Data Science und maschinelles Lernen ohne Code
Verbreiten Sie Data Science in Ihrer gesamten Organisation und helfen Sie allen, datengesteuerte Entscheidungen zu treffen

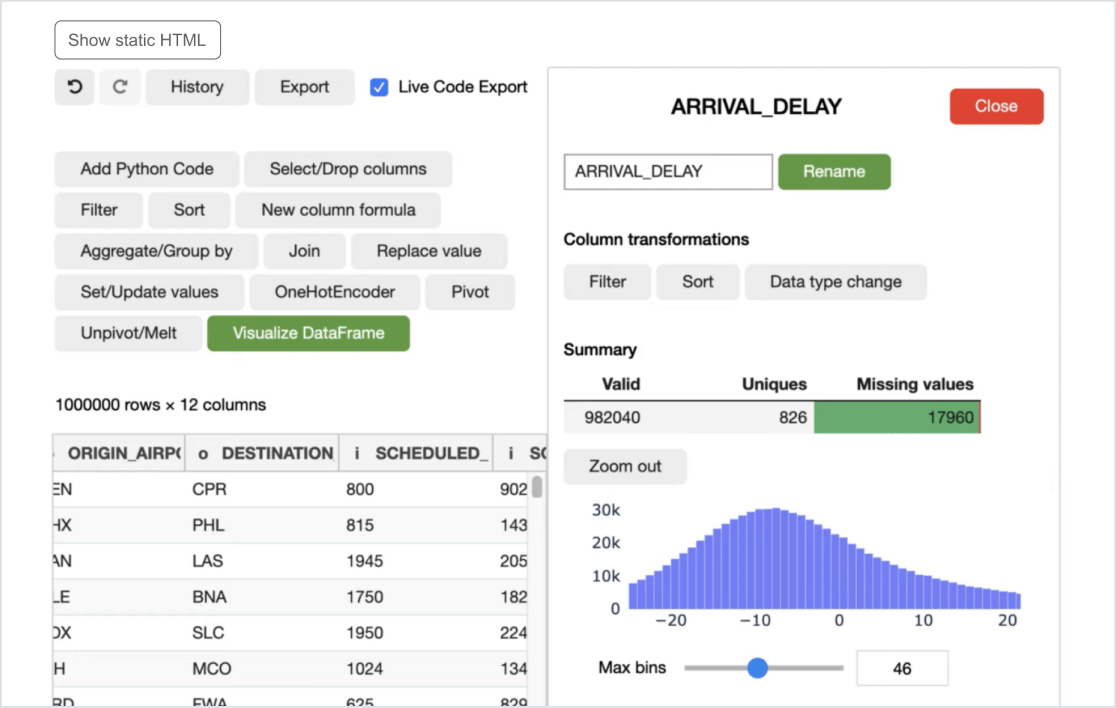
Tools mit Unternehmenszuverlässigkeit und Scale für Citizen data scientists
Databricks hilft Ihnen, große und komplexe Datensätze zu analysieren, je nach Kontext Einblicke, Erkenntnisse, Informationen, Daten, Statistiken usw. zu entdecken und mit nur wenigen Klicks Vorhersagen zu treffen. Organisieren, transformieren und visualisieren Sie Ihre Daten, ohne eine einzige Codezeile schreiben zu müssen.
