Eine Implementierung eines CNN (Convolutional Neural Network) für die Fahrzeugklassifizierung
von Dr. Evan Eames und Henning Kropp
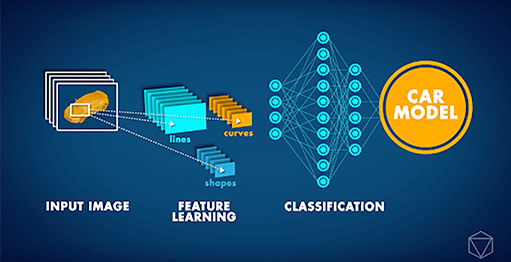
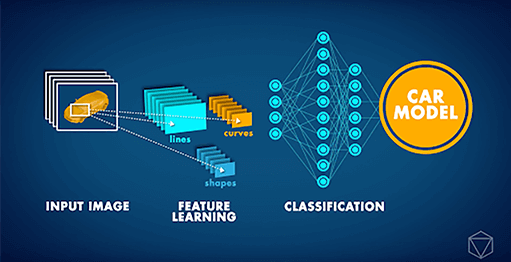
CNN (Convolutional Neural Networks) sind hochmoderne neuronale Netzwerkarchitekturen, die hauptsächlich für Aufgaben im Bereich des maschinellen Sehens eingesetzt werden. CNN kann für eine Reihe verschiedener Aufgaben eingesetzt werden, u. a. zur Bilderkennung, Objektlokalisierung und Änderungserkennung. Kürzlich erhielt unser Partner Data Insights eine anspruchsvolle Anfrage von einem großen Automobilhersteller: die Entwicklung einer Computer-Vision-Anwendung, die das Automodell auf einem bestimmten Bild erkennen kann. Wenn man bedenkt, dass verschiedene Automodelle ziemlich ähnlich aussehen können und jedes Auto je nach Umgebung und dem Winkel, aus dem es fotografiert wird, sehr unterschiedlich aussehen kann, war eine solche Task bis vor Kurzem einfach unmöglich.

Jedoch ermöglichte es die ‚Deep Learning Revolution‘ ab etwa 2012, ein solches Problem zu bewältigen. Anstatt dass ihnen das Konzept eines Autos erklärt wurde, konnten Computer stattdessen wiederholt Bilder studieren und solche Konzepte selbst lernen. In den letzten Jahren haben zusätzliche Innovationen bei künstlichen neuronalen Netzen zu einer KI geführt, die Bildklassifizierungs-Tasks mit menschenähnlicher Genauigkeit durchführen kann. Aufbauend auf solchen Entwicklungen konnten wir ein Deep CNN trainieren, um Autos nach ihrem Modell zu klassifizieren. Das neuronales Netz wurde mit dem Stanford Cars Dataset trainiert, das über 16.000 Bilder von Autos enthält, die 196 verschiedene Modelle umfassen. Im Laufe der Zeit konnten wir sehen, dass sich die Genauigkeit der Vorhersagen zu verbessern begann, als das neuronale Netz das Konzept eines Autos lernte und wie man zwischen verschiedenen Modellen unterscheidet.
{kind=link}
Gemeinsam mit unserem Partner haben wir eine durchgängige Machine Learning-Pipeline aufgebaut und dabei Apache Spark™ und Koalas für die Datenvorverarbeitung, Keras mit Tensorflow für das Modell-Training, MLflow für die Nachverfolgung von Modellen und Ergebnissen und Azure ML für die Bereitstellung eines REST-Dienstes verwendet. Dieses Setup in Azure Databricks ist für das schnelle und effiziente Trainieren von Netzwerken optimiert und hilft außerdem dabei, viele verschiedene CNN-Konfigurationen viel schneller auszuprobieren. Schon nach wenigen Testläufen erreichte die Genauigkeit des CNN etwa 85 %.
