Tecniche di modellazione del data warehousing e loro implementazione sulla piattaforma Databricks Lakehouse
Utilizzo di Data Vault e Star Schema sul Lakehouse
di Soham Bhatt e Deepak Sekar
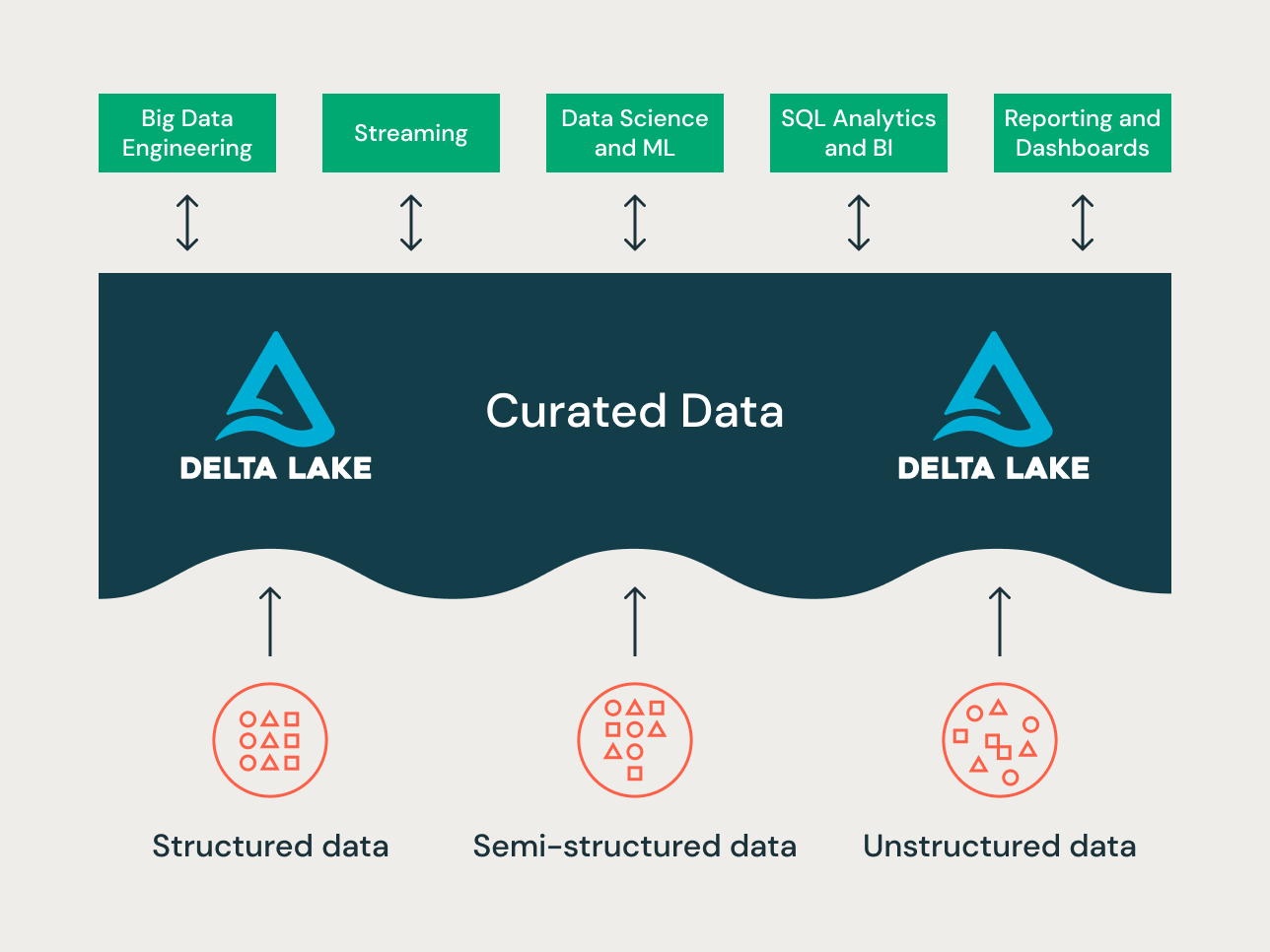
Il lakehouse è un nuovo paradigma di piattaforma dati che combina le migliori caratteristiche di data lake e data warehouse. È progettato come una piattaforma dati aziendale su larga scala in grado di ospitare molti casi d'uso e prodotti dati. Può fungere da unico repository dati aziendale unificato per tutti i tuoi:
- domini dati,
- casi d'uso di streaming in tempo reale,
- data mart,
- data warehouse disparati,
- feature store e sandbox per data science, e
- sandbox di analisi self-service dipartimentali.
