Lakeflow: Eine neue Ära des agentischen Data Engineerings
Die einheitliche Echtzeit-Datengrundlage, auf die Ihr Unternehmen vertrauen kann
von Bilal Aslam, Ray Zhu, Manish Dalwadi, Saad Ansari und Giselle Goicochea
- Einheitliches Fundament für agentenbasierte AI: Lakeflow vereinheitlicht Datenaufnahme, Transformation und Orchestrierung unter Unity Catalog. Dadurch wird die durch Tool-Wildwuchs entstehende Lücke geschlossen und AI-Agenten erhalten eine einzige Quelle für vertrauenswürdigen Echtzeit-Kontext.
- Leistungsstarke Datenaufnahme und Streaming: Verbinden Sie sich über Lakeflow Connect mit mehr als 100 Enterprise-Datenquellen, streamen Sie hochvolumige Event-Daten über mehrere Schnittstellen mit Zerobus Ingest und erreichen Sie Millisekunden-Latenzzeiten mit dem Real-Time Mode für Spark Declarative Pipelines.
- Agentenbasierte Entwicklung und Betrieb: Erstellen Sie Pipelines visuell mit dem Lakeflow Designer, beschleunigen Sie die Code-Erstellung mit Genie Code, reduzieren Sie den operativen Aufwand mit Genie ZeroOps und konsolidieren Sie veraltete Orchestratoren mit Lakeflow Jobs.
Alle Analysen, AI und Anwendungen beginnen mit Daten. In den letzten Jahrzehnten haben sich Data-Engineering-Tools über eine Vielzahl von Anwendungsfällen und Benutzer-Personas hinweg rasant verbreitet. Das führt dazu, dass die meisten Unternehmen am Ende einen sehr komplexen und fragmentierten Data Stack haben, der schwer zu integrieren, zu warten oder zu verwalten ist. Da AI alle Daten und AI-Praktiker unterstützt, wird der Druck auf diese instabilen Data Stacks noch weiter zunehmen.
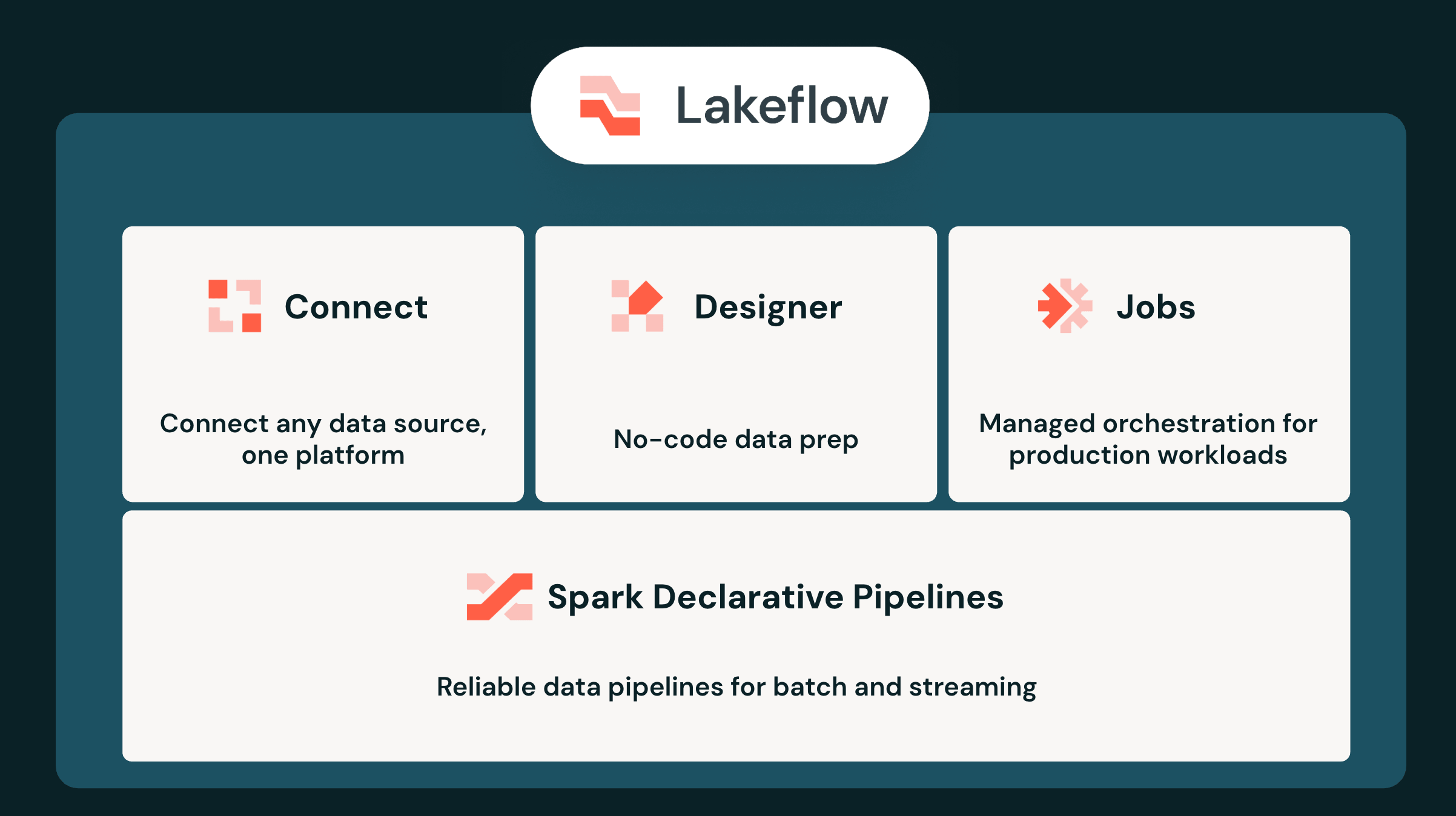
