Strukturierte vs. unstrukturierte Daten
- Strukturierte Daten sind in vordefinierten Schemata organisiert – In Tabellen mit festen Formaten gespeichert, ermöglichen strukturierte Daten schnelle SQL-Abfragen, unterstützen Business Intelligence-Tools und dienen traditionellen Analytics wie Reporting und Prognosen, aber Schemaänderungen können eine Herausforderung sein.
- Unstrukturierte Daten machen 80–90 % der Unternehmensdaten aus und erfordern fortschrittliche Tools, um Erkenntnisse aus Data Lakes oder Lakehouse-Architekturen zu gewinnen.
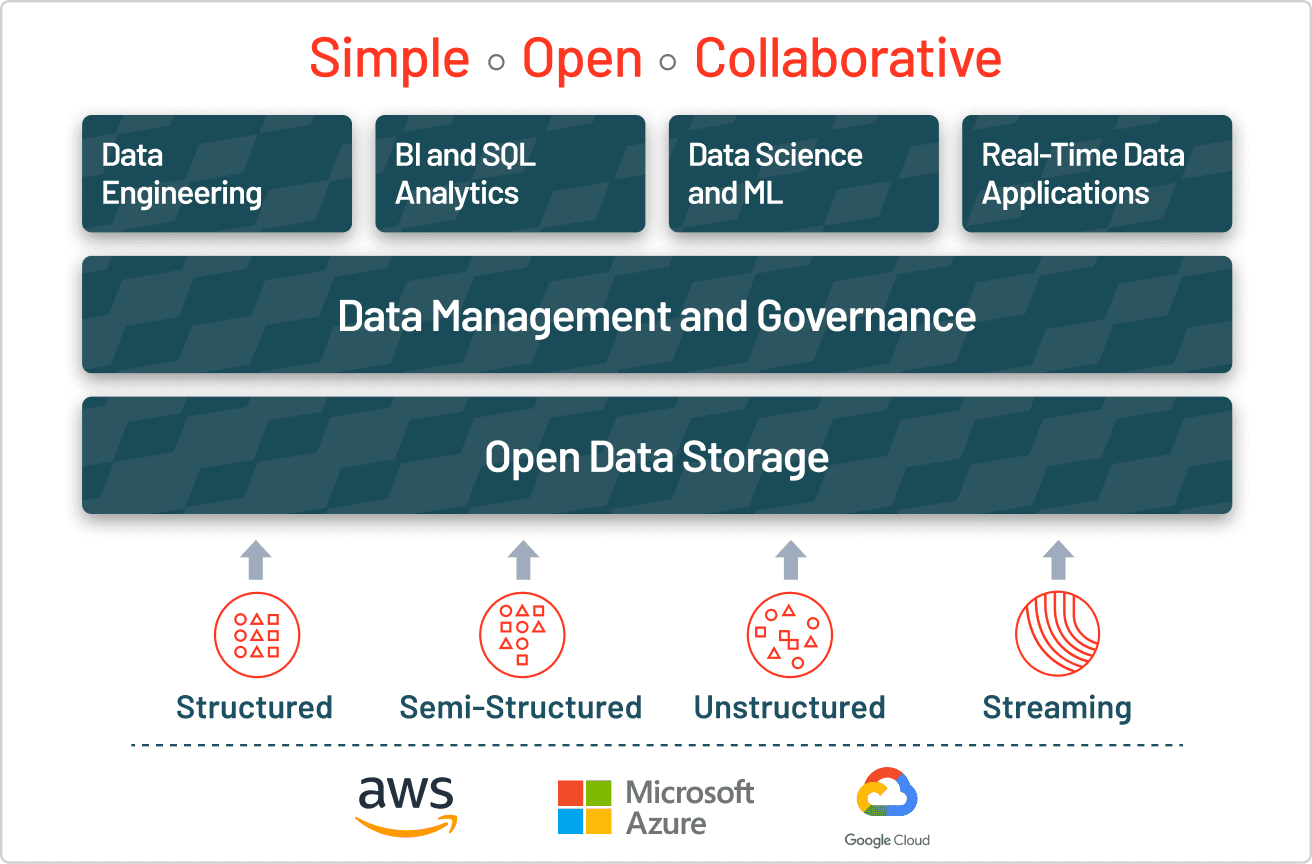
- Moderne Unternehmen benötigen hybride Ansätze, die beide Datentypen kombinieren – Lakehouse-Architekturen vereinheitlichen die Datenverwaltung von strukturierten und unstrukturierten Daten und bieten die Offenheit von Data Lakes mit der Zuverlässigkeit von Data Warehouses, während sie eine einheitliche Governance über alle Datentypen hinweg bereitstellen.
