Vom Stammeswissen zu sofortigen Antworten: Die Entwicklung von Reffy auf Databricks
von Rafi Kurlansik, Gavin Edgley und Sara Steffen
- Warum das Finden der richtigen Kundenreferenz zur richtigen Zeit eine ständige Herausforderung für den Vertrieb und das Marketing von Databricks war.
- Wie wir Reffy – eine Full-Stack-Agentenanwendung, die RAG, AI Search, AI Functions und Lakebase verwendet – entwickelt haben, um über 2.400 Kundengeschichten sofort durchsuchbar zu machen.
- Seit seiner Einführung im Dezember 2025 haben über 1800 Databricks-Mitarbeiter mehr als 7.500 Abfragen auf Reffy ausgeführt.
Die richtige Kundenreferenz zur richtigen Zeit zu finden, ist überraschend schwieriger, als es sein sollte. Um die Produktivität der Mitarbeiter zu steigern, haben wir Reffy entwickelt – eine App, mit der Benutzer über 2.400 Databricks-Kundenreferenzen entdecken und analysieren können. Sie liefert personalisierte Antworten, referenzübergreifende Analysen, Zitate und mehr. In den ersten beiden Monaten haben über 1.800 Mitarbeiter aus dem Vertrieb und Marketing von Databricks mehr als 7.500 Abfragen in Reffy ausgeführt. Das führt zu relevanterem und konsistenterem Storytelling, einer schnelleren Durchführung von Kampagnen und der Gewissheit, dass Kundenreferenzen im großen Scale genutzt werden. Indem wir diese Referenzen auffindbar und verständlich gemacht haben, haben wir das Problem des Stammeswissens im Zusammenhang mit Kundenreferenzen gelöst und die wertvolle Arbeit der vielen Menschen erschlossen, die sie über die Jahre gesammelt haben.
