Die nächste Ära des Open Lakehouse: Apache Iceberg™ v3 in Public Preview auf Databricks
Volle Leistung. Volle Interoperabilität. Keine Kompromisse.
von Ryan Blue, Daniel Weeks, Jason Reid, Benjamin Mathew und Hao Jiang
• Unity Catalog ist die zentrale Anlaufstelle für Ihr Iceberg-Ökosystem – egal welche Engines oder Kataloge Ihr Team verwendet, jedes Tool liest dieselben Daten mit konsistenter, feingranularer Governance
• Iceberg v3 führt Row Lineage, Deletion Vectors und VARIANT ein und ermöglicht Hochleistungs-Inkrementalverarbeitung und Workloads mit semistrukturierten Daten
• Iceberg v3 beendet den Kompromiss zwischen Leistung und Interoperabilität: Deletion Vectors, Row Lineage und VARIANT sind Teil der offenen Spezifikation, sodass Datenteams diese Leistungssteigerungen erzielen, ohne die Kompatibilität zwischen den Engines zu beeinträchtigen
Heute tritt die Unterstützung von Databricks für Iceberg v3 in die öffentliche Vorschau ein, wodurch die neuesten Innovationen aus der Iceberg-Community nativ im offenen Lakehouse freigeschaltet werden.
Iceberg v3 stellt einen großen Fortschritt für offene Tabellenformate dar und ermöglicht Anwendungsfälle für inkrementelle Datenverarbeitung und die Analyse semi-strukturierter Daten, die bisher umständliche Workarounds erforderten. Darüber hinaus stellt Iceberg v3 eine bedeutende technologische Innovation dar, indem es die Datenebene von Iceberg und Delta Lake weiter vereinheitlicht und so die Notwendigkeit entfällt, Daten beim Erstellen interoperabler Pipelines neu zu schreiben.
Hier erfahren Sie, was es Neues in Iceberg v3 gibt, warum es wichtig ist und warum Databricks der beste Ort für Ihr Lakehouse ist.
Was gibt es Neues in Iceberg v3?
Unity Catalog Managed Iceberg v3-Tabellen unterstützen Row Lineage, Deletion Vectors und VARIANT, wodurch neue Anwendungsfälle und erhebliche Leistungsvorteile freigeschaltet werden. Databricks kann auch mit diesen Funktionen auf fremden Iceberg-Tabellen (in anderen Katalogen registrierte Iceberg-Tabellen) interagieren, was es Kunden ermöglicht, Agenten und KI-Anwendungen auf Basis ihrer Daten zu erstellen, unabhängig davon, wo diese gespeichert sind.
Inkrementelle Verarbeitung im großen Maßstab: Row Lineage und Deletion Vectors
Die meisten Daten kommen als Strom von Änderungen (INSERTs, UPDATEs, MERGEs, DELETEs) und nicht in Batches an, typischerweise aus operativen Datenbanken, Ereignisströmen und Drittanbieter-APIs. Historisch gesehen erforderte die Verarbeitung dieser Änderungen die Lösung zweier schwieriger Probleme:
- Identifizierung, welche Zeilen in Bronze-Datensätzen geändert wurden
- Effiziente Anwendung dieser Änderungen auf Silver/Gold-Datensätze
Teams griffen normalerweise auf vollständige Tabellenscans oder externe CDC-Systeme zurück, um Änderungen zu erkennen, und auf teure Dateineuschreibungen, um sie anzuwenden. Dies führte zu Pipelines, die langsam, kostspielig in der Wartung und anfällig für Drift und Datensilos waren.
Jetzt ermöglicht Row Lineage Teams, schnell zu identifizieren, welche Zeilen geändert wurden. Jede Zeile in einer Iceberg v3-Tabelle verfügt über eine permanente Zeilen-ID und eine Sequenznummer, die angibt, wann die Zeile zuletzt geändert wurde.
