5 mosse fondamentali per una migrazione efficace da Hadoop all'architettura lakehouse
di Harsh Narula
La decisione di migrare da Hadoop a una moderna architettura basata sul cloud come l'architettura lakehouse è una decisione aziendale, non tecnologica. In un blog precedente, abbiamo approfondito i motivi per cui ogni organizzazione deve rivalutare il proprio rapporto con Hadoop. Una volta che gli stakeholder dei settori tecnologia, dati e business prendono la decisione di far migrare l'azienda da Hadoop, vi sono diverse considerazioni da fare prima di iniziare la transizione vera e propria. In questo blog, ci concentreremo specificamente sul processo di migrazione vero e proprio. Scoprirai i passaggi chiave per una migrazione di successo e il ruolo che l'architettura lakehouse svolge nell'innescare la prossima ondata di innovazione basata sui dati.
I passaggi della migrazione
Diciamo le cose come stanno. Le migrazioni non sono mai facili. Tuttavia, le migrazioni possono essere strutturate per ridurre al minimo l'impatto negativo, garantire la continuità operativa e gestire i costi in modo efficace. Per farlo, suggeriamo di suddividere la migrazione da Hadoop in questi cinque passaggi chiave:
- Amministrazione
- Migrazione dei dati
- Elaborazione dei dati
- Sicurezza e governance
- SQL e livello BI
Fase 1: Amministrazione
Esaminiamo alcuni dei concetti essenziali di Hadoop dal punto di vista dell'amministrazione e come si confrontano e differiscono rispetto a Databricks.
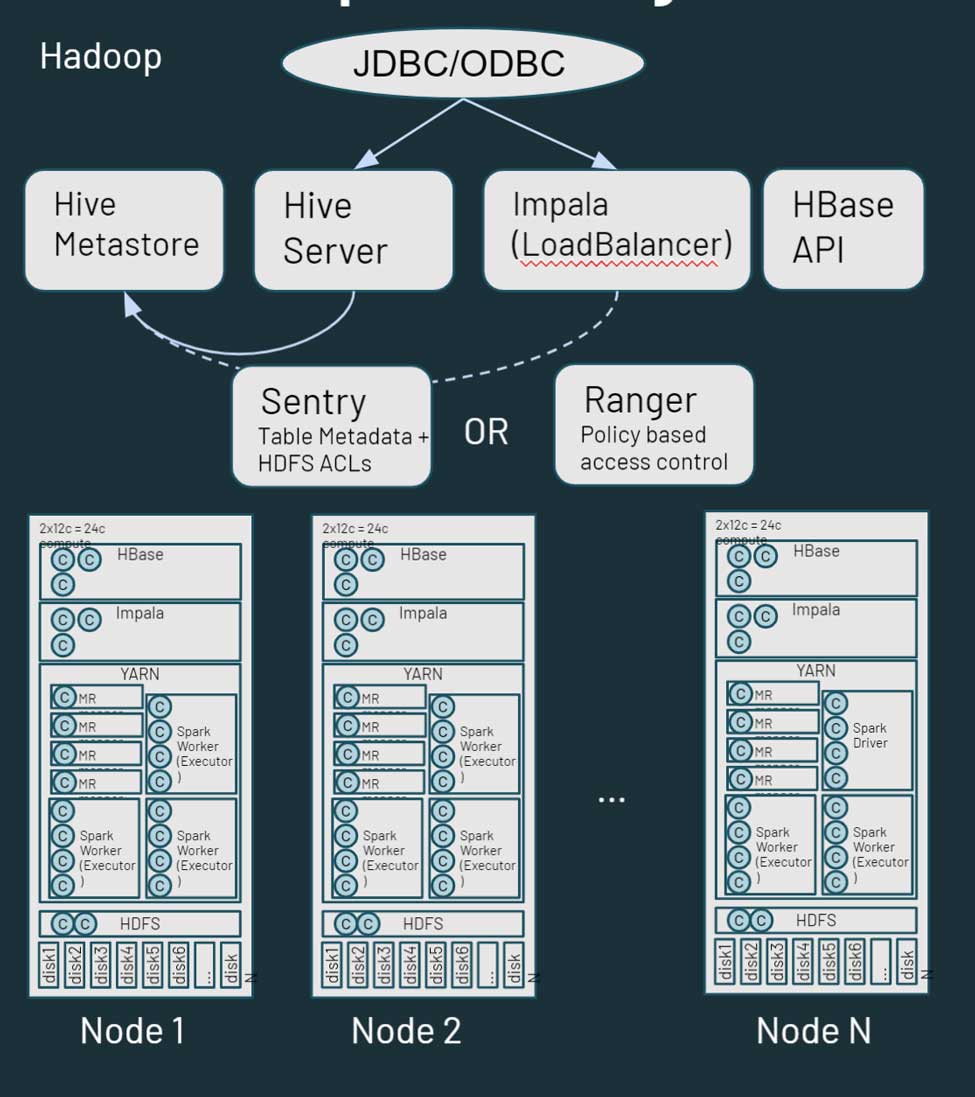
Hadoop è essenzialmente una piattaforma monolitica di archiviazione e compute distribuita. È costituito da più nodi e server, ciascuno con la propria capacità di archiviazione, CPU e memoria. Il lavoro è distribuito su tutti questi nodi. La gestione delle risorse avviene tramite YARN, che cerca di garantire al meglio che i carichi di lavoro ricevano la loro quota di risorse di calcolo.