Aus diesem Grund haben wir uns das Ziel gesetzt, Databricks Lakeflow zu entwickeln – eine einheitliche Plattform für das gesamte Data Engineering, von der Ingestion über die Transformation bis hin zur Orchestrierung. Alle Lakeflow-Funktionen sind vollständig integriert und werden zentral über Unity Catalog verwaltet. In der Ära der KI-Agenten bietet diese einheitliche Architektur erhebliche Vorteile, da Agenten Ihre Datenpipelines nicht nur erstellen, sondern auch betreiben können. Heute kündigen wir auf dem Data + AI Summit die nächste große Entwicklungsstufe von Databricks Lakeflow an.
Genie Code und Lakeflow Designer: Pipeline-Entwicklung mit KI-Agenten
Genie Code ist jetzt tief in jeden Aspekt der Lakeflow-Benutzererfahrung integriert. Sie können Genie Code verwenden, um Ingestion-Konnektoren zu erstellen, Pipelines in Python und SQL zu bauen und Jobs mit Tasks, Triggern und Abhängigkeiten zu entwickeln. All dies wird durch den einheitlichen Data-Engineering-Stack ermöglicht, der Genie Code den vollständigen End-to-End-Kontext über Ihre Ingestion-, Transformations- und Orchestrierungs-Workloads hinweg zur Verfügung stellt.
Der jetzt allgemein verfügbare Lakeflow Designer demokratisiert das Data Engineering im gesamten Unternehmen. Diese visuelle, AI-gestützte No-Code-Benutzeroberfläche ermöglicht es Teams, Pipelines über eine Drag-and-Drop-Arbeitsfläche und Prompts in natürlicher Sprache zu erstellen. Business-Analysten und nicht-technische Anwender können produktionsbereite ETL-Pipelines erstellen, ohne Code schreiben zu müssen. Jeder im Designer erstellte visuelle Flow läuft nativ auf einer produktionsbereiten Spark Declarative Pipeline, was eine verlustfreie Übersetzung ohne komplexe Übergaben garantiert. Data Engineers können diesen Code ganz einfach direkt vor Ort überprüfen und verfeinern, ohne den Kontext wechseln oder die Logik neu schreiben zu müssen.
