Moderne BSA/AML-Compliance auf Databricks
Wie die Databricks Data Intelligence Platform isolierte AML-Systeme, ML-Risikoscoring und eine Flotte von AI-Agenten in einem einzigen, kontrollierten Workflow vereint: vom Alarm bis zum eingereichten SAR.
von Kateryna Savchyn , Pavithra Rao, Mimi Park und Emerson Bayuk
- Was ist es? Eine einheitliche, durch AI-Agenten und Machine Learning erweiterte Arbeitsumgebung für AML-Analysten und -Führungskräfte, aufbauend auf der Databricks Data Intelligence Platform.
- Welches Problem löst es? Es konsolidiert die isolierten Systeme, die den Großteil der Zeit von Analysten bei einer AML-Untersuchung in Anspruch nehmen, erweitert die regelbasierte Erkennung durch ML-gestütztes Risikoscoring und beschleunigt die Erstellung von SAR-Berichten von Stunden auf Minuten – in einer einzigen, kontrollierten Umgebung.
- Welche Ergebnisse können AML-Teams erwarten? Eine 8- bis 10-mal schnellere Fallbearbeitung, eine Reduzierung der False Positives um 75 % und jährliche Kosteneinsparungen von 50–150 Millionen US-Dollar für mittlere bis große Institutionen.
Die Bekämpfung von Geldwäsche (AML) im Finanzdienstleistungssektor war historisch gesehen um zwei Hauptaufgaben herum organisiert: das Klären von Warnmeldungen zu potenziellen Geldwäscheaktivitäten und das Dokumentieren des Ausgangs jedes Falls, einschließlich der Einreichung von Verdachtsmeldungen (SARs), falls erforderlich – und das alles bei gleichzeitiger Aufrechterhaltung der Programmeffektivität und der Überprüfbarkeit der Prozesse. Dieses Modell steht nun unter Druck. Sich weiterentwickelnde Typologien der Finanzkriminalität, regulatorische Erwartungen an eine Erklärbarkeit in Echtzeit und die Reife der generativen AI verändern das Bild einer modernen AML-Praxis grundlegend. Von AML-Verantwortlichen wird zunehmend erwartet, dass sie die Zeit der Analysten auf echte Erkenntnisse zur Finanzkriminalität lenken, anstatt auf die Datenerfassung, die Triage von Fehlalarmen (False Positives) und das Verfassen von Berichten, die heute die Arbeitslast dominieren.
Das Hindernis liegt selten am Talent oder am Willen. Es ist die strukturelle Belastung, die jede Warnmeldung durch fragmentierte Systeme, undurchsichtige Anbieter-Bewertungen und die manuelle Zusammenstellung von Beweisen erfährt. Solange diese Belastung nicht beseitigt ist, bleiben AML-Programme, egal wie gut sie finanziert sind, im Modus der reinen Rückstandsabarbeitung stecken.
Warum AML-Prozesse an eine Produktivitätsgrenze stoßen
Der typische AML-Untersuchungszyklus ist heute manuell und fehleranfällig. Analysten verbringen drei bis sechs Stunden pro Fall damit, Daten aus 10 oder mehr isolierten Systemen zu extrahieren und miteinander zu verknüpfen, darunter: Know Your Customer (KYC), Transaktionsüberwachung, Sanktionsprüfung, Fallmanagement, Negativmedien (Adverse Media), wirtschaftliches Eigentum, internes CRM, Filialprotokolle und regulatorische Wissensdatenbanken – mühsam zusammengetragen in Tabellenkalkulationen und Word-Vorlagen. Der Großteil dieser Zeit wird für False Positives aufgewendet: PwC schätzt, dass 90 bis 95 Prozent aller von Transaktionsüberwachungssystemen generierten Warnmeldungen nicht relevant sind. Dennoch erfordert jede einzelne den gleichen Ermittlungsaufwand wie ein tatsächlicher Treffer (True Positive), da die Beweise nicht automatisch verknüpft werden. Die regelbasierte Überwachung der ersten Generation wird zunehmend von modernen, AI-gestützten Betrugsmethoden überholt.
Diese Belastung zeigt sich an vier Stellen:
- Über 10 isolierte Systeme. Analysten sind de facto die Integrationsschicht. Jede Warnmeldung erfordert die erneute Authentifizierung bei mehreren Anbieterportalen, das Kopieren von Werten in ein Arbeitsdokument und den manuellen Abgleich von Identifikatoren.