Hadoop è costituito anche da metadati. È presente un metastore Hive, che contiene informazioni strutturate sugli asset archiviati in HDFS. È possibile utilizzare Sentry o Ranger per controllare l'accesso ai dati. Dal punto di vista dell'accesso ai dati, utenti e applicazioni possono accedere ai dati direttamente tramite HDFS (o le CLI/API corrispondenti) o tramite un'interfaccia di tipo SQL. L'interfaccia SQL, a sua volta, può basarsi su una connessione JDBC/ODBC utilizzando Hive per SQL generico (o in alcuni casi script ETL) o Hive su Impala o Tez per query interattive. Hadoop fornisce anche un'API HBase e servizi di sorgente di dati correlati. Maggiori informazioni sull'ecosistema Hadoop sono disponibili qui.
Di seguito, vedremo come questi servizi vengono mappati o gestiti nella Databricks Lakehouse Platform. In Databricks, una delle prime differenze da notare è che si ha a che fare con più cluster in un ambiente Databricks. Ogni cluster può essere utilizzato per un caso d'uso specifico, un progetto, una business unit, un team o un gruppo di sviluppo. Ancora più importante, questi cluster sono progettati per essere effimeri. Per i cluster di job, il ciclo di vita del cluster è destinato a durare per l'intera durata del flusso di lavoro. Eseguirà il flusso di lavoro e, una volta completato, l'ambiente verrà smantellato automaticamente. Allo stesso modo, se si pensa a un caso d'uso interattivo, in cui è presente un ambiente compute condiviso tra gli sviluppatori, questo ambiente può essere avviato all'inizio della giornata lavorativa, e gli sviluppatori possono eseguire il loro codice per tutto il giorno. Durante i periodi di inattività, Databricks lo smantellerà automaticamente tramite la funzionalità di terminazione automatica (configurabile) integrata nella piattaforma.
A differenza di Hadoop, Databricks non fornisce servizi di archiviazione dati come HBase o SOLR. I tuoi dati risiedono nella tua archiviazione di file, all'interno dell'archiviazione a oggetti. Molti dei servizi come HBase o SOLR hanno alternative o offerte di tecnologia equivalenti in cloud. Potrebbe trattarsi di una soluzione nativo per il cloud o ISV.
