
Mit Databricks bringt Ihnen Data Science noch mehr Erkenntnisse
Optimieren Sie den gesamten Data-Science-Workflow – von der Datenaufbereitung über die Modellierung bis hin zum Austausch von Erkenntnissen – mit einer kollaborativen und einheitlichen Data-Science-Umgebung, die auf ein offenes Lakehouse aufsetzt. Sie erhalten schnellen Zugriff auf bereinigte und belastbare Daten, vorkonfigurierte Datenverarbeitungsressourcen, IDE-Integrationen, Unterstützung mehrerer Sprachen und integrierte fortschrittliche Visualisierungstools. So erhalten Ihre Datenanalyseteams maximale Flexibilität.

Zusammenarbeit im gesamten Data-Science-Workflow
Schreiben Sie mit Databricks Notebooks Code in Python, R, Scala und SQL, analysieren Sie Daten mit interaktiven Visualisierungen und gewinnen Sie neue Erkenntnisse. Geben Sie Ihren Code sicher und ohne Bedenken frei – mit Co-Authoring, Kommentaren, automatischer Versionierung, Git-Integrationen und rollenbasierter Zugriffssteuerung.

Schwerpunktlegung auf Data Science (statt der Infrastruktur)
Künftig sind Sie nicht mehr auf die Datenspeicherkapazität Ihres Laptops oder die Ihnen zur Verfügung stehende Compute-Leistung beschränkt. Migrieren Sie Ihre lokale Umgebung schnell in die Cloud und verbinden Sie Notebooks mit Ihren eigenen, persönlichen Compute- und automatisch verwalteten Clustern.

Ihre bevorzugte lokale IDE – mit skalierbarer Rechenleistung
Die Wahl einer IDE ist eine sehr persönliche Angelegenheit und hat erheblichen Einfluss auf die Produktivität.Verbinden Sie Ihre bevorzugte IDE mit Databricks, um künftig von unbegrenztem Datenspeicher und unbeschränkter Rechenleistung zu profitieren. Alternativ verwenden Sie RStudio oder JupyterLab einfach direkt innerhalb von Databricks. So wird das Nutzungserlebnis nahtlos.
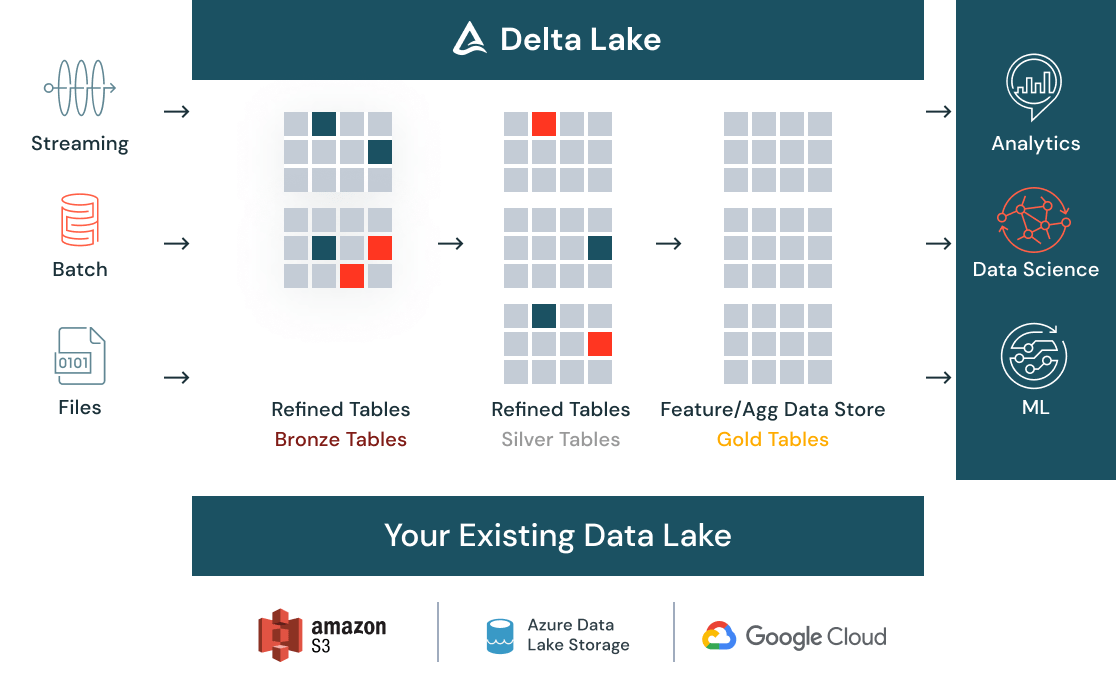
Daten für Data Science aufbereiten
Bereinigen und katalogisieren Sie alle Ihre Daten – ob Batch- oder Streaming-, strukturierte oder unstrukturierte Daten – mit Delta Lake an einer Stelle und machen Sie sie mithilfe eines zentralen Datenspeichers unternehmensweit auffindbar. Automatische Qualitätsprüfungen sorgen dafür, dass eingehende Daten alle Erwartungen erfüllen und direkt zur Analyse nutzbar sind. Und wenn Ihre Daten im Laufe der Zeit mit weiteren Daten ergänzt oder transformiert werden, sorgt die Datenversionierung dafür, dass alle Compliance-Anforderungen konsequent erfüllt werden.

