Best Practices for Cost Management on Databricks
von Tomasz Bacewicz und Greg Wood
Diese Blogreihe gehört zu unserer Reihe „Admin Essentials“, in der wir uns auf Themen konzentrieren, die für diejenigen wichtig sind, die Databricks-Umgebungen verwalten und warten. Halten Sie Ausschau nach zusätzlichen Blogs zu weiteren Themen und sehen Sie sich unsere vorherigen Blogs zu bewährten Methoden für die Organisation von Arbeitsbereichen (Workspace) und für Administratoren (Admin) an!
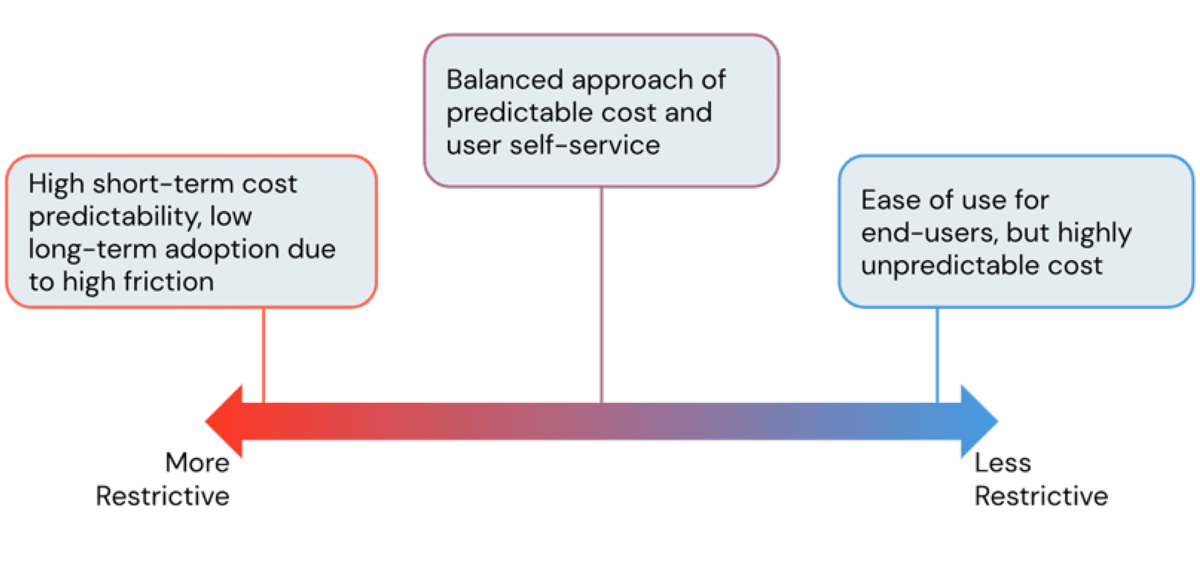
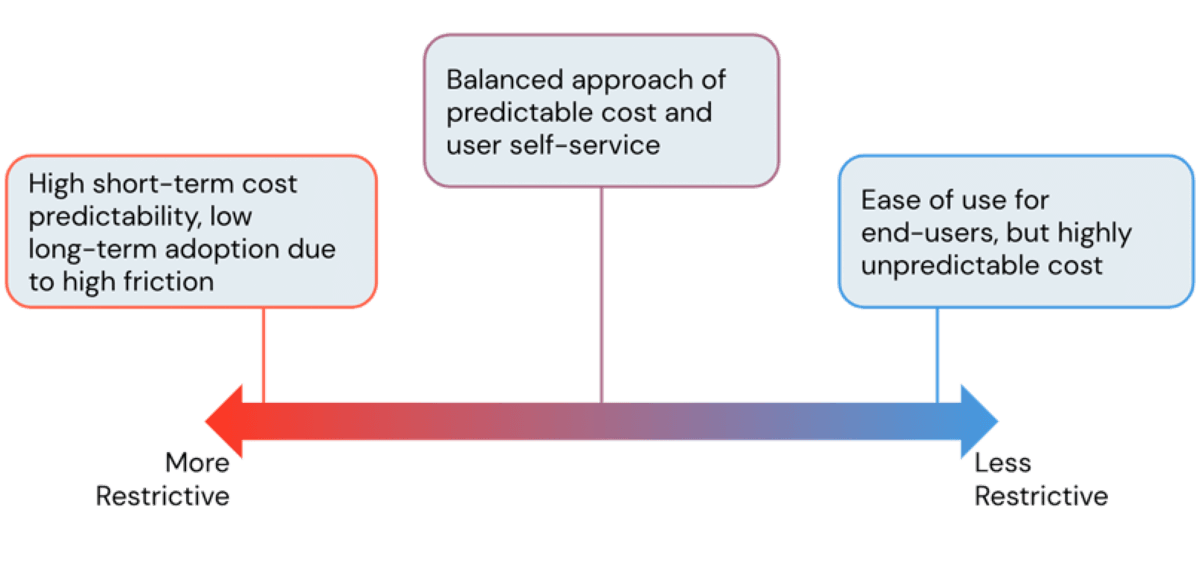
Einer der Hauptvorteile der Nutzung einer Cloud-Plattform ist ihre Flexibilität. Die Databricks Lakehouse Platform bietet Benutzern einfachen Zugriff auf nahezu sofort skalierbare Rechenleistung. Mit dieser einfachen Erstellung von Rechenressourcen besteht jedoch die Gefahr, dass die Cloud-Kosten außer Kontrolle geraten, wenn sie unkontrolliert und ohne Leitplanken bleibt. Als Administratoren versuchen wir immer, die perfekte Balance zu finden, um überhöhte Infrastrukturkosten zu vermeiden und gleichzeitig den Benutzern die Arbeit ohne unnötige Reibungsverluste zu ermöglichen. In diesem Blogbeitrag werden wir Databricks Admin-Tools besprechen, um diese Balance zu finden und Kosten zu kontrollieren, ohne die Benutzerproduktivität zu beeinträchtigen.
{kind=link}
Was ist eine DBU?
Bevor wir uns mit den Kostenkontrollen auf der Databricks-Plattform befassen, ist es wichtig, zunächst die Kostenbasis für den Betrieb einer Workload zu verstehen. Eine Databricks Unit (DBU) ist die zugrunde liegende Verbrauchseinheit innerhalb der Plattform. Mit Ausnahme eines SQL Warehouse basiert die Menge der verbrauchten DBUs auf der Anzahl der Knoten und der Rechenleistung der zugrunde liegenden VM-Instanztypen, die Teil des jeweiligen Clusters sind (da SQL Warehouses im Wesentlichen eine Gruppe von Clustern sind, ist die DBU-Rate die Summe der DBU-Raten der Cluster, aus denen sich der Endpunkt zusammensetzt). Auf höchster Ebene hat jede Cloud leicht unterschiedliche DBU-Raten für ähnliche Cluster (da sich die Knotentypen über die Clouds hinweg unterscheiden), aber die Databricks-Website bietet DBU-Rechner für jeden unterstützten Cloud-Anbieter (AWS | Azure | GCP).
