Private LLMs mit Databricks Model Serving bereitstellen
von Ahmed Bilal, Ankit Mathur, Kasey Uhlenhuth und Joshua Hartman
Wir freuen uns, die öffentliche Vorschau der Unterstützung für die GPU- und LLM-Optimierung für Databricks Model Serving anzukündigen! Mit dieser Einführung können Sie Open-Source-Modelle oder Ihre eigenen benutzerdefinierten KI-Modelle jedes Typs, einschließlich LLMs und Vision-Modellen, auf der Lakehouse-Plattform bereitstellen. Databricks Model Serving optimiert Ihr Modell automatisch für das LLM-Serving und bietet erstklassige Performance ohne Konfigurationsaufwand.
Databricks Model Serving ist das erste serverlose GPU-Serving-Produkt, das auf einer einheitlichen Daten- und KI-Plattform entwickelt wurde. Damit können Sie GenAI-Anwendungen erstellen und bereitstellen – von der Datenaufnahme und Feinabstimmung bis hin zur Modellbereitstellung und zum Monitoring – und das alles auf einer einzigen Plattform.
Erstellen Sie generative KI-Anwendungen mit Databricks Model Serving
„Mit der Modellbereitstellung von Databricks sind wir in der Lage, generative KI in unsere Prozesse zu integrieren, um das Kundenerlebnis zu verbessern und die betriebliche Effizienz zu steigern. Die Modellbereitstellung ermöglicht es uns, LLMs anzuwenden und gleichzeitig die vollständige Kontrolle über unsere Daten und Modelle zu behalten.“ – Ben Dias, Director of Data Science and Analytics bei easyJet – Mehr erfahren
Hosten Sie KI-Modelle sicher, ohne sich um das Infrastrukturmanagement kümmern zu müssen.
Databricks Model Serving bietet eine einheitliche Lösung, um jedes KI-Modell bereitzustellen, ohne komplexe Infrastruktur verstehen zu müssen. Das bedeutet, Sie können jedes Modell für natürliche Sprache, Bilderkennung, Audio, tabellarische Daten oder benutzerdefinierte Modelle bereitstellen, unabhängig davon, wie es trainiert wurde – ob von Grund auf neu erstellt, aus Open-Source-Quellen bezogen oder mit proprietären Daten feinabgestimmt. Loggen Sie Ihr Modell einfach mit MLflow, und wir bereiten automatisch einen produktionsbereiten Container mit GPU-Bibliotheken wie CUDA vor und stellen ihn auf serverlosen GPUs bereit. Unser vollständig verwalteter Dienst übernimmt die ganze schwere Arbeit für Sie, sodass Sie keine Instanzen verwalten, die Versionskompatibilität aufrechterhalten und Versionen patchen müssen. Der Dienst skaliert Instanzen automatisch, um den Traffic-Mustern gerecht zu werden, wodurch Infrastrukturkosten gespart und gleichzeitig die Latenz-Performance optimiert wird.
„Mit der Modellbereitstellung von Databricks können wir Informationen schneller in eine Vielzahl von Anwendungsfällen einbringen, die von aussagekräftigen semantischen Suchanwendungen bis hin zur Vorhersage von Medientrends reichen. Durch die Abstraktion und Vereinfachung der komplizierten Abläufe der CUDA- und GPU-Serverskalierung können wir uns mit Databricks auf unsere eigentlichen Fachgebiete konzentrieren, nämlich die Ausweitung der KI-Nutzung bei Condé Nast auf alle unsere Anwendungen, ohne den Aufwand und die Belastung durch die Infrastruktur.“
Latenz und Kosten mit optimiertem LLM-Serving reduzieren
Databricks Model Serving umfasst jetzt Optimierungen für das effiziente Serving von großen Sprachmodellen, wodurch Latenz und Kosten um das 3- bis 5-Fache reduziert werden. Die Verwendung von Optimized LLM Serving ist unglaublich einfach: Stellen Sie einfach das Modell zusammen mit seinen OSS- oder feinabgestimmten Gewichtungen bereit, und wir erledigen den Rest, um sicherzustellen, dass das Modell mit optimierter Performance bereitgestellt wird. So können Sie sich darauf konzentrieren, das LLM in Ihre Anwendung zu integrieren, anstatt Low-Level-Bibliotheken für Modelloptimierungen zu schreiben. Databricks Model Serving optimiert automatisch die Modellklassen MPT und Llama2, wobei weitere Modelle in Kürze unterstützt werden.