Strukturierte und unstrukturierte Daten sind beides wichtige Assets für moderne Organisationen, aber sie unterscheiden sich grundlegend. Organisationen müssen diese Unterschiede verstehen und jeden Typ effektiv verwalten, um ihren vollen Wert zu nutzen. Dieser Leitfaden untersucht praktische Auswirkungen, Anwendungsfälle aus der Praxis und strategische Überlegungen zur Wahl des richtigen Datentyps. Er behandelt auch Tools für gängige Geschäftsanforderungen und geht über allgemeine Vergleiche hinaus zu umsetzbaren Entscheidungs-Frameworks.
Strukturierte Daten: Merkmale und Anwendungen
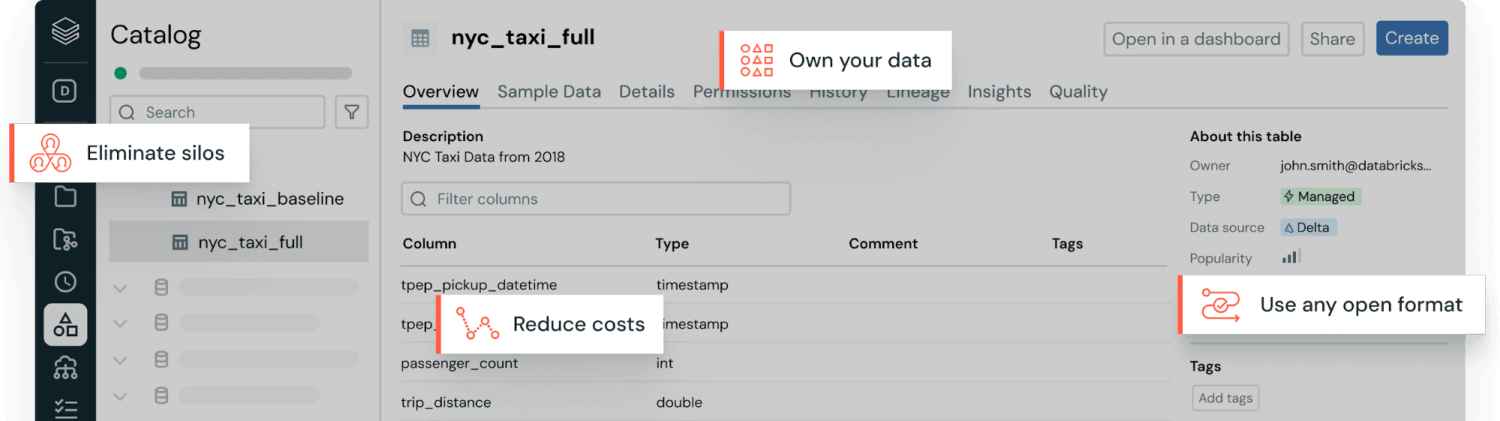
Kernmerkmale strukturierter Daten
Strukturierte Daten sind Informationen, die in einem vordefinierten relationalen Datenmodell organisiert sind, d. h. die Daten sind in Tabellen mit festen Schemata angeordnet. Dieses Modell legt die Struktur (Zeilen und Spalten), die Datentypen und die Beziehungen zwischen den Tabellen fest, bevor Daten gespeichert werden, um eine effiziente Suche und Analyse zu ermöglichen. Gängige Beispiele für strukturierte Daten sind Finanztransaktionen, Excel-Dateien, CRM-Datensätze (Customer-Relationship-Management), Lagerbestände, Kundenaufträge, Reservierungssysteme und Sensordaten.