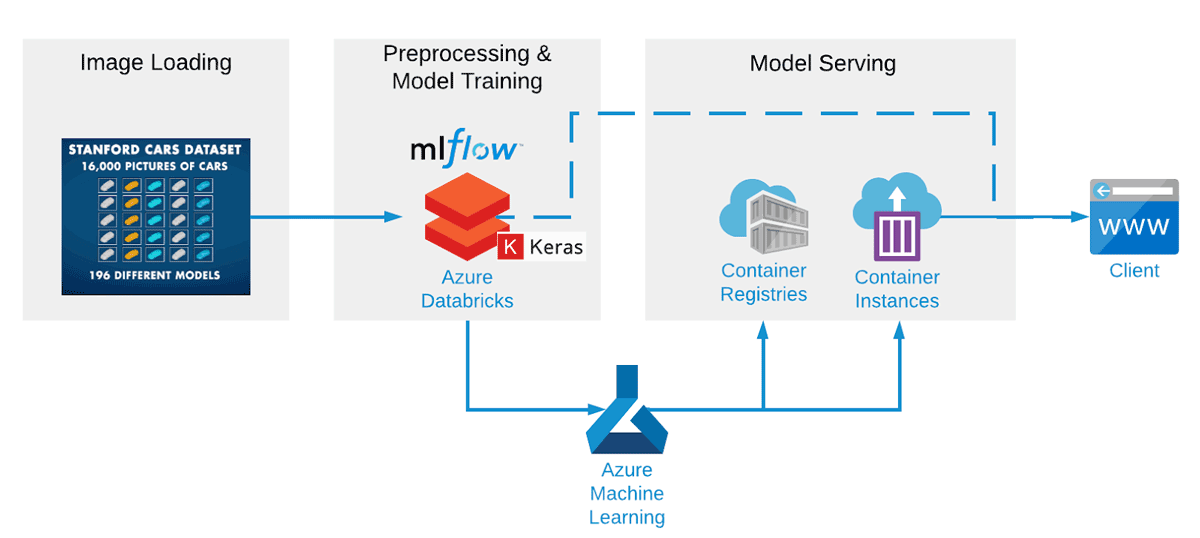
Einrichtung eines künstlichen neuronalen Netzes zur Klassifizierung von Bildern
In diesem Artikel skizzieren wir einige der wichtigsten Techniken, die verwendet werden, um ein neuronales Netz in die Produktion zu bringen. Wenn Sie das neuronale Netz selbst ausführen möchten, finden Sie unten die vollständigen Notebooks mit einem detaillierten Schritt-für-Schritt-Leitfaden.
Diese Demo verwendet den öffentlich verfügbaren Stanford Cars Dataset. Er ist einer der umfassenderen öffentlichen Datensätze, wenn auch etwas veraltet, sodass Sie keine Automodelle nach 2012 finden werden (obwohl nach dem Training durch Transfer-Learning problemlos ein neuer Datensatz eingesetzt werden könnte). Die Daten werden über ein ADLS Gen2-Speicher-Account bereitgestellt, das Sie in Ihren workspace einbinden können.

Im ersten Schritt der Datenvorverarbeitung werden die Bilder in hdf5 -Dateien komprimiert (eine für das Training und eine für das Testen). Diese können dann vom neuronalen Netz eingelesen werden. Dieser Schritt kann auf Wunsch vollständig weggelassen werden, da die hdf5-Dateien Teil des ADLS Gen2-Speichers sind, der als Teil der hier bereitgestellten Notebooks zur Verfügung gestellt wird.
- Laden des Stanford Cars-Datasets in HDF5-Dateien
- Verwenden Sie Koalas für die Bildaugmentation.
- Training des CNN mit Keras
- Modell als REST-Dienst in Azure ML bereitstellen
Bildaugmentation mit Koalas
Die Menge und Diversität der gesammelten Daten hat einen großen Einfluss auf die Ergebnisse, die mit Deep-Learning-Modellen erzielt werden können. Datenaugmentation ist eine Strategie, die die Lernergebnisse erheblich verbessern kann, ohne dass tatsächlich neue Daten gesammelt werden müssen. Mit verschiedenen Techniken wie Cropping, Padding und horizontalem Spiegeln, die häufig zum Trainieren großer neuronaler Netze verwendet werden, können die Datensätze künstlich aufgebläht werden, indem die Anzahl der Bilder für das Training und Testen erhöht wird.