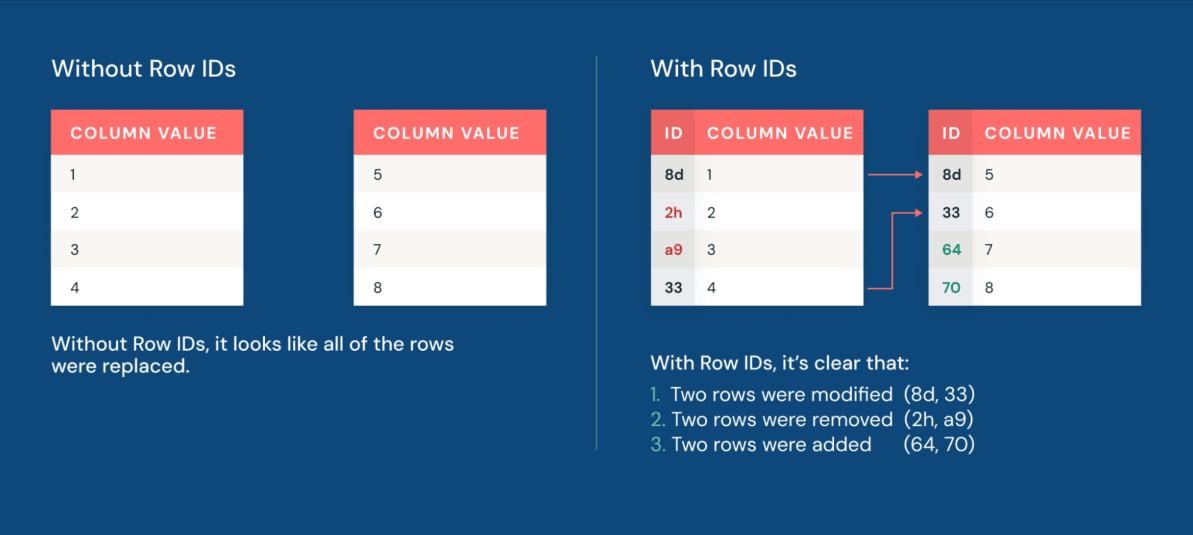
Darüber hinaus machen Deletion Vectors die Anwendung von Änderungen auf Datensätze leistungsfähiger als je zuvor. Deletion Vectors ermöglichen es Iceberg, zu verfolgen, welche Zeilen logisch gelöscht wurden, ohne die zugrunde liegenden Datendateien sofort neu zu schreiben. Anstatt Zeilen durch das Neuschreiben großer Parquet-Dateien physisch zu löschen, schreibt die Engine eine leichtgewichtige Löschdatei neben die Daten. Das Ergebnis ist eine Datenmanipulationsleistung, die bis zu 10x schneller ist als der traditionelle Copy-on-Write-Ansatz.

Da Deletion Vectors jetzt nativ in Iceberg integriert sind, kann Geodis sein Iceberg Lakehouse auf Databricks aufbauen, ohne Kompromisse bei Leistung oder Engine-Auswahl einzugehen.
„Da Deletion Vectors jetzt in Iceberg integriert sind, können wir unsere Iceberg-Datenlandschaft in Unity Catalog zentralisieren und gleichzeitig die Engine unserer Wahl nutzen und erstklassige Leistung beibehalten.“ —Delio Amato, Chief Architect & Data Officer, Geodis
Zusammen machen Row Lineage und Deletion Vectors CDC zu einer nativen Eigenschaft der Tabelle selbst. Teams können Pipelines erstellen, die sich darauf konzentrieren, inkrementell nur das zu verarbeiten, was sich tatsächlich geändert hat, wodurch Kosten gesenkt und die Time-to-Insight für jeden nachgelagerten Analysten und Data Scientist beschleunigt werden.

Semi-strukturierte Daten als First-Class-Bürger über VARIANT
Protokolle, API-Antworten, Clickstreams und IoT-Nutzlasten sind sehr wertvolle semi-strukturierte Datenquellen. Wenn sie sich weiterentwickeln, können KI-Modelle sich parallel dazu anpassen und direkt aus sich ändernden realen Signalen lernen.