In diesem Artikel gehen wir auf die Motivation für Reffy ein, die vollständige Databricks-Lösung, ihre Auswirkungen auf unser Unternehmen und wie wir planen, sie intern noch weiter zu skalieren.
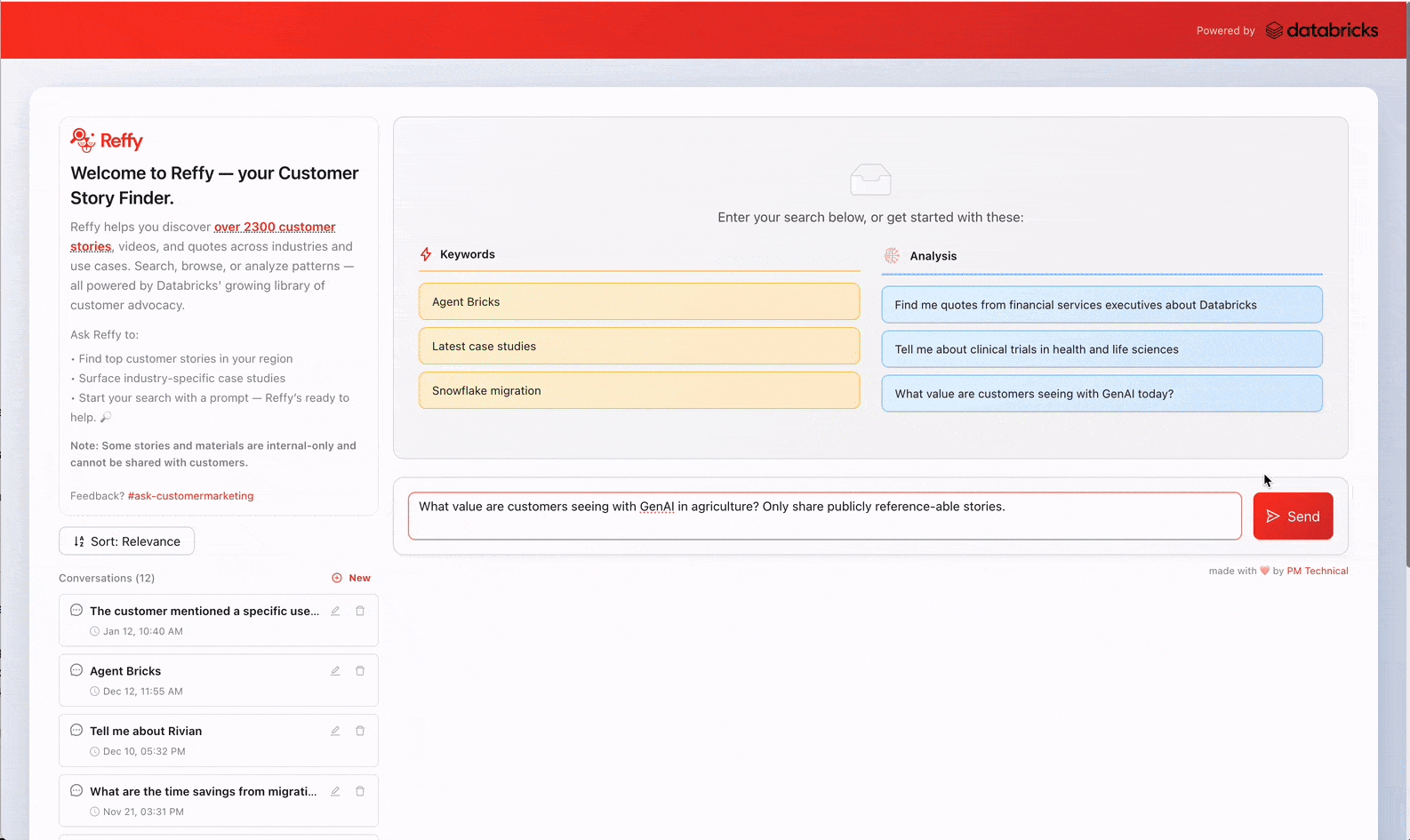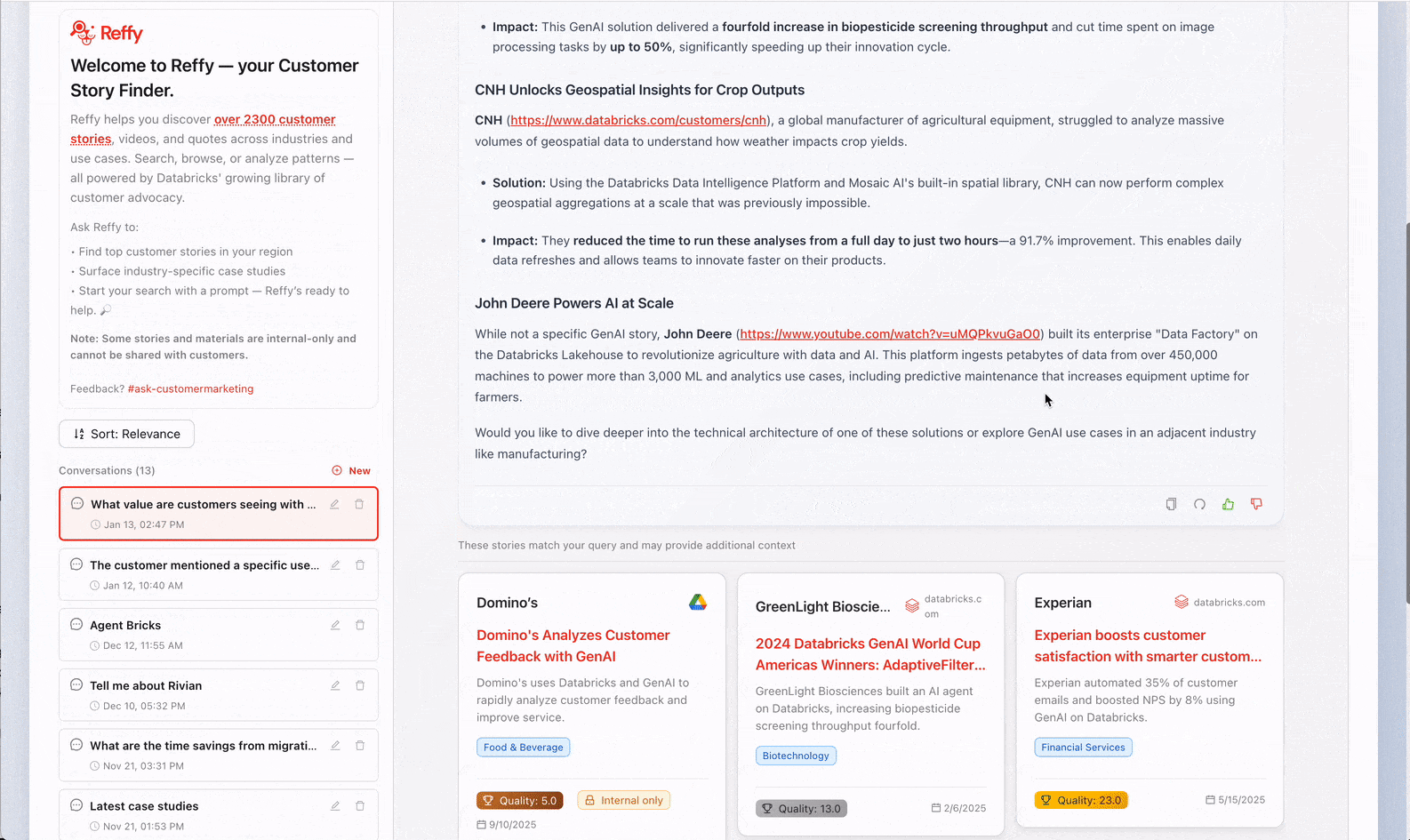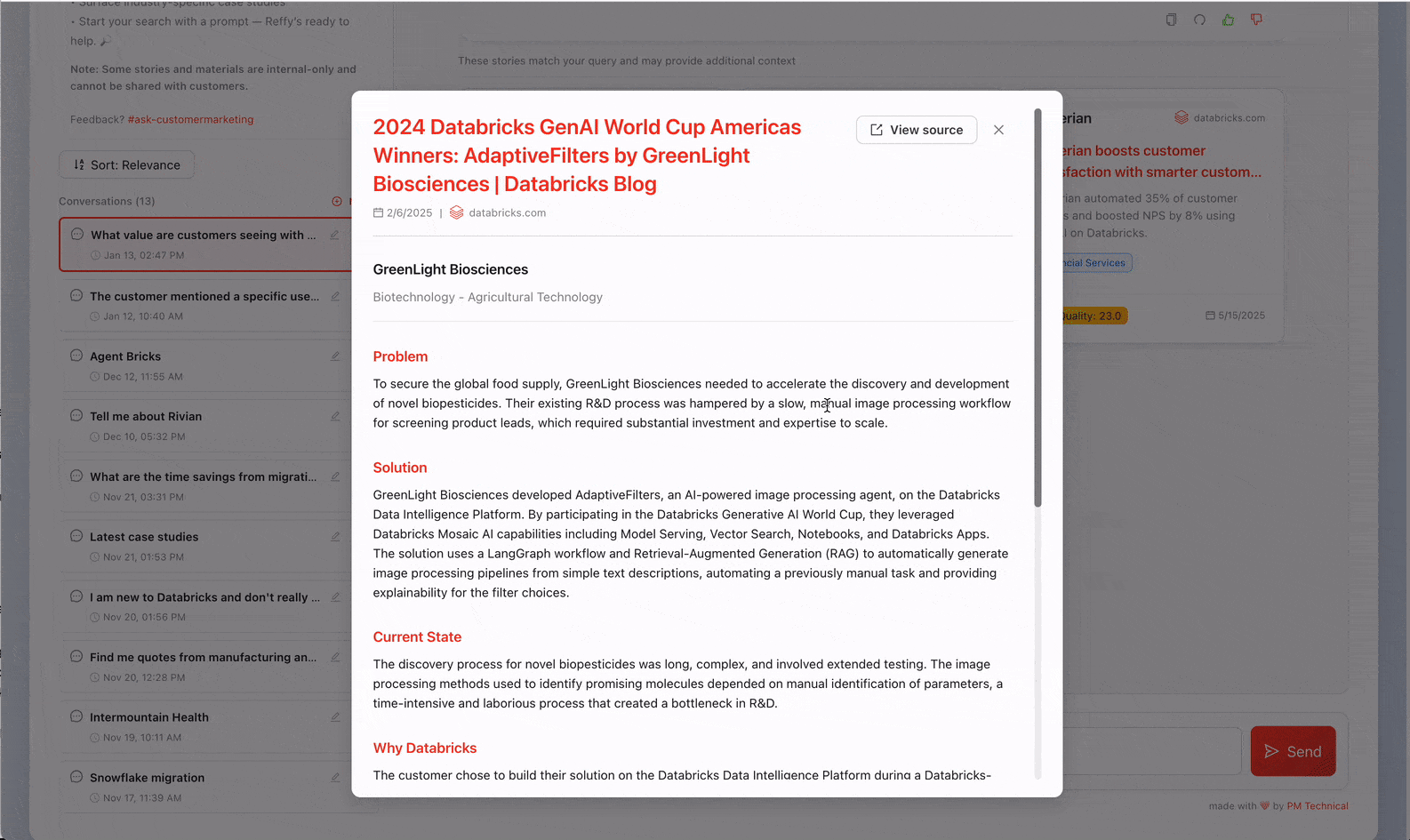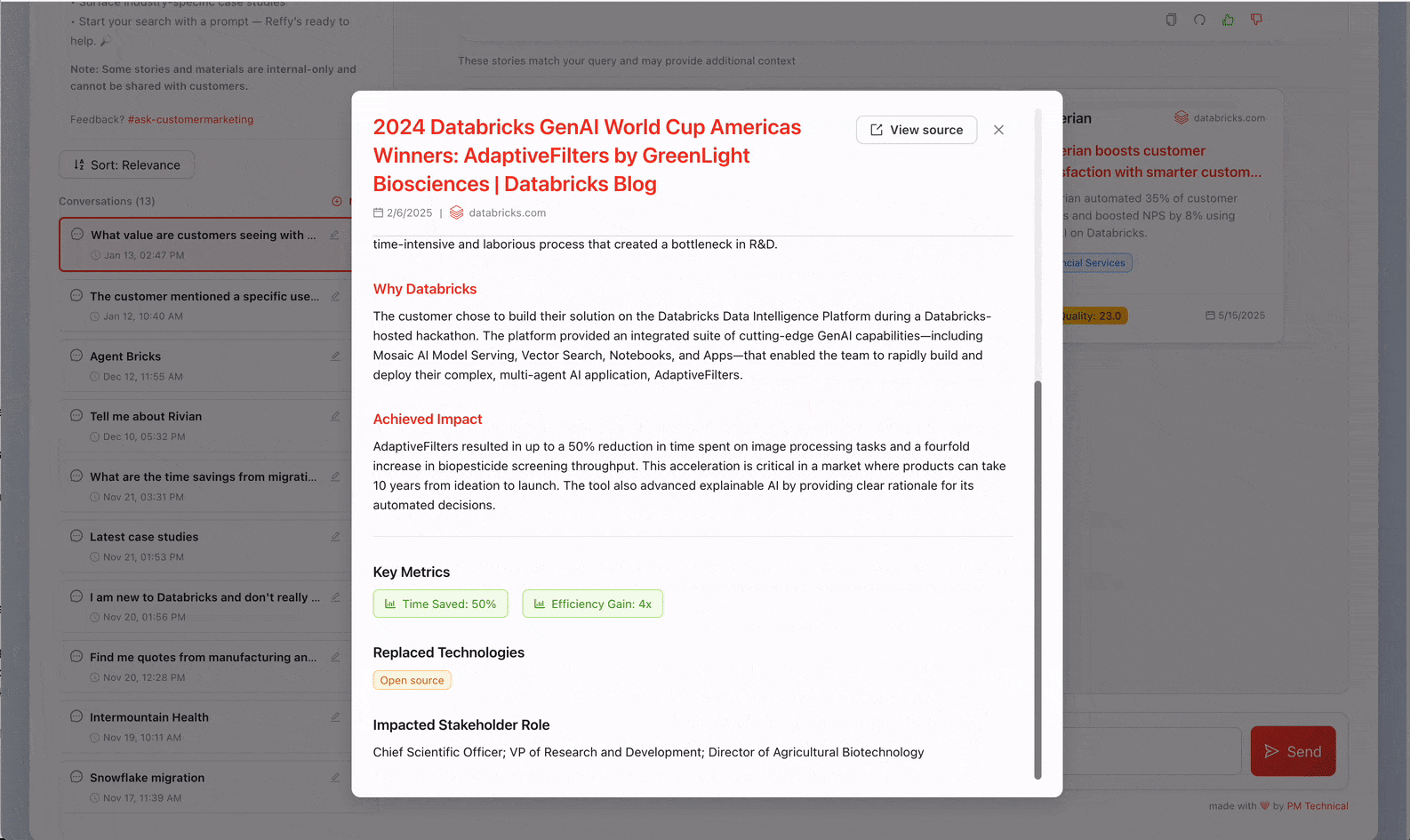
Die Herausforderung, Stammeswissen zu demokratisieren
"Wer hat das sonst noch gemacht?" ist eine Frage, die jeder Verkäufer hört. Ein potenzieller Kunde ist von Ihrem Pitch fasziniert, aber bevor er weitermacht, will er einen Beweis – einen Kunden wie ihn, der diesen Weg bereits gegangen ist. Die Beantwortung sollte einfach sein.