Data la varietà dei casi d'uso, diversi principi di organizzazione dei dati e tecniche di modellazione possono essere applicati a diversi progetti su un lakehouse. Tecnicamente, la Databricks Lakehouse Platform può supportare molti stili di modellazione dati diversi. In questo articolo, miriamo a spiegare l'implementazione dei principi di organizzazione dei dati Bronze/Silver/Gold del lakehouse e come le diverse tecniche di modellazione dati si inseriscono in ciascun livello.
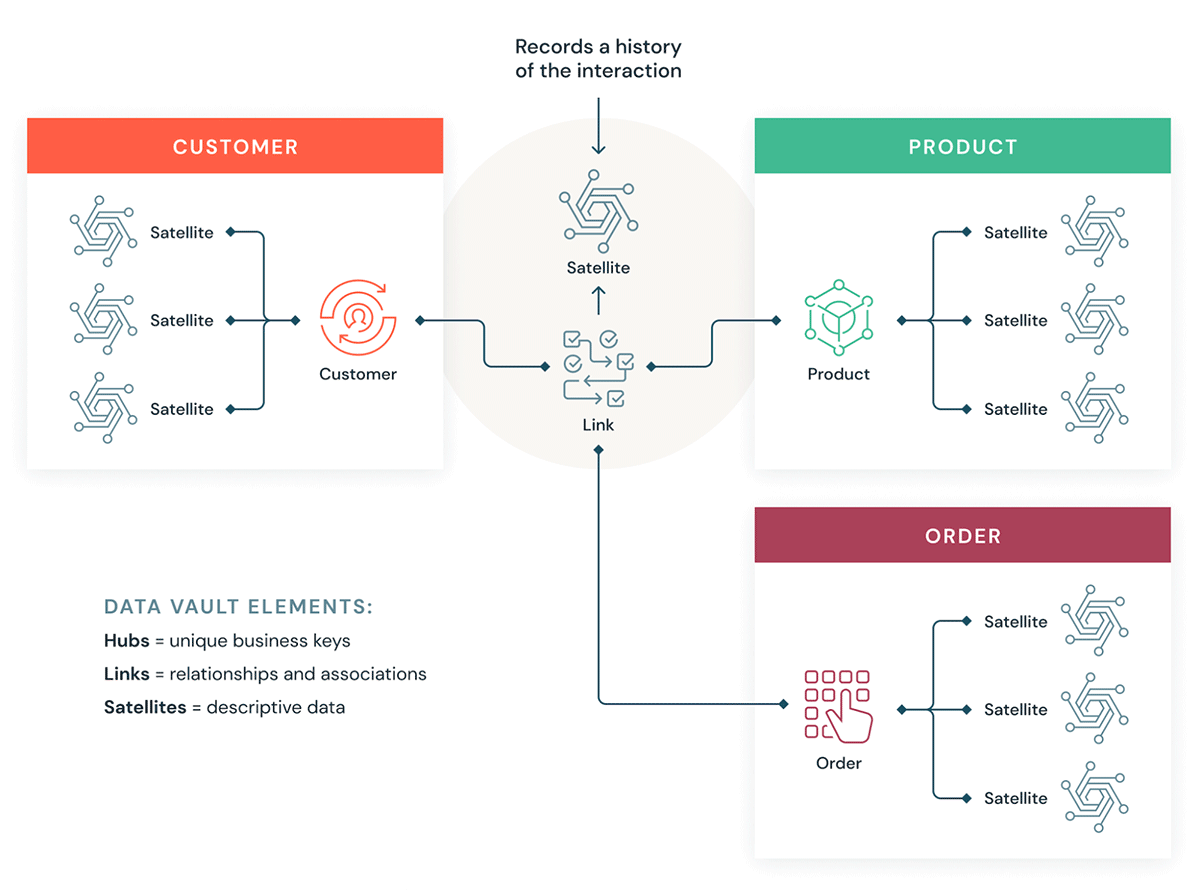
Cos'è un Data Vault?