Genie ZeroOps: Daten- und AI-Betrieb auf Autopilot stellen
Das heute angekündigte Genie ZeroOps hilft Datenteams dabei, Daten- und AI-Assets in der Produktion zu betreiben. Genie ZeroOps ist ein speziell entwickelter AI-Hintergrundagent, der Daten- und AI-Assets überwacht und verwaltet. ZeroOps erkennt Fehler und führt Ursachenanalysen durch, um mithilfe von Datenqualitätsmetriken, Fehlerprotokollen und Lineage-Daten aus Unity Catalog festzustellen, was schiefgelaufen ist. Darüber hinaus generiert es Lösungsvorschläge und validiert diese in einer sicheren und isolierten Sandbox-Umgebung, die von Unity Catalog verwaltet wird. Die Anwendung einer Fehlerbehebung erfolgt mit „Human-in-the-loop“, sodass Genie ZeroOps die schwere Arbeit übernimmt und Sie die Kontrolle behalten. Ähnlich wie bei der Entwicklung mit KI-Agenten ist die Funktionalität von Genie ZeroOps nur dank des vollständigen Kontextbewusstseins und der End-to-End-Governance möglich, die ein einheitlicher Data Stack mit Lakeflow bietet.
Lakeflow Connect: Schnell wachsendes Ökosystem mit über 100 integrierten Konnektoren
Automatisierte Pipelines sind nur so wertvoll wie die Daten, die durch sie fließen. Um ein vollständiges "Unternehmensgedächtnis" aufzubauen und AI-Agenten wie Databricks Genie zu verankern, benötigen Sie nahtlosen Zugriff auf den neuesten verwalteten Kontext aus allen Bereichen Ihres Unternehmens. Lakeflow Connect vereinfacht diesen Prozess, indem es kontinuierlich neue Daten aus einer stetig wachsenden Liste von Unternehmenssystemen direkt in von Unity Catalog verwaltete Delta-Tabellen einliest.
Heute geben wir bekannt, dass Lakeflow Connect erweitert wird, um mehr als 100 native, verwaltete Konnektoren für Unternehmensanwendungen, Datenbanken, Dateiquellen und Cloud-Speicher zu unterstützen. Sie können nun auf instabile Drittanbieter-Tools verzichten und optimierte Ingestion-Pipelines für die Anwendungsfälle ausführen, die Kunden am dringendsten benötigen:
- Wissensmanagement im Unternehmen: Führen Sie Geschäftsdaten aus Jira (Beta), GitHub (Beta) und Confluence (GA) zusammen mit unstrukturierten Dokumenten, Verträgen und PDFs aus SharePoint (GA), Google Drive (Beta) und Outlook (Beta) zusammen. Betreiben Sie kontextbewusste AI-Anwendungen, Support-Agenten und intelligente Dokumentenverarbeitung auf einer einzigen Basis.
- MarTech: Laden Sie Kampagnen- und Kundendaten direkt aus Meta Ads (Beta), TikTok Ads (Beta), Google Ads (Beta) und HubSpot (GA), um Personalisierung in Echtzeit voranzutreiben.
- IT & Security Operations: Zentralisieren Sie Protokolle und Telemetriedaten für eine robuste SIEM-Analyse.
- Abfragebasierte Erfassung (Query-based Capture) für alle Datenbank-Konnektoren und Lakehouse Federation-Quellen (GA): Fragen Sie die Datenbank direkt für die Erfassung von Änderungen (Change Capture) ab, ohne dass Protokolle analysiert werden müssen.
Für Organisationen mit spezialisierten oder proprietären Systemen bieten Community Connectors (Beta) eine auf Databricks aufbauende Open-Source-Lösung. Stellen Sie einen vorgefertigten Konnektor aus der Community bereit oder erstellen Sie Ihren eigenen, um ihn in Ihrer Organisation oder dem breiteren Ökosystem zu teilen.
Panasonic nutzte Lakeflow Connect, um Daten aus SAP, Workday und SharePoint zusammenzuführen und ersetzte damit instabile Legacy-ETL-Systeme durch eine einzige Plattform für gesteuerte Echtzeit-Intelligence.
„Durch den Wechsel von einem starren Legacy-ETL-Stack zur Databricks-Plattform können unsere BI-Teams wichtige Daten jetzt ganz einfach finden und darauf zugreifen, was die Aktualisierungszeiten in Power BI um 50 % verkürzt. Wir verwandeln externe, inkonsistente Daten in vertrauenswürdige, produktionsreife Assets, die neue geschäftliche Erkenntnisse freisetzen und den Wettbewerbsvorteil von Panasonic stärken.“—Jerry Deng, BI Director, Panasonic
Zudem machen wir es Unternehmen leichter, die TCO für hochvolumige Ingestion mit dem Lakeflow Connect Free Tier dauerhaft zu senken. Kunden erhalten automatisch 100 kostenlose DBUs pro Tag, was bis zu 100 Millionen Datensätze täglich über beliebte verwaltete SaaS- und Datenbank-Konnektoren hinweg unterstützt.
