
序章
今日のデジタルエコノミーにおけるデータとAIの共有
今日の経済はデータを中心に回っています。日々、ますます多くの組織が、顧客、サプライヤー、パートナーとデータを交換する必要があります。セキュリティは重要です。とは言え、効率性と即時アクセス性も、同じくらい重要です。これまで任意とされてきたデータ共有が、今では必須となっています。バリューチェーン全体で社内外のデータ共有の効率化に投資する組織が増えています。しかし、人的な制約からレガシーソリューション、ベンダーロックインに至るまで、依然として大きな障害に直面しています。ガートナー社の最近の調査によると、データ共有の取り組みを成功させた最高データ責任者は、データ分析戦略から得られるビジネス価値と投資収益率を示す上で、1.7倍も高い効果を発揮していることがわかりました。デジタルエコノミーで競争するためには、組織にはオープンかつセキュアなデータ共有へのアプローチが必要です。
近年、AIの台頭はデータ共有に新たな次元を加えています。AIモデルは大量かつ多様なデータで性能が向上するため、組織が構造化データセットだけでなく非構造化データ(画像、動画、テキストなど)やAIモデルそのものを共有することが不可欠です。高度なAI主導のユースケースの実現を目指す企業にとって、AIモデルと非構造化データを効率的に共有する能力は、主要な差別化要因となりつつあります。
この電子書籍は、現代のデータ共有とコラボレーションについて、一般的なユースケースと主なメリットから従来のアプローチとその課題に至るまで、深く掘り下げて解説します。データ共有に対する当社のオープンなアプローチの概要をご覧いただくとともに、Databricks を利用して、プラットフォームを横断したデータ共有、すべてのデータとAIの共有、そして統一ガバナンスによるプライバシーを保護した安全なデータ共有�を実現する方法をご確認いただけます。
データ共有とは何か、なぜそれが重要なのか?
データ共有とは、社内外の 1 人または複数のステークホルダーが同じデータを利用できるようにすることです。今日では、増え続けるデータ量は、あらゆる企業にとって戦略的な資産となっています。組織内または外部とのデータ共有は、データ エンリッチメント、高度な分析、またはマネタイゼーションを可能にする技術です。データを共有したり、外部ソースからデータを利用したりすることで、企業はパートナーとの連携、新たなパートナーシップの構築、データ収益化による新たな収益源の創出が可能になります。データ共有は、企業全体のビジネスグループにメリットをもたらすことができます。これらのビジネスグループにとって、データ共有によって重要な意思決定に必要なデータへのアクセスが可能になります。
データとAI共有の一般的な活用事例

BU間の内部共有
どのような企業でも、全員がビジネスの現状を完全に把握したうえで意思決定を行えるように、さまざまな部門、事業部門、子会社がデータの共有を目指します。たとえば、財務部門と人事部門は、各従業員の真のコストを分析する際にデータを共有する必要があります。マーケティングチームと営業チームは、最近のマーケティングキャンペーンの効果を判断するために、データを一元的に��把握する必要があります。また、同じ会社のさまざまな子会社は、ビジネスの健全性を一元的に把握する必要があります。データへの不正アクセスを防ぐという重要な目的で設けられることが多いデータサイロを解消することは、デジタルトランスフォーメーションを推進し、データのビジネス価値を最大化するうえで不可欠です。

ピアツーピア共有
現在、多くの企業が、自社内でデータを共有するのと同様に、パートナーやサプライヤーともデータを共有しようと努めています。たとえば、消費者の嗜好が絶えず変化する時代において製品を円滑に流通させるため、小売業者とサプライヤーはより緊密な連携を続けています。小売業者は、SKU 別の販売データをリアルタイムで共有してサプライヤーに最新情報を伝えることができる一方、サプライヤーはリアルタイムの在庫データを小売業者と共有することで、小売業者が状況を把握できるようになります。科学研究機関は、創薬に取り組んでいる製薬会社に自社のデータを提供できます。公共安全機関は、気候変動の統計や火山噴火の可能性に関する最新情報など、環境に関するリアルタイムの公開データフィードを提供できます。

第三者データライセンス
業界を問わず、企業によるデータの商用化が進んでおり、この分野は成長を続けています。データの収益化のみを目的として設立された大規模な多国籍企業がある一方で、他の組織は自社のデータを収益化し、新たな収益源を生み出す方法を模索しています。こうした企業の例としては、S&P のような資本市場データ プロバイダー、Epsilon のようなマーケティング データのハイジーンおよびエンリッチメントを行う企業、独自の 5G データを保有するテレコミュニケーション会社、オンラインとオフラインのデータを組み合わせる独自の能力を持つ小売業者などが挙げられます。より良い意思決定のためには外部データが必要であると企業が認識するにつれ、データベンダーの重要性が高まっています。

SaaS アプリケーションの共有
企業は、業務のさまざまな側面において、各種クラウドベース サービスへの依存度を高めています。その結果、データは個々のSaaSアプリケーション内に孤立し、ビジネス オペレーションの全体像の把握が困難になります。SaaSアプリケーション共有は、複数のSaaSプラットフォームからのデータを統合して分析するという、企業の高まるニーズに対応します。このアプローチにより、組織はさまざまなSaaSアプリケーションから情報を取り込むことでデータエコシステムを拡張し、より包括的��で統一されたデータ戦略を実現できます。例えば、AVEVAはDatabricksと提携し、お客様が信頼性の高い、高品質な産業データを地域やプラットフォームを越えてシームレスかつ安全に共有できるようにしました。
データとAIの共有による主な利点
記載されているユースケースからわかるように、データ共有には次のような多くのメリットがあります。

既存のパートナーとの連携を強化。
今日の超接続デジタル経済では、どの組織も単独ではパートナーシップなしに事業目標を推進することはできません。データ共有は、既存のパートナーシップを強化し、組織が新しいパートナーシップを確立するのに役立ちます。

新たな収益源の創出。
データ共有により、組織は最終消費者にデータプロダクトやデータサービスを提供することで、新たな収益源を生み出すことができます。

新しい製品、サービス、ビジネスモデルの生み出しやすさ。
製品開発チームは、ファーストパーティデータとサードパーティデータの両方を活用して、製品やサービスを改善し、製品/サービス カタログを拡充することができます。