Für unser Marketingteam sind Kundengeschichten eine zentrale Grundlage für nahezu jede Maßnahme – Kampagnen, Produkteinführungen, Werbung, PR, Analystenbriefings und die Kommunikation mit der Führungsebene. Wenn diese Geschichten nicht leicht zu finden oder zu bewerten sind, verschärfen sich echte Probleme: hochwertige Referenzen werden überstrapaziert, neuere Anwendungsfälle oder Branchen werden übersehen und die Effektivität des Marketings wird durch Stammeswissen eingeschränkt.
Databricks hat Tausende von YouTube-Vorträgen, Fallstudien auf databricks.com, interne Folien, LinkedIn-Artikel, Medium-Posts. Irgendwo darin befindet sich die perfekte Referenz – ein Finanzdienstleistungsunternehmen in Kanada, das Betrugserkennung in Echtzeit durchführt, ein Einzelhändler, der ein altes Data Warehouse ersetzt hat, oder ein Hersteller, der GenAI skaliert. Aber sie zu finden? An diesem Punkt scheitert es. Die Geschichten sind auf einem Dutzend Plattformen ohne einheitliche Suche verteilt, und wenn man etwas findet, kann man nicht sofort sagen, ob es überzeugend ist – hat es glaubwürdige Geschäftsergebnisse oder nur vage Behauptungen?
Also tun die Leute, was Leute eben so tun: Sie schreiben dem Marketing-Team auf Slack, durchsuchen Ordner, an die sie sich nur vage erinnern, oder fragen herum, bis jemand etwas Brauchbares findet. Manchmal finden sie Gold. Meistens geben sie sich mit "gut genug" zufrieden oder geben ganz auf – ohne je zu wissen, ob die perfekte Story nicht doch die ganze Zeit da draußen war.
Offensichtlich brauchten wir für Vertrieb und Marketing eine bessere Möglichkeit, die relevantesten Kundengeschichten zu entdecken.
Reffy: Eine Full-Stack-Lösung auf Databricks
Um dieses Problem zu lösen, konsolidieren wir alle Stories in einer einzigen Tabelle, kategorisieren sie und verwenden dann einen RAG-basierten Agenten für die Suche – all dies wird über eine Vibe-codierte Databricks-App bereitgestellt. Die Architektur umfasst die gesamte Databricks-Plattform: Lakeflow Jobs orchestrieren unsere ETL-Pipelines, Unity Catalog verwaltet unsere Daten, AI Search ermöglicht den Abruf, Model Serving hostet unseren Agenten, Lakebase verarbeitet Lese- und Schreibvorgänge in Echtzeit und Databricks Apps stellt das Frontend bereit. Gehen wir ins Detail.
Datenquellen & ETL
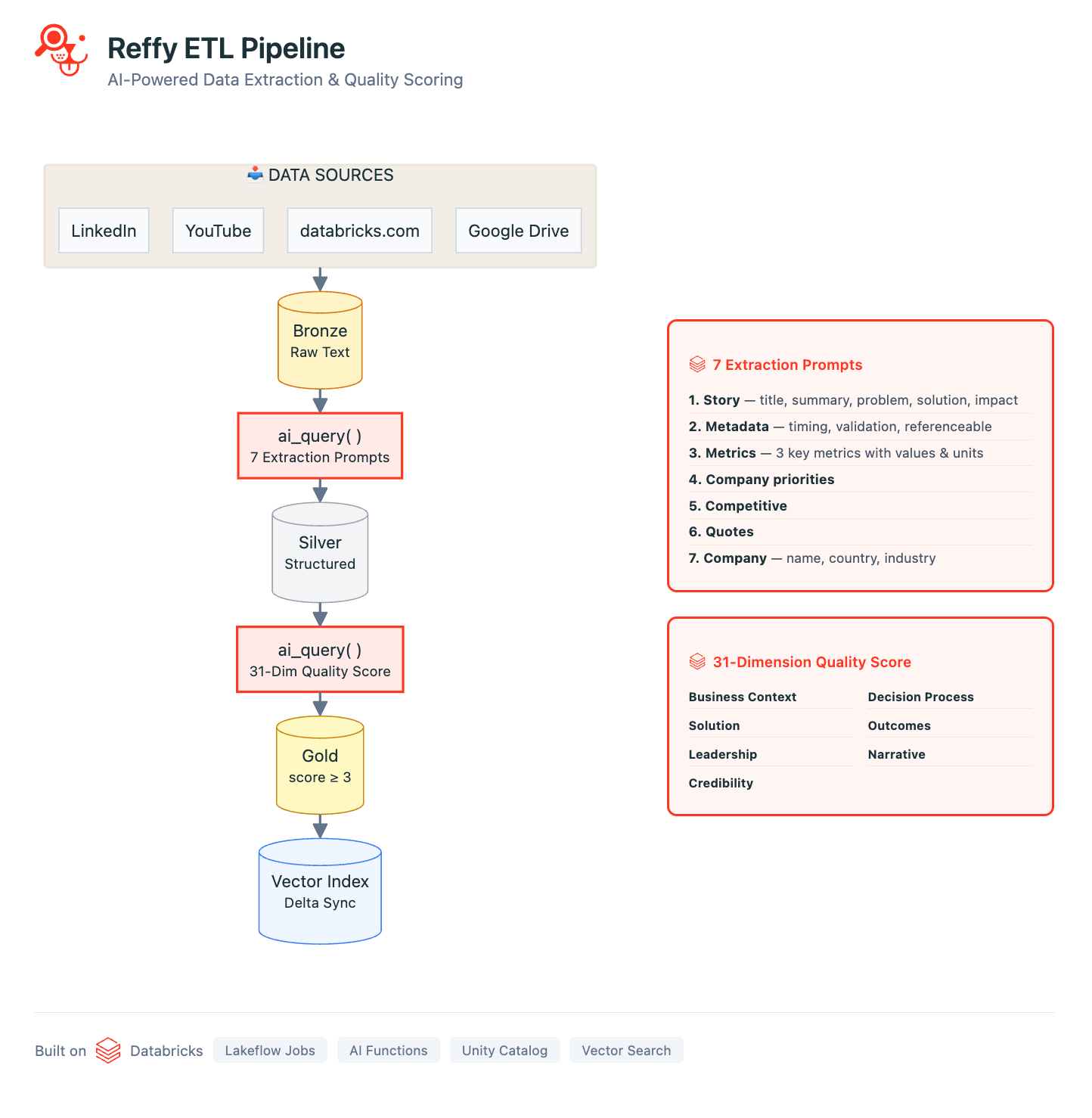
Unsere Pipeline ist in einer Reihe von Databricks Notebooks definiert, die mit Lakeflow Jobs orchestriert werden. Die Pipeline beginnt mit der Erfassung der Texte von Storys aus all unseren Datenquellen: Wir verwenden Standard-Python-Webscraping-Bibliotheken, um YouTube-Transkripte, LinkedIn/Medium-Artikel und alle öffentlichen Kundenstorys auf databricks.com zu sammeln. Mithilfe von Google Apps-Skripts führen wir außerdem den Text aus Hunderten von internen Google Slides und Docs in einer einzigen Google-Tabelle zusammen. All diese Quellen werden mit grundlegenden Metadaten verarbeitet und in einer „Bronze“-Delta-Lake-Tabelle im Unity Catalog (UC) gespeichert.
