Ankündigung der allgemeinen Verfügbarkeit von Databricks Lakeflow
Der einheitliche Ansatz für Datenverarbeitung über Aufnahme, Transformation und Orchestrierung hinweg
von Bilal Aslam und Michael Armbrust
- Databricks Lakeflow löst die Herausforderungen der Datenverarbeitung, die durch fragmentierte Systeme entstehen, indem es eine einheitliche Lösung für die Aufnahme, Transformation und Orchestrierung auf der Data Intelligence Platform bietet.
- Lakeflow Connect fügt weitere Konnektoren für Datenbanken, Dateiquellen, Unternehmensanwendungen und Data Warehouses hinzu. Zerobus führt Hochdurchsatz-Direktschreibvorgänge mit geringer Latenz ein.
- Lakeflow Declarative Pipelines, basierend auf dem neuen offenen Spark Declarative Pipelines Standard, verfügt über eine neue IDE für Dateningenieure zur besseren Entwicklung von ETL-Pipelines.
Wir freuen uns, Ihnen mitteilen zu können, dass Lakeflow, die einheitliche Data-Engineering-Lösung von Databricks, jetzt allgemein verfügbar ist. Sie umfasst erweiterte Ingestionskonnektoren für gängige Datenquellen, eine neue „IDE für Data Engineering“, die das Erstellen und Debuggen von Datenpipelines vereinfacht, sowie erweiterte Funktionen für die Operationalisierung und Überwachung von ETL.
Auf dem Data + AI Summit im letzten Jahr haben wir Lakeflow vorgestellt – unsere Vision für die Zukunft des Data Engineering – eine End-to-End-Lösung, die drei Kernkomponenten umfasst:
- Lakeflow Connect: Zuverlässige, verwaltete Ingestion aus Unternehmensanwendungen, Datenbanken, Dateisystemen und Echtzeit-Streams, ohne den Aufwand für benutzerdefinierte Konnektoren oder externe Dienste.
- Lakeflow Declarative Pipelines: Skalierbare ETL-Pipelines, die auf dem offenen Standard von Spark Declarative Pipelines basieren, integriert mit Governance und Observability und bieten eine optimierte Entwicklungserfahrung durch eine moderne „IDE für Data Engineering“.
- Lakeflow Jobs: Native Orchestrierung für die Data Intelligence Platform, die fortschrittliche Kontrollflüsse, Echtzeit-Datentrigger und umfassende Überwachung unterstützt.
Durch die Vereinheitlichung des Data Engineering eliminiert Lakeflow die Komplexität und Kosten der Verknüpfung verschiedener Tools und ermöglicht es Datenteams, sich auf die Wertschöpfung für das Unternehmen zu konzentrieren. Lakeflow Designer, der neue KI-gestützte visuelle Pipeline-Builder, ermöglicht es jedem Benutzer, produktionsreife Datenpipelines ohne Code zu erstellen.
Es war ein geschäftiges Jahr, und wir freuen uns sehr, Ihnen die Neuerungen mitteilen zu können, da Lakeflow die allgemeine Verfügbarkeit erreicht.
Data-Engineering-Teams kämpfen damit, mit den Datenanforderungen ihrer Organisation Schritt zu halten
In jeder Branche ist die Fähigkeit eines Unternehmens, durch Analysen und KI Wert aus seinen Daten zu ziehen, sein Wettbewerbsvorteil. Daten werden in jeder Facette der Organisation genutzt – zur Erstellung von 360°-Kundenansichten und neuen Kundenerlebnissen, zur Ermöglichung neuer Einnahmequellen, zur Optimierung von Abläufen und zur Stärkung von Mitarbeitern. Wenn Organisationen ihre eigenen Daten nutzen wollen, landen sie bei einer Sammlung von Tools. Daten-Ingenieure finden es schwierig, die Komplexität von Data-Engineering-Aufgaben zu bewältigen und gleichzeitig fragmentierte Tool-Stacks zu navigieren, deren Integration mühsam und deren Wartung kostspielig ist.