内部業務の効率化。
組織全体のチームは、データのサイロ化を解消する方法を考えることに時間を費やす必要がなくなるため、ビジネス目標をより迅速に達成できます。チームがライブデータにアクセスできると、データが必要になってから適切なデータソースに接続するまでにラグが生じません。
データとAI共有の従来手法とその課題
さまざまなプラットフォーム、企業、クラウド間でデータを共有することは、簡単なタスクではありません。従来、組織は、安全なテクノロジーの欠如、競合上の懸念、データ共有ソリューションの実装コストといった認識から、より自由なデータ共有をためらってきました。
データ共有テクノロジーを導入する予算がある企業であっても、現在の多くのアプローチでは、オープンフォーマット、マルチクラウド、ハイパフォーマンス ソリューションに対する今日の要件に対応しきれていません。ほとんどのデータ共有ソリューションは単一のベンダーに縛られているため、互換性のないプラットフォームを使用するデータプロバイダーとデータ利用者にとっては摩擦が生じます。生成AIの台頭により、データは構造化データだけではなくなりました。非構造化データ(音声、動画、画像、PDF など)が急増しており、AI モデルが必要とされています。
過去30年間、データ共有ソリューションには、レガシーおよび自社開発のソリューション、クラウドオブジェクトストレージ、クローズドソースの商用ソリューションという3つの形態がありました。これらのアプローチにはそれぞれ長所と短所があります。
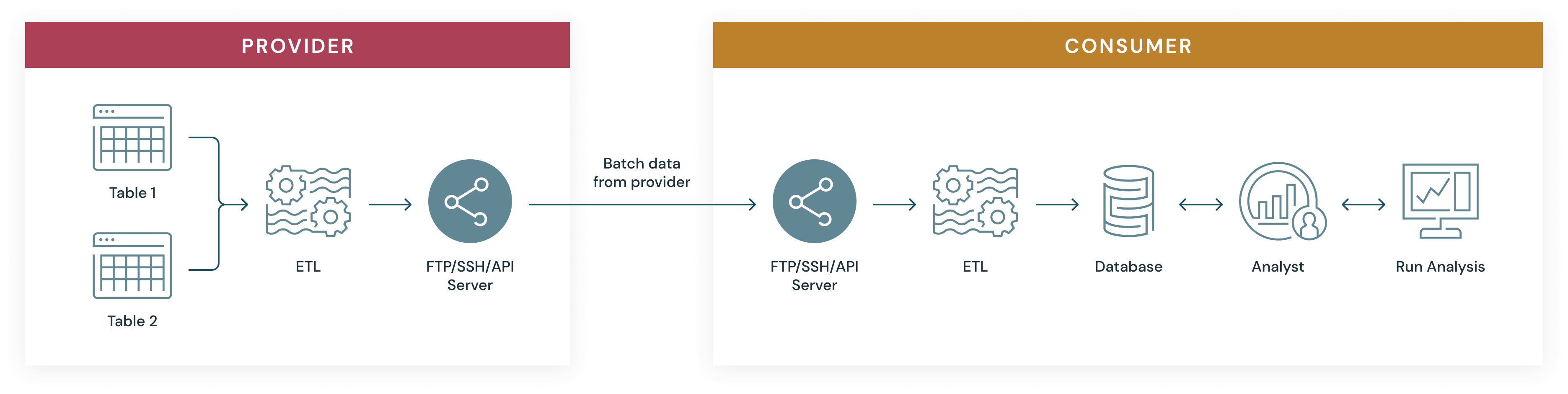
レガシーおよび内製のソリューション
多くの企業が、Eメール、(S)FTP、APIsなどのレガシーテクノロジーをベースに、自社開発のデータ共有ソリューションを構築してきました。
メリット
- ベンダー非依存:FTP、Eメール、APIs はすべて、ドキュメントが整備されたプロトコルです。データ利用者は、一連のクライアントを活用して、提供されたデータにアクセスできます。
- 柔軟性: 多くの内製ソリューションはオープンソース技術に基づいて構築されており、オンプレミスとクラウドの両方で動作します。
短所
- データの移動: クラウド ストレージからデータを抽出し、変換して、さまざまな受信者向けに FTP サーバーでホストするには、多大な労力がかかります。さらに、このアプローチでは、データ プロバイダーが複数のプラットフォームや多数のリージョンに手動でデータをコピーすることになります。データコピーはデータの重複を招き、組織はライブデータに即座にアクセスできなくなります。
- データ共��有の複雑さ: 自社開発のソリューションは、レプリケーションとプロビジョニングのために、通常は複雑なアーキテクチャ上に構築されます。これにより、データ共有に多大な時間がかかるようになり、エンドユーザーが受け取るデータが古くなってしまう可能性があります。
- データ受信者の運用オーバーヘッド: データ受信者は共有データをエンドユースケースで利用するために抽出、変換、読み込み(ETL)を行う必要があり、知見を得るまでの時間がさらに遅延します。プロバイダーから新しいデータ更新があるたびに、コンシューマーは ETL パイプラインを何度も再実行する必要があります。
- セキュリティとガバナンス: 現代のデータ要件が厳しくなるにつれて、自社開発のテクノロジーやレガシー テクノロジーでは、セキュリティを確保しガバナンスを徹底することがますます困難になっています。
- スケーラビリティ: このようなソリューションは管理と維持に費用がかかり、大規模なデータセットに対応するようには拡張できません。
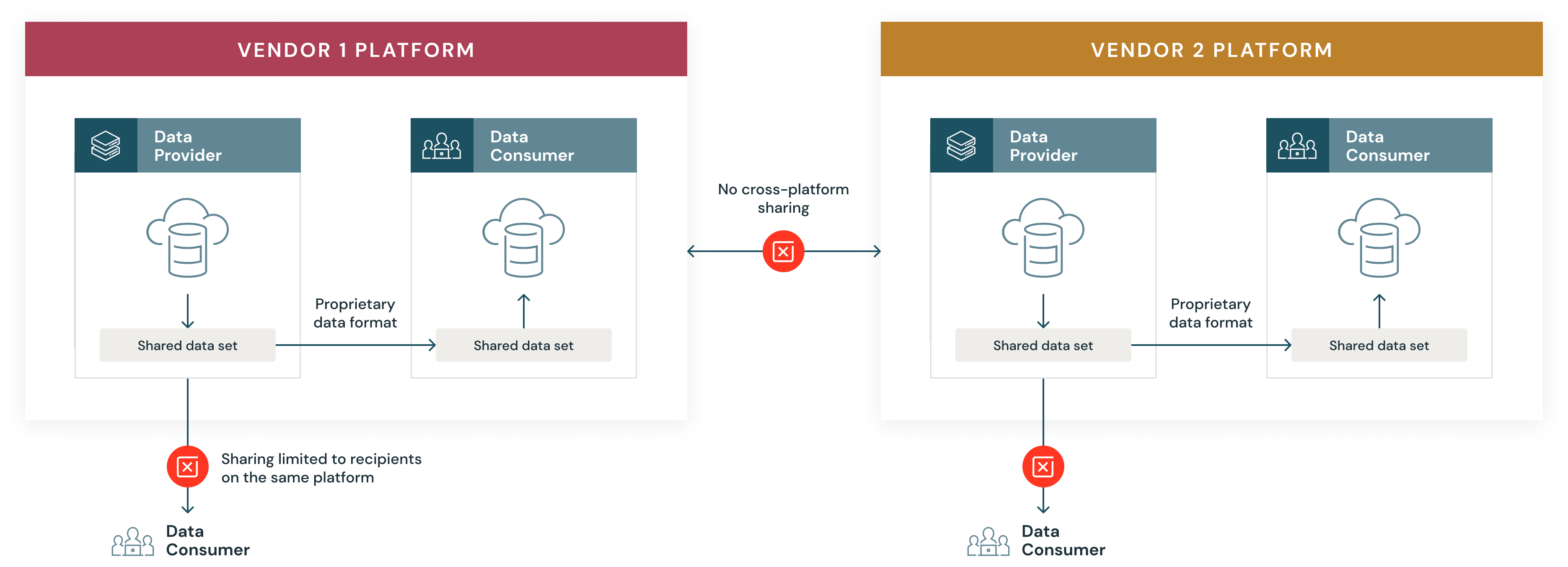
独自のベンダーソリューション
社内ソリューションの構築に時間とリソースをかけたくはないものの、クラウドオブジェクトストレージが提供するものよりも高度な管理を求める企業にとって、商用のデータ共有ソリューションは一般的な選択肢です。
メリット
- シンプルさ:商用ソリューションでは、ユーザーは同じプラットフォームを使用している他のユーザーと簡単にデータを共有できます。
短所
- ベンダー ロックイン: 商用ソリューションは、他のプラットフォームとの相互運用性が高くありません。顧客同士でのデータ共有は簡単ですが、競合ソリューションを利用しているユーザーとの共有は、通常不可能です。これによりデータの活用範囲が狭まり、ベンダー ロックインにつながります。さらに、データ提供者と受信者間でプラットフォームが異なると、データ共有が複雑になります。
- データ移動:データをプラットフォームにロードするには、追加の ETL とデータのコピーが必要です。
- スケーラビリティ: 商用データ共有には、ベンダーによるスケーリングの制限があります。
- コスト: データ プロバイダは、さまざまなクラウド プラットフォーム上のさまざまな受信者向けにデータを複製する必要があるため、これらすべての課題によって、データを潜在的な利用者に共有する際に追加のコストが発生します。
ク�ラウド オブジェクト ストレージ
オブジェクト ストレージは、弾力性があり、無制限のデータ増加に対応するために複数ペタバイトまで容易に拡張できるため、クラウドに適していると考えられています。3大クラウドプロバイダーはすべて、安価でスケーラブル、かつ信頼性がきわめて高いオブジェクトストレージサービス(AWS S3、Azure Blob Storage、Google Cloud Storage)を提供しています。
クラウド オブジェクト ストレージの興味深い機能として、オブジェクトを download するための期間限定の権限を付与する署名付き URL の生成機能が挙げられます。事前署名付きURLは、受け取った人が誰でも指定のオブジェクトにアクセスできる、便利なデータ共有方法です。
メリット
- データのインプレース共有: オブジェクト ストレージをインプレースで共有することで、コンシューマーは利用可能な最新のデータにアクセスできるようになります。
- スケーラビリティ: クラウド オブジェクト ストレージは、通常オンプレミスでは達成できない可用性と耐久性の保証の恩恵を受けます。データコンシューマーはクラウドプロバイダーから直接データを取得することで、プロバイダーの帯域幅を節約します。
短所
- 単一のクラウド プロバイダーに限定: 受信者がオブジェクトにアクセスするには、同じクラウドを利用している必要があります。
- 煩雑なセキュリティとガバナンス: 権限の割り当てとアクセスの管理は複雑です。署名付き URL を生成するには、カスタム アプリケーション ロジックが必要です。
- 複雑さ: データ共有を管理する担当者(DBA、アナリスト)は、ID とアクセス管理(IAM)ポリシーや、データが基盤となるファイルにどのようにマッピングされているかを理解することが困難だと感じています。大量のデータを保有する企業にとって、クラウドストレージ経由でのデータ共有は時間がかかり、煩雑で、スケールさせることはほぼ不可能です。
- データ受信者の運用上のオーバーヘッド: データ受信者は、最終的なユースケースでデータを使用する前に、未加工ファイルに対して抽出、変換、読み込み(ETL)パイプラインを実行する必要があります。
新しい課題: AIモデルの共有と非構造化データ共有
AIが進化を続け、産業の未来を形作る中で、組織は従来の構造化データや表形式データセットを超える、さらなる課題に直面しています。現代の企業は、構造化データセットだけでなく、画像、動画、ドキュメントなどの非構造化データ、およびAIモデル自体(例: 機械学習モデルやノートブック)も共有する必要があります。
1. 非構造化データの共有
- 非構造化データセット(テキスト ドキュメントやマルチメディア ファイルなど)の共有には、特有の課題があります。これらの形式は、データベースやスプレッドシートなど��の構造化データセットと比較して、サイズが大きかったり、標準化されたスキーマがなかったりすることが多いためです。
- セキュリティ基準を維持しつつ、異なるプラットフォームやクラウドにまたがって非構造化ボリュームのリアルタイム コラボレーションが必要になると、複雑さは増大します。
2. AIモデルの共有
- AIモデル(例: トレーニング済みの機械学習モデル)、ノートブック、その他のAIアーティファクトを組織間で簡単に共有できないことは、イノベーションを制限します
- フレームワーク間の技術的な非互換性やセキュリティ上の懸念などにより、クロスプラットフォームでのAIモデル交換の効果的なメカニズムがなければ、組織は共有データセットの潜在能力を最大限に引き出すことに苦労します。
非構造化データセットの共有とAIモデルの共有は、どちらも組織が高度なAI駆動型のユースケースを完全に実現することを妨げる大きな障壁となっています。
包括的なソリューションがないため、データプロバイダーとコンシューマーがデータとAIアセットを簡単に共有することは困難になっています。煩雑で不完全なデータ共有プロセスも、共有データからのビジネス機会の創出を制約します。
Delta Sharing:データとAIアセットを安全に共有するためのオープンスタンダード
私たちは、データとAI共有の未来は、オープンなテクノロジーによって築かれるべきだと信じています。デ�ータとAIの共有は、プロセスに不要な制限や金銭的負担をもたらすプロプライエタリなテクノロジーに縛られるべきではありません。大規模にデータを共有したい人なら誰でも、すぐに利用できるべきです。この理念に触発され、データを共有するための新しいプロトコル「Delta Sharing」を開発・リリースしました。
Delta Sharingとは何ですか?
Databricks の Delta Sharing は、レイクハウスからのライブデータをセキュアに共有するためのオープンなソリューションです。あらゆるコンピューティングプラットフォームでの共有を可能にします。データを受信するユーザーは、Databricks プラットフォームを利用している必要も、同じクラウド上にいる必要もなく、そもそもクラウドを利用している必要もありません。データプロバイダーは、他のシステムにレプリカの作成や移動しなくても、ライブデータを共有できます。データを受信するユーザーは、常に最新バージョンのデータにアクセスできるという利点があり、BI、分析、機械学習用に選択したツールを使用して、共有データをすばやく照会できるため、価値創出までの時間が短縮されます。
また、データプロバイダーは共有データのガバナンス、監査、使用状況の追跡は 1 つのプラットフォームで一元管理できます。Delta Sharing は Unity Catalog とネイティブに統合されており、これにより組織は、セキュリティとコンプライアンスのニーズを満たしながら、組織間で共有されるデータを一元的に管理・監査し、データ資産を安心して共有できます。Delta Sharingプロトコルは、データとAI製�品を交換するためのオープンマーケットプレイスであるDatabricks Marketplaceや、複数の関係者が機密性の高い企業データで共同作業を行うための安全でプライバシーを保護する環境であるDatabricks Clean Roomsの基盤ともなっています。
Delta Sharing を使用すると、組織はデータを移動させることなく、オープンソース形式の Apache Parquet、Apache Iceberg™、Delta Lake に基づく既存の大規模なデータセットを簡単に共有できます。チームは、任意のツールを使用して、共有データに対するクエリー、可視化、変換、インジェスト、エンリッチを柔軟に行うことができます。
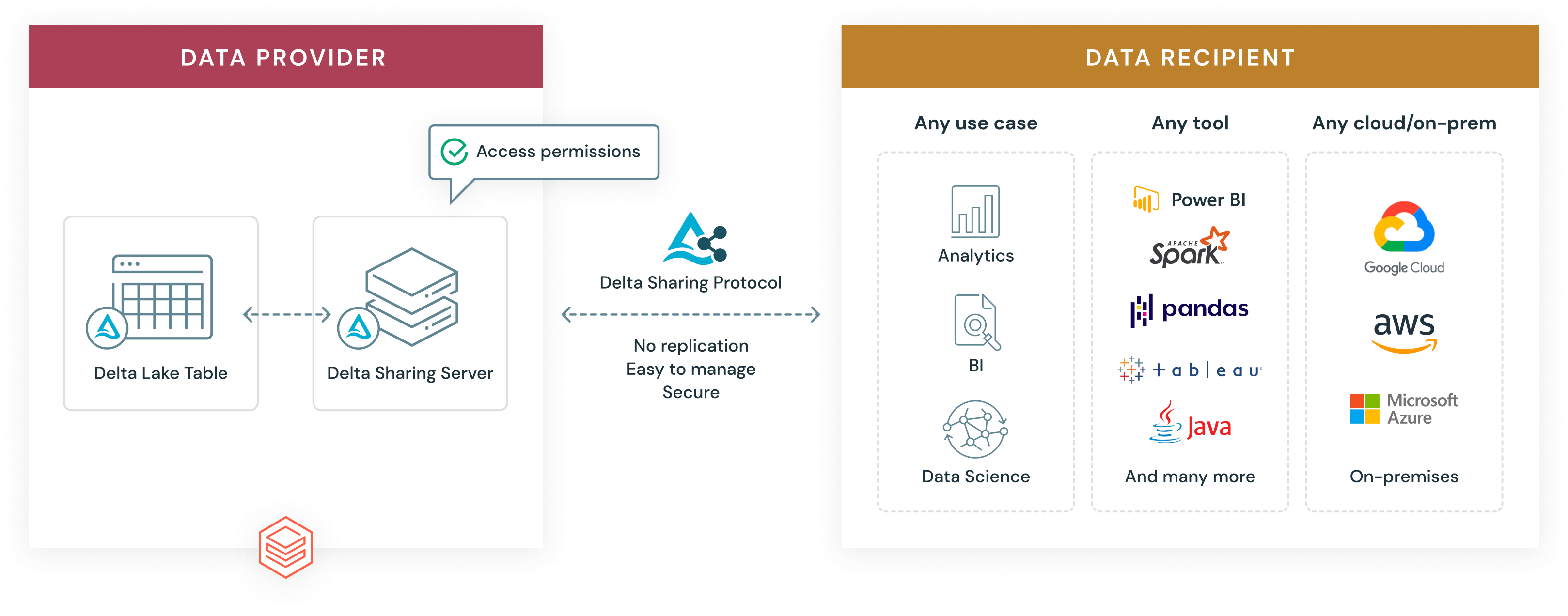
DatabricksによるDelta Sharingの設計には、5つの目標があります:
- オープンなクロスプラットフォーム共有ソリューションを提供する
- 他のシステムにコピーせずに、ライブデータを共有する
- Power BI、Tableau、Apache Spark™、pandas、Java などの幅広いクライアントをサポートし、BI、Machine Learning、AI のユースケースにおいて、お好みのツールを使用してデータを柔軟に利用できます。
- 強力なセキュリティ、監査、ガバナンスを提供
- 大規模な構造化データ�セットにスケーリングし、表形式データに加えて、非構造化データ、機械学習 モデル、ダッシュボード、ノートブックの共有も可能です。
Delta Sharingの主なメリット
一般的なデータ共有アプローチに伴う障害や欠点を取り除くことで、Delta Sharingはいくつかの主要なメリットをもたらします。

プラットフォームを問わないオープンな共有Delta Sharingは、安全なデータとAI共有のための新しいオープンスタンダードを確立し、オープンソースのDeltaおよびApache Parquetフォーマットをサポートします。Delta Sharing は、クロス クラウドおよびクロス プラットフォームでの共有をサポートしています。Delta Sharingは複数のクラウドにまたがって、さらにはクラウドからオンプレミスのセットアップまで機能するため、データ受信者はDatabricksプラットフォームや同じクラウドを使用している必要はありません。お客様にさらに高い柔軟性を提供するため、Databricks は pandas、Apache Spark、Elixir、Python 向けのオープンソース コネクタもリリースしており、さらに多くのコネクタについてもパートナーと協力しています。