Jetzt haben wir all unsere Referenzen an einem Ort, aber wir haben noch keine Einblicke in ihre Qualität. Um dies zu beheben, klassifizieren wir den Text, indem wir über KI-Funktionen ein strenges 31-Punkte-Bewertungssystem (das von unserem Value-Team entwickelt wurde) auf jede Story anwenden. Wir fordern Gemini 2.5 auf, die allgemeine Qualität der Geschichte zu beurteilen, indem es die geschäftliche Herausforderung, die Lösung, die Glaubwürdigkeit des Ergebnisses und den Grund, warum Databricks einzigartig positioniert war, um einen Mehrwert zu liefern, identifiziert. Die Beurteilung von Geschichten auf diese Weise ermöglicht es uns auch, die qualitativ minderwertigsten aus Reffy herauszufiltern. Der Prompt extrahiert auch wichtige Metadaten wie Land und Branchen, verwendete Produkte, Wettbewerb und Zitate – und versieht Stories mit Tags, je nachdem, ob sie öffentlich geteilt werden dürfen oder nur für den internen Gebrauch sind. Dieses angereicherte Dataset wird in einer „Silver“-Tabelle in UC gespeichert.
Die letzten Schritte von ETL umfassen das Herausfiltern von Storys mit niedriger Bewertung und das Erstellen einer neuen Spalte „summary“, die wesentliche Story-Komponenten miteinander verknüpft. Die Idee ist einfach: Wir synchronisieren diese „Gold“-Tabelle mit einem Databricks AI Search -Index, wobei die Spalte „summary“ alle wesentlichen Informationen enthält, die ein LLM benötigen würde, um Kunden-Storys mit Queries abzugleichen.
Agentic KI
Mithilfe des DSPy -Frameworks definieren wir einen Tool-aufrufenden Agenten, der mit einer hybriden Schlagwort- und semantischen Suche die relevantesten Kundenreferenzen nachschlagen kann. Wir lieben DSPy! Damit erstellte Agenten lassen sich einfach iterativ in einem Databricks Notebook testen, ohne sie jedes Mal auf einem Model Serving-Endpunkt neu bereitstellen zu müssen, was zu einem schnelleren Entwicklungszyklus führt. Die Syntax ist im Vergleich zu anderen gängigen Frameworks sehr intuitiv und enthält hervorragende Komponenten zur Prompt-Optimierung. Wenn Sie es noch nicht getan haben, sollten Sie sich DSPy unbedingt ansehen.
Wir strukturieren unseren Agenten für Kundenstorys so, dass er je nach Benutzereingabe eine blitzschnelle reine Schlagwortsuche und eine ausführlichere LLM-Antwort mit Begründung ermöglicht: Wenn Sie eine Frage stellen, erhalten Sie eine sorgfältig durchdachte Antwort mit Quellen, aber wenn Sie nur ein paar Schlagwörter eingeben, liefert Reffy die besten Ergebnisse in weniger als zwei Sekunden. Wir verwenden auch den Databricks- Re-Ranker für AI Search, um die Ergebnisse von RAG zu verbessern.
Um eine ausgewogene und professionelle Antwort zu gewährleisten, verwenden wir den folgenden System-Prompt:
Der Agent wird in MLflow protokolliert und auf Databricks Model Serving mit unserem Agent Framework angewendet. Da der größte Teil der Verarbeitung aufseiten des Modellanbieters erfolgt, kommen wir mit der Bereitstellung auf einer kleinen CPU-Instanz aus und sparen so im Vergleich zu GPUs Infrastrukturkosten.