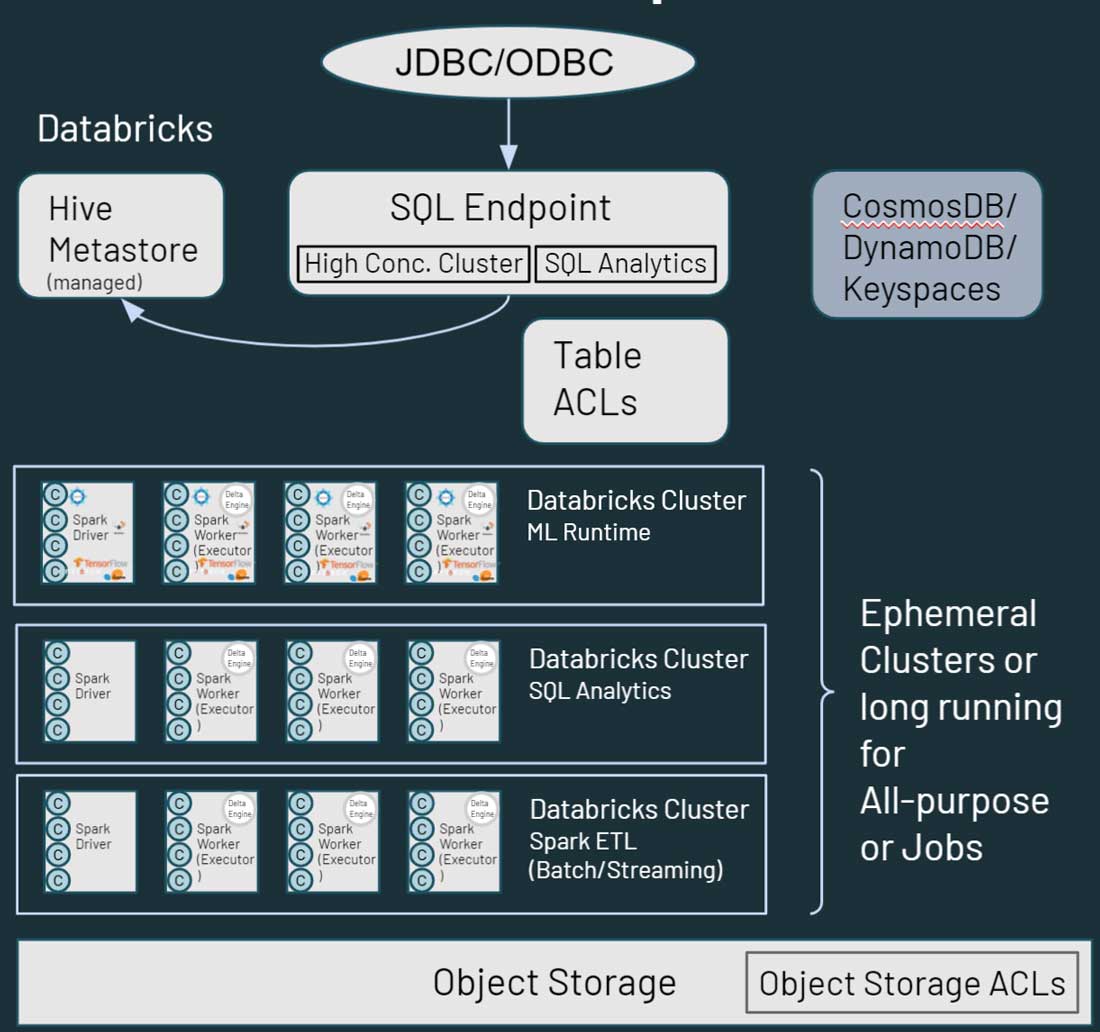
Come si può vedere nel diagramma sopra, ogni nodo del cluster in Databricks corrisponde a un driver Spark o a un worker. Il punto chiave è che i diversi clusters di Databricks sono completamente isolati l'uno dall'altro. Questo permette di garantire che SLA rigidi possano essere rispettati per progetti e casi d'uso specifici. È possibile isolare realmente i casi d'uso di streaming o in tempo reale da altri carichi di lavoro orientati ai batch e non è necessario preoccuparsi di isolare manualmente i Job a esecuzione prolungata che potrebbero monopolizzare le risorse del cluster per molto tempo. È possibile semplicemente avviare nuovi clusters come compute per diversi casi d'uso. Databricks disaccoppia inoltre l'archiviazione dal compute e consente di sfruttare l'archiviazione cloud esistente come AWS S3, Azure Blob Storage e Azure Data Lake Store (ADLS).