複製することなく、ライブデータを安全に共有。
現在、ほとんどの企業データはクラウドデータレイクに格納されています。プロバイ��ダのデータレイクにあるこれらの既存のデータセットは、データを複製したり物理的に移動させたりすることなく、簡単に共有できます。データプロバイダーは、データセットをリアルタイムで確実に更新し、受信者にデータの最新で一貫性のあるビューを提供できます。

ガバナンスの一元化Databricks Delta Sharingを使用すると、データプロバイダーはコンプライアンスやその他の規制要件を満たすため、単一のポイントから共有データセットへのアクセス権の付与、追跡、監査、取り消しを行うことができます。Databricks Delta Sharing ユーザーは以下を利用できます:
- Databricks Data Intelligence Platformのガバナンス機能であるUnity Catalogの一部としてのDelta Sharingの実装
- シンプルで、より安全な共有の設定と管理
- 受信者とデータ共有を作成および管理する機能
- Unity Catalogの一部として自動的にキャプチャされる監査ログ
- Databricks エコシステムの他の部分との直接統合
- 共有の提供と管理に専用のコンピュートは不要
- レイクハウスフェデレーションによる共有では、高価なETLやDatabricksへのデータコピーを必要とせずに、既存のデータウェアハウスやデータベースか�らデータを共有できます。

AI モデル、非構造化データ、ダッシュボード、ノートブックなどのデータ製品を、より柔軟に共有できます。
データプロバイダーは、テーブル全体を共有するか、テーブルのバージョンまたは特定のパーティションのみを共有するかを選択できます。しかし、表形式データを共有するだけでは、今日の消費者の要求に応えるには十分ではありません。Databricks Delta Sharing は、データ Stream、AIモデル、SQLビュー、ボリューム、任意のファイルなどの非表形式データやデータ派生物の共有もサポートしており、コラボレーションとイノベーションを促進します。ボリューム共有を使用すると、プロバイダーは、クラウド ボリュームに保存されている画像、動画、Logsなどの大規模な非構造化データを複製することなく、安全に共有できます。データ プロバイダーは、データセット、ボリューム、AI モデル、ノートブックなどのデータ製品を構築、パッケージ化、配布できるため、データ受信者はより迅速に知見を得ることができます。さらに、このアプローチは、異なる組織間でデータだけでなく知識の交換を促進し、強化します。Databricks Delta Sharing により、真にオープンなMarketplaceと真にオープンなエコシステムの両方を実現できます。対照的に、商用製品は主に生の表形式データの共有に限定されており、このようなより価値の高いデータ派生物の共有には使用できません。

より低いコストでデータを共有。
Delta Sharingは、データプロバイダーとデータ受信者の両方において、共有の管理と利用にかかるコストを削減します。プロバイダーは、クラウド オブジェクト ストアからデータを複製せずに共有することで、ストレージ コストを削減できます。さらに、CloudflareのBandwidth Allianceと、エグレス料金がゼロのR2オブジェクトストレージを統合することで、Delta Sharingはエグレス料金(クラウドプロバイダーのネットワーク外にデータを転送する際に発生する料金)をなくすか、または大幅に削減し、コストをさらに最小化します。
これに対し、既存のデータ共有プラットフォームでは、データプロバイダはまずプラットフォームにデータを移動させるか、あるいは管理ストレージに独自の形式でデータを保存する必要があります。このため、多くの場合コストが増加し、データの重複も発生します。Delta Sharing を使用すると、データ プロバイダーはデータを共有するために個別のコンピューティング環境をセットアップする必要はありません。利用者は、特定のデータ利用環境を構築することなく、任意のツールを使用して共有データに直接アクセスできるため、コストを削減できます。