Historisch gesehen standen Datenteams jedoch bei der Arbeit mit semi-strukturierten Daten vor einem schmerzhaften Kompromiss. Ein Standardansatz war die Durchsetzung starrer Schemata, was jedoch zu brüchigen Pipelines führte, die jedes Mal brachen, wenn sich die vorgelagerten Daten änderten. Ein weiterer kanonischer Workaround war die Speicherung der Daten als rohe Zeichenketten-Dumps, was jedoch Abfragen sehr komplex und langsam machte. Keiner der Ansätze war skalierbar.
Der Iceberg v3 VARIANT-Typ löst diesen Kompromiss. VARIANT ist ein nativer Spaltentyp, der semi-strukturierte Payloads neben relationalen Spalten in derselben Iceberg-Tabelle speichert. Dies erfordert kein Flattening, keine Speicherung in einem separaten System und keine ETL-Pipeline zur Normalisierung. Stattdessen können Datenteams rohe semi-strukturierte Daten so, wie sie sind, erfassen und mit Standard-SQL abfragen.

Panther nutzt VARIANT, um die groß angelegte Erfassung und Analyse von semi-strukturierten Sicherheitsprotokollen zu ermöglichen.
„Unity Catalog und Iceberg v3 erschließen die Leistung semi-strukturierter Daten durch VARIANT. Dies ermöglicht Interoperabilität und kostengünstige Protokollerfassung im Petabyte-Maßstab.“ —Russell Leighton, Chief Architect, Panther
Mit VARIANT arbeiten Ihre KI-Modelle und Analyse-Pipelines direkt mit Live-Daten, die sich in einer einzigen, verwalteten Tabelle entwickeln. Wenn neue Felder in API-Antworten erscheinen oder neue Ereignistypen in Clickstreams eingehen, sind sie sofort abfragbar, ohne eine Schema-Migration. Mit Leistungsoptimierungen wie Shreddingkönnen Kunden von spaltenähnlicher Leistung bei ihren semi-strukturierten Daten profitieren, wodurch BI, Dashboards und Alerting-Pipelines mit geringer Latenz ermöglicht werden.
Unity Catalog bietet Interoperabilität und Leistung für Unternehmen mit mehreren Engines und Katalogen
Moderne Unternehmen verlassen sich auf mehrere Engines und Kataloge, um vielfältige Anwendungsfälle über Geschäftsbereiche und Altsysteme hinweg zu unterstützen. Unity Catalog wurde entwickelt, um Interoperabilität und Governance über Kataloge hinweg zu ermöglichen und gleichzeitig Datenlayouts basierend auf Abfragemustern zu optimieren.
Vereinheitlichte Governance über Kataloge und Engines hinweg
Die offenen APIs von Unity Catalog ermöglichen es Kunden, einmal zu schreiben und überall zu lesen – keine Datenverdopplung oder isolierten Zugriffskontrollen mehr. UC kann zu anderen Iceberg-Katalogen föderiert werden, was eine bidirektionale Interoperabilität ermöglicht. Alle Iceberg-Daten in Snowflake, AWS Glue, Salesforce und anderen wichtigen Katalogen können von Unity Catalog gelesen werden, und alle Daten in UC können von denselben Drittanbieterplattformen über offene APIs abgerufen werden.