Strukturierte Daten werden typischerweise in Data Warehouses gespeichert. Diese sind für schnelle, zuverlässige Abfragen mittels Structured Query Language (SQL) optimiert, die für Workloads für strukturierte Daten verwendet wird.
Das standardisierte Format macht strukturierte Daten zudem sehr gut zugänglich. Geschäftsanwender können diese mit vertrauten Business Intelligence (BI) - und Analysetools einfach untersuchen, analysieren und Berichte darüber erstellen, um Erkenntnisse zu gewinnen, ohne dass dafür fortgeschrittenes technisches Fachwissen erforderlich ist.
Geschäftswert und Analyse von strukturierten Daten
Strukturierte Daten bieten einen erheblichen Mehrwert, da ihr konsistentes, filterbares Format die Datenanalysen mit minimaler Vorverarbeitung unterstützt und es Unternehmen ermöglicht, effizient Berechnungen durchzuführen, Modelle zu erstellen und Trends zu vergleichen. Strukturierte Daten bilden das Rückgrat der Unternehmens-Analytics und bieten schnelle Abfragen, hohe Datenintegrität und zuverlässige Ergebnisse, auf die sich Unternehmen bei der täglichen und strategischen Planung verlassen können. Dazu gehören herkömmliche BI-Methoden wie routinemäßiges Reporting, Prognosen, KPI-Monitoring und interaktive Dashboards, die Unternehmen dabei helfen, die Performance zu verfolgen und Entscheidungen zur Optimierung des Betriebs zu treffen.
Strukturierte Daten sind auch für Modelle für maschinelles Lernen (ML) und automatisierte Systeme, die erweiterte Informationen wie KI-generierte Zusammenfassungen und die Auswertung von Kundenstimmungen generieren, äußerst effektiv.
Speicherung strukturierter Daten und Überlegungen zur Skalierbarkeit
Ein wesentlicher Vorteil von strukturierten Datasets ist die hohe Speichereffizienz durch spaltenweise Komprimierung. Da die Werte in derselben Spalte tendenziell ähnlich sind, ermöglichen spaltenorientierte Datenbanken eine effiziente Komprimierung und das effiziente Lesen von Daten, was zu erheblichen Speichereinsparungen und schnelleren Analytics führt.
Schemaänderungen bei strukturierten Daten können jedoch eine Herausforderung darstellen. Da Datenbank-Ökosysteme stark vernetzt sind und viele Abhängigkeiten aufweisen, können Änderungen wie das Hinzufügen, Ändern oder Entfernen von Feldern zu Datenverlust, Anwendungsausfällen und kaskadierenden Fehlern an anderer Stelle im System führen, wenn sie nicht ordnungsgemäß verwaltet werden. Unternehmen müssen Migrationen sorgfältig planen, um Disruption zu vermeiden.
Unstrukturierte Daten: Merkmale, Herausforderungen und Chancen
Merkmale und Quellen unstrukturierter Daten
Unstrukturierte Daten sind Informationen in ihrem nativen Format. Im Gegensatz zu strukturierten Daten, die in Zeilen und Spalten organisiert sind, fehlt unstrukturierten Daten eine vordefinierte Struktur, was die Suche und Analyse erschwert.
Daten in ihrer unstrukturierten Form können maschinell generiert sein – wie GPS-Daten, Protokolldateien und andere Telemetrieinformationen – oder von Menschen generiert sein. Beispiele für von Menschen erzeugte unstrukturierte Daten sind Social-Media-Beiträge, Audiodateien, Videodateien, E-Mails, Multimediadateien und Textdokumente.
Unstrukturierte Daten machen 80 bis 90 % des Datenwachstums in Unternehmen aus. Diese Art von Daten kann wertvolle Einblicke in Bereichen wie Markttrends, Kundenstimmung und betriebliche Probleme bieten, aber die Gewinnung dieser Einblicke kann im Vergleich zur Arbeit mit strukturierten Daten eine Herausforderung sein.