Zerobus Ingest: Kafka-freie Ingestion für Ihre Datenproduzenten
Zerobus Ingest verändert die Art und Weise, wie Unternehmen hochvolumige Ereignisdaten verarbeiten – ganz ohne Message Bus. Mit Schreibvorgängen in Fast-Echtzeit in unter 5 Sekunden und einem hohen Durchsatz von bis zu 100 MB/s (über 10 GB/s pro Tabelle) liefert Zerobus Daten direkt und skalierbar an Ihre Plattform.
Leistung ist jedoch nur dann von Bedeutung, wenn sich Ihre Produzenten reibungslos verbinden können. Eine Migration sollte so einfach sein wie eine Konfigurationsänderung. Seit dem Erreichen der allgemeinen Verfügbarkeit (General Availability) Anfang des Jahres wurde Zerobus erweitert, um Ihre Datenproduzenten dort abzuholen, wo sie bereits arbeiten:
- Kafka-kompatible APIs (Beta): Ihre bestehenden Kafka-Produzenten übertragen Daten direkt an Databricks – ohne dass Codeänderungen erforderlich sind.
- gRPC- und REST-APIs (GA): Persistente gRPC-Streams für Hochleistungsanwendungen oder zustandslose REST-APIs für Webhooks und Serverless-Funktionen.
- SDK-Ökosystem (GA): Produktionsbereite SDKs für Python, Java, Rust, Go und TypeScript machen es einfach, Zerobus direkt in Ihre benutzerdefinierten Anwendungen einzubetten.
- OpenTelemetry (Public Preview): Senden Sie Metriken, Traces und Protokolle mit nur einer Konfigurationsänderung direkt an das Lakehouse.
Diese Flexibilität durch mehrere Schnittstellen bietet globalen Unternehmen eine direkte Brücke mit geringer Latenz zur Cloud. Beispielsweise nutzt Meta Zerobus Ingest, um seine On-Premises-Rechenzentren mit der Cloud zu verbinden, was eine schnelle Entwicklung datengesteuerter Lösungen in großem Maßstab ermöglicht.
„Wir haben unsere End-to-End-Pipeline-Latenz mit Zerobus Ingest und Spark Declarative Pipelines auf unter eine Minute verkürzt, was eine schnellere Wertschöpfung ermöglicht.“—Srikanth Sakhamuri, Data Engineering Leader, Meta
Sobald Daten in von Unity Catalog verwalteten Delta-Tabellen landen, sind sie sofort für nachgelagerte AI- und BI-Tools wie Databricks Genie verfügbar. Als Teil eines durchgängigen Echtzeit-Analysestacks erfasst Zerobus die Daten und verarbeitet sie im Real-Time Mode in Apache Spark™Declarative Pipelines (SDP), transformiert sie, und Lakehouse//RT, ein neuer Data-Warehouse-Typ, der auf einer vollständig nativen Echtzeit-Engine läuft, stellt sie mit einer Performance im Millisekundenbereich bereit.
Spark Declarative Pipelines: Batch und Streaming, SQL und Python und jetzt auch Echtzeit
Das Erreichen von Streaming mit extrem niedriger Latenz zwang Datenteams traditionell dazu, komplexe, fragmentierte Architekturen zu verwalten, was oft die Wartung einer zweiten spezialisierten Engine wie Apache Flink neben Spark erforderte. Databricks löste diese Komplexität von zwei Engines anfangs durch die Einführung des Real-Time Mode (RTM) für Spark Structured Streaming. Durch die Umstellung von periodischem Microbatching auf kontinuierliche Stream-Verarbeitung unterstützt RTM derzeit Pipelines für globale Marken wie Coinbase, DraftKings und MakeMyTrip.
