配信の主要な場所として機能します。組織は、データウェアハウスを採用する際にいくつかの課題に直面します:
- セルフサービス: SQLアナリストは、データ問題を解決するために他のリ�ソースやツールに依存するという課題に直面することが多く、ビジネスニーズに対応するペースが遅くなる。
- 遅いBIダッシュボード: 大量のデータで構築されたBIダッシュボードは、結果を返すのが遅くなりがちで、さまざまな質問に答える際のインタラクティブ性やユーザビリティが損なわれる。
- 古いデータ: BIダッシュボードは、夜間にのみ実行されるETLジョブのために、昨日のデータなど古いデータを表示することが多い。
SQLを使用して、サードパーティツールを使用せずにデータを取り込み、変換する
ストリーミング・テーブルとマテリアライズド・ビューは、SQLアナリストにデータ・エンジニアリングのベスト・プラクティスを提供します。S3ロケーションから新しく到着したファイルを継続的に取り込み、シンプルなレポートテーブルを準備する例を考えてみましょう。Databricks SQLを使用すると、アナリストはS3内のファイルをすばやく検出してプレビューし、次の例のようにわずか数行のコードでシンプルなETLパイプラインを数分でセットアップすることができます:
1- S3でデータを発見し、プレビューする
2- ストリーミング方式でデータを取り込む
3- マテリアライズド・ビューを使用してデータをインクリメンタルに集約する
マテリアライズド・ビューとは何か?
マテリアライズド・ビューは、低速なクエリや頻繁に使用される計算を事前に計算することで、コストを削減し、クエリの待ち時間�を改善する。データエンジニアリングの文脈では、データを変換するために使用されます。しかし、(1)エンドユーザクエリとBIダッシュボードをスピードアップし、(2)データを安全に共有するために使用することができるため、データウェアハウスコンテキストにおけるアナリストチームにとっても価値があります。MV は Delta Live Tables 上に構築され、低速なクエリや頻繁に使用される計算を事前に計算することで、クエリのレイテンシを削減します。
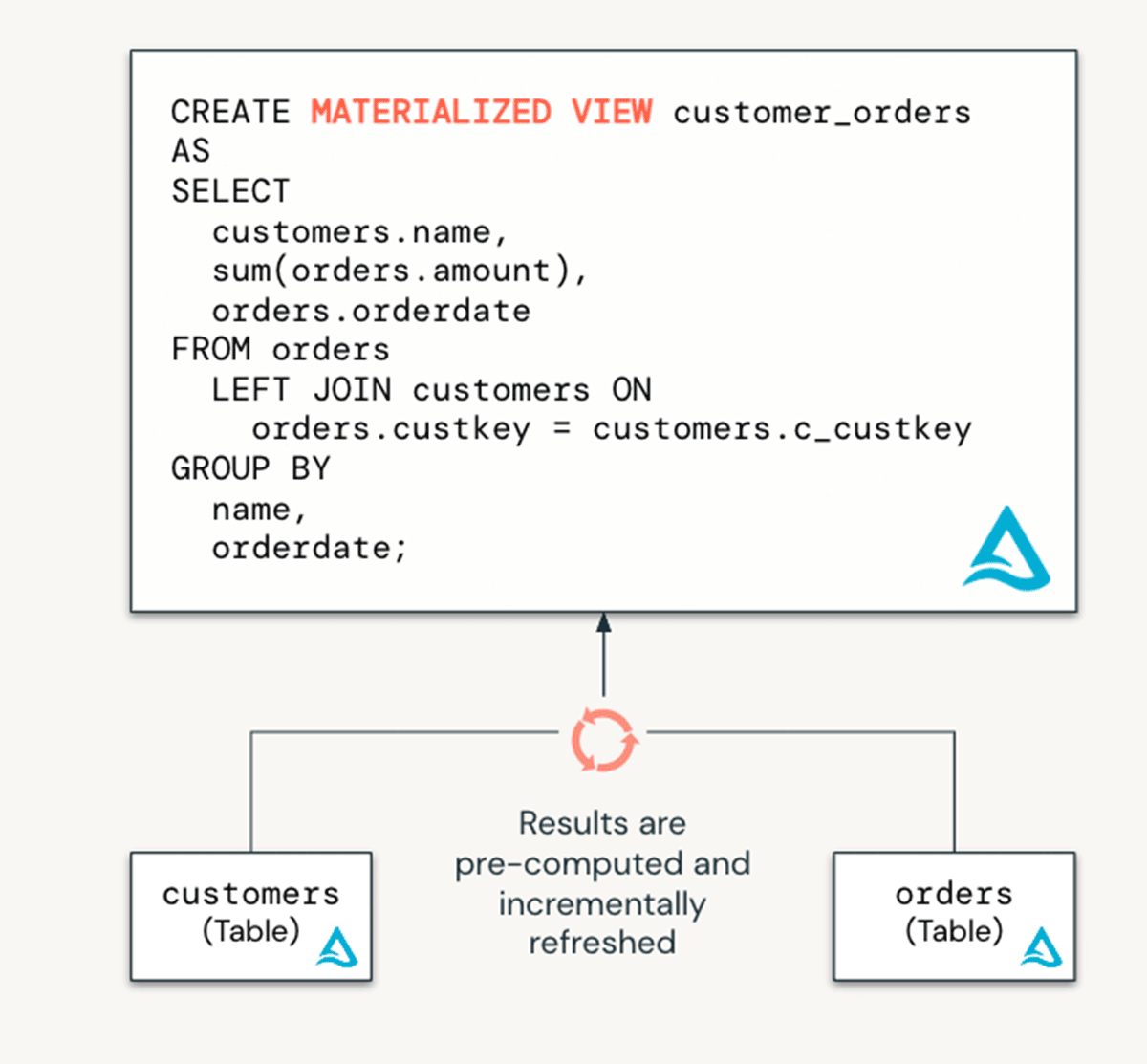
マテリアライズド・ビューの利点