Herausforderungen und Lösungen bei der Analyse unstrukturierter Daten
Erkenntnisse aus unstrukturierten Daten blieben weitgehend ungenutzt, bis fortschrittliche Datenanalysemethoden wie ML-Algorithmen, die Verarbeitung natürlicher Sprache (NLP) und die Stimmungsanalyse entwickelt wurden, mit denen sich automatisch Bedeutung aus großen Mengen unstrukturierter Daten extrahieren lässt.
In der Regel benötigen Unternehmen Data Scientists, um unstrukturierte Daten zu verwalten, zu verarbeiten und mithilfe fortschrittlicher Techniken aussagekräftige Muster daraus zu extrahieren. Data Lakes werden häufig verwendet, um unstrukturierte Daten in ihrem nativen Rohformat zu konsolidieren, und bieten flexiblen Speicher für große Datenmengen. Mit Data Lakes können Sie Rohdaten in strukturierte Daten umwandeln, die mit geringer Latenz für SQL Analytics, Data Science und Machine Learning bereitstehen. Data Lakes können Rohdaten außerdem zu geringen Kosten unbegrenzt für die zukünftige Verwendung in ML und Analysen aufbewahren.
Allerdings können Data Lakes leicht zu "Datensümpfen" mit Problemen bei Zuverlässigkeit, Performance und Governance verkommen. Herkömmliche Data Lakes allein reichen nicht aus, um die Anforderungen innovationsfreudiger Unternehmen zu erfüllen. Deshalb arbeiten Unternehmen oft mit komplexen Architekturen, bei denen die Daten in verschiedenen Speichersystemen im gesamten Unternehmen isoliert sind.
Lakehouse-Speicher vereinheitlicht die Verarbeitung strukturierter und unstrukturierter Daten, um die Herausforderungen von Data Lakes zu bewältigen. Lakehouses implementieren Data-Warehouse-ähnliche Strukturen und Verwaltungs-Features direkt auf dem kostengünstigen Datenspeicher eines Data Lake und