Konzentrieren Sie sich auf Daten-Workloads, nicht auf die Infrastruktur.
Vollständig verwaltetes, versionsloses Spark für alle Ihre Daten- und KI-Workloads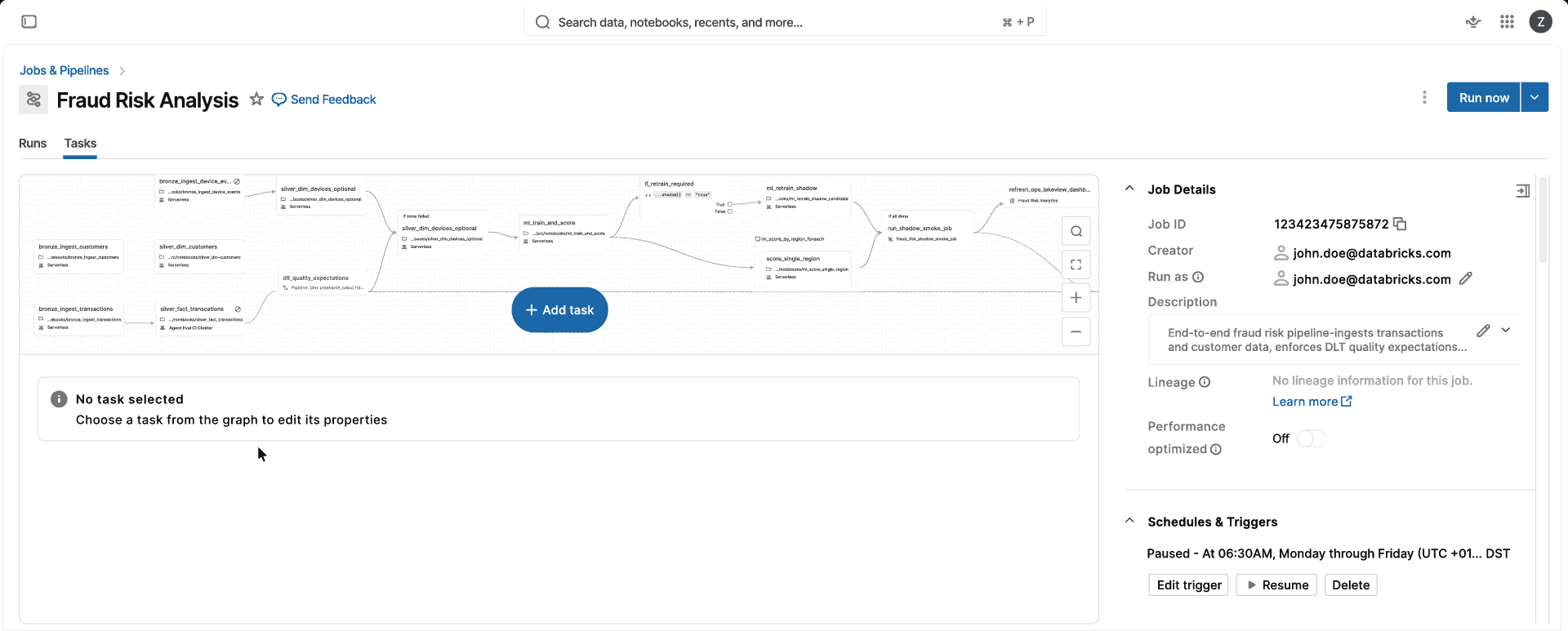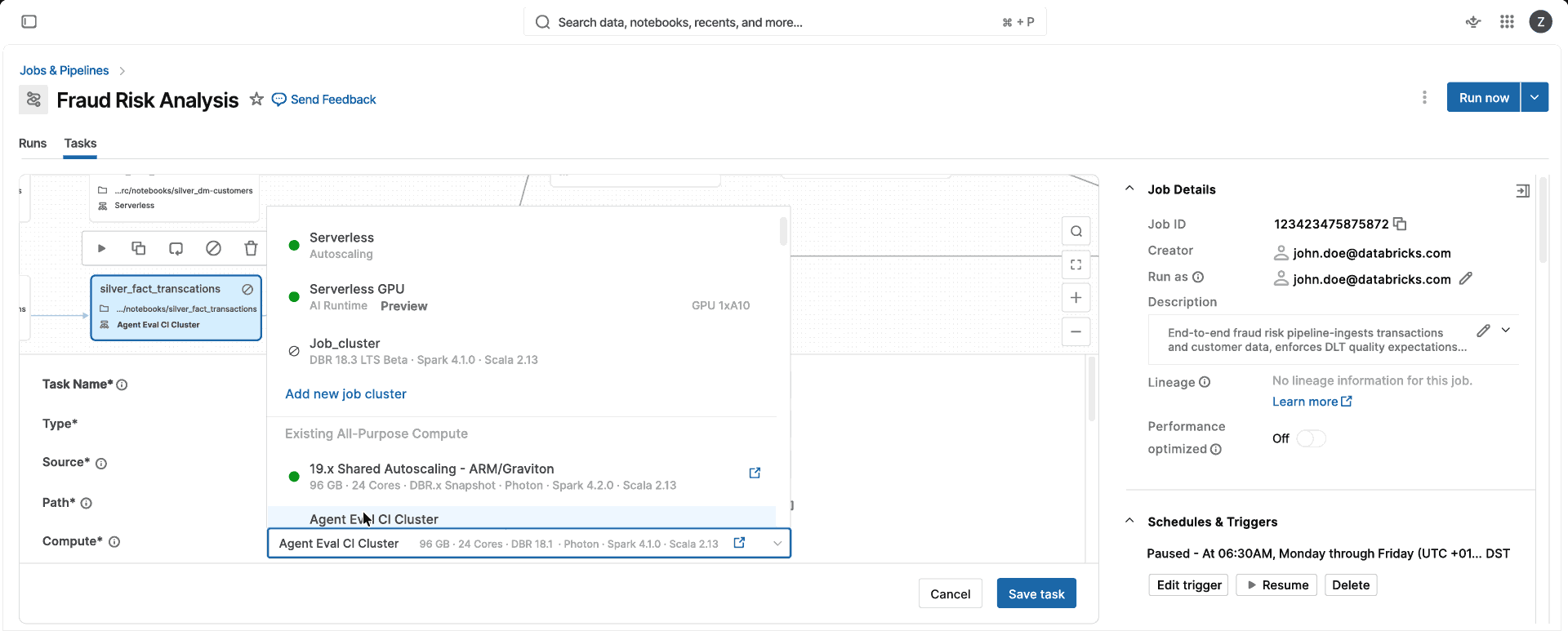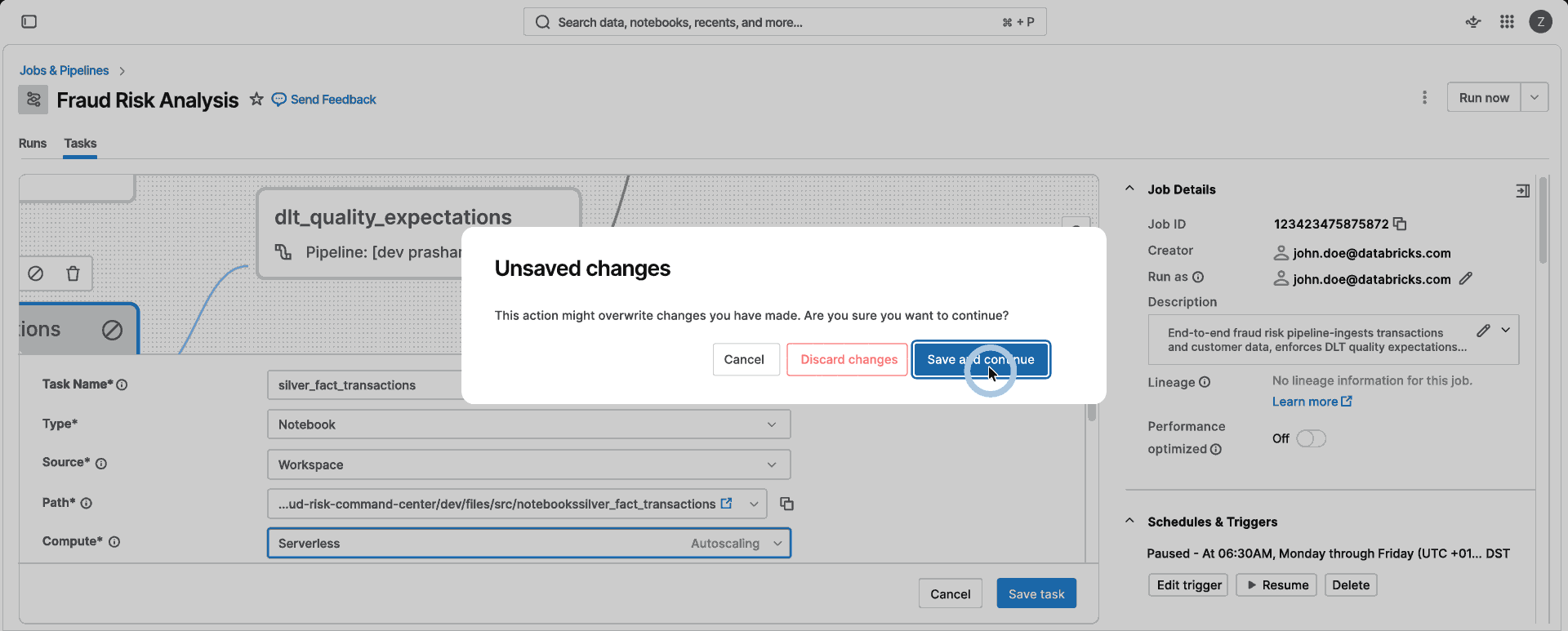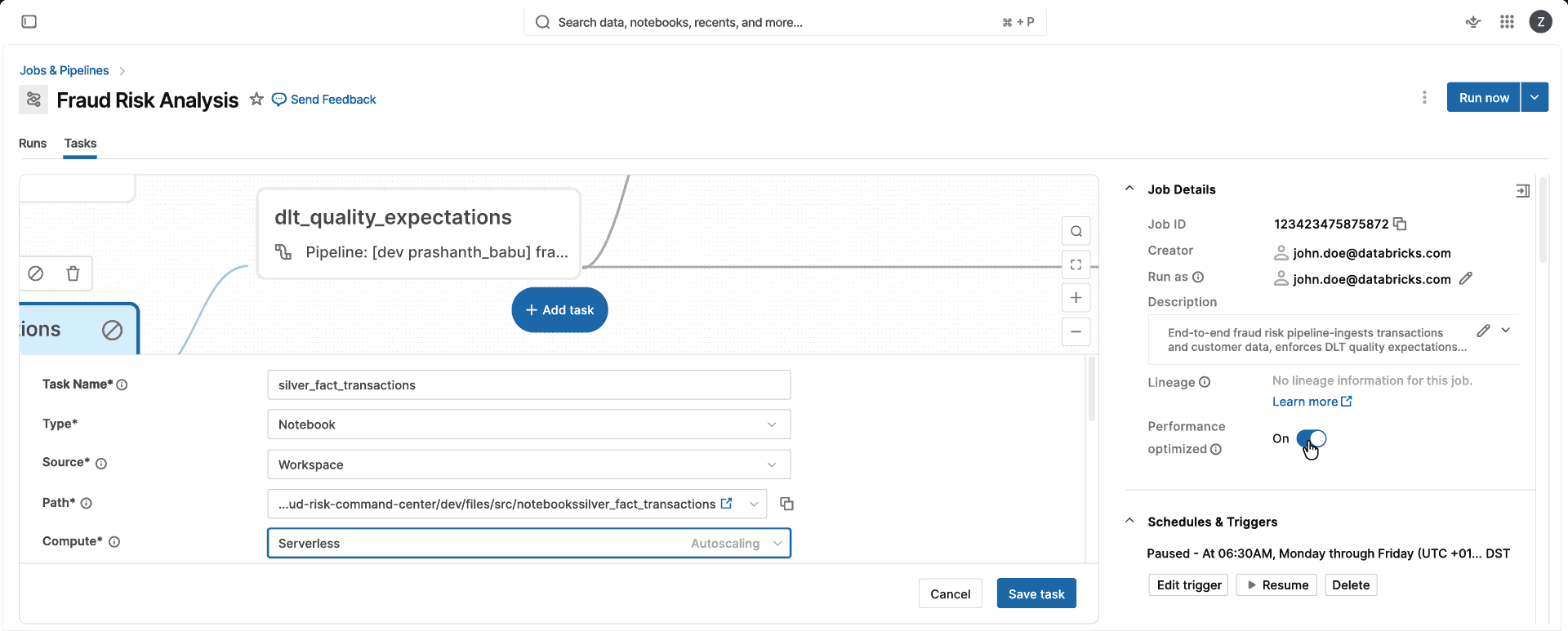
TOP-UNTERNEHMEN NUTZEN SERVERLESS COMPUTE
Wählen Sie Ihr Geschäftsziel, nicht die Infrastruktur.
Führen Sie Daten- und KI-Workloads auf einem Compute aus, das automatisch skaliert, sich aktualisiert und sich optimiert – ganz ohne Infrastrukturmanagement.Vollständig verwaltet
Ein Compute. Keine Entscheidungen über CPU-optimierte, speicheroptimierte oder Instanzklassen, keine zu verwaltende Clusterkonfiguration. Wählen Sie den Standard- oder den leistungsoptimierten Modus, und Databricks w�ählt automatisch die richtigen Instanz- und Compute-Typen (einzelne VM oder Spark-Cluster) für Sie aus, damit Ihr Team Datenprodukte bereitstellen kann, anstatt Compute zu verwalten.