- BIダッシュボードの高速化。MVはデータを事前に計算するため、エンドユーザはベーステーブルに直接クエリを実行してデータを再処理する必要がなく、クエリが大幅に高速化します。
- データ処理コストの削減。MVの結果はインクリメンタルに更新されるため、新しいデータが到着したときにビューを完全に再構築する必要がありません。
- 安全な共有のためのデータアクセス制御の改善。ベース・テーブルへのアクセスを制御することで、コンシューマが閲覧できるデータをより厳密に管理します。
ストリーミング・テーブルとは何か?
DBSQLにおける取り込みは、ストリーミング・テーブル(ST)を使用して行われます。STはデータを "ブロンズ "テーブルに取り込むための理想的なものと考えることができます。STは、クラウドストレージ、メッセージバス(EventHub、Apache Kafka)など、あらゆるデータソースからの継続的でスケーラブルな取り込みを可能にします。
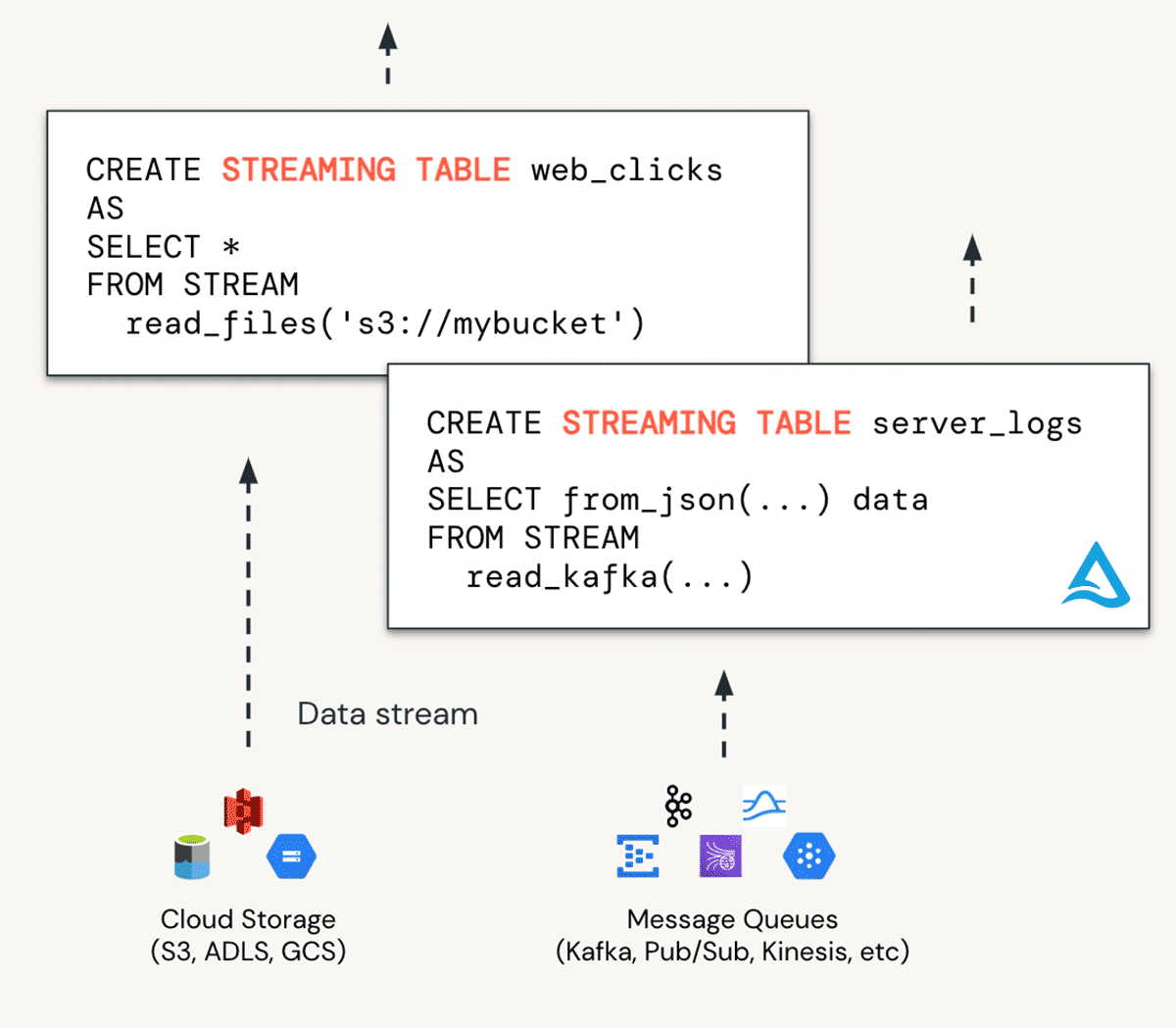
ストリーミング・テーブルのメリット
- リアルタイムのユースケースを解き放つ。リアルタイム分析/BI、機械学習、運用ユースケースをストリーミングデータでサポートできます。
- スケーラビリティの向上。インクリメンタルな処理と大規模なバッチ処理により、大量のデータをより効率的に処理。
- より多くの実務家を支援。シンプルなSQL構文により、すべてのデータエンジニアやアナリストがデータストリーミングにアクセスできるようになります。
顧客事例:AdobeとDanske Spilがマテリアライズド・ビューでダッシュボードのクエリを高速化した方法
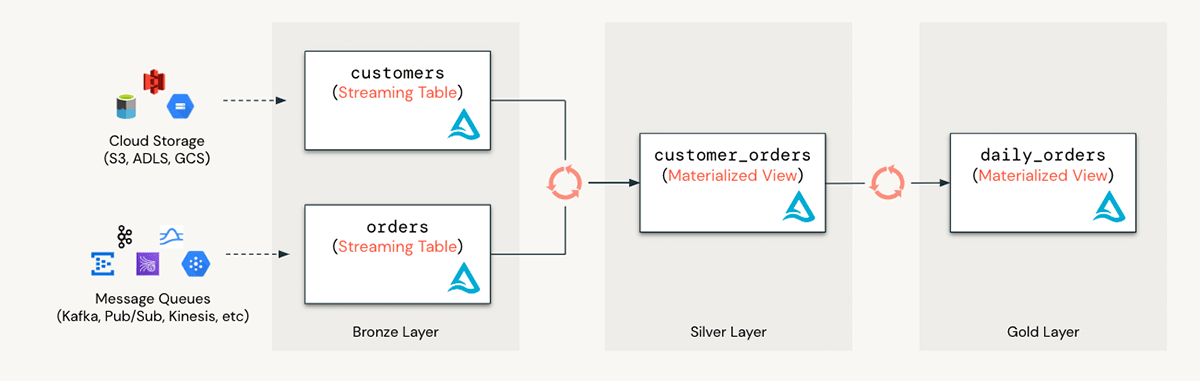
Databricks SQLは、SQLおよびデータアナリストがサードパーティのツールに依存することなく、ビジネスのニーズに合わせてデータを簡単に取り込み、クリーニングし、リッチ化できるようにします。すべてをSQLで行うことができ、ワークフローを合理化します。
マテリアライズド・ビューとストリーミング・テーブルを活用することで、以下のことが可能になります:
- アナリストを強化します: SQLおよびデータアナリストは、データの取り込み、クリーニング、リッチ化を容易に行えるため、ビジネスのニーズに迅速に対応できます。すべてSQLで実行できるため、サードパーティのツールは必要ありません。
