Intelligentes Data Warehousing auf Databricks
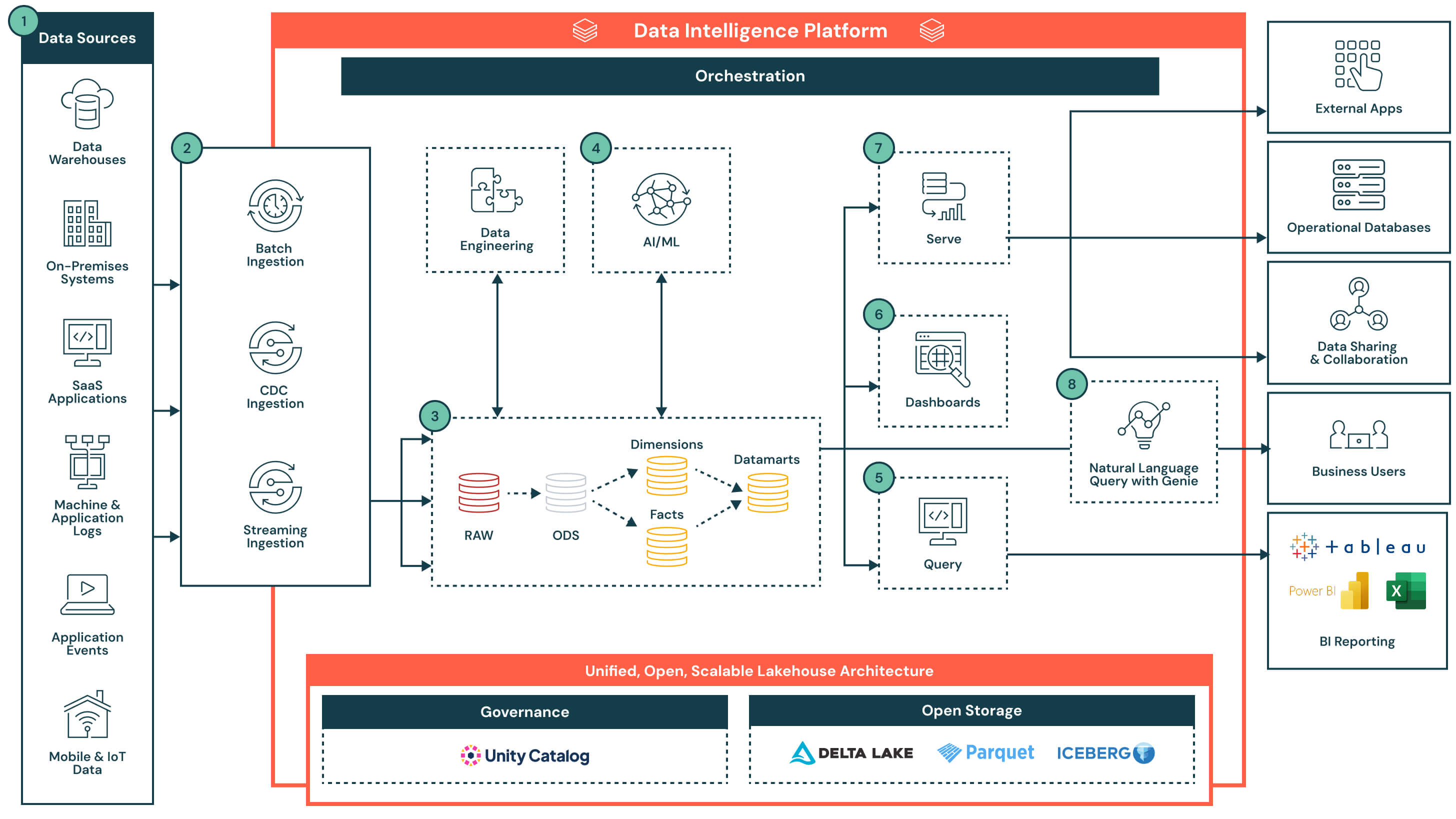
Diese Architektur zeigt, wie die Databricks Data Intelligence Plattform modernes Data Warehousing und BI ermöglicht – durch kombinierte Streaming-/Batch-Datenaufnahme, verwalteten Speicher, skalierbare SQL-Analysen und integrierte KI im Lakehouse.