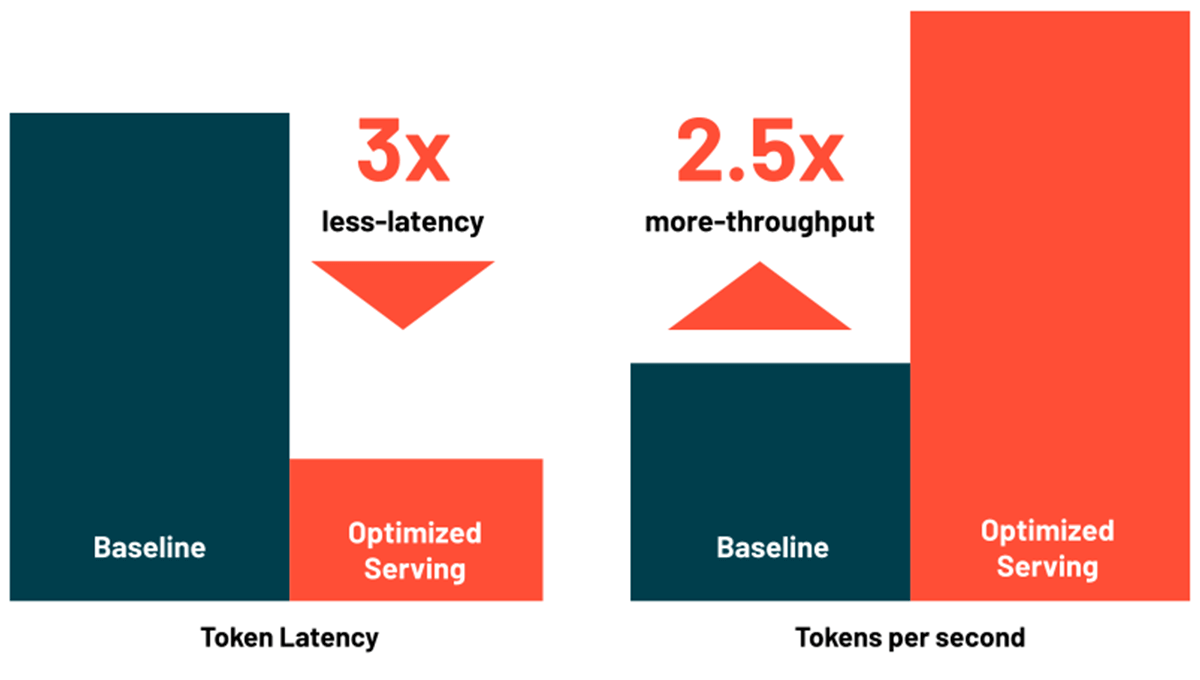
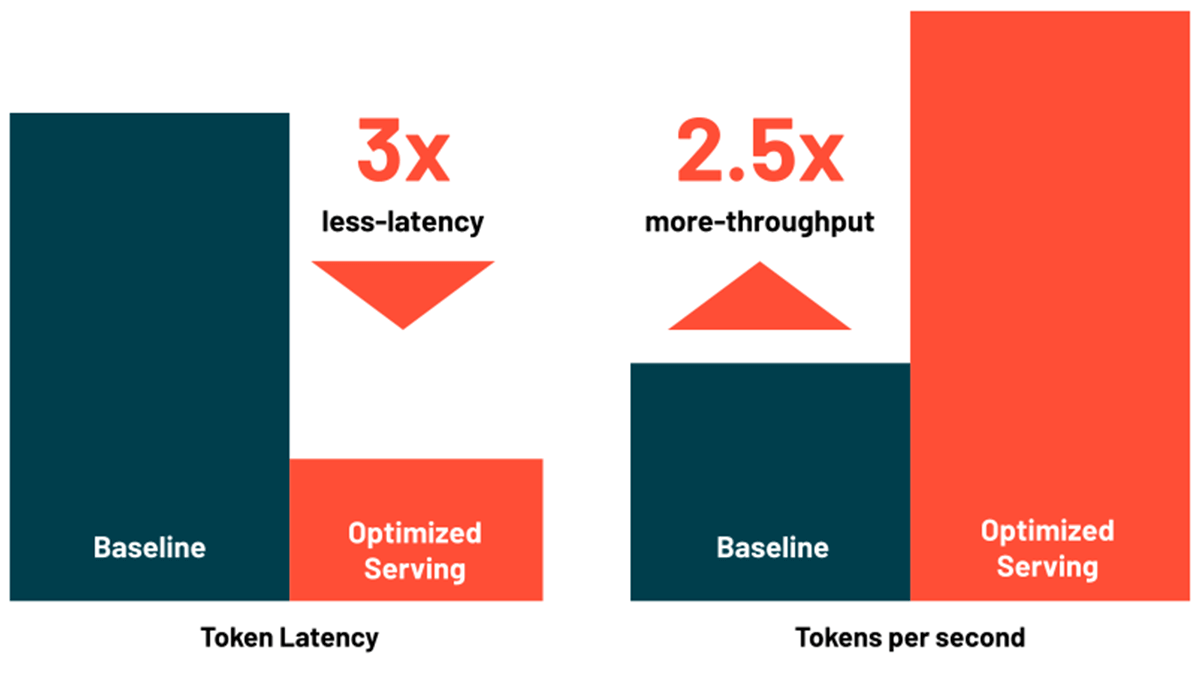{kind=link}
Beschleunigen Sie Bereitstellungen durch Lakehouse-KI-Integrationen.
Bei der Produktivsetzung von LLMs geht es nicht nur darum, Modelle anzuwenden. Sie müssen das Modell außerdem mit Techniken wie Retrieval Augmented Generation (RAG), parametereffizientem Fine-Tuning (PEFT) oder Standard-Fine-Tuning ergänzen. Zudem müssen Sie die Qualität des LLM bewerten und das Modell kontinuierlich auf Performance und Sicherheit überwachen. Dies führt oft dazu, dass Teams viel Zeit mit der Integration unterschiedlicher Tools verbringen, was die betriebliche Komplexität erhöht und Wartungsaufwand verursacht.
Databricks Model Serving baut auf einer einheitlichen Daten- und KI-Plattform auf, die es Ihnen ermöglicht, den gesamten LLMOps-Prozess – von der Datenaufnahme und dem Fine-Tuning bis hin zur Bereitstellung und Monitoring – auf einer einzigen Plattform zu verwalten. Dies schafft eine konsistente Ansicht über den gesamten KI-Lebenszyklus hinweg, was die Bereitstellung beschleunigt und Fehler minimiert. Model Serving lässt sich in verschiedene LLM-Services innerhalb des Lakehouse integrieren, darunter:
- Feinabstimmung: Verbessern Sie die Genauigkeit und heben Sie sich ab, indem Sie grundlegende Modelle mit Ihren proprietären Daten direkt auf Lakehouse feinabstimmen.
- Vektorsuche-Integration: Integrieren und führen Sie die Vektorsuche nahtlos für Anwendungsfälle der abruf-augmentierten Generierung und der semantischen Suche durch. Melden Sie sich hier für die Vorschau an.
- Integriertes LLM-Management: Integriert mit Databricks AI Gateway als zentrale API-Schicht für all Ihre LLM-Aufrufe.
- MLflow: Evaluierung, Vergleich und Verwaltung von LLMs über das PromptLab von MLflow.
- Qualität & Diagnose: Automatisches Erfassen von Anfragen und Antworten in einer Delta-Tabelle zur Überwachung und zum Debuggen von Modellen. Sie können diese Daten zusätzlich mit Ihren Labels kombinieren, um durch unsere Partnerschaft mit Labelbox Trainingsdatensätze zu generieren.
- Einheitliche Governance: Verwalten und steuern Sie alle Daten- und KI-Assets, einschließlich derer, die von Model Serving genutzt und erstellt werden, mit Unity Catalog.
