AIエージェントのメモリスケーリング
によって データブリックス AI 研究チーム による投稿
推論スケーリングにより、LLMは適切なコンテキストが与えられれば、ほとんどの実用的な状況を推論できるレベルにまで到達しました。多くの実世界のエージェントにとって、ボトルネックはもはや推論能力ではなく、エージェントを正しい情報にグラウンディングすること、つまり、目の前のタスクに必要なものをモデルに与えることです。
これは、エージェント設計における新たな軸を示唆しています。より強力なモデルやより良いプロンプトだけに焦点を当てるのではなく、「より多くの情報を蓄積するにつれて、エージェントはより賢くなるのか?」と問うことができます。我々はこれをメモリスケーリングと呼びます。これは、エージェントのパフォーマンスが、メモリに保存さ�れた過去の会話、ユーザーからのフィードバック、インタラクションの軌跡(成功と失敗の両方)、ビジネスコンテキストの量とともに向上する特性のことです。その効果は、暗黙知が豊富で、1つのエージェントが多くのユーザーに対応するエンタープライズ環境では特に顕著です。
しかし、これは先験的に明らかなわけではありません。メモリを増やせば自動的にエージェントの性能が向上するわけではありません。質の低いトレースは間違った教訓を教える可能性があり、ストアが大きくなるにつれて検索はより困難になります。中心的な問題は、エージェントがメモリを単に蓄積するのではなく、より大きなメモリを生産的に活用できるかどうかです。
我々はDatabricksにおいて、人間のフィードバックに基づいてエージェントの行動を調整するALHFやMemAlign、そして検索エージェントが複雑な自然言語の指示やナレッジソースのスキーマを正確で構造化された検索クエリに変換できるようにするInstructed Retrieverを通じて、この方向性への初期のステップを踏み出しました。これらのシステムは総合的に、エージェントが永続的なメモリを通じてより役立つ存在になれることを実証しています。この記事では、メモリ スケーリングの動作を実証する実験結果を紹介し、本番運用でそ��れをサポートするために必要なインフラストラクチャについて説明し、メモリベースのエージェントの将来のビジョンを提示します。
メモリスケーリングとは?
メモリスケーリングとは、外部メモリが大きくなるにつれてエージェントのパフォーマンスが向上するという特性です。ここで「メモリ」とは、モデルの重みや現在のコンテキストウィンドウとは異なる、推論時にエージェントがやり取りできる永続的な情報ストアを指します。
これによりメモリスケーリングは、モデルサイズや推論能力だけでは埋めることのできないドメイン知識とグラウンディングのギャップを埋め、パラメトリックスケーリングと推論時スケーリングの両方にとって、独自の補完的な軸となります。メモリスケーリングによる改善は、回答の質に限定されません。エージェントが、ある環境に関連するスキーマ、ドメインルール、または過去の成功したアクションを記憶している場合、冗長な探索をスキップし、クエリーをより迅速に解決できます。我々のエクスペリメントでは、精度と効率の両方においてスケーリングが観測されました。