Die Databricks App
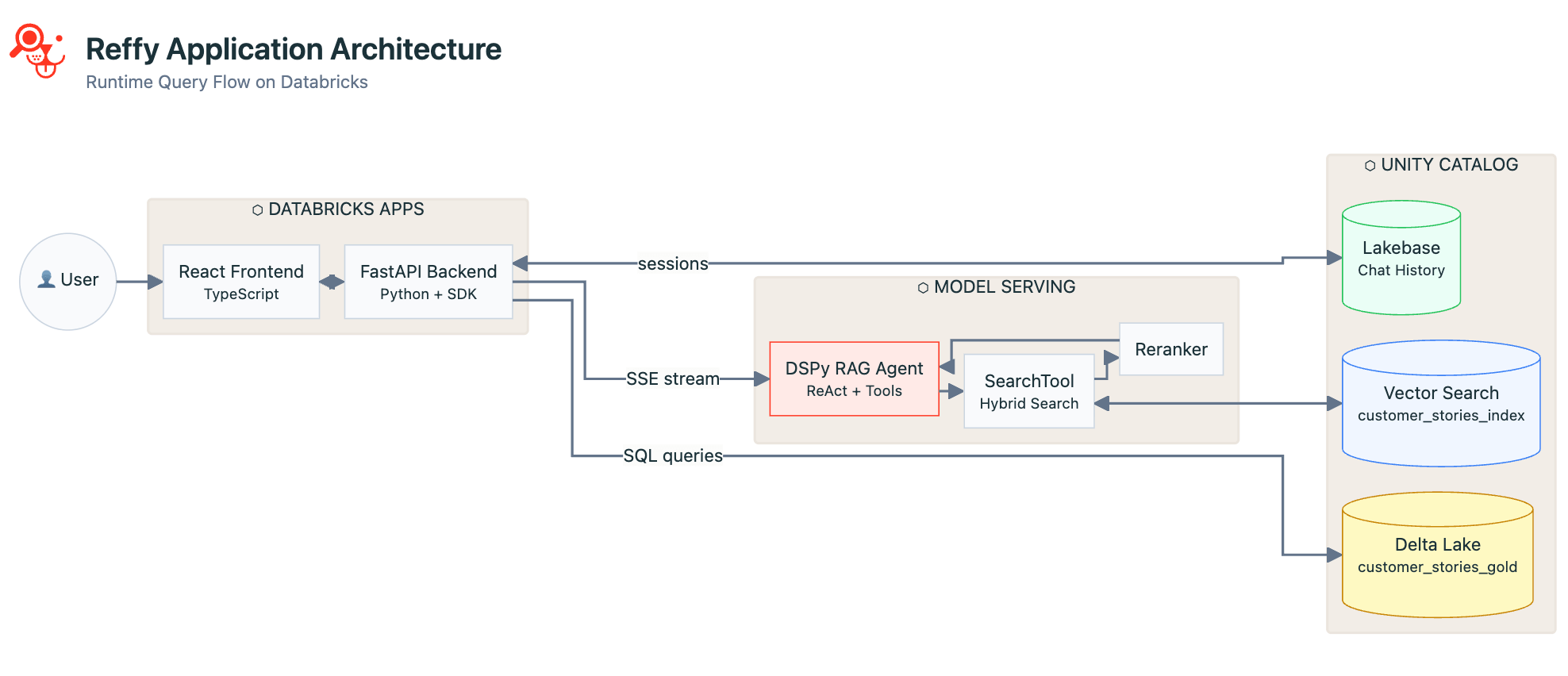
Nachdem wir nun die Daten bereinigt und indiziert haben und der Agent gut funktioniert, ist es an der Zeit, eine App zu entwickeln, die alles zusammenführt und für nicht-technische Benutzer zugänglich macht. Wir haben uns für ein React-Frontend mit einem FastAPI-Python-Backend entschieden. React ist ansprechend und reaktionsschnell im Browser und unterstützt die Streaming-Ausgabe von unserem Model-Serving-Endpunkt. FastAPI ermöglicht es uns, alle Vorteile des Databricks Python SDK in unserer App zu nutzen, nämlich:
- Einheitliche Authentifizierung – keine Codeänderungen bei der lokalen Authentifizierung während der Entwicklung im Vergleich zur Bereitstellung in Databricks Apps. Apps haben die gleichen Umgebungsvariablen wie die lokale Authentifizierung, sodass der Code nahtlos funktioniert.
- Umfassende API-Abdeckung – wir können Model Serving aufrufen, SQL-Abfragen ausführen oder alles andere, was wir aus einem Databricks Workspace benötigen könnten, und das alles über ein einziges SDK.
Reffy ist in erster Linie eine Chat-App, daher verwenden wir Lakebase, um den gesamten Gesprächsverlauf, Protokolle und Benutzeridentitäten für schnelles Lesen und Schreiben, Qualitätssicherung und durchdachte Nachverfolgung zu persistieren, wenn Benutzer zurückkehren oder neue Gespräche beginnen.