Eine zentrale Herausforderung ist die Daten-Governance – fragmentierte Tools erschweren die Durchsetzung von Standards, was zu Lücken bei Discovery, Lineage und Observability führt. Eine aktuelle Studie von The Economist ergab, dass „die Hälfte der Daten-Ingenieure angibt, dass Governance mehr Zeit in Anspruch nimmt als alles andere“. Dieselbe Umfrage fragte Daten-Ingenieure, was den größten Nutzen für ihre Produktivität bringen würde, und sie identifizierten „Vereinfachung der Datenquellenverbindungen für die Ingestion von Daten“, „Verwendung einer einzigen einheitlichen Lösung anstelle mehrerer Tools“ und „bessere Sichtbarkeit von Datenpipelines zur Fehlerfindung und -behebung“ unter den wichtigsten Maßnahmen.
Eine einheitliche Data-Engineering-Lösung, integriert in die Data Intelligence Platform
Lakeflow hilft Datenteams, diese Herausforderungen zu bewältigen, indem es eine End-to-End-Data-Engineering-Lösung auf der Data Intelligence Platform bereitstellt. Databricks-Kunden können Lakeflow für jeden Aspekt des Data Engineering nutzen – Ingestion, Transformation und Orchestrierung. Da all diese Funktionen als Teil einer einzigen Lösung verfügbar sind, entfällt die Zeit für komplexe Tool-Integrationen oder zusätzliche Kosten für die Lizenzierung externer Tools.
Darüber hinaus ist Lakeflow in die Data Intelligence Platform integriert, was konsistente Methoden für die Bereitstellung, Governance und Überwachung aller Daten- und KI-Anwendungsfälle mit sich bringt. Für die Governance integriert sich Lakeflow beispielsweise in Unity Catalog, die einheitliche Governance-Lösung für die Data Intelligence Platform. Über Unity Catalog erhalten Daten-Ingenieure vollständige Transparenz und Kontrolle über jeden Teil der Datenpipeline, sodass sie leicht verstehen können, wo Daten verwendet werden und Probleme bei deren Auftreten beheben können.
Ob es um die Versionierung von Code, die Bereitstellung von CI/CD-Pipelines, die Sicherung von Daten oder die Überwachung von Echtzeit-Betriebsmetriken geht, Lakeflow nutzt die Data Intelligence Platform, um einen einzigen und konsistenten Ort für die Verwaltung von End-to-End-Data-Engineering-Anforderungen zu bieten.
Lakeflow Connect: Mehr Konnektoren und schnelle direkte Schreibvorgänge in Unity Catalog
Im vergangenen Jahr haben wir eine starke Akzeptanz von Lakeflow Connect verzeichnet, wobei über 2.000 Kunden unsere Ingestionskonnektoren nutzen, um Wert aus ihren Daten zu schöpfen. Ein Beispiel ist Porsche Holding Salzburg, die bereits die Vorteile der Verwendung von Lakeflow Connect zur Vereinheitlichung ihrer CRM-Daten mit Analysen zur Verbesserung des Kundenerlebnisses nutzen.
„Die Verwendung des Salesforce-Konnektors von Lakeflow Connect hilft uns, eine kritische Lücke für Porsche auf der Geschäftsseite in Bezug auf Benutzerfreundlichkeit und Preis zu schließen. Auf der Kundenseite können wir ein völlig neues Kundenerlebnis schaffen, das die Bindung zwischen Porsche und dem Kunden durch eine einheitliche und nicht fragmentierte Customer Journey stärkt.“ —Lucas Salzburger, Projektmanager, Porsche Holding Salzburg
Heute erweitern wir die Bandbreite der unterstützten Datenquellen um weitere integrierte Konnektoren für eine einfache und zuverlässige Ingestion. Die Konnektoren von Lakeflow sind für eine effiziente Datenextraktion optimiert, einschließlich der Verwendung von Change Data Capture (CDC)-Methoden, die für jede jeweilige Datenquelle angepasst sind.