継続的学習との関係
継続的学習は通常、時間の経過とともにモデルのパラメータを更新することに焦点を当てています。これは限定された設定ではうまく機能しますが、多数の並列ユーザー、エージェント、および急速に変化するプロジェクトが存在すると、計算コストが高く、脆弱になります。メモリスケーリングは、異なる問いを投げかけます。数千人のユーザーを持つエージェントは、単一のユーザーのエージェントよりも優れたパフ��ォーマンスを発揮するのでしょうか?LLM の重みを固定したままエージェントの共有外部状態を拡張することで、答えはイエスになり得ます。あるユーザーから学習したワークフロー パターンを、再トレーニングなしで即座に取得し、別のユーザーに適用できるからです。これは、単一ユーザーのモデルパラメータ更新に焦点を当てている継続的学習では、提供されるように設計されていなかった特性です。
ロングコンテキストとの関係
大規模なコンテキスト ウィンドウはメモリの代用品のように思えるかもしれませんが、対処する問題が異なります。何百万もの生のトークンをプロンプトに詰め込むと、無関係なトークンがアテンションを競合するため、レイテンシが増加し、コンピュートコストが上昇し、推論品質が低下します。メモリ スケーリングは、その代わりに選択的検索に依存します。含めるコンテキストの量を決めるだけでなく、何を含めるかを決定し、現在のタスクに関連するシグナルの強い情報のみを抽出します。
メモリの種類
すべての記憶が同じ目的を果たすわけではありません。実際には、2つの区別が重要です。
エピソード記憶と意味記憶。エピソード記憶は、会話Logs、ツール呼び出しの軌跡、ユーザーからのフィードバックなど、過去のやり取りの生の記録です。意味記憶は、そうしたやり取りから抽出された一般化されたスキルや事実です(例: "このスペースのユーザーが「四半期」と言うときは、常に会計四半期を意味する")。それぞれのタイプには、異なるストレージ、処理、検索戦略が必要です。エピソード記憶は直接検索のため�に、意味記憶はLLMによって抽出され、より広範なパターンマッチングのために使用されます。
個人的な記憶と組織的な記憶。一部の記憶は単一ユーザーの好みやワークフローに固有のものですが、命名規則、一般的なクエリー、ビジネスルールなど、組織で共有される知識を表すものもあります。記憶システムは、検索と更新の範囲を適切に設定する必要があります。つまり、個人のコンテキストを非公開に保ち、権限とACLを尊重しながら、組織の知識を広く提供する必要があります。
エクスペリメント: Genie SpaceにおけるMemAlign