Databricks dispone anche di un metastore Hive gestito default, che memorizza informazioni strutturate sugli asset di dati che si trovano nello spazio di archiviazione cloud. Supporta anche l'utilizzo di un metastore esterno, come AWS Glue, Azure SQL Server o Azure Purview. È inoltre possibile specificare controlli di sicurezza come gli ACL delle tabelle in Databricks, così come le autorizzazioni di archiviazione degli oggetti.
Per quanto riguarda l'accesso ai dati, Databricks offre funzionalità simili a Hadoop in termini di interazione tra gli utenti e i dati. I dati archiviati nello storage cloud sono accessibili attraverso più percorsi nell'ambiente Databricks. Gli utenti possono usare gli SQL Endpoint e Databricks SQL per query interattive e le analitiche. Possono anche usare i Notebook di Databricks per le funzionalità di Data ingegneria e Machine Learning sui dati archiviati nello storage cloud. HBase in Hadoop corrisponde ad Azure CosmosDB o AWS DynamoDB/Keyspaces, che possono essere utilizzati come livello di serving per le applicazioni downstream.
Passaggio 2: migrazione dei dati
Dato il mio background in Hadoop, presumo che la maggior parte del pubblico abbia già familiarità con HDFS. HDFS è il file system di archiviazione utilizzato con le implementazioni di Hadoop che sfrutta i dischi sui nodi del cluster Hadoop. Quindi, quando si scala HDFS, è necessario aggiungere capacità al cluster nel suo complesso (ovvero è necessario scalare insieme compute e archiviazione). Se questo comporta l'approvvigionamento e l'installazione di hardware aggiuntivo, il tempo e l'impegno richiesti possono essere significativi.
In cloud, si dispone di una capacità di archiviazione quasi illimitata sotto forma di cloud storage come AWS S3, Azure Data Lake o Blob Storage o Google Storage. Non sono necessari controlli di manutenzione o di integrità e offre ridondanza integrata e livelli elevati di durabilità e disponibilità fin dal momento dell'implementazione. Consigliamo di utilizzare servizi cloud nativi per migrare i dati e, per facilitare la migrazione, sono disponibili diversi partner/ISV.
Quindi, come start? Il percorso più comunemente consigliato è iniziare con una strategia di doppia ingestione (cioè aggiungere un feed che upload i dati nell'archivio cloud oltre al proprio ambiente on-premise). Ciò consente di iniziare a usare nuovi casi d'uso (che sfruttano nuovi dati) in cloud senza alcun impatto sulla configurazione esistente. Se si cerca il consenso di altri gruppi all'interno dell'organizzazione, per cominciare si può presentare questa come una strategia di backup. Tradizionalmente, il backup di HDFS è sempre stato un'operazione complessa a causa delle grandi dimensioni e dello sforzo richiesto, pertanto eseguire il backup dei dati nel cloud può comunque essere un'iniziativa produttiva.
Nella maggior parte dei casi, è possibile sfruttare gli strumenti di data delivery esistenti per effettuare il fork del feed e scrivere non solo su Hadoop, ma anche in uno spazio di archiviazione cloud. Ad esempio, se si utilizzano strumenti/framework come Informatica e Talend per elaborare e scrivere dati su Hadoop, è molto facile aggiungere il passaggio aggiuntivo e farli scrivere nello spazio di archiviazione cloud. Una volta che i dati si trovano in cloud, esistono molti modi per lavorarci.
In termini di direzione dei dati, questi possono essere estratti (pull) dall'ambiente on-premise e trasferiti nel cloud, oppure inviati (push) al cloud dall'ambiente on-premise. Alcuni degli strumenti che possono essere utilizzati per inviare (push) i dati nel cloud sono soluzioni native per il cloud (Azure Data Box, AWS Snow Family, ecc.), DistCP (uno strumento Hadoop), altri strumenti di terze parti e qualsiasi framework interno. L'opzione push è di solito più semplice per ottenere le approvazioni necessarie dai team di sicurezza.
