ポーラー vs パンダ
Polarsの高性能並列処理と、DataFrameベースのデータ操作のためのPandasの多用途APIを比較します。
によって Databricks Staff による投稿
- DataFrame操作とデータ分析ワークフローにおけるPolarsとPandasの違いを理解する
- PolarsがRustベースの並列処理と遅延評価を��使用して、大規模データセットで優れたパフォーマンスを実現する方法を学ぶ
- Pandasの広範なエコシステムと柔軟性と、Polarsの速度とメモリ効率のどちらを選ぶべきかを知る
はじめに: DataFrame ライブラリの選択肢を理解する
データフレームは、スプレッドシートに似た2次元のデータ構造(通常はテーブル)です。観測値の行と変数の列で構成される表形式データを保存・操作したり、特定のデータセットから有用な情報を抽出したりできます。データフレームライブラリは、コードでデータを扱うためのスプレッドシートのような構造を提供するソフトウェアツールキットです。DataFrameライブラリはデータ分析プラットフォームに不可欠な要素です。データの読み込み、操作、アナリティクス、推論を容易にする中核的な抽象化を提供し、生データストレージと、より高度なアナリティクス、machine learning、可視化ツールとを橋渡しする役割を担います。
Polarsとpandasは、データ分析と操作のための主要なPythonのDataFrameライブラリですが、それぞれ異なるユースケースと作業規模に合わせて最適化されています。
pandas とは、プログラミング言語 Python でデータ分析を行うためのオープンソースのライブラリでで、高速で適応性の高いデータ構造を提供します。これは Python で最も広く使用されている DataFrame ライブラリです。成熟していて機能が豊富で、多くのインテグレーションを持つ広範なエコシステムがあります。Pandasには、豊富なドキュメント、コミュニティによるサポート、成熟したプロットライブラリがあります。中小規模のデータセットや探索的分析でよく使われます。
Polarsは、Rustベースの高速なカラムナDataFrameライブラリで、Python APIを備えています。速度を重視して設計されており、組み込みの並列処理と「遅延実行」(すぐには実行されない)により、メモリを超える規模のワークロードに対応します。
ご使用のデータ処理要件にもよりますが、Pandas は最大数百万行のデータセットでのデータサイエンスに対して問題なく機能します。ETLやアナリティクスを行ったり、大規模なテーブルで作業したりする場合、一般的にPolarisのほうが効率的です。
ワークフローで pandas を使用するケース
Pandasは、極端な規模よりも、柔軟性、イテレーションの速さ、エコシステムの互換性が重要な場合に威力を発揮します。これは事実上の標準DataFrameライブラリです。柔軟性を優先し、Scikit-learnとの緊密な統合を提供します。NumPy、Matplotlib、statsmodels、その他多くのmachine learningツール。
レガシー コードベースでも動作し、柔軟性が最重要視される対話型分析や探索的データ作業に利用しているデータ処理チームにはおなじみです。その行ベースの形式は、中小規模のデータセットでのアドホック分析、ノートブックベースのワークフロー、ラピッドプロトタイピングに優れ�ています。
pandasでは任意のPython関数を実行できますが、Polarsでは任意のPythonの実行は強く非推奨とされています。pandasでは、インプレースな変更やステップバイステップの編集が一般的で、ユーザーは時間とともに状態を変化させることができます。Polarsでは、DataFrameは実質的にイミュータブルです。
Apache Spark 3.2 の pandas API を実行することができます。これにより、 pandas のワークロードを均等に分散させ、すべての作業を確実に行うことができます。
探索的データ分析において、pandas は高速でインタラクティブな操作、簡単なスライス/フィルタリング/グループ化、素早い視覚的検査を提供します。これは、データの検証/監査や、欠損値、不整合なフォーマット、重複、混合したデータ型を含む生データのクリーニングによく使用されます。
データチームが設定されたタイムスケールでメトリクスを生成する必要があるビジネスアナリティクスやレポート作成において、pandas は簡単な再形成によって groupby と集計を単純化し、CSV/Excel に直接出力します。
データサイエンス チームが機械学習 モデル用のデータを準備する場合、pandas を使用すると、自然な列ベースの特徴量作成と scikit-learn との緊密な連携により、実験が容易になります。SQL、Spark、または本番運用パイプラインでロジックを記述する前の、迅速なプロトタイピングや PoC (概念実証) によく使用されます。
金融や非技術系のビジネスチームでさえ、pandas を使用して Excel ベースのワークフローを自動化しています。
詳しく見る
ワークフローで Polars を使用するタイミング