MemAlignは、AIエージェント向けのシンプルな記憶フレームワークがどのようなものになり得るかを探る私たちの試みです。これは、過去のやり取りをエピソード記憶として保存し、LLMを使用してそれらを一般化されたルールとパターン(意味記憶)に抽出し、推論時に最も関連性の高いエントリを取得してエージェントをガイドします。このフレームワークの詳細については、以前のブログ記事をご覧ください。
私たちはDatabricks Genie SpacesでMemAlignをテストしました。これは、ビジネスユーザーが平易な英語でデータに関する質問を行い、SQLベースの回答を受け取る自然言語インターフェースです。タスクのクエリーと回答の例を以下に示します。
私たちの目標は、キュレーションされた例(ラベル付き)と生のユーザー会話Logs(ラベルなし)という2つのデータソースを使用して、エージェントにより多くの記憶を与えるにつれて、そのパフォーマンスがどのようにスケールするかを測定することです。
ラベル付きデータによるスケーリング
私たちは、10個のGenie spaceにわたる未見の質問に対してMemAlignを評価し、エージェントの記憶に注釈付きトレーニング例のシャードを段階的に追加しました。私たちのベースラインは、専門家が厳選した Genie の指示(手動で記述されたテーブルスキーマ、ドメインルール、フューショットの例)を使用するエージェントです。
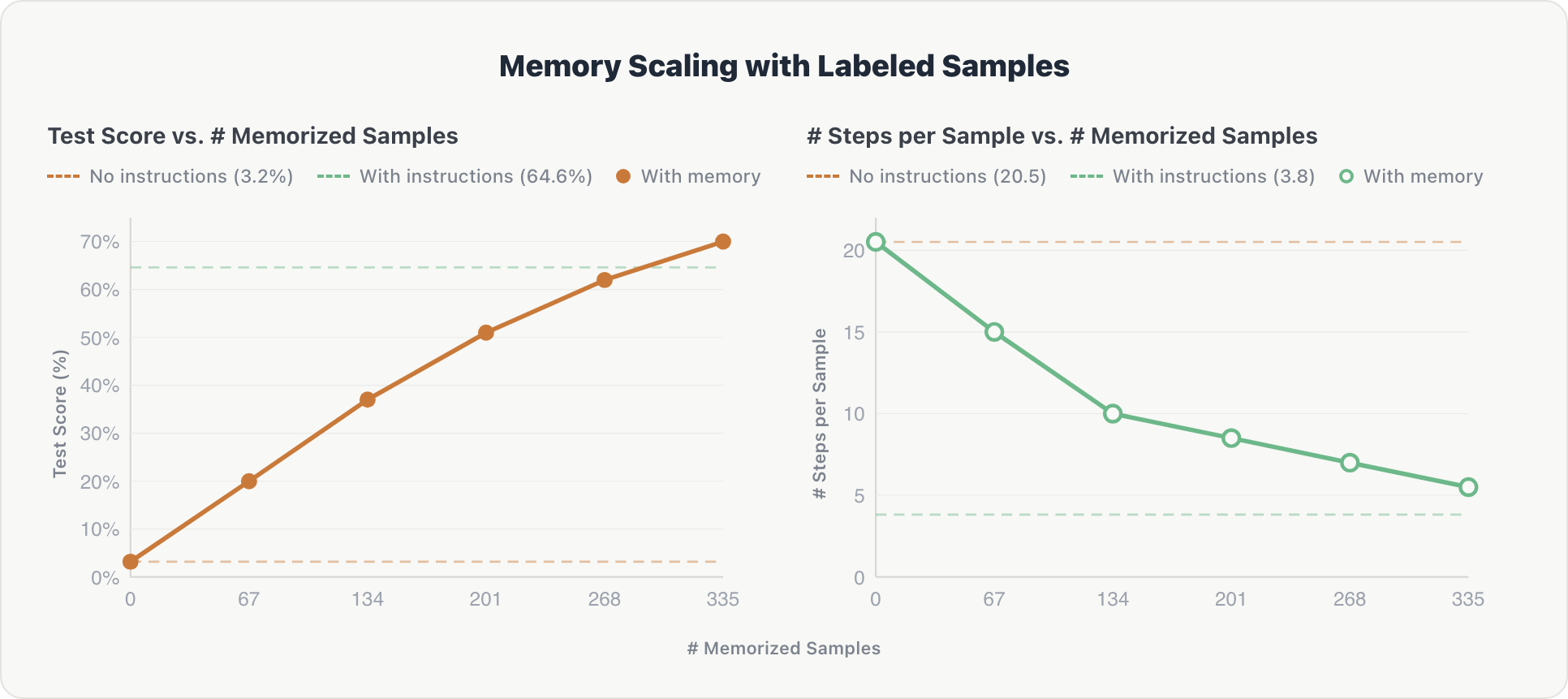
結果は、両方の次元で一貫したスケーリングを示しています。
正確性メモリ シャードが追加されるたびにテストスコアは着実に増加し、ほぼゼロから 70% に上昇し、最終的に専門家が厳選したベースラインを約 5% 上回りました。調査したところ、人間がラベル付けしたデータは、手動で記述されたテーブルスキーマやドメインルールよりも包括的であり、そのためより有用であることがわかりました。
効率性。メモリが増加するにつれて、例あたりの平均推論ステップ数は約20から約5に減�少しました。エージェントは、データベースをゼロから探索する代わりに、関連コンテキストを直接取得するようになり、ハードコードされた命令の効率(約3.8ステップ)に近づきました。
その効果は累積的です。記憶されたサンプルは10の異なるGenieスペースにまたがっているため、各シャードは以前の知識を基に構築するクロスドメイン情報を提供します。
ラベルなしのユーザーLogsによるスケーリング
メモリは、ノイズの多い実世界のデータに合わせてスケールできるのでしょうか?これを調べるために、ライブの Genie スペースで MemAlign を実行し、ゴールドのユーザーの会話ログを入力しました。LLM 判定器がこれらのLogsを有用性でフィルタリングし、品質の高いものだけが記憶されました。