Per trasferire i dati nel cloud, è possibile utilizzare pipeline di streaming Spark/Kafka o di ingestione batch attivate dal cloud. Per il batch, è possibile eseguire l'ingestione dei file direttamente o utilizzare connettori JDBC per connettersi alle piattaforme tecnologiche upstream pertinenti e trasferire i dati. Naturalmente, sono disponibili anche strumenti di terze parti per questo scopo. L'opzione push è la più accettata e compresa tra le due, quindi analizziamo più a fondo l'approccio pull.
Per prima cosa, dovrai configurare la connettività tra il tuo ambiente on-premise e il cloud. Ciò può essere ottenuto con una connessione a Internet e un gateway. Puoi anche sfruttare opzioni di connettività dedicate come AWS Direct Connect, Azure ExpressRoute, ecc. In alcuni casi, se l'organizzazione ha già esperienza con il cloud, questa configurazione potrebbe essere già stata impostata e quindi può essere riutilizzata per il progetto di migrazione di Hadoop.
Un'altra considerazione è la sicurezza all'interno dell'ambiente Hadoop. Se si tratta di un ambiente Kerberized, può essere gestito dal lato Databricks. È possibile configurare script di inizializzazione di Databricks che vengono eseguiti all'startup del cluster, installare e configurare il client Kerberos necessario, accedere ai file krb5.conf e keytab, che sono archiviati in una posizione di archiviazione cloud, e infine eseguire la funzione kinit(), che consentirà al cluster Databricks di interagire direttamente con l'ambiente Hadoop.
Infine, sarà necessario anche un metastore esterno condiviso. Anche se Databricks dispone di un servizio metastore implementato per default, supporta anche l'utilizzo di uno esterno. Il metastore esterno sarà condiviso da Hadoop e Databricks e può essere distribuito sia on-premise (nel tuo ambiente Hadoop) sia nel cloud. Ad esempio, se disponi di processi ETL esistenti in esecuzione in Hadoop e non puoi ancora migrarli a Databricks, puoi sfruttare questa configurazione con il metastore on-premise esistente per consentire a Databricks di utilizzare il set di dati finale curato da Hadoop.
Passaggio 3: Elaborazione dati
La cosa principale da tenere a mente è che, dal punto di vista dell'elaborazione dei dati, tutto in Databricks sfrutta Apache Spark. Tutti i linguaggi di programmazione Hadoop, come MapReduce, Pig, Hive QL e Java, possono essere convertiti per l'esecuzione su Spark, tramite Pyspark, Scala, Spark SQL o anche R. Per quanto riguarda il codice e l'IDE, sia i notebook di Apache Zeppelin che quelli di Jupyter possono essere convertiti in notebook di Databricks, ma è un po' più facile importare i notebook di Jupyter. I notebook di Zeppelin dovranno essere convertiti in Jupyter o Ipython prima di poter essere importati. Se il team di data science desidera continuare a programmare in Zeppelin o Jupyter, può utilizzare Databricks Connect, che consente di sfruttare l'IDE locale (Jupyter, Zeppelin o anche IntelliJ, VScode, RStudio, ecc.) per eseguire il codice su Databricks.
Quando si tratta di migrare i job di Apache Spark™, l'aspetto principale da considerare sono le versioni di Spark. Il tuo cluster Hadoop on-premise potrebbe eseguire una versione precedente di Spark ed è possibile utilizzare la guida alla migrazione di Spark per identificare le modifiche apportate e verificare eventuali impatti sul codice. Un altro aspetto da considerare è la conversione degli RDD in dataframe. Gli RDD erano comunemente utilizzati con le versioni di Spark fino alla 2.x e, sebbene possano ancora essere utilizzati con Spark 3.x, ciò può impedire di sfruttare appieno le funzionalità dell'ottimizzatore di Spark. Consigliamo di modificare gli RDD in dataframe ove possibile.
Infine, ma non meno importante, uno degli intoppi più comuni che abbiamo riscontrato con i clienti durante la migrazione sono i riferimenti hardcoded all'ambiente Hadoop locale. Questi dovranno, ovviamente, essere aggiornati, altrimenti il codice non funzionerà nella nuova configurazione.