Zusammenfassung der Architektur
Die Architektur unterstützt traditionelle Berichterstattung, Echtzeit-Dashboards, prädiktive Modellierung und Self-Service-Analysen - alles unter Einhaltung der Unternehmensstandards für Sicherheit, Governance und Leistung.
Diese Lösung zeigt, wie die Databricks Data Intelligence Platform, angetrieben von Databricks SQL, Organisationen dabei hilft, ihre Datenlagerstrategie zu modernisieren und dabei die Bedürfnisse sowohl von Datenteams als auch von Geschäftsinteressenten zu erfüllen.
Die Architektur beginnt mit einem offenen, geregelten Lakehouse, das vom Unity-Katalog verwaltet wird. Daten werden aus einer Reihe von Systemen - einschließlich Betriebsdatenbanken, SaaS-Anwendungen, Event-Streams und Dateisystemen - eingespeist und landen in einer zentralen Speicherschicht. Die Datenintelligenz der Plattform ermöglicht alles, von ETL und SQL-Analysen bis hin zu Dashboards und KI-Anwendungsfällen. Durch die Unterstützung flexibler Zugriffe über SQL, BI-Tools und natürliche Sprachabfragen beschleunigt die Plattform die Bereitstellung von Datenprodukten und macht Erkenntnisse im gesamten Unternehmen zugänglich.
Anwendungsfälle
Technischer Anwendungsfall
- Einnahme von strukturierten, unstrukturierten, Batch- und Streaming-Daten aus verschiedenen Quellen
- Aufbau robuster deklarativer ETL-Pipelines
- Modellierung von Fakten, Dimensionen und Datenmärkten mit einer Medaillon-Architektur
- Ausführung von SQL-Abfragen mit hoher Nebenläufigkeit für Berichterstattung und Dashboarding
- Integration von ML-Ergebnissen direkt in das Warehouse für die nachgelagerte Nutzung
Geschäftliche Anwendungsfälle
- Bereitstellung von Echtzeit-Dashboards zu Verkaufs-, Betriebs- oder Kundenmetriken
- Ermöglicht Ad-hoc-Erkundungen über natürliche Sprachschnittstellen wie Genie
- Unterstützung von prädiktiven Anwendungsfällen wie Bedarfsprognose und Churn-Modellierung
- Teilen von geregelten Datenprodukten über Abteilungen oder mit Partnern
- Bereitstellung schneller, zuverlässiger Erkenntnisse für Finanz-, Marketing- und Produktteams
Schlüsselkompetenzen mit Data Intelligence
Die Datenintelligenzkomponente dieser Architektur macht die Plattform intelligenter, anpassungsfähiger und einfacher zu bedienen für verschiedene Personas und Arbeitslasten. Sie wendet KI und Metadatenbewusstsein im gesamten System an, um Erfahrungen zu vereinfachen und Entscheidungsfindung zu automatisieren:
- Natürliche Sprachschnittstelle (Genie): Versteht den Geschäftskontext und lässt Benutzer Datenfragen in einfacher Sprache stellen
- Semantisches Bewusstsein: Erkennt Beziehungen zwischen Tabellen, Spalten und Nutzungsmustern, um Verknüpfungen, Filter oder Berechnungen vorzuschlagen
- Vorhersagende Optimierung: Stimmt kontinuierlich die Abfrageleistung und die Berechnungszuweisung auf historische Arbeitslasten ab
- Einheitliche Governance: Markiert, klassifiziert und verfolgt die Nutzung von Datenressourcen, wodurch die Entdeckung intuitiver und sicherer wird
- Schlüsselfähigkeit: Eine sich selbst optimierende Plattform, die sich an Ihre Daten und Benutzer anpasst
- Differenzierungsmerkmal: Data Intelligence ist in die Eingabe, Abfrage, Governance und Visualisierung eingebettet - nicht aufgesetzt
Datenfluss mit Schlüsselkompetenzen und Differenzierungsmerkmalen
- Datenquellen: Daten werden in einer Vielzahl von Systemen gespeichert, einschließlich Unternehmensanwendungen (z.B. SAP, Salesforce), Datenbanken, IoT-Geräten, Anwendungsprotokollen und externen APIs. Diese Quellen können strukturierte, halbstrukturierte oder unstrukturierte Daten erzeugen.