Um die DBU-Nutzung in Dollarbeträge umzurechnen, benötigen Sie die DBU-Rate des Clusters sowie den Workload-Typ, der die jeweilige DBU generiert hat (z. B. Automated Job, All-Purpose Compute, Delta Live Tables, SQL Compute, Serverless Compute) und die Abonnementplan-Stufe (Standard und Premium für Azure und GCP; Standard, Premium und Enterprise für AWS). Beispielsweise hat ein Enterprise Databricks Workspace eine Jobs DBU-Listenrate von 20 Cent/DBU auf AWS. Mit einem Instanztyp, der mit 3 DBU/Stunde läuft, würde ein 4-Knoten-Jobs-Cluster für eine Stunde mit 2,40 $ (0,2 $ * 3 * 4) berechnet werden. DBU-Rechner können verwendet werden, um die Gesamtgebühren zu berechnen, und die Listenpreise sind in einer Cloud-spezifischen Matrix zusammengefasst, einschließlich SKU und Stufe (AWS | Azure | GCP).
Da die Kosten durch die Nutzung von Rechenressourcen und insbesondere von Clustern berechnet werden, ist es unerlässlich, Databricks-Arbeitsbereiche über Cluster-Richtlinien zu verwalten. Der nächste Abschnitt behandelt, wie verschiedene Attribute von Cluster-Richtlinien den DBU-Verbrauch einschränken und die Kosten der Plattform effektiv verwalten können. In den folgenden Abschnitten werden einige der zugrunde liegenden Cloud-Kosten, die zu berücksichtigen sind, sowie die Überwachung der Databricks-Nutzung und -Abrechnung erläutert.
Kostenmanagement durch Cluster-Richtlinien
Was sind Cluster-Richtlinien?
Eine Cluster-Richtlinie ermöglicht es einem Administrator, die Menge der Konfigurationen zu steuern, die beim Erstellen eines neuen Clusters verfügbar sind. Diese Richtlinien können einzelnen Benutzern oder Benutzergruppen zugewiesen werden. Standardmäßig haben alle Benutzer die Berechtigung „Unbeschränkte Clustererstellung zulassen“ innerhalb eines Arbeitsbereichs. Diese Berechtigung sollte selten verwendet werden, da sie es dem Benutzer ermöglicht, Cluster ohne Einschränkungen außerhalb der zugewiesenen Richtlinien zu erstellen, was potenziell zu unkontrollierten und außer Kontrolle geratenen Kosten führen kann.
Innerhalb einer Richtlinie kann ein Administrator jede Konfigurationseinstellung durch einen unveränderlichen festen Wert, einen permissiveren Wertebereich und Regex oder einen vollständig offenen Standardwert einschränken. Richtlinien begrenzen effektiv die Menge der DBUs, die von einem einzelnen Cluster verbraucht werden können, durch Einschränkungen bei allem, von granulareren Einstellungen wie VM-Instanztypen bis hin zu übergeordneten „synthetischen“ Attributen wie den maximal zulässigen DBUs pro Stunde oder Cluster-Workload-Typen.
Obwohl es auf den ersten Blick so aussehen mag, dass restriktivere Cluster zu niedrigeren Kosten führen, ist dies nicht immer der Fall. Sehr restriktive Richtlinien führen zu Clustern, die Aufgaben nicht rechtzeitig abschließen können, was zu höheren Kosten durch lang laufende Aufträge führt. Daher ist es unerlässlich, einen anwendungsfallorientierten Ansatz bei der Formulierung von Cluster-Richtlinien zu verfolgen, um den Teams die richtige Menge an Rechenleistung für ihre Workloads zur Verfügung zu stellen. Um dies zu unterstützen, bietet Databricks Leistungsfunktionen wie optimierte Apache Spark(™) Runtimes und insbesondere die Photon-Engine, die durch schnellere Verarbeitungszeiten zu Kosteneinsparungen führen. Wir werden Richtlinien für Runtimes in einem späteren Abschnitt besprechen, aber beginnen wir zunächst mit Richtlinien, die die horizontale Skalierung verwalten.
Knotenanzahlgrenzen, automatische Skalierung und automatische Beendigung
Ein häufiges Problem bei den Kosten für Rechenleistung sind Cluster, die unterausgelastet sind oder im Leerlauf laufen. Databricks bietet automatische Skalierungs- und automatische Beendigungsfunktionen, um diese Probleme dynamisch und ohne direkte Benutzereingriffe zu beheben. Diese Funktionen können über Richtlinien erzwungen werden, ohne die dem Benutzer zur Verfügung stehenden Rechenressourcen zu beeinträchtigen.
Knotenanzahlgrenzen und automatische Skalierung
Richtlinien können erzwingen, dass die automatische Skalierungsfunktion des Clusters mit einer festgelegten Mindestanzahl von Worker-Knoten aktiviert wird. Eine Richtlinie wie die folgende stellt beispielsweise sicher, dass die automatische Skalierung verwendet wird, und ermöglicht es einem Benutzer, einen Cluster mit bis zu 10 Worker-Knoten zu haben, aber nur, wenn sie benötigt werden:
Da der Erzwingungstyp „range“ für die maximale Anzahl von Workern ist, kann er während der Erstellung auf einen Wert kleiner als 10 geändert werden. Die minimale Anzahl von Workern ist jedoch auf „fixed“ auf eins festgelegt, sodass der Cluster immer auf einen Worker herunterskaliert wird, wenn er unterausgelastet ist, was Kosteneinsparungen bei der Rechenleistung gewährleistet. Ein weiterer hier gezeigter Feld ist „defaultValue“, der, wie der Name schon sagt, einen Standardwert für die maximale Anzahl von Workern in der Clusterkonfigurationsseite festlegt. Dies ist hilfreich, um die maximale Anzahl von Workern in einem Cluster standardmäßig zu reduzieren, sodass der Ersteller bewusst zulassen muss, dass ein Cluster auf 10 Knoten skaliert.