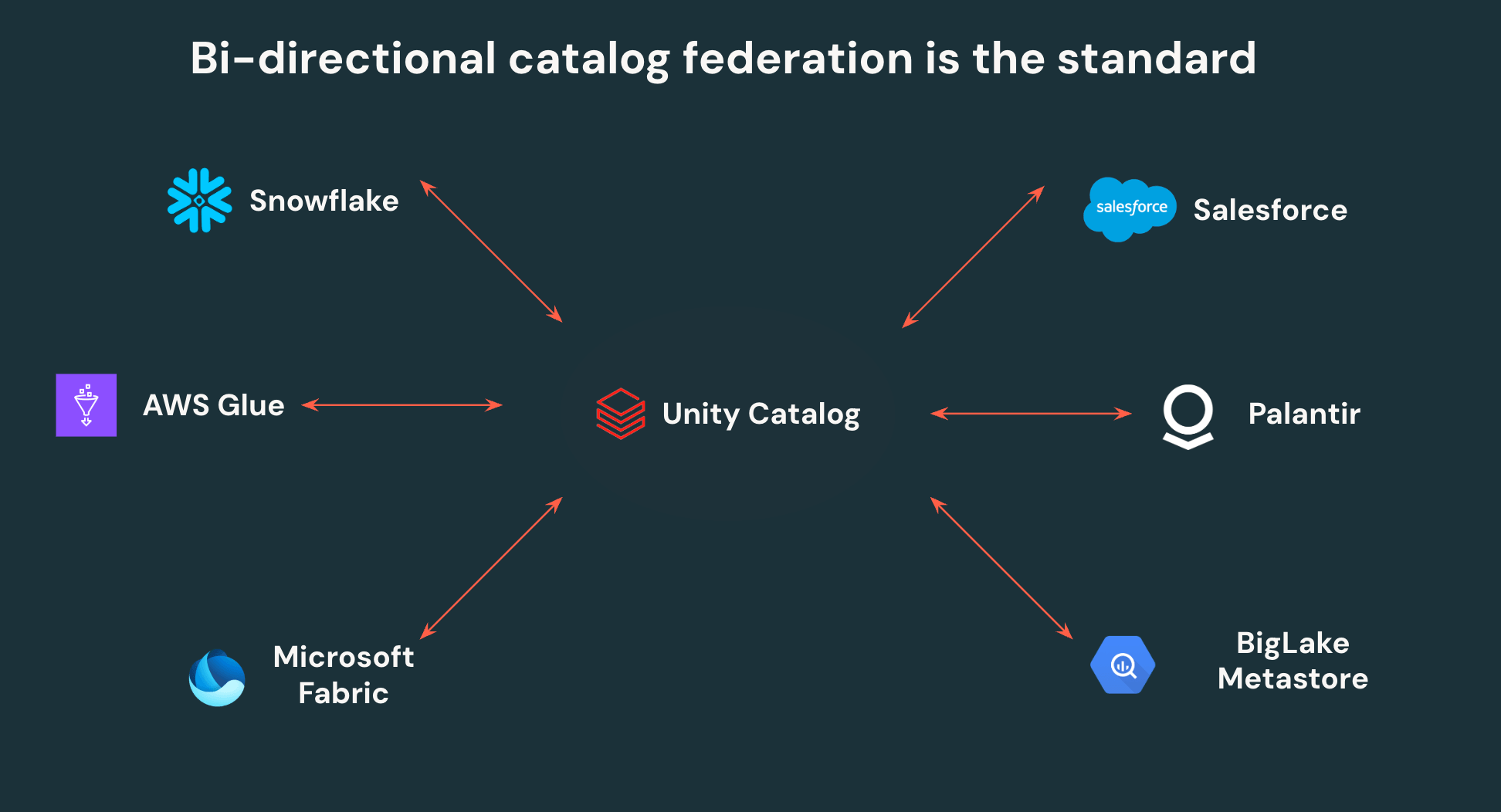
Darüber hinaus ist Unity Catalog der erste Katalog, der feingranulare Zugriffskontrolle auf externen Enginesunterstützt, wodurch Teams Zeilenfilter und Spaltenmasken einmal definieren und diese überall dort durchsetzen können, wo auf Daten zugegriffen wird. Die Zentralisierung der Governance auf Unity Catalog erleichtert es Sicherheitsteams erheblich, ihr Lakehouse zu verwalten und zu überwachen, während Datenteams gleichzeitig die Autonomie erhalten, jedes Tool auf ihr Lakehouse zu richten.