Un Data Vault è uno schema di progettazione dati più recente utilizzato per costruire data warehouse per analisi su scala aziendale rispetto ai metodi Kimball e Inmon.
I Data Vault organizzano i dati in tre tipi diversi: hub, link e satelliti. Gli hub rappresentano entità aziendali principali, i link rappresentano relazioni tra hub e i satelliti memorizzano attributi relativi a hub o link.
Il Data Vault si concentra sullo sviluppo agile di data warehouse in cui scalabilità, integrazione dati/ETL e velocità di sviluppo sono importanti. La maggior parte dei clienti dispone di una landing zone, una vault zone e una data mart zone che corrispondono ai paradigmi organizzativi Databricks di livelli Bronze, Silver e Gold. Lo stile di modellazione Data Vault di tabelle hub, link e satellite si adatta tipicamente bene al livello Silver del Databricks Lakehouse.
Ulteriori informazioni sulla modellazione Data Vault sono disponibili presso la Data Vault Alliance.
Cos'è la Modellazione Dimensionale?
La modellazione dimensionale è un approccio bottom-up alla progettazione di data warehouse per ottimizzarli per l'analisi. I modelli dimensionali vengono utilizzati per denormalizzare i dati aziendali in dimensioni (come tempo e prodotto) e fatti (come transazioni in importi e quantità), e diverse aree tematiche sono collegate tramite dimensioni conformi per navigare verso diverse tabelle dei fatti.