Performant
Serverless start in Sekunden, nicht in Minuten, lädt Umgebungen aus dem Cache und passt die Größe automatisch an die Auslastung an. Der Standardmodus bietet eine kosteneffiziente Batch-Verarbeitung, während der leistungsoptimierte Modus latenzempfindliche Jobs in der Regel 2x schneller als klassische Cluster ausführt.
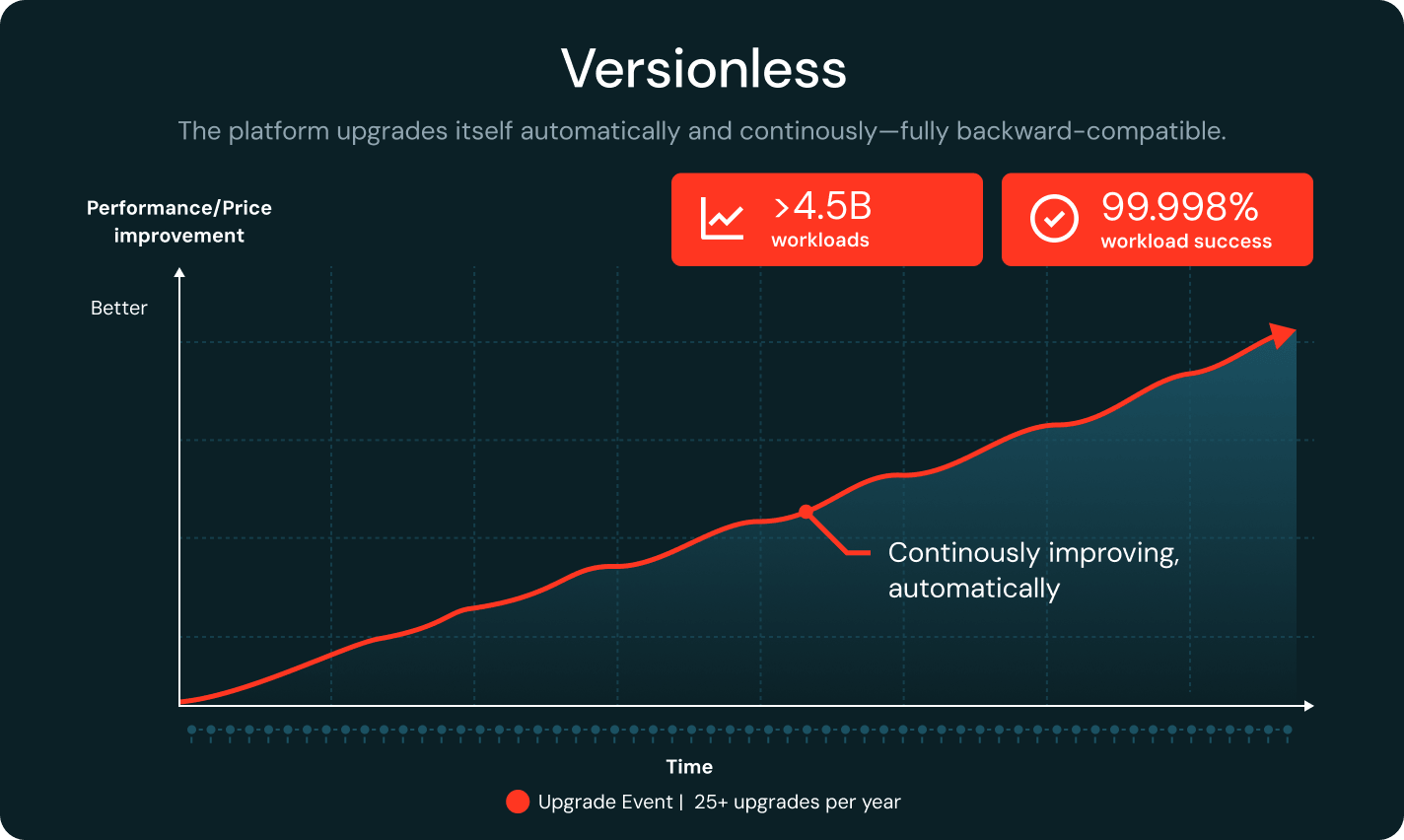
Versionslos
Databricks aktualisiert die Runtime kontinuierlich und bleibt dabei vollständig abwärtskompatibel. Die Regressionserkennung heftet Workloads automatisch an stabile Versionen. Mit über 25 Upgrades pro Jahr und einer Erfolgsrate von 99,998 % bei Workloads sparen Teams bis zu 20 % ihrer Engineering-Zeit.