- BIダッシュボードのスピードアップ: MVを作成し、事前に結果を計算することで、SQLアナリティクスとBIレポートを高速化します。
- リアルタイム分析への移行: MVとストリーミング・テーブルを組み合わせて、リアルタイムのユースケースに対応するインクリメンタルなデータ・パイプラインを作成できます。ストリーミングデータパイプラインをセットアップして、Databricks SQLウェアハウスで直接取り込みと変換を行うことができます。

アドビは、人間の創意工夫を増幅する副操縦士としての人工知能によって、世界をより創造的、生産的、そしてパーソナライズされたものにするというミッションのもと、AIに対する先進的なアプローチをとっています。Databricks SQL上のマテリアライズド・ビューの主要なプレビュー顧客として、アドビはこのミッションの実現に役立つ膨大な技術的およびビジネス上の利点を目の当たりにしてきました:
「マテリアライズド��・ビューへの変換により、クエリのパフォーマンスが劇的に改善され、実行時間が 8 分からわずか 3 秒に短縮されました。これにより、私たちのチームはより効率的に作業し、データから得られた洞察に基づいてより迅速な意思決定を行うことができるようになりました。加えて、コスト削減も本当に役立っています。" - アドビ、セキュリティソフトウェアエンジニアリングシニアマネージャー、カーティク・ヴェンカテサン氏

1948 年に設立された Danske Spil はデンマークの国営宝くじで、DB SQL のマテリアライズド・ビューの初期のプレビュー顧客の 1 つでした。データエンジニアリングチームリーダーの Søren Klein 氏が、Danske Spil にとって Materialized Views が非常に価値あるものである理由について語ります:
「Danske Spil 社では、マテリアライズド・ビューを使用して、ウェブサイト追跡データのパフォーマンスを高速化しています。この機能により、不要なテーブルの作成と複雑さを回避し、永続化されたビューの速度を得ることで、エンドユーザーのレポーティングソリューションを高速化しています。" - Danske Spil 社、データエンジニアリングチームリーダー、Søren Klein 氏
dbtによる簡単なストリーミングの取り込みと��変換