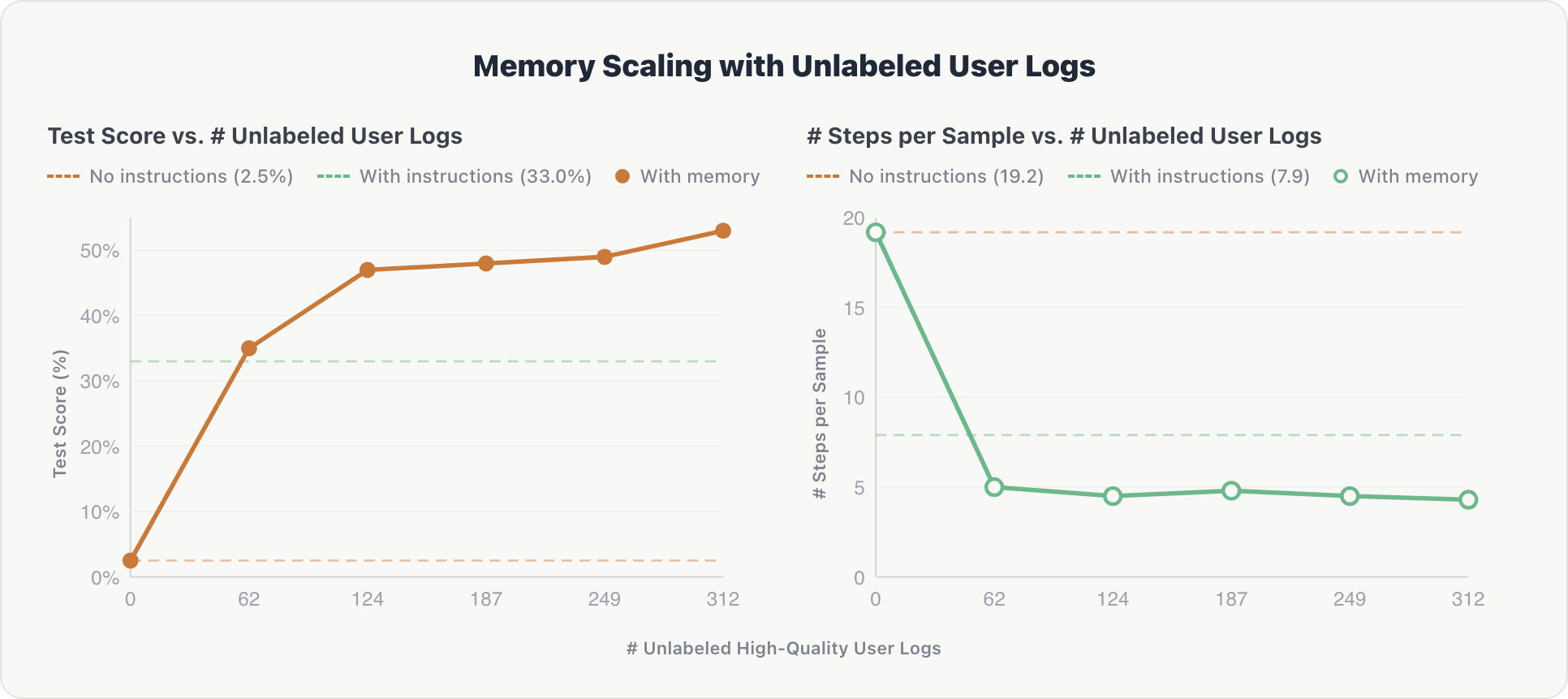
スケーリング曲線は同様のパターンをたどり、最初はより急勾配になります。
正確性エージェントは、初期に急激な向上を示しました。最初のログシャードの後、関連テーブルと暗黙的なユーザーの好みに関する主要な情報が抽出されました。わずか62件のログレコードで、パフォーマンスは2.5%から50%以上に上昇し、専門家がキュレーションしたベースライン(33.0%)を上回りました。
効率性。推論ステップは、最初のシャードの後、約 19 から約 4.3 に減少し、その後は安定していました。エージェントは早い段階でスペースのスキーマを内部化し、その後のクエリーでの冗長な探索を回避しました。
重要なポイント: 自動化され、参照を使用しないジャッジによってのみフィルタリングされた、キュレーションされていないユーザーインタラクションは、コストと時間がかかる手作業で設計されたドメインの指示の代わりになり得ます。これは、通常の使用から継続的に改善し、人間によるアノテーションの限界を超えてスケーリングできるエージェントの方向性も示しています。
エクスペリメント: 組織ナレッジストア
上記のエクスペリメントは、ユーザーインタラクションによってメモリスケーリングがどのように起こるかを示しています。しかし、企業には、ユーザーの操作が行われる前から存在する既存のナレッジ(テーブル スキーマ、ダッシュボードのクエリー、ビジネス用語集、社内ドキュメントなど)もあります。この組織ナレッジを事前計算して構造化されたメモリ ストアに格納することで、エージェントのパフォーマンスが向上するかどうかをテストしました。
私たちはこのナレッジストアを、社内のデータリサーチベンチマークと、製品マネージャーの会議メモや企画資料などのさまざまな社内ドキュメントにわたる徹底的なファクト検索をテストするPMBenchで評価しました。
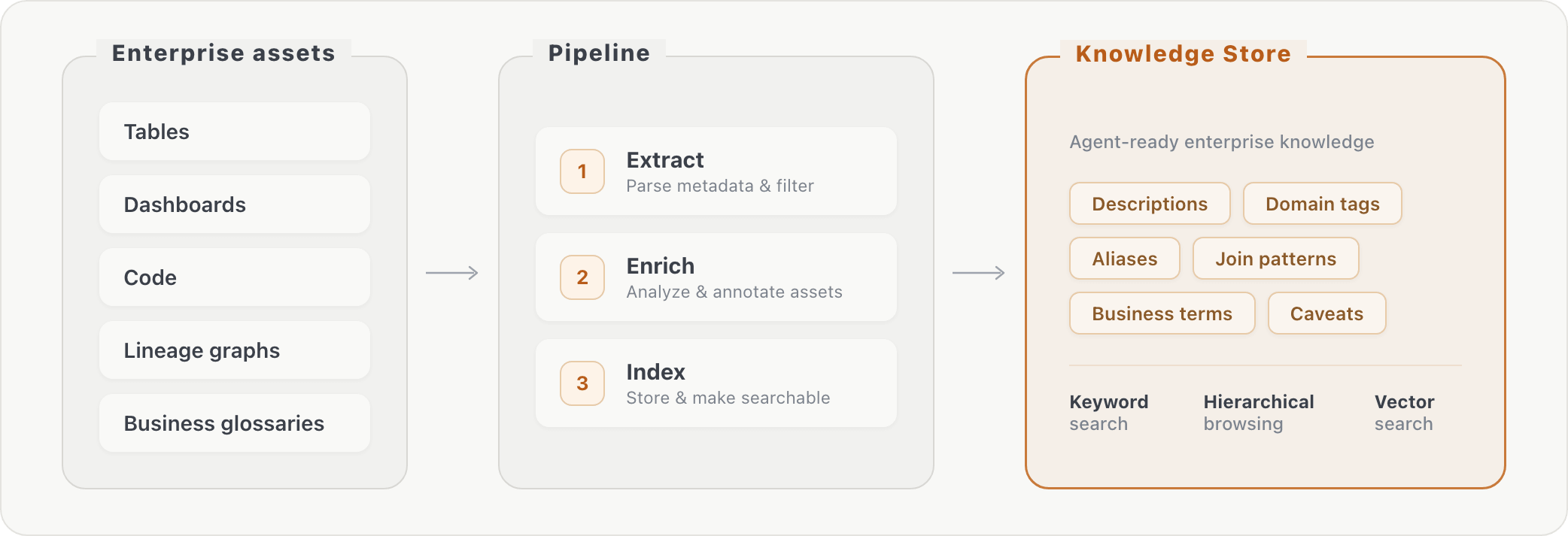
当社のパイプラインは、未加工のデータベースメタデータを3つの段階で検索可能なナレッジに処理します。(1) アセ�ットに関する情報の抽出、(2) 追加の変換によるアセットのエンリッチメント、(3) エンリッチされたコンテンツのインデックス作成です。クエリー時に、エージェントはキーワード検索または階層的ブラウジングを介して、エンタープライズコンテキストを検索できます。これは、ビジネスユーザーが質問を表現する方法(「AI consumption」)と、データが実際に保存される方法(特定のテーブルの特定の列名)との間のギャップを埋めます。
ナレッジストアを追加したことで、評価された両方のベンチマークにおいて精度が約10%向上しました。この効果は、語彙のブリッジング、テーブルの結合、列レベルのナレッジを必要とする質問に集中していました。つまり、エージェントがスキーマの探索だけでは発見できなかった情報です。