Das Verständnis der Anwendungsfälle bei der Erstellung und Zuweisung von Richtlinien ist in Bezug auf die Grenzen der Knotenanzahl und die Frage, ob die automatische Skalierung erzwungen werden soll, von entscheidender Bedeutung. Beispielsweise funktioniert die Erzwingung der automatischen Skalierung gut für:
- Gemeinsam genutzte Allzweck-Compute-Cluster: Ein Team kann einen Cluster für Ad-hoc-Analysen und experimentelle Aufträge oder Machine-Learning-Workloads gemeinsam nutzen.
- Lang laufende Batch-Aufträge mit unterschiedlicher Komplexität: Aufträge können die automatische Skalierung nutzen, sodass der Cluster auf den benötigten Ressourcenumfang skaliert.
Beachten Sie, dass zeitkritische Aufträge, die die automatische Skalierung verwenden, nicht zeitkritisch sein sollten, da die Skalierung des Clusters die Fertigstellung aufgrund der Startzeit der Knoten verzögern kann. Um dies zu mildern, verwenden Sie nach Möglichkeit einen Instanzpool.
Standard-Streaming-Workloads konnten bisher nicht von Autoskalierung profitieren; sie skalierten einfach auf die maximale Knotenanzahl und blieben dort für die Dauer des Jobs. Eine produktionsreifere Option für Teams, die an diesen Arten von Workloads arbeiten, ist die Nutzung von Delta Live Tables und erweiterter Autoskalierung (DLT-Workloads können mit der "cluster_type"-Richtlinie, die später in diesem Blog besprochen wird, erzwungen werden). Obwohl DLT mit Blick auf Streaming-Workloads entwickelt wurde, ist es durch die Nutzung der Trigger.AvailableNow-Option, die inkrementelle Updates von Zieltabellen ermöglicht, genauso gut für Batch-Pipelines geeignet.
Eine weitere gängige Konfiguration von Cluster-Größenrichtlinien ist die Single-Node-Richtlinie. Single-Node-Cluster können nützlich sein für neue Benutzer, die die Plattform erkunden möchten, Data-Science-Teams, die nicht-verteilte ML-Bibliotheken nutzen, sowie für Benutzer, die leichte explorative Datenanalysen durchführen müssen. Wie im Beispiel für eine Single-Node-Cluster-Richtlinie dargelegt, können Richtlinien eingeschränkt werden, um einen bestimmten Instanzpool zu nutzen. Folglich hat das Team, das dieser Richtlinie zugewiesen ist, eine Begrenzung der Anzahl von Single-Node-Clustern, die es erstellen kann, basierend auf der maximalen Kapazitätseinstellung des Pools.
Automatische Beendigung
Ein weiteres Attribut, das beim Erstellen eines Clusters auf der Databricks-Plattform festgelegt werden kann, ist die automatische Beendigungszeit, die einen Cluster nach einer festgelegten Leerlaufzeit abschaltet. Leerlaufperioden werden durch das Fehlen jeglicher Aktivität auf dem Cluster definiert, wie z. B. Spark-Jobs, Structured Streaming oder JDBC-Aufrufe. Aktivitäten, die nicht als Aktivitäten auf dem Cluster gelten, sind das Erstellen einer SSH-Verbindung zum Cluster und das Ausführen von Bash-Befehlen.
Das gängigste automatische Beendigungsfenster ist eine Stunde. Als Beispiel hier die Richtlinie, die auf ein festes Ein-Stunden-Fenster eingestellt ist:
In diesem Beispiel wird das Attribut "hidden" auch zu dieser Steuerung hinzugefügt, was das Widget auf der Cluster-Konfigurationsseite des Benutzers ausblendet. Dieses Attribut ist nur für Allzweckcluster anwendbar, da Jobs und DLT-Cluster automatisch heruntergefahren werden, wenn alle ihnen zugewiesenen Aufgaben abgeschlossen sind.
Cluster-Laufzeiten und Photon
Databricks Runtimes sind ein wichtiger Teil der Leistungsoptimierung auf Databricks; Kunden sehen oft einen automatischen Vorteil, wenn sie zu einem Cluster wechseln, der eine neuere Runtime ausführt, ohne viele andere Änderungen an ihrer Konfiguration vorzunehmen. Für einen Administrator, der Cluster-Richtlinien erstellt, ist die Aufklärung der Cluster-Ersteller über die Auswirkungen der Ausführung einer neueren Runtime wertvoll für Kosteneinsparungen. Wenn Benutzer zu neueren Runtimes wechseln, können ältere Runtimes ausgemustert und durch Richtlinien eingeschränkt werden. Als schnelles Beispiel hier das Attribut "spark_version", das Benutzer auf DB Runtimes der Version 11.0 oder 11.1 beschränkt.
Diese Richtlinie könnte jedoch flexibler gestaltet werden, indem andere Versionen, ML-Runtimes, Photon-Runtimes oder GPU-Runtimes zugelassen werden, indem die Zulassungsliste erweitert oder Regex verwendet wird.
Die andere Runtime-Funktion, die bei der Leistungsoptimierung zur Kostensenkung berücksichtigt werden sollte, ist die Nutzung unserer vektorisierten Photon-Engine. Photon beschleunigt intelligent Teile einer Workload durch eine vektorisierte Spark-Engine, mit der Kunden eine Leistungssteigerung von 3x bis 8x erzielen. Die massive Leistungssteigerung führt zu schnelleren Jobs und folglich zu geringeren Gesamtkosten.
Cloud-Instanztypen und Spot-Instanzen
Während der Cluster-Erstellung können VM-Instanztypen sowohl für den Treiberknoten als auch für die Arbeitsknoten separat ausgewählt werden. Die verfügbaren Instanztypen haben jeweils eine andere berechnete DBU-Rate und sind auf den Databricks-Preisübersichtsseiten für die jeweilige Cloud zu finden (AWS, Azure, GCP). Zum Beispiel verbraucht im AWS der Instanztyp m4.large mit zwei Kernen und 8 GB Speicher 0,4 DBUs pro Stunde, während ein Instanztyp m4.16xlarge mit 64 Kernen und 256 GB Speicher 12 DBUs pro Stunde im Allzweck-Compute-Modus verbraucht. Bei einer so großen Bandbreite an DBU-Nutzung zwischen den Rechenressourcen ist es entscheidend, dieses Attribut durch eine Richtlinie einzuschränken.
Cloud-Instanztypen können am bequemsten über den "allowlist"-Typ oder andernfalls über den "fixed"-Typ gesteuert werden, um nur einen Instanztyp zuzulassen. Das folgende Beispiel zeigt das Attribut "node_type_id", das eine Richtlinie für die verfügbaren Arbeitsknotentypen für den Benutzer festlegt, während "driver_node_type_id" eine Richtlinie für den Treibernknotentyp festlegt.