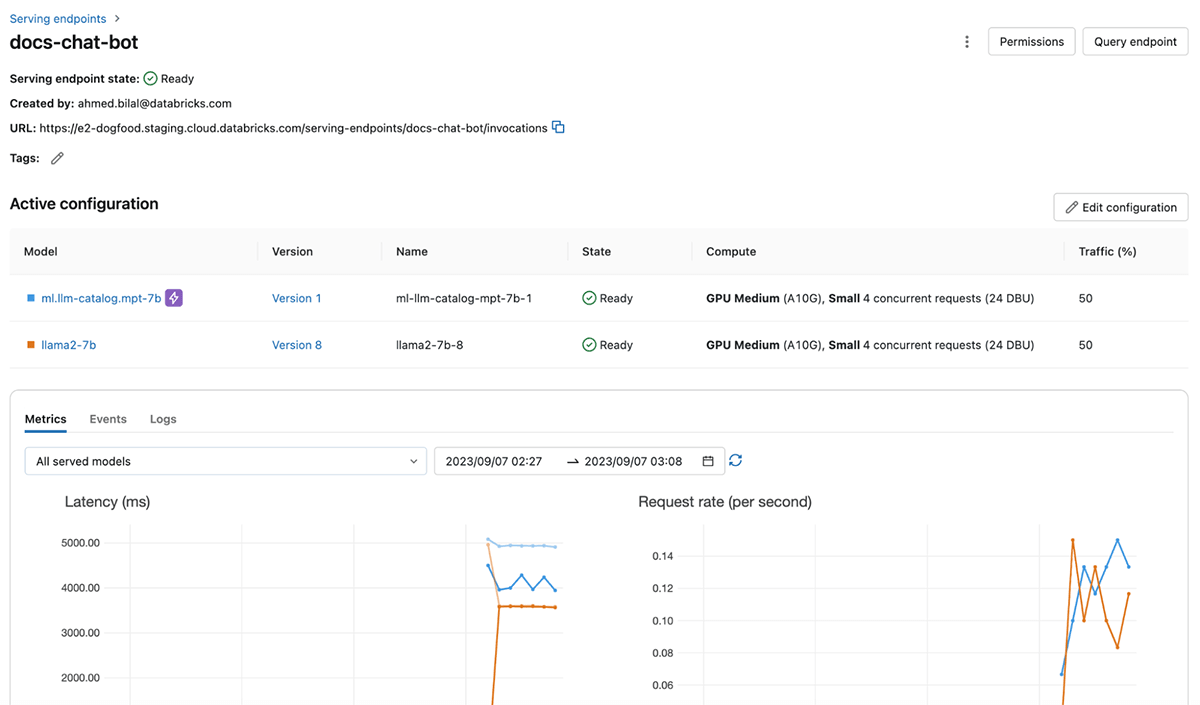
Zuverlässigkeit und Sicherheit für das LLM-Serving
Databricks Model Serving stellt dedizierte Rechenressourcen bereit, die eine skalierbare Inferenz mit voller Kontrolle über die Daten, das Modell und die Bereitstellungskonfiguration ermöglichen. Durch dedizierte Kapazitäten in der von Ihnen gewählten Cloud-Region profitieren Sie von geringer Overhead-Latenz, vorhersehbarer Performance und SLA-gestützten Garantien. Zudem sind Ihre Serving-Workloads durch mehrere Sicherheitsebenen geschützt, was eine sichere und zuverlässige Umgebung selbst für die sensibelsten Tasks gewährleistet. Wir haben mehrere Kontrollen implementiert, um die besonderen Compliance-Anforderungen stark regulierter Branchen zu erfüllen. Für weitere Informationen besuchen Sie bitte diese Seite oder wenden Sie sich an Ihr Databricks-Account-Team.
Erste Schritte mit dem GPU- und LLM-Serving
- Probieren Sie es aus! Stellen Sie Ihr erstes LLM auf Databricks Model Serving bereit, indem Sie das Tutorial für die ersten Schritte lesen (AWS | Azure).
- Tauchen Sie tiefer in die Dokumentation zu Databricks Model Serving ein.
- Erfahren Sie hier mehr über den Ansatz von Databricks für generative KI.
- Generative KI Engineer Learning Pathway: Nehmen Sie an On-Demand-Kursen im Selbststudium und von Kursleitern geführten Kursen zu Generative KI teil
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.