Jetzt bringen wir dieselbe Leistung in unser vereinheitlichtes ETL-Produkt: Der Real-Time Mode (RTM) für Spark Declarative Pipelines ist jetzt in der Public Preview. RTM für SDP erreicht End-to-End-Latenzen von nur 5 Millisekunden, ohne die Komplexität und die Kosten für die Verwaltung separater Engines. Es ist sowohl auf klassischem als auch auf Serverless-Compute verfügbar und bietet Streaming mit extrem niedriger Latenz sowie die betrieblichen Vorteile von Spark Declarative Pipelines: versionslose Ausführung, automatisierte Infrastruktur-Upgrades und Wartung mit minimaler bis gar keiner Ausfallzeit.
Als Nächstes machen wir die deklarativen APIs von Spark Declarative Pipelines – einschließlich Append, Auto CDC, incremental Replace Where und Materialized View – überall auf der Databricks-Plattform verfügbar. Das bedeutet, dass Benutzer die inkrementelle Datenverarbeitung direkt aus dem Produkt, dem Compute-Typ und der Benutzeroberfläche nutzen können, die sie bereits kennen. Alle diese APIs sind ab sofort in Databricks SQL verfügbar und werden in den nächsten Wochen auch in Serverless Notebooks und im Lakeflow Designer verfügbar sein.
Lakeflow Jobs: Jetzt mit über 50 Integrationen
Die Orchestrierung sollte nicht der schwierigste Teil der Verwaltung Ihrer Datenpipeline sein. Unabhängig davon, ob Sie komplexe Produktions-DAGs ausführen, Zeitpläne erstellen oder AI-Agents starten, ist Lakeflow Jobs die native Orchestrierungs-Engine von Databricks, die all diese Aufgaben übernimmt. Durch die Integration von verwalteter Orchestrierung und End-to-End-Beobachtbarkeit in jede Ebene des Datenlebenszyklus konsolidieren Datenteams ältere Orchestratoren wie Apache Airflow auf einer einzigen, einheitlichen Plattform.
Daten- und kontextbewusste Orchestrierung
Jeder Cron-Zeitplan ist nur eine Vermutung darüber, wann Daten bereit sind. Mit Lakeflow Jobs müssen Sie nicht mehr raten, sondern können Pipelines basierend auf der tatsächlichen Datenbereitschaft auslösen. In einfachem Englisch können Sie Genie bitten, die SQL-Trigger zu schreiben, die definieren, was „bereit“ für Ihre Daten bedeutet. Ihr Job wird ausgeführt, sobald die Bedingungen erfüllt sind. Dabei werden Ihre Data Contracts eingehalten und sichergestellt, dass Sie niemals veraltete Daten verarbeiten.
„Mit Lakeflow Jobs konnten wir auf Daten zugreifen, die mit älteren Technologien nicht erreichbar waren, was uns in die Lage versetzte, tiefere und zuverlässigere geschäftliche Erkenntnisse zu gewinnen.“—Sachin Wadhwa, Director of Data Architecture and Platforms, The Rank Group
Universelle Orchestrierung für alles und überall
Für Kunden mit Daten-Workflows außerhalb von Databricks bietet Lakeflow Jobs External Orchestration, um Ihre Reichweite nativ auf externe Systeme auszudehnen, ohne dass Sie Integrationen von Grund auf neu erstellen müssen. Durch die Verwendung eines offenen Operator-Frameworks können Sie nahtlos Snowflake-Jobs auslösen, benutzerdefinierte REST-APIs aufrufen oder Slack- und PagerDuty-Benachrichtigungen verwalten. Compute-Ressourcen werden intelligent pausiert, während auf externe Bedingungen gewartet wird, die unter Umständen erst in einigen Stunden eintreffen. Wir veröffentlichen über 40 Operator-Beispiele auf GitHub und werden in den kommenden Quartalen Dutzende von verwalteten Integrationen hinzufügen. Darüber hinaus fließen alle Anmeldeinformationen durch den Unity Catalog und verfügen über einen vollständigen Audit-Trail.
Erste Schritte mit Lakeflow
Lakeflow bietet die einheitliche Datengrundlage, die Sie für die Erstellung zuverlässiger, agentenbasierter AI-Anwendungen benötigen. Um tiefer in die technischen Konfigurationen einzusteigen und diese neuen Funktionen in Aktion zu sehen, erkunden Sie unsere praktischen Tutorials oder lesen Sie unsere technische Dokumentation, um mit Ihrem nächsten Projekt zu beginnen.
Bereit loszulegen? Testen Sie Databricks kostenlos, um Lakeflow noch heute zu erleben.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.