Laufendes Monitoring & Metriken
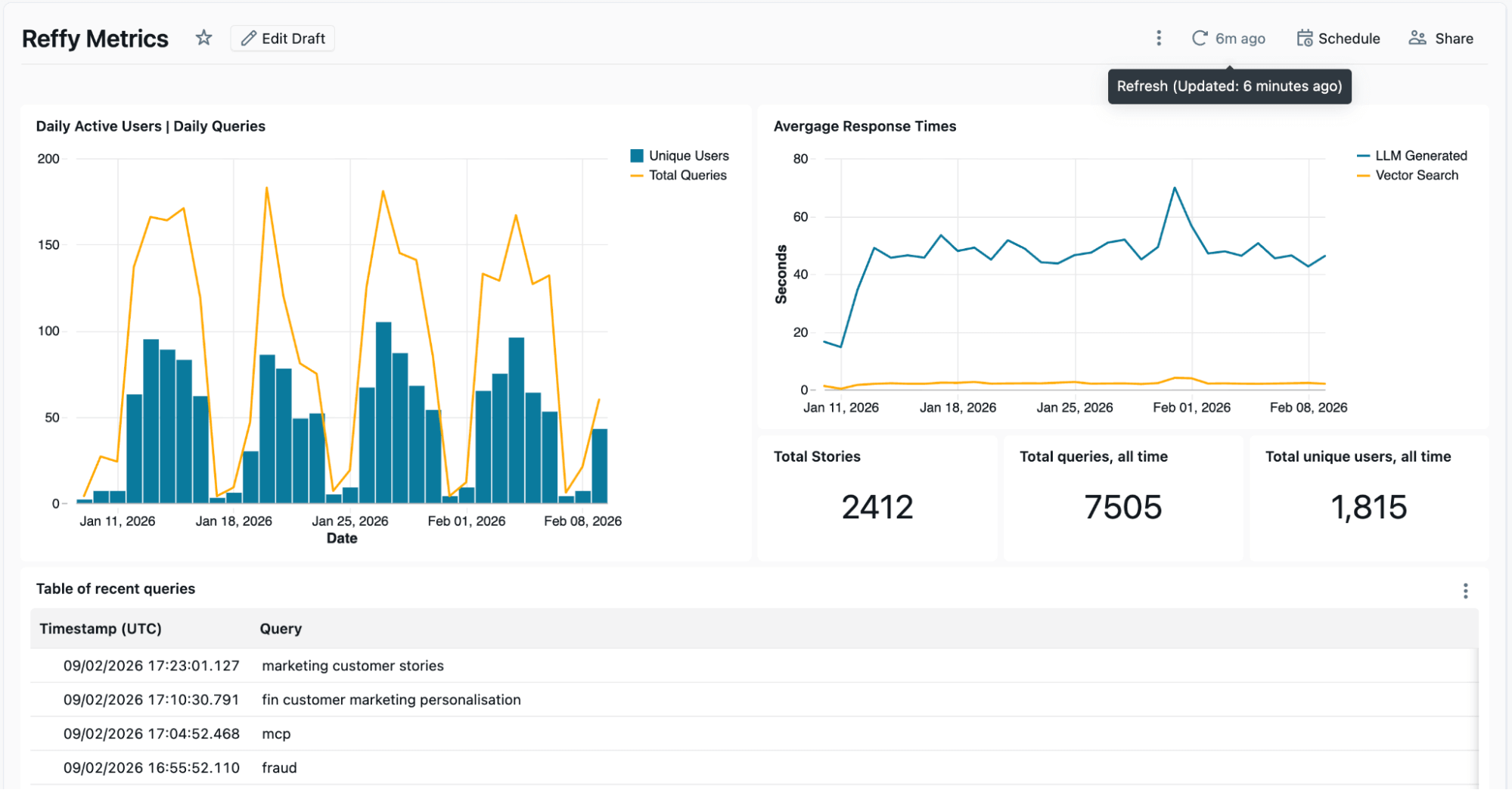
Die Logs von Lakebase werden in einem separaten Lakeflow Job verarbeitet, um Key Metriken, wie z. B. täglich aktive Benutzer und durchschnittliche Antwortzeiten, in einem AI/BI-Dashboard anzuzeigen. Dieses Dashboard zeigt uns auch aktuelle Eingaben und Antworten, und wir gehen noch einen Schritt weiter, indem wir eine weitere KI-Funktion anwenden, um die Eingaben und Antworten in aktuelle Themen und eine Lückenanalyse zusammenzufassen. Wir möchten verstehen, welche Kundenstorys beliebt sind und wo wir möglicherweise Lücken haben, und die logs, die wir von Reffy sammeln, helfen uns genau dabei. Zum Beispiel haben wir entdeckt, dass Benutzer besonders daran interessiert waren, Storys über Agent Bricks und Lakebase zu finden, zwei der neuesten Databricks-Produkte.