Als Administrator, der diese Richtlinien erstellt, ist es wichtig, eine Vorstellung davon zu haben, welche Art von Workloads jedes Team ausführt und die richtigen Richtlinien entsprechend zuzuweisen. Workloads mit kleineren Datenmengen sollten nur Instanztypen mit geringem Speicherbedarf erfordern, während das Training von Deep-Learning-Modellen am meisten von GPU-Clustern profitieren würde, die im Allgemeinen mehr DBUs verbrauchen. Letztendlich kann die Einschränkung von Instanztypen ein Balanceakt sein. Wenn ein Team Workloads ausführen muss, die mehr Ressourcen erfordern, als aufgrund von Richtlinienbeschränkungen verfügbar sind, kann der Job länger dauern und folglich die Kosten erhöhen. Es gibt einige Best Practices, die bei der Konfiguration eines Clusters für eine definierte Workload befolgt werden sollten. Zum Beispiel wird das vertikale Skalieren (Verwendung leistungsfähigerer Instanztypen) gegenüber dem horizontalen Skalieren (Hinzufügen weiterer Knoten) für komplexe Workloads mit vielen breiten Transformationen, die Data Shuffling erfordern, empfohlen. Dennoch sollten unerfahreneren Teams Richtlinien zugewiesen werden, die auf kleinere Instanztypen beschränkt sind, da unnötig leistungsstarke VMs für gängigere, weniger komplexe Workloads keinen großen Nutzen bringen.
Eine relativ neue kostensparende Funktion der Databricks-Plattform ist die Möglichkeit, AWS Graviton-fähige VMs zu verwenden, die auf der Arm64-Befehlssatzarchitektur basieren. Basierend auf Studien von AWS sowie Benchmarks von Databricks mit Photon bieten diese Graviton-fähigen Instanzen einige der besten Preis-Leistungs-Verhältnisse im Satz der AWS EC2-Instanztypen.
Spot-Instanzen
Databricks bietet eine weitere Konfiguration, die Kosten speziell bei den zugrunde liegenden VM-Compute-Kosten sparen kann: Spot-Instanzen (die über Databricks auf GCP verfügbare Option verwendet preemptible Instanzen, die Spot-Instanzen ähneln). Spot-Instanzen sind freie VMs, die vom zugrunde liegenden Cloud-Anbieter angeboten und in einem Live-Marktplatz versteigert werden. Diese Instanzen können erhebliche Rabatte ermöglichen, manchmal bis zu 90 % Reduzierung der Instanz-Compute-Kosten. Der Nachteil von Spot-Instanzen ist, dass sie vom zugrunde liegenden Cloud-Anbieter jederzeit mit kurzer Vorankündigung (2 Minuten für AWS, 30 Sekunden für Azure und GCP) zurückgenommen werden können.
Wenn Sie AWS verwenden, kann eine Cluster-Richtlinie definiert werden, die die Verwendung von Spot-Instanzen wie folgt beinhaltet:
Auf Azure:
In diesen Beispielen kann nur ein Knoten (speziell der Treiberknoten) eine On-Demand-Instanz sein, während alle anderen Knoten im Cluster während der anfänglichen Cluster-Erstellung Spot-Instanzen sein werden. Da die Fallback-Option hier aktiviert ist, wird eine On-Demand-Instanz angefordert, um eine Spot-Instanz zu ersetzen, die an den Cloud-Anbieter zurückgegeben wurde. Obwohl Richtlinien auf GCP derzeit das Attribut "first_on_demand" nicht erzwingen können, können preemptible Knoten dennoch wie folgt erzwungen werden:
Standardmäßig verwendet nur der Treiberknoten beim Start des Clusters eine On-Demand-Instanz, wenn preemptible Instanzen aktiviert sind.
Wenn fehlertolerante Prozesse wie experimentelle Workloads oder Ad-hoc-Abfragen ausgeführt werden, bei denen Zuverlässigkeit und Dauer der Workload keine Priorität haben, können Spot-Instanzen eine einfache Möglichkeit sein, die Instanzkosten niedrig zu halten. Daher eignen sich Spot-Instanzen am besten für Entwicklungs- und Staging-Umgebungen.
Die Raten für die Ausmusterung von Spot-Instanzen und die Preise können je nach T-Shirt-Größe und Cloud-Region variieren. Daher kann die Planung für optimale Cluster-Konfigurationen durch Tools der jeweiligen Cloud-Anbieter unterstützt werden, wie z. B. den AWS Spot Instance Advisor, Azure Spot Pricing and History im Azure-Konto-Portal oder den Google Cloud Pricing Calculator.
Beachten Sie, dass Azure einen zusätzlichen Hebel zur Kostenkontrolle hat: Reservierte Instanzen können von Databricks verwendet werden und bieten einen weiteren (potenziell hohen) Rabatt, ohne die Instabilität zu erhöhen.
Cluster-Tagging
Die Möglichkeit, die von einem Team genutzten Ressourcen zu beobachten, wird durch das Tagging von Clustern ermöglicht. Diese Tags werden auf die Ebene des Cloud-Anbieters weitergegeben, sodass die Nutzung und die Kosten sowohl von der Databricks-Plattform als auch von den zugrunde liegenden Cloud-Kosten zugewiesen werden können. Ohne eine Cluster-Richtlinie ist ein Benutzer, der einen Cluster erstellt, jedoch nicht verpflichtet, Tags zuzuweisen. Wenn ein Administrator eine Richtlinie für ein Team erstellt, das Zugriff auf die Databricks-Plattform anfordert, ist es daher unerlässlich, dass die Richtlinie eine Cluster-Tag-Erzwingung enthält, die spezifisch für das Team ist, dem die Richtlinie zugewiesen wird.
Hier ist ein Beispiel für die Erstellung einer Richtlinie mit einem benutzerdefinierten Kostenstellen-Tag, das erzwungen wird:
Sobald ein Tag zugewiesen ist, um das Team zu identifizieren, das den Cluster verwendet, können Administratoren die Nutzungsprotokolle analysieren, um die generierten DBUs und Kosten dem Team, das den Cluster nutzt, zuzuordnen. Diese Tags werden auch auf die VM-Nutzungsebene weitergegeben, sodass die Instanzkosten des Cloud-Anbieters ebenfalls dem Team oder der Kostenstelle zugeordnet werden können. Optionen zur Überwachung von Nutzungsprotokollen im Allgemeinen werden in einem Abschnitt weiter unten erläutert.