Diese verwalteten Konnektoren umfassen jetzt Unternehmensanwendungen, Dateiquellen, Datenbanken und Data Warehouses und werden in verschiedenen Release-Status ausgerollt:
- Unternehmensanwendungen: Salesforce, Workday, ServiceNow, Google Analytics, Microsoft Dynamics 365, Oracle NetSuite
- Dateiquellen: SFTP, SharePoint
- Datenbanken: Microsoft SQL Server, Oracle Database, MySQL, PostgreSQL
- Data Warehouses: Snowflake, Amazon Redshift, Google BigQuery
Darüber hinaus ist ein häufiger Anwendungsfall, den wir von Kunden sehen, die Ingestion von Echtzeit-Ereignisdaten, typischerweise mit Message-Bus-Infrastruktur außerhalb ihrer Datenplattform. Um diesen Anwendungsfall auf Databricks zu vereinfachen, kündigen wir Zerobus an, eine Lakeflow Connect API, die es Entwicklern ermöglicht, Event-Daten mit sehr hohem Durchsatz (100 MB/s) und geringer Latenz (<5 Sekunden) direkt in ihr Lakehouse zu schreiben. Diese optimierte Ingestionsinfrastruktur bietet Leistung im großen Maßstab und ist mit der Databricks Platform vereinheitlicht, sodass Sie sofort breitere Analyse- und KI-Tools nutzen können.
„Joby kann unsere Fertigungsagenten mit Zerobus nutzen, um Gigabytes an Telemetriedaten pro Minute direkt in unser Lakehouse zu pushen und so die Zeit bis zu den Erkenntnissen zu beschleunigen – alles mit Databricks Lakeflow und der Data Intelligence Platform.“ —Dominik Müller, Factory Systems Lead, Joby Aviation Inc.
Lakeflow Declarative Pipelines: Beschleunigte ETL-Entwicklung auf Basis offener Standards
Nach Jahren des Betriebs und der Weiterentwicklung von DLT mit Tausenden von Kunden über Petabytes von Daten hinweg haben wir alles, was wir gelernt haben, genutzt und einen neuen offenen Standard geschaffen: Spark Declarative Pipelines. Dies ist die nächste Evolutionsstufe der Pipeline-Entwicklung – deklarativ, skalierbar und offen.
Und heute freuen wir uns, die allgemeine Verfügbarkeit von Lakeflow Declarative Pipelines bekannt zu geben, die die Leistung von Spark Declarative Pipelines auf die Databricks Data Intelligence Platform bringt. Es ist zu 100 % quellcodekompatibel mit dem offenen Standard, sodass Sie Pipelines einmal entwickeln und überall ausführen können. Es ist außerdem zu 100 % abwärtskompatibel mit DLT-Pipelines, sodass bestehende Benutzer die neuen Funktionen übernehmen können, ohne etwas neu schreiben zu müssen. Lakeflow Declarative Pipelines sind eine vollständig verwaltete Erfahrung auf Databricks: Serverless Compute ohne Aufwand, tiefe Integration mit Unity Catalog für einheitliche Governance und eine speziell entwickelte IDE für Data Engineering.