kombinieren so die Offenheit von Data Lakes mit den Verwaltungs- und Zuverlässigkeits-Features von Data Warehouses. Diese Struktur stellt sicher, dass Unternehmen verschiedene Arten von Daten für Data Science-, ML- und Business-Analytics-Projekte nutzen können.
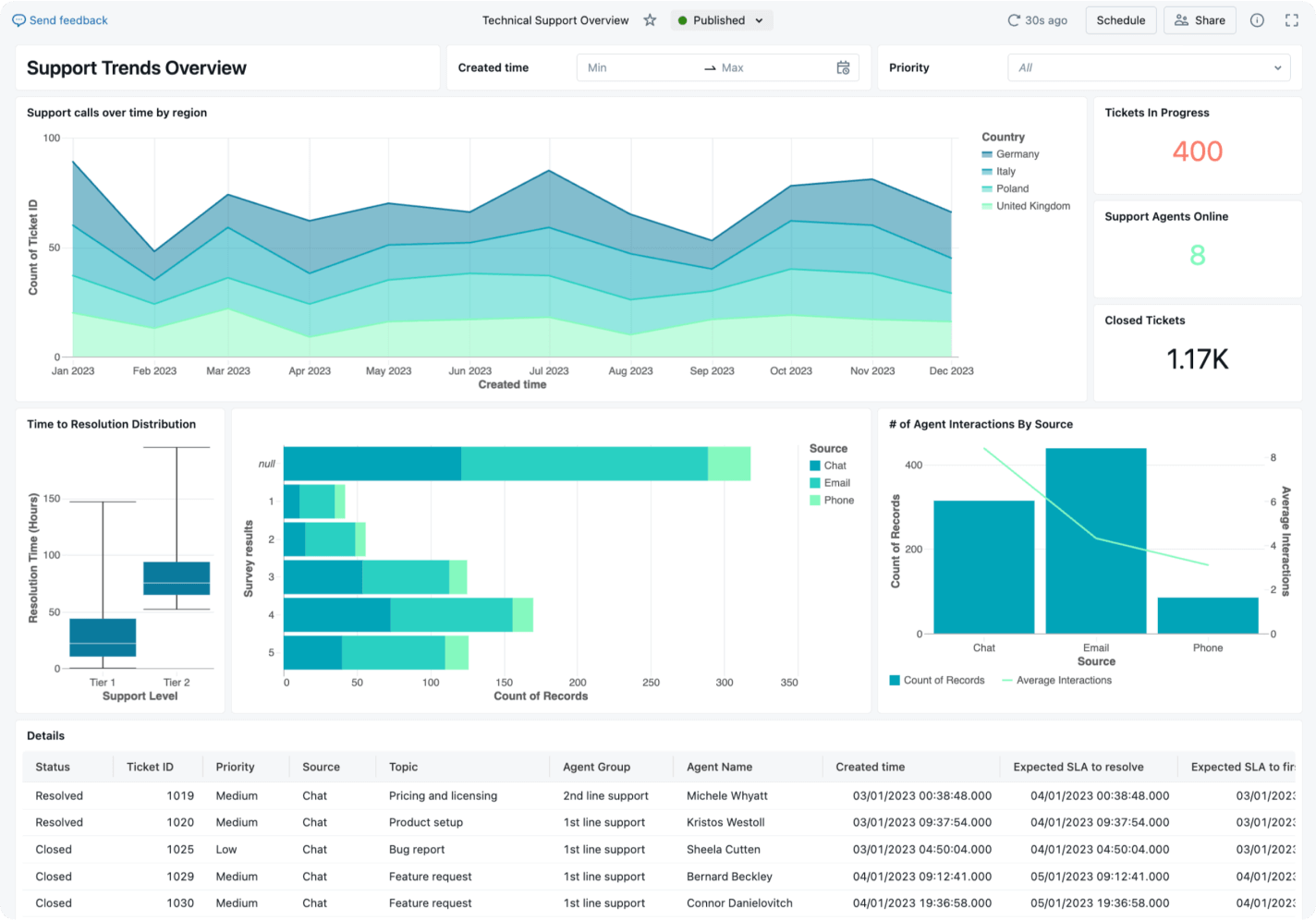
Geschäftswert aus unstrukturierten Daten erschließen
Unstrukturierte Daten enthalten reichhaltige Informationen, die herkömmliche Analysetechniken nicht einfach interpretieren können. Machine-Learning-Funktionen ermöglichen die Verarbeitung unstrukturierter Inhalte in großem Umfang, wobei Muster, Themen, Stimmungen und Anomalien identifiziert werden, die andernfalls verborgen bleiben würden. Mithilfe von Techniken wie NLP und Computer Vision können Unternehmen qualitative Daten in handlungsrelevante Erkenntnisse umwandeln, die zur Entscheidungsfindung genutzt werden.
Um beispielsweise den Kundenservice zu verbessern, können Unternehmen KI nutzen, um eine Vielzahl von Quellen zu analysieren, darunter Produktbewertungen, Callcenter-Transkripte, Erwähnungen in sozialen Medien und Chatbot-Konversationen. Die erkannten Muster können genutzt werden, um Möglichkeiten zur Problemlösung aufzuzeigen, die Effizienz zu steigern und Innovationen anzustoßen, um das Kundenerlebnis zu verbessern.
Wichtige Unterschiede zwischen strukturierten und unstrukturierten Daten und Entscheidungs-Framework
Das Verständnis der Unterschiede zwischen strukturierten und unstrukturierten Daten ist für den Entwurf effektiver Datenarchitekturen und die Auswahl geeigneter Analysemethoden unerlässlich. Jeder Typ bringt einzigartige Stärken und Herausforderungen mit sich, die in die Datenstrategie eines Unternehmens einfließen müssen.
