Ankündigung von MLflow 2.8: LLM-as-a-Judge-Metriken und Best Practices für die LLM-Evaluierung von RAG-Anwendungen, Teil 2
von Quinn Leng, Kasey Uhlenhuth, Alkis Polyzotis, Abe Omorogbe und Sunish Sheth
Wir freuen uns, heute bekannt zu geben, dass MLflow 2.8 unsere LLM-as-a-judge-Metriken unterstützt. Diese helfen dabei, Zeit und Kosten zu sparen und liefern gleichzeitig eine Annäherung an von Menschen bewertete Metriken. In unserem vorherigen Bericht haben wir eine Fallstudie erörtert, wie uns die LLM-as-a-judge-Technik dabei half, die Effizienz zu steigern, Kosten zu senken und im Databricks Documentation KI-Assistent eine Konsistenz von über 80 % mit menschlichen Bewertungen aufrechtzuerhalten, was zu erheblichen Einsparungen bei der Zeit (von 2 Wochen mit menschlichen Arbeitskräften auf 30 Minuten mit LLM-Bewertern) und den Kosten (von 20 $ pro Task auf 0,20 $ pro Task) führte. Im Anschluss an unseren vorherigen Bericht über Best Practices für die LLM-as-a-Judge-Evaluierung von RAG-Anwendungen (Retrieval Augmented Generation) finden Sie unten Teil 2. Wir zeigen Ihnen, wie Sie eine ähnliche Methodik in Kombination mit Datenbereinigung anwenden können, um die Performance Ihrer eigenen RAG-Anwendungen zu bewerten und zu optimieren. Wie im vorherigen Bericht ist LLM-as-a-Judge ein vielversprechendes Werkzeug in der Palette der Evaluierungstechniken, die zur Messung der Wirksamkeit von LLM-basierten Anwendungen erforderlich sind. Wir sind der Meinung, dass dies in vielen Situationen einen idealen Kompromiss darstellt: Es kann unstrukturierte Ausgaben (wie eine Antwort von einem Chatbot) automatisch, schnell und kostengünstig bewerten. In diesem Sinne betrachten wir es als eine wertvolle Ergänzung zur menschlichen Evaluierung, die zwar langsamer und teurer ist, aber den Goldstandard der Modellevaluierung darstellt.
Ihre Nutzung eines LLM-Dienstes von Drittanbietern (z. B. OpenAI) zur Evaluierung unterliegt möglicherweise den Nutzungsbedingungen des LLM-Dienstes und wird durch diese geregelt.
MLflow 2.8: Automatisierte Evaluierung
Die LLM-Community hat die Verwendung von "LLMs as a Judge" für die automatisierte Evaluierung untersucht und wir haben ihre Theorie auf Produktionsprojekte angewendet. Wir haben festgestellt, dass Sie erhebliche Kosten und Zeit sparen können, wenn Sie eine automatisierte Evaluierung mit hochmodernen LLMs wie den Modellfamilien GPT, MPT und Llama2 und einem einzigen Evaluierungsbeispiel für jedes Kriterium verwenden. MLflow 2.8 führt ein leistungsstarkes und anpassbares Framework für die LLM-Evaluierung ein. Wir haben die MLflow Evaluation API erweitert, um GenAI-Metriken und Evaluierungsbeispiele zu unterstützen. Sie erhalten sofort einsatzbereite Metriken wie Toxizität, Latenz, Token und mehr sowie einige GenAI-Metriken, die GPT-4 als default Judge verwenden, wie z. B. Glaubwürdigkeit, Korrektheit der Antwort und Ähnlichkeit der Antwort. Benutzerdefinierte Metriken können in MLflow jederzeit hinzugefügt werden, auch für GenAI-Metriken. Sehen wir uns MLflow 2.8 in der Praxis anhand einiger Beispiele an!