Die neue IDE für Data Engineering ist eine moderne, integrierte Umgebung, die entwickelt wurde, um die Pipeline-Entwicklung zu optimieren. Sie umfasst:
- Code und DAG nebeneinander, mit Abhängigkeitsvisualisierung und sofortigen Datenvorschau
- Kontextbezogenes Debugging, das Probleme inline anzeigt
- Integrierte Git-Unterstützung für schnelle Entwicklung
- KI-gestützte Erstellung und Konfiguration
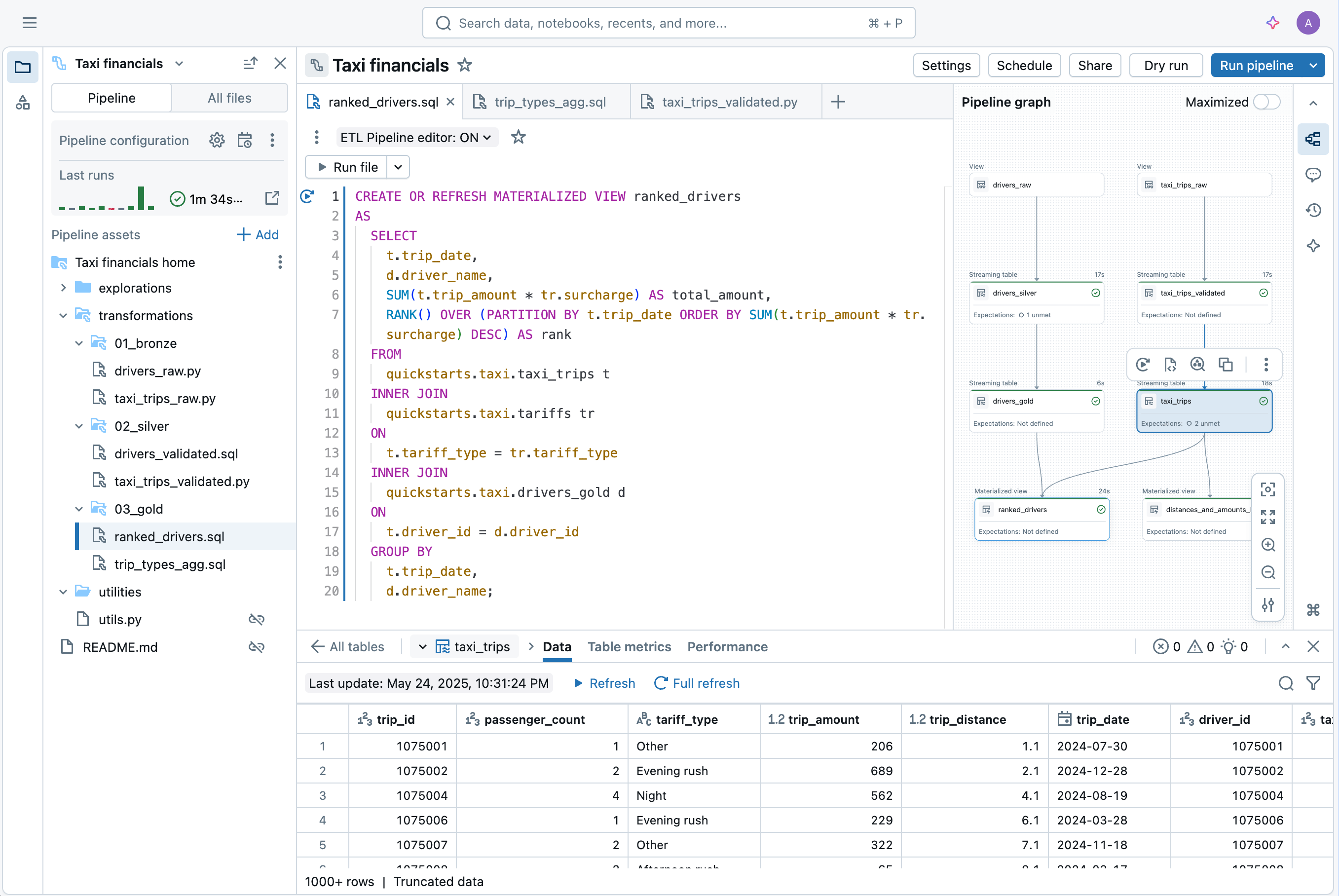
“Der neue Editor fasst alles an einem Ort zusammen – Code, Pipeline-Graph, Ergebnisse, Konfiguration und Fehlerbehebung. Kein Jonglieren mehr mit Browser-Tabs oder Verlust des Kontexts. Die Entwicklung fühlt sich fokussierter und effizienter an. Ich kann die Auswirkungen jeder Codeänderung direkt sehen. Ein Klick bringt mich zur genauen Fehlerzeile, was das Debugging beschleunigt. Alles hängt zusammen – Code mit Daten; Code mit Tabellen; Tabellen mit dem Code. Der Wechsel zwischen Pipelines ist einfach, und Funktionen wie automatisch konfigurierte Utility-Ordner reduzieren die Komplexität. Das fühlt sich an, als wäre dies der richtige Weg für die Pipeline-Entwicklung.” —Chris Sharratt, Data Engineer, Rolls-Royce
Lakeflow Declarative Pipelines sind jetzt der einheitliche Weg, um skalierbare, verwaltete und kontinuierlich optimierte Pipelines auf Databricks zu erstellen – egal, ob Sie mit Code arbeiten oder visuell über den Lakeflow Designer, eine neue No-Code-Erfahrung, die es Datenpraktikern jeder technischen Fähigkeit ermöglicht, zuverlässige Datenpipelines zu erstellen.
