Einführung in Apache Spark 3.0
Jetzt in Databricks Runtime 7.0 verfügbar
von Matei Zaharia, Reynold Xin, Xiao Li, Wenchen Fan und Yin Huai
Wir freuen uns, bekannt zu geben, dass das Apache SparkTM 3.0.0 Das Release ist auf Databricks als Teil unserer neuen Databricks Runtime 7.0 verfügbar. Die 3.0.0 Release über 3.400 Patches enthält, den Höhepunkt der enormen Beiträge aus der Open Source-Community darstellt und wichtige Fortschritte bei den Python- und SQL-Funktionen sowie einen Fokus auf die Benutzerfreundlichkeit für Exploration und Produktion bringt. Diese Initiativen zeigen, wie sich das Projekt entwickelt hat, um mehr Anwendungsfälle abzudecken und ein breiteres Publikum anzusprechen, wobei es in diesem Jahr sein 10-jähriges Jubiläum als Open-Source-Projekt feiert.
Hier sind die wichtigsten neuen Features in Spark 3.0:
- 2-fache Performanceverbesserung bei TPC-DS gegenüber Spark 2.4, ermöglicht durch adaptive Query execution, dynamic partition pruning und andere Optimierungen
- ANSI-SQL-Compliance
- Wesentliche Verbesserungen bei den pandas-APIs, einschließlich Python Type-Hints und zusätzlicher pandas-UDFs
- Bessere Python-Fehlerbehandlung, Vereinfachung von PySpark-Ausnahmen
- Neue UI für strukturiertes Streaming
- Bis zu 40-fache Beschleunigung beim Aufrufen von benutzerdefinierten R-Funktionen
- Über 3.400 Jira-Tickets abgeschlossen
Für die Übernahme dieser Version von Apache Spark sind keine größeren Code-Änderungen erforderlich. Weitere Informationen finden Sie im Migrationsleitfaden.
Wir feiern 10 Jahre Entwicklung und Weiterentwicklung von Spark