Compute, das einfach funktioniert
Vergessen Sie die Infrastrukturverwaltung und führen Sie Ihre Daten- und KI-Workloads auf einer vollständig verwalteten, automatisch skalierbaren und versionslosen Compute-Plattform aus.Serverless wird kontinuierlich und automatisch aktualisiert und bleibt dabei vollständig abwärtskompatibel, sodass Workloads ohne Eingreifen weiterlaufen.
Wählen Sie den Standard-Modus für kostenoptimierte Batch-Workloads oder den Performance-Optimized-Modus für latenzempfindliche Jobs, bei dem Jobs in der Regel 2x schneller als in klassischen Clustern ausgeführt werden.
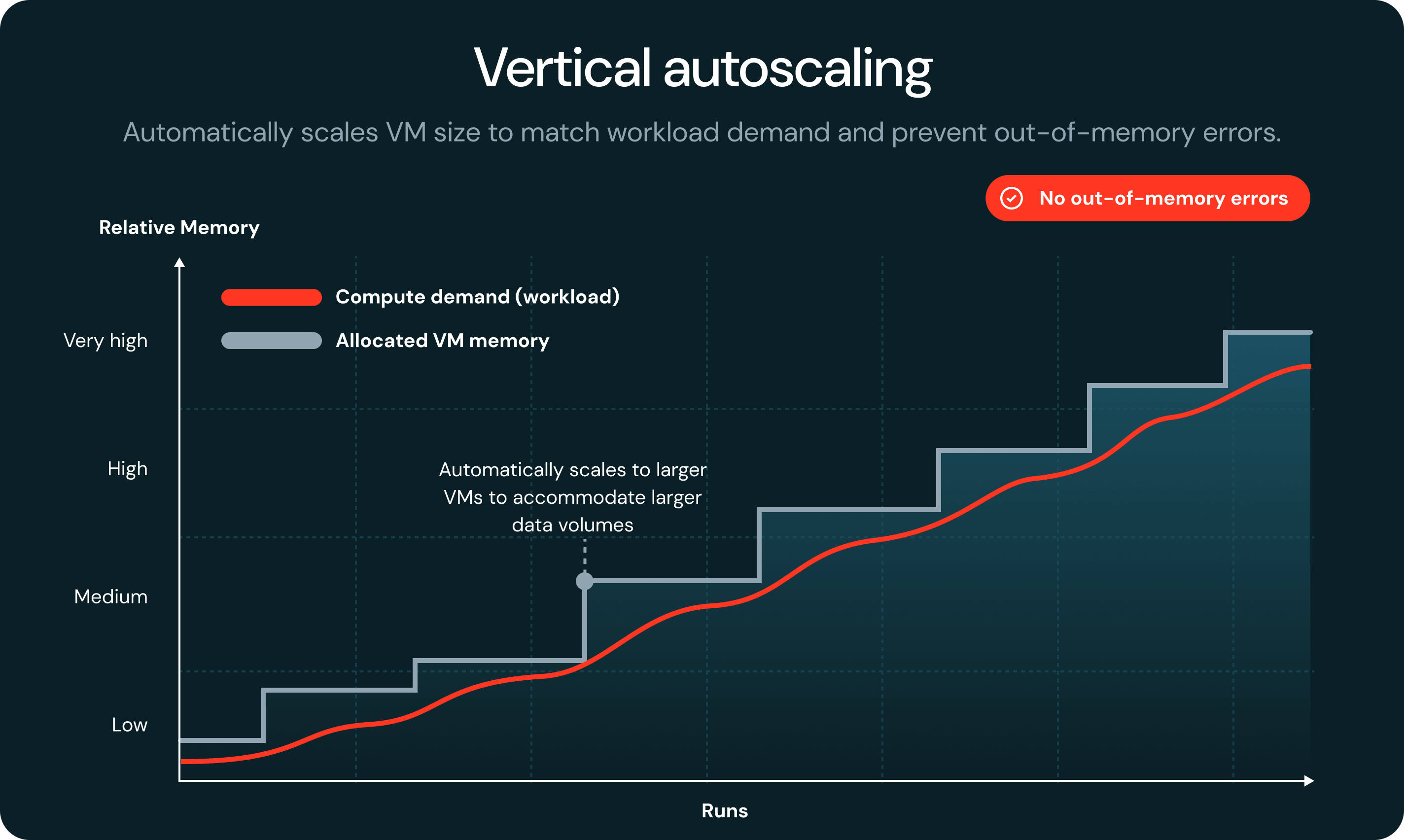
Wenn einem Task der Speicher ausgeht, erkennt Serverless den Fehler automatisch und startet ihn auf einer größeren VM neu, ohne dass es zu Jobfehlern kommt oder ein manueller Eingriff erforderlich ist.