Lakeflow Jobs: Zuverlässige Orchestrierung für alle Workloads mit einheitlicher Beobachtbarkeit
Databricks Workflows wird seit langem für die Orchestrierung geschäftskritischer Workflows genutzt, wobei Tausende von Kunden sich auf unsere Plattform verlassen, um über 110 Millionen Jobs pro Woche auszuführen. Mit der allgemeinen Verfügbarkeit von Lakeflow entwickeln wir Workflows zu Lakeflow Jobs weiter und vereinheitlichen diesen ausgereiften, nativen Orchestrator mit dem Rest des Data-Engineering-Stacks.
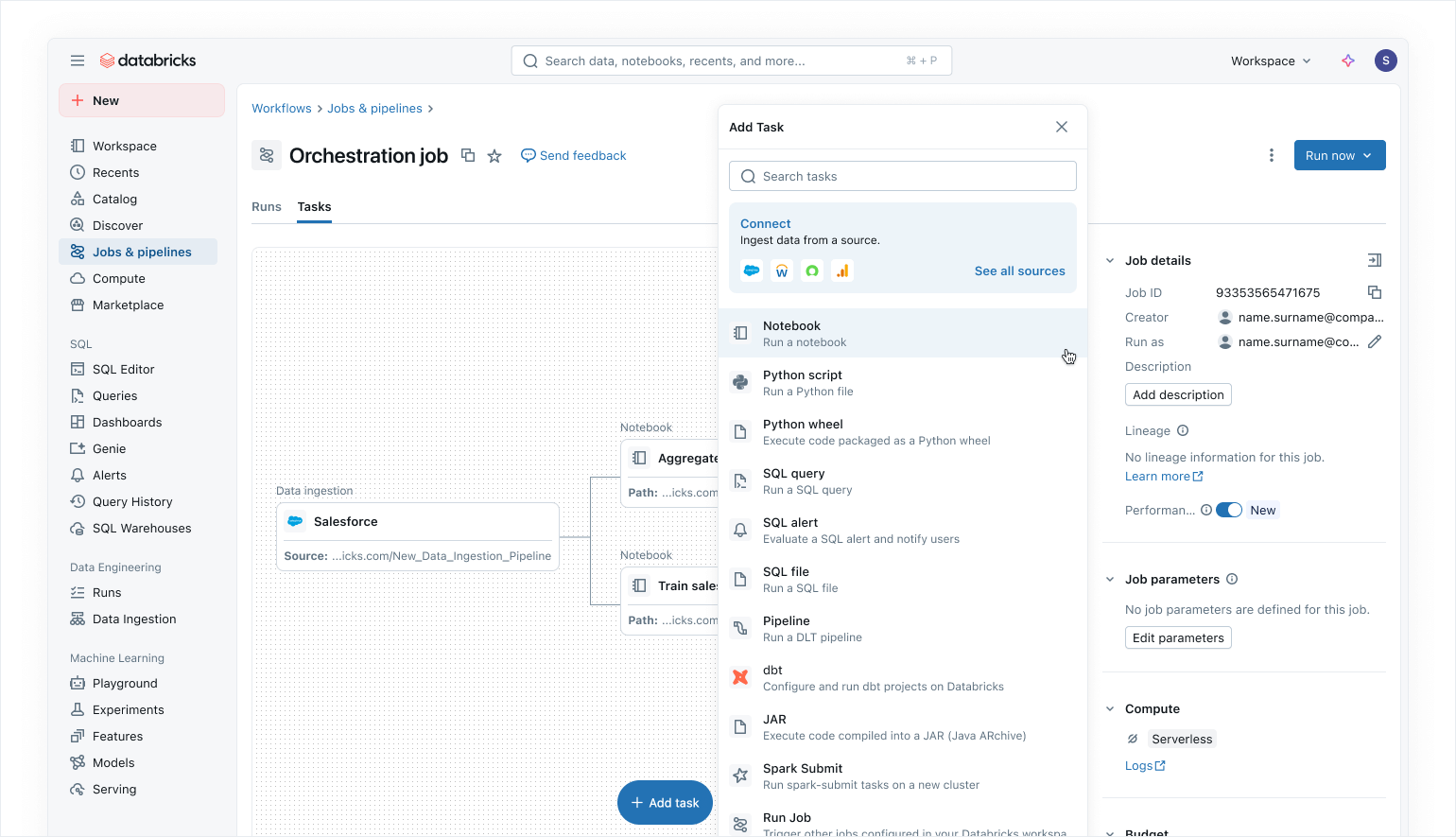
Lakeflow Jobs ermöglicht es Ihnen, jeden Prozess auf der Data Intelligent Platform mit einer wachsenden Reihe von Funktionen zu orchestrieren, darunter:
- Unterstützung für eine umfassende Sammlung von Aufgabentypen zur Orchestrierung von Flows, die Declarative Pipelines, Notebooks, SQL-Abfragen, dbt-Transformationen und sogar die Veröffentlichung von KI/BI-Dashboards oder für Power BI umfassen.
- Kontrollflussfunktionen wie bedingte Ausführung, Schleifen und Parametereinstellungen auf Aufgaben- oder Jobebene.
- Trigger für Jobausführungen über einfache Zeitplanung hinaus mit Dateiankunfts-Triggern und den neuen Tabellenaktualisierungs-Triggern, die sicherstellen, dass Jobs nur ausgeführt werden, wenn neue Daten verfügbar sind.
- Serverless Jobs, die automatische Optimierungen für bessere Leistung und geringere Kosten bieten.