Polarsは、アドホックな柔軟性よりも、パフォーマンス、スケーラビリティ、信頼性が重要な場合に威力を発揮します。Rustエンジン、マルチスレッド、カラムナーメモリモデル、遅延実行エンジンのおかげで、Polarsはメモリ効率が重要な単一のマシンで、驚くほど大規模な ETLワークロードを処理できます。遅延実行とは、操作がすぐに実行されるのではなく、記録、最適化され、出力が明示的に要求されたときにのみ実行されることを意味します。これにより、各操作を段階的に実行する代わりに、最適化された1つの実行計画が作成されるため、大幅なパフォーマンス向上が期待できます。データ変換は最初に計画され、後で実行されるため、システムはパイプライン全体を最適化して、速度と効率を最大限に高めることができます。
一貫した高いパフォーマンスとスピードが重要なワークフローを必要とする本番運用データパイプラインのために、Polarsはデフォルトでマルチスレッド化され、利用可能なすべてのCPUコアを活用し、DataFrameの各チャンクを異なるスレッドで処理します。これにより、pandasのような従来のシングルスレッドDataFrameライブラリよりも劇的に高速になります。
クリックストリームログとユーザーメタデータを結合するなど、数千万行の結合を実行する場合、Polarsの結合はマルチスレッド化されており、カラムナデータによって不要なメモリコピーが削減されます。
大規模なデータセット、複雑な変換、または複数ステップのパイプラインを含む使用シナリオでは、Polarsは並列処理の恩恵を受けます。各行を個別に処理し、結合操作を複数のコアに分割し、ハッシュパーティショニングを並列で実行できます。多数の変換を伴う複数ステップのクエリーパイプラインの場合、Polarsはパイプライン全体を最適化して並列で実行できます。並列ストリーミングと遅延評価を使用することで、PolarsはRAMより大きいデータセットを処理できます。並列処理と遅延評価は、大規模なファイル(CSV/Parquetファイル)のスキャン操作にも役立ちます。
Polarsは、クエリーの最適化のためにApache Arrow上に構築されたカラムナーストレージを使用することで、パフォーマンス面でも大きな利点を得ています。列型ストレージでは、データは行ごとではなく列ごとに保存されます。これにより、Polarsは必要なカラムのみを読み込み、ディスクI/Oとメモリアクセスを最小限に抑え、分析処理をより効率的に行うことができます。データをコピーすることなく、Apache Arrowの連続メモリバッファを直接操作することができます。
非常に大規模なデータセットで機械学習のフィーチャーエンジニアリングや探索を行う場合、大規模なファクトテーブルを結合する場合、大規模な集計やOLAPアナリティクスを行う場合、時系列ワークロードを行う場合、大規模なファイルスキャンを行う場合、大容量のメモリ処理を行う場合、厳しいSLAでバッチ処理を行��う場合は、Polarsを選択する方がよいでしょう。
- 内部Link Apache Spark(アンカー: 分散データ処理)
- 内部リンク:データパイプライン (アンカー: スケーラブルなデータパイプラインの構築)
データ表現とアーキテクチャ
pandas と Polars のデータ表現モデルとアーキテクチャは意図的に異なっています。pandas で使用される行ベースのストレージは完全な行をメモリ内で連続的に格納しますが、Polars で見られる列ベースのストレージは各列を連続的に格納します。実行するクエリーの種類に応じて、それぞれの方法がパフォーマンスに影響を与える可能性があります。
分析クエリーの場合、クエリーは必要な列にのみアクセスすればよいため、通常は列ベースのストレージの方がパフォーマンスが優れています。一方、行ストアは完全な行を読み取る必要があります。
列は均一な型を持つため、圧縮率が向上し、ベクトル化によって高速なバッチ処理が可能になります。
OLTP ワークロードなどのトランザクション クエリーには、行ベースのストレージが適しています。行全体がまとめて格納されるため、1 回の読み取りで完全なレコードを取得でき、行の更新もメモリ上のコンパクトな 1 領域の変更で済みます。
以下のチャートは、行ベースと列ベースのDataFrameライブラリ(ここではKoalasとDask)を比較した平均パフォーマンス比を示しています。
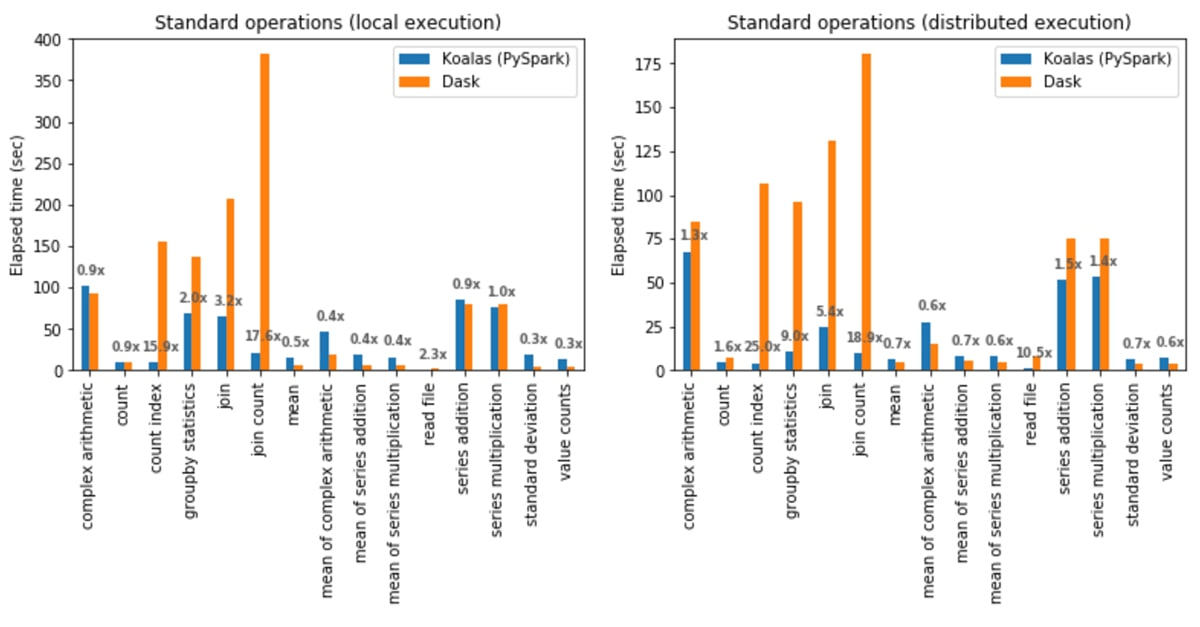
Polars のカラムナーフォーマットにより、より高速な集計が可能になります。各列はメモリ上で連続して保存されるため、無関係なデータをスキャンすることなく単一の列をストリーム処理でき、CPU コア間で集計を並列化します。大規模なデータセットの場合、クエリーで必要な列のみを読み取るため、列指向ストレージは RAM への負荷を軽減します。
Polarsの列指向レイアウトは、Apache Arrowを使用したベクトル化実行を可能にし、ゼロコピーでのデータ共有を実現します。Polarsは、基盤となるデータバッファをコピーすることなく、フィルタリングやスライシングを実行できます。