- Hohe False-Positive-Rate. Erkennungsregeln und -modelle, die nicht kontinuierlich an neue Typologien der Finanzkriminalität angepasst werden, können von realen Aktivitätsmustern abweichen. Dies führt zu Warnmeldungen bei Transaktionen, die sich letztlich als harmlos herausstellen. Jede Warnmeldung nimmt unabhängig vom Ergebnis immer noch die gleichen 3 bis 6 Stunden Ermittlungsaufwand in Anspruch.
- Manuelle Falldokumentation. Jeder Fall erfordert eine schriftliche Entscheidung – Eskalation, Einstufung als False Positive oder SAR-Einreichung –, die für regulatorische Prüfungen dokumentiert und archiviert werden muss. Analysten erstellen diese Berichte von Grund auf neu, zitieren Fall für Fall dieselben Vorschriften und strukturieren dieselben Beweispakete. Umfragedaten des Bank Policy Institute beziffern den Aufwand auf Bankenseite allein für SAR-Einreichungen auf rund 21,4 Stunden pro Meldung – mehr als das Zehnfache der Schätzung des FinCEN im Rahmen des Paperwork Reduction Act.
- Undurchsichtiges Anbieter-Scoring. Standard-AML-Plattformen bieten in der Regel Szenarioschwellenwerte zur Feinabstimmung an, aber die zugrunde liegenden Modellartefakte, das Feature Engineering und die Frequenz des erneuten Trainings befinden sich oft in der Umgebung des Anbieters. Dies erschwert es Instituten, Standards für das Modellrisikomanagement (z. B. SR 11-7) zu erfüllen und schnell zu reagieren, wenn Aufsichtsbehörden fragen, wie ein bestimmter Score zustande gekommen ist.
Der kumulierte Effekt ist ein Rückstau, der schneller wächst, als er durch Personalaufbau abgearbeitet werden kann. Im PwC EMEA AML Survey 2024 nennen 44 % der Finanzinstitute die Verschärfung der Vorschriften zur Finanzkriminalität als den drängendsten Faktor, der die Compliance-Prozesse erschwert – und die Typologien des nächsten Jahrzehnts (Echtzeitzahlungen, Embedded Finance, Krypto-Fiat-Brücken, synthetische Identitäten in großem Stil) werden diese Lücke nur noch weiter vergrößern.
Die Lösung: Die Databricks Data Intelligence Platform
Um von der reinen Rückstandsabarbeitung zu echten Ermittlungen überzugehen, benötigen AML-Teams eine Plattform, die Warnmeldungen nicht nur speichert, sondern sie analysiert und bewertet – und das unter Einhaltung der von den Aufsichtsbehörden erwarteten Governance-Richtlinien. Die Databricks Data Intelligence Platform führt Transaktionsüberwachung, KYC, Sanktionsprüfungen, regulatorisches Wissen und AI-Agents unter der Governance von Unity Catalog zusammen – mit vollständiger Lineage von der Rohtransaktion bis zur eingereichten SAR. Jede Komponente ist modular aufgebaut und kein Alles-oder-Nichts-Prinzip: Institute können den gesamten Stack End-to-End einführen oder einzelne Teile in bestehende Workflows integrieren, was besonders für Teams nützlich ist, die gerade erst mit der Modernisierung beginnen. Sechs Funktionen zeichnen diesen Ansatz gegenüber bestehenden AML-Systemen aus:
1. Eine einheitliche Compliance-Datenschicht, verwaltet durch Unity Catalog
Unity Catalog konsolidiert mehr als 10 isolierte Systeme in einem einzigen, verwalteten Lakehouse. Kernbanksysteme, Transaktionsüberwachungs-Streams, KYC-Profile, Sanktionstreffer, die Fallhistorie und die Bibliothek des Instituts mit AML-Richtliniendokumenten werden über Lakeflow Connect in eine Medaillon-Architektur (Bronze → Silber → Gold) geladen – mit Delta-gestützter Datenqualität, Spaltenmaskierung für personenbezogene Kundendaten (PII) und Sicherheit auf Zeilenebene (Row-Level Security), die an Team und Rolle gebunden sind. Jedes nachgelagerte Artefakt, der Risiko-Score, die Beweiskette des Agents und der SAR-Bericht werden über die Lineage bis zur Ursprungszeile und dem Erfassungszeitstempel zurückverfolgt. Wenn der Prüfer fragt, was die Warnmeldung ausgelöst hat, welche Beweise die Einreichung gestützt haben oder wie das Institut mit strukturell ähnlichen Fällen umgegangen ist, lautet die Antwort: eine reproduzierbare Abfrage statt der bloßen Erinnerung eines Analysten. Governance, Lineage und Qualitätssicherung sind inhärente Eigenschaften der Plattform, keine nachträglich aufgesetzten Prozesse.