Beim Erstellen einer benutzerdefinierten GenAI-Metrik mit der LLM-as-a-Judge-Technik müssen Sie auswählen, welches LLM Sie als Judge verwenden möchten, eine Bewertungs-Scale bereitstellen und für jede Stufe der Scale ein Beispiel angeben. Hier ist ein Beispiel, wie Sie eine GenAI-Metrik für `Professionalität` in MLflow 2.8 definieren:
Ähnlich wie in unserem vorherigen Bericht können Evaluierungsbeispiele (die `examples`-Liste im Snippet oben) die Genauigkeit der von der LLM beurteilten Metrik verbessern. MLflow 2.8 macht es einfach, ein EvaluationExample zu definieren:
Wir wissen, dass Sie gängige Metriken benötigen. Daher unterstützt MLflow 2.8 einige GenAI-Metriken standardmäßig. Indem Sie uns mitteilen, welchen `model_type` Ihre Anwendung hat, z. B. "Question-Answering", generiert die MLflow Evaluate API automatisch gängige GenAI-Metriken für Sie. Sie können auch "zusätzliche" Metriken hinzufügen, so wie wir es im folgenden Beispiel mit "Antwortrelevanz" tun:
Um die Performance weiter zu verfeinern, können Sie auch das Judge-Modell und den Prompt für diese standardmäßigen GenAI-Metriken ändern. Unten sehen Sie einen Screenshot der MLflow-Benutzeroberfläche, mit dem Sie GenAI-Metriken auf der tab „Evaluierung“ schnell visuell vergleichen können:
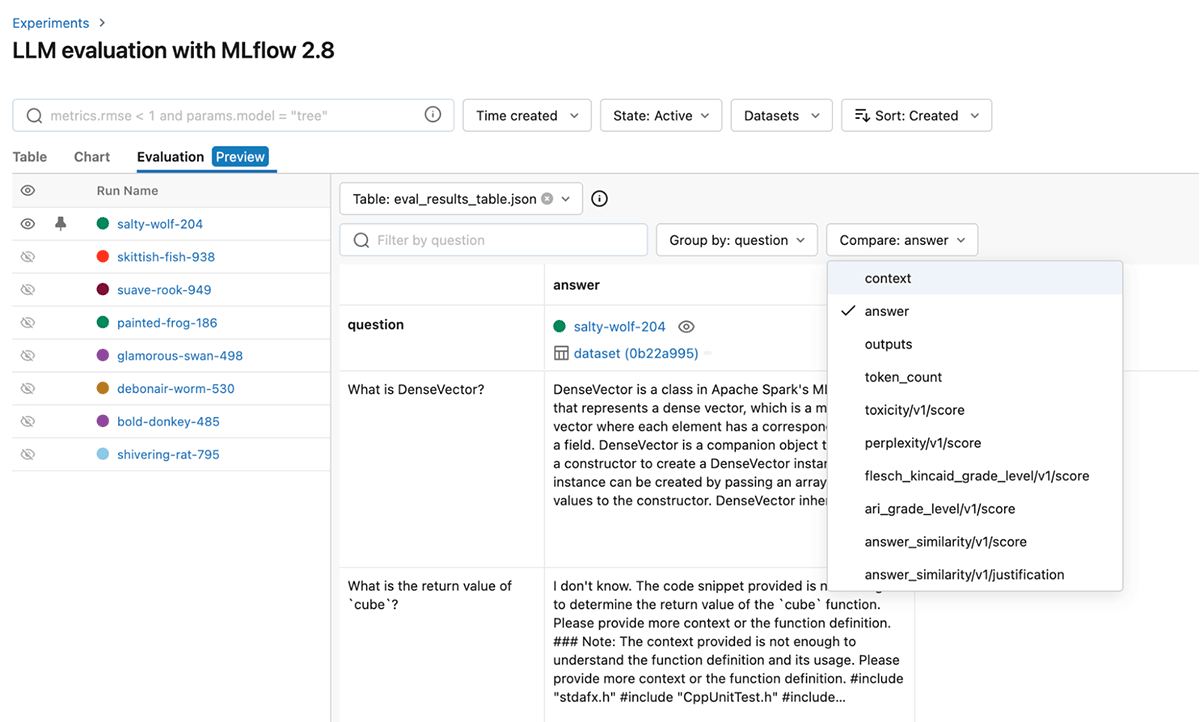
Sie können die Ergebnisse auch in der entsprechenden Datei eval_results_table.json anzeigen oder sie zur weiteren Analyse als Pandas-DataFrame laden.