„Mit serverless Lakeflow Jobs haben wir eine Latenzverbesserung von 3-5x erzielt. Was früher 10 Minuten dauerte, dauert jetzt nur noch 2-3 Minuten, was die Verarbeitungszeiten erheblich verkürzt. Dies hat es uns ermöglicht, schnellere Feedbackschleifen für Spieler und Trainer zu liefern und sicherzustellen, dass sie die Erkenntnisse erhalten, die sie nahezu in Echtzeit benötigen, um umsetzbare Entscheidungen zu treffen.“ —Bryce Dugar, Data Engineering Manager, Cincinnati Reds
Als Teil der Vereinheitlichung von Lakeflow bringt Lakeflow Jobs End-to-End-Beobachtbarkeit in jede Ebene des Datenlebenszyklus, von der Datenerfassung über die Transformation bis hin zur komplexen Orchestrierung. Ein vielfältiges Toolset passt sich jedem Überwachungsbedarf an: Visuelle Überwachungstools bieten einen Überblick über Suche, Status und Nachverfolgung, Debugging-Tools wie Abfrageprofile helfen bei der Leistungsoptimierung, Benachrichtigungen und Systemtabellen helfen bei der Identifizierung von Problemen und bieten historische Einblicke, und Datenqualitätsregeln erzwingen Regeln und stellen hohe Standards für Ihre Datenpipeline-Anforderungen sicher.
Erste Schritte mit Lakeflow
Lakeflow Connect, Lakeflow Declarative Pipelines und Lakeflow Jobs sind ab sofort für jeden Databricks-Kunden allgemein verfügbar. Erfahren Sie mehr über Lakeflow hier und besuchen Sie die offizielle Dokumentation, um mit Lakeflow für Ihr nächstes Data-Engineering-Projekt zu beginnen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.