Spark hat seinen Ursprung im AMPlab der UC Berkeley, einem Forschungslabor mit Schwerpunkt auf datenintensivem Computing. Forscher des AMPlab arbeiteten mit großen Internetunternehmen an deren Daten- und KI-Problemen. Dabei erkannten sie, dass diese Probleme bald alle Unternehmen mit großen und wachsenden Datenmengen betreffen würden. Das Team hat eine neue Engine entwickelt, um diese neuen Workloads zu bewältigen und gleichzeitig die APIs für die Arbeit mit Big Data für Entwickler deutlich zugänglicher zu machen.
Beiträge aus der Community erweiterten Spark schnell auf verschiedene Bereiche. Neue Funktionen für Streaming, Python und SQL kamen hinzu und diese Muster bilden heute einige der dominanten Anwendungsfälle für Spark. Diese kontinuierliche Investition hat Spark dorthin gebracht, wo es heute steht: als De-facto-Engine für Workloads in den Bereichen Datenverarbeitung, Data Science, Machine Learning und Datenanalyse. Apache Spark 3.0 setzt diesen Trend fort, indem es die Unterstützung für SQL und Python – die beiden heute am weitesten verbreiteten Sprachen mit Spark – erheblich verbessert sowie die Performance und Bedienbarkeit im übrigen Spark optimiert.
Verbesserung der Spark SQL-Engine
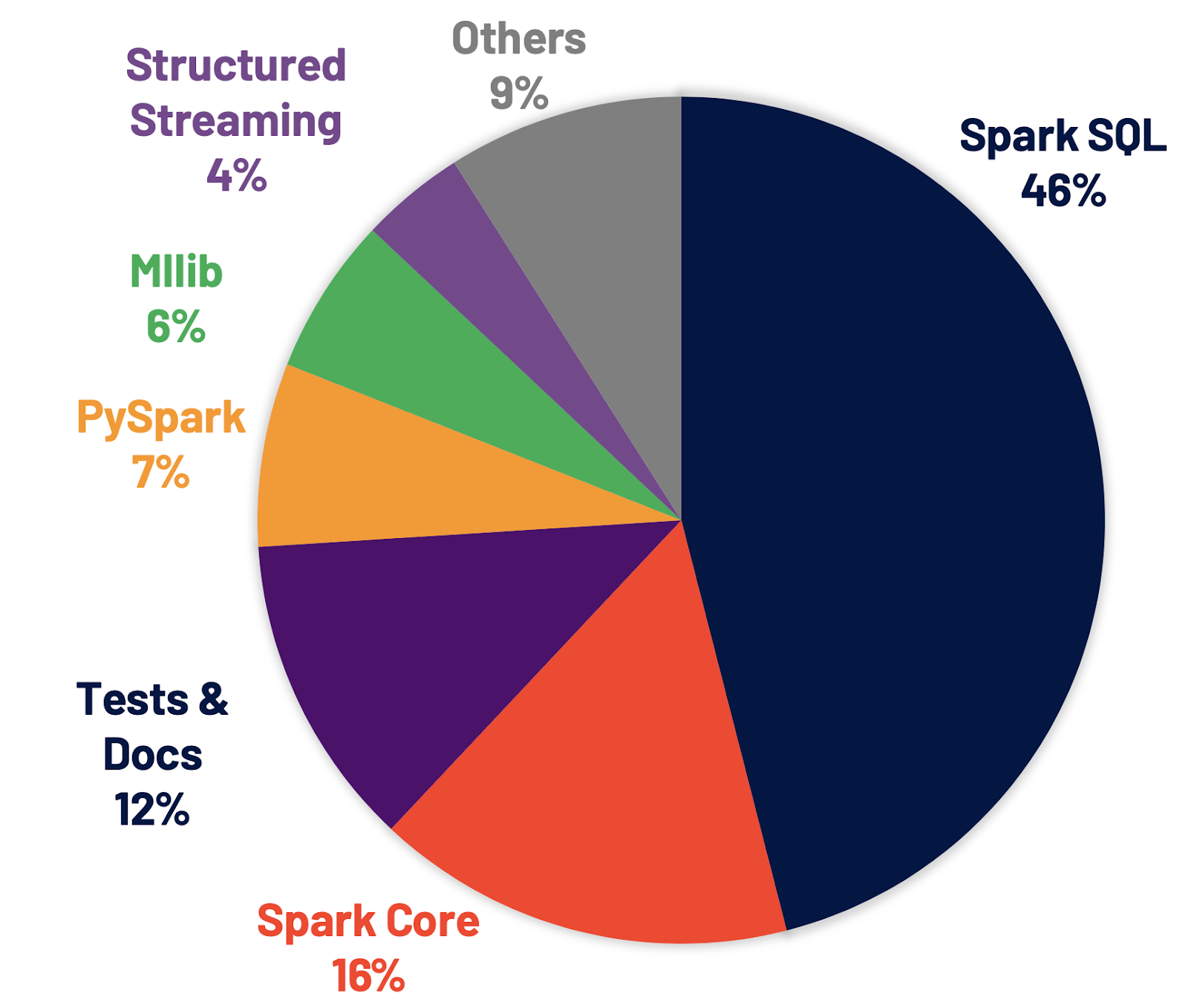
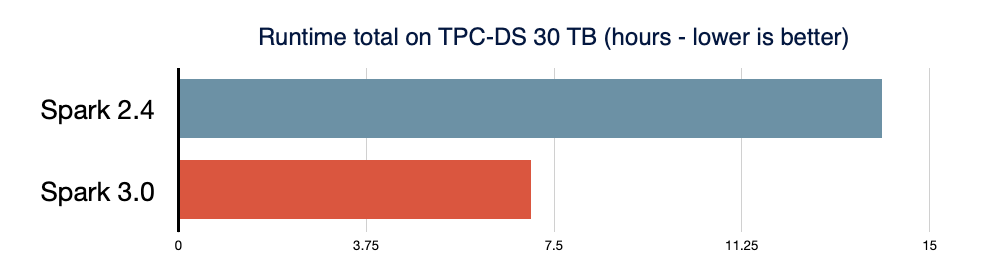
Spark SQL ist die Engine, die den meisten Spark-Anwendungen zugrunde liegt. Beispielsweise haben wir auf Databricks festgestellt, dass über 90 % der Spark-API-Aufrufe DataFrame-, Dataset- und SQL-APIs zusammen mit anderen vom SQL-Optimierer optimierten Bibliotheken verwenden. Das bedeutet, dass selbst Python- und Scala-Entwickler einen Großteil ihrer Arbeit über die Spark SQL-Engine laufen lassen. Im Spark 3.0-Release betrafen 46 % aller eingereichten Patches SQL, wodurch sowohl die Performance als auch die ANSI-Kompatibilität verbessert wurden. Wie unten dargestellt, war die Gesamt-Runtime von Spark 3.0 etwa doppelt so schnell wie die von Spark 2.4. Als Nächstes erläutern wir vier neue Features in der Spark SQL-Engine.