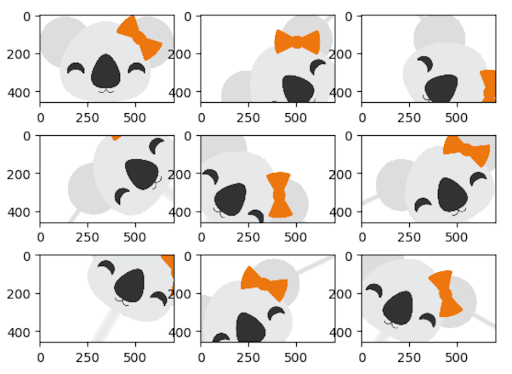
Die Anwendung von Augmentierung auf einen großen Korpus von Trainingsdaten kann sehr teuer sein, insbesondere beim Vergleich der Ergebnisse verschiedener Ansätze. Mit Koalas wird es einfach, bestehende Frameworks für die Bildaugmentation in Python auszuprobieren und den Prozess auf einem Cluster mit mehreren Knoten mithilfe der im Bereich Data Science bekannten Pandas-API zu skalieren.
Ein ResNet in Keras programmieren
Wenn man ein CNN zerlegt, besteht es aus verschiedenen ‚Blöcken‘, wobei jeder Block einfach eine Gruppe von Operationen darstellt, die auf Eingabedaten angewendet werden. Diese Blöcke lassen sich grob in folgende Kategorien einteilen:
- Identitätsblock: Eine Reihe von Operationen, die die Form der Daten beibehalten.
- Convolution-Block: Eine Reihe von Betriebe, die die Form der Eingabedaten zu einer kleineren Form reduzieren.
Ein CNN ist eine Reihe von sowohl Identity-Blöcken als auch Convolution-Blöcken (oder ConvBlocks), die ein Eingabebild auf eine kompakte Gruppe von Zahlen reduzieren. Jede dieser resultierenden Zahlen (wenn richtig trainiert) sollte Ihnen schließlich etwas Nützliches zur Klassifizierung des Bildes sagen. Ein Residual CNN fügt für jeden Block einen zusätzlichen Schritt hinzu. Die Daten werden als temporäre Variable gespeichert, bevor die Operationen, die den Block ausmachen, angewendet werden, und dann werden diese temporären Daten zu den Ausgabedaten hinzugefügt. Im Allgemeinen wird dieser zusätzliche Schritt auf jeden Block angewendet. Als Beispiel zeigt die folgende Abbildung ein vereinfachtes CNN zur Erkennung von handschriftlichen Zahlen:
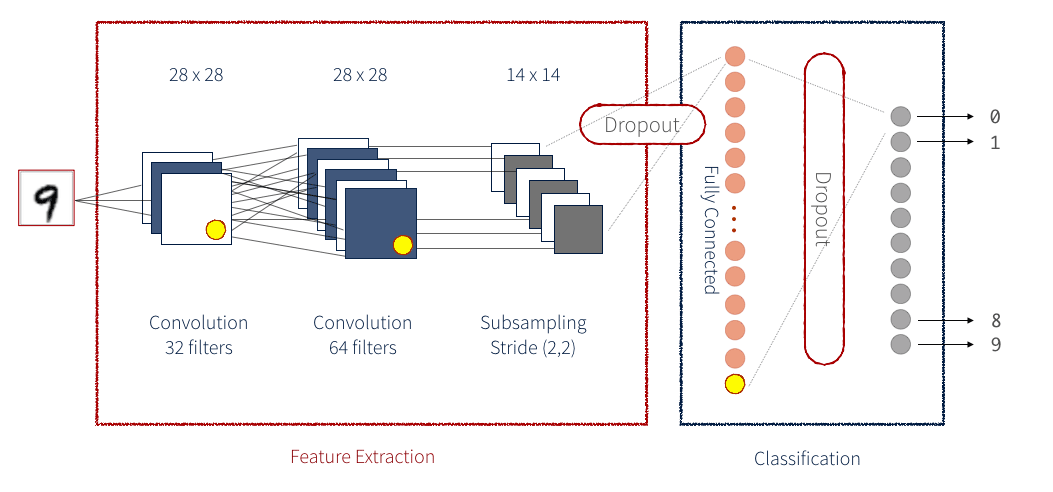
Es gibt viele verschiedene Methoden zur Implementierung eines neuronalen Netzwerks. Eine der intuitiveren Möglichkeiten ist über Keras. Keras bietet eine einfache Front-End-Bibliothek zur Ausführung der einzelnen Schritte, aus denen ein neuronales Netz besteht. Keras kann für die Verwendung mit einem Tensorflow -Back-End oder einem Theano-Back-End konfiguriert werden. Hier werden wir ein Tensorflow-Back-End verwenden. Ein Keras-Netzwerk ist, wie unten dargestellt, in mehrere Schichten unterteilt. Für unser Netzwerk definieren wir auch unsere benutzerdefinierte Implementierung einer Schicht.