メモリをスケーリングするためのインフラストラクチャ
エンタープライズ展開におけるメモリのスケーリングには、単純なベクトルストアを超える堅牢なインフラストラクチャが必要です。以下では、このインフラストラクチャが対処する必要のある3つの主要な課題、すなわちスケーラブルなストレージ、メモリ管理、ガバナンスについて説明します。
スケーラブルなストレージ
最もシンプルなメモリストレージはファイルシステムです。つまり、階層�的なフォルダ内の Markdown ファイルを、標準のシェルツールで閲覧・検索するものです。ファイルベースのメモリは小規模で個々のユーザーにはうまく機能しますが、インデックス作成、構造化クエリー、効率的な類似性検索の機能が欠けています。メモリが多くのユーザーにわたって数千のエントリにまで増大すると、検索性能が低下し、ガバナンスの実施が困難になります。
専用のデータストアは、当然の次のステップです。スタンドアロンのベクトル データベースはセマンティック検索をうまく処理しますが、結合やフィルタリングなどのリレーショナル機能に欠けています。最新のPostgreSQLベースのシステムは、より統合された代替手段を提供します。これらのシステムは、単一のエンジンで構造化クエリー、全文検索、ベクトル類似性検索をネイティブにサポートします。
ストレージとコンピューティングを分離し、低コストで耐久性のあるストレージを提供する、このアーキテクチャのServerless variantsは自然に適合します。Neon のServerless PostgreSQLエンジン上に構築された Lakebase を、スケールトゥゼロのコストと、ベクトル検索と完全一致検索の両方をサポートしているという理由から使用しています。組み込みのデータベース分岐機能も開発サイクルを簡素化します。エンジニアは本番運用に影響を与えることなく、テスト用にエージェントのメモリ状態をフォークできます。
メモリ管理
スケーラブルなストレージだけでは不十分です。メモリシステムは、そのコンテンツも管理する必要があります。
- ブートストラップ。新しいエージェントはコールド起動問題に悩まされることが知られています。ドキュメントの解析と抽出を通じて既存の企業アセット(Wiki、ドキュメント、内部ガイド)を取り込むことは、初期メモリベースを提供し、これらの問題のいくつかを軽減できます。これは私たちの組織ナレッジストアの**エクスペリメント**で示されたとおりです。
- 蒸留。生のエピソード記憶は直接的な検索には役立ちますが、大規模になると保存と検索のコストが高くなります。これらを定期的にセマンティック メモリ(圧縮されたルールとパターン)に蒸留することで、メモリストアを扱いやすく保ち、エピソード記憶だけでは明らかにならない可能性のある、一般化可能な知見をエージェントに提供します。