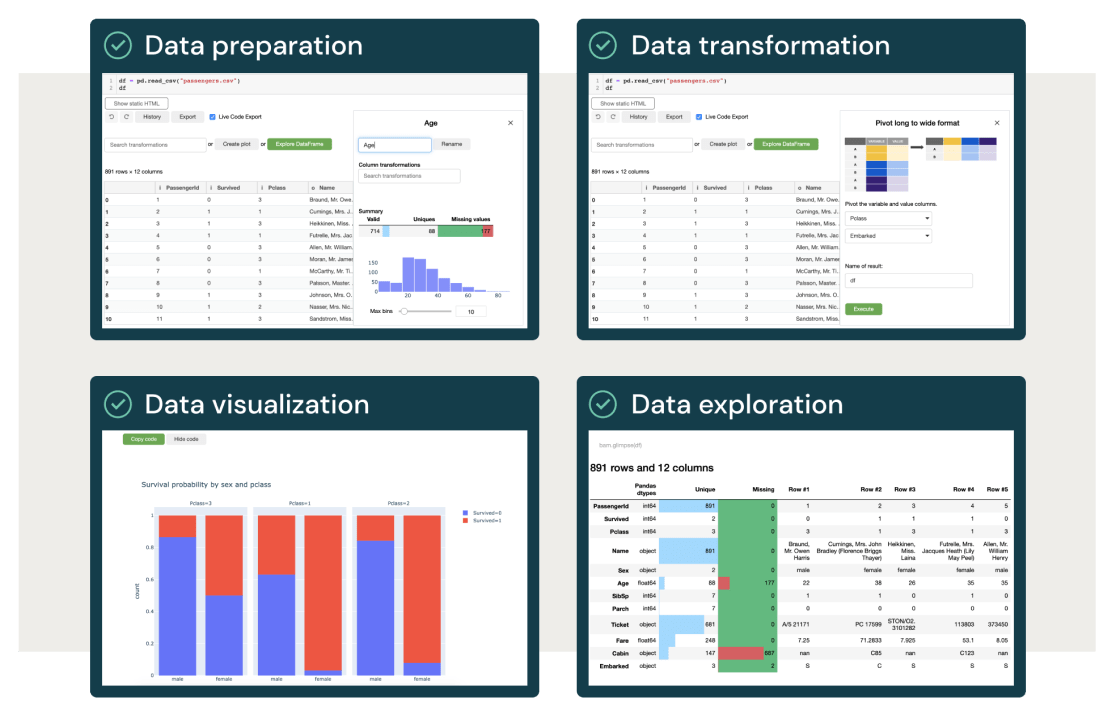
Data Engineering für Nicht-Ingenieure
Maschinelles Lernen beginnt mit Data Engineering. Jetzt können Sie erstmals Daten vorbereiten, transformieren, visualisieren und explorative Analysen durchführen, ohne Code zu schreiben. Mit Databricks kann jeder in der Organisation Daten für jeden nachgelagerten Anwendungsfall vorbereiten.
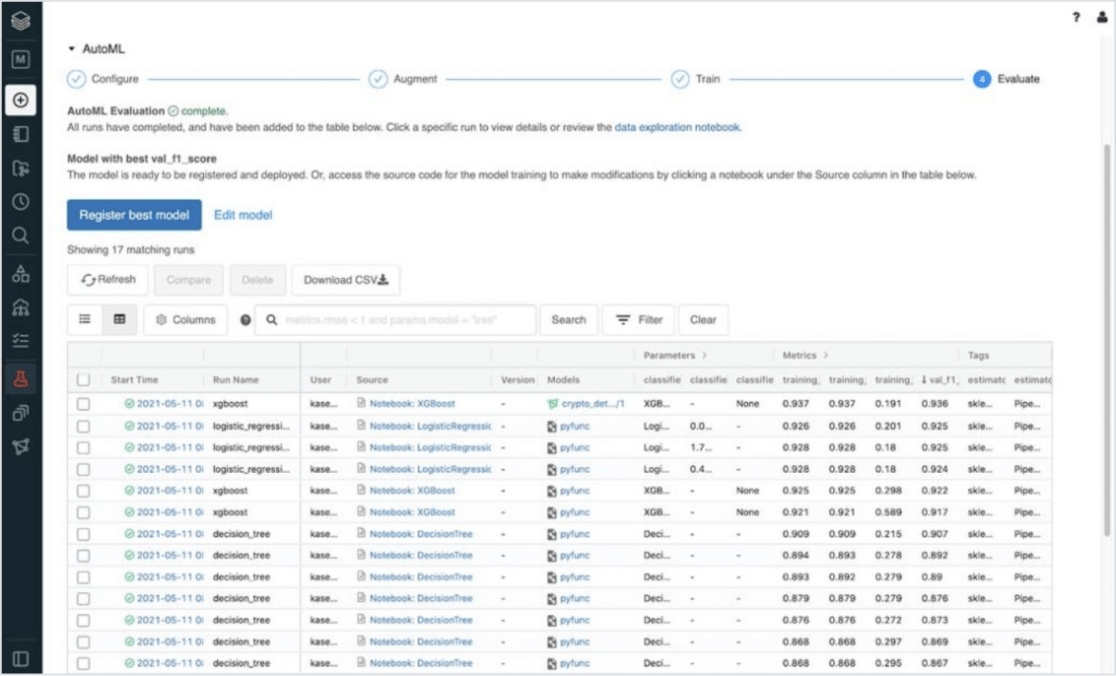
Vollautomatisches maschinelles Lernen
Databricks AutoML bietet einen Glassbox-Ansatz für Citizen Data Science, der es Teams ermöglicht, schnell Machine-Learning-Modelle (ML-Modelle) zu erstellen, zu trainieren und anzuwenden, indem die schwere Arbeit der Vorverarbeitung, Feature Engineering sowie des Training und -tunings automatisiert wird. Importieren Sie Datensätze, konfigurieren Sie Training und angewendete Modelle – ohne die Benutzeroberfläche verlassen zu müssen.
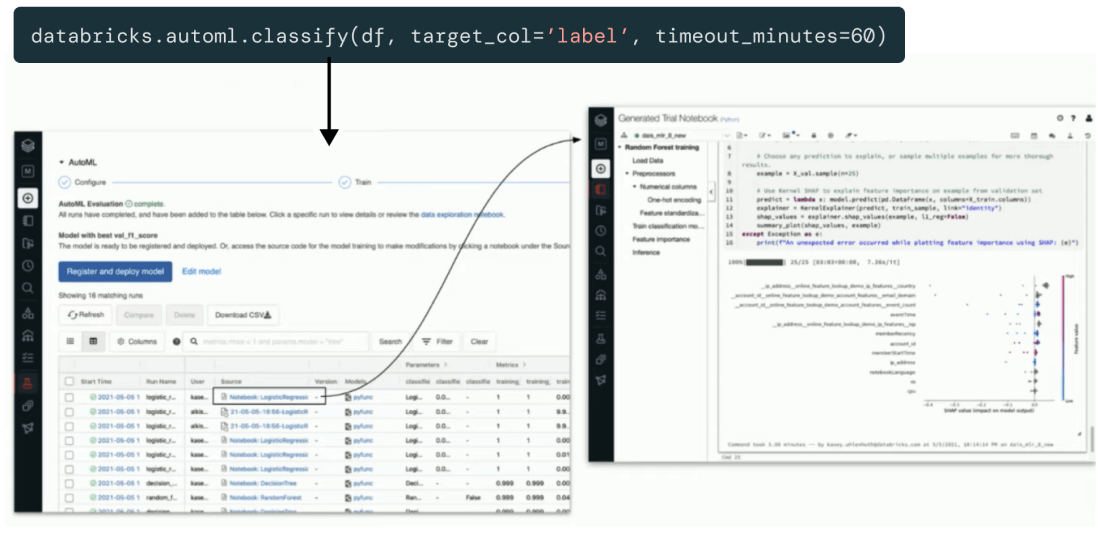
Transparenz und Sichtbarkeit für einen genaueren Blick, wenn Sie ihn brauchen
Einzigartig bei Databricks Machine Learning ist, dass alle in der Benutzeroberfläche ausgeführten Schritte im Hintergrund auch produktionstauglichen Code generieren.