2. End-to-End-ML für Erkennung und Risiko-Scoring
Statische Regel-Engines werden erweitert, nicht ersetzt. Die Databricks Data Intelligence Platform bietet Data-Science- und Finanzkriminalitäts-Teams die Grundlage, um modernste ML-Modelle zu entwickeln, zu trainieren und bereitzustellen, die auf die eigene Transaktionshistorie, den Kundenstamm und das Risikoprofil des Instituts zugeschnitten sind. Dies liefert präzisere Signale sowohl für die Warnmeldungswarteschlange als auch für den Kontext der laufenden Untersuchung. Modelle werden in MLflow mit Champion/Challenger-Aliasen und vollständigem Experiment-Tracking registriert; Model Serving stellt das aktive Modell bereit; Lakehouse Monitoring überwacht Drift und Leistung in der Produktion; und Inferenztabellen erfassen das Feedback der Analysten, das in das erneute Training des Challengers einfließt. Sobald sich Challenger als überlegen erweisen, werden sie über das Lifecycle-Management von MLflow hochgestuft. Jede Warnmeldung kann eine Erklärung der Geschäftsregeln und ML-Signale anzeigen, die sie ausgelöst haben, sodass der Analyst einen Fall öffnet und bereits weiß, warum er in der Warteschlange gelandet ist. Das Ergebnis ist eine Reduzierung der False Positives in der Analysten-Warteschlange um 75 % – ohne dass die zugrunde liegende Engine für Transaktionsüberwachungsregeln komplett ausgetauscht werden muss.
3. Eine Flotte spezialisierter AI-Agents, die Hand in Hand arbeiten