- 統合。メモリが増大するにつれて、システムの一貫性を保ち、コンパクトかつ最新の状態に維持することが重要です。これには、重複を削除し、古い情報を整理し、新旧のエントリ間の競合を解決するパイプラインが必要です。
セキュリティ
メモリは、ステートレスエージェントには存在しないガバナンス要件をもたらします。エージェントがユーザーの好み、独自のワークフロー、内部データパターンなどの深く文脈的な知識を蓄積するにつれて、企業データに適用されるのと同じガバナンス原則をエージェントのメモリにも拡張する必要があります。
アクセス制御は ID を認識するものでなければなりません。個人の記憶は非公開とし、組織の知識はアクセス制御された範囲内で共有できるようにします。これは、Unity Catalog のようなプラットフォームが、行レベルのセキュリティ、列マスキング、属性ベースのアクセス制御など、データ資産に対してすでに適用している、きめ細かい権限に自然に対応します。
これらの制御をメモリのエントリに拡張することは、あるユーザーのコンテキストを取得するエージェントが、誤って別のユーザーのプライベートなやり取りを表面化させることがないようにすることを意味します。
アクセス制御に加えて、データリネージと監査可能性が重要です。エージェントの行動がそのメモリによって形成される場合、チームは、どのメモリが特定の応答に影響を与えたか、そしてそれらのメモリがいつ作成または更新されたかを追跡する必要があります。コンプライアンスおよび規制要件は、特に規制の厳しい業界において、メモリストアが基になるデータと同じ可観測性の保証(完全なリネージ追跡、保持ポリシー、要求に応じて特定のエントリを消去する機能)をサポートすることを要求します。
適切なメモリが適切なユーザー、そしてそのユーザーだけに届くようにすることは、大規模な運用における中心的な設計上の問題です。
障害となるもの
すべてのスケーリング軸は、最終的にそれ自体のボトルネックに突き当たります。パラメトリックスケーリングは、高品質なトレーニングデータの�供給によって制約されます。推論時のスケーリングは「考えすぎ」に陥る可能性があり、より長い推論の連鎖がシグナルを追加することなくコストを増加させ、最終的にシーケンス長が増加するにつれてパフォーマンスを低下させます。メモリのスケーリングには、品質、スコープ、アクセスという同様の限界があります。
メモリの品質を維持するのは困難です。最初から間違っている記憶もあれば、時間とともに間違っていく記憶もあります。ステートレス エージェントは個別の間違いをしますが、メモリを搭載したエージェントは、間違いを保存し、後で証拠として取得することで、1つの間違いを繰り返し発生するものに変えてしまう可能性があります。私たちは、エージェントがそれ自体が間違っていた以前のランのノートブックを引用し、さらに自信を持ってそれらの結果を再利用するのを見てきました。陳腐化はもっと微妙な問題です。前四半期のスキーマを学習したエージェントが、その後名前が変更されたり削除されたりしたテーブルにクエリを実行し続ける可能性があります。取り込み時のフィルタリングは役立ちますが、本番運用のシステムにはフィルタリング以上のものが必要です。それらにはプロビナンス、信頼性の推定値、鮮度のシグナル、そして定期的な再検証が必要です。