pandasで使用される行ベースのストレージモデルでは、DataFrameの各行が、グループ化されたPythonオブジェクトのコレクションとして格納されます。このモデルは、完全なレコードを取得または変更する操作に最適化されています。1回のルックアップでレコードのすべてのデータを取得できるため、大規模なベクトルよりも、多数の小規模な混合ワークロード操作に適しています。 Pythonオブジェクト、文字列、数値、リスト、ネストされたデータなどの異種データ型をサポートします。このような柔軟性は、整理されていない実世界のデータ、CSVレコード内のJSON、混合型の特徴量セットに役立ちます。
ユーザーレベルのレコードの取得やAPIのための行レベルのデータのシリアライズなど、1つの行に対して多くの、あるいはすべての列へのアクセスを必要とするクエリー��の場合、pandasは複数の列バッファにアクセスして行を再構築する必要がありません。また、DataFrameセルのインプレースでの変更が可能なため、頻繁な変更を伴うワークロードでも高速です。
データがメモリに余裕をもって収まる場合、pandas は非常に便利で、中小規模のデータセットに対して十分なパフォーマンスを提供します。
パフォーマンス: 速度とリソース使用率の評価
Polars は、特にデータ エンジニアリング関連の作業で、データが大規模になり、複雑さが増すにつれて、pandas よりも高速でリソース効率が高くなる傾向にあります。Polars はカラムナであり、デフォルトでマルチスレッドで、遅延/最適化クエリープランを実行できます。pandas は DataFrame の操作ではほとんどがシングルスレッドで、各行が即座に実行されて中間 DataFrames を実体化する Eager Execution (積極的な評価) を使用します。pandas は、小規模なデータや一部の単純なベクトル化された操作では高速になることがあり、より柔軟です。しかし、その柔軟性によって CPU/メモリが犠牲になる可能性があります。
下のグラフは、スレッド数がパフォーマンスにどのように影響するかを示しています。
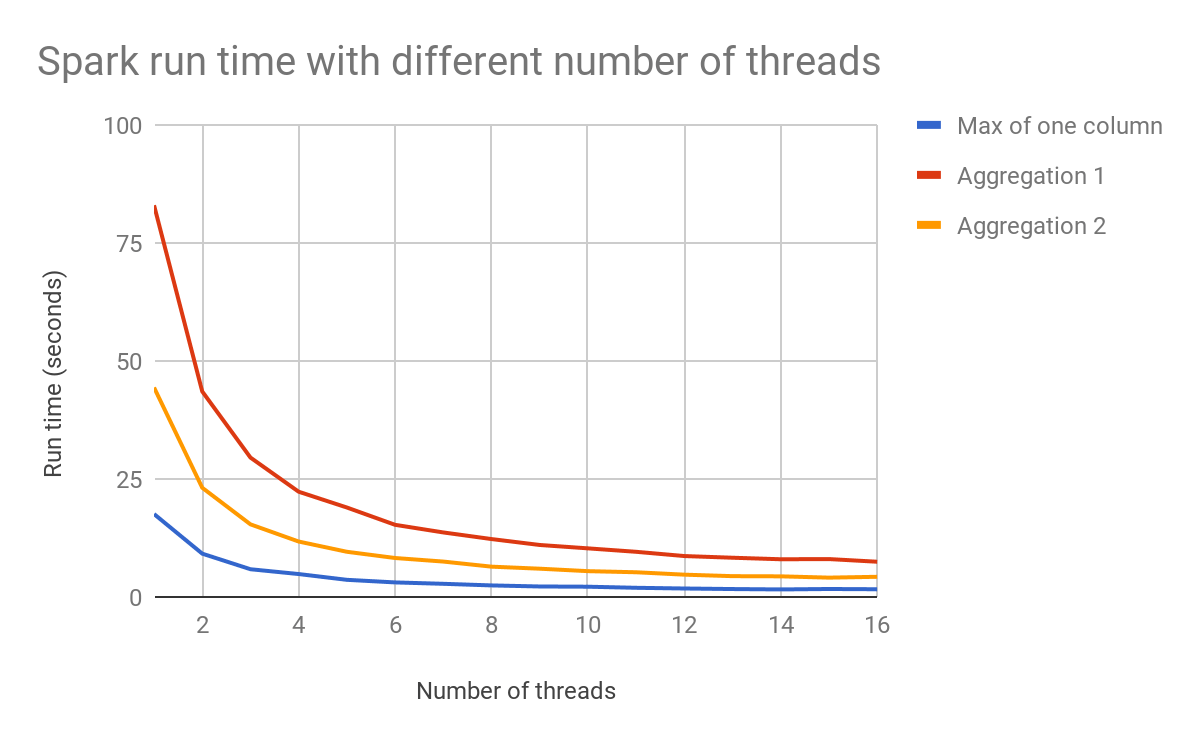
PolarsのLazyFrameクエリープランニングとオプティマイザを使用すると、コードはまずクエリープランを構築し、Polarsはそのプランを最適化して、指示されたときに実行します。それだけで、Polarsの速度とメモリ使用量における優位性のほとんどを説明できます。
pandasでは、正格評価は直ちにコンピュートを行い、メモリ内に中間オブジェクトを作成し、その中間オブジェクトを次のステップに渡すことを意味します。そのため、データを複数回パスすることで速度が低下します(多くの場合、複数のフルサイズの中間オブジェクトが作成されます)。pandasはパイプライン全体を見ることができないため、グローバルな最適化はできません。しかし、データがメモリに快適に収まり、操作が小さくインタラクティブで、各行の後にすぐにフィードバックが欲しい場合には、pandasは強力です。目安として、次のような場合にpandasを選択してください:
- 簡単なEDAを行う場合
- データセットは小規模/中規模です
- ステップごとの調査とデバッグが必要な場合
- ロジックが高度にカスタマイズされた Python (行ごと) である場合
次のような場合はPolarsを選択します:
- 反復可能な ETL/アナリティクス パイプラインを実行している
- データセットが大きい、または幅が広い
- Parquet/Arrow を頻繁に読み込む場合
- スピード、メモリ、中間コピーの削減を重視する場合
設計思想の違い(pandas は柔軟性を、Polars は速度を重視して構築)のため、2つのライブラリは欠損データとヌル値の扱いが異なり、これがパフォーマンスに影響を与えることもあります。
Pandasはいくつかの異なる値を「欠損」として扱うことができるため、柔軟性が保たれる一方で、一貫性がなく、Pythonオブジェクトの処理により操作が遅くなることがあります。Polarsは、すべてのデータ型で「null」を唯一の欠損値として使用し、SQLのセマンティクスに厳密に一致させることで、大規模な処理においてより高速でメモリ効率が高くなります。
下のグラフで示されているように、代表的なワークフローのランタイム比較において、pandasが大規模なデータセット上でPythonレベル(行ごと)の実行を強制されると、多くの中間コピーが作成され、操作が遅くなります。
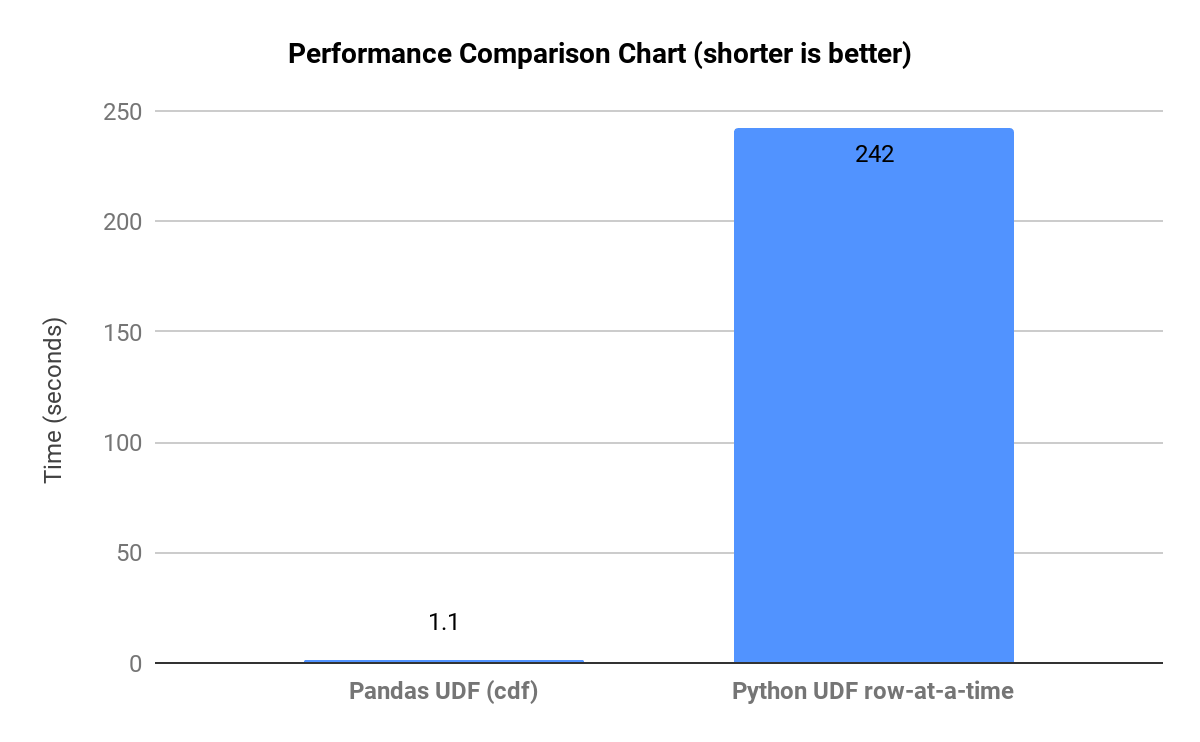
また Polars も、ベクトル化が中断されてクエリーの最適化が妨げられる場合や、大規模なパイプラインで遅延モードが使用されていない場合に、パフォーマンスのボトルネックが発生する可能性があります。Polars の最適化は、非常に大規模な多対多の結合で破綻する可能性もあります。
下のグラフは、pandasのメモリ消費量がデータサイズに伴って線形に増加することを示しています。
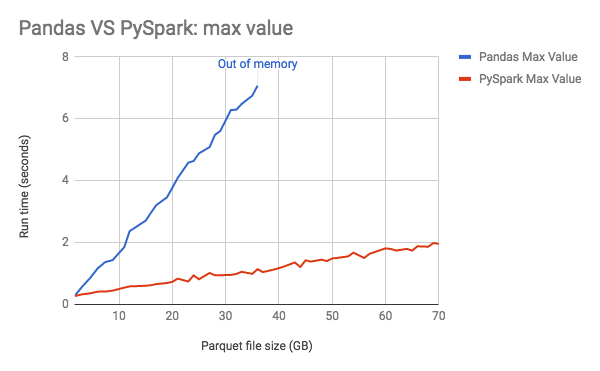
パフォーマンスガイダンス:
- ワークロードが大規模なParquetのgroupby/join/scanである場合、通常はPolarsの方が優れています。