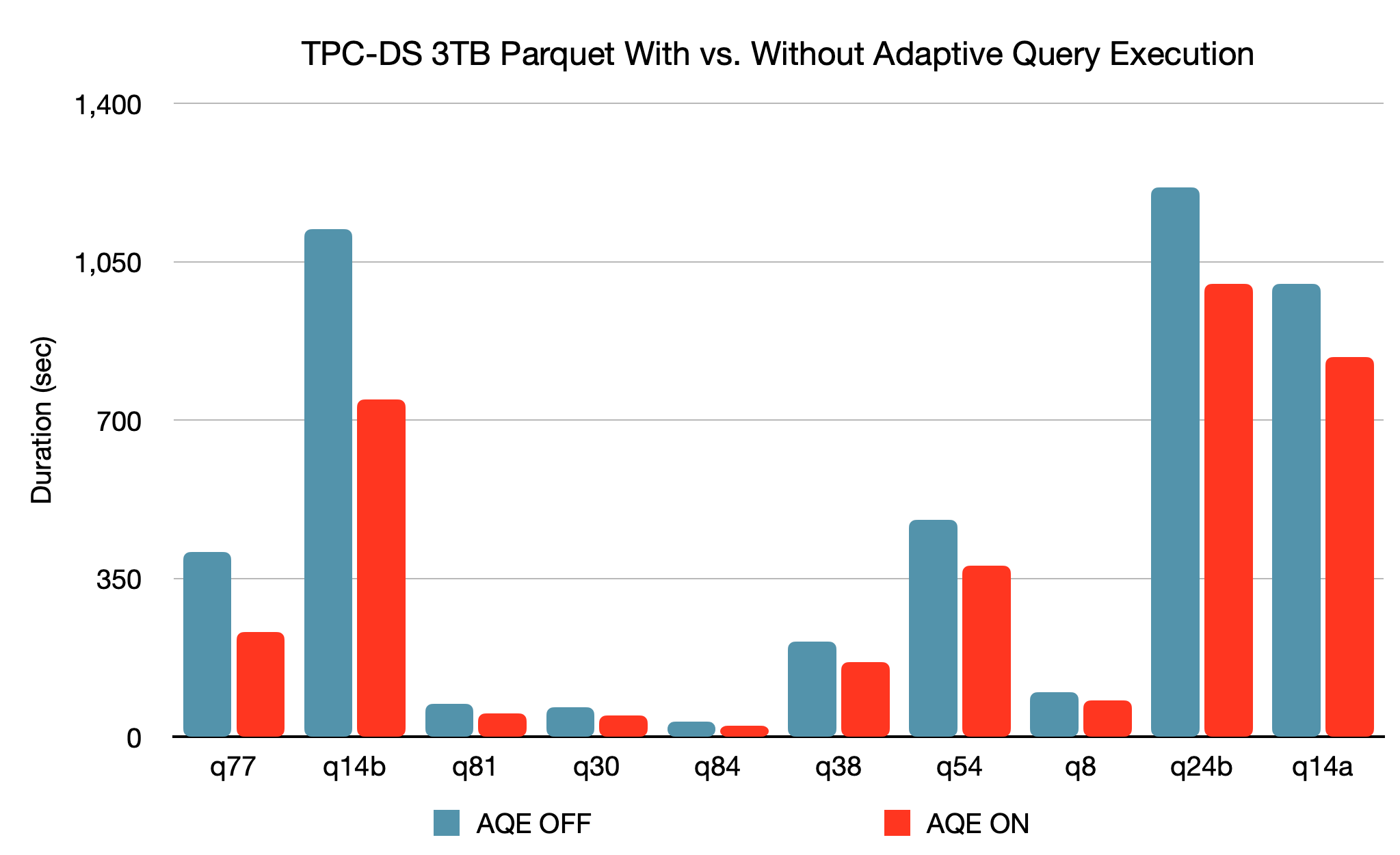
Das neue Framework Adaptive Abfrage Execution (AQE) verbessert die Performance und vereinfacht das Tuning, indem es zur Laufzeit einen besseren Ausführungsplan generiert, selbst wenn der ursprüngliche Plan aufgrund fehlender/ungenauer Datenstatistiken und falsch geschätzter Kosten suboptimal ist. Aufgrund der Trennung von Speicherung und compute in Spark kann der Dateneingang unvorhersehbar sein. Aus all diesen Gründen wird die Anpassungsfähigkeit zur Laufzeit für Spark wichtiger als für herkömmliche Systeme. Dieses Release führt drei wichtige adaptive Optimierungen ein:
- Dynamisches Zusammenführen von Shuffle-Partitionen vereinfacht oder vermeidet sogar das Abstimmen der Anzahl der Shuffle-Partitionen. Benutzer können zu Beginn eine relativ große Anzahl von Shuffle-Partitionen festlegen, und AQE kann dann zur Laufzeit benachbarte kleine Partitionen zu größeren zusammenfassen.
- Dynamisches Wechseln von Join-Strategien vermeidet teilweise die Ausführung suboptimaler Pläne aufgrund fehlender Statistiken und/oder falscher Größenschätzungen. Diese adaptive Optimierung kann zur Laufzeit automatisch einen Sort-Merge-Join in einen Broadcast-Hash-Join umwandeln, was das Tuning weiter vereinfacht und die Performance verbessert.