Parliamo ora della conversione dei carichi di lavoro non Spark, che per la maggior parte dei casi comporta la riscrittura del codice. Per MapReduce, in alcuni casi, se si utilizza una logica condivisa sotto forma di libreria Java, il codice può essere sfruttato da Spark. Tuttavia, potrebbe essere ancora necessario riscrivere alcune parti del codice per eseguirlo in un ambiente Spark anziché MapReduce. Sqoop è relativamente facile da migrare poiché nei nuovi ambienti si esegue una serie di comandi Spark (anziché comandi MapReduce) utilizzando un'origine JDBC. È possibile specificare i parametri nel codice Spark nello stesso modo in cui vengono specificati in Sqoop. Per Flume, la maggior parte dei casi d'uso che abbiamo visto riguarda il consumo di dati da Kafka e la scrittura su HDFS. Questa è un'attività che può essere facilmente eseguita utilizzando lo streaming Spark. Il compito principale nella migrazione di Flume è convertire l'approccio basato su file di configurazione in un approccio più programmatico in Spark. Infine, abbiamo Nifi, che viene utilizzato principalmente al di fuori di Hadoop, soprattutto come strumento di acquisizione dati self-service di tipo drag-and-drop. Nifi può essere sfruttato anche in cloud, ma vediamo che molti clienti colgono l'opportunità di migrare al cloud per sostituire Nifi con altri strumenti più recenti disponibili in cloud.
La migrazione di HiveQL è forse l'attività più semplice di tutte. Esiste un elevato grado di compatibilità tra Hive e Spark SQL e la maggior parte delle query dovrebbe poter essere eseguita su Spark SQL così com'è. Ci sono alcune piccole differenze nel DDL tra HiveQL e Spark SQL, ad esempio il fatto che Spark SQL utilizza la clausola “USING” rispetto alla clausola “FORMAT” di HiveQL. Consigliamo vivamente di modificare il codice per utilizzare il formato Spark SQL, poiché consente all'ottimizzatore di preparare il miglior piano di esecuzione possibile per il tuo codice in Databricks. È ancora possibile sfruttare i SerDe e gli UDF di Hive, il che semplifica ulteriormente la migrazione di HiveQL a Databricks.
Per quanto riguarda l'orchestrazione del flusso di lavoro, è necessario considerare le potenziali modifiche al modo in cui verranno inviati i Job. Puoi continuare a sfruttare la semantica di Spark submit, ma sono disponibili anche altre opzioni più veloci e integrate più fluidamente. È possibile sfruttare i Job di Databricks e le Delta Live Tables per l'ETL senza codice per sostituire i Job Oozie e definire pipeline di dati end-to-end all'interno di Databricks. Per i flussi di lavoro che implicano dipendenze di elaborazione esterne, dovrai creare flussi di lavoro/pipeline equivalenti in tecnologie come Apache Airflow, Azure Data Factory, ecc. per l'automazione/pianificazione. Con le API REST di Databricks, quasi tutte le piattaforme di pianificazione possono essere integrate e configurate per funzionare con Databricks.
È disponibile anche uno strumento automatizzato chiamato MLens (creato da KnowledgeLens), che può aiutare a migrare i carichi di lavoro da Hadoop a Databricks. MLens può aiutare a migrare il codice PySpark e HiveQL, inclusa la traduzione di alcune specifiche di Hive in Spark SQL, in modo da poter sfruttare la piena funzionalità e i vantaggi in termini di prestazioni dell'ottimizzatore di Spark SQL. Stanno anche pianificando di supportare a breve la migrazione dei flussi di lavoro Oozie ad Airflow, Azure Data Factory e così via.
Passaggio 4: sicurezza e governance
Diamo un'occhiata alla sicurezza e alla governance. Nel mondo Hadoop, abbiamo l'integrazione LDAP per la connettività a console di amministrazione come Ambari o Cloudera Manager, o anche Impala o Solr. Hadoop dispone anche di Kerberos, che viene utilizzato per l'autenticazione con altri servizi. Dal punto di vista dell'autorizzazione, Ranger e Sentry sono gli strumenti più comunemente utilizzati.