- ワークフローが、多数のカスタムPythonロジックを用いた対話的なEDAである場合、pandasの方が便利なことが多いです。
ベンチマーク
パフォーマンスの違いを理解するために、実装できるベンチマークのアプローチを以下にいくつか示します。
クイックアドホック
- ウォール時間には
time.perf_counter()を使用します。 - 複数回繰り返す
median/p95を報告
再現可能なマイクロベンチマーク(チーム/PR向け)
pytest-benchmarkまたはasvを使用します- 安定したマシン(またはピン留めされたCIランナー)でランする
- コミット間で結果を保存
本番運用に近いベンチマーキング(最も意味のある)
- 実際のデータセットの形状 & サイズ
- コールドキャッシュとウォームキャッシュでのラン
- エンドツーエンドのパイプラインのタイミング
- メモリとCPUの追跡
比較を公平にするため、同じ入力形式を使用し、データ型を一致させ、同じグルーピング、キー、出力を使用し、スレッドを制御します(デフォルトの動作、またはシングルコアでの公平な比較)。
- 特定のユースケースでパフォーマンスの違いが最も重要になる場合
- 大規模データセットにおけるPolarsでの実環境での平均時間改善
欠損データとデータ型の処理
DataFrameライブラリが欠損データとデータ型をどのように扱うかは、正確性、データ品質、パフォーマンス、使いやすさに影響します。Pandasは、欠損データとdtypeの処理において柔軟ですが、時として一貫性がないことがあります。一方、Polarsは厳密な型付けを持つ単一のnullモデルを適用するため、特に大規模な場合に、より安全で、高速で、予測可能な動作につながります。
pandasの欠損データモデルでは、NaN (float)、None、NaT (datetime)、pd.NA (nullable scalar) といった複数の値が欠損値として扱われます。これは柔軟性を高めるのに役立ちますが、データ型によって欠損データの扱いが異なると、一貫性がなくなる可能性があります。欠損値を埋める際、pandasは予期せずデータ型を変更することがあります。曖昧なnullセマンティクスにより、pandasでデータ品質の問題を検出することが難しくなっています。
Polarsは単一の欠損値(null)を使用し、すべてのデータ型で同じように動作します。また、すべてのデータ型はデフォルトでnull許容です。これにより、通常は予測可能な動作とパフォーマンスの向上がもたらされます。欠損値を埋める際、Polarsは明示的であり、データ型を保持します。Polarsの一貫したnull処理により、通常はデータ品質のエラーが減少します。
また、さまざまなメモリモデルがデータ型の変換と相互運用性にどのように影響するかという考慮事項もあります。pandasは歴史的にNumPy(混合データ型を格納できるPythonオブジェクトである行形式)に依存してきましたが、PolarisはArrowネイティブの列形式であるため、他のPythonデータスタックに接続するのがより簡単になります。
両方のDataFrameライブラリを使用しながら、データ完全性を維持するためのベストプラクティスをいくつか紹介します。
- どちらのライブラリーも...
主キーの一意性、外部キーの有効性、期待される行数/パーティションなど、一意性や主要なデータベース制約を強制します。joinを検証して、サイレントな行の爆発的増加を防ぎます。一貫性のある決定論的な変換を使用します。これらはテス��トや再現がはるかに容易です。型を維持するために、「信頼できる情報源」のデータを安定したスキーマでParquetで保存します。そして、検証を最後まで待たないでください。取り込み後、主要な変換後、公開後など、主要なポイントで検証します。
- pandasでは…
可能な限り読み取り時にデータ型を明示的に設定し、pandasがobjectにフォールバックしないように、Int64、Boolean、string、datetime64[ns]などのnull許容データ型を優先してください。欠損値は早い段階で正規化し、NaN == Naan のようなサイレントな問題に注意してください。コアロジックでは、連鎖インデックスと行単位の処理は避けてください。
- Polars の場合…
スキーマとデータ型を明示的に定義し、Polars の厳密な型付けを利用します。null を一貫して使用し、式ベースの null 処理を優先します。
構文とAPIの移行
- コアAPIの違い: Polarsの連鎖 vs. pandasの操作
- Polars では、通常、単一の連鎖した式ベースのパイプラインを構築します。遅延モードでは、Polars はチェーン全体を最適化できます。pandas では、多くの場合、Eager(ステップバイステップ)メソッドでミューテートする一連のステートメントを記述します。
- 並べて表示したコード例: フィルタリング、グループ化、集計
- フィルタリングと選択(チェイニング)
- pandas
- フィルタリングと選択(チェイニング)
result = pdf[pdf["country"] == "US"][["user_id", "revenue"]]
- Polars
result = (
pldf
.filter(pl.col("country") == "US")