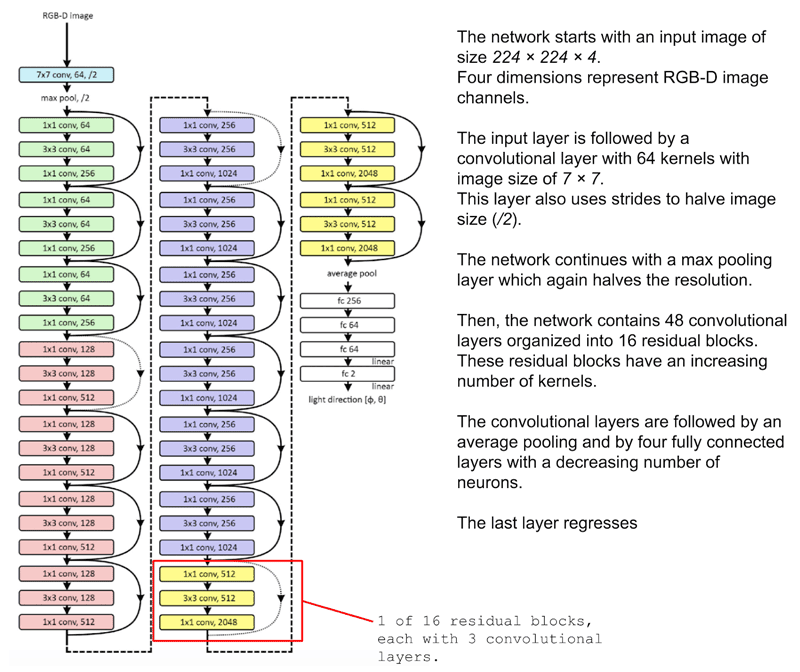
Die Scale-Schicht
Für jede benutzerdefinierte Operation mit trainierbaren Gewichten ermöglicht Ihnen Keras, Ihren eigenen Layer zu implementieren. Beim Umgang mit riesigen Mengen an Bilddaten kann es zu Speicherproblemen kommen. Ursprünglich enthalten RGB-Bilder Ganzzahldaten (0-255). Wenn man den Gradientenabstieg als Teil der Optimierung während der Backpropagation ausführt, stellt man fest, dass ganzzahlige Gradienten keine ausreichende Genauigkeit für die korrekte Anpassung der Netzwerkgewichte bieten. Daher ist es notwendig, auf Gleitkommagenauigkeit umzustellen. Hier können Probleme auftreten. Selbst wenn Bilder auf 224x224x3 herunterskaliert werden, ergeben sich bei zehntausend Trainingsbildern über 1 Milliarde Gleitkommaeinträge. Anstatt ein gesamtes Dataset in Fließkommapräzision umzuwandeln, empfiehlt es sich, einen ‘Scale Layer’ zu verwenden, der die Eingabedaten Bild für Bild und nur bei Bedarf skaliert. Dies sollte nach der Batch-Normalisierung im Modell angewendet werden. Die Parameter dieses Scale Layers sind ebenfalls Parameter, die durch Training gelernt werden können.
Um diese benutzerdefinierte Schicht auch während des Scorings zu verwenden, müssen wir die Klasse zusammen mit unserem Modell paketieren. Mit MLflow können wir dies mit einem Keras-Wörterbuch „custom_objects“ erreichen, das Namen (Strings) benutzerdefinierten Klassen oder Funktionen zuordnet, die mit dem Keras-Modell verbunden sind. MLflow speichert diese benutzerdefinierten Layer mithilfe von CloudPickle und stellt sie automatisch wieder her, wenn das Modell mit mlflow.keras.load_model() geladen wird. und mlflow.pyfunc.load_model().