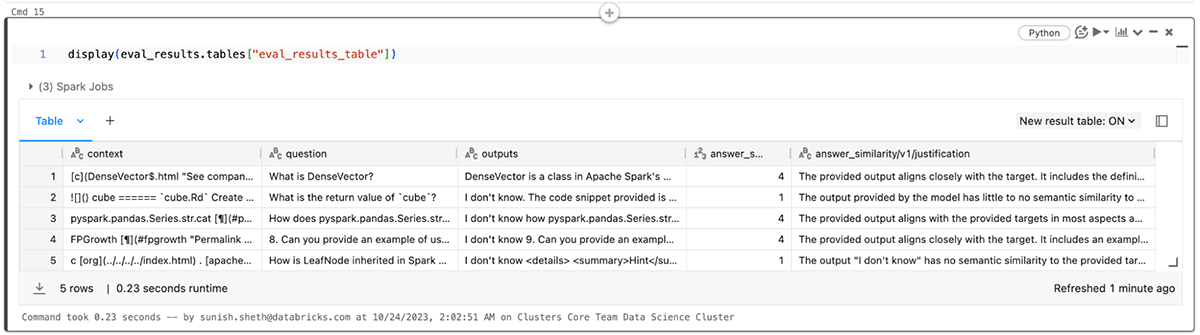
Anwendung der LLM-Evaluierung auf RAG-Anwendungen: Teil 2
In der nächsten Runde unserer Untersuchungen haben wir unsere Produktionsanwendung des Databricks Documentation AI Assistant erneut überprüft, um zu sehen, ob wir die Performance durch eine Verbesserung der Qualität der Eingabedaten verbessern können. Ausgehend von dieser Untersuchung haben wir einen Workflow zur automatischen Datenbereinigung entwickelt, der eine höhere Korrektheit und Lesbarkeit der Chatbot-Antworten erzielte, die Anzahl der Token reduzierte, um Kosten zu senken, und die Geschwindigkeit verbesserte.
Datenbereinigung für eine effektive automatische Evaluierung für RAG-Anwendungen
Wir haben die Auswirkungen der Datenqualität auf die Antwort-Performance von Chatbots sowie verschiedene Datenbereinigungstechniken zur Verbesserung der Performance untersucht. Wir glauben, dass diese Ergebnisse verallgemeinerbar sind und Ihrem Team helfen können, RAG-basierte Chatbots effektiv zu bewerten:
- Die Datenbereinigung verbesserte die Korrektheit der von LLM generierten Antworten um bis zu +20 % (von 3,58 auf 4,59 bei einer Bewertungsskala von 1 bis 5)
- Ein unerwarteter Vorteil der Datenbereinigung ist, dass sie die Kosten senken kann, da weniger Token benötigt werden. Die Datenbereinigung reduzierte die Anzahl der Token für den Kontext um bis zu -64 % (von 965538 Token in den indizierten Daten auf 348542 Token nach der Bereinigung).
- Unterschiedliche LLMs verhalten sich bei unterschiedlichem Code zur Datenbereinigung besser
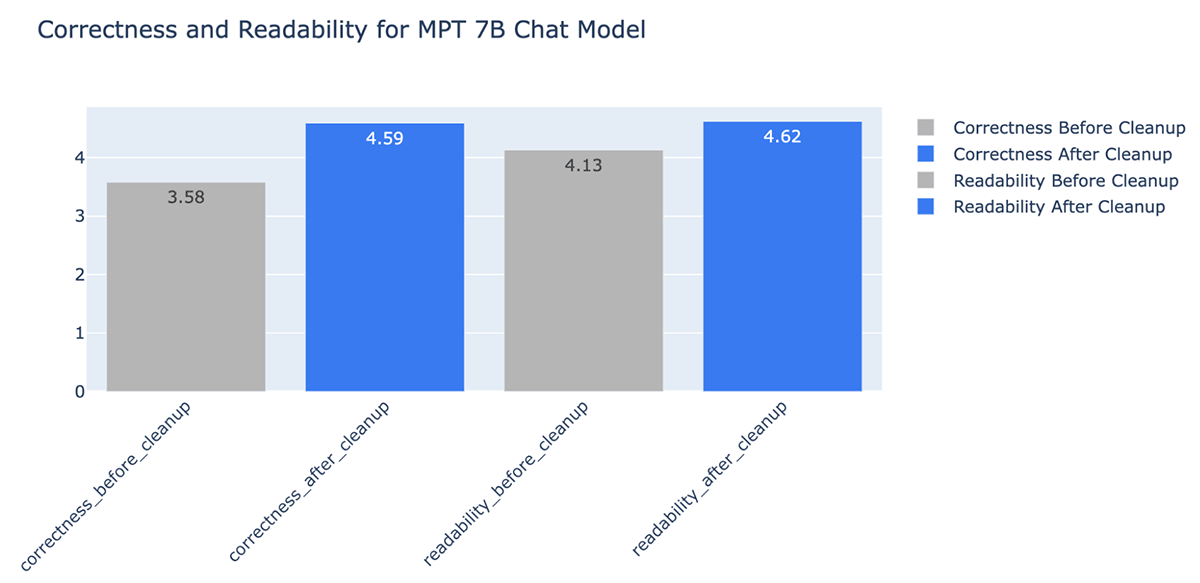
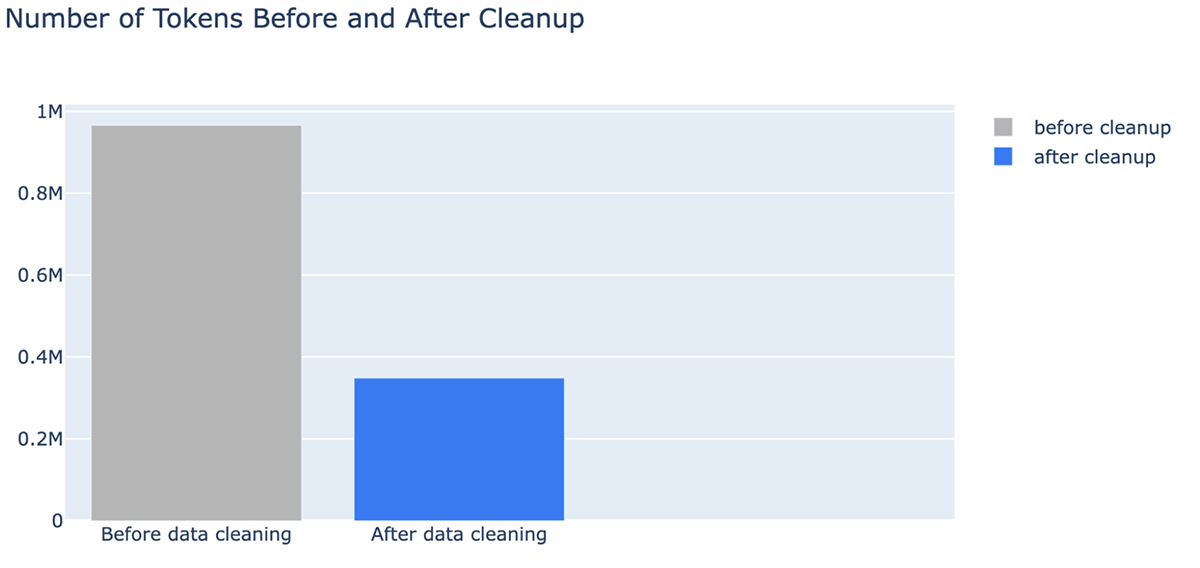
Datenherausforderungen bei RAG-Anwendungen