.select(["user_id", "revenue"])
)
- グループ化と集計:
- pandas
rev_by_user = (
pdf
.groupby("user_id", as_index=False)["revenue"]
.sum()
)
- Polars
rev_by_user = (
pldf
.group_by("user_id")
.agg(pl.col("revenue").sum())
)
Polars の構文の基礎:
Polarsを学ぶ上で最も重要な概念は、式 (expression) と、遅延実行と即時実行の2つです。Polarsは式 (expression) を中心に構築されています。これは、計算したい内容を記述する (SQLに似た) 列ごとの計算であり、エンジンがその効率的な計算方法を決定します。式はすぐには実行されません。これらは「遅延」実行モードにおける構成要素であり、操作によってクエリープランが構築され、呼び出されたときにのみ実行が行われます。
逆に、Eager モード (pandas の動作) では操作がすぐに実行されるため、探索やデバッグには適していますが、大規模なパイプラインでは速度が低下します。Polarsは、対話性のためのEager実行と、最適化された大規模パイプラインのためのLazy実行を提供します。
既存のPandasコードをPolarsに変換する
変換とは通常、次のことを意味します。
df[...]の行/列インデックス指定を.filter()に置き換えます/.select()- インプレース代入を
.with_columns()に置き換える .apply()を置き換えるネイティブな式で (可能な限り)- ファイルベースのETLには遅��延モードを検討します
変換の例:
元の pandas:
df = pd.read_parquet("events.parquet")
df = df[df["country"] == "US"][["user_id", "revenue", "ts"]]
df["revenue"] = df["revenue"].fillna(0)
df["day"] = pd.to_datetime(df["ts"]).dt.date
)
out = (
df.groupby(["user_id","day"], as_index=False)
.agg(total_revenue=("revenue", "sum"))
Polarsの遅延最適化:
import polars as pl
out = (
pl.scan_parquet("events.parquet")
.filter(pl.col("country")== "US")
.select(["user_id", "revenue", "ts"])
.with_columns([
pl.col("revenue").fill_null(0),
pl.col("ts").dt.date().alias("day")、
])
.group_by(["user_id","day"])
.agg(pl.col("revenue").sum().alias("total_revenue"))
.collect()
)
チームがデータライブラリを切り替える場合 (たとえば、pandas から Polars に切り替えたり、pandas と並行して Polars を追加したりする場合)、学習曲線は構文よりも考え方、ワークフロー、リスク管理が重要になります。pandas の考え方は、命令的、ステップバイステップで、処理を進めながら変更し、各行の後に検査するというものです。Polars の考え方は宣言的で式ベースです。不変データを使用して変換をパイプラインとして構築し、SQL のようなクエリープランニングを使用します。
学習上の課題は、1行ずつではなく、列単位かつ宣言的に考え始めることです。デバッグと検査の習慣を変える必要があります。状態ではなく、変換で考えてください。
Polars では、スキーマの一貫性を強制し、データ型の問題に対して迅速に失敗するため、データ型の厳格さが厳しいと感じられることがありますが、その失敗は、気づきにくいデータ品質のバグを防ぎます。課題は、データ型のエラーを厄介なものとしてではなく、データ品質のシグナルとして扱うことです。
ほぼすべての Python データツールが pandas に対応しており、ドキュメントを含む広大なエコシステムが存在するため、チームは Polars に切り替える際にツールのギャップを感じる可能性があります。レガシーなツールが必要な場合は、ハイブリッド アプローチを検討し、負荷の高いデータ準備には Polars を、モデリングとプロットには pandas を使用することに重点を置きます。
Polars 上で pandas 風の DataFrame コードを再利用するための API 互換性レイヤーが存在します。これらのアダプターは、pandas と同じメソッド名/シグネチャをサポートし、同様の動作で、呼び出しを Polars のネイティブ操作に変換できます。ただし、API レイヤーは変換ではないため注意が必要です。セマンティック ギャップを生み出したり、パフォーマンスの落とし穴を隠したりする可能性があります。