- Die dynamische Optimierung von Skew-Joins ist eine weitere entscheidende Performance-Verbesserung, da Skew-Joins zu einem extremen Arbeitsungleichgewicht führen und die Performance stark beeinträchtigen können. Nachdem AQE anhand der Shuffle-Dateistatistiken eine Datenschiefe erkennt, kann es die schiefen Partitionen in kleinere aufteilen und sie mit den entsprechenden Partitionen der anderen Seite Join. Diese Optimierung kann die Skew-Verarbeitung parallelisieren und eine bessere Gesamt-Performance erzielen.
Basierend auf einem 3-TB-TPC-DS-Benchmark kann Spark mit AQE im Vergleich zu Spark ohne AQE bei zwei Queries eine mehr als 1,5-fache Performance und bei weiteren 37 Queries eine mehr als 1,1-fache Performance erzielen.
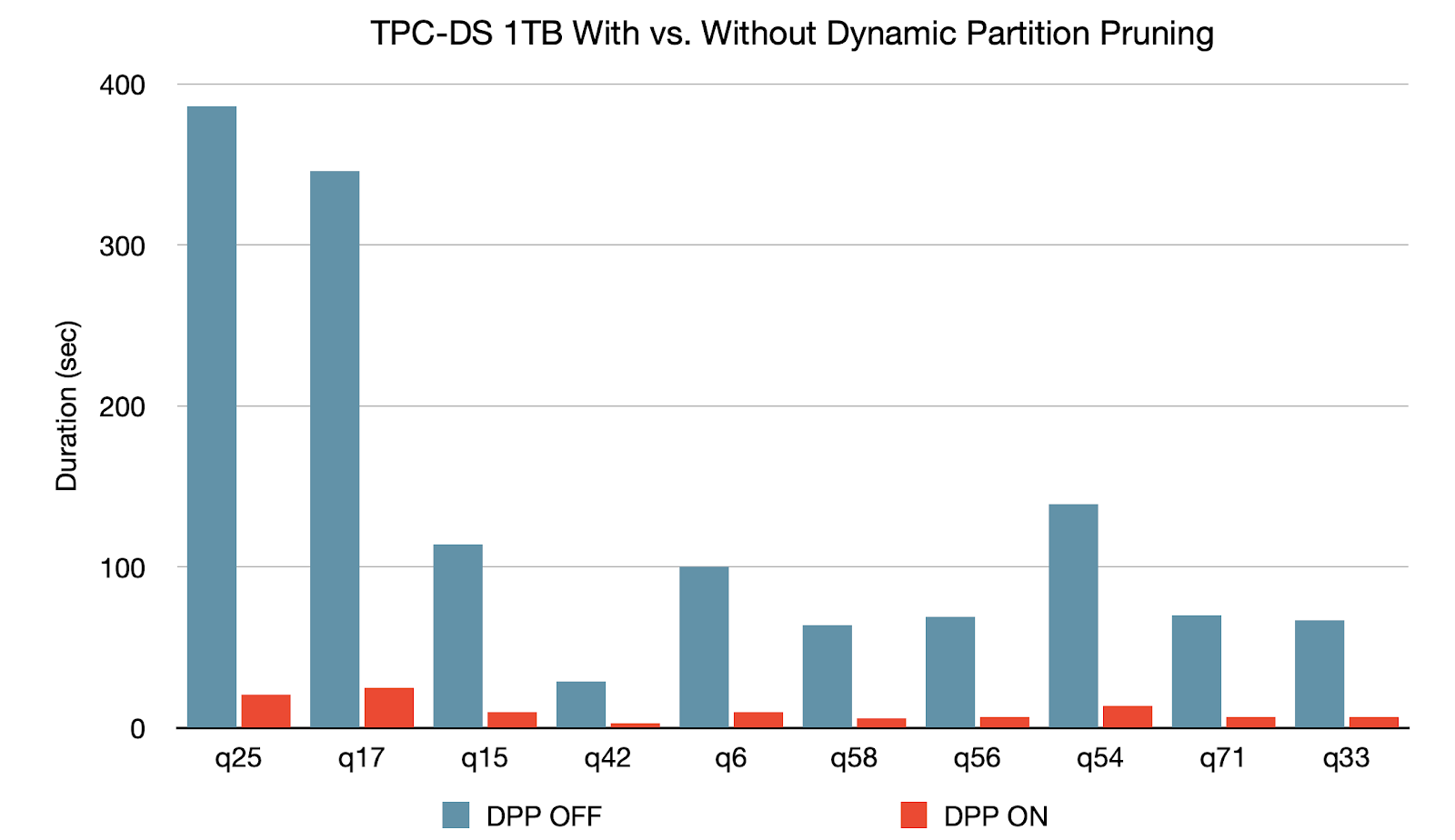
Dynamic Partition Pruning wird angewendet, wenn der Optimierer zur Kompilierzeit nicht identifizieren kann, welche Partitionen übersprungen werden können. Dies ist bei Sternschemata nicht unüblich, die aus einer oder mehreren Faktentabellen bestehen, die auf eine beliebige Anzahl von Dimensionstabellen verweisen. Bei solchen Join-Operationen können wir die Partitionen, die der Join aus einer Faktentabelle liest, bereinigen, indem wir jene Partitionen identifizieren, die aus dem Filtern der Dimensionstabellen resultieren. In einem TPC-DS-Benchmark zeigen 60 von 102 Abfragen eine signifikante Beschleunigung zwischen dem 2-fachen und 18-fachen.