Bibliothekumgebungen werden global zwischengespeichert. Sobald also ein Nutzer in Ihrer Organisation einen Lauf mit einem bestimmten Satz von Paketen startet, ist die Umgebung in Sekundenschnelle für alle anderen bereit.
Serverless skaliert die Rechenleistung in Sekunden statt Minuten und passt sie automatisch an die Auslastung an – ganz ohne Clusterkonfiguration.
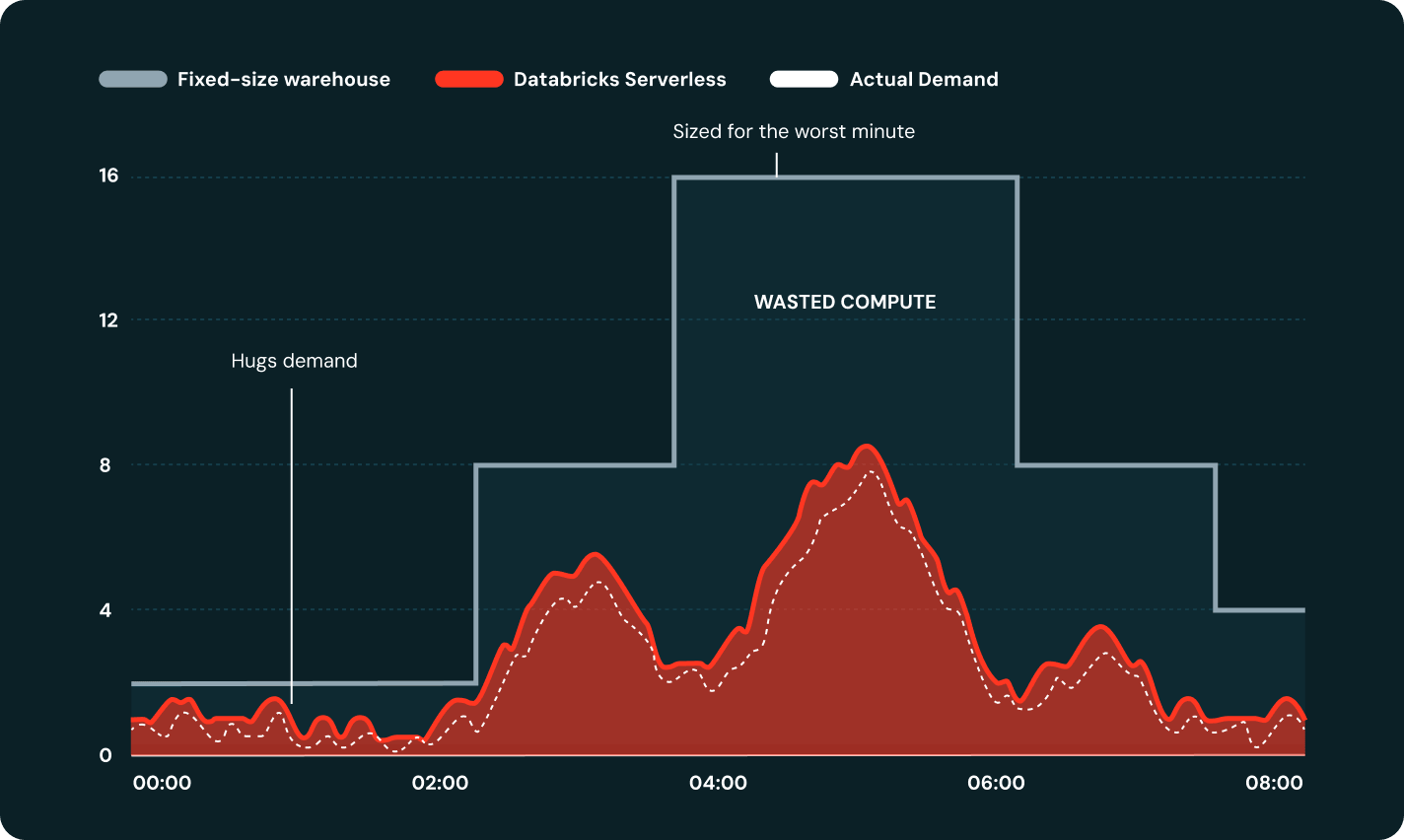
Serverless wiederholt fehlgeschlagene Aufgaben automatisch und umgeht Ausfälle auf Cloud-Ebene, sodass Pipelines im Zeitplan bleiben, ohne dass der Bereitschaftsdienst eingreifen muss.