あるDataFrameスタックから別のスタックに移行する際の、一般的なリファクタリングパターンと移行戦略をいくつか紹介します。
一般的なリファクタリング パタ�ーン (pandas から Polars へ):
Booleanインデックスを.filter()に置き換えるおよび.select()
- pandas
df2 = df[df["x"] > 0][["id", "x"]]
- Polars
df2 = df.filter(pl.col("x")> 0).select(["id", "x"])
インプレースなミューテーションは .with_columns() で置き換えます
- pandas
df["y"] = df["x"] * 2
- Polars
df = df.with_columns((pl.col("x")* 2).alias("y"))
np.where / 条件付き代入を when/then/otherwise に置き換えます。
- pandas
df["tier"] = np.where(df["revenue"]> 100, "high", "low")
- Polars
df = df.with_columns(
pl.when(pl.col("revenue")>= 100).then("high").otherwise("low").alias("tier")
)
- groupby 集計を式ベースの .agg(...) に書き換えます
- pandas
out = df.groupby("k",as_index=False).agg(total=("v","sum"),users=("id","nunique"))
- Polars
out = df.group_by("k").agg(
pl.col("v").sum().alias("total"),
pl.col("id").n_unique().alias("users"),
)
ファイルベースのETLには遅延スキャンを推奨
- pandas
df = pd.read_parquet("events.parquet")
- Polars
out = (
.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id","revenue"])
.group_by("user_id")
.agg(pl.col("revenue").sum().alias("rev"))
.collect()
)
.apply() の置き換えネイティブな式の使用 (またはUDFの分離)
- Pandas
ほとんどの pandas からの移行は .apply(axis=1) で行き詰まります。
- Polars
Polars の式 (str.*, dt.*, list.*, when/then) で表現してみてください。
やむを得ない場合は、UDF を小さな列/サブセットに分離し、return_dtype を指定します。
- 内部リンク: Python プログラミング (アンカー: データ分析のための Python)
エンタープライズ向けエージェントAIプレイブック

統合とエコシステムの互換性
Polars と pandas は連携して動作するように設計されていますが、異なる実行モデルと型モデルに基づいて構築されています。相互運用性は、共有された内部構造ではなく、明示的な変換ポイントを介して存在します。両方のライブラリが Apache Arrow に対応しているため、Arrow は主要な相互運用性レイヤーとなり、効率的なカラムナ転送とよりクリーンなスキーマの保持を可能にします。
- 交換形式としてParquetまたはArrowテーブルを使用する
- ライブラリをまたぐワークフローではCSVを避ける
相互運用性は明示的かつ意図的なものです。共有の実行エンジンやインデックスのセマンティクスはありません。また、ゼロコピーの保証もありません。常に検証してください。
フォーマット間のデータ変換: to_pandas() と import polars:
- pandas から Polars へ
- pandasの列はArrow互換のPolars型に変換されます
- リセットしない限り、pandas のインデックスは削除されます。
- object列の検査と型強制 (多くはUtf8またはエラー)
- ベストプラクティス
pd_df.reset_index()を呼び出しますインデックスが重要な場合- まずdtypeを正規化します:
- string、Int64、Boolean を使用
- 混合型のobject列を避ける
- Polarsからpandasへ
- Polarsの列はpandasに変換されます(利用可能な場合は、多くの場合Arrowをバックエンドとして使用します)
- デフォルトRangeIndexの作成
- Nullはpandasの欠損表現にマッピングされます。
- ベストプラクティス
- 繰り返しではなく、境界で一度だけ変換します
- 変換後にデータ型を検証 (特に int + null)
- 経験則:ループやホットパスの中ではなく、ワークフローの境界で変換します。
可視化ライブラリやプロットツールと統合する場合、ほとんどのPythonプロットライブラリはpandas(またはNumPy配列)を想定しています。Polarsはうまく統合できますが、プロットの境界でpandasに変換するか、配列/列を直接渡すことが多くなります。
