Presentazione di Databricks Lakeflow: una soluzione unificata e intelligente per l'ingegneria dei dati
Ingerisici dati da database, app aziendali e origini cloud, trasformarli in batch e streaming in tempo reale, e distribuiscili e gestiscili con sicurezza in produzione.
Oggi siamo entusiasti di annunciare Databricks Lakeflow, una nuova soluzione che contiene tutto il necessario per creare e gestire pipeline di dati di produzione. Include nuovi connettori nativi e altamente scalabili per database come SQL Server e per applicazioni aziendali come Salesforce, Workday, Google Analytics, ServiceNow e SharePoint. Gli utenti possono trasformare i dati in batch e in streaming utilizzando SQL e Python standard. Annunciamo anche la modalità Real Time per Apache Spark, che consente l'elaborazione in streaming con latenze ordini di grandezza inferiori rispetto al microbatch. Infine, è possibile orchestrare e monitorare i flussi di lavoro e distribuirli in produzione utilizzando CI/CD. Databricks Lakeflow è nativo della Piattaforma di Intelligenza dei Dati, fornendo calcolo serverless e governance unificata con Unity Catalog.

In questo post del blog discutiamo i motivi per cui crediamo che Lakeflow aiuterà i team di dati a soddisfare la crescente domanda di dati e AI affidabili, nonché le funzionalità chiave di Lakeflow integrate in un'unica esperienza di prodotto.
Sfide nella creazione e gestione di pipeline di dati affidabili
L'ingegneria dei dati - raccolta e preparazione di dati freschi, di alta qualità e affidabili - è un ingrediente necessario per democratizzare dati e AI nella tua azienda. Tuttavia, raggiungere questo obiettivo rimane complesso e richiede l'unione di molti strumenti diversi.
Innanzitutto, i team di dati devono ingerire dati da più sistemi, ognuno con i propri formati e metodi di accesso. Ciò richiede la creazione e la manutenzione di connettori interni per database e applicazioni aziendali. Il semplice mantenimento delle modifiche alle API delle applicazioni aziendali può essere un lavoro a tempo pieno per un intero team di dati. I dati devono quindi essere preparati sia in batch che in streaming, il che richiede la scrittura e la manutenzione di logiche complesse per l'attivazione e l'elaborazione incrementale. Quando la latenza aumenta o si verifica un errore, significa ricevere notifiche, un insieme di consumatori di dati insoddisfatti e persino interruzioni per l'azienda che influiscono sui profitti. Infine, i team di dati devono distribuire queste pipeline utilizzando CI/CD e monitorare la qualità e la provenienza degli asset di dati. Ciò richiede normalmente la distribuzione, l'apprendimento e la gestione di un altro strumento completamente nuovo come Prometheus o Grafana.
Ecco perché abbiamo deciso di costruire Lakeflow, una soluzione unificata per l'ingestione, la trasformazione e l'orchestrazione dei dati potenziata dall'intelligenza dei dati. I suoi tre componenti chiave sono: Lakeflow Connect, Lakeflow Pipelines e Lakeflow Jobs.
Lakeflow Connect: Ingestione dati semplice e scalabile
Lakeflow Connect fornisce ingestione dati point-and-click da database come SQL Server e applicazioni aziendali come Salesforce, Workday, Google Analytics e ServiceNow. La roadmap include anche database come MySQL, Postgres e Oracle, nonché applicazioni aziendali come NetSuite, Dynamics 365 e Google Ads. Lakeflow Connect può anche ingerire dati non strutturati come PDF e fogli di calcolo Excel da origini come SharePoint.
Integra i nostri popolari connettori nativi per lo storage cloud (ad es. connettori S3, ADLS Gen2 e GCS) e le code (ad es. connettori Kafka, Kinesis, Event Hub e Pub/Sub), e soluzioni partner come Fivetran, Qlik e Informatica.