価値実現までの時間を短縮。
Delta Sharing により、データを利用するために新しい取り込みプロセスを設定する必要がな��くなります。データ受信者は、最新のデータに直接アクセスし、任意のツールを使用してクエリーを実行できます。受信者は、人気のデータプロバイダーのデータセットでデータをエンリッチすることもできます。オープンソースおよび商用のパートナーで構成される Delta Sharing エコシステムは、日々拡大しています。
Delta SharingでデータとAIの価値を最大化する
Delta Sharingは、すでに幅広い業界の企業において、データとAIの共有活動を変革しています。利用可能なデータの多様性や、次々と登場するテクノロジーを考えると、Delta Sharingが対応できるあらゆるユースケースを予測することは困難です。Delta Sharing のアプローチは、あらゆるデータを、いつでも誰とでも、簡単かつ安全に共有できるようにすることです。このセクションでは、そのようなアプローチの構成要素と、そこから生まれるユースケースについて見ていきます。
"Databricksとの連携を継続し、同社のDelta Sharingプラットフォームを通じて当社のデータ配信機能を強化できることを嬉しく思います。このプラットフォームはオープンなエコシステムを提供し、お客様が数多くのS&P Globalコンテンツセットに、よりシームレスにアクセスし、利用できるようになります。「これにより、S&P Global Capital IQ Workbench で始まった Databricks とのコラボレーションが拡大し、同社のテクノロジーを活用して、ユーザー向けの協調的なアナリティクス ノートブック環境を構築しています。」—David Coluccio氏、ディストリビューション・ソリューション部門長、S&P Global Market Intelligence
"ほとんどのデータプラットフォームはクローズドな共有ソリューションを提供しているため、すべての顧客にリーチする当社の能力が制限されています。私たちは、すべてのお客様やパートナーと、クラウド間だけでなくプラットフォーム間でもデータを共有できるオープンなソリューションに投資することを優先しています。"—デレク・スレイガー、Amperity、CTO兼共同創業者
"AI21 Labsは、Jamba 1.5 MiniがDatabricks Marketplaceで利用可能になったことを嬉しく思います。"「Delta Sharing」により、企業は256Kのコンテキストウィンドウを特長とする当社の「Mamba-Transformer」アーキテクチャにアクセスでき、革新的なAIソリューションのための卓越した速度と品質が保証されます。—パンカジ・ドゥガー、AI21 Labs、SVP 兼 GM
"当社では、一部の製品に強化学習(RL)モデルを使用しています。"RL モデルは教師あり学習モデルに比べ、トレーニング時間が長く、トレーニング プロセスに多くのランダム性の要因があります�。これらのRLモデルは、個別のAWSリージョンにある3つのワークスペースにデプロイする必要があります。モデル共有により、1 つの RL モデルを再トレーニングしたり、モデルを移動するための面倒な手動ステップを踏んだりすることなく、複数のワークスペースで利用できます。"—Mihir Mavalankar、Ripple、Machine Learning Engineer
"Delta Sharingを使用すると、データのコピーや複製を行うことなく、ビジネス ユニットや子会社とデータを安全かつ簡単に共有できます。これにより、ワークスペースに ID を持たない受信者とも、データを共有できるようになります。"—Robert Hamlet、Cox Automotive、リードデータエンジニア
「パートナーと共同で POS 消費者ローンなどの製品を立ち上げて成長させたい場合、データの所有者は数万人もの顧客に関する膨大なデータセットを送信する必要があります。」以前は、従来のデータウェアハウスのアプローチでは、送信されたデータのスキーマをシステムで読み取れるように変更する必要があったため、新しいデータソースを取り込むのに通常 1~2 か月かかっていました。しかし今では、Databricks を適用すれば、価値が生まれるまでわずか 2 日です。「Delta Sharing を使用したところ、10分もかからずに Databricks ワークスペース��にデータテーブルが表示されました。」—Barb MacLean 氏、Coastal Community Bank、SVP 兼 技術運用・導入部門責任者
Delta Sharingによる事業部門間の内部共有
組織内のデータ共有は、現代の組織にとってますます重要な検討事項となっています。特に、同じ概念を記述するデータが、組織内のさまざまなデータサイロで、さまざまな方法で作成されている場合はなおさらです。したがって、データとプロセスの統制された意図的なフェデレーションを可能にすると同時に、それらのデータとプロセスを容易かつシームレスに統合できるようにするシステムとプラットフォームを設計することが重要です。
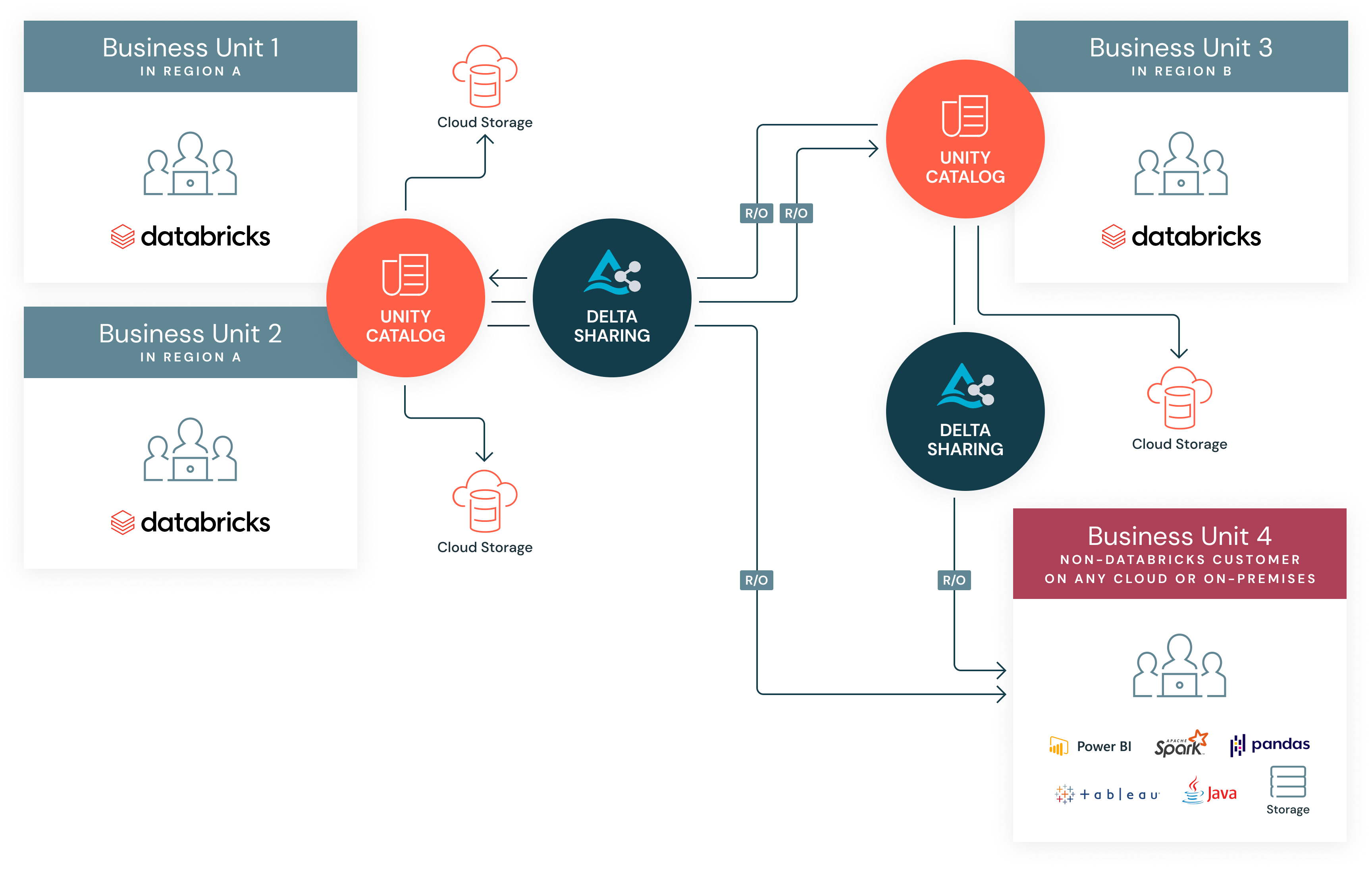
さらに複雑なことに、組織は合併や買収によって成長することもあります。このような場合、買収される組織が、自社のプラットフォームを定義してデータを作成する際に、同じ一連のルールや基準に従ってきたと想定することはできません。さらに、同じクラウドプロバイダーを使用しているとさえ想定できず、そのデータモデルの複雑さも想定できません。
Delta Sharingは、新たに買収した組織とそのデータやプロセスの統合と吸収を簡素化し、加速させることができます。選択されたデータソースのみ、異なるクラウド、プラットフォーム�、リージョン間で交換できます。これにより、チームはデータを失うことなく統合中の組織間を自由に移動できます。むしろ、両方のデータを組み合わせることで、より質の高い知見を引き出すことが可能になります。
Databricks Marketplaceは、組織が特定の事業部門やパートナーとデータおよびAIプロダクトを安全に共有できるプライベートエクスチェンジ機能を提供することで、内部共有をさらに強化します。公開マーケットプレイスのリスティングとは異なり、プライベート エクスチェンジでは、プロバイダーは誰が自分のデータと AI 製品を発見し、アクセスできるかを制御できます。この機能はDelta Sharingを基盤として構築されており、データを複製しなくても共有データのセキュリティが確保されます。
Unity Catalogは、組織内の事業部門 (BU) 間の内部データ共有を効率化し、ガバナンスを強化する上で中心的な役割を果たします。Unity Catalogは、すべてのデータ資産に対する一元的なガバナンス、監査、アクセス制御を提供し、組織のポリシーに準拠した安全な共有を保証します。Delta Sharing とシームレスに統合されます。これは、Databricks が開発した、異なるプラットフォーム間で安全なデータ共有を行うためのオープンプロトコルです。
Unity CatalogとDelta Sharing、Databricks Marketplaceのプライベートエクスチェンジを組み合わせることで、堅牢なセキュリティ制御を維持しつつ、BU間の内部コラボレーションのための強力なフレームワークが提供されます。チームは、重要なデータへのアクセスを失うことなく、組織内のさまざまな部門や新たに買収した事業体の間を自由に移動できます。これにより、より迅速な知見の獲得と、より適切な意思決定が可能になります。
Delta Sharingによるピアツーピア共有
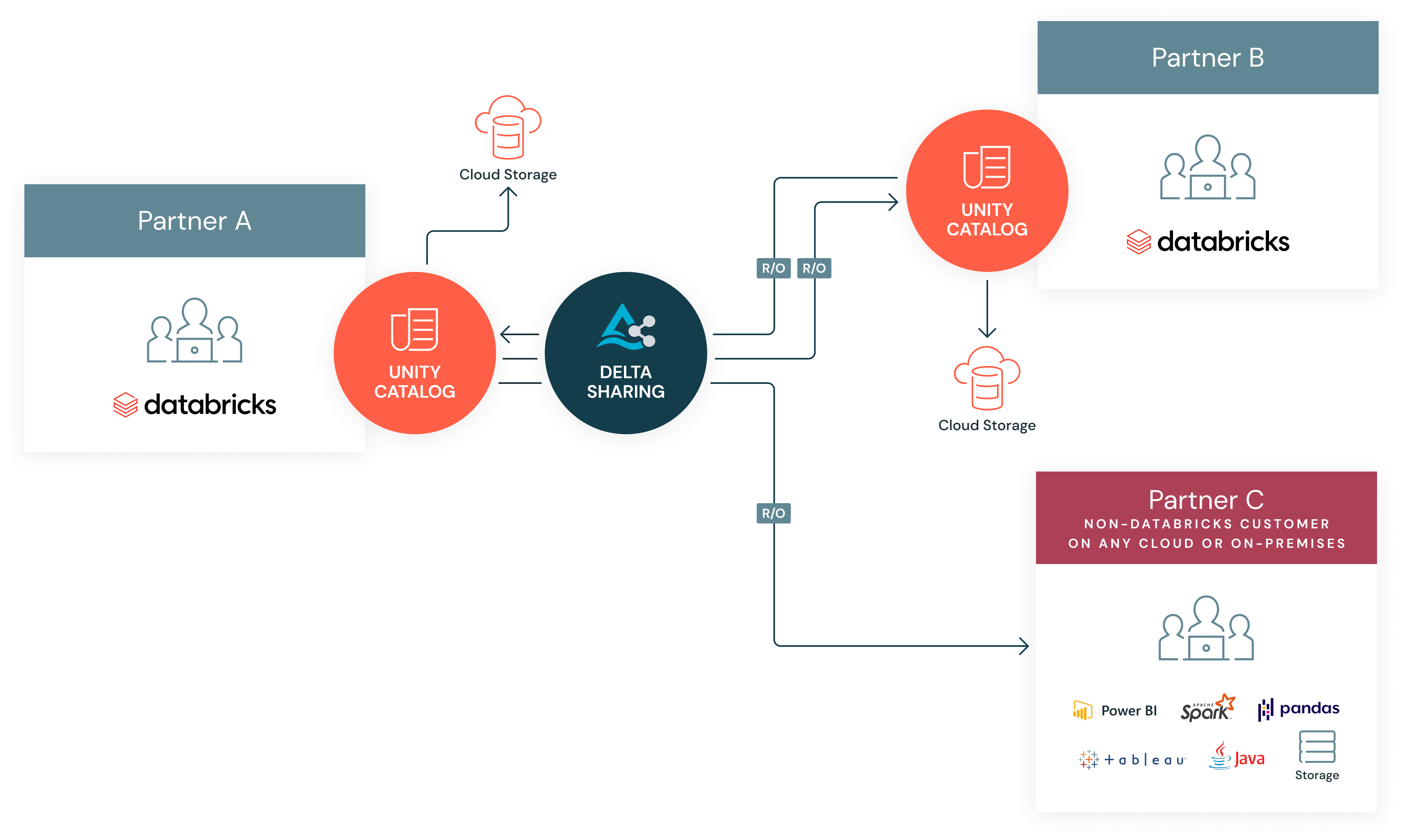
Delta Sharingは双方向のデータ交換を実現する堅牢なソリューションへと進化し、企業はパートナー、顧客、サプライヤーを自社のワークフローにシームレスに統合できるようになりました。
従来、ピアツーピア共有は簡単なタスクではありませんでした。組織は、パートナーが独自のデータプラットフォームをどのように実装しているかを管理することはできません。さまざまなパートナーが、各種の形式、プロトコル、メソッド(API、CSV、JSON、FTP、HTTP)を使用することもあります。パートナーやサプライヤーがパブリック クラウド、プライベート クラウド、またはオンプレミスにデプロイされたデータ プラットフォームに存在する可能性があることを考慮すると、複雑性はさらに高まります。パートナーやサプライヤーに、プラットフォームとアーキテクチャの選択が強制されることはありません。Delta Sharingは、オープン プロトコルでこれらの課題に対処し、パートナーやサプライヤーに特定のアーキテクチャの選択を強いることなく、クラウド、プラットフォーム、リージョンを越えたデータ共有を可能にします。この柔軟性は、データを必要な場所ならどこにでも配置できるようにす�る、幅広いコネクタによって支えられています。
データだけでなく、Delta SharingではAIモデルも外部の関係者と共有し、革新的な方法でのコラボレーションを可能にします。1か所でモデルをトレーニングし、どこにでもデプロイできます。共有モデルは、Databricks AI 機能ですぐに動作します。共有モデルは Unity Catalog に表示され、顧客は AI 機能とガバナンス機能を利用して、あらゆるモデルを本番稼働させることができます。これには、モデルのサービングからファインチューニングまでのエンドツーエンドのモデル開発機能に加え、Unity Catalogのセキュリティ機能と管理機能も含まれています。
これにより、パートナーやサプライヤーと、はるかにアジャイルなデータ交換パターンを構築でき、結合データからこれまで以上に迅速に価値を引き出すことが可能になります。
Delta Sharingによる第三者データライセンス供与
Delta Sharing により、企業は必要なガバナンスを確保しつつ、データ製品を簡単に収益化できます。
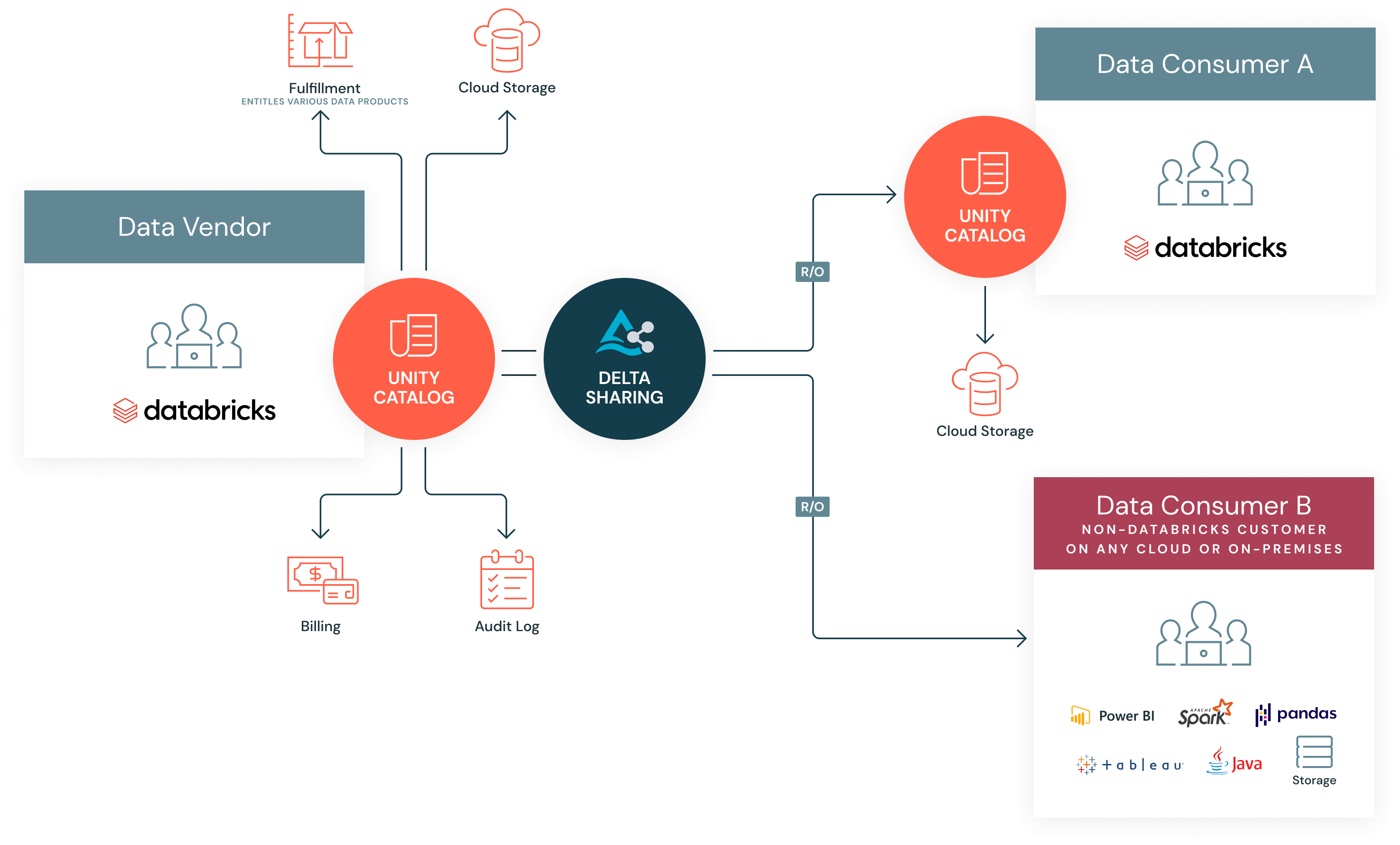
Delta Sharingは、データプロバイダーがサードパーティのデータやAIモデルのライセンス供与を行い、収益化する能力を大幅に向上させました。これにより、プロバイダーは、従来の SFTP サーバーにありがちなスケーラビリティの問題なしに、大規模なデー��タセットをシームレスに共有できるようになります。データ製品ごとに専用のサービスを必要とする API サービスとは異なり、Delta Sharing では、プロバイダーはデータを複製することなくデータ受信者へのアクセスを許可および管理できるため、プロセスが簡素化されます。共有の際に、データを複数コピーする必要はありません。共有中にデータの移動がないため、データ プロバイダーはストレージの重複を回避し、利用者が遅延なく最新のデータにアクセスできることを保証します。ELT/ETL パイプラインから出力されるデータはすべて、データ製品になる可能性があります。従来、データプロバイダーは、すべてのパートナーや顧客にリーチするために、さまざまなプラットフォームとの複雑なインテグレーションを構築する必要がありました。クロスクラウドおよびクロスプラットフォーム共有により、データプロバイダーは、複雑な統合を必要とせずに、クラウド、プラットフォーム、リージョンを越えて消費者へと市場リーチを拡大できます。