データベース接続とファイル形式のサポートに関しては、アドホックな読み取りやエコシステムの互換性を考慮すると pandas が最適です。Polarsは、大規模なファイル、Parquet、ファイル中心の**アナリティクス**に最適です。Pandasは、PostgreSQL、MySQL、SQL Server、Oracle、SQLite、およびSQLAlchemyドライバーを持つあらゆるデータベースをサポートしています。Polarsは、完全なデータベースクライアントではありません。データがファイルまたはArrowテーブルとして渡されることを想定しています。一部のデータベースやツールはArrowを直接出力でき、Polarsはそれを効率的に取り込むことができます。
どちらもCSVの解析をサポートしています。Polarsは非常に高速でメモリのオーバーヘッドが低い一方、pandasは非常に柔軟な解析が可能で、乱雑なCSVをうまく処理しますが、解析はCPU負荷が高くなる傾向があり、メモリ使用量が急増することがあります。
PolarsはParquetにおいて優れています。PandasはParquetを読み込めますが、Polarsと比較して、操作はeager(即時実行)のみでプッシュダウンは限定的です。ストリーミング実行とArrowネイティブの列指向エンジンにより、Polarsは大規模なデータセットで桁違いに高速な結果を生�成できます。
機械学習 (ML) ライブラリの統合と互換性は、pandasとPolarsのどちらかを選択するか、あるいは両方を実行するかを決める際に、最も大きな実用的な要因の1つです。ほとんどの機械学習ライブラリは、NumPy配列 (X: np.ndarray, y: np.ndarray)、pandasのDataFrames/Series (sklearnのワークフローで一般的)、またはArrowを想定しています。多くのライブラリは、pandasをデフォルトの表形式コンテナとして扱います。そのため、お使いの機械学習スタックが主にsklearnとその関連エコシステムで構成されている場合、pandasを使うのが最も手間のかからない方法であり続けます。
ほとんどの機械学習ライブラリは、まだPolars DataFramesを直接ファーストクラスの入力として受け付けていません。ポーラーズはフィーチャーエンジニアリングには最適ですが、境界でコンバートする予定です。Polarsで大量のデータプリパレーションを行い、モデルトレーニングと推論のためにpandasやNumPyに変換することをお勧めします。
機械学習にデータを取り込むための簡単なチェックリストは次のとおりです。
- 混合型の列は使用しない
- すべての特徴量が数値またはエンコード済み
- Nullの処理 (代入/削除/欠損対応モデル)
- 特徴量の順序は安定
- 特徴量名は保持されます(必要な場合)
- トレーニング/推論のスキーマ検証が導入済み
本番運用に関する考慮事項
pandasやPolarsのワークロードをノートブックから本番運用に移行する際の「落とし穴」は、通常、構文に関するものよりも、ランタイム、パッケージング、パフォーマンスの予測可能性、運用性に関するものです。デプロイターゲットの実際のメモリ/CPU制限下で動作を検証します。ファイルベースのワークロードには、列プルーニング、早期フィルタリング、ストリーミング/遅延スキャンなどの戦略を選択します。
ランタイムとパッケージングについては、本番環境のPythonバージョンがローカルでテストするものと一致することを確認してください。Polarsはネイティブコード (Rust) を同梱しており、pandasはNumPyや、PyArrowやfastparquetなどのオプションのエンジンに依存しています。Parquet/Arrowは通常、本番運用に最適です。CSVよりもスキーマの安定性が高く、読み取りが高速で、データ型の予期せぬ問題が少ないという利点があります。
Polarsはデフォルトでマルチスレッディングを使用します。本番運用では、環境設定を通じてスレッド使用量を設定/制御することを検討してください。PolarsのLazy最適化はスループットを向上させることができますが、非常に小さなジョブではプランニングのオーバーヘッドが発生する可能性があります。
本番運用パイプラインでは、データ型とnull許容性の期待値を明示的に強制する必要があります(どちらのライブラリでも制約をassertする必要があります)。joinの前後でチェックを追加して、意図しない行の急増を防ぎます。
可観測性のため、ランタイム、行数、主要な列のNULL数、ランごとの出力サイズを追跡します。境界(出力を公開する前)で「ストップ・ザ・ライン」チェックを追加します。そして、エラーが対応可能なコンテキスト(どのパーティション/ファイル/テーブル、どの��チェックが失敗したか)とともに表面化するようにしてください。
出力 (行数、集計、null率) とパフォーマンスバジェット (時間/メモリのしきい値) を検証します。ネイティブホイールに関する予期せぬ問題を避けるため、本番運用のOS/glibcと一致するコンテナでテストを実行します。