Visuelle Low-Code-Tools für die Datenerkundung
Verwenden Sie native visuelle Tools aus den Databricks-Notebooks heraus, um Ihre Daten aufzubereiten, zu transformieren und zu analysieren, sodass Teams unabhängig vom jeweiligen Kenntnisstand mit Daten arbeiten können. Sobald Datentransformationen und Visualisierungen abgeschlossen sind, können Sie den Code generieren, der im Hintergrund ausgeführt wird. So sparen Sie Zeit beim Schreiben von Boilerplate-Code, sodass Sie mehr Zeit für hochwertige Arbeit haben.
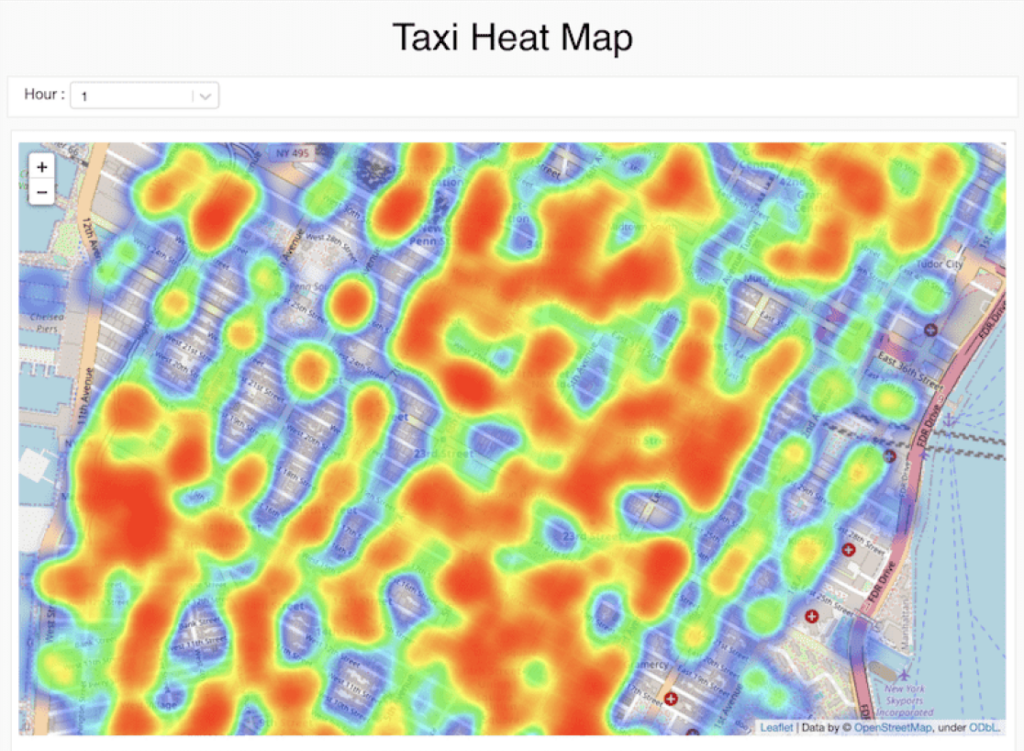
Neue Einblicke schnell entdecken und teilen
Verwandeln Sie Ihre Analyse im Handumdrehen in ein dynamisches Dashboard, um Ergebnisse schnell und einfach weiterzugeben und zu exportieren. Die Dashboards sind immer auf dem neuesten Stand und können auch interaktive Abfragen durchführen. Zellen, Visualisierungen oder Notebooks können mit rollenbasierter Zugriffssteuerung geteilt und in verschiedenen Formaten wie HTML oder IPython Notebook exportiert werden.