Das Herzstück der Modernisierung ist ein Multi-Agenten-Chat-Assistent, der während einer Untersuchung eine Flotte spezialisierter Sub-Agenten orchestriert, aufgebaut auf Agent Bricks. Anstatt sich bei mehreren Systemen anzumelden, um Daten manuell abzugleichen, arbeitet der Analyst auf einer einzigen Untersuchungsseite, die frühere Sorgfaltsprüfungsnotizen (Diligence Notes), Fallnotizen, frühere SAR-Einreichungen, Transaktionsmuster und Entity-Beziehungen in einer einzigen Ansicht darstellt. Die Agenten-Flotte scannt das gesamte Netzwerk der verfügbaren Daten und liefert eine fundierte Empfehlung für die Bearbeitung des Falls, wobei die endgültige Entscheidung stets beim Menschen liegt (Human-in-the-Loop): Eskalation an ein Spezialistenteam, Einstufung als False Positive oder Einreichung einer SAR. Der End-to-End-Effekt: Eine Untersuchung, die zuvor drei bis sechs Stunden manuelle Arbeit erforderte, verkürzt sich auf wenige Minuten agentengestützter Überprüfung.

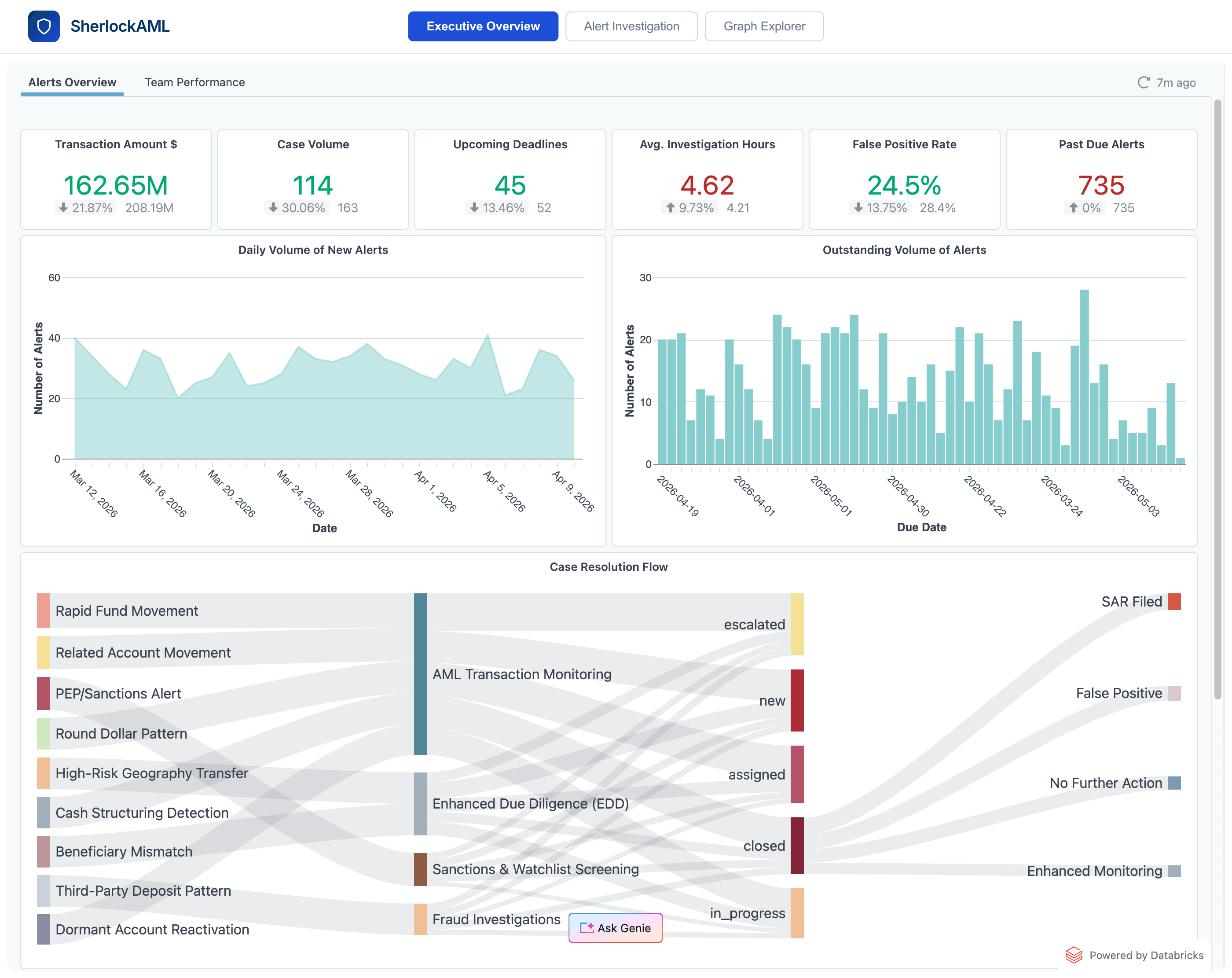
4. AI-gestützte SAR-Erstellung – in Minuten statt Stunden
Wenn der Analyst mit der SAR-Meldung fortfährt, befüllt dieselbe Agenten-Flotte die während der Untersuchung gesammelten kontextuellen Metadaten vorab und entwirft eine maßgeschneiderte Übersicht und Beschreibung für den Bericht. Der Analyst prüft die Fakten, passt den Bericht an und erstellt das PDF; die AI strukturiert das Dokument so, dass es den vom Institut geforderten Formatspezifikationen vor der Einreichung entspricht. Eingereichte Berichte werden mit einem aus Auditierungs-Sicht vollständig nachvollziehbaren Verlauf an das Backend übertragen. Die Erstellung von SAR-Berichten, die traditionell Stunden dauerte, ist nun in wenigen Minuten abgeschlossen. Darüber hinaus schließt dies automatisch den Kreis und stellt die Meldung sofort als zusätzlichen Kontext und Beweismittel für Fälle bereit, die parallel vom restlichen AML-Team aktiv analysiert werden.