実践的な移行戦略
チームをpandasからPolarsに移行する、またはpandasと並行してPolarsを導入するための移行戦略:
- ストラングラーパターン – 低リスクかつ継続的デリバリーが必要な場合は、古いpandasを実行し続けたまま、一度に1つのセグメントをPolarsに置き換えます。境界で変換します。
- 両方使う - ボトルネックがETL/アグリゲーションだが、下流でpandasネイティブツールに依存している場合、I/O結合、グループ化、特徴計算にはPolarを使い、最終結果をpandasに変換してscikit-learn、プロット、統計ライブラリに使います。
- 1つのパイプラインを完全に書き直す - 明確な成功事例と再利用可能なパターンが必要な場合は、1つのパイプラインをエンドツーエンドで選択し、Polarsで完全に書き直して内部参照実装として使用します。
- デュアルランでの同等性 – 正確性が重要な場合は、pandasとPolarsのバージョンを一定期間並行して実行し、出力、メトリクス、コストを比較します。同等性が証明されたら切り替えてください。
パフォーマンス・プロファイリング- 最適化の機会を特定するために、起動トラッキング、ウォールタイム(ユーザーがどれだけ待ったか)、ピークメモリー、行数、列数、出力の正確性を確認します。パイプラインのボトルネックの多くは、以下のいずれかです:I/O、join、groupby、ソート、文字列解析、Python UDF。それらのステージの周りに簡単なタイマーを追加します。Pythonレベルの作業が疑われる場合はpandas (Python)プロファイラを使用し、遅延クエリープランを検査する場合はPolarsプロファイラを使用します。目標を1つ変更し、同じベンチマークを再実行して比較します。
チームのトレーニングとナレッジトランスファーに関する考慮事項
目標は、デリバリーを遅らせず、データへの信頼も失わずに成功することです。チームがその動機を理解し、それを具体的な成果 (すなわち、どの問題を解決するのか、どのワークロードが最も恩恵を受けるのか、そして何が変わらないのか) に結び付けられるようにしてください。説明責任を果たすため、オーナーシップ (移行リード、レビュー担当者、意思決定者) を任命します。
関連性を持たせ、賛同を得るために、例として実際の企業のパイプラインを使用します。PolarsはPython構文でありながらSQLに近いため、最大の変更点は概念的な考え方の転換です:
- 命令型から宣言型へ
- 行単位から列単位へ
- ミュータブルな状態からイミュータブルなパイプラインへ
- 即時実行から遅延プランニングと実行へ
チームが早い段階で生産性を実感できるように、トレーニングは段階的に進めましょう。式、null処理、データ型の違いに進む前に、フィルタリング、選択、グループ化から始めるとよいでしょう。次に、移行と本番運用パターンの前に、遅延実行と最適化に取り組みます。不安を軽減するため、pandas を使用できる範囲に関する明��確なガイダンスを伴うハイブリッド フェーズを確立します。ナレッジトランスファーを迅速化するため、経験豊富な Polars ユーザーと pandas を多用するユーザーをペアにします。
信頼を築き、勝利を測定し共有するために、正しさを公に検証します。
FAQ
- pandasはPolarsより優れていますか?どちらかが普遍的に優れているわけではありません。選択は、特定のワークフロー要件、データセットのサイズ、パフォーマンスのニーズによって決まります。
- Polars と pandas はどちらが優れていますか?Pandas は対話型分析とエコシステムとの統合に優れており、Polars は大規模な本番運用パイプラインでより優れたパフォーマンスを発揮します。
- Polars は pandas の代替ですか?Polars は pandas を置き換えるのではなく補完するものであり、どちらもさまざまなユースケースで効果的に機能します。
- Polars に切り替える価値はありますか?それは、Polars の遅延モードとクエリー最適化が測定可能なメリットをもたらすような、大規模なデータセットを処理しているかどうかによります。
まとめ
チームにとってどの DataFrame ライブラリが適しているかを決める際に、万能な答えはありません。一般的に、pandas は中小規模のデータセットや探索的分析に適している一方、遅延実行を備えた Polars は、大規模な(メモリを超えるサイズの)ワークロードで高いパフォーマンスを発揮するのに適しています。ユースケースによっては両方を使用することになるかもしれません。そのため、特定のワークフローの小さな部分で両方のラ��イブラリを試し、実際のデータ処理タスクに基づいて評価してください。
チームは、列指向ストレージと行指向ストレージの長所と短所、そしてそれらがさまざまなクエリーパターンに与える影響を理解する必要があります。コアAPI、構文、データ形式、データベース接続の違いにより、DataFrameライブラリを切り替える際には習熟期間が必要となります。
さらなる学習と実験のためのリソース:
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。