Ein wichtiger Unterschied bei Cluster-Tags, wenn ein Cluster-Pool verwendet wird, ist, dass nur die Cluster-Pool-Tags (und nicht die Cluster-Tags) auf die zugrunde liegenden VM-Instanzen weitergegeben werden. Die Erstellung von Cluster-Pools ist nicht durch Cluster-Richtlinien eingeschränkt, und daher sollte ein Administrator Cluster-Pools mit den entsprechenden Tags erstellen, bevor er Nutzungsp Berechtigungen an ein Team vergibt. Das Team kann dann über Richtlinien auf den entsprechenden Pool zugreifen, wenn es seine Cluster erstellt. Dies stellt sicher, dass die mit dem Team verbundenen Tags, das den Pool nutzt, für die Abrechnung auf die VM-Instanzebene weitergegeben werden.
Richtlinien-virtuelle Attribute
Außerhalb der Einstellungen, die auf der Cluster-Konfigurationsseite sichtbar sind, gibt es auch "virtuelle" Attribute, die durch Richtlinien eingeschränkt werden können. Insbesondere die beiden Attribute, die in dieser Kategorie verfügbar sind, sind "dbus_per_hour" und "cluster_type".
Mit dem Attribut "dbus_per_hour" können Ersteller von Clustern einige Flexibilität bei der Konfiguration haben, solange die DBU-Nutzung unter der in der Richtlinie festgelegten Einschränkung liegt. Dieses Attribut selbst schränkt die Kosten, die den zugrunde liegenden VM-Instanzen zugerechnet werden, nicht direkt ein, wie die zuvor diskutierten Attribute (obwohl DBU-Raten oft mit VM-Instanzraten korreliert sind). Hier ist ein Beispiel für eine Richtliniendefinition, die den Benutzer auf die Erstellung von Clustern beschränkt, die weniger als 10 DBUs pro Stunde verwenden:
Das andere verfügbare virtuelle Attribut ist "cluster_type", das verwendet werden kann, um Benutzer von verschiedenen Arten von Clustern auszuschließen. Die Typen, die über dieses Attribut zulässig sind, sind "all-purpose", "job" und "dlt", wobei sich letzteres auf Delta Live Tables bezieht. Hier ist ein Beispiel für die Verwendung dieser Richtlinie:
Cluster-Typ-Beschränkungen sind besonders wertvoll, wenn mit verschiedenen Teams gearbeitet wird, die am Lebenszyklus von Entwicklung und Bereitstellung beteiligt sind. Ein Team, das an der Entwicklung einer neuen ETL- oder Machine-Learning-Pipeline arbeitet, benötigt normalerweise nur Zugriff auf einen Allzweck-Cluster, während Bereitstellungs-Engineering-Teams Job-Cluster oder Delta Live Tables (DLT) verwenden würden. Diese Richtlinien können Best Practices erzwingen, indem sie sicherstellen, dass für jede spezifische Phase des Entwicklungs- und Bereitstellungslebenszyklus der richtige Cluster-Typ verwendet wird.
Eine häufige schlechte Praxis ist die Bereitstellung von automatisierten Workloads, die sich einen Allzweck-Cluster teilen. Auf den ersten Blick mag dies wie die günstigere Option erscheinen, da der Verbrauch einem einzigen Cluster zugeordnet werden kann. Diese Art von Konfiguration führt jedoch zu Ressourcenkonflikten, die die Laufzeit des Clusters verlängern und die Rechenkosten erhöhen. Stattdessen reduziert die Verwendung von Job-Clustern, die isoliert sind, um jeweils einen Job auszuführen, die für die Fertigstellung eines Satzes von Jobs erforderliche Rechenzeit. Dies führt zu geringerem Databricks DBU-Verbrauch sowie zu geringeren zugrunde liegenden Cloud-Instanzkosten. Bessere Leistung zusammen mit den niedrigeren Kosten pro DBU, die Job-Cluster bieten, führen zu dramatischen Kosteneinsparungen. Wir haben Kunden gesehen, die Zehntausende von Dollar gespart haben, indem sie nur zehn Prozent ihrer Workloads von Allzweck-Clustern auf Job-Cluster umgestellt haben. Die Wiederverwendung von Job-Clustern kann genutzt werden, um die rechtzeitige Fertigstellung eines Satzes von Jobs sicherzustellen, indem die Cluster-Startzeit zwischen den einzelnen Aufgaben entfällt.
Um Richtlinien zu formulieren, die es Teams ermöglichen, Cluster für die richtige Workload zu erstellen, gibt es einige Best Practices zu befolgen. Einige typische restriktive Richtlinienmuster sind Single-Node-Cluster, nur Job-Cluster oder Auto-Scaling-Allzweck-Cluster für Teams zur gemeinsamen Nutzung. Beispiele für vollständige Richtlinien finden Sie hier.
Cloud-Anbieterkosten
Aus Sicht des Databricks-Verbrauchs (DBUs) können alle Kosten den genutzten Computeressourcen zugeordnet werden. Kosten, die dem Netzwerk und Speicher der zugrunde liegenden Cloud zugerechnet werden, sollten jedoch ebenfalls berücksichtigt werden.
Speicher
Der Vorteil der Verwendung einer Plattform wie Databricks ist, dass sie nahtlos mit relativ kostengünstigem Cloud-Speicher wie ADLS Gen2 unter Azure, S3 unter AWS oder GCS unter GCP zusammenarbeitet. Dies ist besonders vorteilhaft bei der Verwendung des Delta Lake-Formats, da es Data Governance für eine ansonsten schwer zu verwaltende Speicherschicht sowie Leistungsoptimierungen bei der Verwendung in Verbindung mit Databricks bietet.