Databricks Marketplace は、これらの機能をさらに強化します。Databricks Marketplaceは、データとAI製品を交換するためのオープンなフォーラムとして機能し、Delta Sharingを活用してデータコンシューマーに安全な共有と簡単なアクセスを提供します。プロバイダーは、Databricks Marketplaceでデータセット、AIモデル、ノートブック、およびソリューションアクセラレータを公開し、より幅広いオーディエンスがアクセスできるようにすることができます。このプラットフォームは公開リスティングとプライベート エクスチェンジの両方に対応しており、プライベート エクスチ�ェンジでは、承認されたユーザーにのみリスティングが共有されます。
Databricks Marketplaceと統合することで、Delta Sharingは消費者の知見獲得までの時間を短縮し、プロバイダーが新規購入者にリーチして販売サイクルを加速させることを可能にします。堅牢な Databricks Marketplace のインフラストラクチャにより、プロバイダーは Delta Sharing のオープンプロトコルを通じてセキュリティとガバナンスの標準にコンプライアンスしつつ、自社のオファリングを効果的に紹介できます。
コストに関する懸念を軽減するため、Delta Sharing では、データへの許可されたアクセスをすべて追跡する監査ログを保持しています。データプロバイダーは、この情報を使用して、いずれかのデータ製品に関連するコストを判断し、そうした製品が商業的に実行可能で妥当なものかどうかを評価できます。さらに、Delta Sharing はデータ複製の必要性をなくすことで、コストを最小限に抑えます。このプロトコルは、エグレス料金のかからないストレージ ソリューションである Cloudflare R2 との統合もサポートしているため、クロスリージョンやクロス クラウドでのデータ共有コストをさらに削減できます。
Delta Sharing の仕組み
Delta Sharingは、データからより多くの価値を引き出すことを真剣に考えている組織のために、シンプル、スケーラブル、非プロプライエタリで、費用対効果の高いソリューションとして設計されています。Delta SharingはUnity Catalogとネイティブに統合されており、お客様はきめ細かいガバナンスとセキュリティ制御を追加することで、内部または外部でデータを簡単かつ安全に共有できます。
Delta Sharing は、クラウド上のデータセットに対するアクセスをセキュアに共有するシンプルな REST (Representational state transfer) API を利用したプロトコルです。AWS S3、Azure ADLS、Google GCS などの最新のクラウド ストレージ システムを活用して、大規模なデータセットへの読み取り専用アクセスを確実に許可します。データプロバイダーとデータ受信者向けの仕組みは次のとおりです。
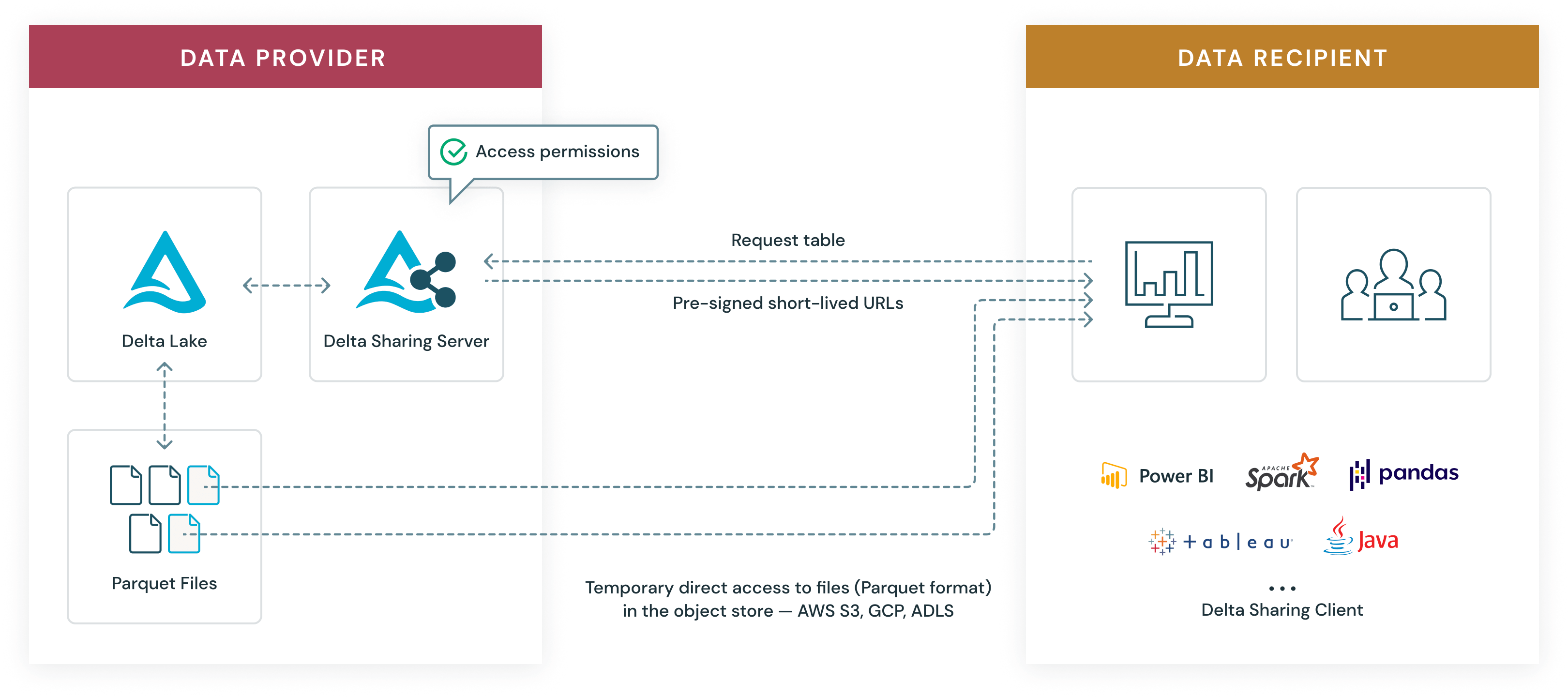
データプロバイダ
データプロバイダーは、クラウド データレイクに保存されている既存のテーブルまたはその一部(特定のテーブル バージョンやパーティションなど)を Delta Lake 形式で共有します。データ提供者は共有したいデータを決定し、Delta Sharing プロトコルを実装するシェアリングサーバーを稼働させ、受領者のアクセス権を管理します。シェアと受信者を管理するには、SQL コマンド、Unity Catalog CLI、または直感的なユーザー インターフェイスを使用できます。
データ受信者
データ受信者は、プロトコルをサポートしている多数のDelta Sharingクライアントのいずれか1つを必要とするだけです。Databricksは、pandas、Apache Spark、Java、Python用のオープンソース コネクタをリリースしており、パートナーと協力してさらに多くのコネクタを開発しています。
データ交換
Delta Sharing のデータ交換は、3 つの効率的なステップで行われます:
- 受信者のクライアントは共有サーバーで認証を行い、特定のテーブルに対するクエリーを要求します。サブセットのデータを読み取れるように、データに対するフィルター(例:“country=US”)を指定することも可能です。
- シェアリングサーバーは、クライアントがデータに対してアクセス権を有しているかを検証し、リクエストを記録して、どのデータを返すのかを決定します。これは、テーブルを構成するクラウド ストレージ システム内のデータ オブジェクトのサブセットになります。
- データに一時的にアクセスできるように、サーバーは、クライアントがクラウド プロバイダーから直接 Parquet ファイルを読み取れる、有効期間の短い事前署名付き URL を生成します。これにより、共有サーバー経由でストリーミングすることなく、大規模な帯域幅で並列に読み取り専用アクセスが可能になります。
Databricks Marketplace のご紹介
企業には、データとAIのためのオープンなコラボレーションが必要です。組織内または外部でのデータ共有により、企業はパートナーと協業し、新たなパートナーシップを構築し、データ収益化によって新たな収益源を生み出すことができます。
生成AIへの需要が業界全体で破壊的変革を促進しており、自社のサービスを差別化するために独自のデータに基づいて生成AIモデルや大規模言語モデル(LLM)を構築することが、技術チームにとって急務となっています。
従来のデータ マーケットプレイスは制限されており、データやシンプルなアプリケーションしか提供しないため、データ コンシューマーにとっての価値が限られています。また、基本的な説明や例以外にデータアセットを評価するツールは提供していません。最後に、データの配信は制限されており、多くの場合、ETL または独自の配信メカニズムが必要になります。
企業には、柔軟で安全、かつビジネス価値を生み出す、より良いデータとAIの共有方法が必要です。エコシステムは、強力なデータ共有とコラボレーションを可能にします。
データ マーケットプレイスには多くの課題があり、データ利用者とデータ提供者の両方にとって連携が複雑になることがあります。
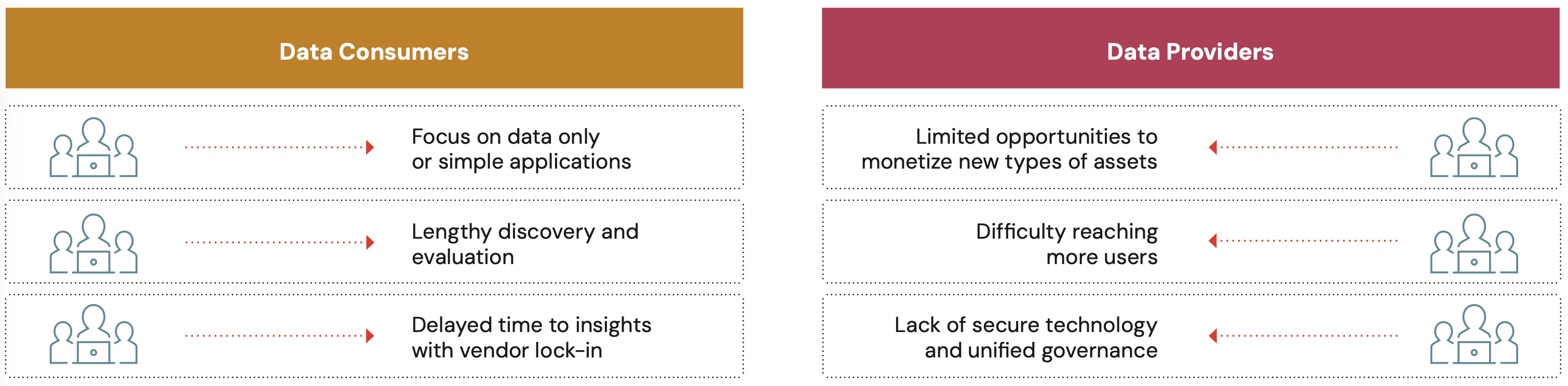
今日のデータマーケットプレイスにおける課題
| データコンシューマ | データプロバイダ |
|---|---|
| データのみ、またはシンプルなアプリケーションに限定: データセットにしかアクセスできない場合、AI と Machine Learning の活用を目指す組織は、他のソリューションを探すかゼロから始める必要があり、ビジネス 知見 の獲得が遅れる原因となります。 | 新しい��タイプのアセットを収益化する機会が限られる: データのみのアプローチでは、組織はデータセット以外のものを収益化することに限定され、互換性のないプラットフォームで新しい収益機会を創出する際に、より多くの困難に直面します。 |
| 時間のかかる発見と評価: ほとんどのマーケットプレイスがデータコンシューマのデータ評価用に提供するツールは、単なる説明や SQL ステートメントのサンプルにすぎません。評価ツールが最小限であると、データ 製品が自分に適しているかどうかを見極めるのに時間がかかり、プロバイダとのやり取りに時間を費やしたり、まったく新しいプロバイダを探したりする必要が生じる可能性があります。 | より多くのユーザーにリーチする際の難しさ: データ プロバイダは、ビジネス チャンスを逃すか、データを複製するための費用を負担するかの二者択一を迫られます。 |
| ベンダー ロックインによる知見を得るまでの時間の遅延:独自の共有テクノロジーや FTP を介した配信では、ベンダー ロックインが起きるか、あるいはデータを業務で利用するために必要な場所に配置するのに時間のかかる ETL プロセスが必要になります。 | 安全なテクノロジーと統一されたガバナンスの欠如: プラットフォームやクラウドをまたいでデータを安全に共有するためのオープン スタンダードがないと、データ プロバイダは散在するデータへのアクセスを保護するために複数のツールを使用する必要があり、結果としてガバナンスに一貫性がなくなります。 |
Databricks Marketplace とは?
Databricks Marketplaceは、Delta Sharingを利用した、あらゆるデータ、アナリティクス、AIのためのオープンなマーケットプレイスです。
Databricks MarketplaceはDelta Sharingを基盤としているため、ベンダーロックインされることなく、オープンソースの柔軟性を活かして、あらゆるプラットフォーム、クラウド、リージョンにわたってコラボレーションできます。このオープンなアプローチにより、任意のツールを利用して、あらゆるクラウドで、より迅速にデータを活用できます。
Databricks Marketplaceは、プラットフォームへの依存、複雑なETL、高価なレプリケーション、ベンダーロックインを伴うことなく、データ利用者とデータプロバイダーの広大なエコシステムを結びつけ、多種多様なデータセットにわたるコラボレーションを可能にします。
Databricks MarketplaceはAIモデルの共有もサポートしており、ユーザーはOSSモデルと独自(自社製およびサードパーティ製)のAIモデルの両方にアクセスできます。これにより、データの利用者と提供者は、AI モデルを見つけて収益化し、自社のデータソリューションに AI を統合できるようになります。
Databricks Marketplace は、AI21 Labs、John Snow Labs、OLA Krutrim、Bitext といった外部プロバイダーが提供する、事前トレーニング済みの生成 AI モデル、大規模言語モデル (LLM)、業界特化型モデルをはじめ、多種多様な AI アセットを提供しています。これらのモデルは、そのまま使用することも、特定のユースケースに合わせてカスタムデータでファインチューニングすることもできます。
Databricks Marketplace の主なメリット
Databricks MarketplaceはDelta Sharingを基盤としているため、ベンダーロックインのないオープンソースの柔軟性を活用し、あらゆるプラットフォーム、クラウド、リージョンでコラボレーションできます。このオープン マーケットプレイスは、データ利用者とデータ提供者からなる広大なエコシステムを結びつけ、プラットフォームへの依存、複雑なETL、高価なレプリケーション、ベンダー ロックインなしで、多種多様なデータセットにわたるコラボレーションを可能にします。
データだけでなく、プロバイダーはAIモデルを収益化できます。消費者は、ビジュアライゼーションやサンプルデータを含む事前構築済みのノートブックなど、リッチなプレビューでAIモデルを評価できます。消費者はボタンをクリックするだけで、AI モデルをインストールできます。これらはすべて、Databricks Data Intelligence PlatformのAI機能により、リアルタイム推論とバッチ推論の両方において、すぐに機能します。