Erfahrene data scientists und Ingenieure für maschinelles Lernen können diesen Code prüfen und ihre eigenen Anpassungen hinzufügen. Oder Regulierungsbehörden können darauf verweisen, wenn Reproduzierbarkeit und Transparenz von entscheidender Bedeutung sind. Databricks Machine Learning ist nativ in MLflow integriert und ermöglicht granulares Experiment Tracking, Nachverfolgung (kontextsensitiv) und Versionskontrolle – von der Vorverarbeitung und Feature Engineering bis hin zu Training und Bereitstellung.
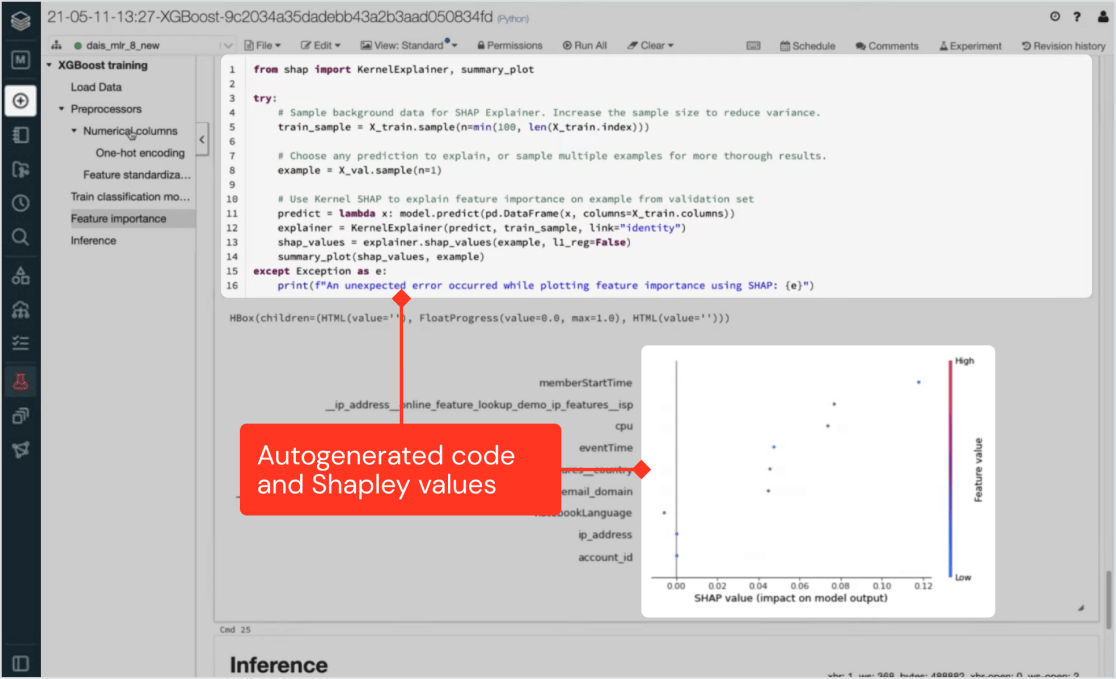
Erklärbar und konform für die abteilungsübergreifende Zusammenarbeit
Die Unterstützung von Databricksfür vollständiges Lineage Tracking, Nachverfolgung (kontextsensitiv) und Registrierung automatisch generierten Codes stellt sicher, dass Data Science Projekte aller sicher, konform und nachvollziehbar sind. Die Erklärbarkeitsfunktion bietet Einblicke, Erkenntnisse, Informationen, Daten, Statistiken usw., je nach Kontext, welche Eingaben den größten Einfluss auf das generierte Modell haben. Dies schafft eine Grundlage für die Zusammenarbeit unterschiedlichster Teams – vom Anwender über data scientists und Ingenieure für maschinelles Lernen bis hin zu IT, Recht und Compliance.
Ressourcen
E-Books
Dokumentation
Lösungen
Ready to get started with Databricks?