Die ANSI-SQL-Compliance ist entscheidend für die Migration von Workloads von anderen SQL-Engines zu Spark SQL. Um die Compliance zu verbessern, wechselt dieses Release zum proleptischen gregorianischen Kalender und ermöglicht es Benutzern außerdem, die Verwendung der reservierten Schlüsselwörter von ANSI SQL als Bezeichner zu verbieten. Zusätzlich haben wir eine Laufzeit-Überlaufprüfung bei numerischen Operationen und eine Typdurchsetzung zur Kompilierzeit beim Einfügen von Daten in eine Tabelle mit einem vordefinierten Schema eingeführt. Diese neuen Validierungen verbessern die Datenqualität.
Join-Hints: Auch wenn wir den Compiler kontinuierlich verbessern, gibt es keine Garantie, dass er in jeder Situation die optimale Entscheidung trifft – die Auswahl des Join-Algorithmus basiert auf Statistiken und Heuristiken. Wenn der Compiler nicht die beste Wahl treffen kann, können Benutzer Join-Hints verwenden, um den Optimizer zu beeinflussen, einen besseren Plan zu wählen. Dieses Release erweitert die bestehenden Join-Hints um neue Hints: SHUFFLE_MERGE, SHUFFLE_HASH und SHUFFLE_REPLICATE_NL.
Python ist mittlerweile die am weitesten verbreitete Sprache in Spark und war daher ein Schwerpunkt bei der Entwicklung von Spark 3.0. 68 % der Notebook-Befehle auf Databricks sind in Python. PySpark, die Python-API für Apache Spark, verzeichnet mehr als 5 Millionen monatliche Downloads auf PyPI, dem Python Paket Index.
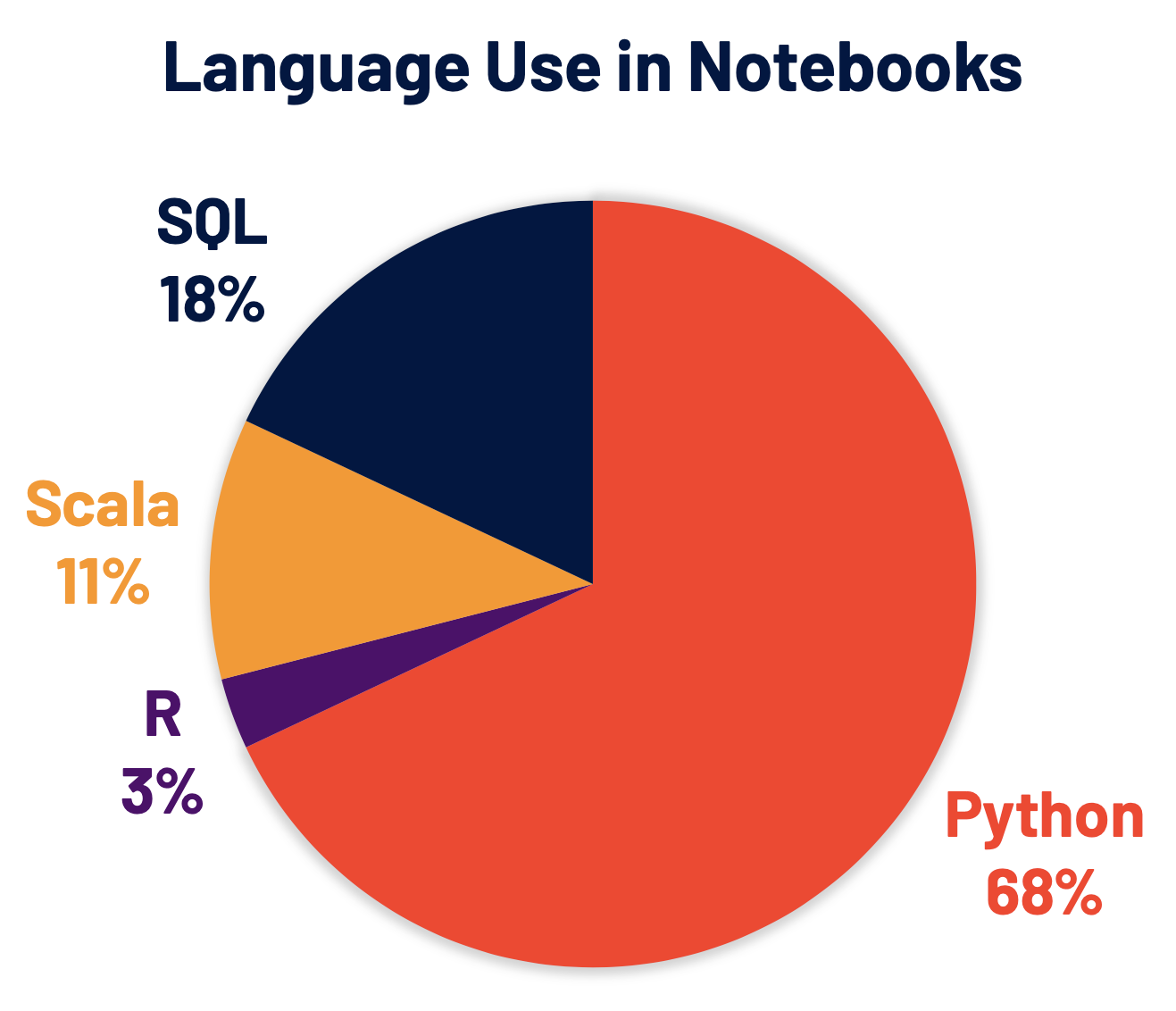