Weitere Funktionen
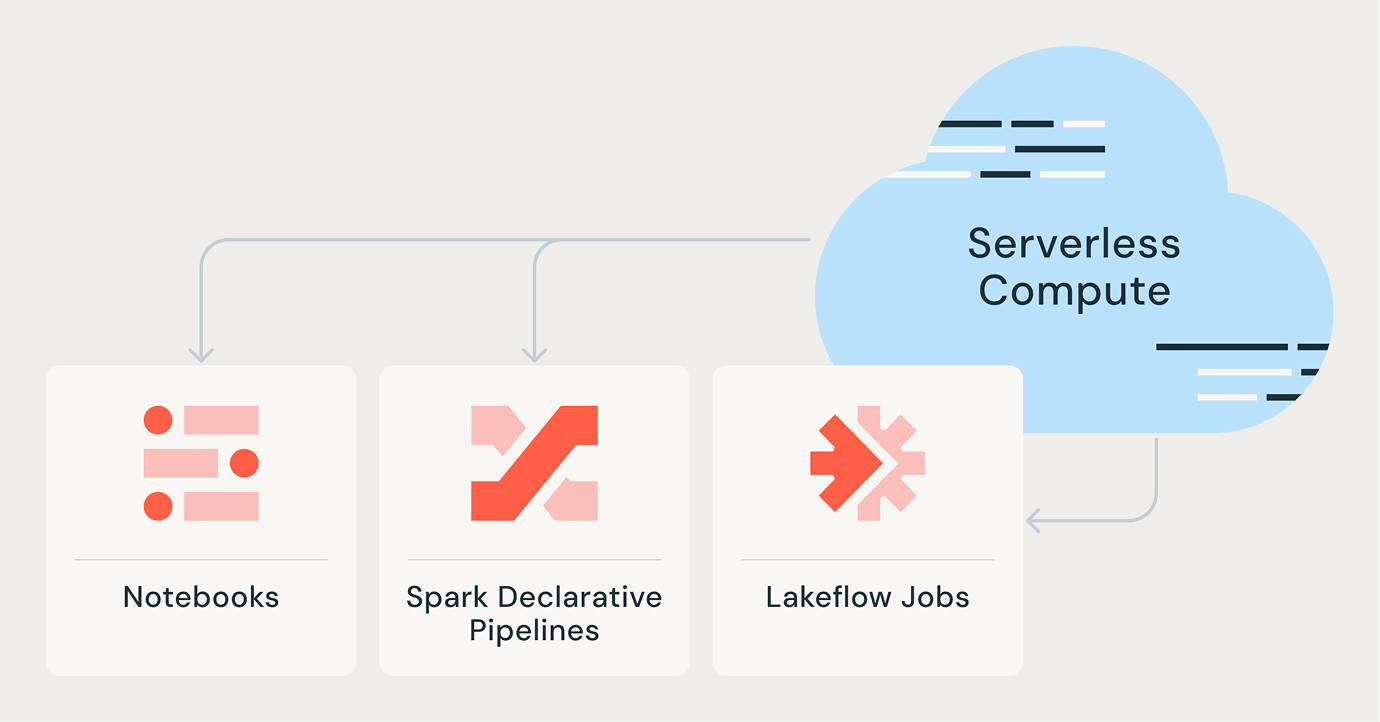
Serverless für jeden Workload

Daten abfragen, ohne die Warehouse-Rechenleistung zu verwalten.
Serverless SQL-Warehouses von Databricks starten in Sekunden und skalieren automatisch je nach Bedarf, sodass Analysten immer compute zur Verfügung steht. Keine Entscheidungen zur Dimensionierung, keine inaktiven Cluster und kein Infrastruktur-Overhead. Einfach schnelle, zuverlässige Abfragen.




