API di Pandas nel prossimo Apache Spark™ 3.2
di Hyukjin Kwon e Xinrong Meng
La Free Edition ha sostituito la Community Edition, offrendo funzionalità avanzate senza alcun costo. Inizia a usare la Free Edition oggi stesso.
Siamo entusiasti di annunciare che l'API di pandas farà parte della prossima release di Apache Spark™ 3.2. pandas è una libreria potente e flessibile ed è cresciuta rapidamente fino a diventare una delle librerie standard per la data science. Ora gli utenti di pandas potranno sfruttare l'API di pandas sui loro cluster Spark esistenti.
Alcuni anni fa, abbiamo lanciato Koalas, un progetto open-source che implementa l'API DataFrame di pandas su Spark e che ha ottenuto un'ampia adozione tra i data scientists. Recentemente, Koalas è stato ufficialmente unito a PySpark da SPIP: Support pandas API layer on PySpark come parte del Progetto Zen (vedi anche Project Zen: Making Data Science Easier in PySpark dal Data + AI Summit 2021).
Gli utenti di pandas potranno scalare i loro carichi di lavoro con una semplice modifica di una riga nella prossima release di Spark 3.2:
Questo post su un blog riassume il supporto dell'API di pandas su Spark 3.2 ed evidenzia le funzionalità, le modifiche e la roadmap più importanti.
Scalabilità oltre una singola macchina
Una delle limitazioni note di pandas è che non scala linearmente con il volume dei dati a causa dell'elaborazione su una singola macchina. Ad esempio, pandas si arresta per memoria esaurita se tenta di leggere un set di dati più grande della memoria disponibile in una singola macchina:
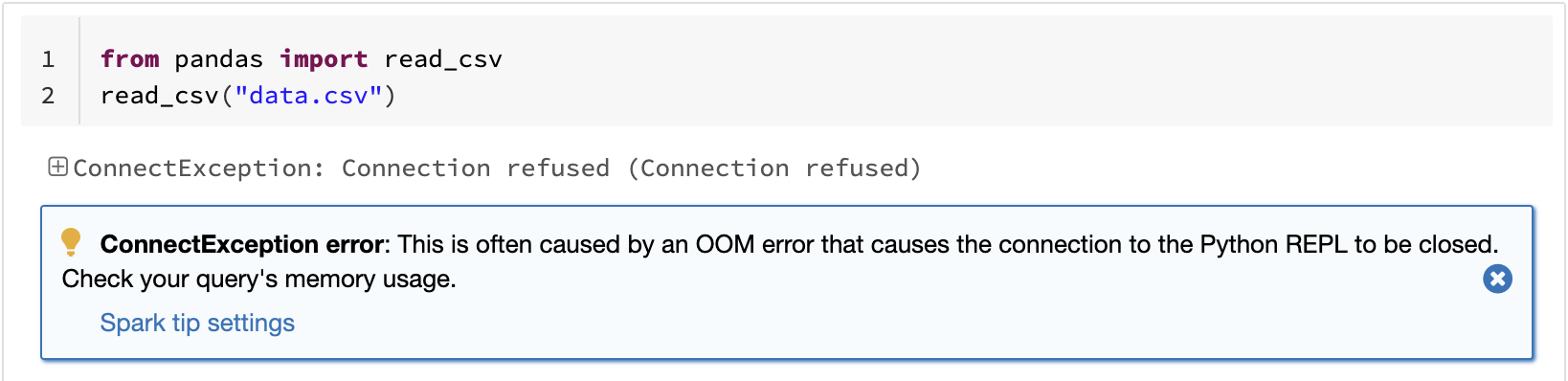
L'API pandas su Spark supera questa limitazione, consentendo agli utenti di lavorare con set di dati di grandi dimensioni sfruttando Spark:

L'API pandas su Spark si adatta bene anche a cluster di nodi di grandi dimensioni. Il grafico seguente mostra le sue prestazioni durante l'analisi di un set di dati Parquet da 15 TB con clusters di dimensioni diverse. Ogni macchina del cluster ha 8 vCPU e 61 GiB di memoria.