Databricks Marketplaceに関する、データプロバイダーとデータコンシューマーからの声をご紹介します。
Dun & Bradstreetは、Databricks Marketplaceでグローバルなデータセットへのリアルタイムアクセスを提供します
「信頼できる最新のデータは、情報に基づいた意思決定の根幹です。」Dun & Bradstreetのデータセットと分析的知見が持つ力、そしてDatabricks Marketplaceのオープン性、拡張性、セキュリティは、組織がビジネス目標の達成を加速させるために、必要な時に必要な場所でデータの力を活用するための強固な基盤を提供します。"—ジニー・ゴメス、Dun & Bradstreet 北米担当社長
HealthVerityは、Databricks Marketplaceで非識別化された医療データを提供します。
"Databricks とのパートナーシップを深め、Databricks Marketplace を通じて当社のプレゼンスを拡大できることを嬉しく思います。"この協業により、製薬会社、政府機関、医療機関をはじめとするお客様は、国内最大のリアルワールドヘルスケアデータエコシステムが提供する包括的で匿名化されたヘルスケアデータに、かつてないほど簡単にアクセスできるようになります。これにより、科学的発見を加速させ、画期的な医療成果を達成できるようになります。私たちは共に、ヘルスケアデータのプライバシー、ガバナンス、相互運用性に関する新たな標準を打ち立てています」—アンドリュー・クレス、HealthVerity CEO
The Trade Desk は、Databricks Marketplace を通じてファーストパーティデータを活用できる��機能を、初めてお客様に提供します。
「Databricksとのパートナーシップは、顧客がデジタルメディアバイイングにおいてデータを活用する方法に革命をもたらし、リアルタイムの知見を利用して、より効果的な広告キャンペーンを展開する能力を高めます。」データブリックス Delta Sharingのオープンなエコシステムと、データブリックス Data Intelligence Platformの強力な予測分析機能を、The Trade Deskの業界をリードする広告テクノロジーと統合することで、マーケターはキャンペーンを最適化し、これまでにないレベルの精度と効率を達成できるようになります。"—Jay Goebel、The Trade Desk、データパートナーシップ担当バイスプレジデント
Shutterstockの画像データセットが、Databricks Marketplaceで利用できるようになりました
"Shutterstockは、オープンデータとAIのコラボレーションを促進するプラットフォームとして名高いDatabricks Marketplaceに、10億点近くに及ぶ膨大なクリエイティブコンテンツアセットを提供します。"この統合により、倫理的に調達されたビジュアル コンテンツの広範なライブラリに比類のないアクセスが可能となり、さまざまな業界における責任ある AI と機械学習の取り組みを推進します。データ配信方法として新たに Delta Sharing が加わりました。Databricks上の当社の豊富なデ�ータセットをご活用いただくことで、お客様は新たな機会を開拓し、製品イノベーションを加速させ、競争優位性を確保できます。"—エイミー・イーガン、Shutterstock 最高エンタープライズ責任者
Databricks Marketplace は、イノベーションを推進し、収益機会を拡大します。
データコンシューマ
データ消費者にとって、Databricks Marketplaceはイノベーションを実現し、アナリティクスとAIの取り組みを推進する機会を劇的に拡大します。
データ以上の発見: データセットに加え、AI モデル、ノートブック、アプリケーション、ソリューションなども利用できます。
データ製品をより迅速に評価: 事前構築済みのノートブックとサンプルデータを使用すると、データ製品を迅速に評価し、それがお客様の AI やアナリティクス の取り組みに適しているという、より大きな確信を持つことができます。最速かつ最もシンプルな知見までの時間を実現できます。
ベンダーロックインの回避: クラウド、リージョン、プラットフォームを横断してオープンかつシームレスに共有やコラボレーションを行うことで、知見を提供するまでの時間を大幅に短縮し、ロックインを回避します。任意のツールに、場所を問わず直接統合できます。
データプロバイダ
データプロバイダーにとって、Databricks Marketplaceは新しいユーザーへのリーチと新たな収益機会の創出を可能にします。
あらゆるプラットフォームでユーザーにリーチ: プラットフォームを横断してリーチを拡大し、ウォールドガーデンの枠を越えて巨大なエコシステムにアクセスできます。レプリケーションを行うことなく、あらゆるクラウドやリージョンへのシンプルなデータ共有の配信を効率化します。
データ以上のものを収益化: データセット、ノートブック、AI モデルをはじめとする、最も広範なデータアセットを収益化することで、より多くのデータ利用者にアプローチできます。
データを安全に共有: あらゆるデータセット、ノートブック、AI モデル、ダッシュボードなどを、クラウド、リージョン、データ プラットフォームをまたいで安全に共有できます。
コラボレーションを促進し、イノベーションを加速します
急速に成長するエコシステムが原動力です
データブリックス マーケットプレイスは、最も急成長しているデータ マーケットプレイスです。サービス開始以来、小売、通信、メディア & エンターテイメント、金融サービスなどの業界でパートナーを増やし続けており、当社のオープン Marketplace では 250 社以上のプロバイダーによる 2,500 件以上のリスティングを探索できます。
オープン Marketplace のユースケース
あらゆる業界の組織には、単純な(データセットの結合)ものから、より高度な(AIノートブック、アプリケーション、ダッシュボード)ものまで、サードパーティデータを利用・共有するための多くのユースケースがあります。