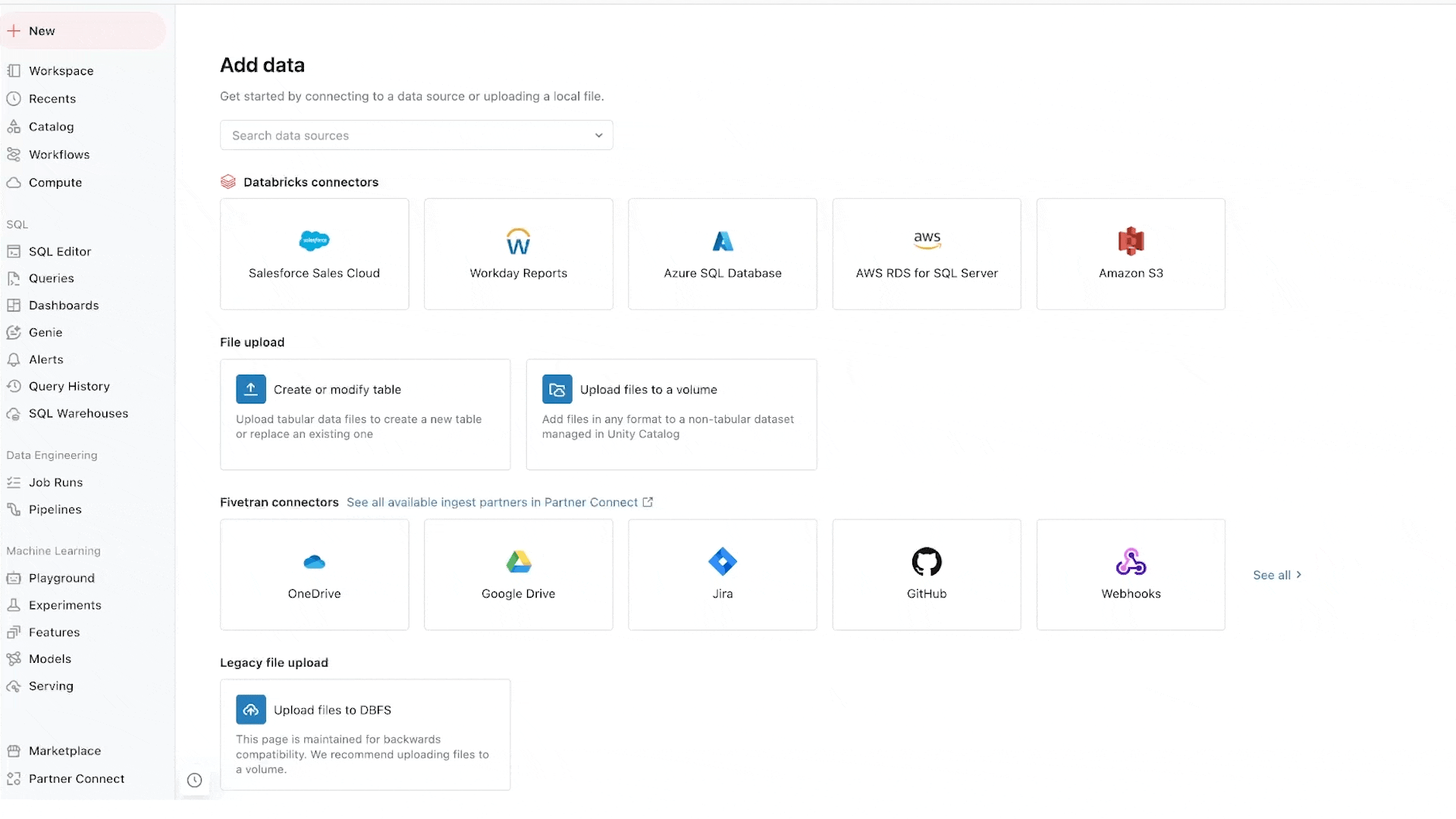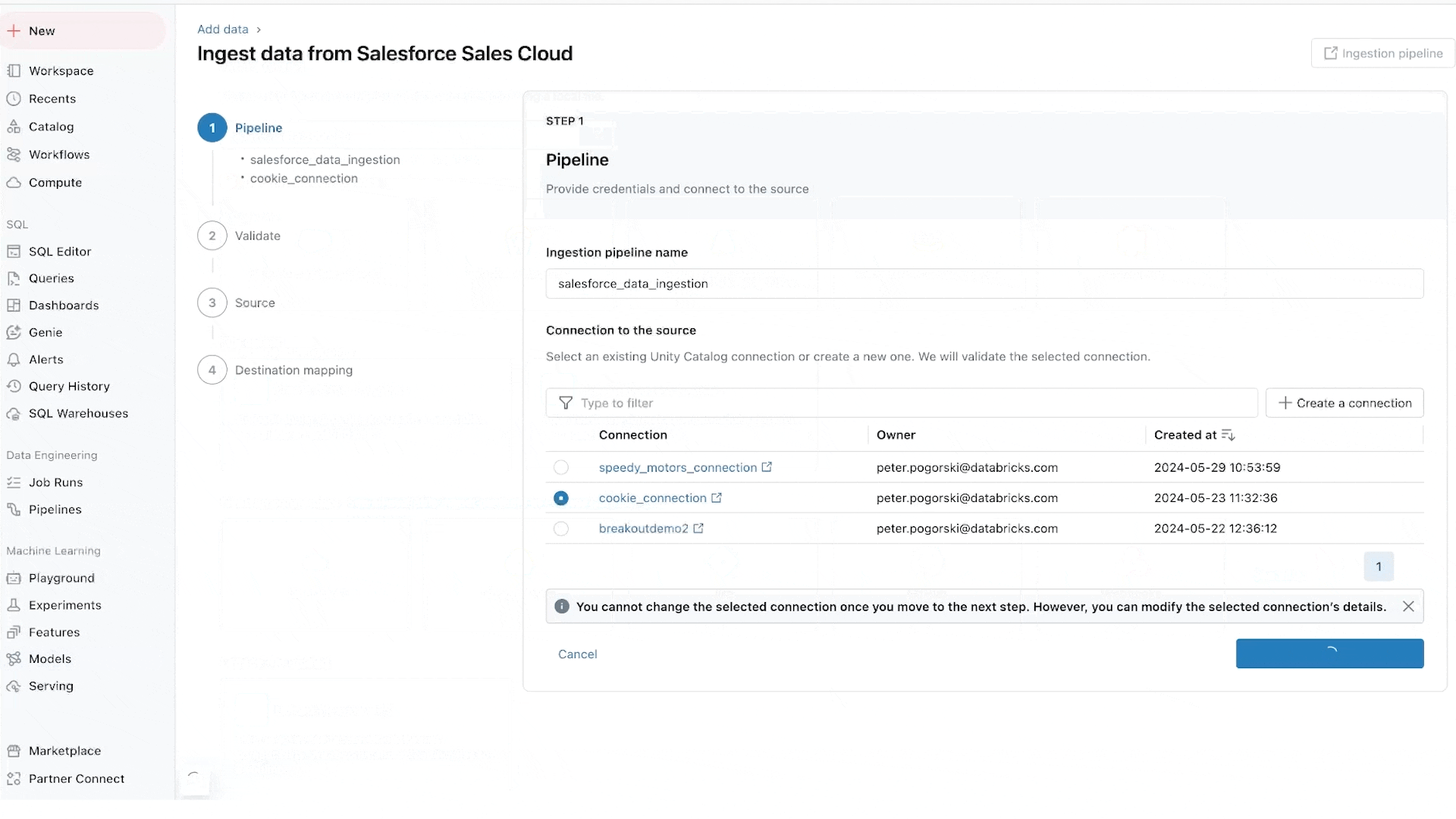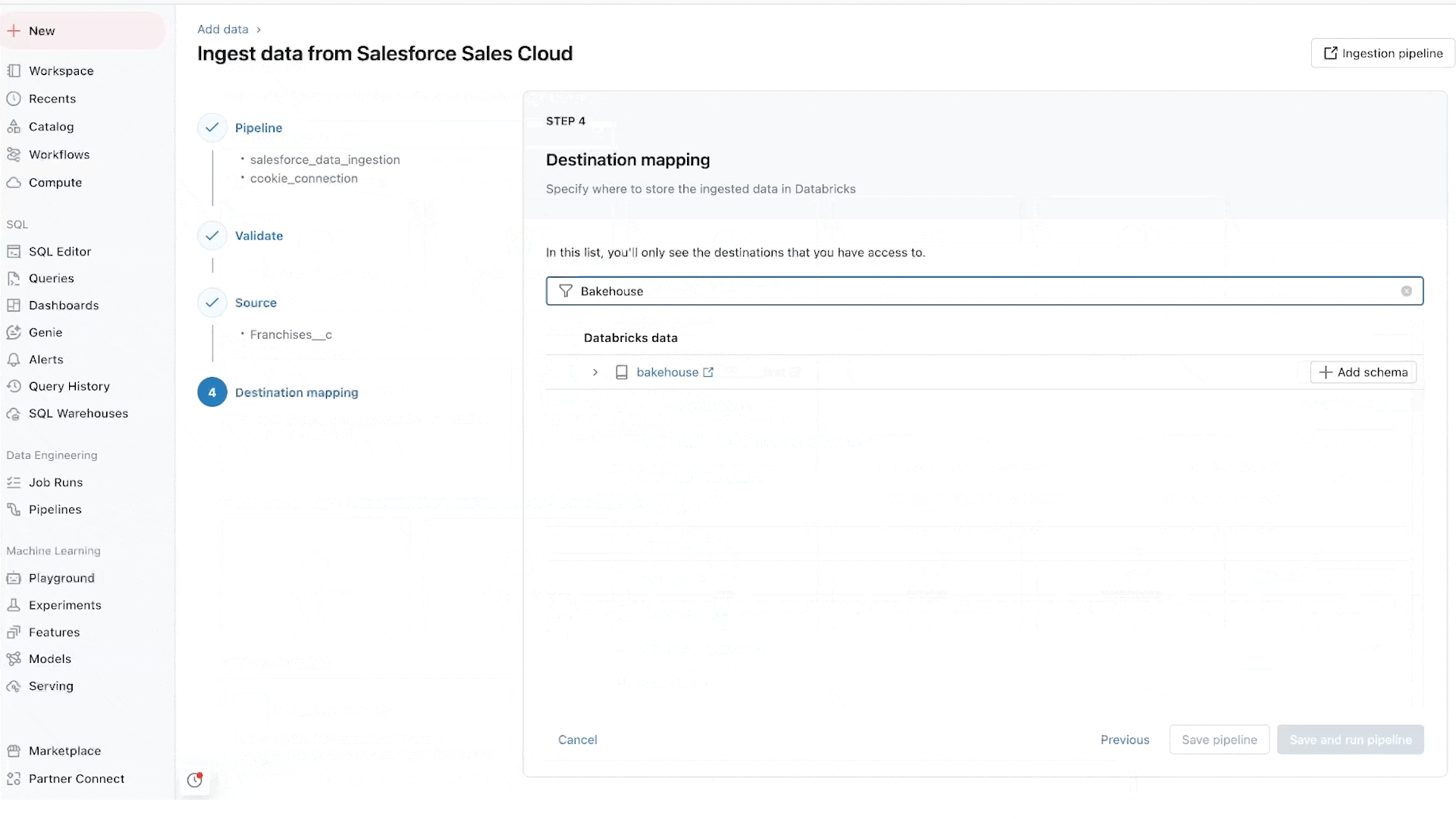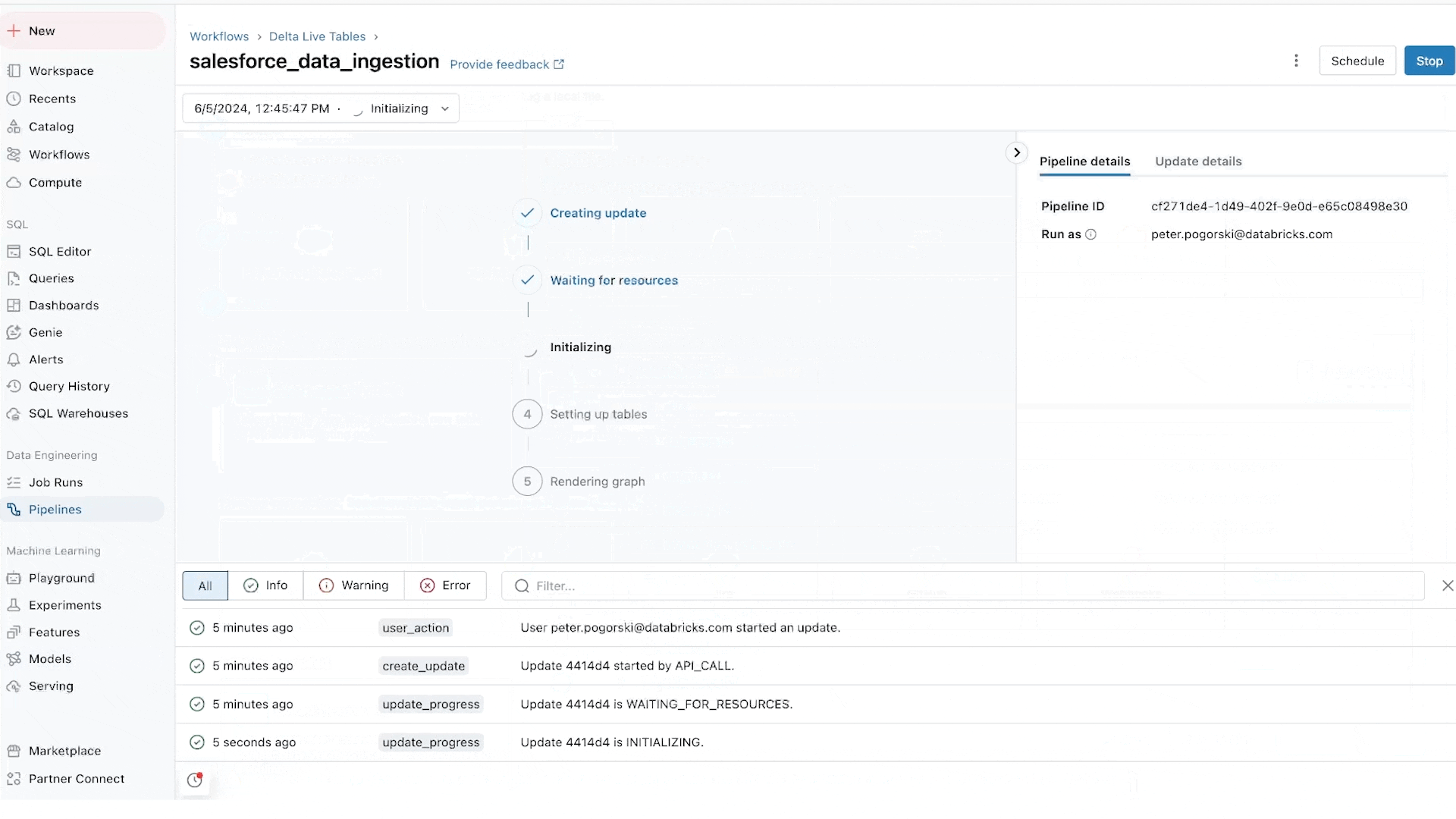
Siamo particolarmente entusiasti dei connettori per database, che sono potenziati dalla nostra acquisizione di Arcion. Un'incredibile quantità di dati preziosi è bloccata nei database operativi. Invece di approcci ingenui per caricare questi dati, che incontrano problemi operativi e di scalabilità, Lakeflows utilizza la tecnologia change data capture (CDC) per rendere semplice, affidabile ed efficiente dal punto di vista operativo portare questi dati nel tuo lakehouse.