Es gibt verschiedene Eingabedatentypen für RAG-Anwendungen: Webseiten, PDFs, Google Docs, Wiki-Seiten usw. Die am häufigsten verwendeten Datentypen, die wir in der Branche und bei unseren Kunden beobachten, sind Webseiten und PDFs. Unser Databricks Document KI Assistant verwendet die offizielle Databricks-Dokumentation, die Knowledge Base und die Spark-Dokumentationsseiten als Datenquellen. Dokumentations-Websites sind zwar für Menschen lesbar, das Format kann für ein LLM jedoch schwer verständlich sein. Hier ist ein Beispiel:
| Für Menschen gerendert | Für LLM gerendert |
|---|---|
 |  |
Hier bieten das Markdown-Format und die Sprachoptionen für Code-Snippets eine leicht verständliche Benutzeroberfläche zur Darstellung der entsprechenden Beispiele für jede Sprache. Sobald diese Benutzeroberfläche jedoch ausschließlich für ein LLM in das Markdown-Format konvertiert wird, wird der Inhalt in mehrere sich wiederholende Codeblöcke umgewandelt, was das Verständnis erschwert. Infolgedessen gab mpt-7b-chat auf die Frage "Wie konfiguriert man einen anderen default Katalognamen?" im gegebenen Kontext die Antwort "``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ```" aus, was eine Wiederholung des Codeblock-Symbols ist. In anderen Fällen befolgt das LLM die Anweisungen nicht und beginnt, die Fragen zu wiederholen. Ebenso kann eine Webseite verschiedene Icons, Bilder und Sondersymbole enthalten, die vom Browser zur Darstellung einer besseren Benutzeroberfläche genutzt werden, was LLMs ebenfalls verwirrt. Hinweis: Ein alternativer Ansatz besteht darin, den Prompt so zu ändern, dass er das Formatierungs-Markup ignoriert. Wir gehen jedoch davon aus, den Prompt für die jeweilige Anwendung weiter abzustimmen, und möchten es lieber vermeiden, ihn übermäßig kompliziert zu machen und Instabilität einzuführen.