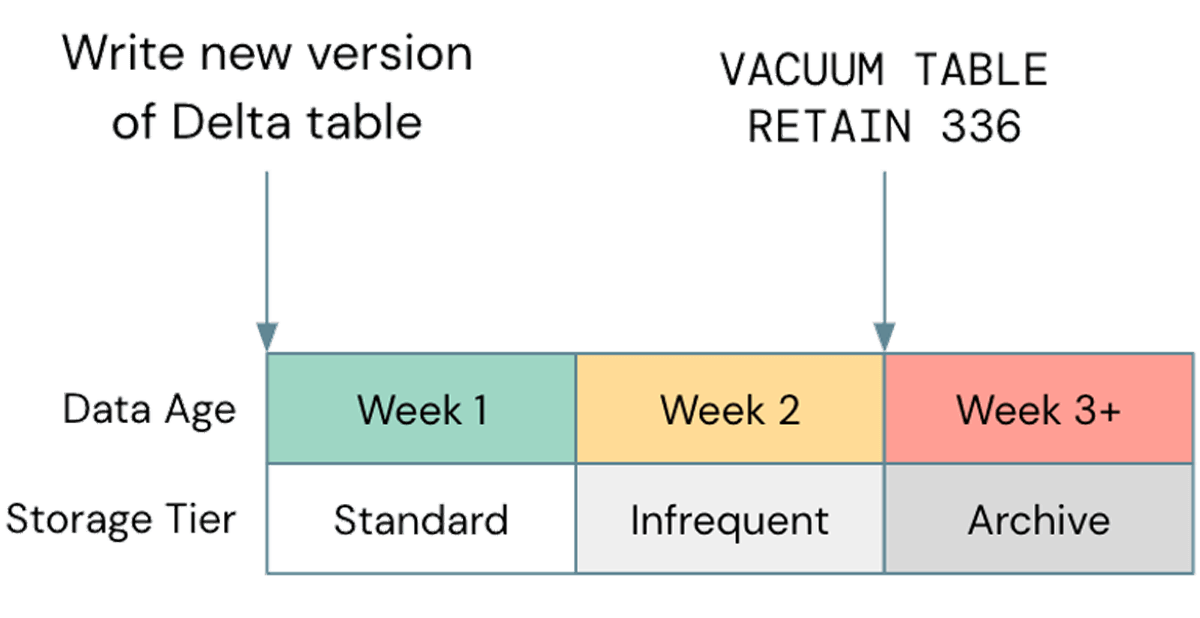
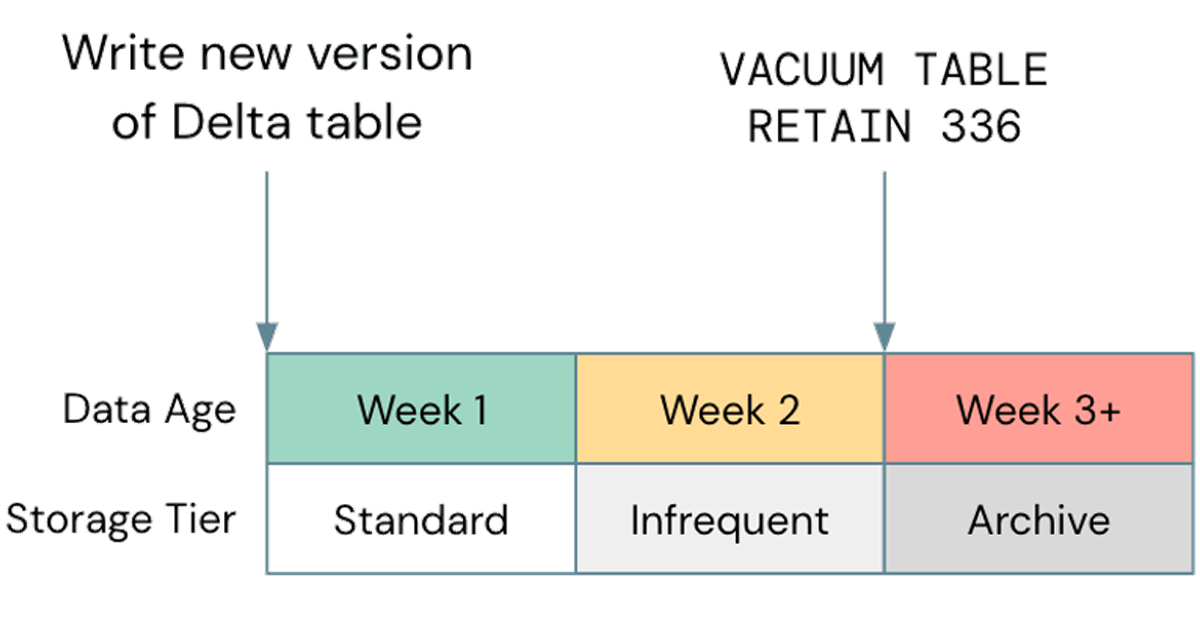
Eine häufige Fehloptimierung in Bezug auf den Speicher ist die Vernachlässigung der Nutzung des Lebenszyklusmanagements, wo immer möglich. In einem aktuellen Fall beobachteten wir einen Kunden-S3-Bucket, der etwa 2,5 PB groß war, wovon nur etwa 800 TB tatsächliche Daten waren. Die verbleibenden 1,7 PB waren versionierte Daten, die keinen Wert lieferten. Obwohl das Auslagern alter Objekte aus Ihrem Cloud-Speicher eine allgemeine Best Practice ist, ist es wichtig, dies mit Ihrem Delta Vacuum-Zyklus abzustimmen. Wenn Ihr Speicherlebenszyklus Objekte auslagert, bevor sie von Delta bereinigt werden können, können Ihre Tabellen beschädigt werden. Stellen Sie sicher, dass Sie alle Lebenszyklusrichtlinien auf Nicht-Produktionsdaten testen, bevor Sie sie weiter verbreiten. Eine Beispielrichtlinie könnte wie folgt aussehen:
{kind=link}
Beachten Sie, dass nicht standardmäßige Speicherklassen wie Glacier auf S3 oder Archive auf ADLS von Databricks nicht unterstützt werden. Stellen Sie daher sicher, dass Sie Vacuum verwenden, bevor diese Klassen verwendet werden.
Netzwerk
Daten, die innerhalb der Databricks-Plattform verwendet werden, können aus einer Vielzahl von Quellen stammen, von Data Warehouses bis hin zu Streaming-Systemen wie Kafka. Der häufigste Bandbreitennutzer ist jedoch das Schreiben in Speicherschichten wie S3 oder ADLS. Um Netzwerkkosten zu senken, sollten Databricks-Arbeitsbereiche mit dem Ziel bereitgestellt werden, die Datenmenge, die zwischen Regionen und Verfügbarkeitszonen übertragen wird, zu minimieren. Dies beinhaltet, wenn möglich, die Bereitstellung in derselben Region wie der Großteil Ihrer Daten und kann bei Bedarf die Einführung regionaler Arbeitsbereiche beinhalten.