I clienti Databricks che utilizzano Lakeflow Connect scoprono che una soluzione di ingestione semplice migliora la produttività e consente loro di passare più velocemente dai dati alle informazioni. Insulet, un produttore di un sistema indossabile per la gestione dell'insulina, l'Omnipod, utilizza il connettore di ingestione Salesforce per ingerire dati relativi al feedback dei clienti nella loro soluzione dati costruita su Databricks. Questi dati vengono resi disponibili per l'analisi tramite Databricks SQL per ottenere informazioni sui problemi di qualità e monitorare i reclami dei clienti. Il team ha trovato un valore significativo nell'utilizzo delle nuove funzionalità di Lakeflow Connect.
"Con il nuovo connettore di ingestione Salesforce di Databricks, abbiamo semplificato significativamente il nostro processo di integrazione dei dati eliminando middleware fragili e problematici. Questo miglioramento consente a Databricks SQL di analizzare direttamente i dati Salesforce all'interno di Databricks. Di conseguenza, i nostri data practitioner possono ora fornire informazioni aggiornate quasi in tempo reale, riducendo la latenza da giorni a minuti." —Bill Whiteley, Senior Director of AI, Analytics, and Advanced Algorithms, Insulet
Lakeflow Pipelines: Pipeline di dati dichiarative efficienti
Lakeflow Pipelines riduce la complessità della creazione e della gestione di pipeline di dati batch e in streaming efficienti. Costruite sul framework dichiarativo Delta Live Tables, ti liberano per scrivere logica di business in SQL e Python, mentre Databricks automatizza l'orchestrazione dei dati, l'elaborazione incrementale e l'autoscaling dell'infrastruttura di calcolo per tuo conto. Inoltre, Lakeflow Pipelines offre monitoraggio integrato della qualità dei dati e la sua modalità Real Time consente di abilitare la consegna a bassa latenza costante di set di dati sensibili al tempo senza alcuna modifica al codice.
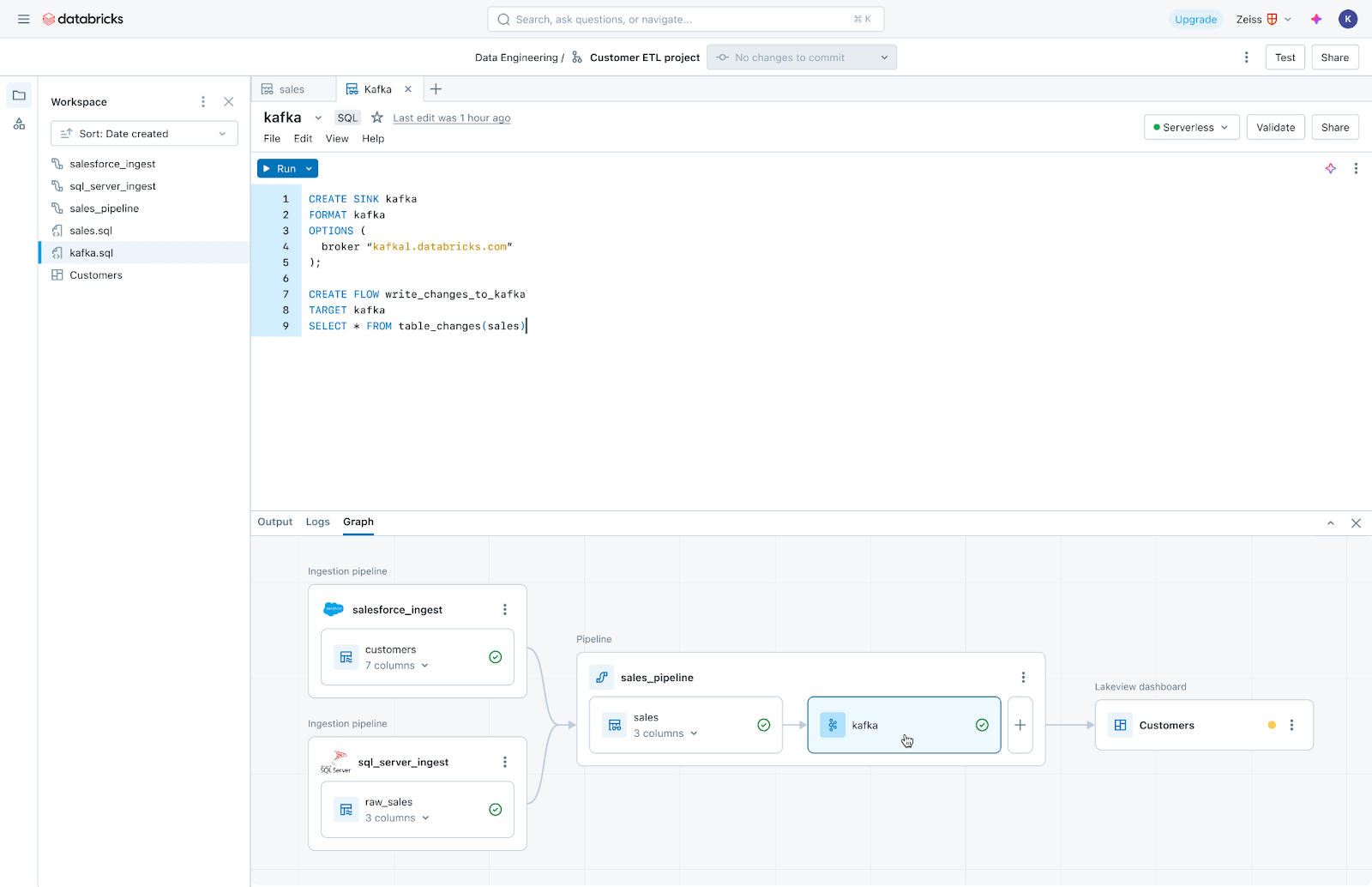
Lakeflow Jobs: Orchestrazione affidabile per ogni carico di lavoro