Tracking von Ergebnissen mit MLflow und Azure Machine Learning
Die Entwicklung von Machine learning bringt zusätzliche Komplexitäten mit sich, die über die Softwareentwicklung hinausgehen. Dass es eine Vielzahl von Tools und Frameworks gibt, erschwert es, Experimente zu verfolgen, Ergebnisse zu reproduzieren und Machine-Learning-Modelle bereitzustellen. Zusammen mit Azure Machine Learning kann man den End-to-End-Lebenszyklus des maschinellen Lernens beschleunigen und verwalten, indem man MLflow verwendet, um Anwendungen für maschinelles Lernen mit Azure Databricks zuverlässig zu erstellen, zu teilen und bereitzustellen.
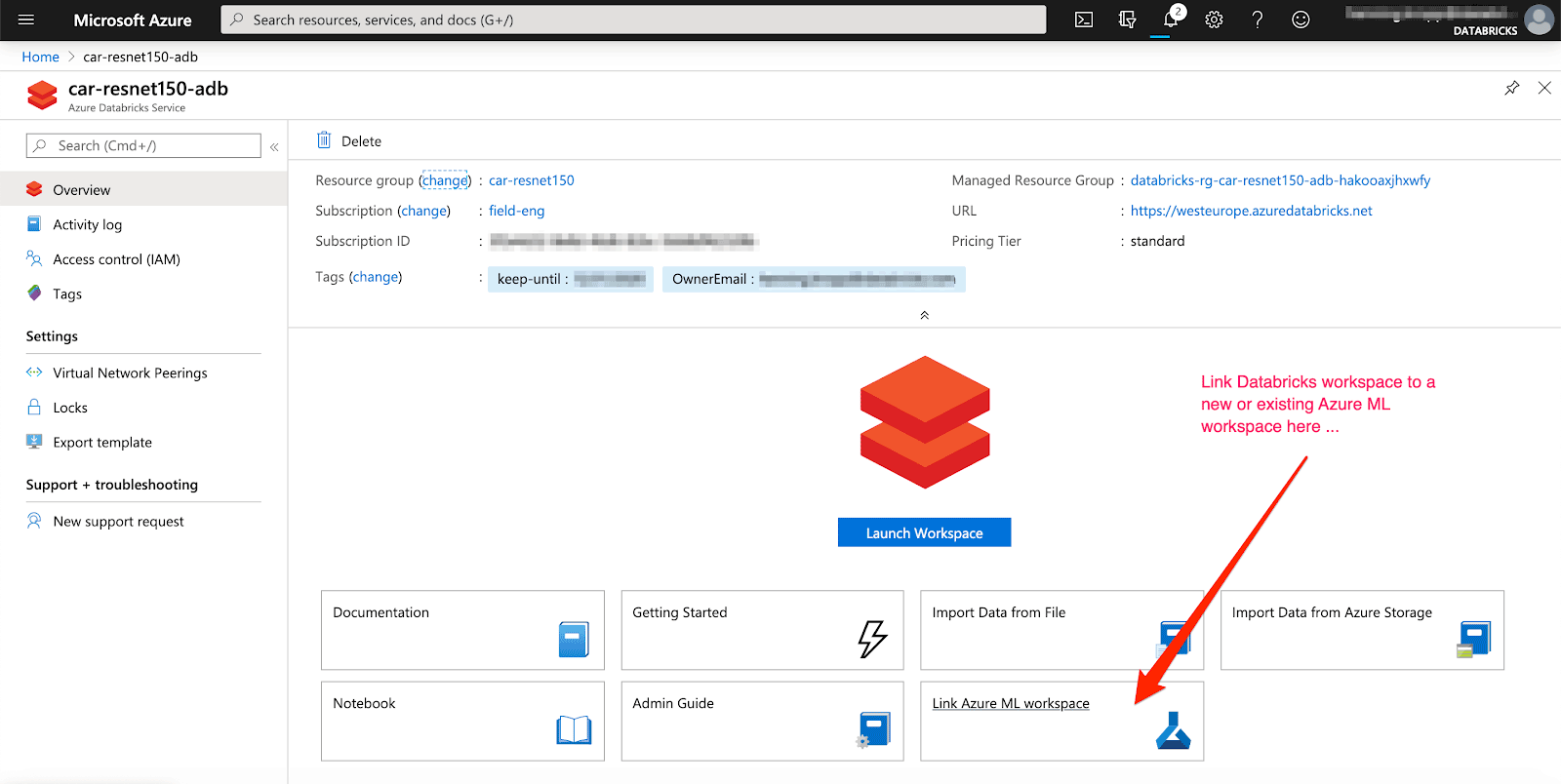
Um Ergebnisse automatisch zu verfolgen, kann ein bestehender oder neuer Azure ML workspace mit Ihrem Azure Databricks workspace verknüpft werden. Zusätzlich unterstützt MLflow die automatische Protokollierung für Keras-Modelle (mlflow.keras.autolog()), was die Erfahrung fast mühelos macht.