Viele Python-Entwickler nutzen die Pandas-API für Datenstrukturen und Datenanalysen, aber sie ist auf die Single-Node-Verarbeitung beschränkt. Wir haben auch Koalas weiterentwickelt, eine Implementierung der pandas-API auf Basis von Apache Spark, um data scientists bei der Arbeit mit Big Data in verteilten Umgebungen produktiver zu machen. Mit Koalas müssen viele Funktionen (z. B. Plotting-Unterstützung) nicht mehr in PySpark erstellt werden, um eine effiziente Performance über einen Cluster hinweg zu erzielen.
Nach mehr als einem Jahr Entwicklungszeit liegt die Abdeckung der Koalas-API für Pandas bei fast 80 %. Die monatlichen PyPI-Downloads von Koalas sind schnell auf 850.000 gestiegen, und Koalas entwickelt sich mit einer zweiwöchentlichen Release-Kadenz schnell weiter. Während Koalas vielleicht der einfachste Weg ist, von Ihrem Single-Node-Pandas-Code zu migrieren, verwenden viele immer noch die PySpark-APIs, die ebenfalls an Popularität gewinnen.
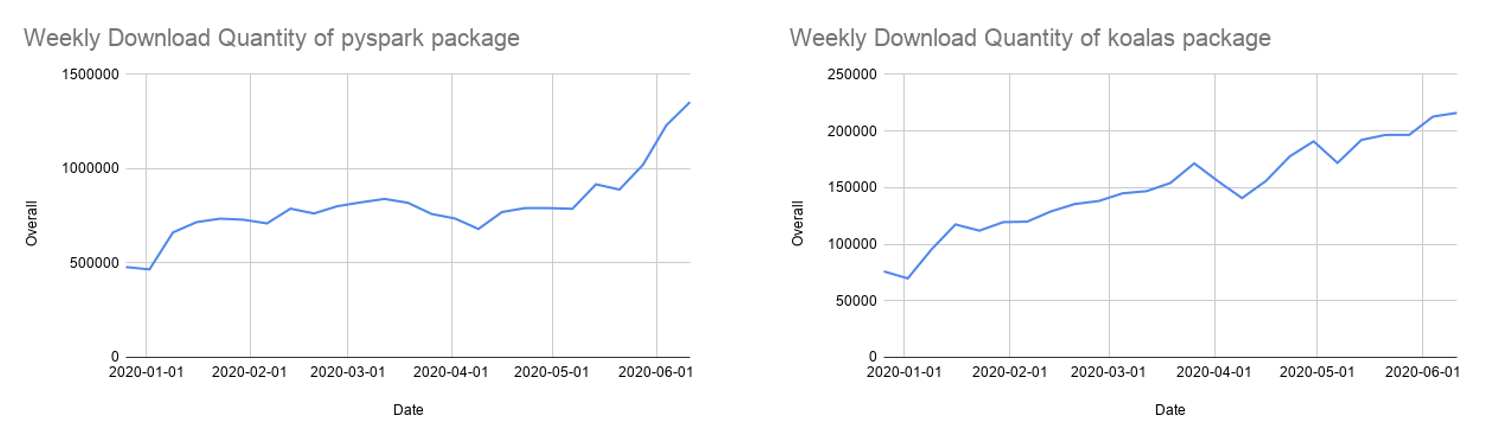
Spark 3.0 bringt mehrere Verbesserungen für die PySpark-APIs:
- Neue Pandas-APIs mit Type Hints: Pandas-UDFs wurden ursprünglich in Spark 2.3 eingeführt, um benutzerdefinierte Funktionen in PySpark zu skalieren und Pandas-APIs in PySpark-Anwendungen zu integrieren. Die bestehende Schnittstelle ist jedoch schwer zu verstehen, wenn weitere UDF-Typen hinzugefügt werden. Dieses Release führt eine neue pandas-UDF-Schnittstelle ein, die Python Type-Hints nutzt, um der zunehmenden Verbreitung von pandas-UDF-Typen entgegenzuwirken. Die neue Benutzeroberfläche ist pythonischer und selbsterklärender.