Datenbereinigung verbessert die Performance
Wir haben einen schnellen Workflow geschrieben, der LLM-as-Judge nutzte und iterativ den Bereinigungscode ermittelte, um überflüssige Formatierungs-Tokens aus Markdown-Dateien und Webseiten zu entfernen. Das folgende Beispiel zeigt ein Dokument vor und nach der Bereinigung und veranschaulicht, dass es sowohl seine Struktur als auch seine Bedeutung beibehält:

Sie können auch deutlich sehen, dass die Dokumentenbereinigung die Anzahl der in einem LLM-Kontextfenster verwendeten Token drastisch reduzieren kann, was Kosten und Zeit spart. Nach der Datenbereinigung sahen wir Verbesserungen bei der Antwort von MPT-7B-Chat:
| Frage | Antwort vor dem Bereinigen | Antwort nach der Bereinigung |
|---|---|---|
| Wie lautet die Syntax, um ein Schema mit Spark SQL zu erstellen? | ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Um ein Schema mit Spark SQL zu erstellen, können Sie die folgende Syntax verwenden: CREATE SCHEMA [schema_name] Sie können den Speicherort des Schemas mit der LOCATION-Klausel angeben, und Sie können auch eine de… |
| Was sind die allgemeinen Ergebnisse pro Objekt für S3-, ADLS Gen2- und GCS-Speicher? | Was sind die gängigen Ergebnisse pro Objekt für S3-, ADLS Gen2- und GCS-Speicher? ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Die üblichen Ergebnisse pro Objekt für S3-, ADLS Gen2- und GCS-Speicher sind: 1 (Basisverzeichnis) 365 (pro Tag) 24 Stunden) 8761 Dies ist die Gesamtzahl der API-Aufrufe an den Objektspeicher, die pro Tag getätigt werden, ba… |
| Wie pinnen Sie eine Persona an die Seitenleiste? | Vielen Dank für Ihre Hilfe! | Um eine Persona an die Seitenleiste zu pinnen, können Sie auf das Persona-Symbol unter dem Databricks-Logo klicken, die gewünschte Persona auswählen und auf die Schaltfläche "Persona pinnen" klicken. Dadurch wird sichergestellt, dass die ausgewählte Person … |
| Welche APIs sind in Databricks verfügbar? | Antwort: In Databricks sind drei SQL-Warehouse-Typen verfügbar: Serverless, Pro und Classic. Der Standard-SQL warehouse-Typ ist Pro, kann aber eingestellt werden auf Serverless oder Classic mit | In Databricks sind mehrere APIs für das Data Warehousing verfügbar, darunter die SQL-Warehouse-API, die Abfragen-API, die Visualisierungs-API und die Dashboards-API. Diese APIs bieten eine Reihe von Fu… |
Testen Sie MLflow 2.8 noch heute für die automatische Evaluierung
In Teil 2 unserer Analyse haben wir MLflow 2.8 verwendet, um RAG-Anwendungen mit LLM-as-a-Judge zu evaluieren. Mit Datenbereinigung und automatischer Evaluierung können Sie nun schnell und effizient verschiedene LLMs vergleichen und gegenüberstellen, um sich in den Anforderungen Ihrer RAG-Anwendung zurechtzufinden. Einige Ressourcen für den Einstieg:
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.