Obwohl die integrierten Dienstprogramme zur Modellpersistenz von MLflow für das Paketieren von Modellen aus verschiedenen beliebten ML-Bibliotheken wie Keras praktisch sind, decken sie nicht jeden Anwendungsfall ab. Zum Beispiel möchten Sie vielleicht ein Modell aus einer ML-Bibliothek verwenden, das nicht explizit von den integrierten Flavors von MLflow unterstützt wird. Alternativ möchten Sie vielleicht benutzerdefinierten Inferenzcode und Daten paketieren, um ein MLflow-Modell zu erstellen. Glücklicherweise bietet MLflow zwei Lösungen, mit denen sich diese Tasks erledigen lassen: Custom Python Models und Custom Flavors.
In diesem Szenario möchten wir sicherstellen, dass wir eine Modellinferenz-Engine verwenden können, die die Verarbeitung von Anforderungen von einem REST-API-Client unterstützt. Dafür verwenden wir ein benutzerdefiniertes Modell, das auf dem zuvor erstellten Keras-Modell basiert, um ein JSON-Dataframe-Objekt zu akzeptieren, das ein Base64-codiertes Bild enthält.
Im nächsten Schritt können wir dieses py_model verwenden und es auf einem Azure Container Instances -Server bereitstellen, was durch die Azure ML-Integration von MLflow erreicht werden kann.
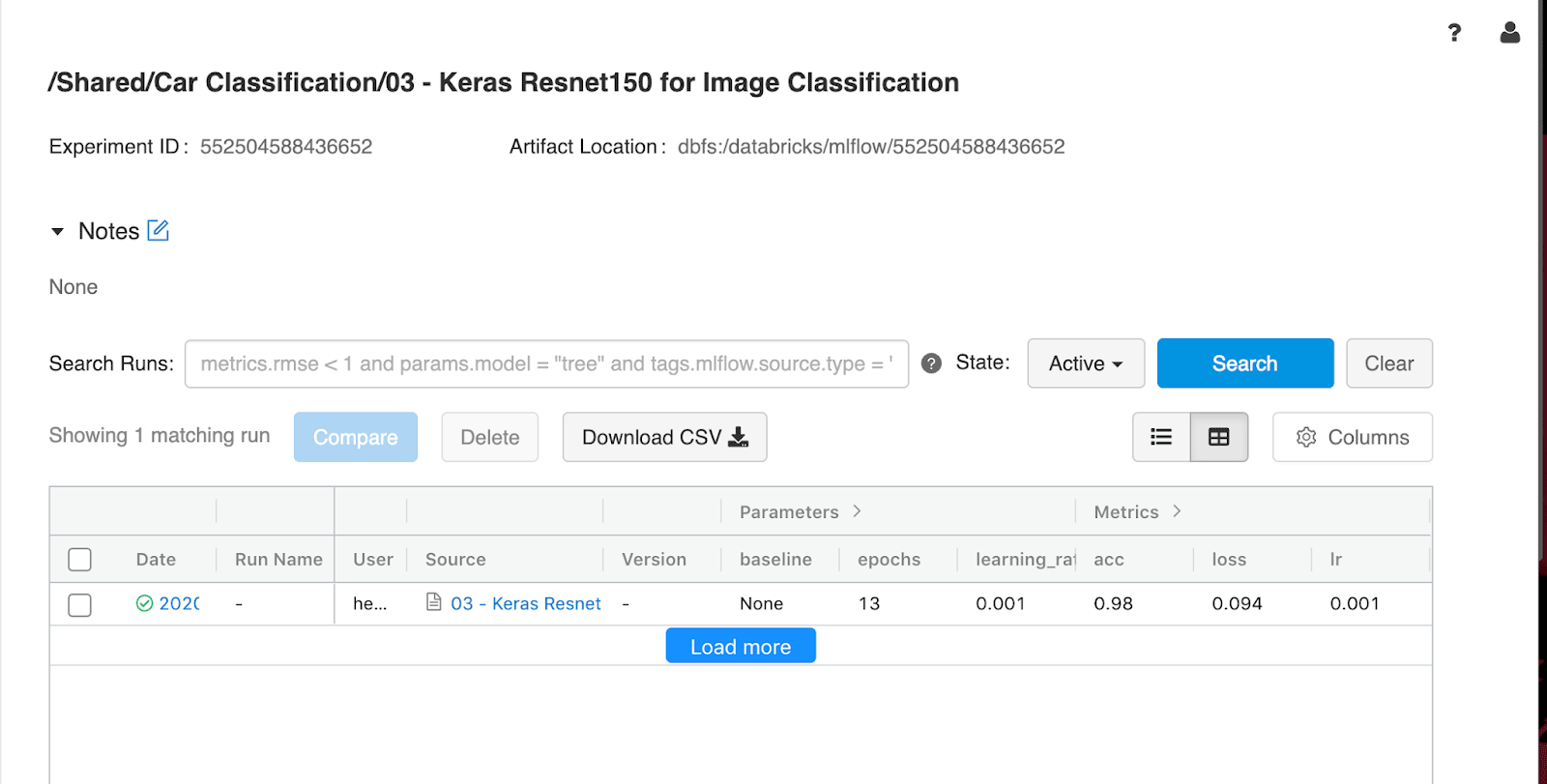
Bereitstellen eines Bildklassifizierungsmodells in Azure Container Instances
Wir haben jetzt ein trainiertes Machine-Learning-Modell und haben mit MLflow ein Modell in unserem workspace in der Cloud registriert. Als letzten Schritt möchten wir das Modell als Webdienst in Azure Container Instances bereitstellen.