Databricksとdbt Labsは、lakehouseアーキテクチャ上でのリアルタイムアナリティクスエンジニアリングを簡素化するために協業します。高い人気を誇るdbtのアナリティクスエンジニアリングフレームワークとDatabricks Lakehouse Platformの組み合わせは、強力な機能を提供します:
- dbt + ストリーミングテーブル: dbt + ストリーミングテーブル:あらゆるソースからのストリーミング取り込みがdbtプロジェクトに組み込まれました。SQLを使用して、アナリティクスエンジニアはdbtパイプライン内で直接クラウド/ストリーミングデータを定義し、取り込むことができます。
- dbt + Materialized Views: Databricks の強力なインクリメンタルリフレッシュ機能を活用することで、効率的なパイプラインの構築がより簡単になりました。ユーザーは dbt を使用して MV に裏付けされたパイプラインを構築・実行し、効率的なインクリメンタル計算によってインフラコストを削減できます。
要点
データウェアハウスとデータエンジニアリングは、データ駆動型企業にとって重要な要素です。しかし、データウェアハウスとデータエンジニアリングをそれぞれ別個に管理することは、コストがかかり、ミスが発生しやすく、保守が困難です。Databricks Lakehouse Platform は、最高のデータエンジニアリング機能を Databricks SQL にネイティブに統合し、SQL ユーザに統合ソリューションを提供します。さらに、dbtのようなパートナーとの統合により、共同利用者はこれらのユニークな機能を活用して、より迅速な洞察、リアルタイムの分析、合理化されたデータエンジニアリングワークフローを実現す�ることができます。
Get access to Databricks SQL materialized views and streaming tables by following this link. You can also get started today with Databricks and Databricks SQL, or review the documentation for materialized views and streaming tables.
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。