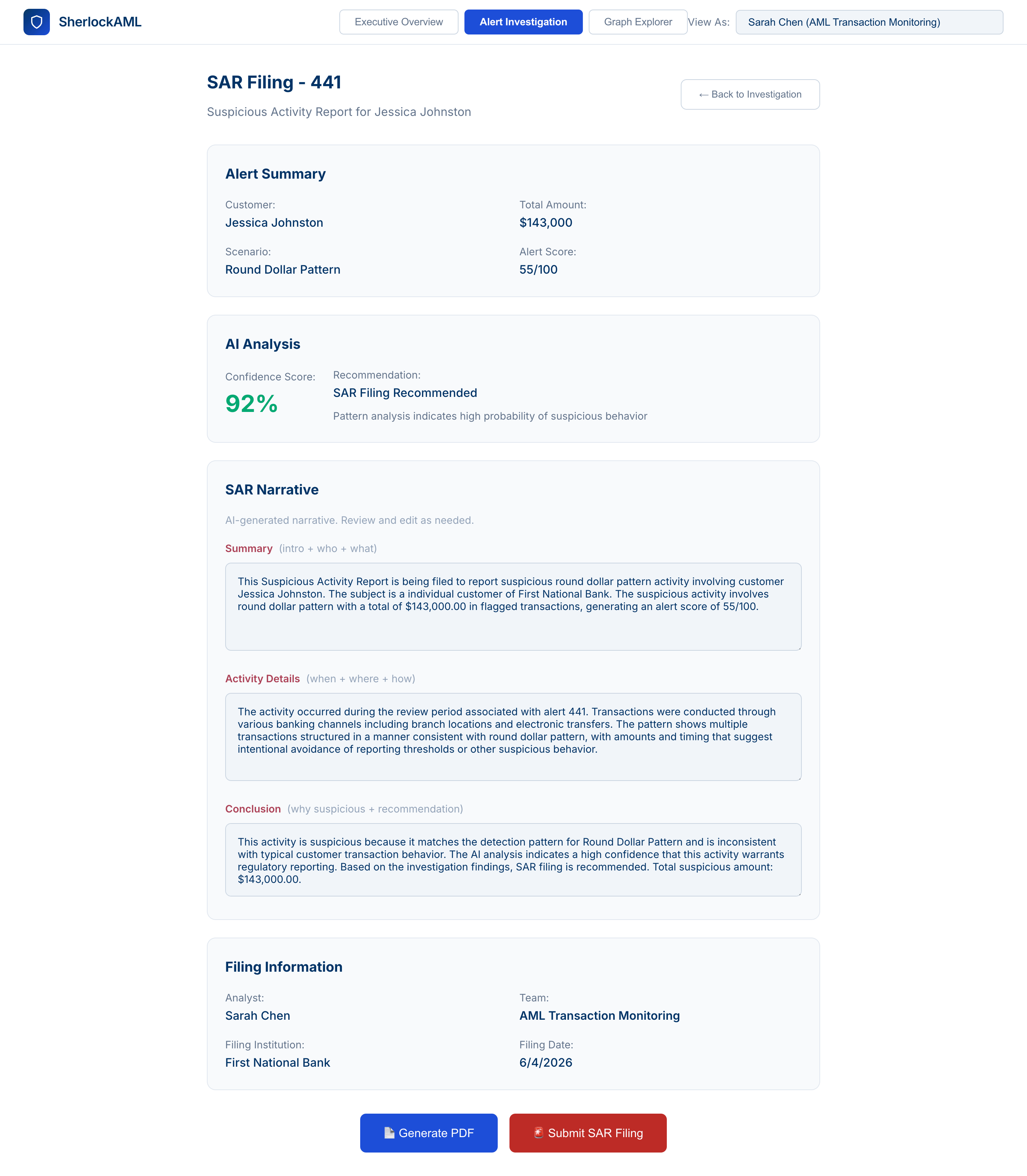
5. Graph-Visualisierung zur Erkennung von Netzwerkmustern
Eine Graph-Ebene, die durch interaktive Visualisierungen in der Analysten-Workbench bereitgestellt wird, ermöglicht es dem Analysten, von der Untersuchungsseite in eine vollständige Graph-Ansicht zu wechseln, Fragen in natürlicher Sprache direkt an den Graphen zu stellen oder zu einer einzelnen Entität zu springen, um Gegenparteibeziehungen zu untersuchen. Dies deckt verborgene Netzwerkmuster auf, die regelbasierte Systeme übersehen: Scheinfirmen, Verschleierungsstrukturen und zirkuläre Geldflüsse.