- Neue Typen von Pandas-UDFs und Pandas-Funktions-APIs: Dieses Release fügt zwei neue Pandas-UDF-Typen hinzu: Iterator von Series zu Iterator von Series und Iterator von mehreren Series zu Iterator von Series. Dies ist nützlich für Data-Prefetching und aufwendige Initialisierungen. Außerdem werden zwei neue Pandas-Funktions-APIs hinzugefügt: map und co-grouped map. Weitere Details finden Sie in diesem Blogpost.
- Bessere Fehlerbehandlung: Die Fehlerbehandlung von PySpark ist für Python-Nutzer nicht immer benutzerfreundlich. Dieses Release vereinfacht PySpark-Exceptions, verbirgt den unnötigen JVM-Stack-Trace und gestaltet sie Python-konformer.
Die Verbesserung der Python-Unterstützung und der Benutzerfreundlichkeit in Spark ist nach wie vor eine unserer höchsten Prioritäten.
Hydrogen, Streaming und Erweiterbarkeit
Mit Spark 3.0 haben wir Key-Komponenten für Project Hydrogen fertiggestellt und neue Funktionen zur Verbesserung von Streaming und Erweiterbarkeit eingeführt.
- Accelerator-aware Scheduling: Projekt Hydrogen ist eine wichtige Spark-Initiative, um Deep Learning und Datenverarbeitung in Spark besser zu vereinen. GPUs und andere Beschleuniger werden häufig zur Beschleunigung von Deep-Learning-Workloads eingesetzt. Damit Spark die Vorteile von Hardware-Beschleunigern auf Zielplattformen nutzen kann, erweitert dieses Release den bestehenden Scheduler, um den Cluster-Manager Accelerator-aware zu machen. Benutzer können mithilfe eines Discovery-Skripts Beschleuniger über die Konfiguration festlegen. Benutzer können dann die neuen RDD-APIs aufrufen, um diese Beschleuniger zu nutzen.
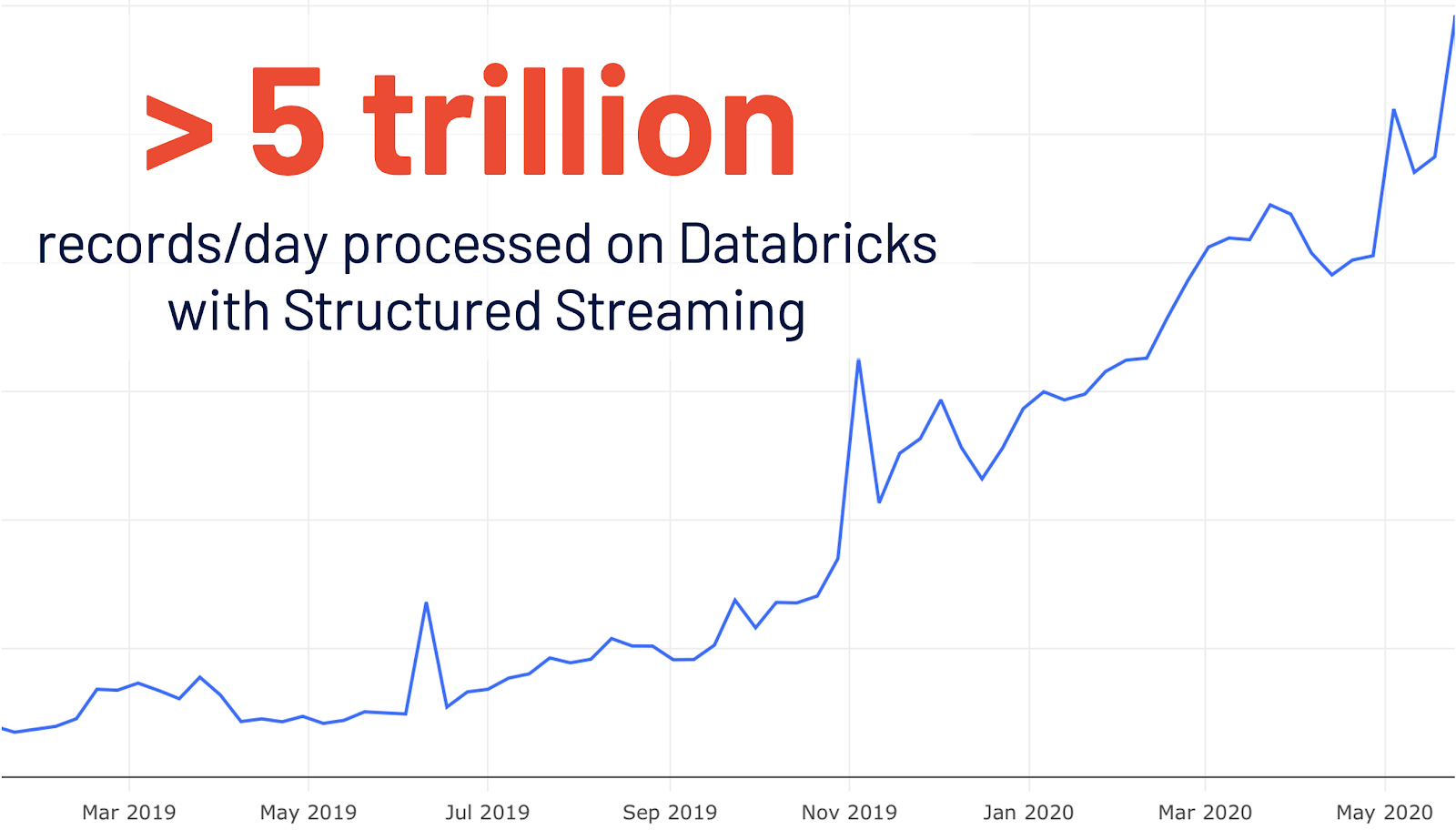
- Neue Benutzeroberfläche für Structured Streaming: Structured Streaming wurde ursprünglich in Spark 2.0 eingeführt. Nach einem vierfachen Wachstum der Nutzung auf Databricks im Jahresvergleich werden täglich mehr als 5 Billionen Datensätze auf Databricks mit strukturiertes Streaming verarbeitet. Dieses Release fügt eine neue, dedizierte Spark-Benutzeroberfläche zur Überprüfung dieser Streaming-Jobs hinzu. Diese neue Benutzeroberfläche bietet zwei Arten von Statistiken: 1) aggregierte Information über abgeschlossene Streaming-Abfrage-Jobs und 2) detaillierte statistische Information über Streaming-Abfragen.