Ein Web-Dienst ist ein Image, in diesem Fall ein Docker-Image. Es kapselt die Bewertungslogik und das Modell selbst. In diesem Fall verwenden wir unsere benutzerdefinierte MLflow-Modelldarstellung, die uns die Kontrolle darüber gibt, wie die Bewertungslogik Bilder von einem REST-Client verarbeitet und wie die Antwort geformt wird.
Container Instances ist eine hervorragende Lösung zum Testen und Verstehen des Workflows. Für skalierbare Produktionsbereitstellungen ziehen Sie die Verwendung von Azure Kubernetes Service in Betracht. Weitere Informationen finden Sie unter Anleitung zur Bereitstellung.
Erste Schritte mit der CNN-Bildklassifizierung
Dieser Artikel und die zugehörigen Notebooks zeigen die wichtigsten Techniken für die Einrichtung eines End-to-End-Workflows für das Training und die Bereitstellung eines neuronalen Netzes in der Produktion auf Azure. Die Übungen des verlinkten Notebooks führen Sie durch die erforderlichen Schritte zur Erstellung in Ihrer eigenen Azure Databricks -Umgebung mit Tools wie Keras, Databricks Koalas, MLflow und Azure ML.
Ressourcen für Entwickler
- Notebooks
- Video: https://www.youtube.com/watch?v=mxEqcIbPqPs
- GitHub: https://github.com/EvanEames/Cars
- Folien: https://www.slideshare.net/jonbros/deep-learning-with-databricks
- PDF: https://github.com/EvanEames/Cars/blob/master/CNN_howto.pdf
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.