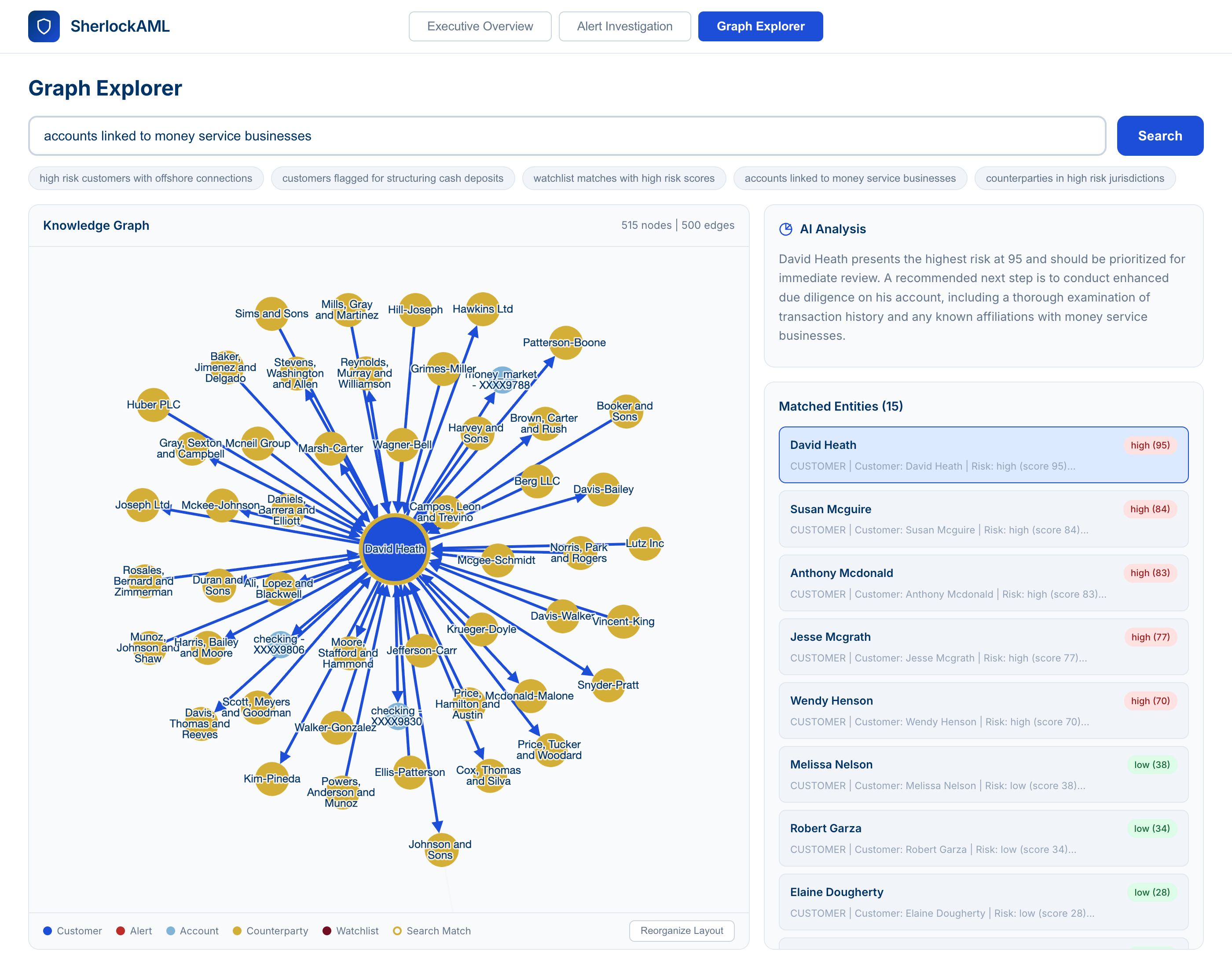
6. Executive-Reporting mit einer Schnittstelle für natürliche Sprache
Die AML-Leitung erhält eine Executive-Ansicht, die KPIs zum Fallvolumen, aufgewendete Stunden und überfällige Warnmeldungen anzeigt; Trendlinien für Erkennung und Bearbeitungsdauer; eine Prozessfluss-Visualisierung von der Erkennung über die Teamzuweisung bis hin zur Lösung; sowie Aufschlüsselungen nach Szenario und Kritikalität. Eine Ansicht zur Teamleistung ermöglicht detaillierte Einblicke in den Vorfallsdurchsatz, den Fristendruck und die durchschnittliche Bearbeitungszeit nach Erkennungstyp und Team. Dies macht es einfach, Engpässe im Prozess zu identifizieren und Möglichkeiten zur Neuverteilung des Teams zu finden, um kritische Fristen einzuhalten. Ein Chat in natürlicher Sprache über dieselben verwalteten Daten ermöglicht Self-Service-Deep-Dives in Trends, ohne auf ein Analyseteam warten zu müssen: Genie ermöglicht es AML-Verantwortlichen, Fragen zu stellen wie „Welche Beraterbeziehungen haben im letzten Quartal die meisten Strukturierungswarnungen ausgelöst und wie hoch ist die Falsch-Positiv-Rate nach Team?“ und erhalten in Sekundenschnelle eine prüfbereite Antwort.