Wenn Sie ein kundenverwaltetes VPC für einen Databricks-Workspace auf AWS verwenden, können die Netzwerkkosten durch die Nutzung von VPC-Endpunkten reduziert werden, die eine Konnektivität zwischen dem VPC und AWS-Diensten ohne Internet-Gateway oder NAT-Gerät ermöglichen. Die Verwendung von Endpunkten reduziert die Kosten für den Netzwerkverkehr und macht die Verbindung sicherer. Gateway-Endpunkte können speziell für die Verbindung mit S3 und DynamoDB verwendet werden, während Schnittstellen-Endpunkte ähnlich verwendet werden können, um die Kosten von Compute-Instanzen zu reduzieren, die sich mit der Databricks-Steuerungsebene verbinden. Diese Endpunkte sind verfügbar, solange der Workspace Secure Cluster Connectivity verwendet.
Ähnlich wie auf Azure können Private Link oder Service Endpoints für die Kommunikation von Databricks mit Diensten wie ADLS konfiguriert werden, um NAT-Kosten zu reduzieren. Auf GCP kann Private Google Access (PGA) genutzt werden, sodass der Datenverkehr zwischen Google Cloud Storage (GCS) und Google Container Registry (GCR) das interne Netzwerk von Google anstelle des öffentlichen Internets nutzt und somit auch die Verwendung eines NAT-Geräts umgeht.
Serverless Compute
Für Analyse-Workloads ist eine Option, die Sie in Betracht ziehen können, die Verwendung eines SQL Warehouse mit der aktivierten Serverless-Option. Mit Serverless SQL verwaltet die Databricks-Plattform einen Pool von Compute-Instanzen, die einem Benutzer zugewiesen werden können, sobald eine Workload gestartet wird. Daher werden die Kosten der zugrunde liegenden Instanzen vollständig von Databricks verwaltet, anstatt zwei separate Gebühren zu haben (d. h. die DBU-Compute-Kosten und die zugrunde liegenden Cloud-Compute-Kosten).
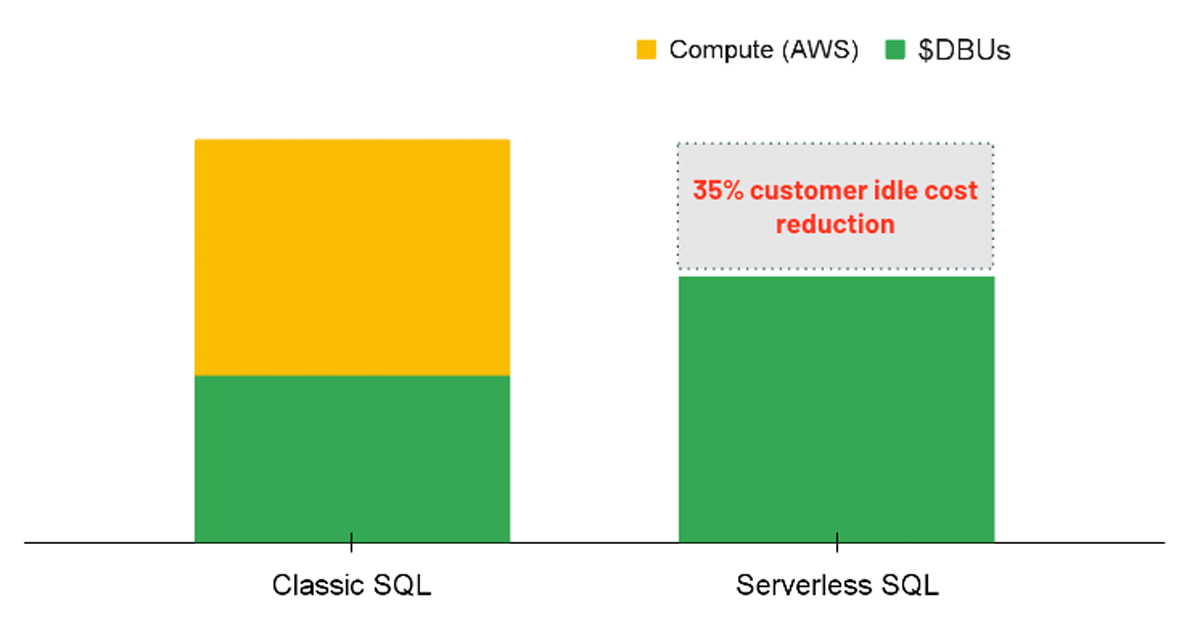
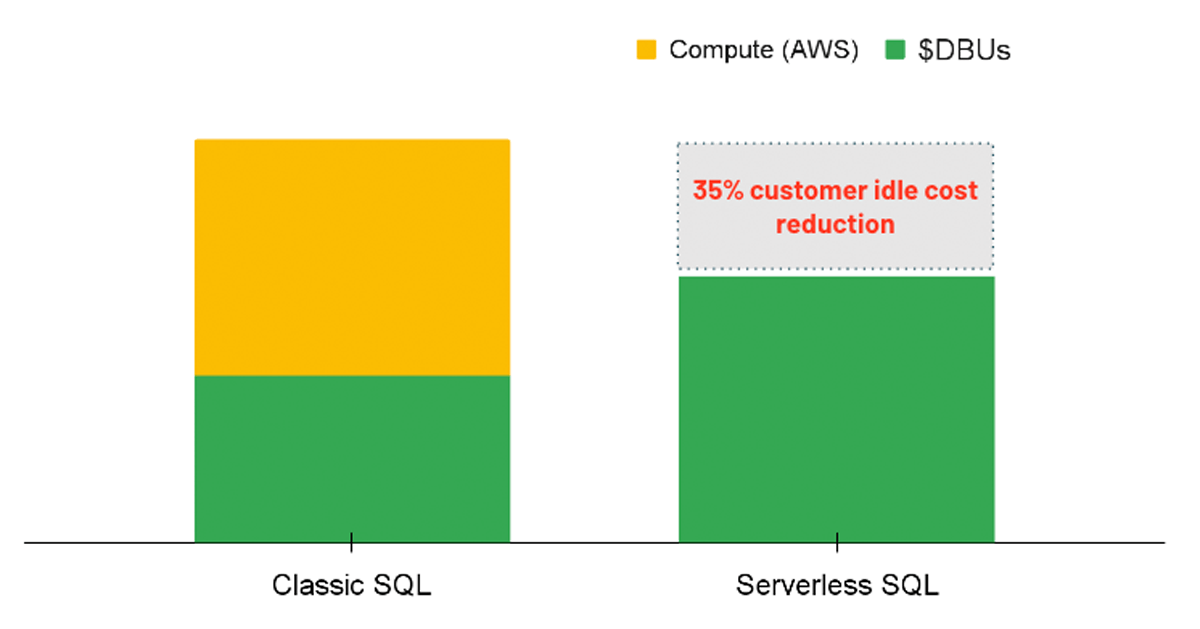{kind=link}
Serverless führt zu einem Kostenvorteil, indem sofortige Compute-Ressourcen bereitgestellt werden, wenn eine Abfrage ausgeführt wird, wodurch Leerlaufkosten von unterausgelasteten Clustern reduziert werden. In gleicher Weise ermöglicht Serverless eine präzisere automatische Skalierung, sodass Workloads effizient abgeschlossen werden können, was folglich durch verbesserte Leistung Kosten spart. Obwohl die Serverless-Option noch nicht direkt über eine Richtlinie erzwungen werden kann, können Administratoren die Option aktivieren für alle Benutzer mit Berechtigungen zur Erstellung von SQL Warehouses.