- Dateneingabe: Nimmt Daten über Batch-Jobs, Change Data Capture (CDC) oder Streaming auf. Diese Pipelines speisen die Lakehouse-Architektur in nahezu Echtzeit oder in geplanten Intervallen, abhängig vom Quellsystem und dem Anwendungsfall.
- Schlüsselunterschied: Vereinheitlichte Aufnahme für alle Modalitäten - Batch, Streaming und CDC - ohne separate Infrastruktur oder Pipelines zu benötigen
- Daten Transformation, ETL, Deklarative Pipelines: Nach der Aufnahme wird die Daten durch die Medaillon-Architektur transformiert und schrittweise von Rohdaten zu kuratierten Daten verfeinert.
- Rohzone zu Bronzezone: Daten werden von externen Quellsystemen aufgenommen, wobei die Strukturen in dieser Schicht den Tabellenstrukturen des Quellsystems "wie sie sind" entsprechen, ohne Transformation oder Aktualisierungen der Daten
- Bronze-Zone zur Silber-Zone: Standardisierung und Bereinigung eingehender Daten
- Silberzone zu Goldzone: Anwendung von Geschäftslogik zur Erstellung wiederverwendbarer Modelle
- Fakten und Dimensionen → Datenmärkte: Aggregieren und kuratieren von Daten für nachgelagerte Analysen
- Schlüsselunterschied: Deklarative, produktionsreife Pipelines mit eingebauter Abstammung, Beobachtbarkeit und Schemaevolution
- Kuratierte Daten für KI-Anwendungsfälle: Kuratierte Daten aus Datenmärkten können zum Trainieren oder Anwenden von Machine-Learning-Modellen verwendet werden. Diese Modelle unterstützen Anwendungsfälle wie Nachfrageprognose, Anomalieerkennung und Kundenscoring.
- Modellergebnisse werden neben traditionellen Warehouse-Daten gespeichert, um einen einfachen Zugriff über SQL oder Dashboards zu ermöglichen
- Ergebnisse können je nach Anforderungen regelmäßig aktualisiert oder in Echtzeit bewertet werden
- Schlüsseldifferenzierung: Kollokation von Analyse- und KI-Workloads auf derselben Plattform - keine Datenbewegung erforderlich. Modellausgaben werden als native, abfragbare, geregelte Assets behandelt.
- Abfragefütternde BI-Berichtswerkzeuge: Databricks SQL unterstützt hochparallele, latenzarme Abfragen durch serverloses Rechnen und lässt sich leicht mit beliebten BI-Tools verbinden.
- Integrierter Abfrage-Editor und Abfrageverlauf
- Abfragen liefern geregelte, aktuelle Ergebnisse aus Datenmärkten oder angereicherten Modellergebnissen
- Schlüsselunterschied: Databricks SQL ermöglicht es BI-Tools, Daten direkt abzufragen - ohne Replikation - was die Komplexität reduziert, zusätzliche Lizenzkosten vermeidet und die Gesamtbetriebskosten senkt. In Kombination mit serverlosem Rechnen und intelligenter Optimierung bietet es Lagerleistung mit minimaler Abstimmung.
- Dashboards: Können direkt in Databricks oder in externen BI-Tools wie Power BI oder Tableau erstellt werden. Benutzer können Visualisierungen in natürlicher Sprache beschreiben, und der Databricks-Assistent generiert die entsprechenden Diagramme, die dann mit einer Point-and-Click-Schnittstelle verfeinert werden können.