La forma più comune di modellazione dimensionale è lo star schema. Uno star schema è un modello dati multidimensionale utilizzato per organizzare i dati in modo che siano facili da comprendere e analizzare, e molto facili e intuitivi per eseguire report. Gli star schema in stile Kimball o i modelli dimensionali sono praticamente lo standard di riferimento per il livello di presentazione nei data warehouse e nei data mart, e persino per i livelli semantici e di reporting. Il design dello star schema è ottimizzato per l'interrogazione di grandi set di dati.
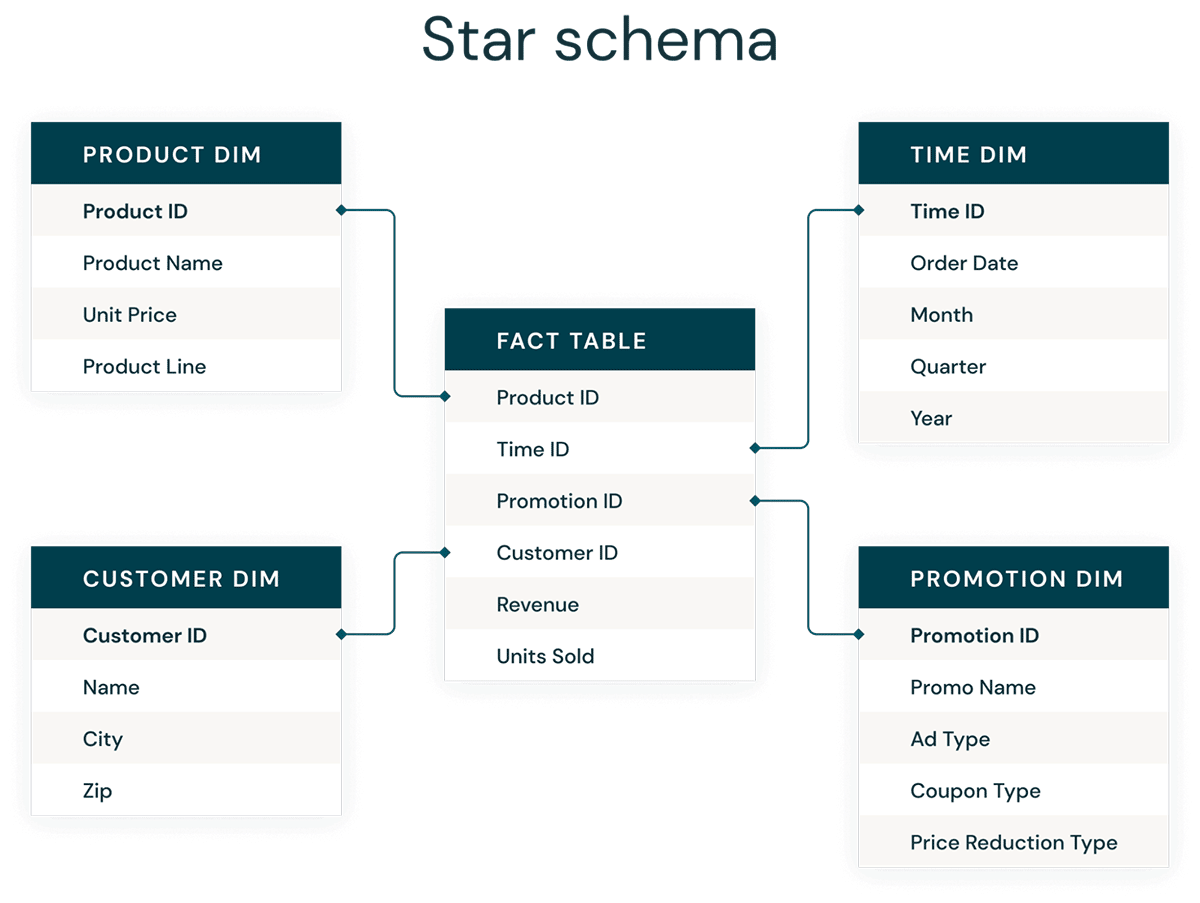
Sia i modelli dati Data Vault normalizzati (ottimizzati per la scrittura) che i modelli dati dimensionali denormalizzati (ottimizzati per la lettura) hanno un posto nel Databricks Lakehouse. Gli hub e i satelliti del Data Vault nel livello Silver vengono utilizzati per caricare le dimensioni nello star schema, e le tabelle link del Data Vault diventano le tabelle chiave per caricare le tabelle dei fatti nel modello dimensionale. Ulteriori informazioni sulla modellazione dimensionale sono disponibili presso il Kimball Group.
Principi di organizzazione dei dati in ogni livello del Lakehouse
Un moderno lakehouse è una piattaforma dati aziendale onnicomprensiva. È altamente scalabile e performante per tutti i tipi di casi d'uso diversi come ETL, BI, data science e streaming che possono richiedere approcci di modellazione dati differenti. Vediamo come è organizzato un tipico lakehouse:
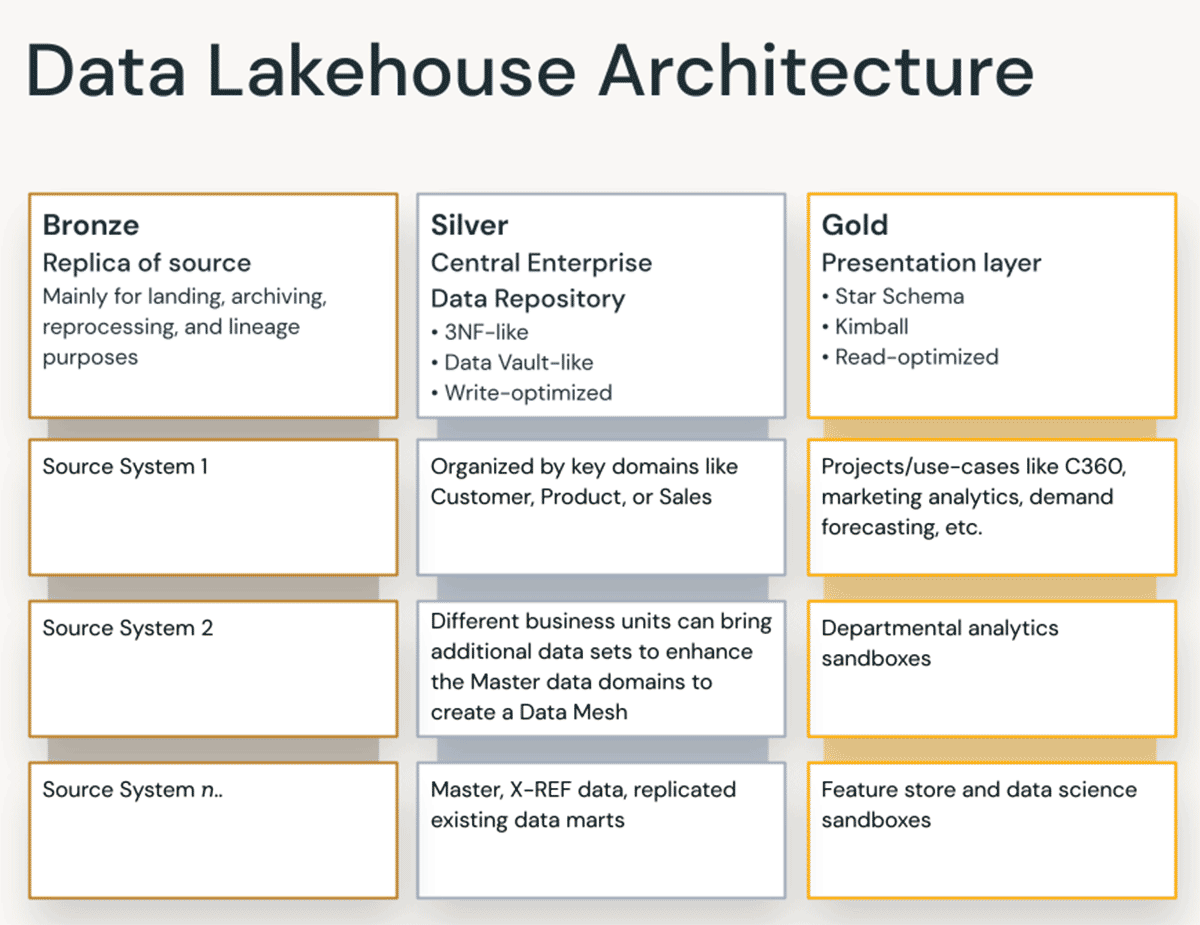
Livello Bronze — la Landing Zone