Nutzungsüberwachung
Neben der Kostenkontrolle durch Cluster-Richtlinien und Workspace-Bereitstellungskonfigurationen ist es für Administratoren ebenso wichtig, die Kosten überwachen zu können. Databricks bietet einige Optionen dafür mit Funktionen zur Automatisierung von Benachrichtigungen und Warnungen basierend auf Nutzungsanalysen. Insbesondere können Administratoren die Databricks Account Console für einen schnellen Nutzungsüberblick, Nutzungsprotokolle für eine detailliertere Ansicht analysieren und unsere neue Budgets API verwenden, um aktive Benachrichtigungen zu erhalten, wenn Budgets überschritten werden.
Verwendung der Account Console
Mit der Databricks Enterprise 2.0-Architektur enthält die Account Console eine Nutzungsseite, die es Administratoren ermöglicht, die Nutzung nach DBU oder Dollarbetrag visuell anzuzeigen. Das Diagramm kann den Verbrauch mit einer aggregierten Ansicht, gruppiert nach Workspace oder gruppiert nach SKUs anzeigen. Bei der Gruppierung nach SKUs wird die Nutzung beispielsweise nach Job-Clustern, Allzweck-Clustern oder SQL-Compute angezeigt. Wenn das Diagramm nach Workspace segmentiert ist, wird eine Gruppe für die Top-Neun-Workspaces nach DBU-Verbrauch angezeigt, wobei die letzte Gruppierung eine kombinierte Summe aller anderen Workspaces ist. Um die detaillierteren Informationen jedes einzelnen Workspaces einzeln zu verstehen, befindet sich am unteren Rand der Seite eine Tabelle, die jeden Workspace separat mit den DBU/USD-Beträgen nach SKU auflistet. Diese Seite eignet sich gut für Administratoren, um eine vollständige Übersicht über die Nutzung und Kosten über alle Workspaces eines Kontos zu erhalten.
Da Databricks ein First-Party-Dienst auf der Azure-Plattform ist, kann das Azure Cost Management-Tool verwendet werden, um die Databricks-Nutzung zu überwachen (zusammen mit allen anderen Diensten auf Azure). Im Gegensatz zur Account Console für Databricks-Bereitstellungen auf AWS und GCP bieten die Azure-Überwachungsfunktionen Daten bis zur Tag-Granularitätsebene. Benutzerdefinierte Tags in Azure können nicht nur auf Cluster-Ebene, sondern auch auf Workspace-Ebene erstellt werden. Diese Tags werden als Gruppen und Filter bei der Analyse der Nutzungsdaten angezeigt. Innerhalb dieser Berichte wird die von Databricks Compute generierte Nutzung zusammen mit der zugrunde liegenden Instanznutzung bequem in derselben Ansicht angezeigt. Protokolle können auch zeitgesteuert in einen Speichercontainer geliefert und für eine automatisierte Analyse und Benachrichtigungen verwendet werden, wie im nächsten Abschnitt erläutert.
Administratoren haben die Möglichkeit, Nutzungsprotokolle manuell aus der Account Console auf der Nutzungsseite oder mit der Account API herunterzuladen. Ein effizienterer Prozess zur Analyse dieser Nutzungsprotokolle ist jedoch die Konfiguration der automatischen Protokollbereitstellung in Cloud-Speicher (AWS, GCP). Dies ergibt eine tägliche CSV-Datei, die die Nutzung für jeden Workspace in einem detaillierten Schema enthält.
Sobald die Bereitstellung von Nutzungsprotokollen in einer der drei Clouds konfiguriert wurde, ist es eine gängige bewährte Methode, eine Datenpipeline innerhalb von Databricks zu erstellen, die diese Daten täglich aufnimmt und mit einem geplanten Workflow in einer Delta-Tabelle speichert. Diese Daten können dann für die Nutzungsanalyse oder zur Auslösung von Warnungen verwendet werden, die Administratoren oder Teamleiter, die für die Kostenstellenabrechnung verantwortlich sind, benachrichtigen, wenn der Verbrauch einen festgelegten Schwellenwert erreicht.
Budgets API
Eine bevorstehende Funktion, die die Budgetierung der Databricks-Compute-Kosten erleichtert, ist der neue Budget-Endpunkt (derzeit in der privaten Vorschau) innerhalb der Account API. Dies ermöglicht es jedem, der einen Databricks-Workspace verwendet, benachrichtigt zu werden, sobald ein Budgetschwellenwert für einen beliebigen benutzerdefinierten Zeitraum erreicht ist, gefiltert nach Workspace, SKU oder Cluster-Tag. Daher kann über diese API ein Budget für jeden Workspace, jede Kostenstelle oder jedes Team konfiguriert werden.
Zusammenfassung
Obwohl die Databricks Lakehouse Platform viele Anwendungsfälle und Benutzergruppen umfasst, ist es unser Ziel, ein einheitliches Set von Tools bereitzustellen, um Administratoren dabei zu helfen, Kostenkontrolle und Benutzererfahrung in Einklang zu bringen. In diesem Blog haben wir mehrere Strategien dargelegt, um diesen Ausgleich anzugehen:
- Verwenden Sie Cluster-Richtlinien, um zu steuern, welche Benutzer Cluster erstellen können und welche Größe und welchen Umfang diese Cluster haben
- Gestalten Sie Ihre Umgebung so, dass die von Databricks-Workspaces generierten Nicht-DBU-Kosten wie Speicher- und Netzwerkkosten minimiert werden
- Verwenden Sie Überwachungstools, um sicherzustellen, dass Ihre Kostenerwartungen erfüllt werden und dass Sie effektive Praktiken implementiert haben
Schauen Sie sich unsere anderen Blogs für Administratoren an, die in diesem Artikel verlinkt sind, und halten Sie Ausschau nach weiteren bevorstehenden Blogs. Probieren Sie auch neue Funktionen wie Private Link (AWS | Azure) und Budgetierung aus!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.