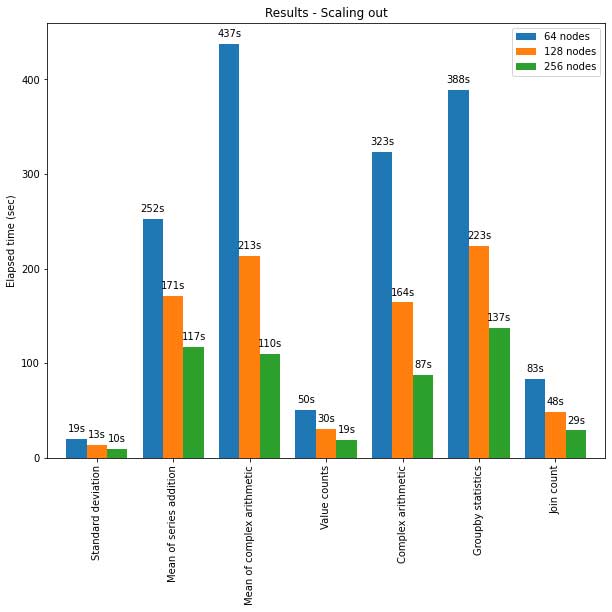
L'esecuzione distribuita dell'API di pandas su Spark scala in modo quasi lineare in questo test. Il tempo trascorso si dimezza quando il numero di macchine all'interno di un cluster raddoppia. Anche l'aumento di velocità rispetto a una singola macchina è significativo. Ad esempio, nel benchmark della deviazione standard, un cluster di 256 macchine può elaborare circa 250 volte più dati di una singola macchina all'incirca nello stesso tempo (ogni macchina ha 8 vCPU e 61 GiB di memoria):
| Macchina singola | Cluster di 256 macchine | |
| Set di dati Parquet | 60 GB | 60 GB x 250 (15 TB) |
| Tempo trascorso (sec) della deviazione standard | 12 s | 10 s |
Prestazioni ottimizzate per singola macchina
L'API di pandas su Spark spesso supera le prestazioni di pandas anche su una singola macchina grazie alle ottimizzazioni del motore di Spark. Il grafico seguente mostra l'API pandas su Spark a confronto con pandas su una macchina (con 96 vCPU e 384 GiB di memoria) su un set di dati CSV da 130 GB:
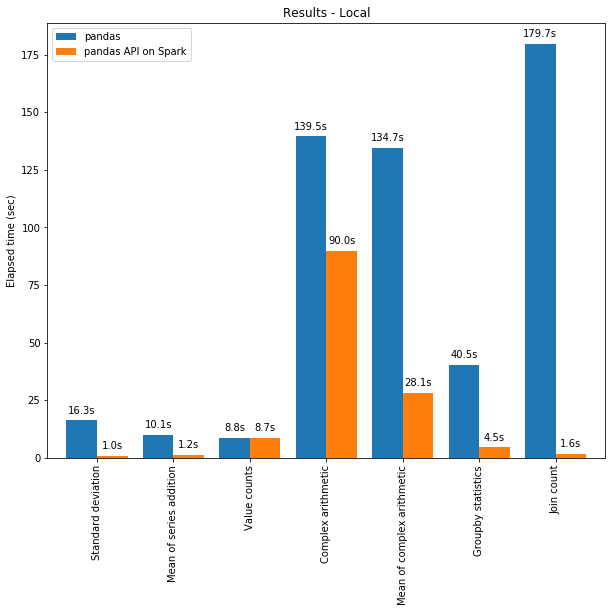
Sia il multi-threading che l'ottimizzatore Catalyst di Spark SQL contribuiscono a ottimizzare le prestazioni. Ad esempio, l'attività operativa Join count è circa 4 volte più veloce con la generazione di codice "whole-stage": 5,9 s senza generazione di codice, 1,6 s con generazione di codice.
Spark offre un vantaggio particolarmente significativo nel concatenamento delle operazioni. L'ottimizzatore di query Catalyst può riconoscere i filtri per saltare i dati in modo intelligente e può applicare join basati su disco, mentre pandas tende a caricare tutti i dati in memoria a ogni passaggio.
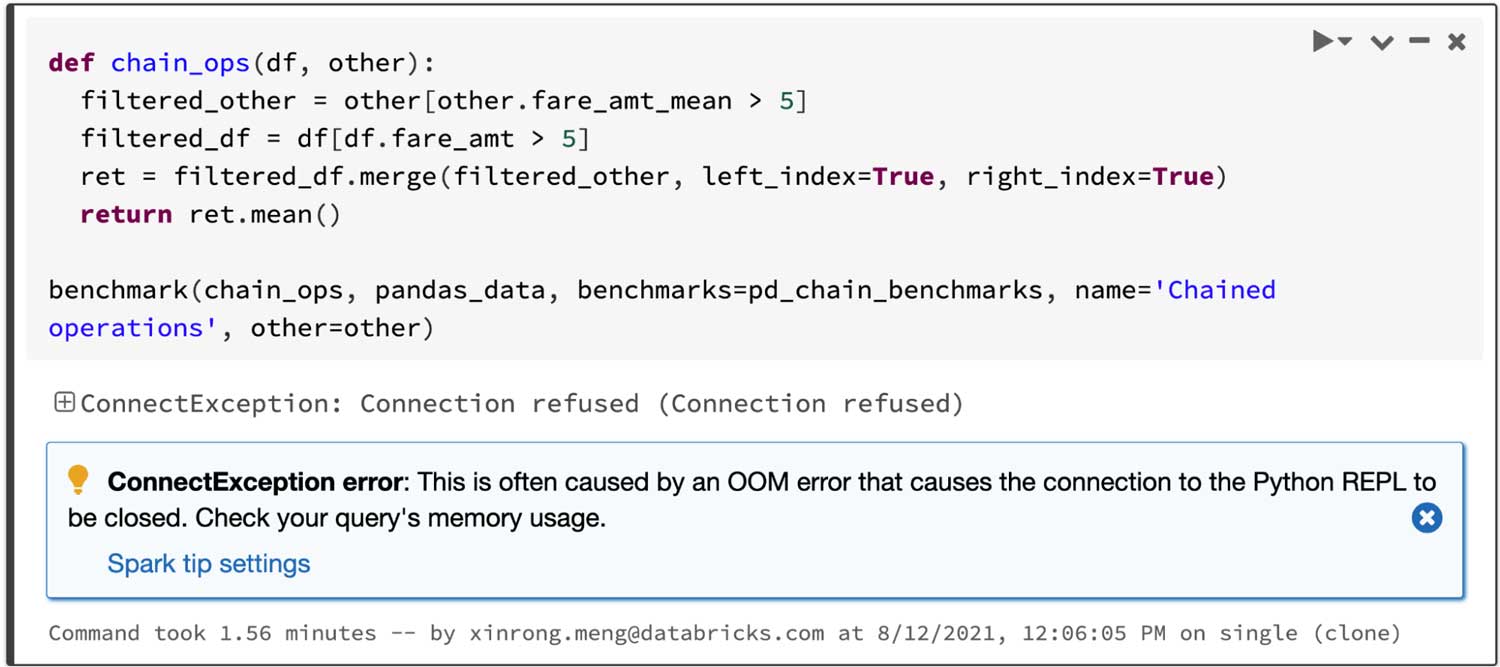
Considerando una query che unisce due frame filtrati e quindi calcola la media del frame unito, l'API di pandas su Spark riesce nell'operazione in 4,5 s, mentre pandas fallisce a causa dell'errore OOM (Out of Memory) come mostrato di seguito:
Visualizzazione interattiva dei dati
pandas utilizza matplotlib per impostazione predefinita, che fornisce grafici statici. Ad esempio, il codice seguente genera un grafico statico:
Al contrario, l'API di pandas su Spark utilizza per impostazione predefinita un backend plotly, che fornisce grafici interattivi. Ad esempio, consente agli utenti di ingrandire e ridurre la visualizzazione in modo interattivo. In base al tipo di grafico, l'API di pandas su Spark determina automaticamente il modo migliore per eseguire il calcolo internamente quando si generano grafici interattivi:
Sfruttare le funzionalità di unified analytics in Spark
pandas è progettato per la Data Science in Python con elaborazione batch, mentre Spark è progettato per la unified analytics, che include SQL, elaborazione streaming e machine learning. Per colmare questo divario, l'API pandas su Spark offre agli utenti esperti molti modi diversi per sfruttare il motore Spark, ad esempio:
- Gli utenti possono interrogare direttamente i dati tramite SQL con il motore SQL ottimizzato di Spark, come mostrato di seguito:
- Supporta anche la sintassi di interpolazione delle stringhe per interagire con gli oggetti Python in modo naturale:
- L'API pandas su Spark supporta anche l'elaborazione in streaming:
- Gli utenti possono richiamare facilmente le librerie di machine learning (MLlib) scalabili in Spark:
Vedi anche il post su un blog sull'interoperabilità tra PySpark e l'API pandas su Spark.
E adesso?
Per le prossime release di Spark, la roadmap si concentra su:
• Più suggerimenti sui tipi
Il codice nell'API pandas su Spark è attualmente parzialmente tipizzato, il che consente comunque l'analisi statica e il completamento automatico. In futuro, tutto il codice sarà completamente tipizzato.
• Miglioramenti delle prestazioni
In diversi punti dell'API di pandas su Spark possiamo migliorare ulteriormente le prestazioni interagendo più strettamente con il motore e con l'ottimizzatore SQL.
• Stabilizzazione
Ci sono diversi punti da correggere, specialmente per quanto riguarda i valori mancanti come NaN e NA che presentano casi limite con differenze di comportamento.
Inoltre, in questi casi l'API pandas su Spark seguirà e adeguerà il suo comportamento alla versione più recente di pandas.
• Maggiore copertura delle API
L'API pandas su Spark ha raggiunto una copertura dell'83% dell'API pandas e questo numero continua ad aumentare. Ora l'obiettivo è raggiungere il 90%.
Ti preghiamo di segnalare un problema in caso di bug o funzionalità mancanti di cui hai bisogno e, naturalmente, i contributi della community sono sempre i benvenuti.
Guida introduttiva
Se vuoi provare l'API di pandas su Spark in Databricks Runtime 10.0 Beta (il futuro Apache Spark 3.2), registrati gratuitamente a Databricks Community Edition o Databricks Trial e inizia a usarlo in pochi minuti.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.