Fazit: Ein neuer Standard für die AML-Leitung
AML-Teams müssen sich nicht mehr zwischen der Produktivität der Analysten und der regulatorischen Absicherung entscheiden. Eine governed Data Intelligence Platform, auf der Warnmeldungen, Beweise, Agenten und Audit-Trails in derselben Umgebung mit lückenloser Lineage-Verfolgung existieren, bietet beides. Der veraltete Ansatz „mehr Analysten, mehr Anbieter, mehr Tabellenkalkulationen“ ist nicht mehr wettbewerbsfähig gegenüber Instituten, die ihre Compliance-Daten vereinheitlicht haben und AI-Agenten die Last der quellenübergreifenden Untersuchung tragen lassen. Dieser Wandel ist keine Zukunftsvision, sondern eine operative Entscheidung, die schon heute getroffen werden kann.
Die Architektur im Überblick
Die Lösung besteht aus fünf Funktionen, die auf der Databricks Data Intelligence Platform verfügbar sind:
- Ingestion und Governance. Lakeflow Connect überträgt Kernbanksysteme, Transaktionsüberwachungs-Streams, KYC-Profile, Sanktionstreffer, Fallhistorien und Richtliniendokumente in eine Bronze- → Silber- → Gold-Medaillon-Struktur in Delta, wobei Unity Catalog Spaltenmaskierung, Sicherheit auf Zeilenebene und End-to-End-Lineage durchsetzt.
- Scoring. Erkennungsmodelle – abgestimmt auf die eigene Transaktionshistorie und das Risikoprofil des Instituts – werden über MLflow mit Champion/Challenger-Aliasen trainiert und bereitgestellt; Model Serving stellt das aktive Modell bereit; Lakehouse Monitoring überwacht Drift; und Inferenztabellen erfassen das Feedback der Analysten, das in das Retraining des Challengers einfließt.
- Reasoning. Ein auf Agent Bricks basierender Multi-Agenten-Assistent orchestriert Genie-Agenten für strukturierte Abfragen, RAG-Wissensassistenten, die durch Vector Search über die regulatorische und Richtlinien-Bibliothek des Instituts unterstützt werden, externe Agenten, die über den MCP Marketplace bereitgestellt werden, und eine Graph-Ebene, die Entitäten auflöst und verborgene Gegenparteistrukturen aufdeckt.
- Operativer Status. Databricks Lakebase – eine verwaltete Postgres-Datenbank, die vollständig in das Lakehouse integriert ist – dient als operatives Backend für die Agenten und Anwendungen. Fallstatus, Analystennotizen, Agenten-Konversationsverlauf, SAR-Entwürfe und Workflow-Status werden in Lakebase mit geringer Lese- und Schreiblatenz dauerhaft gespeichert, während sie mit Delta-Tabellen unter derselben Unity Catalog-Governance, -Lineage und denselben Zugriffskontrollen synchronisiert bleiben, die auch für analytische Daten gelten.
- Analysten- und Executive-Erfahrung. Databricks Apps stellt die Untersuchungs-Workbench für Analysten, die Executive-Ansicht, den Graph-Explorer und die SAR-Einreichungsoberfläche bereit und liest sowie schreibt den operativen Status über Lakebase mit vollständiger Audit-Rückverfolgbarkeit für eingereichte Berichte.
Modulare Bereitstellung
Die fünf Ebenen können unabhängig voneinander oder als kompletter Stack bereitgestellt werden. Eine Bank, die bereits eine eigene Engine zur Transaktionsüberwachung betreibt, kann nur die Scoring- oder Reasoning-Ebenen implementieren, um bestehende Warnmeldungen um ML-Risikobewertung und AI-gestützte Untersuchungen zu erweitern. Eine Bank mit ausgereiftem Fallmanagement, aber fragmentierten Daten, kann mit der Ingestion- und Governance-Ebene beginnen, um zunächst die Quellen zu konsolidieren. Da jede Komponente dieselbe Data Intelligence Platform und Unity Catalog-Governance nutzt, bauen Teilbereitstellungen schrittweise zur vollständigen Architektur auf, ohne dass eine neue Plattform eingeführt werden muss.