Delta- und Iceberg-Interoperabilität
Delta Lake mit UniForm ermöglicht Interoperabilität zwischen den Delta Lake- und Iceberg-Ökosystemen der Kunden: Einmal in Delta Lake schreiben und als Iceberg aus Snowflake, BigQuery, Redshift, Athena, Trino oder jeder anderen Iceberg-Engine lesen. Da Iceberg v3 Deletion Vectors, Row Lineage und VARIANT nativ übernimmt, stehen Kunden nicht mehr vor einem Kompromiss zwischen den Leistungsmerkmalen von Delta Lake und der Iceberg-Kompatibilität. Das Ergebnis ist eine einzige Datenkopie, die jede Engine in Ihrem Stack bedient, ohne Wartungspipelines für die Replikation oder das Risiko von Drift. Ein führender Finanzdienstleister ersetzte einen kostspieligen Full-Table-Replikationsdienst durch UniForm, sodass Snowflake direkt auf Unity Catalog-verwaltete Tabellen zugreifen konnte.
Automatisierte Leistung und Optimierung
Databricks vereint Leistung, Layoutoptimierung und Governance in einem einzigen System, sodass Teams diese Fähigkeiten nicht selbst zusammensetzen müssen. Databricks kombiniert intelligente Wartung (Predictive Optimization), physische Layoutoptimierungen basierend auf Abfragemustern (Automatic Liquid Clustering) und Engine-übergreifende Governance (Unity Catalog) in einer Schicht, ohne manuelle Konfiguration.
Andere verwaltete Iceberg-Angebote erfordern, dass Teams Tabellenwartung, Dateilayout und Durchsetzung von Zugriffsrichtlinien unabhängig verwalten. Auf Databricks sind diese Funktionen vereinheitlicht und automatisch, wodurch eine ganze Klasse von betrieblichem Mehraufwand entfällt und gleichzeitig die vollständige Datenportabilität erhalten bleibt.
Erste Schritte mit Apache Iceberg v3 auf Databricks
Iceberg v3 auf Databricks ist heute Public Preview! Teams können jetzt die besten Funktionen von Delta und Iceberg nutzen, ohne Kompromisse zwischen Leistung und Interoperabilität eingehen zu müssen.
Iceberg v3 ist auf Databricks Runtime 18.0+ mit aktiviertem Unity Catalog verfügbar.
Das Erstellen einer von Unity Catalog verwalteten Iceberg-Tabelle mit aktiviertem v3 ist einfach:
Das Erstellen einer von Unity Catalog verwalteten Delta-Tabelle mit UniForm und aktiviertem v3 ist genauso einfach:
Ausblick: Iceberg v4
Iceberg v3 vereinheitlicht die Datenschicht über Delta und Iceberg auf einer performanten, interoperablen Grundlage – die nächste Grenze ist die Metadatenschicht. Databricks-Ingenieure treiben aktiv mehrere Kernvorschläge für Iceberg v4 in der Apache-Community voran, um Metadaten einfacher, schneller und skalierbarer zu machen. Dazu gehören der adaptive Metadatenbaum, der die Metadatenstruktur vereinfacht, sodass die meisten Operationen nur eine einzige Datei anstelle mehrerer schreiben müssen. Zusätzliche Vorschläge umfassen die Unterstützung relativer Pfade für eine nahtlose Tabellenverschiebung zwischen Umgebungen und ein modernisiertes Statistikmodell, das sich auf neuere Datentypen wie VARIANT und GEOMETRY erstreckt. Zusammen werden diese Fortschritte zu schnellerer Aufnahme, effizienterer Abfrageplanung und einfacherer Tabellenverwaltung im Enterprise-Maßstab führen. Wir freuen uns darauf, die Iceberg-Spezifikation gemeinsam mit der Community weiterzuentwickeln.
Erfahren Sie mehr auf dem Data and AI Summit
Beginnen Sie mit Iceberg v3 und nehmen Sie an unserem bevorstehenden Data and AI Summit in San Francisco, 15.-18. Juni 2026, teil, um mehr über unsere Iceberg-Roadmap und unsere Arbeit im gesamten Ökosystem zu erfahren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.