- Beobachtbare Metriken: Die kontinuierliche Monitoring von Änderungen der Datenqualität ist eine sehr gefragte Feature für die Verwaltung von Datenpipelines. Dieses Release führt das Monitoring für Batch- und Streaming-Anwendungen ein. Beobachtbare Metriken sind beliebige Aggregatfunktionen, die für eine Abfrage (DataFrame) definiert werden können. Sobald die Ausführung eines DataFrame einen Abschlusspunkt erreicht (z. B. eine Batch-Abfrage beendet oder eine Streaming-Epoche erreicht), wird ein benanntes Ereignis ausgegeben, das die Metriken für die seit dem letzten Abschlusspunkt verarbeiteten Daten enthält.
- Neue Katalog-Plug-in-API: Der bestehenden Datenquellen-API fehlt die Möglichkeit, auf die Metadaten externer Datenquellen zuzugreifen und diese zu bearbeiten. Dieses Release erweitert die Datenquelle-V2-API und führt die neue Katalog-Plug-in-API ein. Für externe Datenquellen, die sowohl die Katalog-Plug-in-API als auch die Datenquelle-V2-API implementieren, können Benutzer nach der Registrierung des entsprechenden externen Katalogs sowohl Daten als auch Metadaten externer Tabellen direkt über mehrteilige Bezeichner bearbeiten.
Weitere Updates in Spark 3.0
Spark 3.0 ist ein wichtiges Release für die Community, in dem über 3.400 Jira-Tickets gelöst wurden. Es ist das Ergebnis von Beiträgen von über 440 Mitwirkenden, darunter Einzelpersonen sowie Unternehmen wie Databricks, Google, Microsoft, Intel, IBM, Alibaba, Facebook, Nvidia, Netflix, Adobe und viele mehr. Wir haben in diesem Blogpost eine Reihe der wichtigsten Fortschritte bei SQL, Python und Streaming in Spark hervorgehoben, aber es gibt viele andere Funktionen in diesem Meilenstein 3.0, die hier nicht behandelt werden. Erfahren Sie mehr in den Versionshinweisen und entdecken Sie alle anderen Verbesserungen in Spark, einschließlich Datenquellen, Ökosystem, Monitoring und mehr.
Legen Sie noch heute mit Spark 3.0 los
Wenn Sie Apache Spark 3.0 in der Databricks Runtime 7.0 ausprobieren möchten, registrieren Sie sich für einen Kostenlose Testversion Account und legen Sie in wenigen Minuten los. Die Verwendung von Spark 3.0 ist ganz einfach: Wählen Sie beim Starten eines Clusters die Version „7.0“ aus.
Erfahren Sie mehr über die Feature- und Release-Details:
- O’Reillys neues E-Book „Learning Spark, 2nd Edition“ als kostenloser Download
- Adaptive Query Execution -Blog
- Pandas UDFs und Python Type Hints -Blog
- Spark 3.0 Preview On-Demand-Webinar
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.