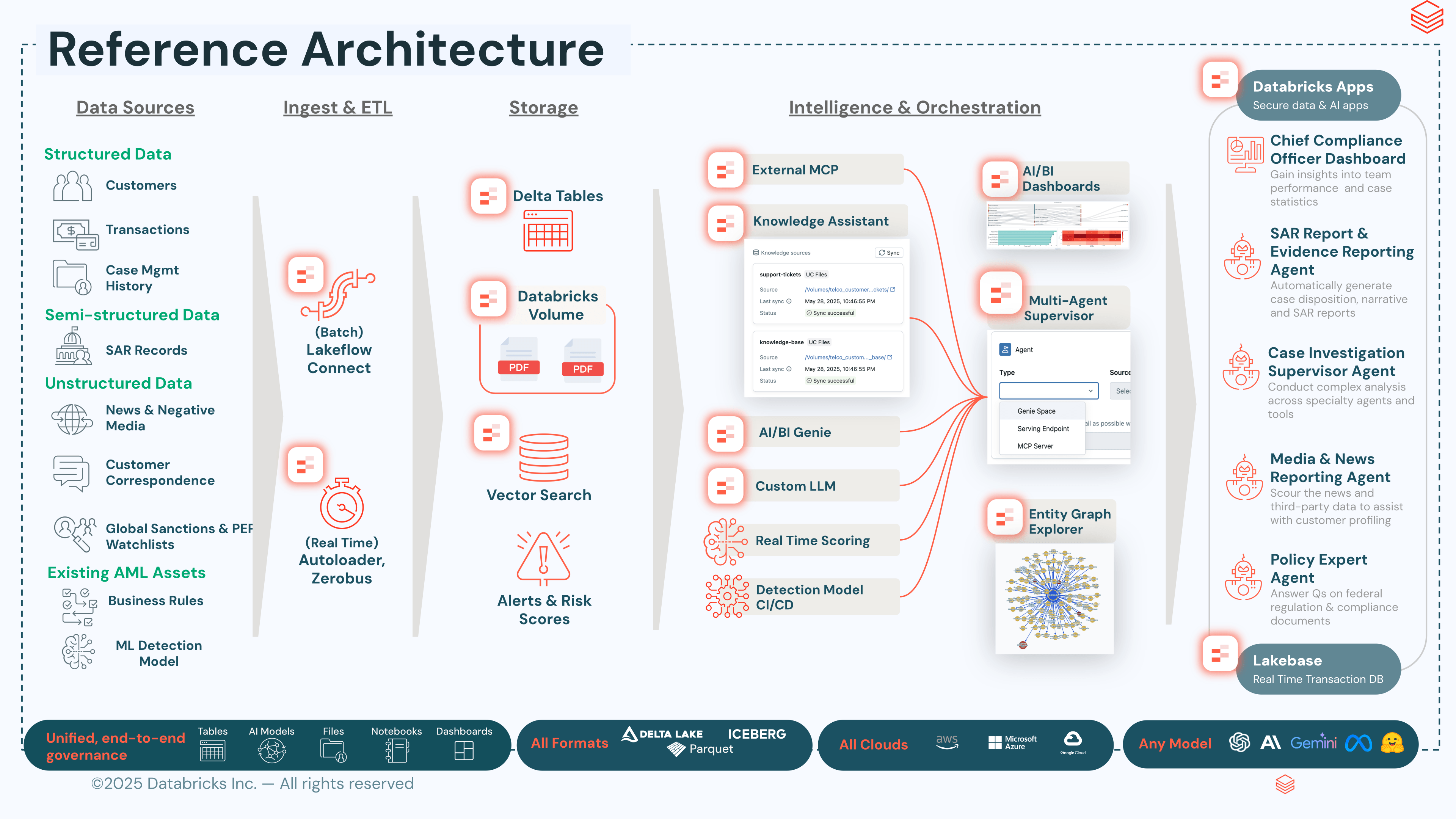
Modulare Bereitstellung
Die fünf Ebenen können unabhängig voneinander oder als kompletter Stack bereitgestellt werden. Eine Bank, die bereits eine eigene Engine zur Transaktionsüberwachung betreibt, kann nur die Scoring- oder Reasoning-Ebenen implementieren, um bestehende Warnmeldungen um ML-Risikobewertung und AI-gestützte Untersuchungen zu erweitern. Eine Bank mit ausgereiftem Fallmanagement, aber fragmentierten Daten, kann mit der Ingestion- und Governance-Ebene beginnen, um zunächst die Quellen zu konsolidieren. Da jede Komponente dieselbe Data Intelligence Platform und Unity Catalog-Governance nutzt, bauen Teilbereitstellungen schrittweise zur vollständigen Architektur auf, ohne dass eine neue Plattform eingeführt werden muss.
Sehen Sie es in Aktion
▸ Stellen Sie die Lösung in Ihrem Workspace bereit
▸ Sprechen Sie mit uns: Wenden Sie sich noch heute an Ihr Databricks-Account-Team, um dies in Ihren bestehenden AML-Workflow zu integrieren!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.