ガバナンスは蒸留にも及ぶ必要があります。組織全体でメモリをスケールさせるには、繰り返されるインタラクションを蒸留し、再利用可能なセマンティック メモリにする必要があります。しかし、抽象化によって機密性がなくなるわけではありません。「Y 社については、CRM、市場インテリジェンス、およびパートナーシップのテーブルを結合する」のようなメモリは、無害に見えるかもしれませんが、機密の買収関心を明らかにしてしまう可能性があります。課題は、プライベートなパターンを共有知識に変えることなく、メモリを幅広く役立つものにすることです。アクセス制御と機密性ラベルは、取り込みだけでなく、蒸留の後も維持される必要があります。
有用なメモリにアクセスできないままである可能性があります。たとえ記憶が正確で最新であっても、エージェントはその存在を発見しなければなりません。取得は本質的にメタ認知的です。エージェントは、メモリ ストアに何があるかを知る前に、何を尋ねるかを決定しなければなりません。関連するメモリが役立つ可能性を予測できない場合、エージェントは適切なクエリーを発行せず、低速で冗長な探索に頼ってしまいます。実際には、保存された知識とアクセス可能な知識との間のギャップが、メモリのスケーリングにおける主な制限要因となる可能性があります。
これらは、メモリ スケーリングに反対する議論ではありません。それらは、メモリのスケーリングを堅牢にするために、まだ解決する必要がある研究課題です。中心的な課題は、単に履歴を多く保存することだけではありません。適切な記憶を見つけ、それを適切に使用し、最新かつ適切な範囲に保つ方法をエージェントに教えることです。
今後の展望: メモリとしてのエージェント
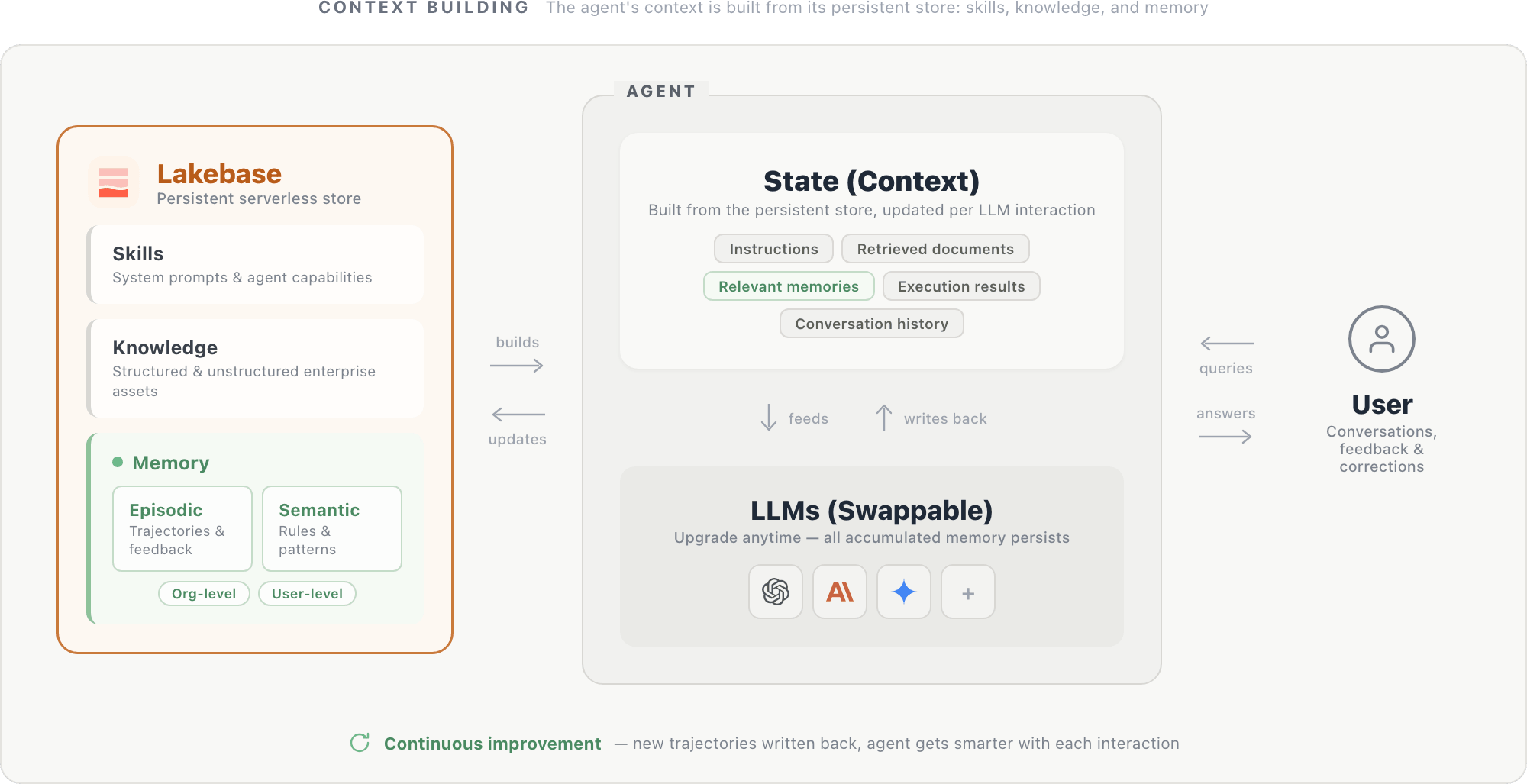
上記のエクスペリメントとインフラストラクチャは、モデルの重みではなくメモリにそのアイデンティティが存在するエージェントとい��う、自然な設計パターンを示唆しています。
この設計では、エージェントのコンテキストは Lakebase のようなServerless データベースに格納された永続ストアから構築されます。ストアには、システムプロンプトとエージェントの能力(スキル)、構造化および非構造化のエンタープライズ資産(ナレッジ)、そして組織およびユーザーレベルでスコープ指定されたエピソード記憶と意味記憶という3つのコンポーネントが保持されます。これらのコンポーネントが一体となってエージェントの状態(指示、取得したドキュメント、関連するメモリ、実行結果(SQL クエリ、API 呼び出し、その他のツールから)、会話履歴)を形成します。この状態は各ステップで LLM に入力され、各インタラクションの後に更新されます。