Wichtige Vergleichsdimensionen
- Datenformat: Strukturierte Daten sind in einem festen, vordefinierten Format organisiert. Jeder Datensatz verwendet denselben Satz an Feldern und Datentypen, sodass alles konsistent bleibt. Unstrukturierte Daten werden in ihrer rohen, nativen Form ohne eine einheitliche Struktur gespeichert, was sie flexibler macht, aber ihre Organisation und Analyse erschwert.
- Analysetools: Strukturierte Daten können einfach mit SQL abgefragt und in gängige Business-Intelligence-Tools integriert werden. Unstrukturierte Daten erfordern fortschrittlichere Analytics-Methoden, einschließlich ML, NLP und Computer Vision. Diese werden in der Regel von Data Scientists oder spezialisierten Analysten verwaltet.
- Speicherung: Strukturierte Daten eignen sich von Natur aus für Data Warehouses, die für relationale Queries und Performance optimiert sind. Unstrukturierte Daten eignen sich besser für Data Lakes, die es Unternehmen ermöglichen, Rohdaten im großen Scale zu speichern, oder für hybride Lakehouse-Architekturen.
- Verarbeitungszeit: Da strukturierte Daten bereits organisiert sind, können sie oft sofort mit minimaler Vorbereitung analysiert werden. Unstrukturierte Daten benötigen im Allgemeinen eine erhebliche Vorverarbeitung – wie Bereinigung, Tokenisierung, Labeling und Merkmalsextraktion –, bevor aussagekräftige Erkenntnisse gewonnen werden können.
- Benutzerzugänglichkeit: Strukturierte Daten sind für eine breite Palette von Benutzern zugänglich, einschließlich Business-Analysten und Entscheidungsträgern, die sie über Dashboards und Reporting-Tools erkunden können. Unstrukturierte Daten erfordern in der Regel das Fachwissen von Data Scientists oder Ingenieuren, um sie in nutzbare Formate umzuwandeln und umsetzbare Erkenntnisse zu gewinnen.
Semistrukturierte Daten und moderne Ansätze
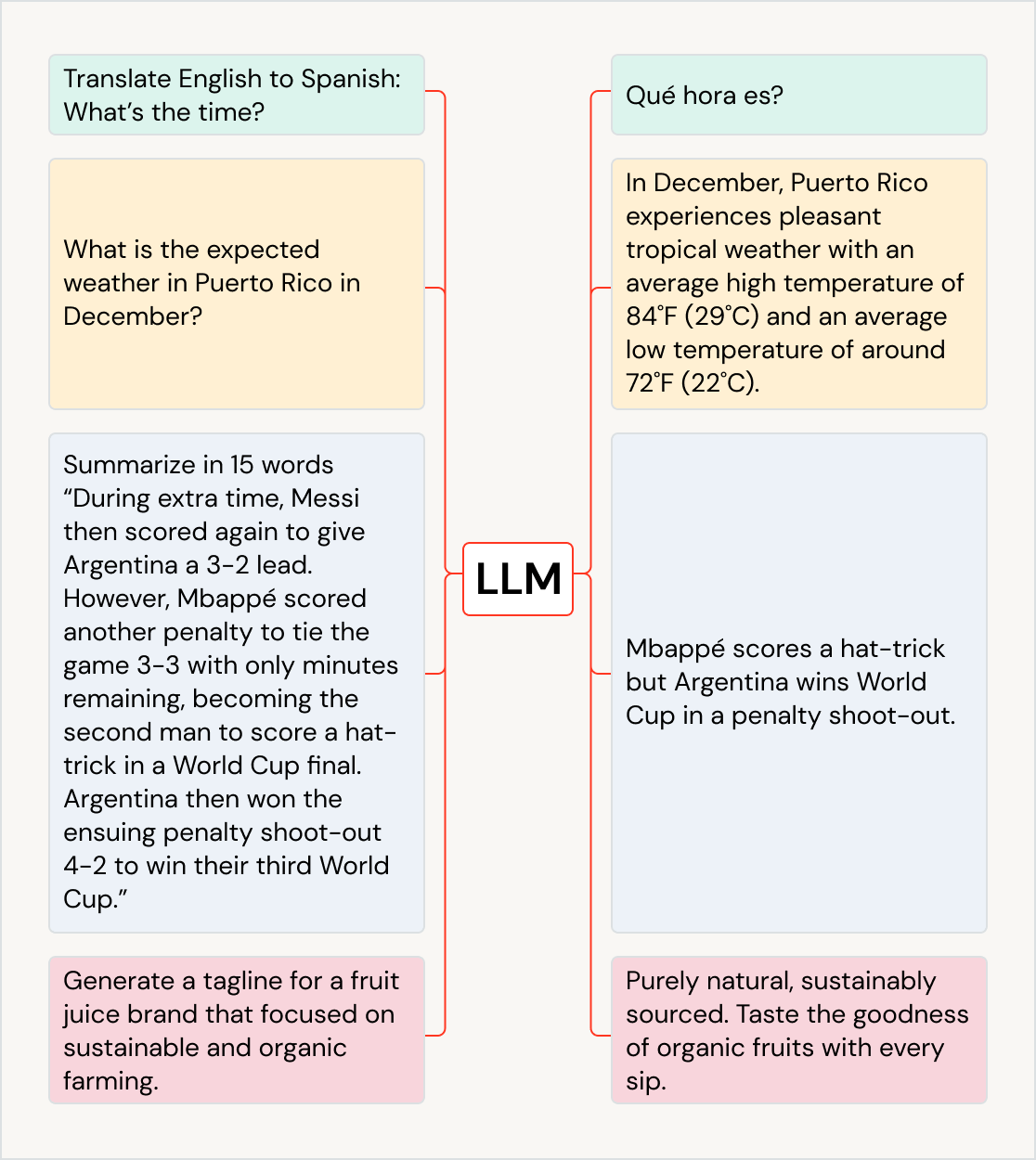
Der hybride Mittelweg