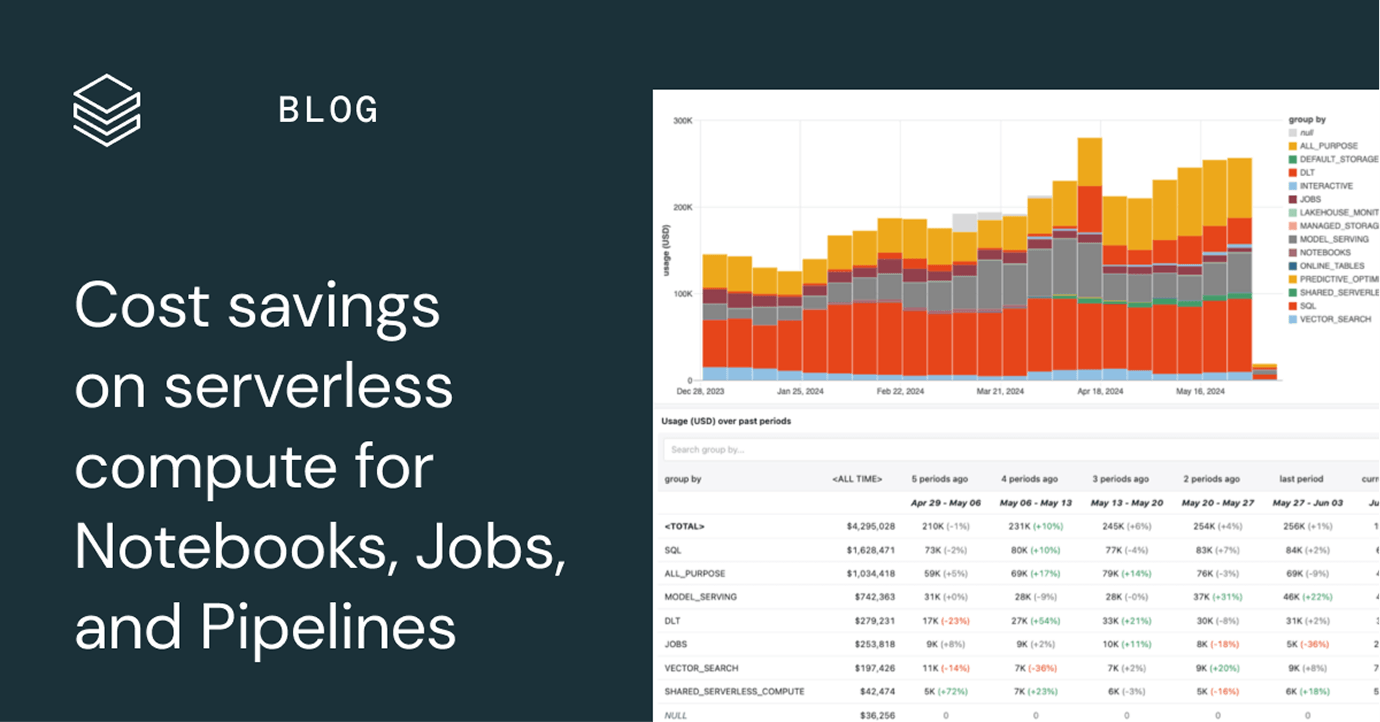
Ausgaben im Griff dank nutzungsbasierter Abrechnung
Sie zahlen nur für die Produkte, die Sie tatsächlich nutzen – und das sekundengenau.Mehr entdecken
Erfahren Sie mehr über Produkte, die auf Serverless compute basieren.
Lakeflow Jobs
Statten Sie Teams besser aus, um jeden ETL-, Analyse- und KI-Workflow mit tiefer Observability, hoher Zuverlässigkeit und breiter Unterstützung für verschiedene Aufgaben zu automatisieren und zu orchestrieren.

Databricks SQL
Ein intelligentes, selbstoptimierendes Data Warehouse auf Basis einer Lakehouse-Architektur – mit dem besten Preis-Leistungs-Verhältnis auf dem Markt.

Spark Declarative Pipelines
Vereinfachen Sie Batch- und Streaming-ETL mit automatisierter Datenqualität, Change Data Capture (CDC), Datenaufnahme, Transformation und einheitlicher Governance.

Notebooks
Steigern Sie die Teamproduktivität mit Databricks Collaborative Notebooks und ermöglichen Sie Echtzeit-Zusammenarbeit und optimierte Data-Science-Workflows.

Databricks Apps
Entwickeln Sie Anwendungen mit beliebten Frameworks, serverloser Bereitstellung und integrierter Governance. Liefern Sie leistungsstarke Lösungen für Benutzer ohne komplexe Infrastrukturverwaltung.

Lakebase
Postgres, integriert in das Lakehouse, entwickelt für moderne operative Workloads.
Wagen Sie den nächsten Schritt
Ähnliche Inhalte
FAQ zu Serverless-Compute
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Datentransformation