- Erstellen von Visualisierungen mit natürlicher Spracheingabe
- Modifizieren und erkunden Sie Dashboards interaktiv mit Filtern und Drill-Downs
- Veröffentlichen und sicher teilen von Dashboards in der gesamten Organisation, einschließlich mit Benutzern außerhalb des Databricks-Arbeitsbereichs
- Schlüsseldifferenzierung: Bietet ein Low-Code- und KI-unterstütztes Erlebnis für den Aufbau und die Erkundung von Dashboards auf geregelten, Echtzeit-Daten
- Bereitstellung kuratierter Daten: Nach der Verfeinerung können Daten über Dashboards hinaus bereitgestellt werden:
- Geteilt mit nachgelagerten Anwendungen oder operationellen Datenbanken für transaktionale Entscheidungsfindung
- Verwendung in kollaborativen Notizbüchern zur Analyse
- Verteilt über Delta Sharing an Partner, Teams oder externe Verbraucher mit einheitlicher Governance
- Natürliche Sprachabfrage (NLQ): Geschäftsanwender können auf verwaltete Daten mit natürlicher Sprache zugreifen. Diese konversationelle Erfahrung, angetrieben durch generative KI, ermöglicht es Teams, über statische Dashboards hinauszugehen und Echtzeit-, Self-Service-Einblicke zu erhalten. NLQ übersetzt Benutzerabsichten in SQL, indem es die Semantik und Metadaten des Unternehmens aus dem Unity-Katalog nutzt.
- Unterstützt Ad-hoc-, interaktive, Echtzeit-Fragen, die nicht in Dashboards vorgebaut sind
- Passt sich intelligent der sich entwickelnden Geschäftsterminologie und dem Kontext im Laufe der Zeit an
- Nutzt bestehende Daten-Governance und Zugriffskontrollen über den Unity-Katalog
- Bietet Auditierbarkeit und Nachverfolgbarkeit von natürlichen Sprachabfragen für Compliance und Transparenz
- Schlüsseldifferenzierung: Passt sich kontinuierlich an sich entwickelnde Geschäftskonzepte an und liefert genaue, kontextbewusste Antworten ohne SQL-Kenntnisse
- Plattformfähigkeiten: Governance, Leistung, Orchestrierung und offener Speicher: Die Architektur wird durch eine Reihe von plattformeigenen Fähigkeiten gestützt, die Sicherheit, Optimierung, Automatisierung und Interoperabilität über den gesamten Datenlebenszyklus hinweg unterstützen. Schlüsselkompetenzen:
- Governance: Der Unity-Katalog bietet zentralisierten Zugriffskontrolle, Herkunft, Auditierung und Datenklassifizierung für alle Workloads
- Leistung: Photon-Motor, intelligentes Caching und arbeitslastbewusste Optimierung liefern schnelle Abfragen ohne manuelle Abstimmung
- Orchestrierung: Eingebaute Orchestrierung verwaltet Datenpipelines, KI-Workflows und geplante Jobs über Batch- und Streaming-Arbeitslasten hinweg, mit nativer Unterstützung für Abhängigkeitsmanagement und Fehlerbehandlung
- Offener Speicher: Daten werden in offenen Formaten (Delta Lake, Parquet, Iceberg) gespeichert, was Interoperabilität über Tools, Portabilität zwischen Plattformen und langfristige Haltbarkeit ohne Vendor-Lock-in ermöglicht
- Überwachung und Prüfbarkeit: End-to-End-Sichtbarkeit in Abfrageleistung, Pipeline-Ausführung und Benutzerzugriff für eine bessere Kontrolle und Kostenmanagement
- Schlüsselunterschied: Plattformebene Dienste sind integriert - nicht aufgeschichtet - was sicherstellt, dass Governance, Automatisierung und Leistung über alle Datenworkflows, Clouds und Teams hinweg konsistent sind
Empfohlen

Referenzarchitektur

Referenzarchitektur

Industriearchitektur

Industriearchitektur