Il livello Bronze è dove atterriamo tutti i dati dai sistemi sorgente. Le strutture delle tabelle in questo livello corrispondono alle strutture delle tabelle del sistema sorgente "così come sono", a parte colonne di metadati opzionali che possono essere aggiunte per catturare la data/ora di caricamento, l'ID del processo, ecc. L'attenzione in questo livello è sulla cattura dei dati modificati (CDC) e sulla capacità di fornire un archivio storico dei dati sorgente (cold storage), la lineage dei dati, l'auditabilità e la rielaborazione se necessario, senza rileggere i dati dal sistema sorgente.
Nella maggior parte dei casi, è una buona idea mantenere i dati nel livello Bronze in formato Delta, in modo che le letture successive dal livello Bronze per l'ETL siano performanti e in modo che sia possibile eseguire aggiornamenti in Bronze per scrivere le modifiche CDC. A volte, quando i dati arrivano in formati JSON o XML, vediamo clienti che li caricano nel formato dati sorgente originale e poi li preparano convertendoli in formato Delta. Quindi, a volte, vediamo clienti che manifestano il livello Bronze logico in una zona di atterraggio e staging fisica.
Memorizzare dati grezzi nel formato dati sorgente originale in una landing zone aiuta anche la coerenza, quando si ingeriscono dati tramite strumenti di ingestione che non supportano Delta come sink nativo o dove i sistemi sorgente scaricano dati direttamente sugli object store. Questo pattern si allinea bene anche con il framework di ingestione autoloader, in cui le sorgenti caricano i dati nella landing zone per i file grezzi e poi Databricks AutoLoader converte i dati nel livello di staging in formato Delta.