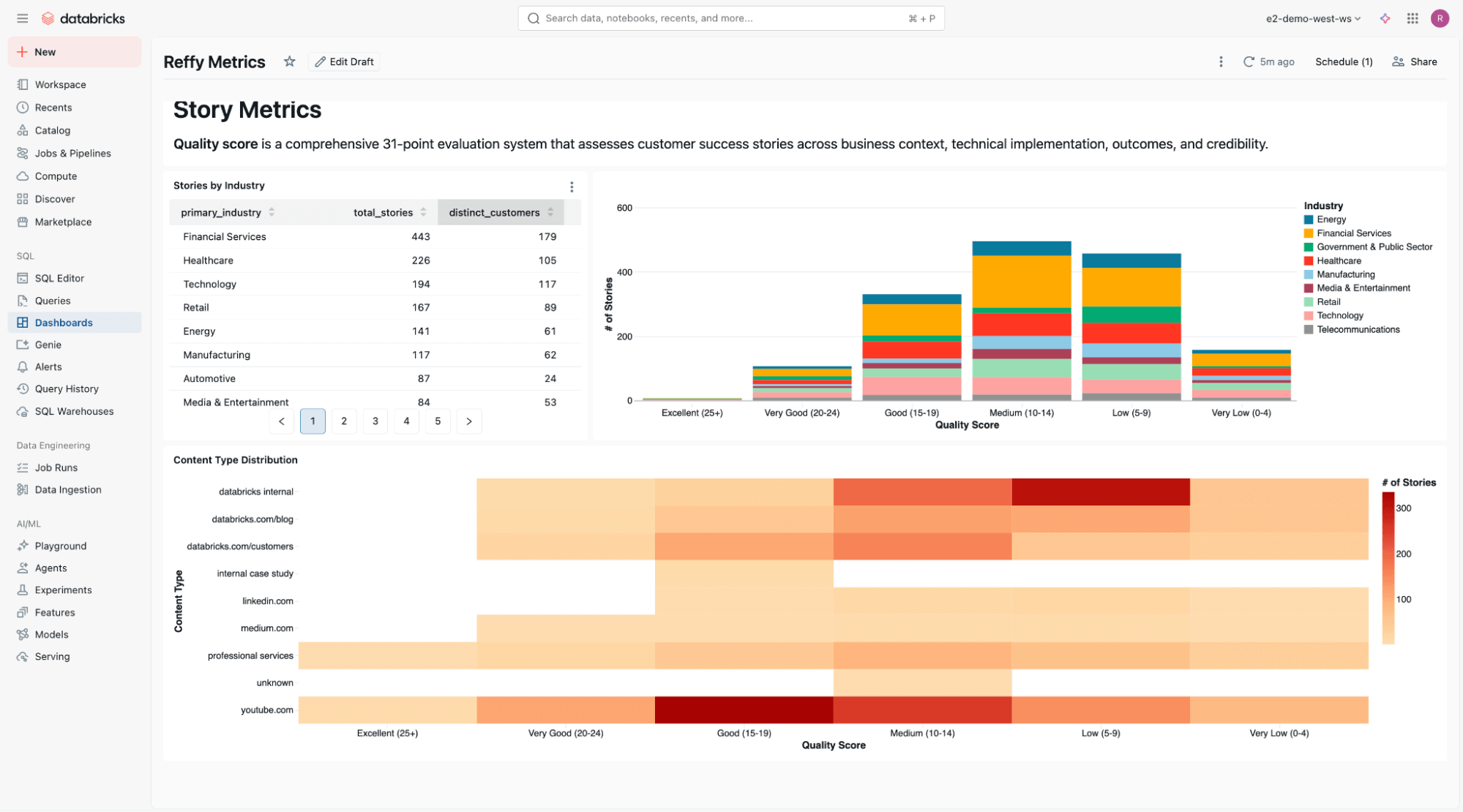
Am unteren Rand des Dashboards befindet sich eine statische Analyse der Story-Qualität über Branchen und Inhaltstypen hinweg.
Ein Hinweis zum Entwicklungs-Setup
Die meiste Projektentwicklung findet in Cursor statt, und wie bereits erwähnt, vereinfacht die einheitliche Authentifizierung zwischen dem Databricks CLI und dem SDK die Dinge. Wir melden uns einmal über das CLI an, und alle unsere lokalen Builds von Reffy, die das SDK verwenden, sind authentifiziert. Wenn wir in Databricks Apps testen möchten, verwenden wir das CLI, um den neuesten Code mit unserem Workspace zu synchronisieren und dann die App bereitzustellen. Databricks Apps prüft auf dieselben Umgebungsvariablen für die Authentifizierung, die wir lokal festgelegt haben, sodass unsere Aufrufe an Model Serving und SQL Warehouses, die auf dem SDK basieren, einfach funktionieren! Unser iterativer Entwicklungszyklus wird zu:
- Im Workspace über CLI anmelden
- Code in Cursor schreiben
- Lokal testen
- Code mit Workspace synchronisieren & App bereitstellen
- In Databricks Apps testen
Um eine ordnungsgemäße CI/CD und Portabilität zu gewährleisten, verwenden wir schließlich Databricks Asset Bundles, um den gesamten von Reffy verwendeten Code und alle Ressourcen in einem einzigen Paket zu bündeln. Dieses Bundle wird dann über GitHub Actions in unserem Ziel-Produktions-Workspace angewendet.
Was wir gelernt haben
Mehrere Teams bei Databricks hatten bereits unabhängig voneinander Teile dieses Problems gelöst und wandten sich dabei natürlich der spannendsten Arbeit zu – der KI-Ebene. Allerdings steht Data Engineering nach wie vor im Mittelpunkt & es erwies sich als ebenso entscheidend wie der Agent selbst, die ETL-Prozesse korrekt umzusetzen, die Qualität der Stories zu bewerten und die Daten für einen effektiven Abruf zu strukturieren.
Die Zusammenarbeit war ebenso wichtig. Kundenstorys berühren fast jeden Bereich der Organisation: Vertrieb, Marketing, Field Engineering und PR spielen alle eine Rolle. Der Aufbau starker Partnerschaften mit diesen Gruppen prägte sowohl das Produkt als auch die Daten, die es antreiben.
Wie geht es weiter?
Während das Anwendungs-Frontend sofortigen Mehrwert liefert, wird die wahre Stärke durch die Verbindung von Reffy mit anderen Lösungen in Databricks entstehen. Wir planen, diese Konnektivität über eine API und einen MCP-Server bereitzustellen, was es Teams ermöglicht, direkt innerhalb ihrer bestehenden Workflows und Tools auf Kundeninformationen zuzugreifen.
Mit Databricks und Lakebase können wir auch nachvollziehen, wie Tausende von Nutzern im Laufe der Zeit mit Reffy interagieren. Diese Einblicke werden es uns ermöglichen, das Tool kontinuierlich zu verfeinern und die Geschichten, die diesem wachsenden Ökosystem hinzugefügt werden, durchdacht zu gestalten.
Für Databricks-Teams, die sich heute mit der Suche nach Kundenreferenzen befassen, bietet Reffy ein konkretes Beispiel dafür, was möglich ist, wenn diese Funktionen zusammengeführt werden. Um mit der Erstellung Ihrer eigenen agentenbasierten App auf Databricks zu beginnen, erfahren Sie mehr über Databricks Apps, unseren RAG-Leitfaden, Lakebase und Agent Bricks.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.