広告と小売
買い物客の行動分析を組み込む | 広告のリフト/パフォーマンス | 需要予測 | 「次の最適 SKU」予測 | 在庫分析 | リアルタイムの気象データ

財務
証券取引所のデータを組み込んで経済的影響を予測 | 市場調査 | 国勢調査や住宅の公開データから保険の売上を予測

医療・ライフサイエンス
ゲノム標的の特定 | 患者リスクスコアリング | 創薬の加速 | 商業的有効性 | 臨床研究
Databricks Marketplace の詳細については、marketplace.databricks.com をご覧ください。
Databricksクリーンルームによるプライバシーを強化した共有
データドリブンのイノベーションを実現するための外部データへの需要がかつてないほど高まる一方で、組織の間ではデータプライバシーに対する懸念も高まっています。組織がパートナーや顧客と、安全で管理され、プライバシーを重視した方法でデータを共有し、連携する必要性が、「データ クリーンルーム」という概念の原動力となっています。
データクリーンルームとは何ですか?
データクリーンルームは、参加者が機密データを持ち寄って、その非公開データについて共同分析を行うことができる、安全で管理され、プライバシーが強化された環境を提供します。参加��者はデータに対する全権限を持ち、基礎となる機密データを開示することなく、どの参加者がどの分析を実行できるかを決定できます。
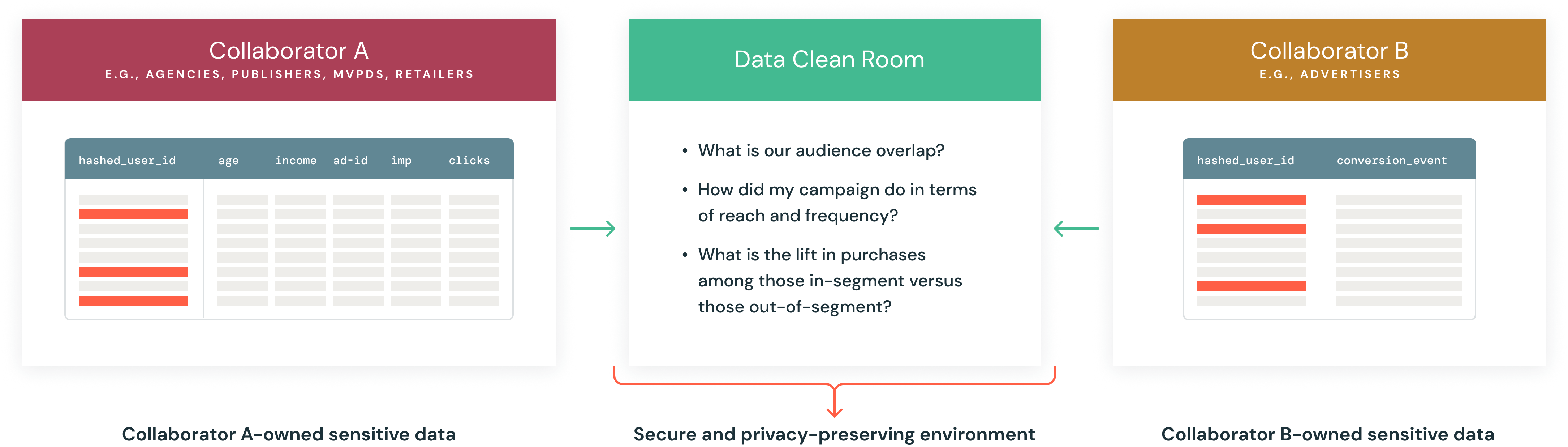
組織がプライバシーに準拠した方法でデータを共同利用する方法を模索するなか、データクリーンルームが再び注目を集めています。この傾向は、データの収集、使用、共有の方法を大きく変えた、GDPR や CCPA のような厳格なデータプライバシー規制によって推進されています。
データクリーンルームへの関心が高まっているにもかかわらず、企業のデータコラボレーションはまだ初期段階にあります。2024 IDC External Data Sourcing and Collaboration Survey によると、データクリーンルームの使用を開始した企業は全体の 3 分の 1 に過ぎず、そうした企業が連携しているデータ コラボレーション パートナーは 1~2 社のみです。多くの組織は、データクリーンルームを導入する際に、テクノロジーとデータマネジメントに関する重大な課題に直面します。企業の約56%が、共有されるデータの取り扱いに関するプライバシーや同意について懸念を抱いています。
一般的なデータクリーンルームのユースケース

メディアとエンターテイメント向けのキャンペーン最適化
クリーンルーム環境を構築することで、メディア企業は広告主のファーストパーティデータと自社のオーディエンスデータを組み合わせ、その価値を安全に引き出すことができます。これにより、個々のユーザー情報に直接アクセスしたり公開したりすることなく、詳細な分析を行い、共通のオーディエンス セグメントとキャンペーン後の測定を特定できます。

ヘルスケアのためのリアルワールドエビデンス(RWE)
クリーンルームは、コラボレーターがデータプライバシーを損なうことなく複数のデータソースに接続してクエリーを実行できるよう、ヘルスケア データセットへの安全なアクセスを提供します。これは、規制当局による意思決定、安全性、臨床試験デザイン、観察研究などの RWE ユースケースをサポートします。

小売および消費財のサプライチェーン最適化
クリーンルームは、小売業者とサプライヤー間のリアルタイムなコラボレーションを可能にし、需要予測、在庫計画、サプライチェーン最適化のための安全な情報交換を実現します。これにより、両者にとって製品の可用性が向上し、コストが削減され、業務が効率化されま��す。

銀行業務におけるKYC(Know Your Customer)
KYC基準は、金融詐欺、マネーロンダリング、テロ資金供与を防止するためのものです。特定の法域内において、金融サービス会社はクリーンルームを使用し、協力して共有アナリティクスを実行することで、調査のために取引の全体像を構築できます。