Con Databricks, l'integrazione Single Sign-On (SSO) è disponibile con qualsiasi provider di identità che supporti SAML 2.0. Tra questi figurano Azure Active Directory, Google Workspace SSO, AWS SSO e Microsoft Active Directory. Per l'autorizzazione, Databricks fornisce ACL (elenchi di controllo degli accessi) per gli oggetti di Databricks, che consentono di impostare le autorizzazioni su entità come Notebook, Job e cluster. Per le autorizzazioni dei dati e il controllo degli accessi, puoi definire ACL di tabella e viste per limitare l'accesso a colonne e righe, oltre a sfruttare una funzionalità come il credential passthrough, con cui Databricks trasferisce le credenziali di accesso al workspace al livello di archiviazione (S3, ADLS, Blob Storage) per determinare se sei autorizzato ad accedere ai dati. Se sono necessarie funzionalità come i controlli basati su attributi o il mascheramento dei dati, è possibile sfruttare strumenti di partner come Immuta e Privacera. Dal punto di vista della governance aziendale, è possibile connettere Databricks a un Data Catalog aziendale come AWS Glue, Informatica Data Catalog, Alation e Collibra.
Passaggio 5: Livello SQL & BI
In Hadoop, come discusso in precedenza, si dispone di Hive e Impala come interfacce per eseguire l'ETL, nonché query e analitiche ad-hoc. In Databricks, si dispone di funzionalità simili tramite Databricks SQL. Databricks SQL offre anche prestazioni estreme tramite il Delta engine, oltre al supporto per casi d'uso high concurrency con cluster a scalabilità automatica. Il motore Delta include anche Photon, un nuovo motore MPP creato da zero in C++ e vettorizzato per sfruttare il parallelismo sia a livello di dati che a livello di istruzioni.
Databricks fornisce un'integrazione nativa con strumenti di BI come Tableau, PowerBI, Qlik e Looker, oltre a connettori JDBC/ODBC altamente ottimizzati che possono essere sfruttati da tali strumenti. I nuovi driver JDBC/ODBC hanno un overhead molto ridotto (¼ di secondo) e una velocità di trasferimento superiore del 50% utilizzando Apache Arrow, nonché diverse operazioni sui metadati che supportano operazioni di recupero dei metadati notevolmente più veloci. Databricks supporta anche SSO per PowerBI e il supporto per SSO con altri strumenti di BI e dashboarding sarà presto disponibile.
Oltre all'esperienza notebook menzionata sopra, Databricks dispone di un'UX SQL integrata che offre agli utenti SQL la propria prospettiva con un workbench SQL, oltre a funzionalità di dashboarding semplificate e di avviso. Ciò consente trasformazioni dei dati basate su SQL e analitiche esplorative sui dati all'interno del data lake, senza la necessità di spostarli a valle in un data warehouse o in altre piattaforme.
Passaggi successivi
Nel considerare il percorso di migrazione verso un'architettura cloud moderna come l'architettura lakehouse, ecco due cose da ricordare:
- Ricorda di coinvolgere i principali stakeholder aziendali nel percorso. Si tratta di una decisione tanto tecnologica quanto aziendale, ed è necessario che gli stakeholder aziendali siano coinvolti nel percorso e nel suo stato finale.
- Inoltre, ricorda che non sei solo e che ci sono risorse qualificate in Databricks e tra i nostri partner che l'hanno fatto abbastanza volte da creare best practice ripetibili, facendo risparmiare alle organizzazioni tempo, denaro e risorse e riducendo lo stress generale.
- Scarica la guida alla migrazione tecnica da Hadoop a Databricks per ottenere istruzioni dettagliate, Notebook e codice per iniziare la migrazione.
Per saperne di più su come Databricks aumenta il valore aziendale e iniziare a pianificare la migrazione da Hadoop, visita www.databricks.com/solutions/migration.

Guida alla migrazione: da Hadoop a Databricks
Sfrutta tutto il potenziale dei tuoi dati con questo playbook autoguidato.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.