Strukturierte und unstrukturierte Daten sind nicht die einzigen Formate, die Unternehmen verwalten müssen. Semistrukturierte Daten schließen die Lücke zwischen den beiden, indem sie Metadaten-Tags verwenden, um eine gewisse Organisation hinzuzufügen, während sie gleichzeitig flexible, sich entwickelnde Felder zulassen. Gängige Beispiele hierfür sind JSON-, XML- und CSV-Dateien. Unternehmen verwenden häufig NoSQL-Datenbanken und moderne Dateisysteme zur Verwaltung dieser Art von Daten, da diese flexible Schemata unterstützen und sich leichter an wechselnde Datenformate anpassen.
Die meisten Unternehmen benötigen alle Arten von Daten und setzen daher auf hybride Speicherstrategien, die die Stärken verschiedener Datenansätze vereinen. Moderne Lakehouse-Architekturen machen die Wahl zwischen Data Lakes und Data Warehouses überflüssig, indem sie deren Funktionen auf einer einzigen Plattform vereinen. Der Unity Catalog von Databricks bietet eine einheitliche und offene Governance für alle strukturierten Daten, unstrukturierten Daten, Geschäftsmetriken und KI-Modelle in jeder Cloud. Dies ermöglicht es Unternehmen, Daten an einem zentralen Ort zu verwalten, zu entdecken, zu überwachen und zu teilen, was die Compliance vereinfacht und zu schnelleren Erkenntnissen führt.
Fazit
Eine Datenstrategie ist keine Einheitslösung. Das Verständnis der Unterschiede zwischen strukturierten, unstrukturierten und semistrukturierten Daten ist für den Aufbau einer effektiven Datenverwaltung unerlässlich. Organisationen benötigen das Fachwissen, um Datentypen auf ihre spezifischen analytischen Bedürfnisse und Geschäftsanforderungen abzustimmen. Indem Unternehmen die Wahl ihrer Daten auf ihre einzigartigen Anwendungsfälle abstimmen, können sie tiefere Einblicke gewinnen, die Entscheidungsfindung verbessern und die Wirkung ihrer Dateninvestitionen maximieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.