Lakeflow Jobs orchestra e monitora in modo affidabile i carichi di lavoro di produzione. Costruito sulle funzionalità avanzate di Databricks Workflows, orchestra qualsiasi carico di lavoro, inclusi ingestione, pipeline, notebook, query SQL, training di machine learning, distribuzione di modelli e inferenza. I team di dati possono anche sfruttare trigger, branching e looping per soddisfare casi d'uso complessi di consegna dei dati.
Lakeflow Jobs automatizza e semplifica anche il processo di comprensione e monitoraggio della salute e della consegna dei dati. Adotta una visione data-first della salute, fornendo ai team di dati la completa provenienza, comprese le relazioni tra ingestione, trasformazioni, tabelle e dashboard. Inoltre, monitora la freschezza e la qualità dei dati, consentendo ai team di dati di aggiungere monitor tramite Lakehouse Monitoring con un clic.
Costruito sulla Piattaforma di Intelligenza dei Dati
Databricks Lakeflow è integrato nativamente con la nostra Piattaforma di Intelligenza dei Dati, che offre queste funzionalità:
- Intelligenza dei dati: L'intelligenza potenziata dall'AI non è solo una funzionalità di Lakeflow, è una capacità fondamentale che tocca ogni aspetto del prodotto. Databricks Assistant potenzia la scoperta, la creazione e il monitoraggio delle pipeline di dati, in modo che tu possa dedicare più tempo alla creazione di dati affidabili.
- Governance unificata: Lakeflow è anche profondamente integrato con Unity Catalog, che potenzia la provenienza e la qualità dei dati.
- Calcolo serverless: Crea e orchestra pipeline su larga scala e aiuta il tuo team a concentrarsi sul lavoro senza doversi preoccupare dell'infrastruttura.
Il futuro dell'ingegneria dei dati è semplice, unificato e intelligente
Crediamo che Lakeflow consentirà ai nostri clienti di fornire dati più freschi, completi e di alta qualità alle loro aziende. Lakeflow entrerà presto in anteprima a partire da Lakeflow Connect. Se desideri richiedere l'accesso, iscriviti qui. Nei prossimi mesi, cerca altri annunci di Lakeflow man mano che diventano disponibili funzionalità aggiuntive.
Vuoi vederlo in azione?
Prova il Tour del Prodotto Lakeflow per ingerire, trasformare e distribuire dati da più origini in batch e in tempo reale in produzione senza interruzioni.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.