Livello Silver — il Repository Centrale Aziendale
Nel livello Silver del Lakehouse, i dati dal livello Bronze vengono abbinati, uniti, conformati e puliti ("quanto basta") in modo che il livello Silver possa fornire una "visione aziendale" di tutte le sue entità aziendali chiave, concetti e transazioni. Questo è simile a un Enterprise Operational Data Store (ODS) o a un Repository Centrale o domini dati di un Data Mesh (ad es. clienti master, prodotti, transazioni non duplicate e tabelle di cross-reference). Questa visione aziendale riunisce i dati da diverse fonti e abilita l'analisi self-service per report ad-hoc, analisi avanzate e ML. Serve anche come fonte per analisti dipartimentali, data engineer e data scientist per creare ulteriormente progetti dati e analisi per rispondere a problemi aziendali tramite progetti dati aziendali e dipartimentali nel livello Gold.
Nel paradigma di Data Engineering del Lakehouse, tipicamente si segue la metodologia ELT (Extract-Load-Transform) rispetto al tradizionale Extract-Transform-Load (ETL). L'approccio ELT significa che solo trasformazioni minime o "quanto basta" e regole di pulizia dei dati vengono applicate durante il caricamento del livello Silver. Tutte le regole "a livello aziendale" vengono applicate nel livello Silver rispetto alle regole di trasformazione specifiche del progetto, che vengono applicate nel livello Gold. Qui viene data priorità a velocità e agilità nell'ingestione e nella consegna dei dati nel Lakehouse.
Dal punto di vista della modellazione dati, il Livello Silver ha modelli dati più simili alla 3ª Forma Normale. Architetture dati e modelli dati Data Vault-like performanti in scrittura possono essere utilizzati in questo livello. Se si utilizza una metodologia Data Vault, sia il Data Vault grezzo che il Business Vault si adatteranno al livello Silver logico del lake, e le viste di presentazione Point-In-Time (PIT) o le viste materializzate saranno presentate nel Livello Gold.
Livello Gold — il Livello di Presentazione
Nel livello Gold, possono essere costruiti più data mart o data warehouse secondo la metodologia di modellazione dimensionale/Kimball. Come discusso in precedenza, il livello Gold è per il reporting e utilizza modelli dati più denormalizzati e ottimizzati per la lettura con meno join rispetto al livello Silver. A volte le tabelle nel Livello Gold possono essere completamente denormalizzate, tipicamente se i data scientist lo desiderano per alimentare i loro algoritmi per il feature engineering.
Le regole ETL e di qualità dei dati "specifiche del progetto" vengono applicate durante la trasformazione dei dati dal livello Silver al livello Gold. I livelli di presentazione finali come data warehouse, data mart o prodotti di dati come analisi dei clienti, analisi di prodotti/qualità, analisi dell'inventario, segmentazione dei clienti, raccomandazioni sui prodotti, analisi di marketing/vendite, ecc. vengono forniti in questo livello. Modelli di dati basati su star-schema in stile Kimball o Data mart in stile Inmon si adattano a questo livello Gold del Lakehouse. Anche i laboratori di data science e le sandbox dipartimentali per l'analisi self-service appartengono al livello Gold.