LLM 自体は交換可能な推論エンジンです。新しいモデルは同じ永続ストアから読み込み、蓄積されたすべてのコンテキストからすぐに恩恵を受けるため、新しいモデルへのアップグレードは簡単です。
基盤モデルの能力が収束するにつれて、エンタープライズエージェントの差別化要因は、どのモデルを呼び出すかということよりも、どのような記憶を蓄積したかという点がますます重要になるでしょう。仮説として、豊富なメモリ ストアを持つ小規模なモデルは、メモリが少ない大規模なモデルを上回る性能を発揮できる可能性があります。もしそうであれば、メモリ インフラストラクチャに投資することは、モデル パラメータをスケーリングするよりも大きなリターンをもたらす可能性があります。あなたの組織に固��有のドメイン知識、ユーザーの好み、運用パターンは、どの基盤モデルにも含まれていません。それらは使用を通じてのみ構築でき、モデルの能力とは異なり、各デプロイメントに固有のものです。
まとめ
私たちは、エージェントがユーザーとの対話やビジネスコンテキストを通じてより多くの経験をメモリに蓄積するにつれてパフォーマンスが向上する「メモリスケーリング」を提案します。私たちの初期のエクスペリメントでは、外部メモリに保存される情報量に応じて、精度と効率性の両方が向上することが示されています。
これを本番運用で実現するには、構造化検索と非構造化検索を統合したストレージシステム、メモリの一貫性を保つ管理パイプライン、アクセスを適切に制御するガバナンス統制が必要です。これらは現在のテクノロジーで解決可能な問題です。その成果は、継続的な使用によって真に改善されるエージェントです。
残りの作業は膨大です。メモリは、大きくなっても、正確で、最新で、アクセス可能でなければなりません。しかし、まさにそれがメモリのスケーリングが興味深い理由です。それは、各組織や問題に特化した方法で継続的に使用することで改善されるエージェントを構築するための、具体的なシステムと研究のアジェンダを提示します。
著者: Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
プロジェクト全体を通して貴重なフィードバックをいただいた Kenneth Choi、Sam Havens、Andy Zhang、Ziyi Yang、Ashutosh Baheti、Sean Kulinski、Alexander Trott、Will Tipton、Gavin Peng、Rishabh Singh、Patrick Wendell の皆様に感謝いたします。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。