拡張された興味関心による小売業者向けのパーソナライゼーション
クリーンルームにより、小売業者は消費者に関する知識を拡充し、個人に関連性がありながらまだ購入されていない新しい商品やサービスを提案できるようになります。
既存のデータクリーンルームの欠点
クリーンルームの選択肢を検討している組織は、既存のソリューションには、「クリーンルーム」という概念のポテンシャルを完全に引き出すことを妨げる、明白な欠点がいくつかあることを見出しています。
まず、多くの既存のデータクリーンルームベンダーは、データが同じクラウド、同じリージョン、および/または同じデータプラットフォーム上にあることを要求します。そのため参加者は、データを独自のプラットフォームに移動させる必要があり、結果としてロックインや追加のデータストレージコストが発生します。
第二に、既存のクリーンルームは、複雑な分析をサポートする柔軟性に欠けることが�多く、ほとんど SQL にしか対応していません。SQLは優れており、クリーンルームには不可欠ですが、その制約が、組織が高度な知見やイノベーションのためにデータを最大限に活用することを妨げる可能性があります。多様なワークロードを実行したり、AI/機械学習 フレームワークと統合したりできないため、価値ある知見を引き出すというデータクリーンルームの潜在的な応用が制限されてしまいます。
最後に、自動化が不足しているため、データクリーンルームの設定は複雑になる場合があります。この手動セットアップ プロセスは、立ち上げ時間の長期化と総所有コスト(TCO)の増大につながるため、組織がこれらのソリューションを迅速にデプロイしてスケールすることが困難になります。実装と保守にかかる高額な費用は、特に中小企業にとっては大きな障壁となり得ます。
Databricksクリーンルームによるプライバシーセーフなコラボレーション
Databricks Clean Roomsは、Delta Sharingを活用することで、プライバシーを侵害したり機密データを共有したりすることなく、あらゆるクラウドで顧客やパートナーとのコラボレーションを容易にします。クリーンルームでの共同作業では、データが移動することはなく、その使用場所や方法を常にお客様が管理できます。
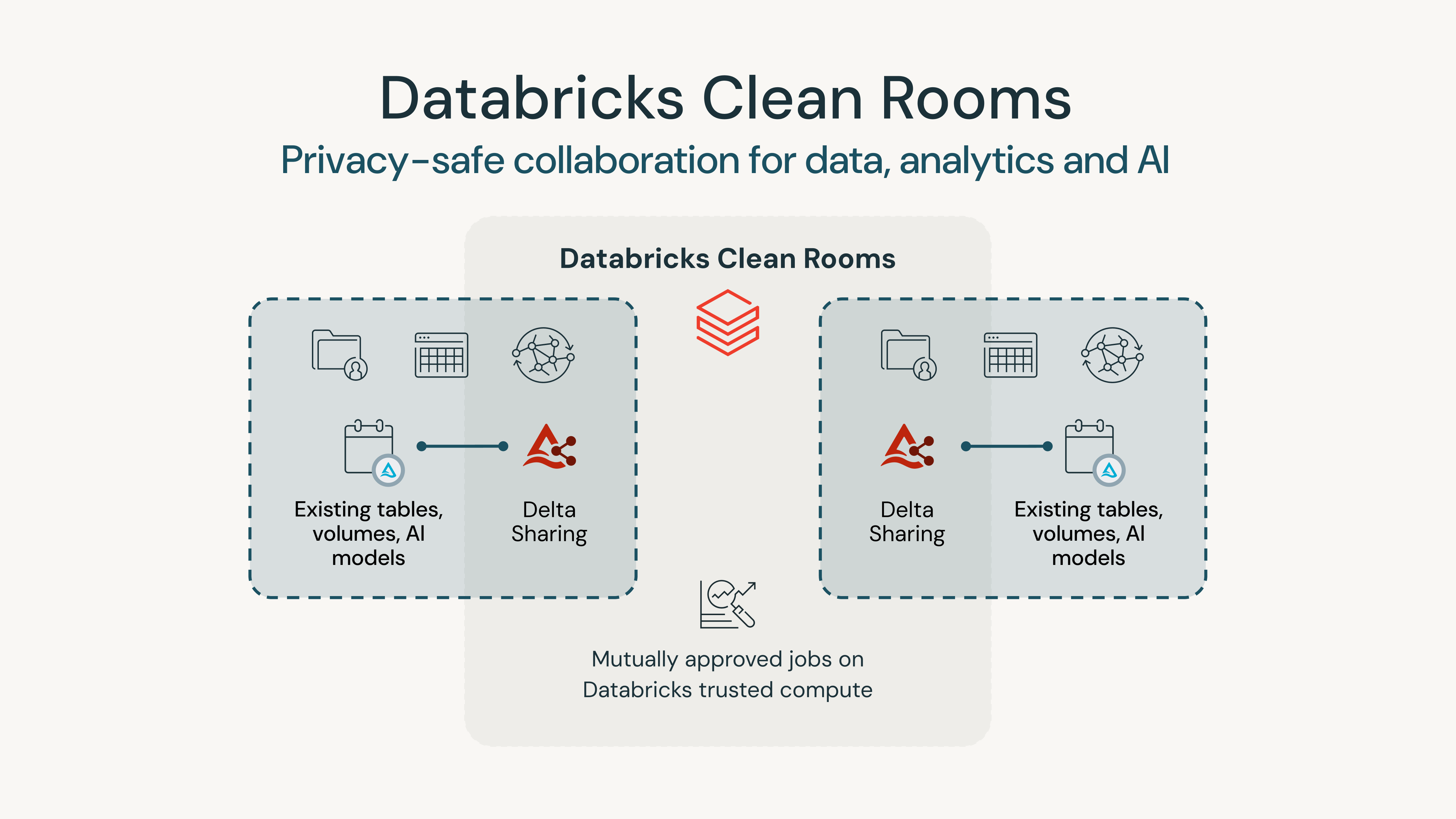
あらゆるクラウド、あらゆるプラットフォーム
Databricks Clean Roomsは、クラウドとプラットフォームを横断したコラボレーションのために構築されています。任意のクラウドとリージョンを選択して、クリーンルームを起動できます。データは元の場所に置いたままで、コピーする必要なくコラボレーションを行えます。Sharing for Lakehouse Federationを利用すると、Databricksのデータだけでなく、Databricks外部のソースデータでも共同作業ができます。Databricks Clean Roomsは、お客様を強力にサポートするとともに、共同作業者のデータがどこにあってもそのニーズに応えます。
あらゆる規模、あらゆる信頼レベル
Databricks Clean Roomsはスケーラブルであり、API、SQLコマンド、組み込みのワークフロー オーケストレーションを使用して、プライバシーセーフなワークロードの自動化をサポートします。また、ノートブックやUnity CatalogでDatabricks Clean Roomsの出力に簡単にアクセスし、他のワークロードで利用することもできます。Databricksクリーンルームは、異なる承認モードを使用することで、信頼レベルの異なる複数のパーティによるコラボレーションもサポートします。
あらゆる言語、あらゆるワークロード
データクリーンルームを使用して共同作業を行う場合、複数の組織の参加者が実行する必要のあるタスクは多様であるため、さまざまなプログラミング言語が不可欠になります。例えば、SQLはデータのクエリや操作に優れている一方、PythonはMachine Learningや統計分析に適しています。Scala と Java は、スケーラブルなデータ処理アプリケーションを構築するためによく使用されます。Databricks Clean Rooms の多言語サポートにより、ユーザーは単純なデータ結合から複雑な 機械学習/AI 計算まで、特定のワークロードに最適な言語を選択できます。Databricks クリーンルームは、生のコンテンツのプライバシーを保護しながら、あらゆる形式のデータとAIモデルに関するコラボレーションをサポートします。Databricks Notebooks の全機能を活用し、複雑なコンピュートや 機械学習/AI ワークロードのために SQL や Python を実行できます。今後、さらに多くの言語に対応予定です。
「Mastercardは、お客様のニーズと現実の課題を解決する新しい知見で、業界をリードしています。」「これらの知見は、企業の最大の資産となりうるデータに基づいています」と、Mastercard の最高データ責任者であるアンドリュー・ライスキン氏は述べました。「そのため、私たちはデータを使用する際に、そのデータの機密性、プライバシー、セキュリティをどのように保護するかを常に検討しています。」Databricks Clean Roomsは、当社のデータと技術に関する責任原則に沿って情報を保護しながら、トレンドの可視性を確保できるソリューションです。Databricks Clean Roomsは、お客様が知見と付加価値サービスを創出するための、新しい革新的な機会を提供します。Databricks と提携し、両方のフレームワークのパイロット運用を行い、柔軟性、拡張性、透明性を提供する統合された一連の PET 機能を開発しました。"—Andrew Reiskind、Mastercard 最高データ責任者
全体の仕組み
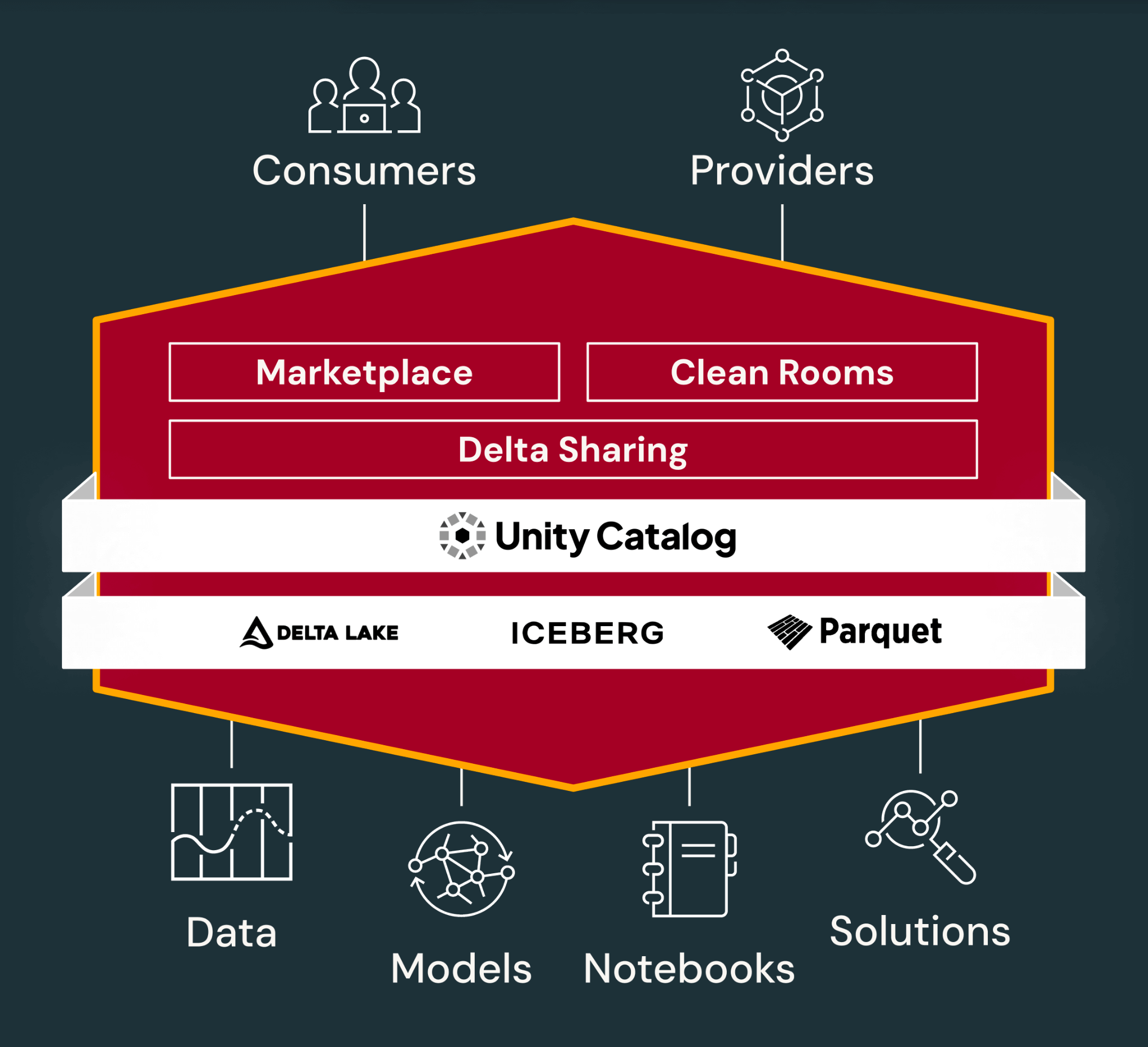
これらはすべて、共有とコラボレーションのために構築された Databricks Data Intelligence Platform で可能になります。Databricks Platform におけるデータ共有とコラボレーションは、ガバナンス (Unity Catalog) とストレージレイヤー (Delta Lake、Iceberg、Parquet) を基盤として構築されています。
本書で先に説明したように、Databricks Marketplaceは、あらゆるデータ、アナリティクス、AIのためのオープンなマーケットプレイスです。Databricks Clean Room を使用することで、企業はあらゆるクラウド上の顧客やパートナーと、プライバシーが保護された安全な環境で簡単に共同作業を行うことができます。どちらもDelta Sharingを利用しています。そして、これらすべては Unity Catalog によってセキュリティ保護され、管理されます。
Delta SharingとUnity Catalogの統合により、データ共有の安全性とガバナンスが確保され、コンプライアンスとプライバシーの要件が満たされます。Unity Catalogは、データ共有のための一元化されたガバナンスとセキュリティを提供します。これにより、組織は共有データの使用状況を管理、監査、追跡し、セキュリティ要件と規制要件へのコンプライアンスを確保できます。
Delta Lake、Apache Iceberg、Parquet は、さまざまな業界で効率的なデータ共有とコラボレーションを可能にする基盤テクノロジーです。
Databricksは、データエンジニア、データサイエンティスト、ビジネスアナリストに必要な機能を単一のプラットフォームに統合することで、個別のツールを使用することに伴う複雑さと非効率性を解消します。この統一されたアプローチは、幅広いデータ分析と AI タスクに対応します。
業界を横断したデータ共有
データ共有は、さまざまな業界にわたり、イノベーション、効率性、コラボレーションを促進する重要な要素となっています。主な例をいくつか紹介します。
- 小売: データ共有は、小売業者が天候、イベント、価格設定などのさまざまなソースからのデータを統合し、パーソナライズされたマーケティングの提供やサプライチェーンの最適化を行うことで、統一された顧客ビューの作成に役立ちます。また、サプライヤーとのリアルタイムのコラボレーションを促進し、在庫管理の改善と応答時間の短縮を実現します。
- 金融サービス: 規制コンプライアンスが最重要である業界では、データ共有によって AML (マネーロンダリング対策) や KYC (顧客確認) といった規制のためのタイムリーかつ正確な報告が可能になります。データにリアルタイムでアクセスすることで、コンプライアンス要件を満たす際の透明性と効率性が向上します。
- ヘルスケアとライフサイエンス: データ共有は、電子カルテ(EHR)、保険請求、ウェアラブル デバイスからの臨床データを組み合わせることで、Patient 360 のようなイニシアチブを推進します。この包括的な視点によって患者の治療成果が向上し、ヘルスケアエコシステム全体でより良い連携が可能になります。データ共有は、ライフサイエンス企業が臨床試験の管理された環境を超え、日常診療において治療法がどのように機能するかを理解するためのリアルワールドエビデンス(RWE)にとって、非常に高い関連性があります。
- 製造業:産業製造では、予知保全と資産の最適化のためにデータ共有が不可欠です。サプライヤーと機器のパフォーマンスデータを安全に共有することで、メーカーは故障を事前に予測し、生産ライン全体の効率向上を推進できます。
- エネルギー: データ共有は、多様なデータソースを統合することで、排出量の追跡とカーボンオフセットの検証をサポートします。これにより、エネルギー企業は機密情報を損なうことなく、資産パフォーマンスを最適化し、持続可能性に関する取り組みで協力できます。
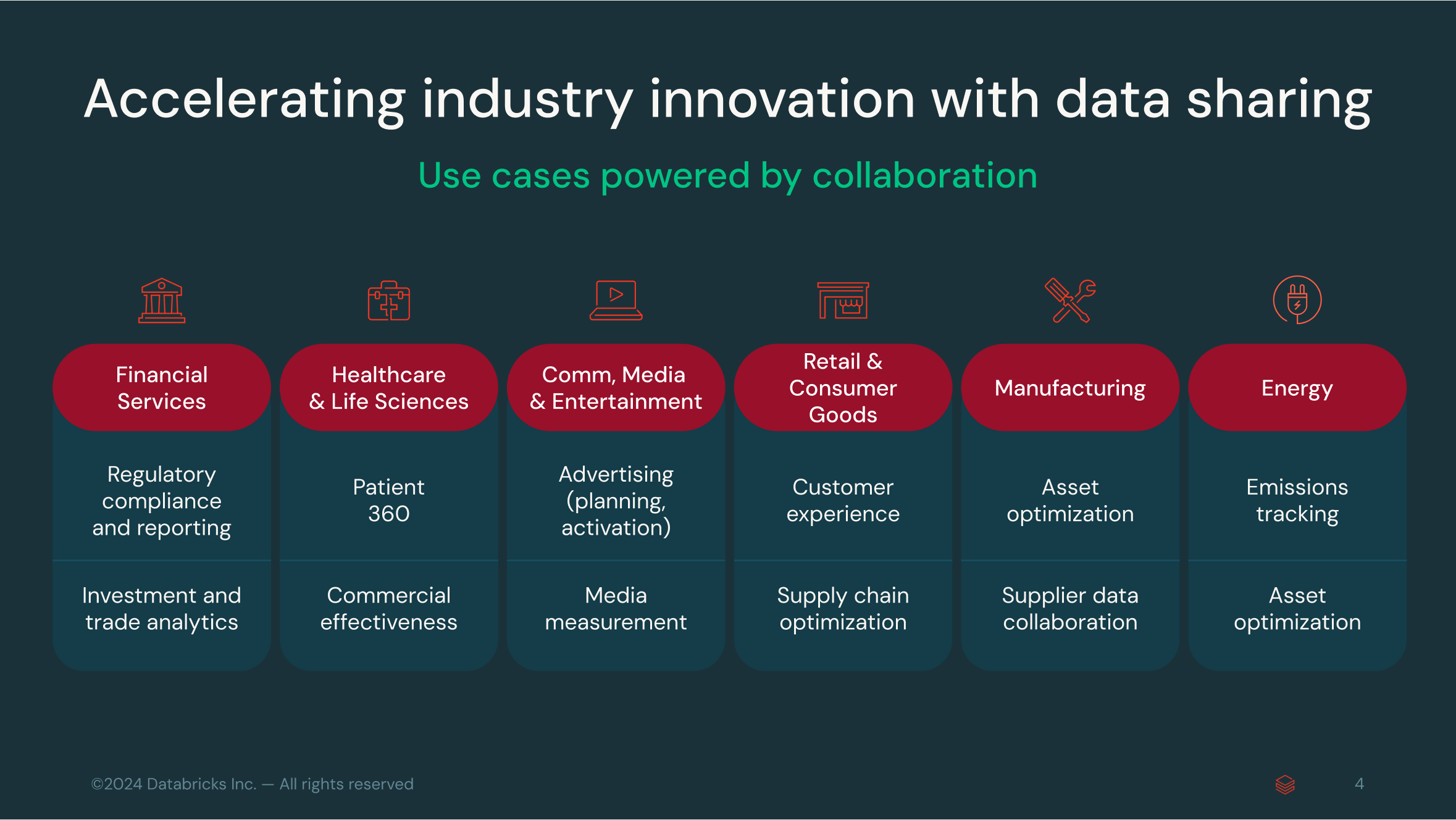
これらの分野において、安全性とプライバシーを確保したデータ共有は、業務の変革、意思決定の向上、そして関係者間のより深い連携の促進につながっています。
データ共有とコラボレーションの始め方
データ共有は、製品開発や社内業務からカスタマーエクスペリエンス、コンプライアンスに至るまで、企業全体のビジネスプロセスにおいて重要な役割を果たします。しかし、システム間の非互換性、複雑さ、セキュリティ上の懸念により、ほとんどの企業で導入が遅れています。
データドリブンな組織には、オープンかつ安全にデータを共有するアプローチが必要です。Delta Sharing は、制限や追加費用を課すことなく、このニーズに応えます。史上初のオープンプロトコルで、データセットを安全に共有するためのオープンスタンダードです。Delta Sharingを使用すると、組織はデータを移動することなく、Apache Parquet、Iceberg、Delta Lakeなどのオープンソース形式に基づいた既存の大規模データセットを簡単に共有できます。Databricks Marketplaceは、データだけでなく、AIモデル、ノートブック、Solution AcceleratorなどのAIおよび分析アセットを交換するためのオープンプラットフォームを提供することで、これを拡張しています。Databricks Clean Roomsは、生データを公開することなく、複数のパーティが機密データでコラボレーションするための、安全でプライバシーセーフな環境を提供します。
- プラットフォーム間での共有: ライブデータセット、AI モデル、ノートブックを、プラットフォーム、クラウド、リージョンをまたいで共有できます。このオープンなアプローチは、安全なデータ共有のための世界初のオープンプロトコルである Delta Sharing によって実現されており、組織はあらゆるユースケース、ツール、クラウドでデータを共有できます。
- すべてのデータとAIを共有:Databricks Marketplaceは、すべてのデータ、アナリティクス、AIのためのオープンなマーケットプレイスであり、データコンシューマーとデータプロバイダーの両方がイノベーショ��ンを実現し、アナリティクスとAIのイニシアチブを推進できるようにします。
- 安全に共有: Databricks Clean Rooms を使用すると、企業はあらゆるクラウド上で顧客やパートナーと、プライバシーを保護した方法で簡単にコラボレーションできます。Delta Sharing を使用すると、クリーンルームの参加者は、クラウドやリージョンを越えてデータを複製することなく、自社のデータレイクからデータを安全に共有できます。お客様のデータはベンダー ロックインされることなく手元に留まり、その使用状況を一元的に監査、監視できます。
以下のリソースを活用して、これらの製品を使い始めましょう。
Delta Sharing
- データ共有 | Databricks
- Databricks Unity Catalog について学ぶ
- ブログ記事:レイクハウスでのデータ共有とコラボレーションの最新情報
- オープンソースのDelta Sharingについて学ぶ
- レイクハウスのデータ共有�とコラボレーションの新機能
- AWS のドキュメント
- Azure のドキュメント
Databricks Marketplace
- Databricks Marketplace について学ぶ
- Databricks Marketplace をチェック
- 動画: Databricks Marketplace — データとアプリケーションの先へ
- デモ:Databricks Marketplace
- AWS ドキュメント: Databricks Marketplace とは
- Azure ドキュメント: Databricks Marketplace とは
Databricks Clean Room
- Databricksクリーンルームについて学ぶ
- レイクハウスのデータ共有とコラボレーションの新機能
- eBook:データクリーンルームの完全ガイド
- ウェビナー:クリーンルームを活用し、セキュアなデータ コラボレーションの力を引き出す
- 製品ツアー
著者について
Vuong NguyenはDatabricksのSolutions Architectであり、Databricks Data Intelligence Platformの力を活用して、お客様がアナリティクスとAIをシンプルに利用できるようにすることに注力しています。ヴオンへはLinkedInでご連絡いただけます。
Somasekar Natarajan (Som) is a Solutions Architect at Databricks specializing in enterprise データマネジメント.ソムは、顧客がデータの力を活用できるよう支援するという唯一の目的を掲げ、20年近くにわたり3大陸にまたがるフォーチュン企業と協業してきました。Som さんには LinkedIn で連絡できます。
Harish Gaur は、データ共有およびコラボレーションチームの製品マーケティング担当ディレクターです。彼は、Databricks Marketplace、Databricks Delta Sharing、Databricks Clean Rooms のプロダクト マーケティング、およびデータ パートナー マーケティング活動を推進しています。Harish さんには LinkedIn で連絡できます。
ジェイ・バンカリアは、Databricksのデータパートナーシップチームのシニアディレクターです。彼の情熱は、顧客がデータから知見を引き出し、アナリティクスニーズに合わせて Databricks Data Intelligence Platform のパワーを活用できるよう、サポートすることです。ジェイにはLinkedInで連絡できます。
Sachin Thakurは、Databricks のデータ エンジニアリングおよびアナリティクス チームのプリンシパル 製品マーケティング マネージャーです。彼の専門分野はUnity Catalogによるデータガバナンスであり、Databricksデータインテリジェンスプラットフォームを用いて、組織がデータとAIを民主化できるよう支援することに情熱を注いでいます。サチンにはLinkedInで連絡できます。
Giselle Goicocheaは、Databricksのデータエンジニアリングおよびアナリティクスチームのシニアプロダクトマーケティングマネージャーです。彼女の専門分野は LakeFlow Connect によるデータ取り込みであり、顧客がデータから価値を引き出し、イノベーションを加速できるよう支援することに専念しています。ジゼルにはLinkedInで連絡できます。
Kelly Albano は、Databricks のデータ エンジニアリングおよびアナリティクス チームのプロダクト マーケティング マネージャーです。彼女の専門分野は、セキュリティ、コンプライアンス、および Databricks Clean Rooms です。ケリーにはLinkedInで連絡できます。
データブリックスについて
Databricks は、グローバルで唯一のデータ & AI 企業です。現在、ブロック、コムキャスト、コンデナスト、リヴィアン、シェルをはじめ、フォーチュン 500 企業の 60% 以上を含む世界中の 10,000 を超える企業が、Databricks データインテリジェンスプラットフォームを利用して、データの管理と AI の活用を実現しています。Databricksは、レイクハウス、Apache Spark™、Delta Lake、MLflowの元の作成者によって設立され、サンフランシスコに本社を置き、世界中にオフィスを構えています。LinkedIn、X、Facebook での情報発信も行っております。ぜひご覧ください。
(このeBookはAI翻訳ツールを使用して翻訳されています) 原文はこちら