Il Paradigma di Organizzazione dei Dati del Lakehouse
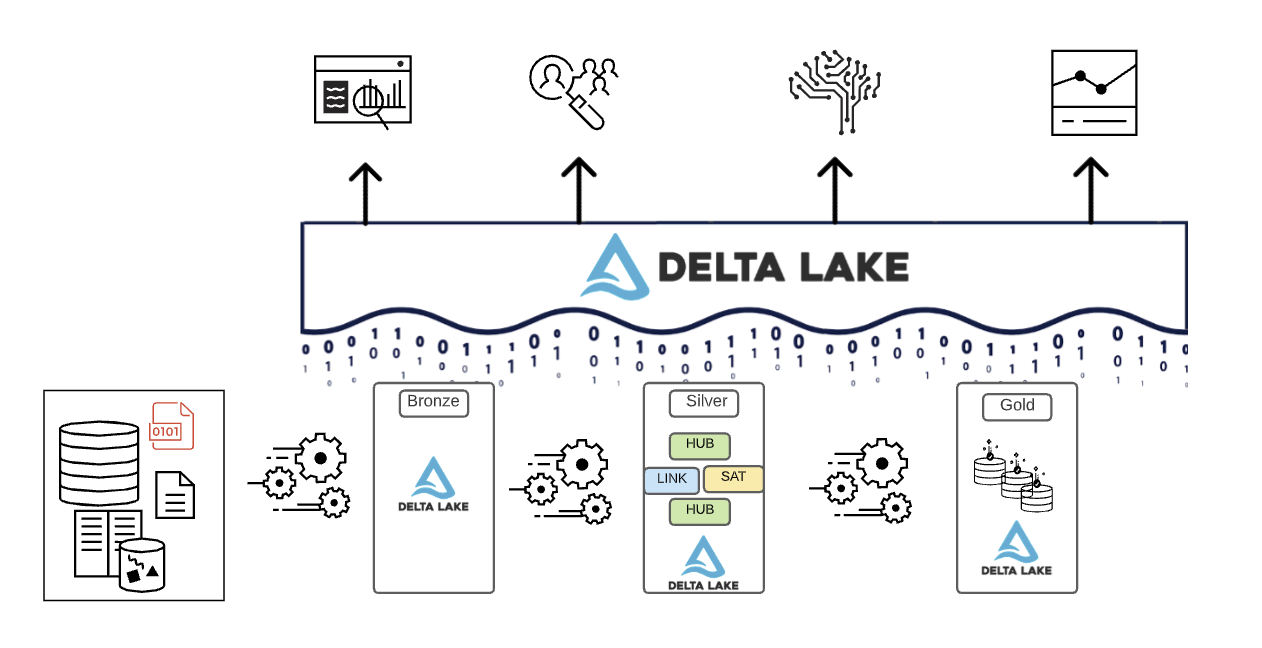
In sintesi, i dati vengono curati mentre si muovono attraverso i diversi livelli di un Lakehouse.
- Il livello Bronze utilizza i modelli di dati dei sistemi sorgente. Se i dati vengono caricati in formati raw, vengono convertiti nel formato Delta Lake all'interno di questo livello.
- Il livello Silver riunisce per la prima volta i dati da diverse fonti e li conforma per creare una vista aziendale dei dati — tipicamente utilizzando modelli di dati più normalizzati e ottimizzati per la scrittura, che sono tipicamente simili alla Terza Forma Normale o Data Vault.
- Il livello Gold è il livello di presentazione con modelli di dati più denormalizzati o appiattiti rispetto al livello Silver, tipicamente utilizzando modelli dimensionali in stile Kimball o star schema. Il livello Gold ospita anche sandbox dipartimentali e di data science per abilitare l'analisi self-service e la data science in tutta l'azienda. Fornire queste sandbox e i loro cluster di calcolo separati impedisce ai team aziendali di creare le proprie copie dei dati al di fuori del Lakehouse.
Questo approccio all'organizzazione dei dati del Lakehouse è pensato per rompere i silos di dati, unire i team e consentire loro di eseguire ETL, streaming, BI e AI su un'unica piattaforma con una governance adeguata. I team centrali di dati dovrebbero essere gli abilitatori dell'innovazione nell'organizzazione, accelerando l'onboarding di nuovi utenti self-service, nonché lo sviluppo di molti progetti di dati in parallelo — piuttosto che il processo di modellazione dei dati diventi il collo di bottiglia. Il Databricks Unity Catalog fornisce ricerca e scoperta, governance e lineage sul Lakehouse per garantire una buona cadenza di governance dei dati.
Crea oggi stesso i tuoi Data Vault e data warehouse star schema con Databricks SQL.
Ulteriori letture:
- Cinque semplici passaggi per implementare uno star schema in Databricks con Delta Lake
- Best practice per implementare un modello Data Vault sulla Databricks Lakehouse Platform
- Best practice di modellazione dimensionale e implementazione su Modern Lakehouse
- Le colonne Identity per generare chiavi surrogate sono ora disponibili in un Lakehouse vicino a te!
- Carica un modello dimensionale EDW in tempo reale con Databricks Lakehouse
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.